加法 ADD
減法 SUB
取負 NEG
比較 CMP
乘法 MUL
移位 LSL、LSR、ASL、ASR、ROL、ROR
加法和減法
絕大多數微處理器都實現了帶進位的加法指令,能夠將兩個操作數和條件碼寄存器中的進位位加到一起。這條指令會使字長大于計算機固有字長的鏈接運算更加方便。
說明了如何使用帶進位的加法指令實現鏈式運算。如:指令ADD r2,r1,r0將源寄存器r0和r1的內容相加,將結果保存到r2中,該操作產生的進位被保存到進位位中。
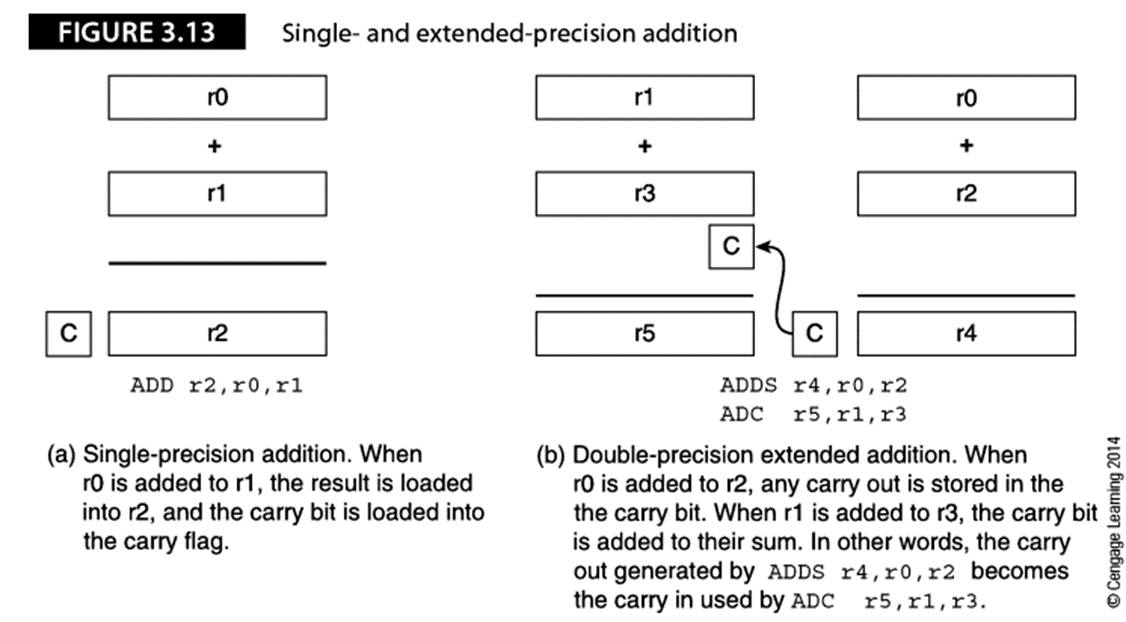
假設使用32位體系結構的ARM處理器,要處理64位整數并要完成64位加法。上圖(b)說明了64位算術運算中如何使用32位寄存器來傳播進位。兩個64位數已經保存到寄存器r1、r0和r3、r2中。
指令ADDS r4,r0,r2,完成r0+r2并將結果保存到r4中,進位輸出保存到CCR中進位位中。
指令ADC r5,r1,r3將高位的兩個數字相加時,進位位也被加到r1與r3的和中。助記符ADC表示帶進位的加法。
ARM還提供了SBC或帶借位的減法指令來支持擴展精度的減法運算。
逆減法指令RSB:減法指令SUB r1,r2,r3被定義為[r1]<-[r2] – [r3],逆減法指令RSB r1,r2,r3被定義為[r1]<-[r3]-[r2]
取負
取負就是用零減去一個數字。如r0的負數就是0 - [r0]。ARM沒有這樣的取負指令。可以使用逆減法來實現,因為RSB r1,r1,#0等價于NEG r1
比較
通過執行指令CMP Q,P比較P和Q時,將發生顯示比較,這條指令會計算Q-P但
不會保存結果。比較操作會修改CCR的內容,后面的指令會測試CCR的值以決定
按順序繼續執行還是進行跳轉。
考慮下面的例子:
CMP r1,r2 ; r1=r2?
