初次嘗試訓練CIFAR-100:【圖像分類】CIFAR-100圖像分類任務-CSDN博客
1.訓練模型(MyModel.py)
import torch
import torch.nn as nnclass BasicRes(nn.Module):def __init__(self, in_cha, out_cha, stride=1, res=True):super(BasicRes, self).__init__()self.layer01 = nn.Sequential(nn.Conv2d(in_channels=in_cha, out_channels=out_cha, kernel_size=3, stride=stride, padding=1),nn.BatchNorm2d(out_cha),nn.ReLU(),)self.layer02 = nn.Sequential(nn.Conv2d(in_channels=out_cha, out_channels=out_cha, kernel_size=3, stride=1, padding=1),nn.BatchNorm2d(out_cha),)if res:self.res = resif in_cha != out_cha or stride != 1: # 若x和f(x)維度不匹配:self.shortcut = nn.Sequential(nn.Conv2d(in_channels=in_cha, out_channels=out_cha, kernel_size=1, stride=stride),nn.BatchNorm2d(out_cha),)else:self.shortcut = nn.Sequential()def forward(self, x):residual = xx = self.layer01(x)x = self.layer02(x)if self.res:x += self.shortcut(residual)return x# 2.訓練模型
class cifar100(nn.Module):def __init__(self):super(cifar100, self).__init__()# 初始維度3*32*32self.Stem = nn.Sequential(nn.Conv2d(in_channels=3, out_channels=64, kernel_size=5, stride=1, padding=2), # (32-5+2*2)/1+1=32nn.BatchNorm2d(64),nn.ReLU(),)self.layer01 = BasicRes(in_cha=64, out_cha=64)self.layer02 = BasicRes(in_cha=64, out_cha=64)self.layer11 = BasicRes(in_cha=64, out_cha=128)self.layer12 = BasicRes(in_cha=128, out_cha=128)self.layer21 = BasicRes(in_cha=128, out_cha=256)self.layer22 = BasicRes(in_cha=256, out_cha=256)self.layer31 = BasicRes(in_cha=256, out_cha=512)self.layer32 = BasicRes(in_cha=512, out_cha=512)self.pool_max01 = nn.MaxPool2d(1, 1)self.pool_max02 = nn.MaxPool2d(2)self.pool_avg = nn.AdaptiveAvgPool2d((1, 1)) # b*c*1*1self.fc = nn.Sequential(nn.Dropout(0.4),nn.Linear(512, 256),nn.ReLU(),nn.Linear(256, 100),)def forward(self, x):x = self.Stem(x)x = self.pool_max01(x)x = self.layer01(x)x = self.layer02(x)x = self.pool_max02(x)x = self.layer11(x)x = self.layer12(x)x = self.pool_max02(x)x = self.layer21(x)x = self.layer22(x)x = self.pool_max02(x)x = self.layer31(x)x = self.layer32(x)x = self.pool_max02(x)x = self.pool_avg(x).view(x.size()[0], -1)x = self.fc(x)return x
由于CIFAR-100圖像維度為(3,32,32),適當修改了ResNet-18的設計框架加以應用。
2.正式訓練
import torch
import torchvision.datasets as dataset
import torchvision.transforms as transforms
import torch.nn as nn
from torch.utils.data import DataLoader, random_split
import matplotlib.pyplot as plt
import time
from MyModel import BasicRes, cifar100total_start = time.time()# 正式訓練函數
def train_val(train_loader, val_loader, device, model, loss, optimizer, epochs, save_path): # 正式訓練函數model = model.to(device)plt_train_loss = [] # 訓練過程loss值,存儲每輪訓練的均值plt_train_acc = [] # 訓練過程acc值plt_val_loss = [] # 驗證過程plt_val_acc = []max_acc = 0 # 以最大準確率來確定訓練過程的最優模型for epoch in range(epochs): # 開始訓練train_loss = 0.0train_acc = 0.0val_acc = 0.0val_loss = 0.0start_time = time.time()model.train()for index, (images, labels) in enumerate(train_loader):images, labels = images.to(device), labels.to(device)optimizer.zero_grad() # 梯度置0pred = model(images)bat_loss = loss(pred, labels) # CrossEntropyLoss會對輸入進行一次softmaxbat_loss.backward() # 回傳梯度optimizer.step() # 更新模型參數train_loss += bat_loss.item()# 注意此時的pred結果為64*10的張量pred = pred.argmax(dim=1)train_acc += (pred == labels).sum().item()print("當前為第{}輪訓練,批次為{}/{},該批次總loss:{} | 正確acc數量:{}".format(epoch+1, index+1, len(train_data)//config["batch_size"],bat_loss.item(), (pred == labels).sum().item()))# 計算當前Epoch的訓練損失和準確率,并存儲到對應列表中:plt_train_loss.append(train_loss / train_loader.dataset.__len__())plt_train_acc.append(train_acc / train_loader.dataset.