目錄
一、復合查詢
1、基本查詢回顧:
2、多表查詢:
3、自連接:
4、子查詢:
單列子查詢
多行子查詢:
多列子查詢:
在from語句中使用子查詢:
5、合并查詢:
union:
union all:
二、內外連接:
1、內連接:
2、外連接:
左外連接:
右外連接:
這里依然是使用經典數據表:員工表(emp)、部門表(dept)和工資等級表(salgrade)
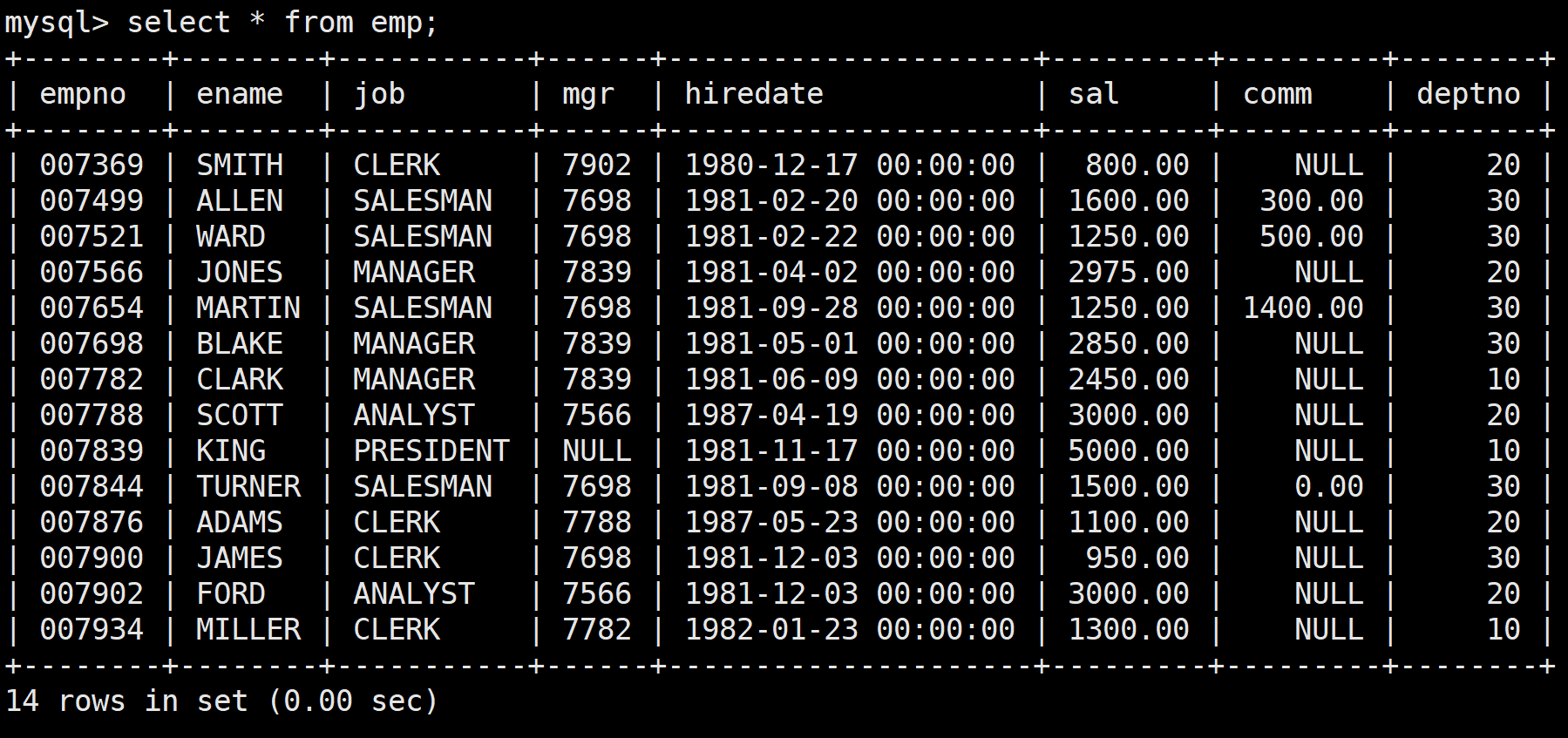
如下是員工表,分別是empno員工號/ename員工姓名/job工作/mgr上級編號/hiredate受雇日期/sal薪金/comm傭金/deptno所屬部門編號
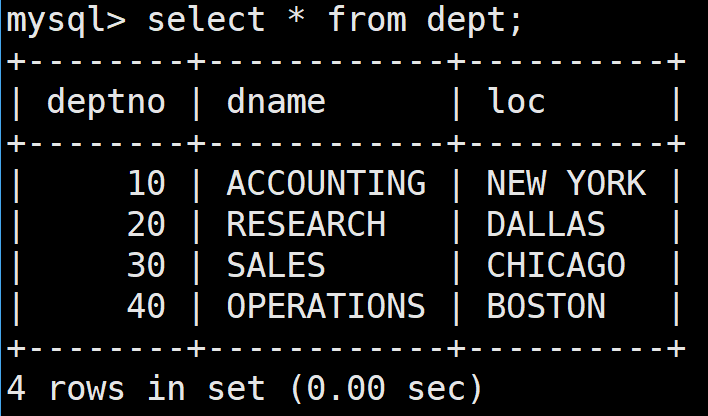
如下是部門表,分別是deptno部門編號,dname部門名稱,loc部門所在地
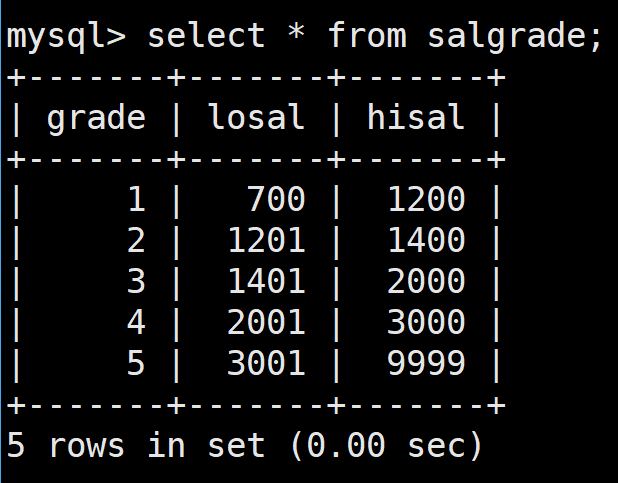
如下是薪資等級:
一、復合查詢
1、基本查詢回顧:
查詢工資高于500或崗位為MANAGER的員工,同時還要滿足他們的名字的首字母大寫的J
select * from emp where (sal>500 or job='MANAGER') and ename like 'J%';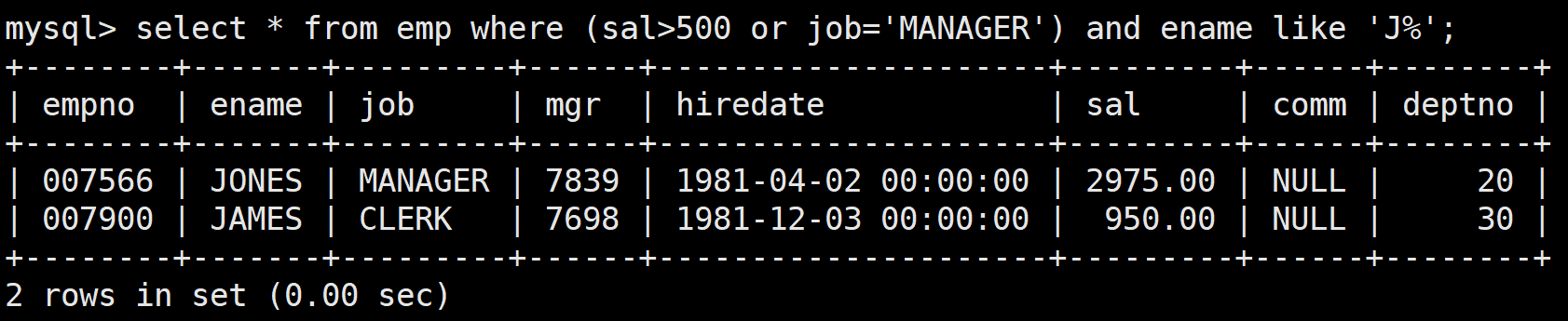
除了用模糊匹配,還有字符串切割也可以
select * from emp where (sal>500 or job='MANAGER') and substring(ename,1,1)='J';
查詢員工信息,按部門號升序而員工工資降序顯示
select ename,sal,deptno from emp order by deptno asc ,sal desc;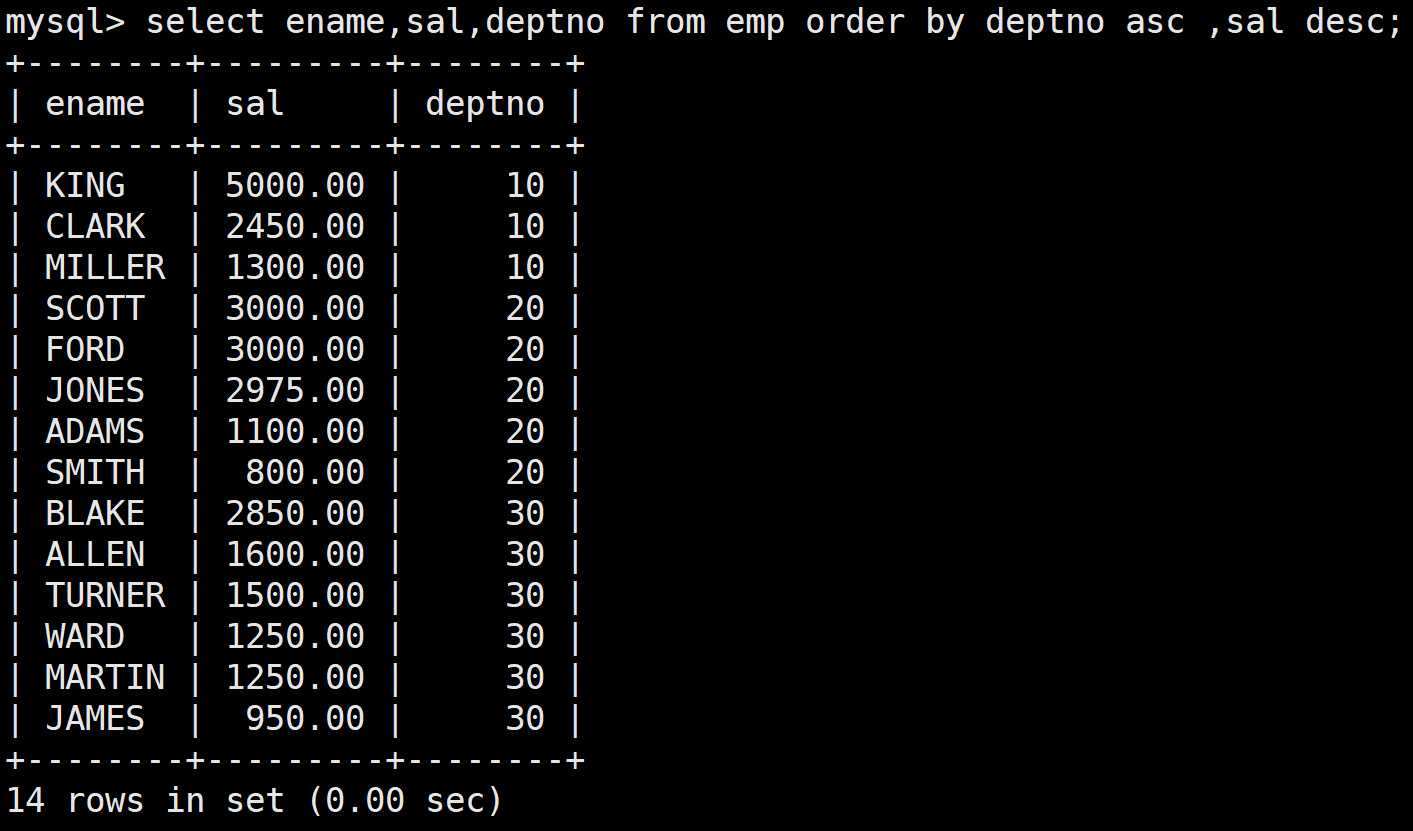
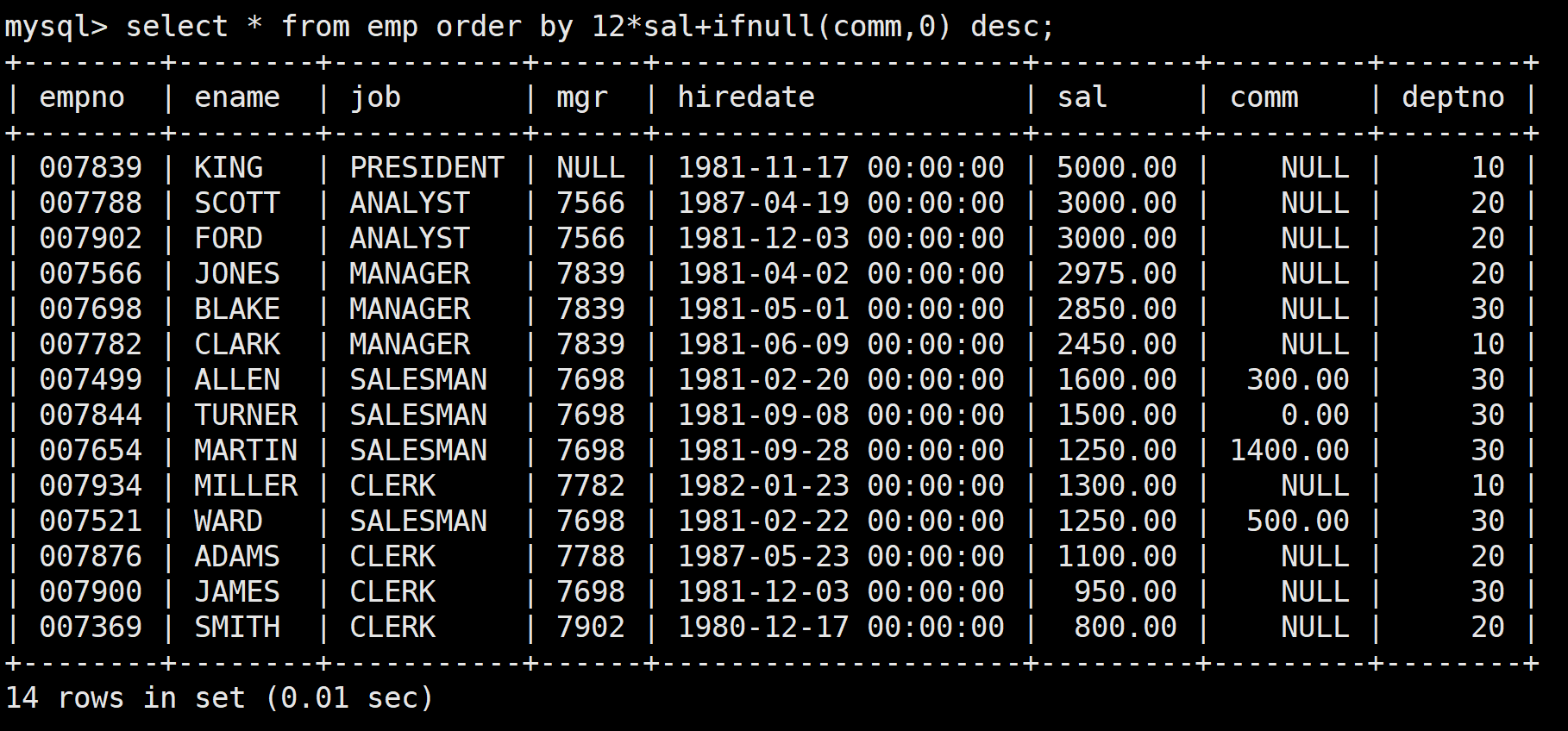
