分詞算法是自然語言處理(NLP)中的一個重要預處理步驟,它將文本分割成更小的單元(如單詞、子詞或字符)。以下是幾種常見的分詞算法:Byte Pair Encoding (BPE)、Byte-level BPE (BBPE)、WordPiece 和 Unigram Language Model (ULM)
1. Byte Pair Encoding (BPE)
論文摘要
- 標題:Neural Machine Translation of Rare Words with Subword Units
- 連接:點擊這里閱讀論文全文
核心思想
從一個基礎小詞表開始,通過不斷合并最高頻的連續token對來產生新的token。
詳細可參考BPE 算法原理及使用指南【深入淺出】

具體做法
- 準備基礎詞表,如英文中26個字母加上各種符號,并初始化ID。
- 基于基礎詞表將準備的語料拆分為最小單元,末尾添加</ w>(示例中使用_)。
- 在語料上統計單詞內相鄰單元對的頻率,選擇頻率最高的單元對進行合并。
- 重復第3步直到達到預先設定的subword詞表大小或下一個最高頻率為1。
優缺點
- 優點:可以有效地平衡詞匯表大小和編碼步數。
- 缺點:
- 無法提供帶概率的多個分詞結果。
- 局部高頻對合并可能破壞全局更有意義的組合。
2. Byte-level BPE (BBPE)
論文信息
- 標題:Neural Machine Translation with Byte-Level Subwords
- 鏈接:https://arxiv.org/pdf/1909.03341
核心思想
該論文提出了一種名為BBPE(Byte-level BPE)的新型機器翻譯方法,將傳統BPE的字符級操作擴展到字節級別,直接處理UTF-8編碼的字節序列。此舉有助于避免傳統字符級BPE中稀有字符(如生僻漢字)占用詞表空間的問題。
具體做法
- 使用基礎詞表,采用256的字節集,UTF-8編碼。
優點
- 與BPE相媲美,但詞表大為減小。
- 可在多語言間通過字節級別的子詞實現更好的共享。
- 即使字符集不重疊,也可通過字節層面的共享實現良好的遷移。
- 高效的壓縮效果,根據文本中的重復模式和常見片段來動態生成詞匯表,尤其適用于大量重復內容的文本數據。
- 適用于多種類型的數據,包括文本、圖像等,因其基于字節級別的編碼方法。
- 無損壓縮,確保壓縮后的數據與原始數據無信息損失。
- 可解碼性,可輕松將編碼后的數據解碼回原始數據。
- 靈活性高,可根據需求調整壓縮效果和詞匯表大小。
缺點
- 編碼序列時可能略長于BPE,計算成本更高。
- 由byte解碼時可能會遇到歧義,需要通過上下文信息和動態規劃進行解碼,確保輸出有效句子。
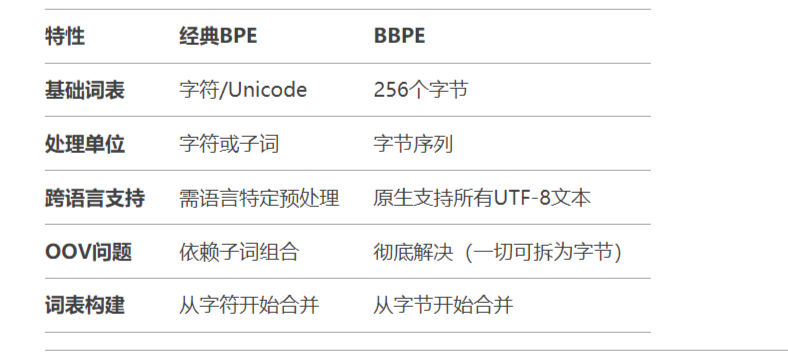
BBPE和BPE的關鍵區別
3. WordPiece
論文:Fast WordPiece Tokenization
- 鏈接:https://arxiv.org/pdf/2012.15524
核心思想
與BPE類似,Fast WordPiece Tokenization 從基礎小詞表出發,通過合并子詞來生成最終詞表。不同之處在于,WordPiece 選擇合并的token對時基于token間的互信息而非頻率。這里的互信息衡量的是兩個子詞同時出現的概率相比于它們各自獨立出現的概率。

具體做法
-
輸入:訓練語料和詞表大小 V。
-
準備基礎詞表,如英文字母和符號。
-
使用基礎詞表將語料拆分為最小單元。
-
基于拆分后的數據訓練語言模型,可以是 unigram 語言模型,通過極大似然估計。

-
選擇能最大程度增加訓練數據概率的 token 對進行合并。假設句子由 N 個子詞組成 S = ( t 1 , t 2 , . . . , t N ) S = (t_1, t_2, ..., t_N) S=(t1?,t2?,...,tN?),句子的似然值為所有子詞概率的乘積:
log ? P ( s ) = ∑ i = 1 N log ? P ( t i ) \log P(s) = \sum_{i=1}^{N} \log P(t_i) logP(s)=i=1∑N?logP(ti?)
合并相鄰兩個子詞 x 和 y 產生新的子詞 z,句子的似然值變化為兩個子詞之間的互信息:
log ? P ( t z ) ? ( log ? P ( t x ) + log ? P ( t y ) ) = log ? P ( t z ) P ( t x ) P ( t y ) \log P(t_z) - (\log P(t_x) + \log P(t_y)) = \log \frac{P(t_z)}{P(t_x)P(t_y)} logP(tz?)?(logP(tx?)+logP(ty?))=logP(tx?)P(ty?)P(tz?)?
每次選擇互信息最大的兩個子詞合并,基于子詞在語言模型上的關聯性,得分計算公式為:
score = P ( t z ) P ( t x ) P ( t y ) \text{score} = \frac{P(t_z)}{P(t_x)P(t_y)} score=P(tx?)P(ty?)P(tz?)? -
重復第 5 步直到達到預設的子詞表大小或概率增量低于閾值。
優點
- 能平衡詞表大小和 OOV 問題
缺點
- 可能產生一些不合理的子詞或錯誤劃分
- 拼寫錯誤敏感
- 對前綴支持不夠好
一種解決方案是將復合詞和前綴拆開處理。
4. Unigram Language Model (ULM)
核心思想
初始化一個大詞表,然后通過unigram語言模型計算刪除不同subword造成的損失來代表subword的重要性,保留loss較大或者說重要性較高的subword。ULM會傾向于保留那些以較高頻率出現在很多句子的分詞結果中的子詞,因為這些子詞如果被刪除,其損失會很大。
具體做法
-
輸入訓練語料和詞表大小V
-
準備基礎詞表:初始化一個很大的詞表,比如所有字符+高頻ngram,也可以通過BPE算法初始化
-
針對當前詞表,用語言模型(unigram lm)估計每個子詞在語料上的概率,比如EM算法,維特比算法尋找最優分割

-
計算刪除每個subword后對總loss的影響,作為該subword的loss
-
將子詞按照loss大小進行排序,保留前x%的子詞;注意,單字符不能被丟棄,以免OOV
-
重復步驟2到4,直到詞表大小減少到設定值
優點
- 使用的訓練算法可以利用所有可能的分詞結果,這是通過data sampling算法實現的
- 提出一種基于語言模型的分詞算法,這種語言模型可以給多種分詞結果賦予概率,從而可以學到其中的噪聲
- 使用時也可以給出帶概率的多個分詞結果
缺點
- 效果與初始詞表息息相關,初始的大詞表要足夠好,比如可以通過BPE來初始化
- 略顯復雜



)


)


:Linux權限管理)









