隨著數據量呈指數級增長,企業面臨著如何有效管理、存儲和分析這些數據的挑戰。 大數據平臺和 數據倉庫作為兩種主流的數據管理工具,常常讓企業在選型時感到困惑,它們之間的界限似乎越來越模糊,功能也有所重疊。本文旨在厘清這兩種技術的核心差異,并為企業提供一個實用的選型參考框架。
基礎概念解析
什么是大數據平臺?
大數據平臺是為了處理海量、多樣化數據而設計的分布式計算和存儲系統。它不僅僅是一種技術,而是一整套解決方案,包括數據采集、存儲、處理、分析和可視化等多個環節。
核心能力:
- 海量異構數據的存儲與分布式計算
- 實時和批量數據處理
- 支持多種數據格式和來源
- 橫向擴展能力強
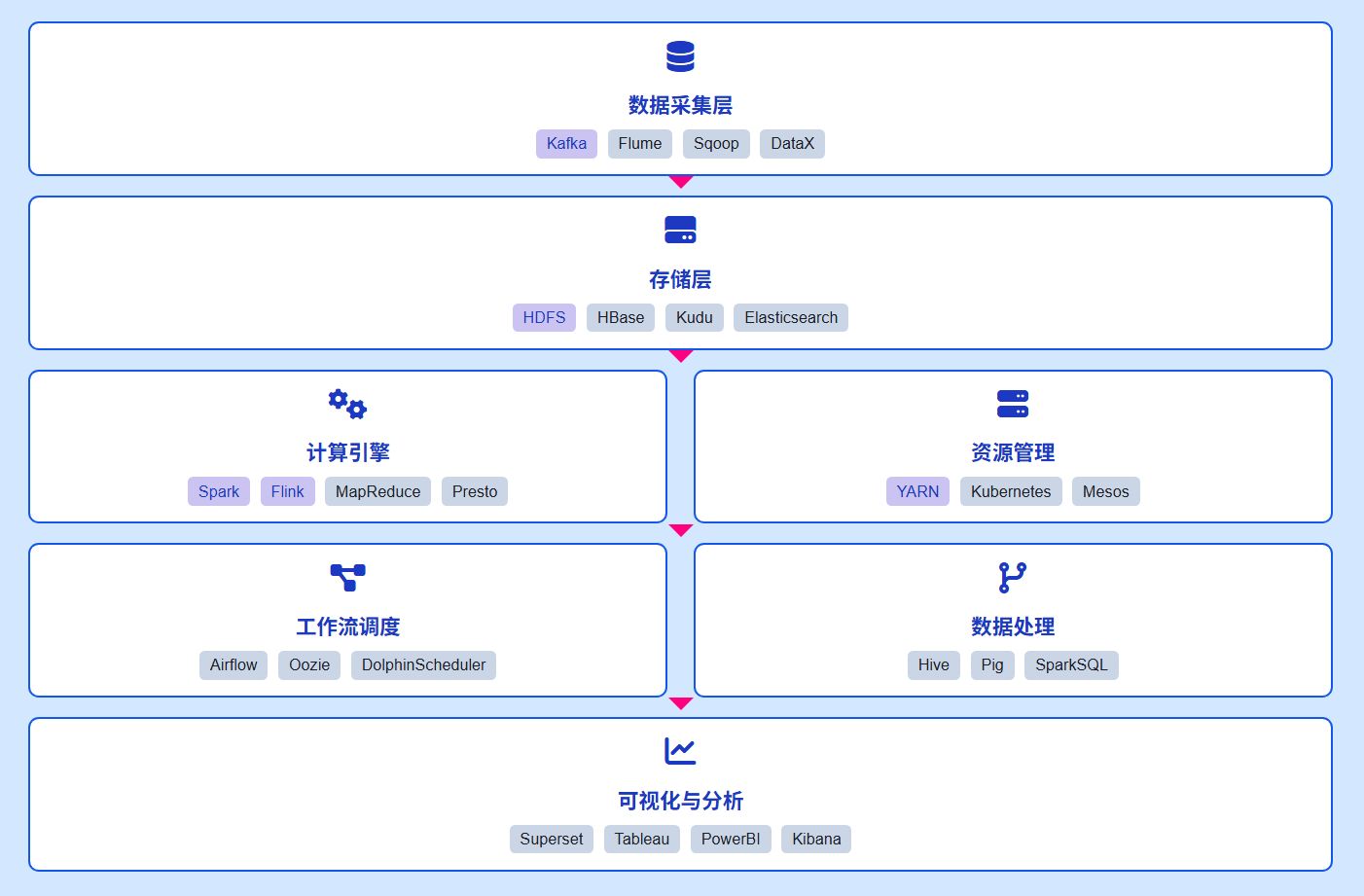
典型組件: 大數據平臺通常由 Hadoop / Spark / Flink 等生態系統組成。Hadoop 提供分布式文件系統(HDFS)和資源管理(YARN),Spark 提供內存計算框架,Flink 則專注于流處理。這些組件共同構成了一個完整的大數據處理生態系統。
適用場景:
- 數據湖?建設:存儲和管理各種原始數據,為后續的數據探索和分析提供基礎。
- 實時流處理:處理持續生成的數據流,如用戶點擊流、傳感器數據、金融交易等。
- 機器學習和人工智能:為訓練復雜的機器學習模型提供大規模數據處理能力。
- 非結構化數據分析:處理文本、圖像、視頻等非結構化數據,提取有價值的信息。
- 大規模 ETL 處理:對原始數據進行清洗、轉換和加載,為數據分析做準備。
什么是數據倉庫?
