機器翻譯與數據集
語言模型是自然語言處理的關鍵,而機器翻譯是語言模型最成功的基準測試。因為機器翻譯正是將輸入序列轉換成輸出序列的序列轉換模型(sequence transduction)的核心問題。序列轉換模型在各類現代人工智能應用中發揮著至關重要的作用。
機器翻譯(machine translation)指的是將序列從一種語言自動翻譯成另一種語言。事實上,這個研究領域可以追溯到數字計算機發明后不久的20世紀40年代,特別是在第二次世界大戰中使用計算機破解語言編碼。幾十年來,在使用神經網絡進行端到端學習的興起之前,統計學方法在這一領域一直占據主導地位 :cite:Brown.Cocke.Della-Pietra.ea.1988,Brown.Cocke.Della-Pietra.ea.1990。因為統計機器翻譯(statistical machine translation)涉及了翻譯模型和語言模型等組成部分的統計分析,因此基于神經網絡的方法通常被稱為神經機器翻譯(neural machine translation),用于將兩種翻譯模型區分開來。
關注神經網絡機器翻譯方法,強調的是端到端的學習。與語言模型中的語料庫是單一語言的語言模型問題存在不同,機器翻譯的數據集是由源語言和目標語言的文本序列對組成的。因此,我們需要一種完全不同的方法來預處理機器翻譯數據集,而不是復用語言模型的預處理程序。下面,我們看一下如何將預處理后的數據加載到小批量中用于訓練。
import os
import torch
from d2l import torch as d2l
[下載和預處理數據集]
首先,下載一個由Tatoeba項目的雙語句子對組成的“英-法”數據集,數據集中的每一行都是制表符分隔的文本序列對,序列對由英文文本序列和翻譯后的法語文本序列組成。請注意,每個文本序列可以是一個句子,也可以是包含多個句子的一個段落。在這個將英語翻譯成法語的機器翻譯問題中,英語是源語言(source language),法語是目標語言(target language)。
# @save
# 將“英語-法語”數據集的URL和校驗碼添加到d2l.DATA_HUB中
# d2l.DATA_HUB是一個字典,用于存儲數據集的下載鏈接和校驗碼
# 'fra-eng' 是數據集的名稱
# d2l.DATA_URL 是數據集的基礎URL
# '94646ad1522d915e7b0f9296181140edcf86a4f5' 是數據集的SHA-1校驗碼,用于驗證文件完整性
d2l.DATA_HUB['fra-eng'] = (d2l.DATA_URL + 'fra-eng.zip','94646ad1522d915e7b0f9296181140edcf86a4f5')# @savedef read_data_nmt():"""載入“英語-法語”數據集。返回:str包含整個數據集的文本內容,每一行是一個制表符分隔的文本序列對。"""# 下載并解壓“英語-法語”數據集# d2l.download_extract 會根據提供的名稱從 d2l.DATA_HUB 下載數據集并解壓data_dir = d2l.download_extract('fra-eng')# 打開解壓后的數據文件 'fra.txt',以只讀模式讀取內容# 使用 UTF-8 編碼以確保正確處理非ASCII字符with open(os.path.join(data_dir, 'fra.txt'), 'r',encoding='utf-8') as f:# 讀取整個文件內容并返回return f.read()# 調用 read_data_nmt 函數,讀取“英語-法語”數據集的原始文本內容
raw_text = read_data_nmt()
# 打印原始文本的前75個字符,方便快速查看數據內容
print(raw_text[:75])

下載數據集后,原始文本數據需要經過幾個預處理步驟。例如用空格代替不間斷空格(non-breaking space),使用小寫字母替換大寫字母,并在單詞和標點符號之間插入空格。
#@save
def preprocess_nmt(text):"""預處理“英語-法語”數據集"""def no_space(char, prev_char):"""判斷是否需要在當前字符和前一個字符之間插入空格。如果當前字符是標點符號(如,.!?)且前一個字符不是空格,則返回True。"""return char in set(',.!?') and prev_char != ' '# 使用空格替換不間斷空格(\u202f)和不可換行空格(\xa0)# 將所有字符轉換為小寫字母text = text.replace('\u202f', ' ').replace('\xa0', ' ').lower()# 遍歷文本中的每個字符# 如果當前字符是標點符號且前一個字符不是空格,則在標點符號前插入一個空格# 否則,保持字符不變out = [' ' + char if i > 0 and no_space(char, text[i - 1]) else charfor i, char in enumerate(text)]# 將字符列表合并為字符串并返回return ''.join(out)# 對原始文本進行預處理