BEQ DoThis ; 如果相等則跳轉到DoThis
ADD r1,r1,#1 ; 否則r1 = r1 + 1
B Next ; 不要忘記跳過THEN部分代碼
.
DoThis SUB r1,r1,#1 ; r1 = r1 -1
Next … ; 兩個分叉匯聚于此
乘法
乘法運算將兩個m位的操作數相乘,得到一個2m位 的積。結果的位長加倍帶
來一個問題。計算機要么自動將結果截斷,32位乘以32位得到一個32位結果。
要么設計一個四操作數指令:兩個源操作數,兩個目的操作數(分別保存結果
的高半部分和低半部分)。而且,二進制補碼加減法運算能得到正確結果,但
乘除法卻不一定,即對有符號和無符號數不能使用同樣的乘法操作。
有些微處理器提供了有符號和無符號乘法操作,以及結果為32位的16位乘法、
結果為64位的32位乘法。
ARM乘法指令MUL Rd,Rm,Rs計算保存在32位寄存器Rm和Rs中的兩個32位有符號數的積,將結果保存在32位寄存器Rd中,僅存放64位積的低32位。當然,應保證結果不超出范圍。如,計算121乘96:
MOV r0,#121 ; 將121加載到r0中
MOV r1,#96 ; 將96加載到r1中
MUL r2,r0,r1 ; r2 = r0 x r1
目的寄存器Rd和源寄存器Rm不用使用相同的寄存器,因為ARM在乘法計算過程中將Rd當作臨時寄存器使用,這是Arm的一個特點。
除了32位乘法指令MUL外,ARM還包括:
UMULL 無符號長整型乘法(Rm x Rd乘積為64位,存放在兩個寄存器中)
UMLAL 無符號長整型乘累加
SMULL 有符號長整型乘法
SMLAL 有符號長整型乘累加
MLA
ARM乘累加指令MLA,先進行乘法,再將乘積與另一個數相加。
MLA指令采用四操作數形式:MLA Rd,Rm,Rs,Rn。RTL定義為[Rd]<-[Rm]x[Rs]+[Rn],32位數與32位數的乘積被截斷為低32位結果。
內積運算
ARM乘累加操作使用一條指令完成乘法和加法運算,支持內積計算。