數據倉庫是一個面向主題的、集成的、相對穩定的、反映歷史變化的數據集合,用于支持企業的決策分析。它將來自不同業務系統的數據整合在一起,構建一個統一的數據視圖,為業務分析和決策提供支持。
核心目標:
- 結構化數據分析與決策支持
- 提供一致、可靠的企業數據視圖
- 支持復雜的 SQL 查詢和報表生成
- 確保數據質量和一致性
架構演進: 數據倉庫的架構已從傳統的集中式系統演變為現代分析型數據庫。傳統數據倉庫如 Oracle、SQL Server 主要依賴于垂直擴展,而現代數據倉庫如 StarRocks 、ClickHouse、Snowflake 則采用了分布式架構,支持更靈活的擴展和更快的查詢性能。
適用場景:
- BI 報表:為業務分析提供數據支持
- 交互式分析:支持用戶進行即席查詢
- 實時看板:展示關鍵業務指標的實時狀態
- 數據集市:為特定業務部門提供定制化的數據視圖
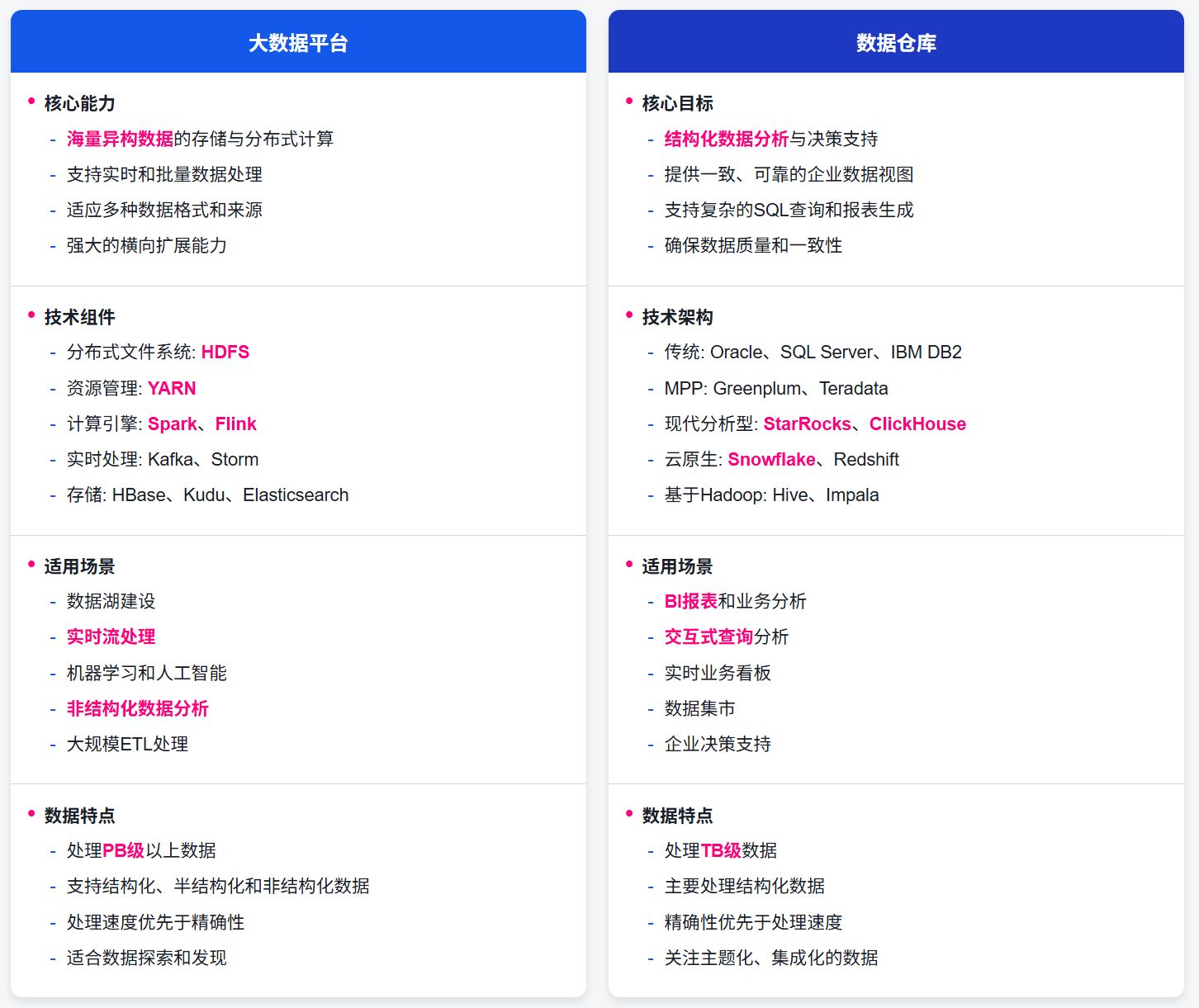
核心差異對比
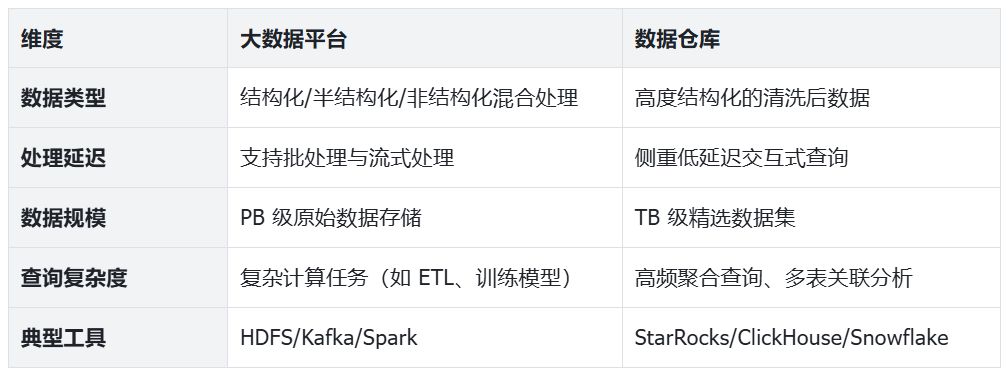
數據類型差異
大數據平臺: 大數據平臺的一個顯著特點是能夠處理多種類型的數據。它不僅可以處理結構化數據(如關系型數據庫中的表格數據),還能處理半結構化數據(如 JSON、XML)和非結構化數據(如文本、圖像、視頻)。這種靈活性使得大數據平臺能夠從各種來源收集和分析數據,包括社交媒體、傳感器、日志文件等。例如,一家電子商務公司可以使用大數據平臺來分析用戶在網站上的行為(結構化數據)、社交媒體上的評論(非結構化數據)以及移動應用的使用模式(半結構化數據),從而全面了解客戶需求和行為。