查詢員工信息,按年薪降序顯示
select * from emp order by 12*sal+ifnull(comm,0) desc;員工的年薪為月工資*12+年終獎,但是這里不能夠直接12*sal+comm,因為comm可能為NULL,此時如果用NULL運算就會使結果為空
所以需要使用函數ifnull,如果comm為NULL就將其設置為0
查詢工資最高的員工的姓名和崗位
首先查看工資最高是誰,這里使用聚合函數:
select max(sal) from emp;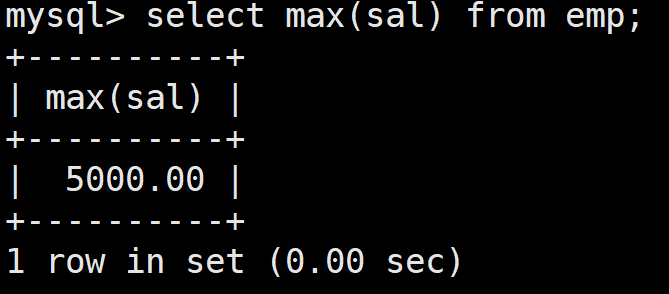
當查詢到最高工資的人后,可以將這個結果放到where語句中作為判斷條件,也就是說where語句中可以進行查詢:
select ename,job from emp where sal=(select max(sal) from emp);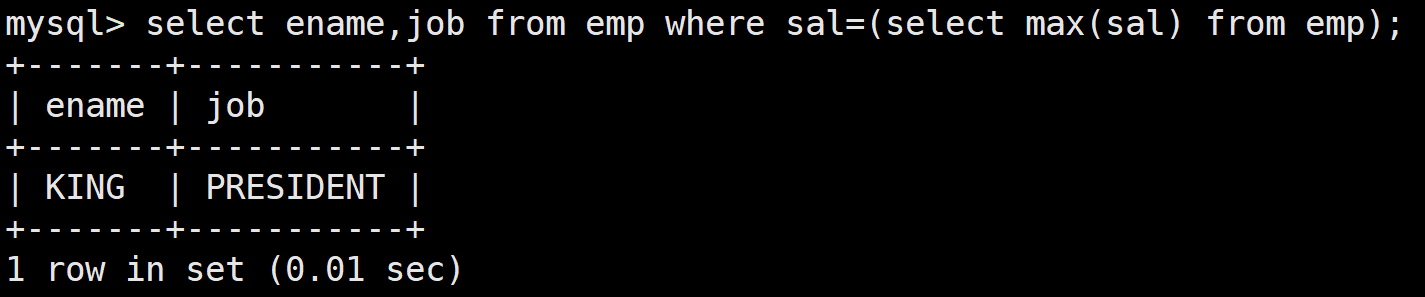
查詢工資高于平均工資的員工信息
首先依然是查詢員工的平均工資:
select avg(sal) from emp;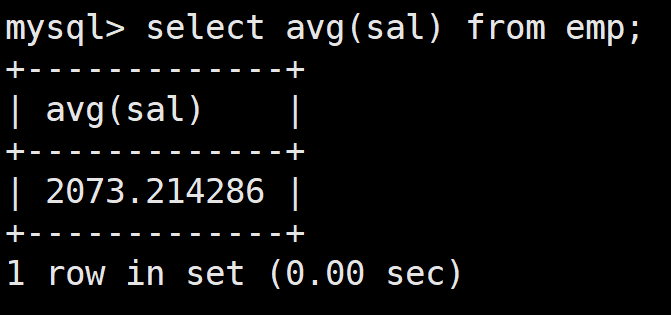
接著將這個語句嵌套在where中作為判斷:
select * from emp where sal>(select avg(sal) from emp);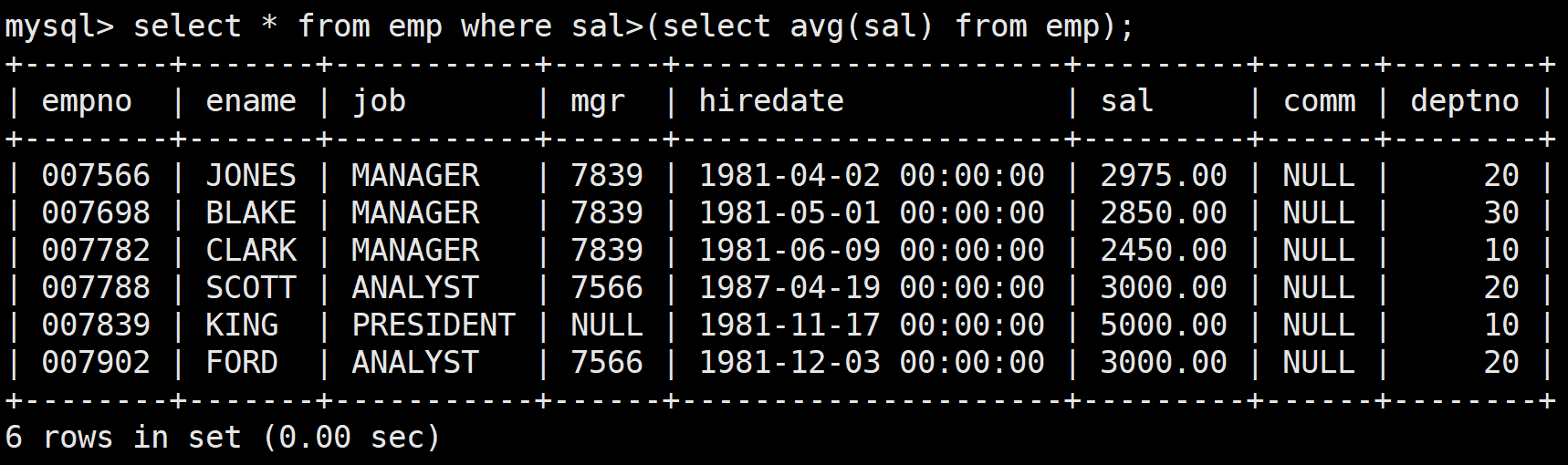
查詢每個部門的平均工資和最高工資
既然是每個部門,就需要進行分組
select deptno,avg(sal) 平均工資,max(sal) 最高工資 from emp group by deptno;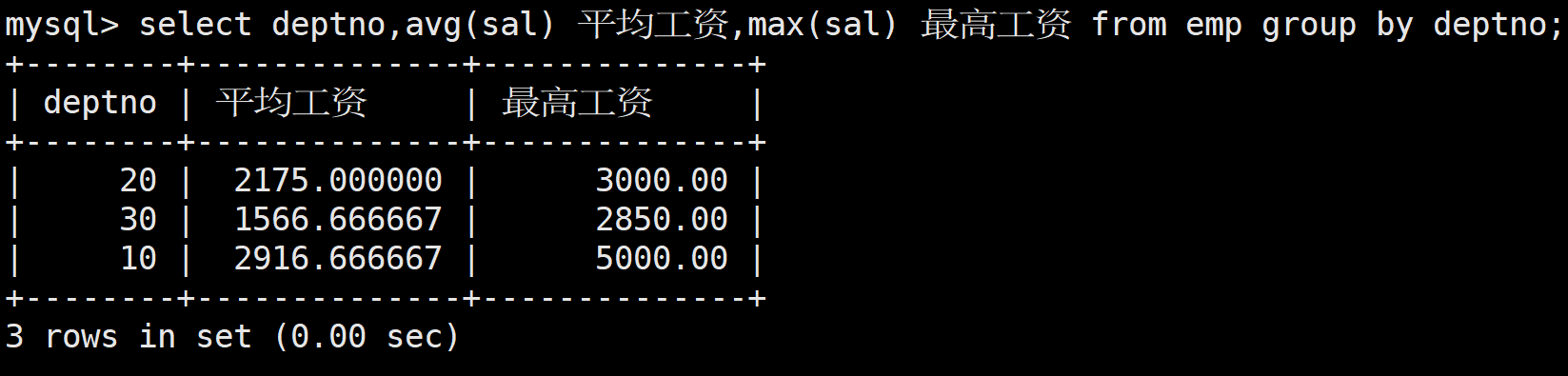
查詢平均工資低于2000的部門號和它的平均工資