假設向量a有n個元素a1,a2,…,an,向量b有n個元素b1,b2,…,bn,則a與b的內積就是標量s=a x b = a1 x b1 + a2 x b2 +…+ an x bn
下面代碼段展示MAL指令計算兩個n元素向量Vector1和Vector2的內積:
n EQU 4
MOV r4,#n ; r4為循環計數器
MOV r3,#0 ; 將內積清零
ADR r5,Vector1 ; r5指向Vector1
ADR r6,Vector2 ; r6指向Vector2
Loop LDR r0,[r5],#4 ; REPEAT 讀向量Vector1的一個元素并更新指針LDR r1,[r6],#4 ; 讀取向量Vector2的相應元素MLA r3,r0,r1,r3 ; 乘累加操作r3= r3 + r0 x r1SUBS r4,r4,#1 ; 循環計數器遞減(更新CCR)BNE Loop ; UNTIL所有計算完畢
位操作
邏輯操作也叫位操作,這些操作被應用到寄存器的每一位。微處理器一般只支持AND(與)、OR(或)、NOT(非)和EOR或(異或)操作。
下面說明了對r1=110010102和 r0=000011112進行的邏輯操作:

邏輯運算的典型應用就是數據合并,即把多個變量合并到一個寄存器或存儲單元中。
假設寄存器r0包含8位數bbbbbbxx,寄存器r1包含8位數bbbyyybb,寄存器r2包、
含8位數zzzbbbbb,x、y、z代表需要的位,b是不需要的位。希望把這些位合并
得到最后結果zzzyyyxx。通過以下代碼可以到達目的:
AND r0,r0,#2_00000011 ; 保留2位xx,其他屏蔽
AND r1,r1,#2_00011100 ; 保留3位yyy,其他屏蔽
AND r2,r2,#2_11100000 ; 保留3位zzz,其他屏蔽
OR r0,r0,r1 ; 合并r1和r0得到000yyyxx
OR r0,r0,r2 ; 合并r2和r0得到zzzyyyxx
假設有一個8位二進制串abcdefgh,需要b、d兩位清零,a、e、f三位置1,h位
取反。可以通過AND、OR和EOR操作完成:
AND r0,r0,#2_10101111 ; 清除b和d位,得到a0c0efgh