數據倉庫: 相比之下,數據倉庫主要處理高度結構化的數據。這些數據通常經過了嚴格的 ETL(提取、轉換、加載)過程,確保了數據的質量、一致性和可靠性。數據倉庫中的數據通常按照預定義的模式組織,便于進行復雜的查詢和分析。數據倉庫的這種特性使其特別適合于需要高度可靠和一致數據的業務智能和報告應用。例如,財務報表、銷售分析和客戶細分等任務都需要高質量、結構化的數據來確保結果的準確性。
處理延遲差異
大數據平臺: 大數據平臺支持多種處理模式,包括批處理和流式處理。批處理適用于處理大量歷史數據,通常以小時或天為單位運行。而流式處理則允許實時或近實時地處理數據,適用于需要即時響應的場景。例如,Apache Spark 可以用于批量處理大量歷史數據以生成趨勢報告,而 Apache Flink 則可以用于實時檢測欺詐交易或監控系統異常。
數據倉庫: 傳統數據倉庫主要側重于批處理,但現代數據倉庫已經發展出了支持低延遲交互式查詢的能力。這使得用戶可以快速獲取查詢結果,而不必等待批處理作業完成。例如,StarRocks 等現代分析型數據庫可以在秒級或亞秒級完成復雜的聚合查詢,使得業務分析師能夠快速探索數據并獲取洞察。
數據規模差異
大數據平臺: 大數據平臺設計用于處理 PB(拍字節)級甚至更大規模的數據。它們采用分布式存儲和計算架構,可以通過添加更多節點來水平擴展,從而應對不斷增長的數據量。例如,一家大型社交媒體平臺每天可能會生成數 PB 的用戶行為數據,這些數據需要被存儲和分析以優化用戶體驗和廣告投放。
數據倉庫: 數據倉庫通常處理 TB(太字節)級的精選數據集。這些數據經過了篩選和聚合,只保留了對業務決策有價值的信息。雖然現代數據倉庫也支持 PB 級數據,但它們通常不會存儲原始數據,而是存儲經過處理的、結構化的數據。