select deptno,avg(sal) 平均工資 from emp group by deptno having avg(sal)<2000;這里因為是進行分組查詢,不能使用where,需要使用having來進行條件判斷

查詢每種崗位的雇員總數和平均工資
人數用count()函數進行統計
select job,count(*) 人數,avg(sal) 平均工資 from emp group by job;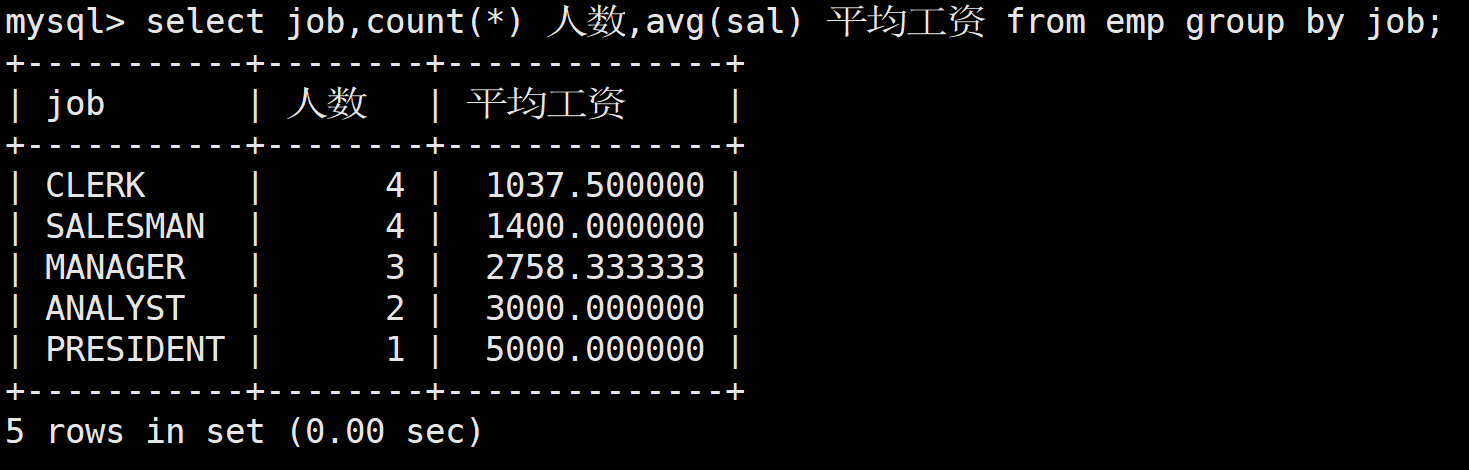
2、多表查詢:
在上述基本查詢中,都是在單表中進行查詢的,但是在實際開發中,更多的是多個表綜合起來進行查詢的,這就叫做多表查詢
笛卡爾積:
在進行多表查詢的時候,將多個表名放在from后面并用逗號隔開,這是,MySQL就會對這些表取笛卡爾積,組成一張新表
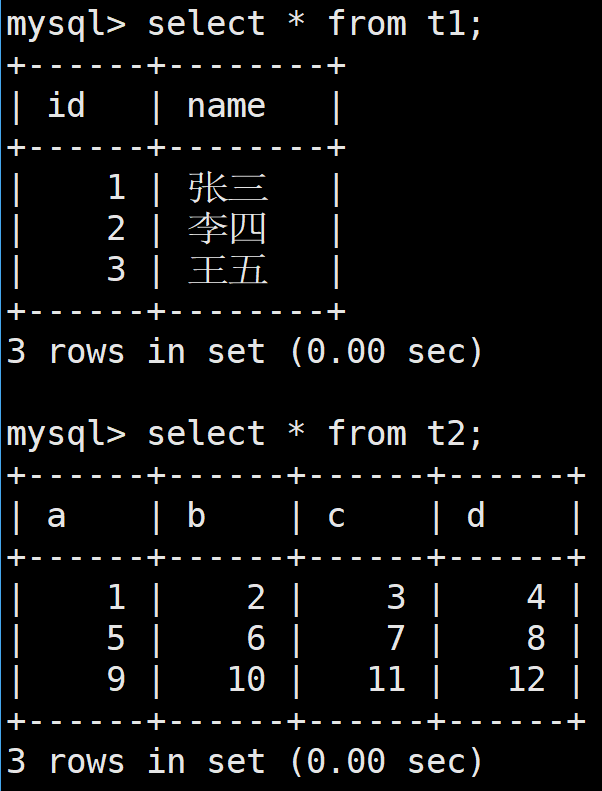
進行笛卡爾積轉化后:
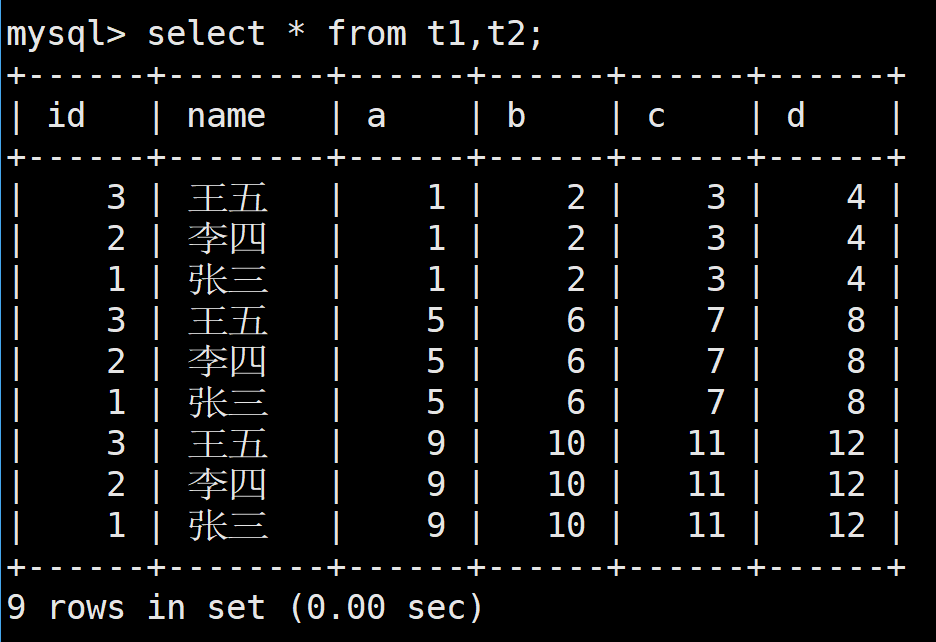
笛卡爾積的本質是拿著第一張表的信息 依次 和第二張表的所有信息進行組合,這樣形成地一張表
多表查詢的本質:對給的多張表取笛卡爾積,然后對笛卡爾積后的表進行查詢
在進行笛卡爾積的多張表中可能會存在相同的列名,這時在選中列名時需要通過(表名.列明)的方式進行指明
顯示雇員名,雇員工資以及所在部門的名字
這里雇員名和雇員工資是在同一張表中的,但是所在部門名字是在另一張表中的,所以需要對這兩張表進行笛卡爾積,然后在進行查詢即可
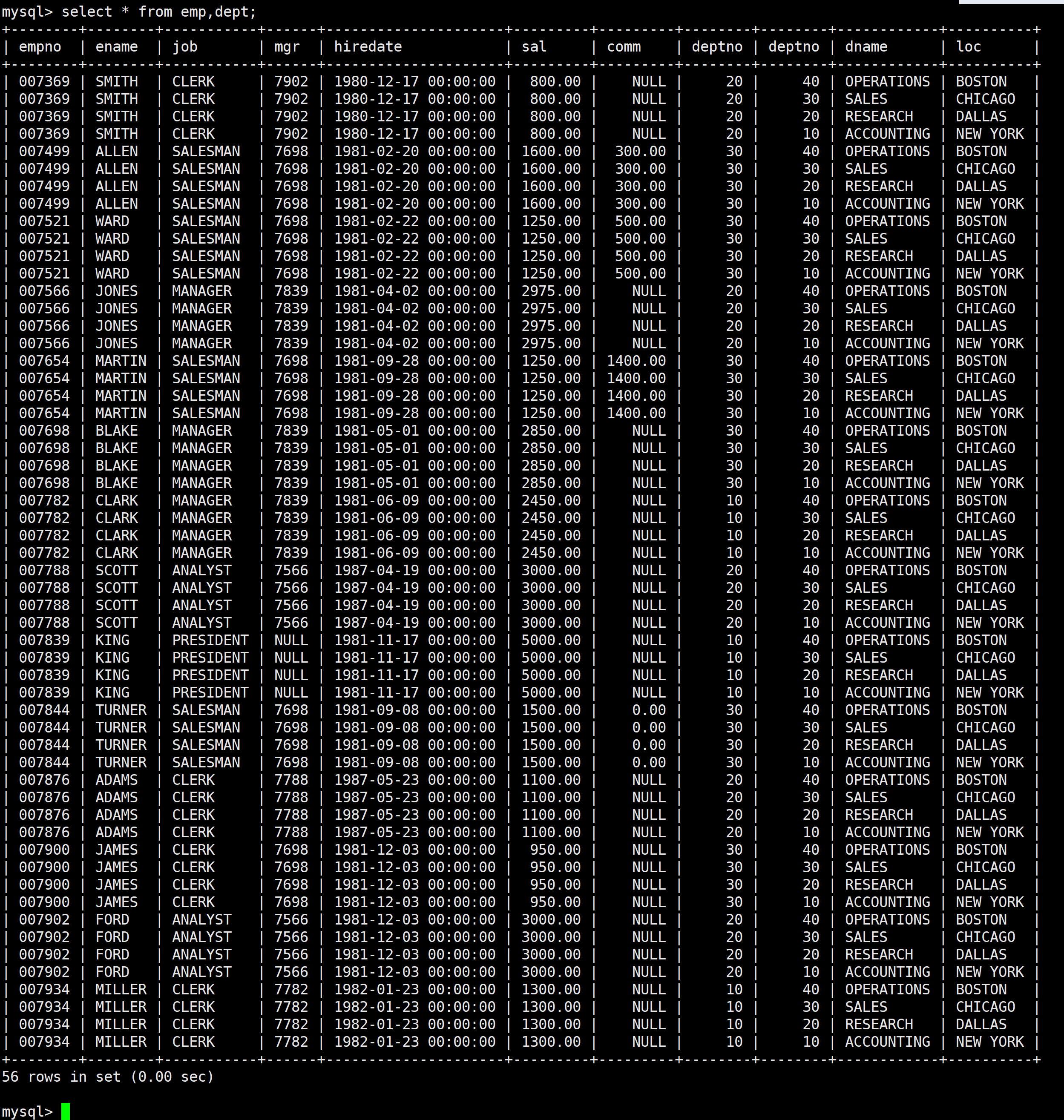
通過上述圖片可以看到,比如Smith他的部門號有兩個,這里是取相等的,其他的就是沒有意義的數據,所以需要進行初步篩選:
select * from emp,dept where emp.deptno=dept.deptno;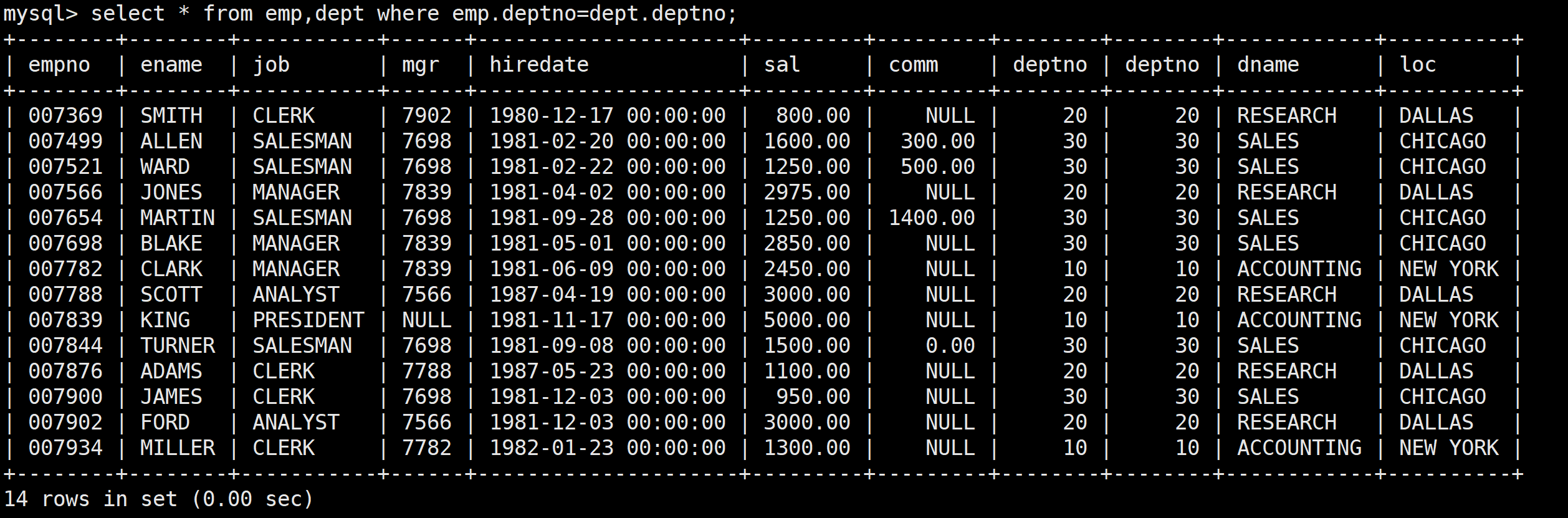
最后在將*修改為所需即可