OR r0,r0,#2_10001100 ; a、e、f位置1,得到10c011gh
EOR r0,r0,#2_00000001 ; b位取反,得到10c011gh(h取反)
位清楚指令BIC
ARM提供了位清除指令BIC,將第一個操作數與第二個操作數的反碼進行與操作。如,IBC r0,r1,r2實現了:
如果BIC第二個操作數中某位為0,則將第一個操作數中對應的位復制到目的操作數中,如果第二個操作數中某位為1,則把目的操作數中對應的位清零。
如果r1=10101010且r2=00001111,則BIC r0,r1,r2的結果為:

可用BIC指令對寄存器的最低位字節清零。指令BIC r0,r1,#0xFF把寄存器r1中的32位復制到寄存器r0中,然后把r0中的第0~7位清零。
移位操作
移位操作就是把字中的位向左或向右移動一個或多個位置。當移位一個位串時,串的一端的位會被丟棄,并在另外一端補充新的位,如:

這里的移位是邏輯移位
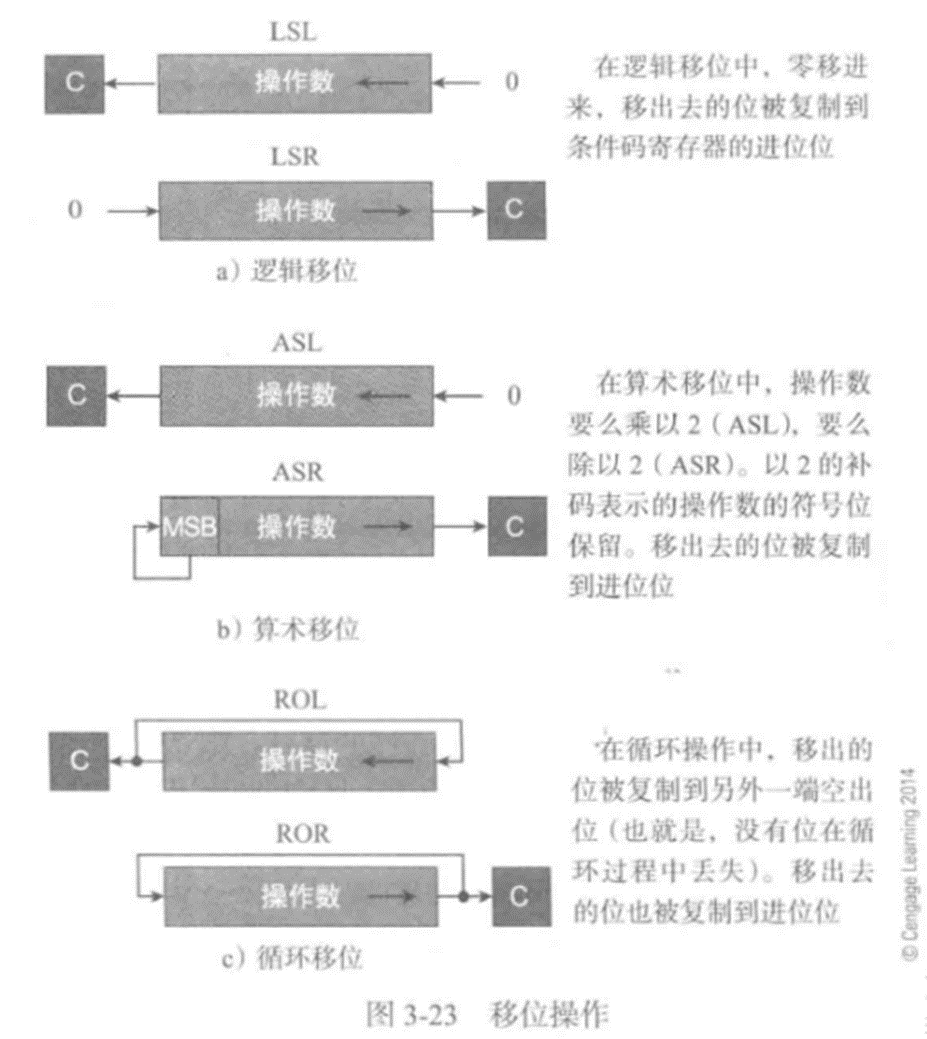
所有微處理器都支持邏輯移位操作。有些支持向左或向右移動一位,其他的支持多位移位。如
果移位的位數在指令中被編碼為常量,這種移位叫作靜態移位,在運行時不能改變移位位數,
如果移位的位數由寄存器的值指定,則叫作動態移位,可以在程序運行時修改移位的位數。
移位的典型應用是從一個字中提取特定的位。假設有一個8位的串bxxxxbbb,x表示要提取的位,
b表示無需關心的位。下面代碼提取所需要的位且將其右對齊:
LSR r0,r0,#3 ; r0右移3位,得到000bxxxx
AND r0,r0,#2_00001111 ; 屏蔽不需要的位,得到0000xxxx
ARM沒有獨立的移位指令,移位是作為其他指令的一部分來實現的。ARM允許對寄存器-寄存
器型指令的第二個操作數進行移位。如,指令ADD r0,r1,r2,LSL #4,先寄存器r2邏輯左移4位,
然后將移位結果與寄存器r1相加。
算術移位
算術移位將操作數視作一個有符號二進制補碼。可以用來完成除以2(右移一