__len__())model.eval() # 模型調為驗證模式with torch.no_grad(): # 驗證過程不需要梯度回傳,無需追蹤gradfor index, (images, labels) in enumerate(val_loader):images, labels = images.cuda(), labels.cuda()pred = model(images)bat_loss = loss(pred, labels) # 算交叉熵lossval_loss += bat_loss.item()pred = pred.argmax(dim=1)val_acc += (pred == labels).sum().item()print("當前為第{}輪驗證,批次為{}/{},該批次總loss:{} | 正確acc數量:{}".format(epoch+1, index+1, len(val_data)//config["batch_size"],bat_loss.item(), (pred == labels).sum().item()))val_acc = val_acc / val_loader.dataset.__len__()if val_acc > max_acc:max_acc = val_acctorch.save(model, save_path)plt_val_loss.append(val_loss / val_loader.dataset.__len__())plt_val_acc.append(val_acc)print('該輪訓練結束,訓練結果如下[%03d/%03d] %2.2fsec(s) TrainAcc:%3.6f TrainLoss:%3.6f | valAcc:%3.6f valLoss:%3.6f \n\n'% (epoch+1, epochs, time.time()-start_time, plt_train_acc[-1], plt_train_loss[-1], plt_val_acc[-1], plt_val_loss[-1]))print(f'訓練結束,最佳模型的準確率為{max_acc}')plt.plot(plt_train_loss) # 畫圖plt.plot(plt_val_loss)plt.title('loss')plt.legend(['train', 'val'])plt.show()plt.plot(plt_train_acc)plt.plot(plt_val_acc)plt.title('Accuracy')plt.legend(['train', 'val'])# plt.savefig('./acc.png')plt.show()# 1.數據預處理
transform = transforms.Compose([transforms.RandomHorizontalFlip(), # 以 50% 的概率隨機翻轉輸入的圖像,增強模型的泛化能力transforms.RandomCrop(size=(32, 32), padding=4), # 隨機裁剪transforms.ToTensor(),transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)) # 對圖像張量進行歸一化
]) # 數據增強
ori_data = dataset.CIFAR100(root="./Data_CIFAR100",train=True,transform=transform,download=True
)
print(f"各標簽的真實含義:{ori_data.class_to_idx}\n")
