系列文章目錄
ArcGIS arcpy代碼工具——關于工具使用的軟件環境說明
ArcGIS arcpy代碼工具——批量對MXD文件的頁面布局設置修改
ArcGIS arcpy代碼工具——數據驅動工具批量導出MXD文檔并同步導出圖片
ArcGIS arcpy代碼工具——將要素屬性表字段及要素截圖插入word模板
ArcGIS arcpy代碼工具——定制屬性表字段輸出表格
ArcGIS arcpy代碼工具——批量柵格轉點文件導出屬性表
ArcGIS arcpy代碼工具——關于標識碼的那些事(查找最大標識碼、唯一性檢查、重排序、空值賦值)
ArcGIS arcpy代碼工具——批量要素裁剪柵格影像
文章目錄
- 系列文章目錄
- 功能說明
- 1 準備工作
- ==知識點:== 關于常見字段類型
- 2 代碼分段
- (1) 設置工作空間
- (2) 新建圖層
- 特別提醒:arcgis新建的圖層要求至少有一個字段,系統會自動生成 ID 字段。
- (3) 讀取屬性結構表
- (4) 解析屬性結構表
- (5) 創建字段
- 1. TEXT 文本型字段
- 2. SHORT 短整型、LONG 長整型字段
- 3. FLOAT 浮點型、DOUBLE 雙精度型字段
- 4. 其他類型字段
- (6) 重命名圖層
- (7) 刪除多余字段
- 3 完整代碼
- 4 后記
- 在arcgis軟件中運行代碼
功能說明
作為一個GISer,根據給定的圖層屬性結構表,創建shape圖層是經常遇到的工作。一個圖層里有各種字段類型、字段精度,小數位數要求,動輒甚至1個圖層有30個字段,如果在GIS軟件一個一個字段進行新建,那是非常繁瑣和容易出錯的。
本文旨在通過arcpy編程,讀取本地屬性結構表,自動創建shape圖層。
本代碼目標為:
- 1 準備屬性結構表
- 2 編寫代碼,讀取結構表
- 3 創建shape圖層
我使用的arcgis軟件版本為 10.8.2 版本。
溫馨提示:如果覺得文章不錯,請多多點贊添加關注,您的支持就是我的動力。
1 準備工作
首先第一步工作,就是準備txt格式(或者CSV格式,只要是逗號 分隔開就好)的屬性結構表,一般新建圖層的工作都是按照某個數據庫標準執行,能找到電子版標準文件摘取最好,沒有電子版就對照的標準錄入,可以先錄入到 Excel表格中,最后另存為CSV格式即可。
下面是我用于演示的屬性結構表:

我保存的是 CSV格式,用逗號分隔,平時編輯的時候使用Excel打開方便分列查看。屬性結構表中列出了常見的幾種字段類型。
知識點: 關于常見字段類型
在 ArcGIS 中,圖層的字段主要有以下幾種類型:
-
文本型(String):用于存儲字符數據,例如名稱、地址、描述等。它可以包含字母、數字、符號等各種字符,長度可根據需要設置。
-
數值型:整型(Integer):用于存儲整數,如人口數量、建筑物數量等。根據存儲范圍不同,又有不同的精度類型,如 16 位整數、32 位整數等。實踐中,如果標準中字段類型為INT(int)并且字段長度>4時,arcgis中均視為 LONG長整形。long 包含 short 的 關系。
-
- 關于 整形(int)字段,細分為 short 類型(短整型) 和 long 類型(長整型),區別如下:
-
- short 類型:一般采用 16 位(2 字節)來存儲數據。其取值范圍是 -32,768 到 32,767,即 最大精度 4 位數,因為> 32767的五位數就是long長整形,
精度 5應該為 long。它僅適用于存儲數值不大的整數。
- short 類型:一般采用 16 位(2 字節)來存儲數據。其取值范圍是 -32,768 到 32,767,即 最大精度 4 位數,因為> 32767的五位數就是long長整形,
-
- long 類型:通常用 32 位(4 字節)存儲數據。取值范圍為 -2,147,483,648 到 2,147,483,647,即 最大精度 10 位數。適用于需要存儲較大整數的場景。
-
- 新建字段時,可以根據要求的字段長度選擇 short 或者 long,長度超過 5 均為 long。不同類型涉及到存儲空間大小不同,如果對存儲空間要求不是那么在意都可以設為long(其實1條記錄多一倍,上萬條記錄也不少,具體視數據量而定)。