位)或乘以2(左移一位)等運算。算術移位的目的是在進行移
位運算時保留二進制補碼數的符號,移位運算代表乘以或除以2的冪。
算術左移與邏輯左移是等價的。算術右移會保留符號位,每次右移后符號位會
自動復制。
例如,如果將8位數11001110算術左移一位,得到10011100(最低位補0),而
算術右移一位得到11100111(符號位被復制)。一個整數算術左移m位相當于
乘以2m,而算術右移m位相當于除以2m。
循環移位
循環移位操作把寄存器的內容看作一個LSB(最低位)和MSB(最高位)相鄰的環。如上圖
(c),進行移位操作時,從一端移出的位會從另一端進來。與邏輯移位和算術移位相比,循
環移位不會丟失位。
例如,如果將8位數11001110循環左移一位,得到10011101,移出的位也被復制到進位寄存器。
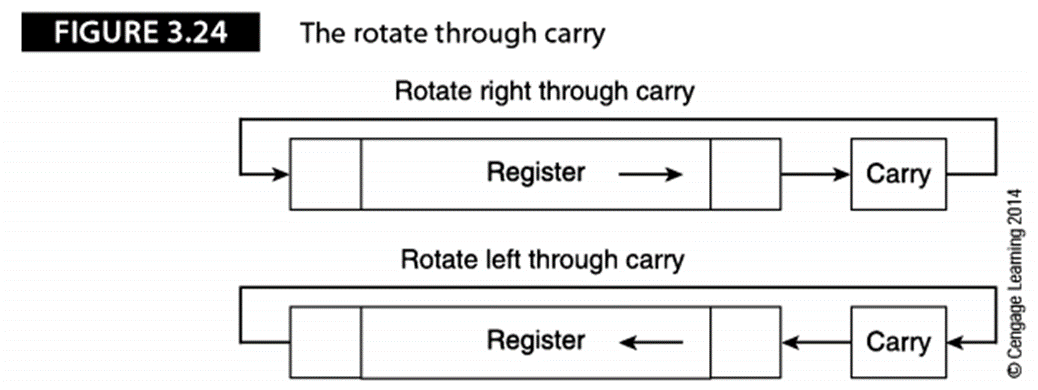
有些處理器實現了另一種循環操作,叫作擴展循環移位或帶進位的循環移位。這種操作與循環
移位一樣,只不過循環時包含了進位位。
如下圖,移出的位被復制到進位位,原來的進位位變成了被移出的位:
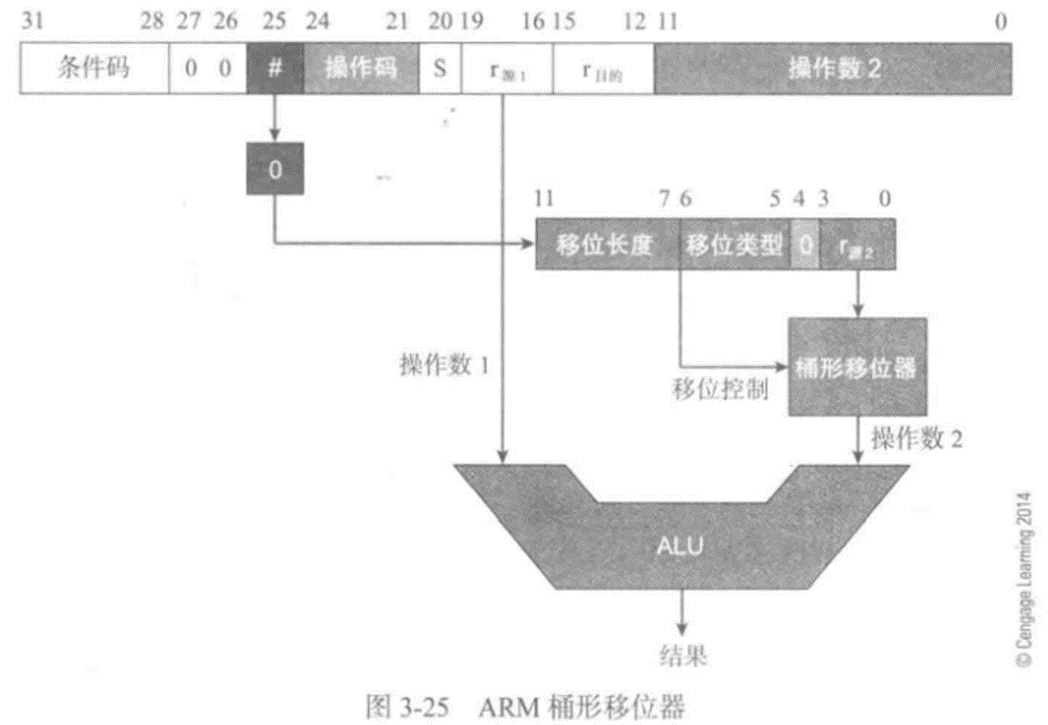
ARM移位操作的實現
ARM沒有獨立的移位操作。實際上,移位操作與其他數據處理操作組合到一起,可以在使用第
二個操作數之前將其移位。
下圖描述了ARM的移位機制,在第二個源操作數的數據通路上增加了一個桶形移位器:
考慮第二個源操作數被移位的ADD操作的例子:
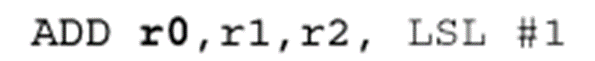
將r2與r1相加之前,先將r2的內容邏輯左移一位,因此該操作等價于
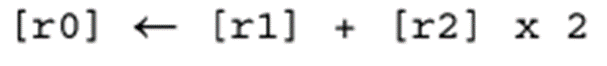
如果僅希望對寄存器進行移位操作,而不需要進行其他數據處理,可以使用下面指令:
MOV r3,r3, LSL #1
由于可以完成動態移位,也可使用指令MOV r4,r3,LSL r1,以r1為移位位數對r3
進行移位,結果送入r4。