text = preprocess_nmt(raw_text)# 打印預處理后的文本的前80個字符
print(text[:80])
詞元化
與語言模型中的字符級詞元化不同,在機器翻譯中,更喜歡單詞級詞元化(最先進的模型可能使用更高級的詞元化技術)。下面的tokenize_nmt函數對前num_examples個文本序列對進行詞元,其中每個詞元要么是一個詞,要么是一個標點符號。此函數返回兩個詞元列表:source和target:source[i]是源語言(這里是英語)第 i i i個文本序列的詞元列表,target[i]是目標語言(這里是法語)第 i i i個文本序列的詞元列表。
#@save
def tokenize_nmt(text, num_examples=None):"""詞元化“英語-法語”數據集。將文本數據分割成源語言和目標語言的詞元列表。參數:text: str包含“英語-法語”數據集的原始文本。每一行是一個制表符分隔的文本序列對(英語和法語)。num_examples: int, 可選指定要處理的最大文本序列對數量。如果為None,則處理所有文本序列對。返回:source: list of list of str源語言(英語)的詞元列表,每個子列表對應一個文本序列。target: list of list of str目標語言(法語)的詞元列表,每個子列表對應一個文本序列。"""source, target = [], [] # 初始化源語言和目標語言的詞元列表for i, line in enumerate(text.split('\n')): # 按行分割文本數據if num_examples and i > num_examples: # 如果達到指定的最大數量,則停止處理breakparts = line.split('\t') # 按制表符分割每一行,得到源語言和目標語言的文本"""line = "I am a student.\tJe suis un étudiant.""""if len(parts) == 2: # 確保每一行有且僅有兩個部分(源語言和目標語言)source.append(parts[0].split(' ')) # 將源語言文本按空格分割成詞元列表target.append(parts[1].split(' ')) # 將目標語言文本按空格分割成詞元列表return source, target # 返回源語言和目標語言的詞元列表# 對預處理后的文本進行詞元化
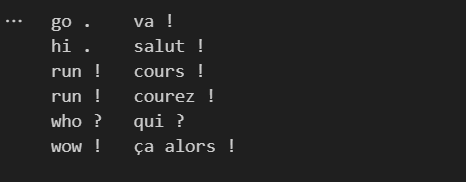
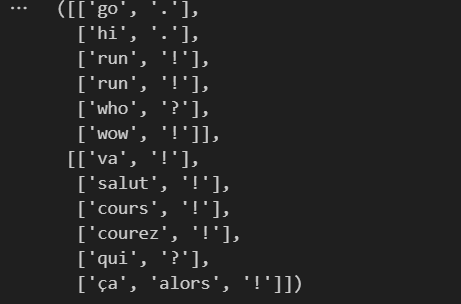
source, target = tokenize_nmt(text)# 打印源語言和目標語言的前6個文本序列的詞元列表
source[:6], target[:6]
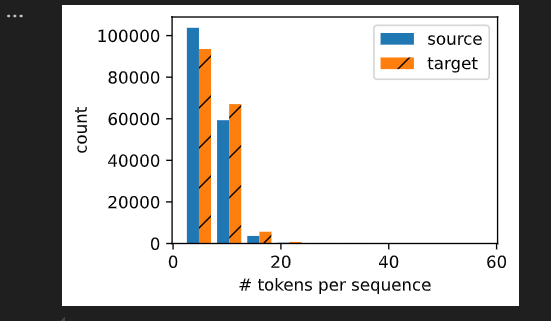
繪制每個文本序列所包含的詞元數量的直方圖。在這個簡單的“英-法”數據集中,大多數文本序列的詞元數量少于 20 20 20個。
#@save
def show_list_len_pair_hist(legend, xlabel, ylabel, xlist, ylist):"""繪制兩個列表中元素長度的直方圖。參數:legend: list of str圖例的標簽列表,用于標識兩個列表的名稱。xlabel: strx軸的標簽,表示橫軸的含義。ylabel: stry軸的標簽,表示縱軸的含義。xlist: list of list第一個列表,包含多個子列表,每個子列表的長度將用于繪制直方圖。ylist: list of list第二個列表,包含多個子列表,每個子列表的長度將用于繪制直方圖。"""# 設置圖形的大小d2l.set_figsize()# 繪制直方圖,統計兩個列表中每個子列表的長度# patches 是一個包含直方圖條形對象的列表_, _, patches = d2l.plt.hist([[len(l) for l in xlist], [len(l) for l in ylist]]) # 計算每個子列表的長度并繪制直方圖# 設置x軸的標簽d2l.plt.xlabel(xlabel)# 設置y軸的標簽d2l.plt.ylabel(ylabel)# 為第二個列表的直方圖條形添加斜線填充樣式,以便區分兩個列表for patch in patches[1].patches:patch.set_hatch('/')# 添加圖例,用于標識兩個列表d2l.plt.legend(legend)# 調用函數,繪制源語言和目標語言的詞元數量直方圖