-
數值型:浮點型(Float):用于存儲 帶有小數部分 的數字,適用于表示測量值、比例等,如海拔高度、面積、溫度等。同樣有不同的精度類型,如單精度(32 位)和雙精度(64 位)。只有浮點型字段才能設置小數位數。
-
日期型(Date):用于存儲日期和時間信息,格式通常為年 / 月 / 日 時:分: 秒。可以進行日期的計算、排序和篩選等操作。
-
二進制型(Binary):用于存儲二進制數據,如圖像、文檔、音頻或視頻文件等。不過,直接在 ArcGIS 中處理二進制字段可能較為復雜,通常需要結合其他工具或編程語言來操作。
-
幾何型(Geometry):用于存儲地理要素的幾何信息,如點、線、面等。這是 ArcGIS 中非常重要的一種字段類型,它定義了要素在地圖上的位置和形狀。
-
OID 型(Object ID):是一種特殊的整型字段,用于唯一標識圖層中的每個要素。它在數據庫中充當主鍵,不能被編輯,由系統自動生成和維護。
-
除 “OID” 和 “Shape” 字段之外,“要素類”和“表”還必須至少具有一個字段,默認會自動生成一個 名稱 為 ID 的字段。一般情況下新建了其他字段后,ID字段就多余了,可刪除之,否則提示多余字段。
2 代碼分段
下面開始編寫代碼,把步驟分解一步一步來。
思路:設置工作空間——新建圖層——讀取屬性結構表——解析結構表(字段類型、字段長度等)——根據不同字段類型創建字段
(1) 設置工作空間
工作空間,也就是 圖層生成的文件夾,給代碼定位在這里工作。
如果新建的是 shape圖層文件,則工作空間設置為文件夾;
//設置工作空間 文件夾
arcpy.env.workspace = r"D:\mulu\tc"
如果新建的是地理數據庫中的圖層,則工作空間設置為mdb或者gdb的地理數據庫。
//設置工作空間 地理數據庫
arcpy.env.workspace = r"D:\mulu\tc\test.mdb"
注意: 這兩種方式,新建圖層的字段,結果是有區別的。后面細說。
(2) 新建圖層
shape的要素類型主要有 點、線、面型,首先定義類型,再定義坐標系統。
我準備新建的圖層為XZQ,是面型。投影坐標系 CGCS2000 40 度分帶。
// 定義新Shapefile的名稱和要素類型
output_shapefile = "XZQ" + ".shp" # 可以是 帶后綴名的shapefile 也可以是不帶后綴名的數據庫圖層
geometry_type = "POLYGON" # 面型
# geometry_type = "POLYLINE" # 線型
# geometry_type = "POINT" # 點型// 創建新的Shapefile
arcpy.CreateFeatureclass_management(arcpy.env.workspace, output_shapefile, geometry_type)// 設置投影坐標系統 為 CGCS2000 40 度分帶
cgcs2000_40 = arcpy.SpatialReference(4528) # CGCS2000 / 高斯投影 3-degree Gauss-Kruger zone 40
arcpy.DefineProjection_management(output_shapefile, cgcs2000_40)坐標系統分為地理坐標系和投影坐標系, 注意標準的要求。
-
常用的地理坐標系和WKID:
地理坐標 4214 GCS_Beijing_1954;
地理坐標 4326 GCS_WGS_1984;
地理坐標 4490 GCS_China_Geodetic_Coordinate_System_2000;
地理坐標 4555 GCS_New_Beijing;
地理坐標 4610 GCS_Xian_1980. -
常用的投影坐標系和WKID:
投影坐標 2364 Xian_1980 3度分帶 40度帶;
投影坐標 4528 CGCS2000 3度分帶 40度帶;
投影坐標 4529 CGCS2000 3度分帶 41度帶。
特別提醒:arcgis新建的圖層要求至少有一個字段,系統會自動生成 ID 字段。