查詢復雜度差異
大數據平臺: 大數據平臺擅長執行復雜的計算任務,如 ETL 處理、機器學習模型訓練、圖分析等。這些任務通常涉及大量的數據轉換和計算,需要分布式計算框架的支持。例如,使用 Spark MLlib 訓練一個推薦系統模型,或者使用 MapReduce 進行大規模的日志分析,都是大數據平臺的典型應用。
數據倉庫: 數據倉庫專為高頻聚合查詢和多表關聯分析而優化。它們通常使用列式存儲、索引和物化視圖等技術來加速這類查詢。例如,一個銷售分析師可能需要快速查詢不同地區、不同產品類別的銷售趨勢,并與歷史數據進行比較。數據倉庫可以在幾秒鐘內完成這類復雜的多維分析查詢。
?
實踐中的互補關系
盡管大數據平臺和數據倉庫在設計理念和適用場景上存在差異,但在實際應用中,它們往往是互補的,而非相互排斥的。現代數據架構通常會同時包含這兩種技術,以充分發揮各自的優勢。
湖倉:混合架構成為現代技術選型的平衡
近年來, 湖倉一體化(Lakehouse)架構的興起標志著大數據平臺和數據倉庫的融合趨勢。數據湖倉結合了數據湖的靈活性和數據倉庫的結構化查詢能力,為企業提供了一個統一的數據平臺。
數據湖倉的特點:
- 支持結構化和非結構化數據
- 提供 ACID 事務支持
- 支持模式演化和數據版本控制
- 結合了批處理和流處理能力
- 提供高性能 SQL 查詢和分析
在實際應用中,常見的架構模式是“分層處理”:原始數據首先進入數據湖,然后經過處理和轉換后加載到數據倉庫中。這種模式充分利用了兩種技術的優勢。
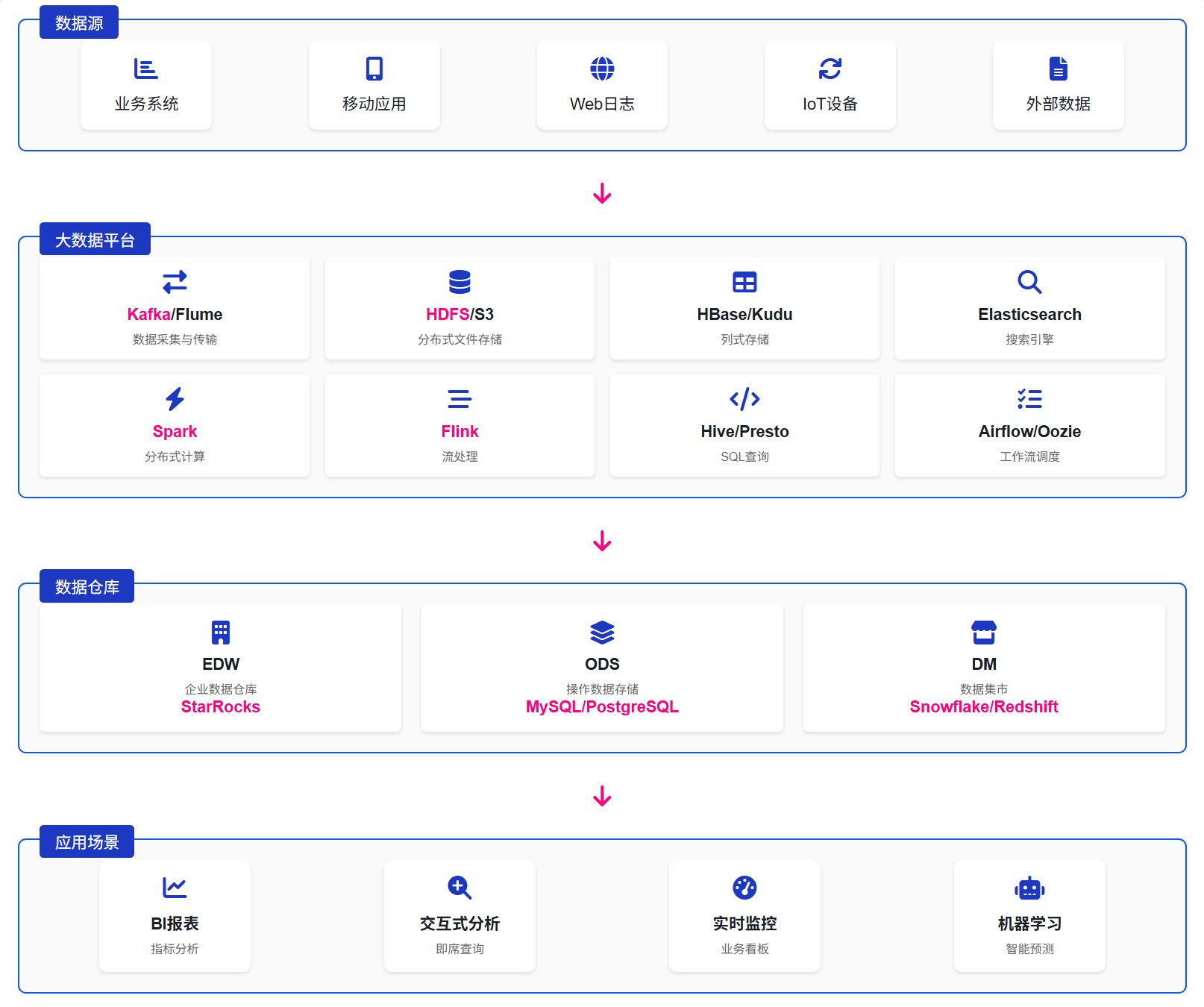
典型的數據流程:
- 數據采集:從各種來源收集原始數據