select ename,sal,dname from emp,dept where emp.deptno=dept.deptno;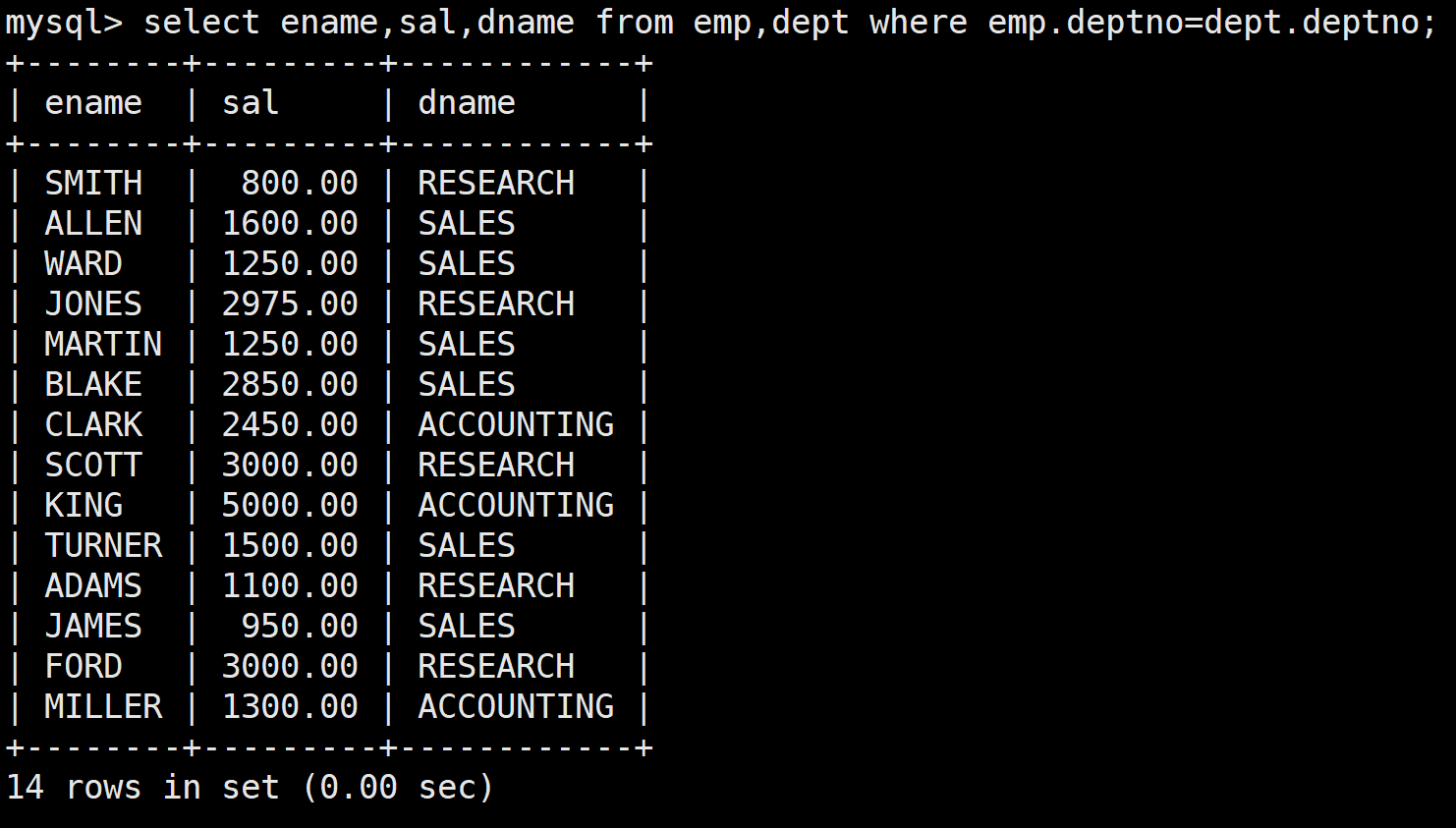
顯示部門號為10的部門名、員工名和員工工資
這里部門名和其他是在不同的表中的
select dname,ename,sal from emp,dept where emp.deptno=dept.deptno and emp.deptno=10;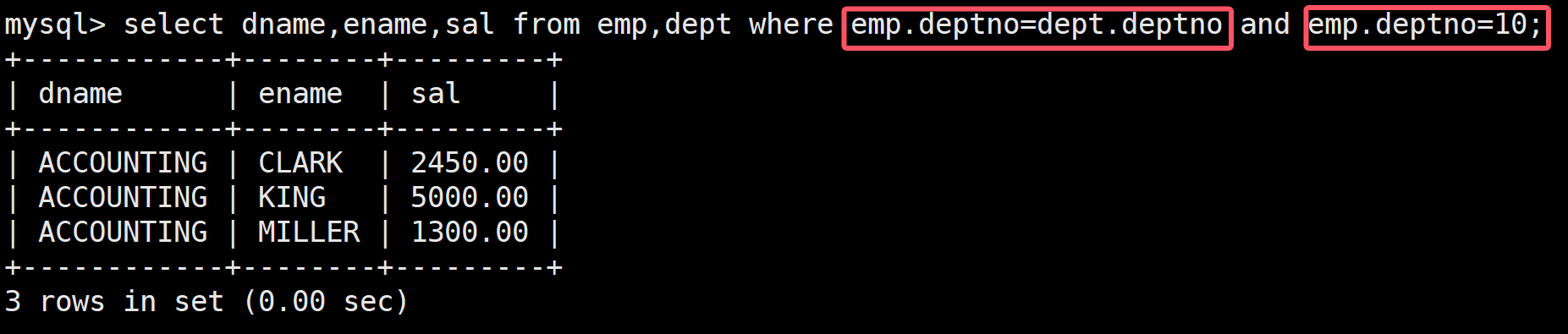
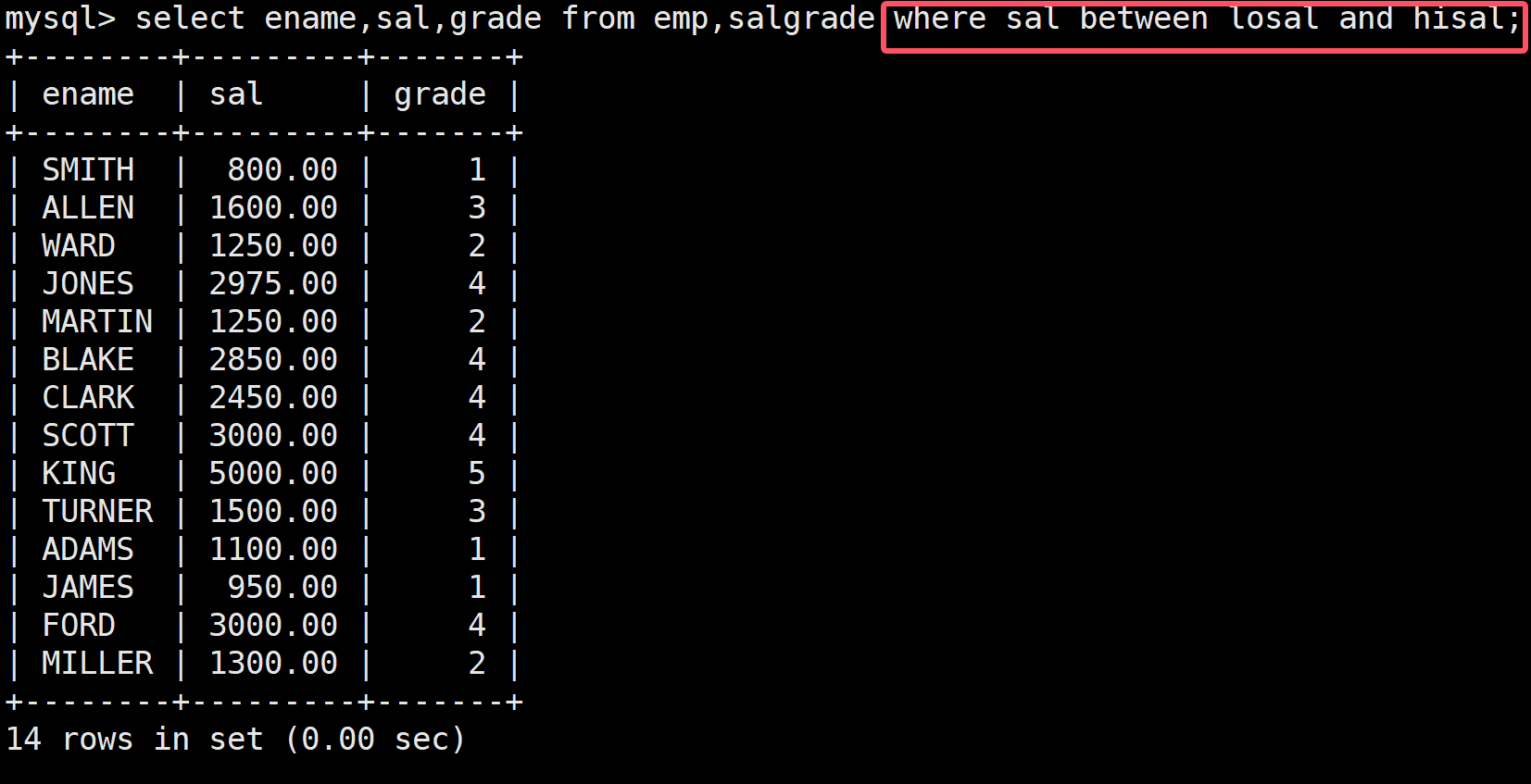
顯示各個員工的姓名、工資和工資級別
這里工資級別和其他是不同的表中:
需要where增加的條件是工資處于最低和最高之間工資篩選出來,才有意義
3、自連接:
自連接是在同一張表進行連接查詢,也就是說對同一張表進行取笛卡爾積,
顯示員工FORD的上級領導的編號和姓名
子查詢解決:
首先找到FORD的上級領導的編號,
select mgr from emp where ename='FORD';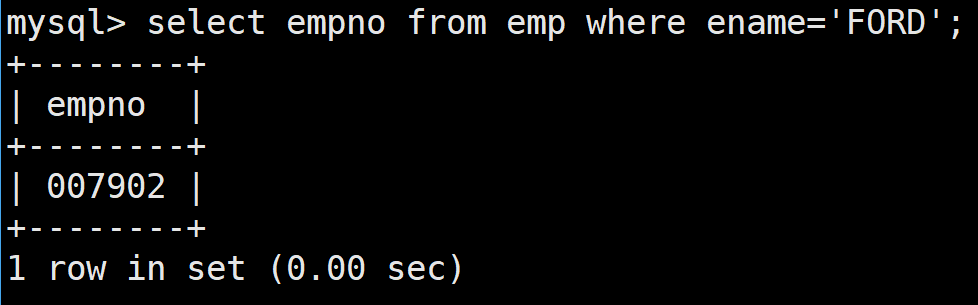
接著通過嵌套找到對應編號的姓名
select empno,ename from emp where empno=(select mgr from emp where ename='FORD');
自連接解決:
員工表中的mgr字段能夠將表中員工的信息和員工領導的信息關聯起來
mysql> select leader.empno,leader.ename from emp leader,emp worker-> where worker.ename='FORD' and leader.empno=worker.mgr;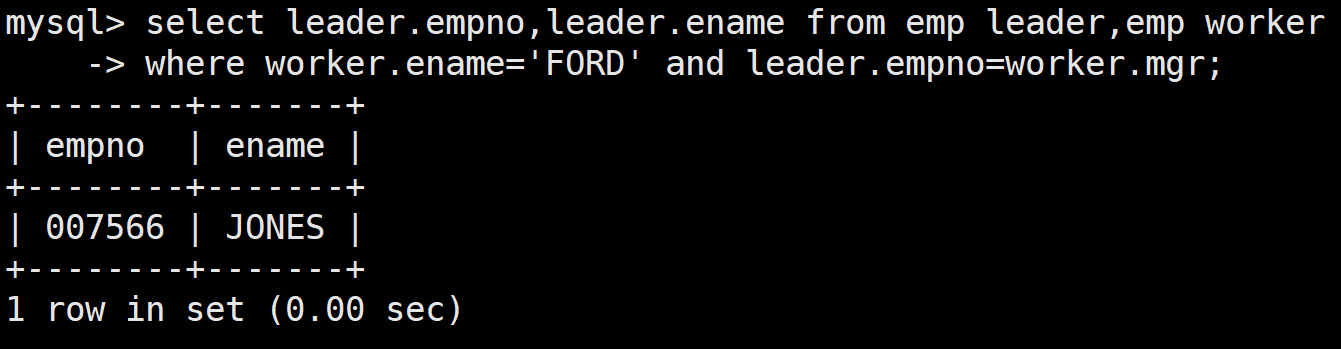
這里是對同一張表進行取笛卡爾積的,所以需要對其取別名來區別開來
4、子查詢:
子查詢是指嵌入在其他sql語句中的select語句,也叫嵌套查詢