(3) 讀取屬性結構表
讀取屬性結構表,先判定一下文件是否存在。首行為字段標題行,需要跳過。
// 讀取CSV文件中的字段信息
csv_file = r"D:\MULU\tc\aa.csv"
if not os.path.exists(csv_file):print("文件不存在: {}.".format(csv_file))
else:with open(csv_file, 'r') as SXB:reader = csv.reader(SXB)next(reader) # 跳過標題行
(4) 解析屬性結構表
在解析過程中,首先判定的應該是字段類型是否符合arcgis的要求。
給定一個符合要求的字段類型集合進行判定。
// 支持的字段類型
valid_field_types = ["TEXT", "FLOAT", "DOUBLE", "SHORT", "LONG", "DATE", "BLOB", "RASTER", "GUID"]
我編制的屬性結構表,結構為:字段別名、字段名稱、字段類型、字段長度、小數位數。
按照這個順序解析字段,存儲值。
// 解析屬性表,按 列 讀取for row in reader:fieldalias = row[0] # 字段別名fieldname = row[1] # 字段名稱fieldtype = row[2].upper() # 字段類型,強制轉換為大寫fieldprecision = row[3] # 字段長度,字段精度
從支持的字段類型集合中可以看到,并沒有 int 整形,故如果屬性結構表中有 int需要按照字段精度修改為 SHORT 或 LONG。
實踐中,如果 int 的精度 ≤4,arcgis生成的是 SHORT 短整型字段。

實踐中,因為大于 32767的五位數就是LONG長整形,如果字段精度是 ≥ 5 則會生成 LONG 長整形字段。LONG 包含 SHORT 的 關系。

// 根據精度判定 int ,修改為 short 或者 long# 如果字段類型為 'INT',替換為 'LONG'或者 shortif fieldtype in ["INT", "INTEGER"]:if fieldprecision and fieldprecision.isdigit() and int(fieldprecision) <= 4:fieldtype = "SHORT"else:fieldtype = "LONG"
關于小數位數,只有 FLOAT 浮點型, DOUBLE 雙精度型,才有小數位數,故 fieldscale 并不是每個字段類型都有值。
// 小數位數fieldscale = int(row[4]) if len(row) > 4 and row[4].isdigit() else None # 小數位數
最后,判定一下,字段類型 是否有效,如果存在無效字段,則跳過該字段,繼續下一個字段。
//檢查字段類型是否有效if fieldtype not in valid_field_types:print("字段類型無效: {},跳過字段: {}".format(fieldtype, fieldname))continue
(5) 創建字段
在 ArcGIS 中,創建 字段 時,可以通過 arcpy.AddField_management 方法的,各類型的字段創建參數有所差異。
下面分字段類型看一下代碼:正常情況需要對 字段長度等驗證為非空,但是在編制屬性結構表階段就保證了數據的完整性,故代碼中不再驗證。
1. TEXT 文本型字段
要求字段長度 field_length 為 >0的數字。
// 添加字段到新的Shapefileif fieldtype.upper() == "TEXT":# 對于文本型字段,設置 field_lengtharcpy.AddField_management(output_shapefile,fieldname,fieldtype,field_length=int(fieldprecision),field_alias=fieldalias)
2. SHORT 短整型、LONG 長整型字段
要求字段精度(等效于字段長度) field_precision 為 >0的數字。