假設r0中的數為0.00000010101111….,希望規格化為0.101…,如果用寄存器r1
表示指數,則執行MOV r0,r0,LSL r1可以在一個周期內完成規格化操作。
除了僅允許移動一位RRX指令外,ARM支持靜態和動態移位。靜態移位在編程
時就已經確定了移位的位數,而動態移位允許在執行代碼時改變移位位數。如,
指令MOV r3,r3,LSL r2以r2的值為移位位數對r3進行邏輯左移。r2的值被看作模
32的數,因為移位不能超過32次。
ARM僅實現了以下5種移位操作
LSL 邏輯左移
LSR 邏輯右移
ASR 算術右移
ROR 循環右移
RRX 帶進位的循環右移(移位一次)
盡管沒有循環左移操作,可以借助循環右移實現。
下面說了4位二進制數的循環左移和循環右移。經過4次循環移位,操作數沒有
變化。循環左移和循環右移是對稱的。對于32位數,循環左移n位等價于循環
右移32-n位。
循環右移 循環左移
1101 開始 1101 開始
1110 循環右移1次 1011 循環左移1次
0111 循環右移2次 0111 循環左移2次
1011 循環右移3次 1110 循環左移3次
1101 循環右移4次 1101 循環左移4次
ARM沒有實現帶進位的循環左移操作,通過指令ADCS r0,r0,r0可以實現帶進位
的循環左移,因為它把r0與r0以及進位位一起相加,并將結果保存在r0中(即
結果為2 x [r0] + C),左移等價于乘以2,把進位位移動到最低位等價于加上進
位位,得到2 x [r0] + C,指令后添加S會強制更新CCR,確保進位輸出被加載到C
位。因此ADCS r0,r0,r0與RXL r0等價。
指令編碼——洞察ARM體系結構
簡單的看一下ARM的移位操作是如何編碼的,下圖給出了ARM數據處理指令的二進制編碼,遵循RISC體系結構 的一般模式:包括一個操作數、兩個寄存器操作數以及第三個多目的操作數。寄存器操作數r源和r目的定義了第一個源操作數和目的寄存器。0~11位是第二個源操作數的編碼:
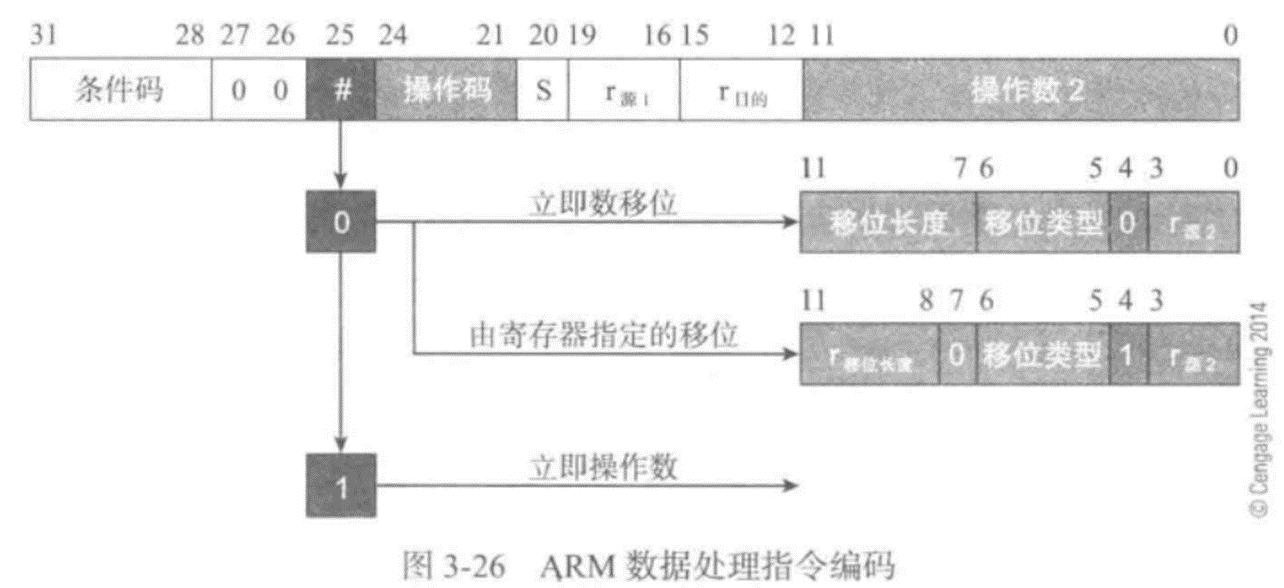














)
)
)