子查詢可分為單行子查詢,多行子查詢,多列子查詢,以及在from子句中使用的子查詢
單列子查詢
顯示SMITH同一部門的員工
首先顯示SMITH的部門
select deptno from emp where ename='SMITH';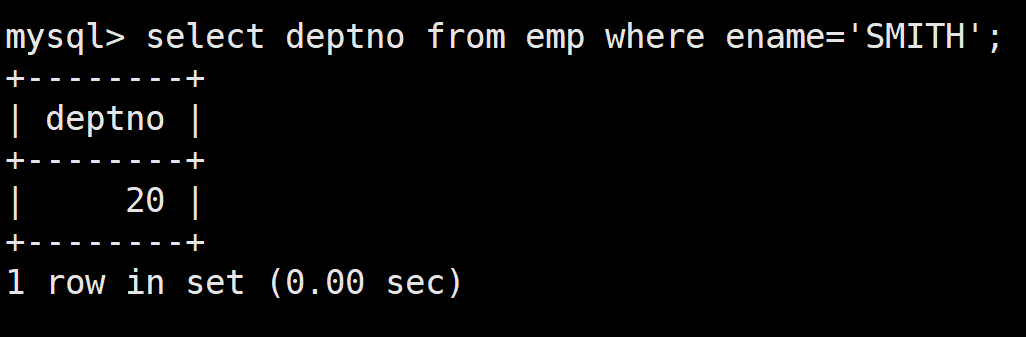
接著將這個語句嵌套在where判斷中,作為嵌套的子語句,再來查詢對應的員工
select * from emp where deptno=(select deptno from emp where ename='SMITH') and ename<>'SMITH';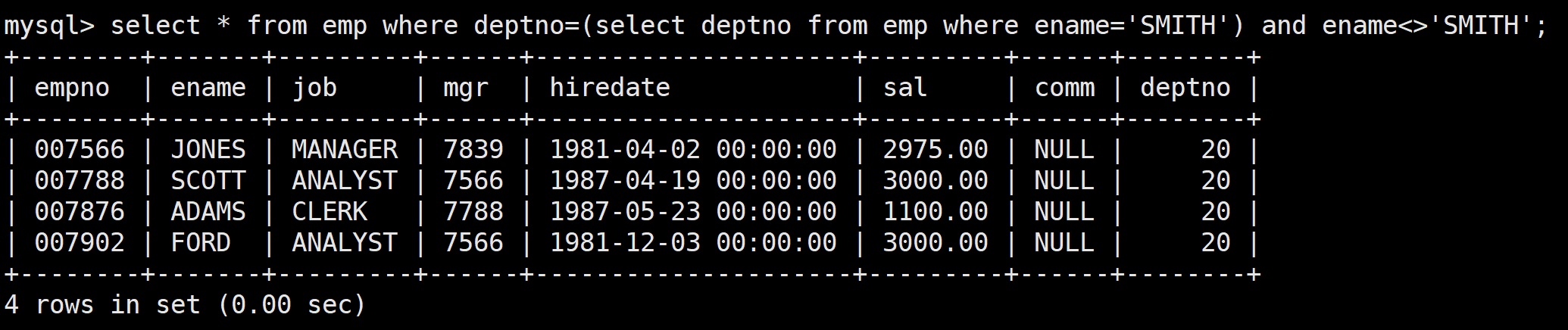
多行子查詢:
返回多行單列數據的子查詢
in關鍵字:查詢和 10 號部門的工作崗位相同的雇員的名字,崗位,工資,部門號,但是不包含 10 自己的
首先查詢10號部門的工作崗位,這里要進行去重,因為可能不同的人在同一個部門有著相同的工作崗位
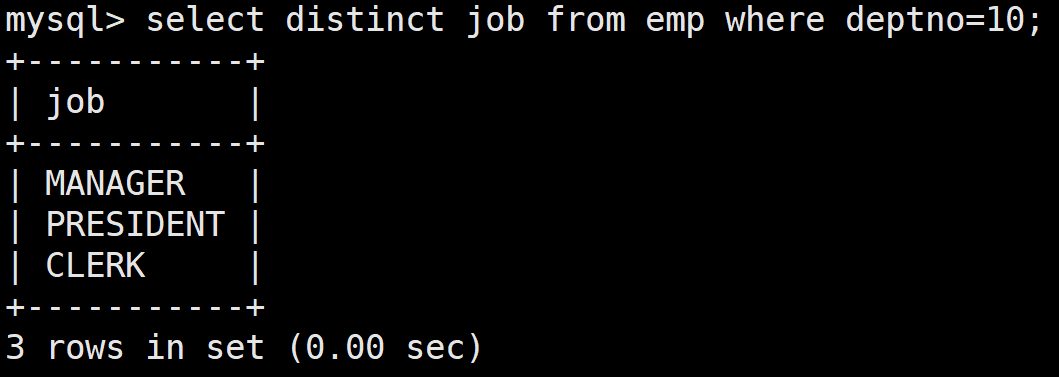
這里查出來和之前不同的是這里查詢的是單列多行的,只要崗位和這里面一個相同就可以,用in關鍵字
select ename,job,sal,deptno from emp where job in(select distinct job from emp where deptno=10) and deptno<>10;
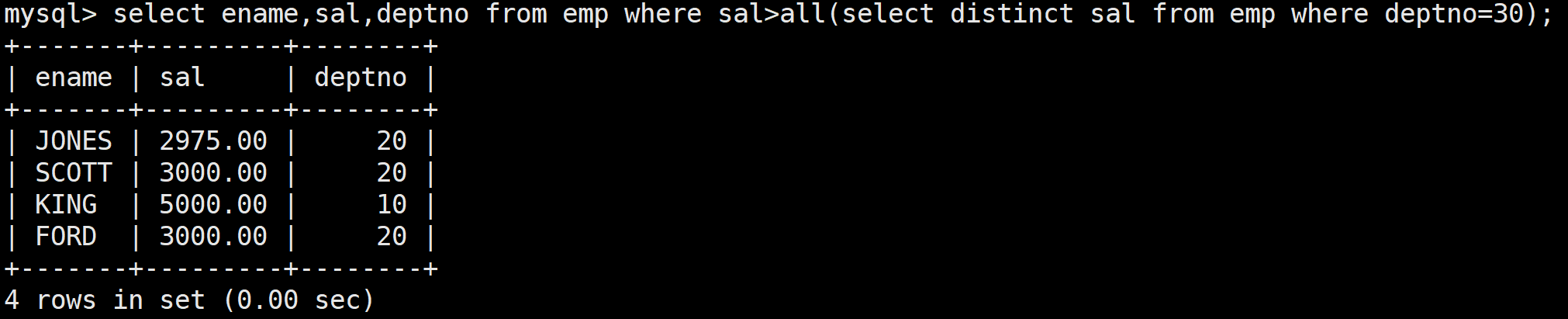
all關鍵字:顯示工資比30號部門的所有員工的工資高的員工的姓名、工資和部門號
先查詢30號部門的所有員工的工資,因為工資可能相等,所以這里最好去重
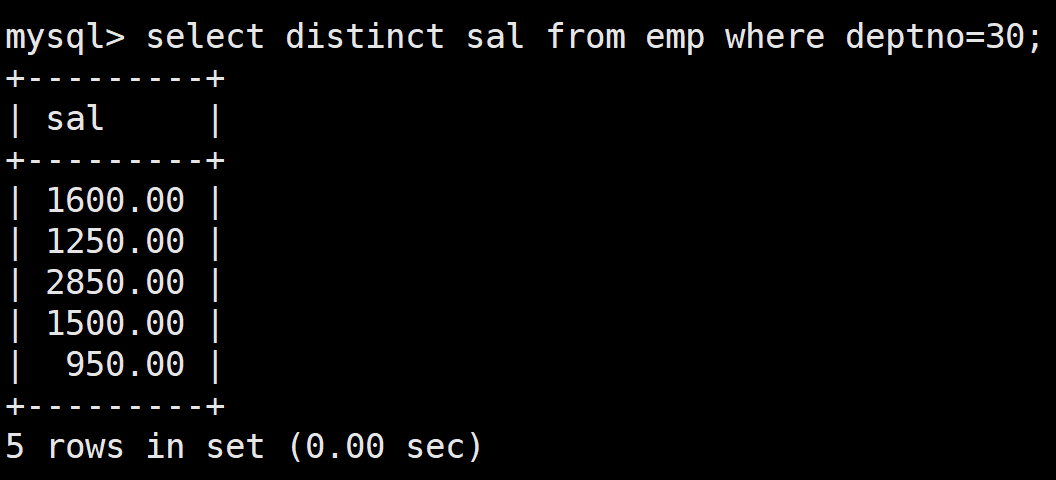
接著在進行嵌套,為了保證所查出來的工資比30號部門的所有員工的工資高,這里使用all關鍵字