elif fieldtype in ["LONG", "SHORT"]:# 對于整型字段,設置 field_precisionarcpy.AddField_management(output_shapefile,fieldname,fieldtype,field_precision=int(fieldprecision),field_alias=fieldalias)
3. FLOAT 浮點型、DOUBLE 雙精度型字段
要求字段精度(等效于字段長度) field_precision 為 >0的數字。
增加有 小數位數 field_scale 屬性為 ≥ 0 的數字。
elif fieldtype in ["FLOAT", "DOUBLE"]:# 對于浮點類型字段,設置 field_precision 和 field_scalearcpy.AddField_management(output_shapefile,fieldname,fieldtype,field_precision=int(fieldprecision),field_scale=fieldscale,field_alias=fieldalias)
4. 其他類型字段
其他類型字段,如 DATE ,無需字段精度 、小數位數 屬性,arcgis固定的字段格式。
else:# 對于其他類型的字段,不傳遞 field_precision 和 field_scalearcpy.AddField_management(output_shapefile,fieldname,fieldtype,field_alias=fieldalias)
特別說明:
- 關于字段別名 field_alias,在 shape層中 創建字段時,即使設置了 字段別名屬性,如 field_alias =“行政區” ,但是在創建字段完成后,字段別名的屬性值會丟失,字段別名 等于默認值 字段名稱 XZQ。
- 但是 ,在 地理數據庫 中新建層中創建字段,如 field_alias =“行政區” ,字段別名會 成功保留屬性值 “行政區”。
- 如果將 地理數據庫 中的 帶 字段別名值的 圖層,導出到 shape層文件,你會發現原來的字段別名值 丟失了,又變成了 默認值 字段名稱 XZQ。
- 關于浮點型 雙精度 的 字段精度 和小數位數,只有在 shape層 中才有意義,在 地理數據庫 中無意義,但存儲的值仍符合字段類型要求。
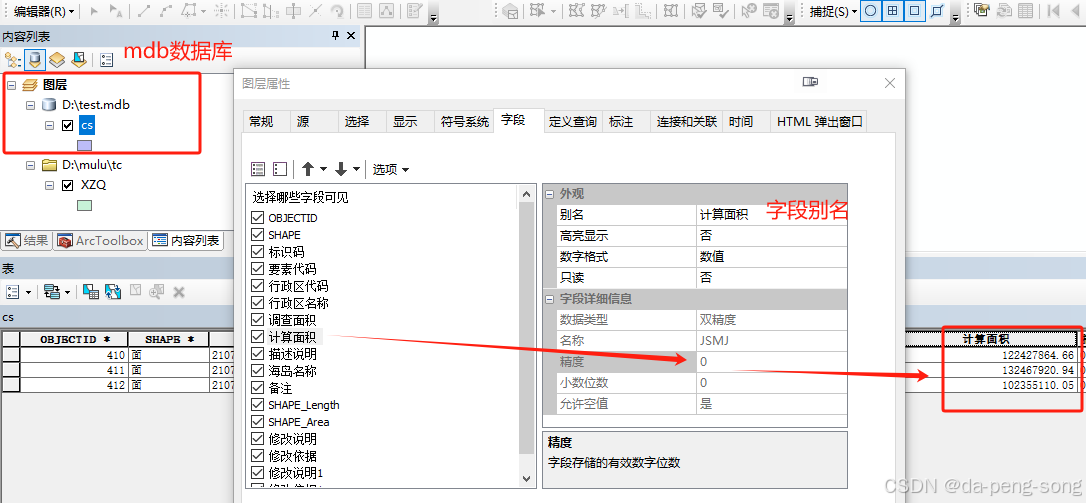
- 如果 你 將 設置好字段屬性的 shape層文件,導入到 地理數據庫中,你會發現,浮點型 雙精度的精度和 小數位數同樣失效了。跟上圖一樣 變為 0,但不影響該字段的數據存儲。這個時候,即使你再 導出為 shape圖層文件,字段精度和 小數位數依然無法恢復了。
- 把 shape層 導入 mdb等地理數據庫中進行編輯和管理,再導出為shape層文件作為最終成果提交的格式,這種操作非常 常見,但是再通過質檢軟件檢查的時候,容易提示 字段類型不符。修正很簡單,在 shape層上重新創建標準字段 把原來的值賦值回來就可以了。
(6) 重命名圖層
各種標準或者某個成果提交要求中,對shape層的命名規則 ,如 “6位行政區代碼”數字+ “XZQ”諸如此類,在arcgis的圖層命名規則中不允許數字或特殊符號作為圖層名稱首字符。
在創建新圖層的時候,不能夠一步到位的直接命名圖層,需要在最后階段對shape層進行重命名 ,給圖層名稱增加 前綴。
// 重命名圖層,在名稱前綴增加“(111111)”
Add_prefix = "(111111)"
if Add_prefix:new_shapefile_name = str(Add_prefix) + output_shapefilearcpy.Rename_management(output_shapefile, new_shapefile_name)
else:new_shapefile_name = output_shapefile
如果沒有重命名 這一步,把 Add_prefix 賦值為空即可。
Add_prefix = ""
......