show_list_len_pair_hist(['source', 'target'], '# tokens per sequence','count', source, target);
詞表
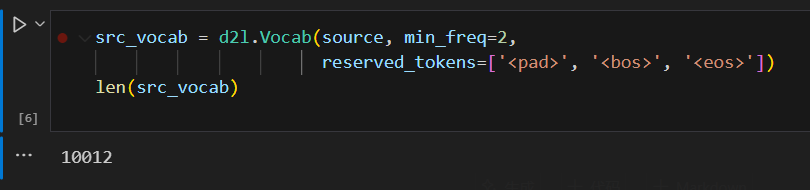
由于機器翻譯數據集由語言對組成,因此我們可以分別為源語言和目標語言構建兩個詞表。使用單詞級詞元化時,詞表大小將明顯大于使用字符級詞元化時的詞表大小。為了緩解這一問題,這里我們將出現次數少于2次的低頻率詞元視為相同的未知(“<unk>”)詞元。除此之外,我們還指定了額外的特定詞元,例如在小批量時用于將序列填充到相同長度的填充詞元(“<pad>”),以及序列的開始詞元(“<bos>”)和結束詞元(“<eos>”)。這些特殊詞元在自然語言處理任務中比較常用。
加載數據集
語言模型中的[序列樣本都有一個固定的長度],無論這個樣本是一個句子的一部分還是跨越了多個句子的一個片斷。這個固定長度是由語言模型中的num_steps(時間步數或詞元數量)參數指定的。在機器翻譯中,每個樣本都是由源和目標組成的文本序列對,其中的每個文本序列可能具有不同的長度。
為了提高計算效率,我們仍然可以通過截斷(truncation)和填充(padding)方式實現一次只處理一個小批量的文本序列。假設同一個小批量中的每個序列都應該具有相同的長度num_steps,那么如果文本序列的詞元數目少于num_steps時,我們將繼續在其末尾添加特定的“<pad>”詞元,直到其長度達到num_steps;反之,我們將截斷文本序列時,只取其前num_steps 個詞元,并且丟棄剩余的詞元。這樣,每個文本序列將具有相同的長度,以便以相同形狀的小批量進行加載。
如前所述,下面的truncate_pad函數將(截斷或填充文本序列)。
#@save
def truncate_pad(line, num_steps, padding_token):"""截斷或填充文本序列。參數:line: list of int表示文本序列的詞元索引列表。num_steps: int指定序列的目標長度。padding_token: int用于填充的特殊詞元索引。返回:list of int經過截斷或填充后的文本序列,長度為num_steps。"""if len(line) > num_steps:# 如果序列長度超過目標長度,則截斷到目標長度return line[:num_steps]# 如果序列長度小于目標長度,則在末尾填充指定的填充詞元,直到達到目標長度"""在 Python 中,列表乘法(*)的行為是:如果乘數為正數,生成一個重復的列表。如果乘數為 0 或負數,返回一個空列表。"""return line + [padding_token] * (num_steps - len(line))# 調用truncate_pad函數,對源語言的第一個文本序列進行截斷或填充
# 將其轉換為長度為10的序列,使用src_vocab['<pad>']作為填充詞元
truncate_pad(src_vocab[source[0]], 10, src_vocab['<pad>'])

現在我們定義一個函數,可以將文本序列[轉換成小批量數據集用于訓練]。我們將特定的“<eos>”詞元添加到所有序列的末尾,用于表示序列的結束。當模型通過一個詞元接一個詞元地生成序列進行預測時,生成的“<eos>”詞元說明完成了序列輸出工作。此外,我們還記錄了每個文本序列的長度,統計長度時排除了填充詞元,在稍后將要介紹的一些模型會需要這個長度信息。
#@save
def build_array_nmt(lines, vocab, num_steps):"""將機器翻譯的文本序列轉換成小批量。參數:lines: list of list of str文本序列的詞元列表,每個子列表表示一個文本序列。vocab: d2l.Vocab詞表對象,用于將詞元轉換為索引。num_steps: int每個序列的目標長度(時間步數)。返回:array: torch.Tensor轉換后的張量,形狀為 (batch_size, num_steps),每行表示一個經過截斷或填充的文本序列。valid_len: torch.Tensor每個序列的有效長度(不包括填充詞元的長度),形狀為 (batch_size,)。"""# 將每個文本序列中的詞元轉換為對應的索引lines = [vocab[l] for l in lines]# 在每個序列的末尾添加特殊的結束詞元(<eos>)lines = [l + [vocab['<eos>']] for l in lines]# 對每個序列進行截斷或填充,使其長度為num_steps# 并將結果轉換為PyTorch張量array = torch.tensor([truncate_pad(l, num_steps, vocab['<pad>']) for l in lines])# 計算每個序列的有效長度(不包括填充詞元的長度)# 使用 (array != vocab['<pad>']) 判斷哪些位置不是填充詞元# 然后對每行的非填充詞元計數valid_len = (array != vocab['<pad>']).type(torch.int32).sum(1)# 返回轉換后的張量和有效長度return array, valid_len