- 數據存儲:將原始數據存儲在數據湖中
- 數據處理:使用大數據處理工具對數據進行清洗、轉換和聚合
- 數據加載:將處理后的數據加載到數據倉庫中
- 數據分析:使用數據倉庫進行業務分析和報表生成
這種分層架構使企業能夠同時保留原始數據的完整性和提供高性能的分析查詢能力。
實踐案例:同程旅行——流式湖倉與用戶畫像優化
StarRocks 通過存算分離、聯邦查詢、物化視圖、主鍵模型四大核心技術,構建了“極速統一”的湖倉新范式。以同程旅行為例:
痛點
用戶畫像分析需處理復雜多表關聯查詢,原有 Spark+Kudu 方案存在查詢延遲高、資源消耗大等問題。
解決方案
- 構建流式湖倉:采用 Flink+Paimon+StarRocks 技術棧,ODS 層數據實時寫入 Paimon 湖表,StarRocks 作為查詢引擎加速 ADS 層分析。
- 物化視圖分層建模:通過 StarRocks 物化視圖自動匹配查詢模式,減少人工建模成本,TPCH 10G 查詢性能提升 3 倍。
收益
- 實時訂單分析響應速度提升至 TP99<10 秒,資源利用率優化 40%。
- 統一查詢引擎替代 ClickHouse/Greenplum,運維復雜度降低 70%
企業可以結合自身業務特點和發展規劃,選擇最適合的大數據平臺或數據倉庫解決方案,實現數據價值的最大化。
)



)
)

 節點/etc/kubernetes/manifests 不存在)

領域)






![洛谷 P9007 [入門賽 #9] 最澄澈的空與海 (Hard Version)](http://pic.xiahunao.cn/洛谷 P9007 [入門賽 #9] 最澄澈的空與海 (Hard Version))