(7) 刪除多余字段
前面也說了,在新建shape圖層文件的時候,自動添加 了一個字段 ID,因為圖層已經添加了其他字段,這個 ID字段已經沒有用處了。需要刪除。
// 刪除 new_shapefile_name 圖層中的 id 字段
arcpy.DeleteField_management(new_shapefile_name, "id")
3 完整代碼
下面列出完整代碼,代碼經測試成功運行,實現按照屬性結構表創建圖層的功能。
# coding=utf-8
import arcpy
import csv
import os# 在 ArcGIS 中,創建 Shapefile 時,可以通過 arcpy.AddField_management 方法的
# 字段別名 ,只能在 地類數據庫中設置,如果是新建shape層會失敗
# field_precision 和 field_scale 參數設置雙精度字段的位數和小數位數。# 設置工作空間
arcpy.env.workspace = r"D:\mulu\tc"# 定義新Shapefile的名稱和要素類型
output_shapefile = "XZQ" + ".shp" # 可以是 帶后綴名的shapefile 也可以是不帶后綴名的數據庫圖層
geometry_type = "POLYGON"
# geometry_type = "POLYLINE"
# geometry_type = "POINT"# 創建新的Shapefile
arcpy.CreateFeatureclass_management(arcpy.env.workspace, output_shapefile, geometry_type)# 設置坐標系統為 CGCS2000 40 度分帶
# cgcs2000_40 = arcpy.SpatialReference(4490) # CGCS2000 / 大地坐標系 2000
cgcs2000_40 = arcpy.SpatialReference(4528) # CGCS2000 / 高斯投影 3-degree Gauss-Kruger zone 40
arcpy.DefineProjection_management(output_shapefile, cgcs2000_40)# 支持的字段類型
valid_field_types = ["TEXT", "FLOAT", "DOUBLE", "SHORT", "LONG", "DATE", "BLOB", "RASTER", "GUID"]# 讀取CSV文件中的字段信息
csv_file = r"D:\MULU\tc\aa.csv"
if not os.path.exists(csv_file):print("文件不存在: {}.".format(csv_file))
else:with open(csv_file, 'r') as SXB:reader = csv.reader(SXB)next(reader) # 跳過標題行for row in reader:fieldalias = row[0] # 字段別名fieldname = row[1] # 字段名稱fieldtype = row[2].upper() # 字段類型,強制轉換為大寫fieldprecision = row[3] # 字段長度,字段精度# 如果字段類型為 'INT',替換為 'LONG'或者 shortif fieldtype in ["INT", "INTEGER"]:if fieldprecision and fieldprecision.isdigit() and int(fieldprecision) <= 4:fieldtype = "SHORT"else:fieldtype = "LONG"fieldscale = int(row[4]) if len(row) > 4 and row[4].isdigit() else None # 小數位數# 檢查字段類型是否有效if fieldtype not in valid_field_types:print("字段類型無效: {},跳過字段: {}".format(fieldtype, fieldname))continue# 添加字段到新的Shapefileif fieldtype.upper() == "TEXT":# 對于文本型字段,設置 