訓練模型
最后定義load_data_nmt函數來返回數據迭代器,以及源語言和目標語言的兩種詞表。
#@save
def load_data_nmt(batch_size, num_steps, num_examples=600):"""返回翻譯數據集的迭代器和詞表。參數:batch_size: int每個小批量的樣本數量。num_steps: int每個序列的目標長度(時間步數)。num_examples: int, 可選要處理的最大文本序列對數量,默認為600。返回:data_iter: torch.utils.data.DataLoader數據迭代器,用于按小批量加載數據。src_vocab: d2l.Vocab源語言的詞表對象。tgt_vocab: d2l.Vocab目標語言的詞表對象。"""# 讀取并預處理原始的“英語-法語”數據集text = preprocess_nmt(read_data_nmt())# 對預處理后的文本進行詞元化,得到源語言和目標語言的詞元列表source, target = tokenize_nmt(text, num_examples)# 構建源語言的詞表,過濾掉出現次數少于2次的低頻詞元# 并添加特殊詞元(<pad>, <bos>, <eos>)src_vocab = d2l.Vocab(source, min_freq=2,reserved_tokens=['<pad>', '<bos>', '<eos>'])# 構建目標語言的詞表,過濾掉出現次數少于2次的低頻詞元# 并添加特殊詞元(<pad>, <bos>, <eos>)tgt_vocab = d2l.Vocab(target, min_freq=2,reserved_tokens=['<pad>', '<bos>', '<eos>'])# 將源語言的詞元列表轉換為張量,并進行截斷或填充# src_array: 轉換后的張量,形狀為 (num_examples, num_steps)# src_valid_len: 每個序列的有效長度(不包括填充詞元的長度)src_array, src_valid_len = build_array_nmt(source, src_vocab, num_steps)# 將目標語言的詞元列表轉換為張量,并進行截斷或填充# tgt_array: 轉換后的張量,形狀為 (num_examples, num_steps)# tgt_valid_len: 每個序列的有效長度(不包括填充詞元的長度)tgt_array, tgt_valid_len = build_array_nmt(target, tgt_vocab, num_steps)# 將源語言和目標語言的張量及其有效長度打包為一個元組data_arrays = (src_array, src_valid_len, tgt_array, tgt_valid_len)# 使用d2l提供的load_array函數,將數據打包為數據迭代器# data_iter: 數據迭代器,用于按小批量加載數據data_iter = d2l.load_array(data_arrays, batch_size)# 返回數據迭代器以及源語言和目標語言的詞表return data_iter, src_vocab, tgt_vocab
下面讀出“英語-法語”數據集中的第一個小批量數據。
train_iter, src_vocab, tgt_vocab = load_data_nmt(batch_size=2, num_steps=8)
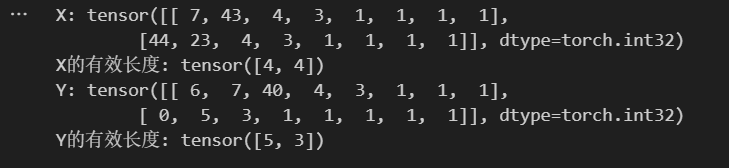
for X, X_valid_len, Y, Y_valid_len in train_iter:print('X:', X.type(torch.int32))print('X的有效長度:', X_valid_len)print('Y:', Y.type(torch.int32))print('Y的有效長度:', Y_valid_len)break
小結
- 機器翻譯指的是將文本序列從一種語言自動翻譯成另一種語言。
- 使用單詞級詞元化時的詞表大小,將明顯大于使用字符級詞元化時的詞表大小。為了緩解這一問題,我們可以將低頻詞元視為相同的未知詞元。
- 通過截斷和填充文本序列,可以保證所有的文本序列都具有相同的長度,以便以小批量的方式加載。
以下是將你提供的內容整理為結構清晰、格式良好的 Markdown 版本文檔:
問題與回答總結
問題 1:在 load_data_nmt 函數中嘗試不同的 num_examples 參數值。這對源語言和目標語言的詞表大小有何影響?