any關鍵字:顯示工資比30號部門的任意員工的工資高的員工的姓名、工資和部門號,包含30號部門的員工
首先查詢30號部門的員工的工資:
select distinct sal from emp where deptno=30;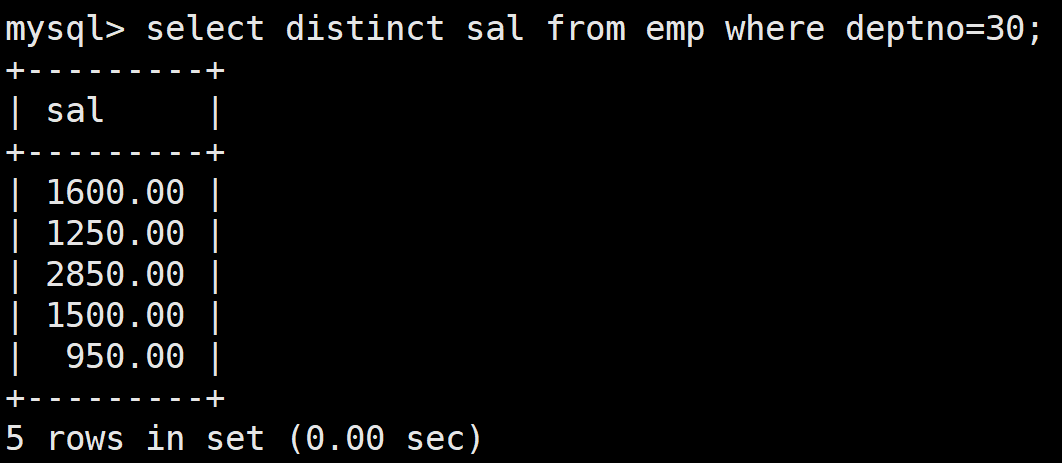
接著通過關鍵字any進行員工的查看:
select ename,sal,deptno from emp where sal>any(select distinct sal from emp where deptno=30);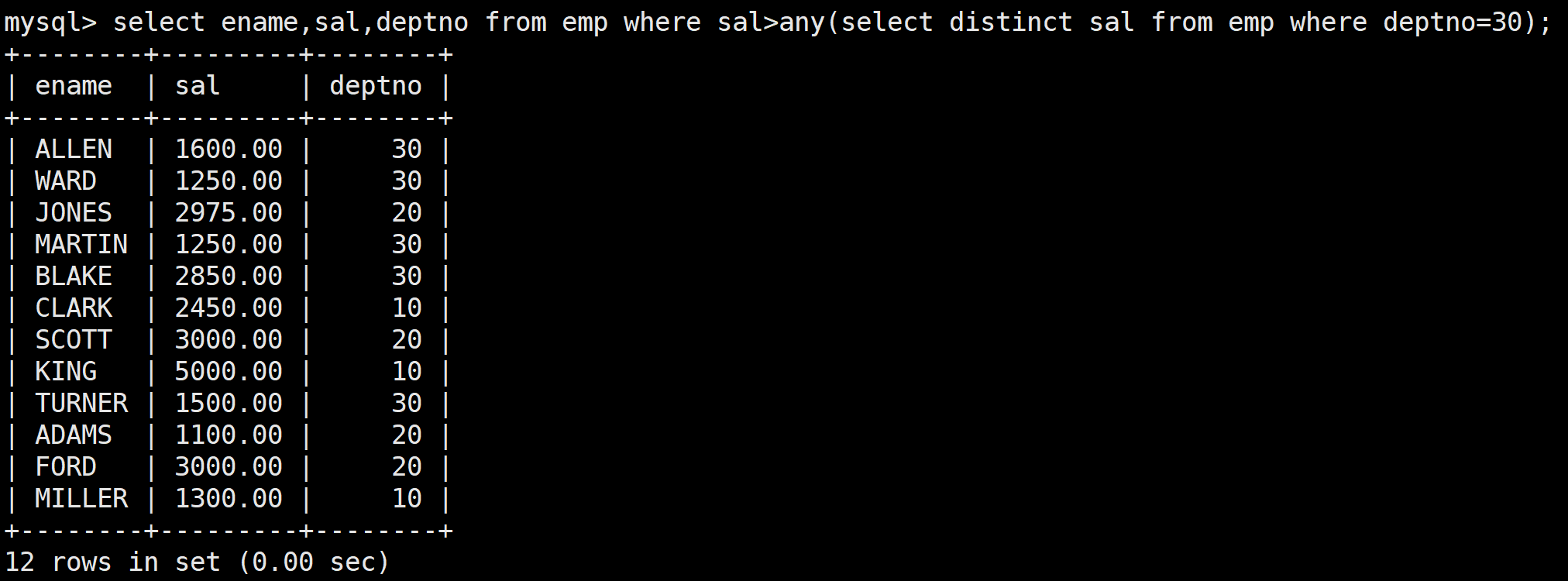
多列子查詢:
這是返回多列多行的查詢
顯示和SMITH的部門和崗位完全相同的員工,不包含SMITH本人
首先顯示SMITH的部門和崗位:
select deptno,job from emp where ename='SMITH';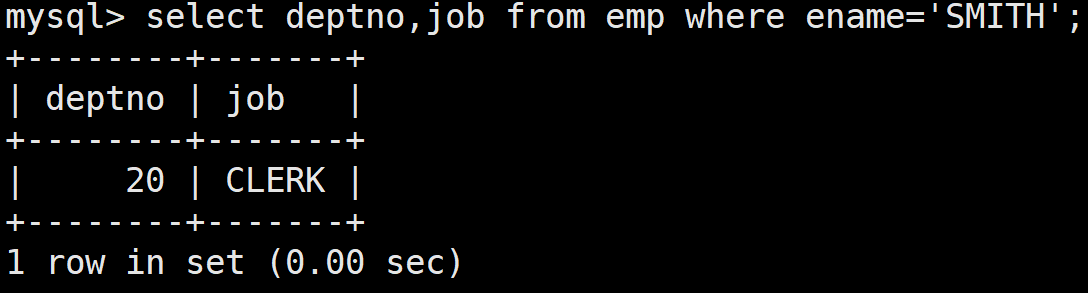
接著通過復合查詢,將上述的查詢放在where后面作為子查詢
這里是采用的多列查詢,所以在where后面匹配的時候通過括號進行多列匹配,并且在后面記得保證名字不能為SMITH

也就是說,多列子查詢在where匹配的時候要用括號將多列數據進行比較,并且如果數據是多行的,也可以使用in,all,any關鍵字
在from語句中使用子查詢:
我們知道from后面跟著的是表,在MySQL下一切皆表,所以可以將一個查詢結果當做臨時表,放在from語句的后面
顯示每個高于自己部門平均工資的員工的姓名、部門、工資和部門的平均工資
首先查詢每一個部門其自己的平均工資:
select deptno,avg(sal) from emp group by deptno;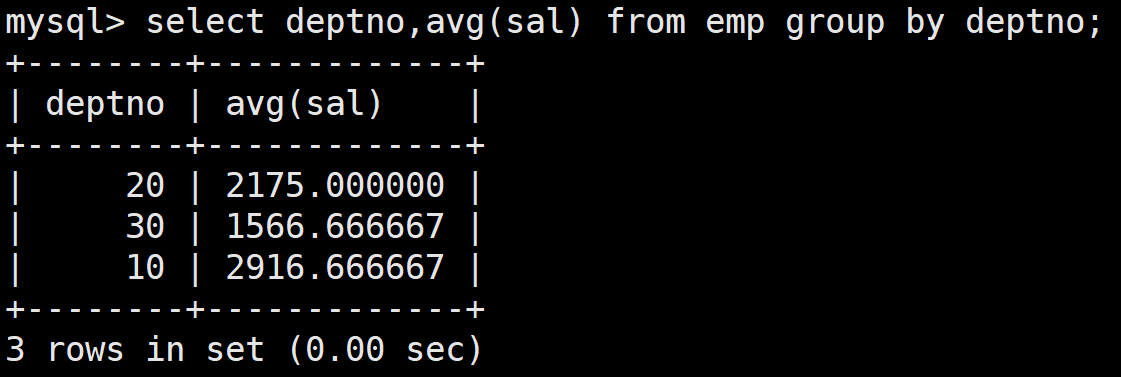
接著將如上表和員工表取笛卡爾積,然后再通過部門號相等刪除部分無效數據,最后where篩選出高于自己部門平均工資的員工的數據