field_lengtharcpy.AddField_management(output_shapefile,fieldname,fieldtype,field_length=int(fieldprecision),field_alias=fieldalias)elif fieldtype in ["LONG", "SHORT"]:# 對于整型字段,設置 field_precisionarcpy.AddField_management(output_shapefile,fieldname,fieldtype,field_precision=int(fieldprecision),field_alias=fieldalias)elif fieldtype in ["FLOAT", "DOUBLE"]:# 對于浮點類型字段,設置 field_precision 和 field_scalearcpy.AddField_management(output_shapefile,fieldname,fieldtype,field_precision=int(fieldprecision),field_scale=fieldscale,field_alias=fieldalias)else:# 對于其他類型的字段,不傳遞 field_precision 和 field_scalearcpy.AddField_management(output_shapefile,fieldname,fieldtype,field_alias=fieldalias)print("新圖層已創建并添加字段。")# 重命名圖層,在名稱前綴增加“(111111)”
Add_prefix = ""
if Add_prefix:new_shapefile_name = str(Add_prefix) + output_shapefilearcpy.Rename_management(output_shapefile, new_shapefile_name)
else:new_shapefile_name = output_shapefile# 刪除 new_shapefile_name 圖層中的 id 字段
arcpy.DeleteField_management(new_shapefile_name, "id")看一下運行的效果如何,
4 后記
日常工作中,創建圖層的工作非常多,使用代碼編程創建,不僅效率高,而且錯誤更少。推薦朋友們使用.
有朋友就為難了,電腦沒有 python環境和編輯軟件怎么辦?這么好的功能我也想用。沒問題,滿足。
如果你的電腦安裝了 arcgis軟件 ,那么你 的電腦中同時也安裝了 python2.7版環境,arcgis軟件中有個 Python窗口,可以運行python代碼。
在arcgis軟件中運行代碼
操作方法如下:
- 新建1個空白的txt文本文檔;
- 把完整代碼全選,復制粘貼到 空白的 txt文本文檔中;
- 編輯代碼,把所有的 注釋內容 #… 都刪除干凈,反復檢查沒有遺漏 # 為止;
- 首行 “# coding=utf-8“ 也刪除不要。
- 把代碼中的參數行 ,修改為你自己的 數據,注意 符號均為英文狀態的符號
-
- 儲存目錄 arcpy.env.workspace
-
- 圖層名稱 output_shapefile
-
- 圖層類型 geometry_type
-
- 坐標系代碼 cgcs2000_40
-
- 屬性代碼表 csv_file
-
- 重命名前綴 Add_prefix
- 再次檢查代碼,確認上述參數都已經修改為自己的值。
- 打開arcgis軟件的 Python窗口,全選復制代碼粘貼到 Python窗口中
- 檢查代碼狀態,每一樣前面都有 三個點 。。。,顏色均為黑色狀態,不能有淺灰色的代碼行
- 回車鍵 Enter 2次,開始運行
- 觀察運行狀態,注意查看Python窗口中的提示信息,是否有錯誤提示
- 運行結束,檢查圖層屬性。
下面看一下完整的運行過程。祝你成功!SYQ
我還編寫了arcgis的工具插件,采用窗口化來創建圖層,更加的簡便,有需要的可以去下載,插件地址如下:根據屬性結構表新建shape圖層

如果覺得文章不錯,請多多點贊添加關注,您的支持就是我的動力。

Gin學習筆記(三)數據解析和綁定:結構體分析,包括JSON解析、form解析、URL解析,區分綁定的Bind方法)
學習筆記(四)--入門基本操作)


![[Vue]props解耦傳參](http://pic.xiahunao.cn/[Vue]props解耦傳參)




)