回答:
num_examples 參數決定了處理的文本序列對的數量。較小的 num_examples 值會減少處理的文本序列對,從而影響源語言和目標語言的詞表大小。
影響分析:
詞表大小的變化:
- 詞表構建基礎:詞表的大小取決于處理的文本序列中出現的唯一詞元數量。
- 參數影響:
- 如果
num_examples較小,則處理的文本序列對較少,詞表中的詞元數量也會減少。 - 如果
num_examples較大,則處理的文本序列對較多,詞表中的詞元數量會更多。
- 如果
相關代碼部分:
在 load_data_nmt 函數中,num_examples 參數限制了 tokenize_nmt 函數處理的文本序列對數量。
詞表的構建依賴于 source 和 target 中的詞元。
實驗示例:
假設 num_examples 分別為 100 和 1000:
- 當
num_examples=100時,詞表大小可能較小,因為處理的文本序列對較少。 - 當
num_examples=1000時,詞表大小會更大,因為處理的文本序列對更多,包含的詞元也更多。
結論:
num_examples的值越大,源語言和目標語言的詞表大小越大。- 選擇合適的
num_examples需要權衡計算效率和模型性能。
問題 2:某些語言(例如中文和日語)的文本沒有單詞邊界指示符(例如空格)。對于這種情況,單詞級詞元化仍然是個好主意嗎?為什么?
回答:
對于中文和日語等沒有明確單詞邊界的語言,單詞級詞元化可能不是最優選擇,但仍然可以使用,具體取決于任務需求和模型設計。
分析:
單詞邊界的缺失:
- 中文和日語文本通常是連續的字符串,沒有空格分隔單詞。
- 直接使用空格分割的單詞級詞元化方法無法正確識別單詞邊界。
單詞級詞元化的適用性:
- 如果可以借助分詞工具(如
jieba或MeCab),可以對中文或日語文本進行分詞,從而實現單詞級詞元化。 - 這種方式適用于需要捕獲更高層次語義的任務。
替代方法:
-
字符級詞元化:
- 將每個字符作為一個詞元。
- 適用于中文和日語,因為這些語言的字符通常具有獨立的語義。
-
子詞級詞元化:
- 使用 BPE(Byte Pair Encoding)或 WordPiece 等方法。
- 將文本分割為子詞單元,適用于多種語言,包括中文和日語。
相關代碼部分:
當前代碼中,tokenize_nmt 函數使用空格分割單詞:
text.split(' ')
對于中文和日語,需要替換為分詞工具的輸出。
結論:
- 如果可以使用分詞工具,單詞級詞元化仍然是一個好主意,因為它能有效捕獲高層次的語義信息。
- 如果無法分詞或分詞效果較差,可以考慮使用字符級或子詞級詞元化作為替代方案。



)



)
)

 節點/etc/kubernetes/manifests 不存在)

領域)






![洛谷 P9007 [入門賽 #9] 最澄澈的空與海 (Hard Version)](http://pic.xiahunao.cn/洛谷 P9007 [入門賽 #9] 最澄澈的空與海 (Hard Version))