# print(len(ori_data))
# # 查看某一樣本數據
# image, label = ori_data[0]
# print(f"Image shape: {image.shape}, Label: {label}")
# image = image.permute(1, 2, 0).numpy()
# plt.imshow(image)
# plt.title(f'Label: {label}')
# plt.show()config = {"train_size_perc": 0.8,"batch_size": 64,"learning_rate": 0.001,"epochs": 50,"save_path": "model_save/Res_cifar100_model.pth"
}# 設置訓練集和驗證集的比例
train_size = int(config["train_size_perc"] * len(ori_data)) # 80%用于訓練
val_size = len(ori_data) - train_size # 20%用于驗證
train_data, val_data = random_split(ori_data, [train_size, val_size])
# print(len(train_data))
# print(len(val_data))train_loader = DataLoader(dataset=train_data, batch_size=config["batch_size"], shuffle=True)
val_loader = DataLoader(dataset=val_data, batch_size=config["batch_size"], shuffle=False)device = "cuda" if torch.cuda.is_available() else "cpu"
print(f"{device}\n")
model = cifar100()
# model = torch.load(config["save_path"]).to(device)
print(f"我的模型框架如下:\n{model}")
loss = nn.CrossEntropyLoss() # 交叉熵損失函數
optimizer = torch.optim.AdamW(model.parameters(), lr=config["learning_rate"], weight_decay=1e-4) # L2正則化
# optimizer = torch.optim.Adam(model.parameters(), lr=config["learning_rate"]) # 優化器train_val(train_loader, val_loader, device, model, loss, optimizer, config["epochs"], config["save_path"])print(f"\n本次訓練總耗時為:{(time.time()-total_start) / 60 }min")
3.測試文件
import torch
import torchvision.datasets as dataset
import torchvision.transforms as transforms
import torch.nn as nn
from torch.utils.data import DataLoader
import matplotlib.pyplot as plt
import time
from MyModel import BasicRes, cifar100total_start = time.time()
# 測試函數
def test(save_path, test_loader, device, loss): # 測試函數best_model = torch.load(save_path).to(device)test_loss = 0.0test_acc = 0.0start_time = time.time()with torch.no_grad():for index, (images, labels) in enumerate(test_loader):images, labels = images.cuda(), labels.cuda()pred = best_model(images)bat_loss = loss(pred, labels) # 算交叉熵losstest_loss += bat_loss.item()pred = pred.argmax(dim=1)test_acc += (pred == labels).sum().item()print("正在最終測試:批次為{}/{},該批次總loss:{} | 正確acc數量:{}".format(index + 1, len(test_data) // config["batch_size"],bat_loss.item(), (pred == labels).sum().item()))print('最終測試結束,測試結果如下:%2.2fsec(s) TestAcc:%.2f%% TestLoss:%.2f \n\n'% (time.time() - start_time, test_acc/test_loader.dataset.__len__()*100, test_loss/test_loader.dataset.__len__()))# 1.數據預處理
transform = transforms.Compose([transforms.RandomHorizontalFlip(), # 以 50% 的概率隨機翻轉輸入的圖像,增強模型的泛化能力transforms.RandomCrop(size=(32, 32), padding=4), # 隨機裁剪transforms.ToTensor(),transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)) # 對圖像張量進行歸一化
]) # 數據增強
test_data = dataset.CIFAR100(root="./Data_CIFAR100",train=False,transform=transform,download=True
)
# print(len(test_data)) # torch.Size([3, 32, 32])
config = {"batch_size": 64,"save_path": "model_save/Res_cifar100_model.pth"
}
test_loader = DataLoader(dataset=test_data, batch_size=config["batch_size"], shuffle=True)
loss = nn.CrossEntropyLoss() # 交叉熵損失函數
device = "cuda" if torch.cuda.is_available() else "cpu"
print(f"{device}\n")test(config["save_path"], test_loader, device, loss)print(f"\n本次訓練總耗時為:{time.time()-total_start}sec(s)")4.訓練結果
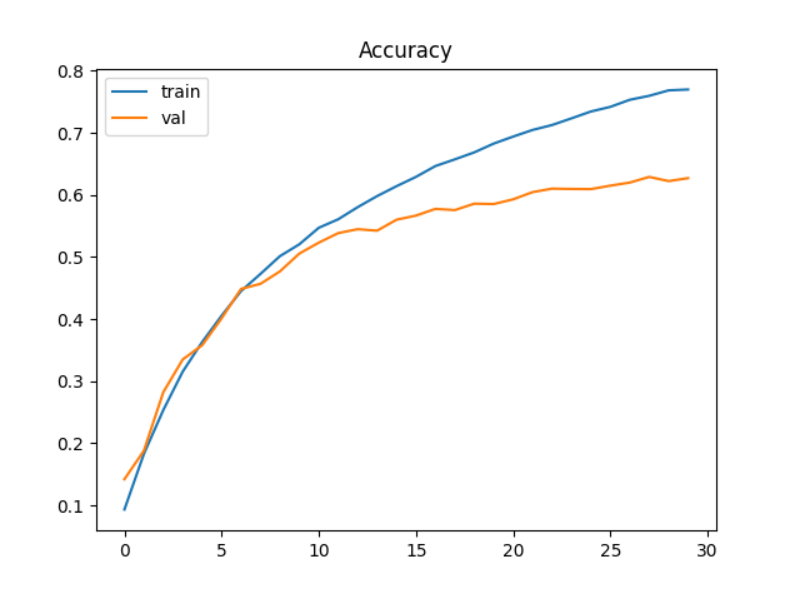
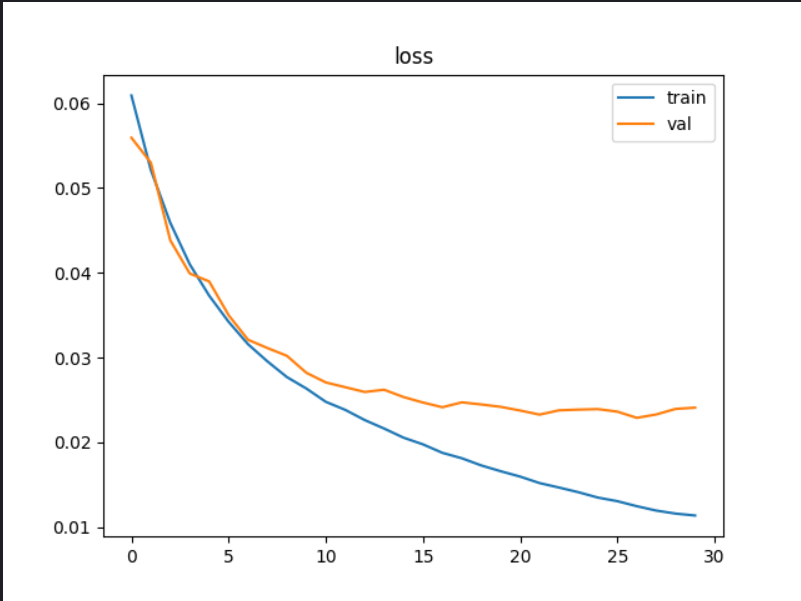

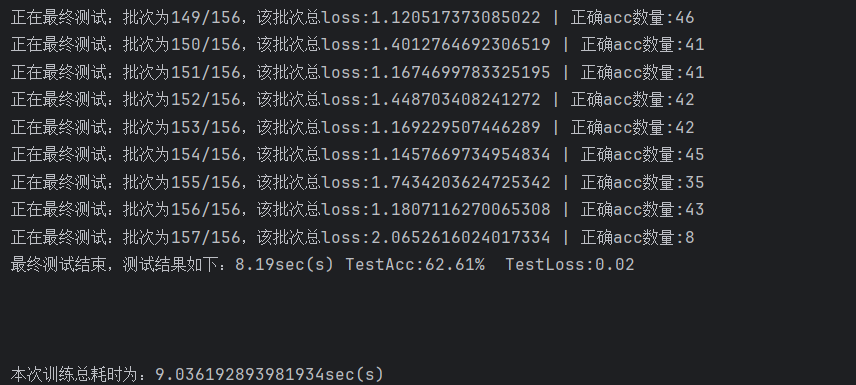
設計learning rate=0.001先訓練了30輪,模型在測試集上的準確率已經來到了62.61%;
?
后續引入學習率衰減策略對同一網絡進行再次訓練,初始lr=0.001,衰減系數0.2,每20輪衰減一次,訓練60輪,結果如下:
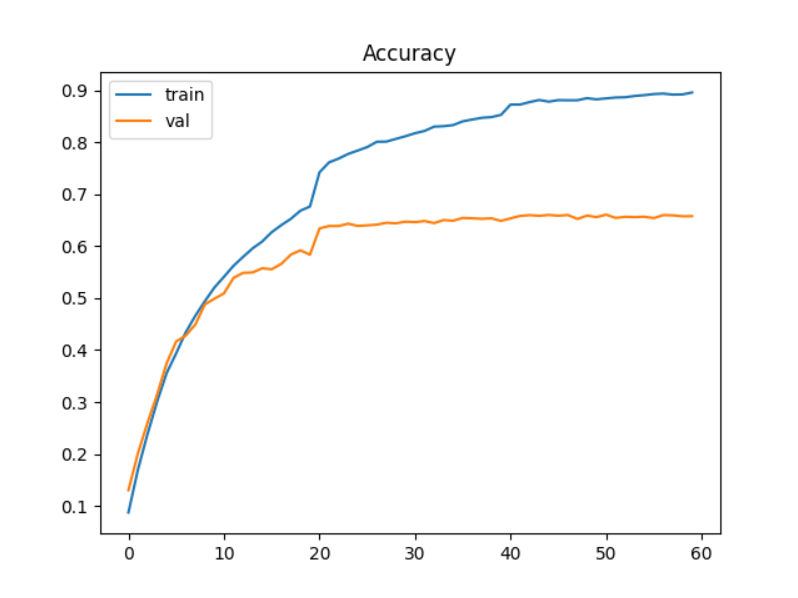
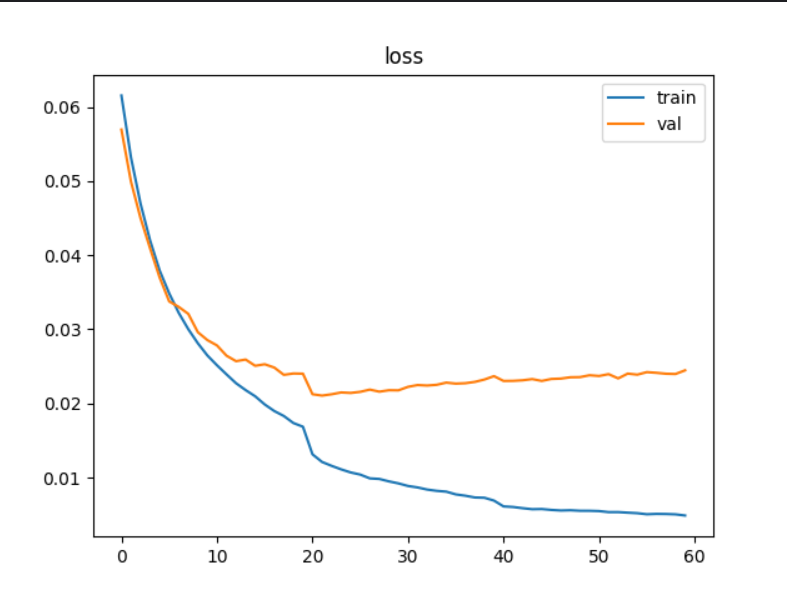
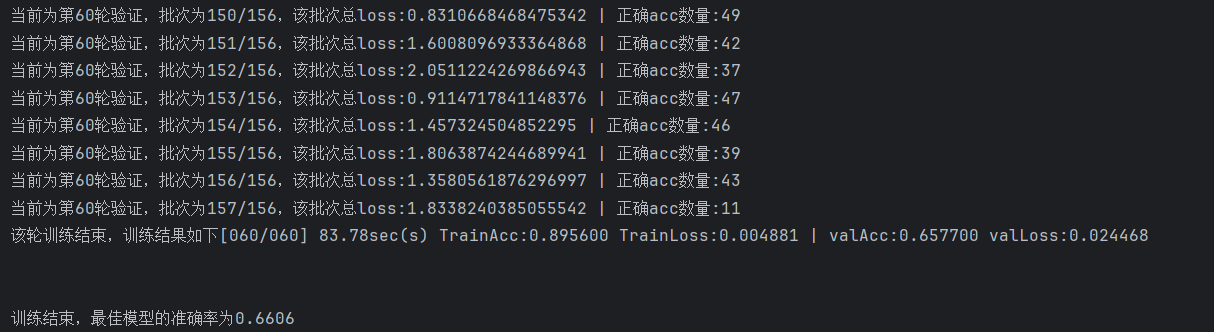
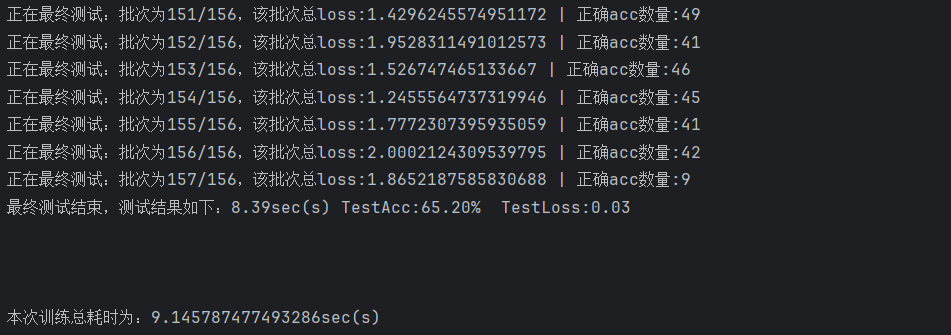
最終訓練模型在測試集上的準確率 達到了65.20%










)
:如何將一臺電腦上的Elasticsearch服務遷移到另一臺電腦上)
的工作原理)





)