mysql> select ename,emp.deptno,sal,平均工資-> from emp,(select deptno,avg(sal) 平均工資 from emp group by deptno) newtable-> where emp.deptno=newtable.deptno and sal>平均工資;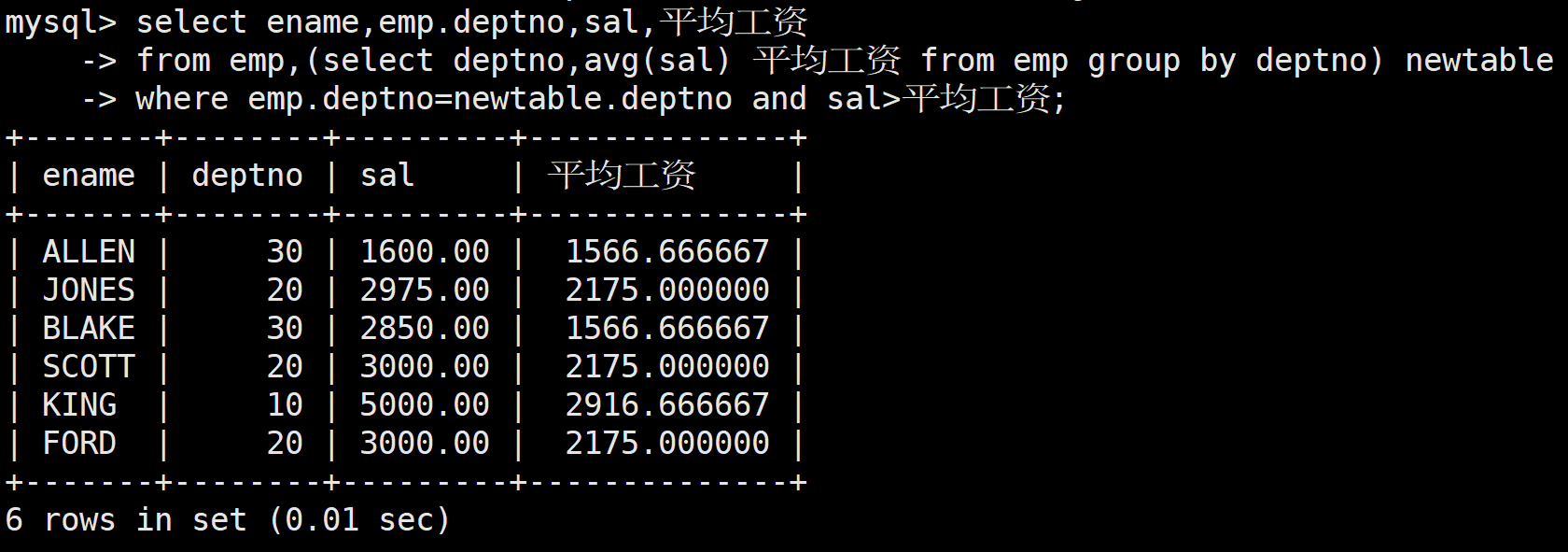
注意:在from子句的查詢中,必須給子查詢所生成的臨時表取一個別名,否則查詢結果會出錯找不到對應的字段,并且如果兩張表中有相同的字段,要指定其是在哪張表的,否則也會報錯
顯示每個部門工資最高的員工的姓名、工資、部門和部門的最高工資
首先查詢每個部門的最高工資的員工:
select deptno,max(sal) from emp group by deptno;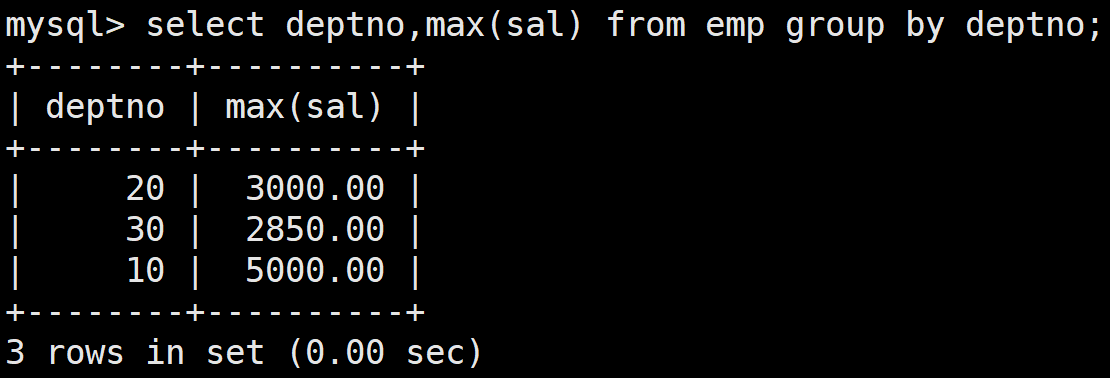
接著將上述表和員工表進行笛卡爾積,在進行篩選即可
mysql> select ename,sal,emp.deptno,最高工資-> from emp,(select deptno,max(sal) 最高工資 from emp group by deptno) newtable-> where emp.deptno=newtable.deptno and sal=最高工資;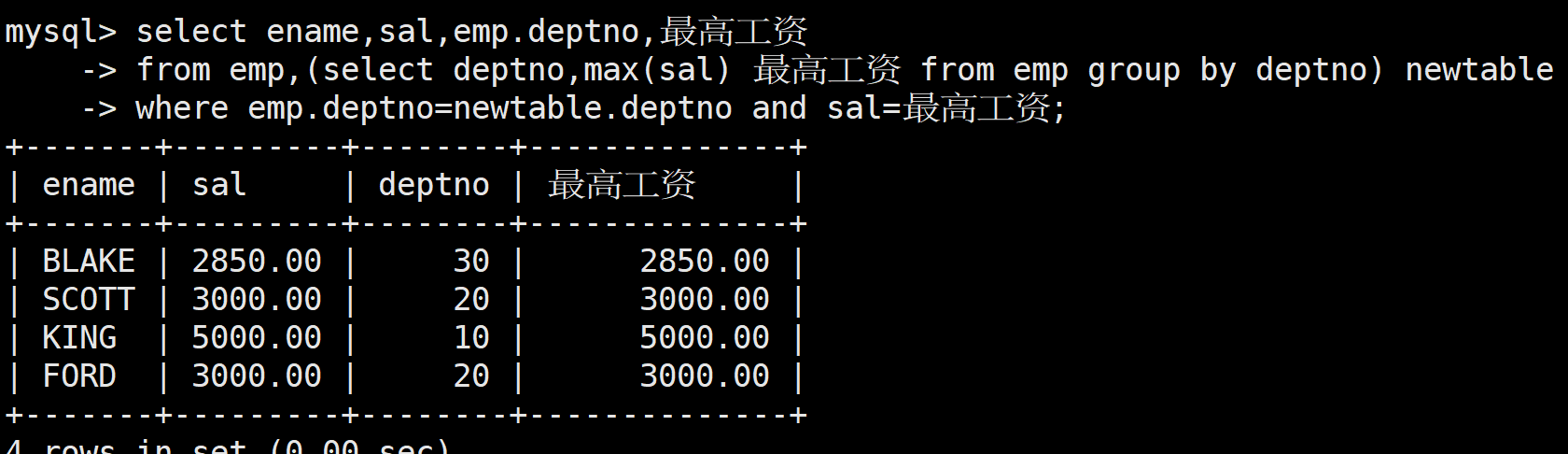
5、合并查詢:
為了合并多個select查詢結果,可以通過操作符union和union all進行合并查詢
union:
用于取得兩個查詢結果的并集,union會自動去掉結果集中的重復行
顯示工資大于2500或職位是MANAGER的員工
首先查詢工資大于2500員工:
select * from emp where sal>2500;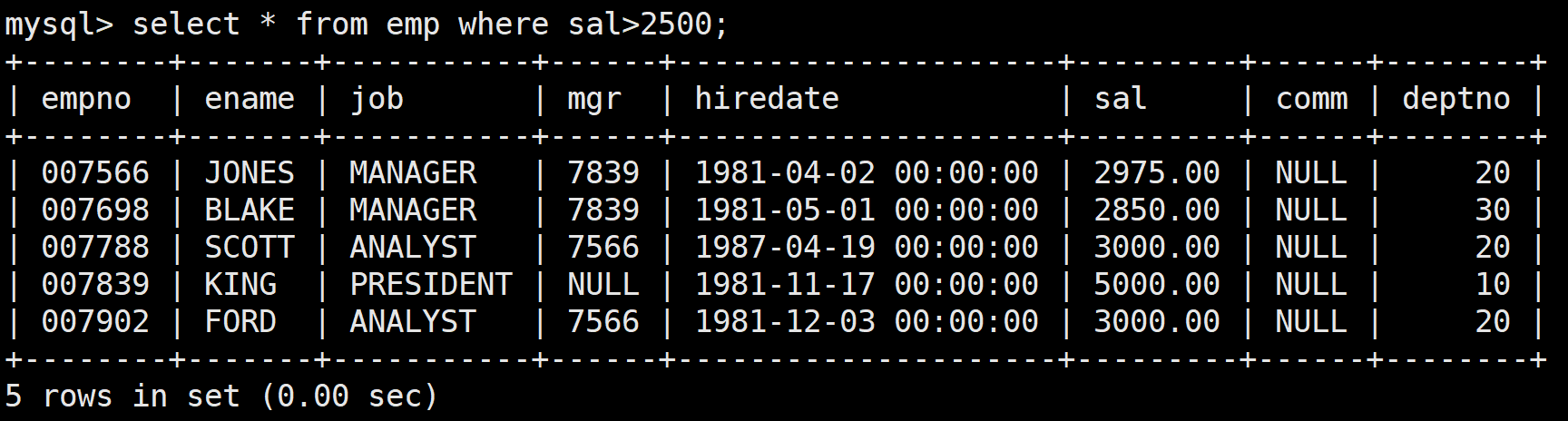
接著查詢職位是MANAGER的員工:
select * from emp where job='MANAGER';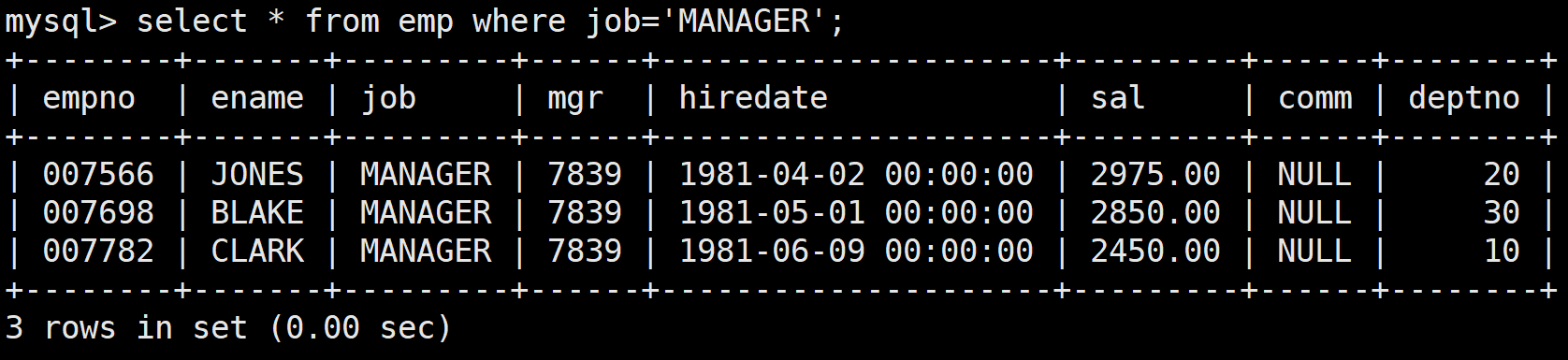
為了完成上述,可以使用or關鍵字:
select * from emp where sal>2500 or job='MANAGER';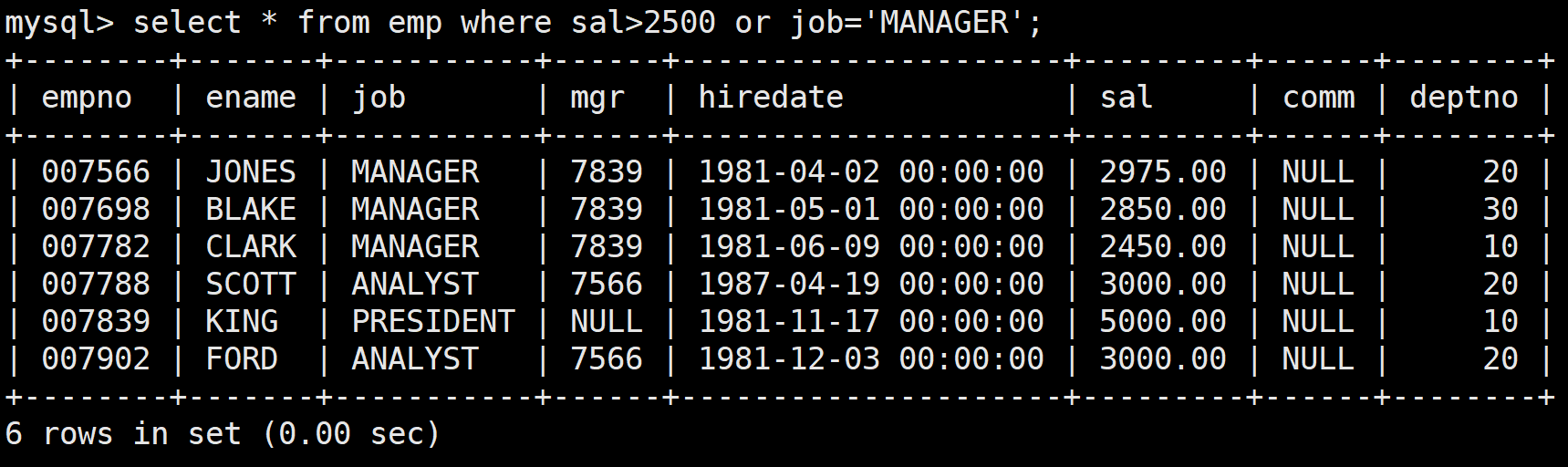
或者使用union關鍵字:
select * from emp where sal>2500 union select * from emp where job='MANAGER';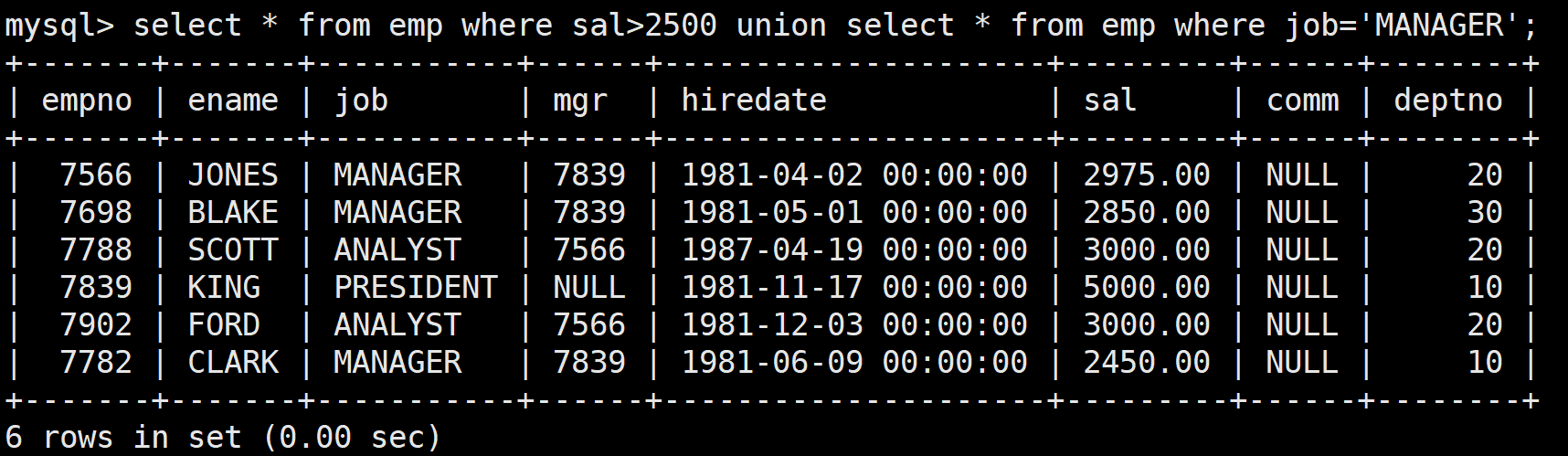
union all:
該操作符用于取得兩個結果集的并集,與union不同的是,這個不會對結果進行去重:
select * from emp where sal>2500 union all select * from emp where job='MANAGER';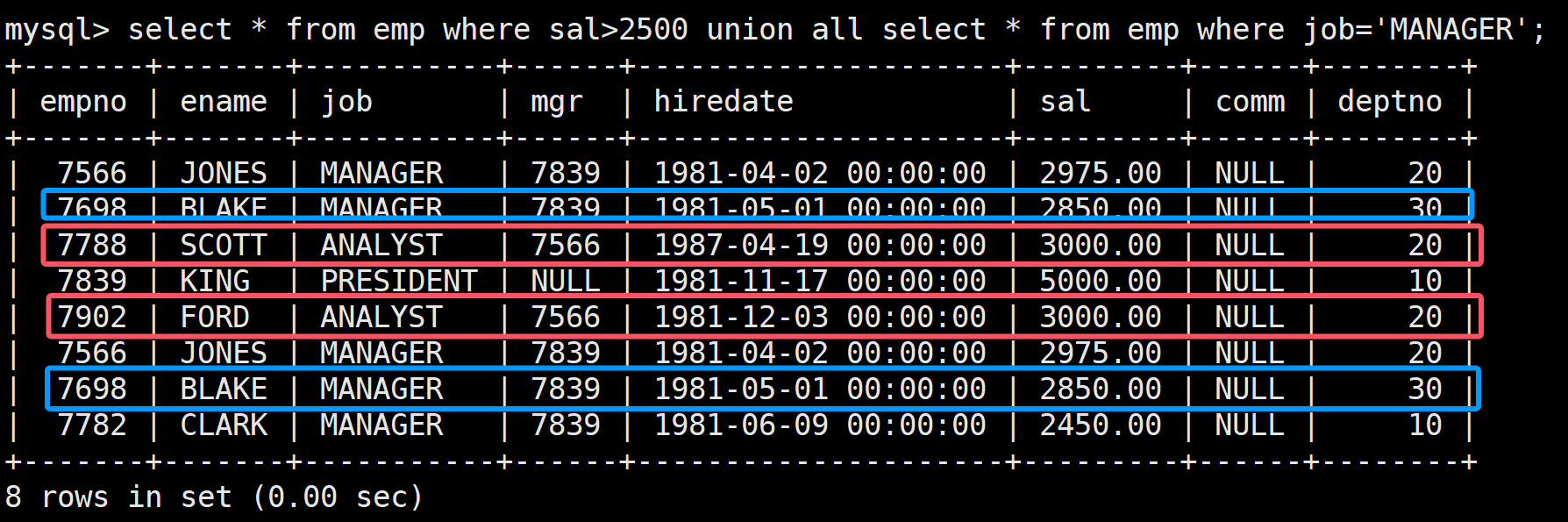
注意:待合并的兩個查詢結果的列的數量必須一致,否則無法合并
二、內外連接:
表的連接分為內連接和外連接
1、內連接:
內連接實際上就是利用where子句對兩種表形成的笛卡兒積進行篩選,我們前面學習的查詢都是內連接,也是在開發過程中使用的最多的連接查詢
語法:
select 字段 from 表1 inner join 表2 on 連接條件 and 其他條件;顯示 SMITH 的名字和部門名稱
其實完成上述查詢可以不使用內連接,用以前學習的已經夠了,只是內連接能夠讓我們的查詢邏輯更清楚
在上述的查詢中,我們可以使用以前學習的笛卡爾積
select emp.ename,dept.dname from emp,dept where emp.deptno=dept.deptno and emp.ename='SMITH';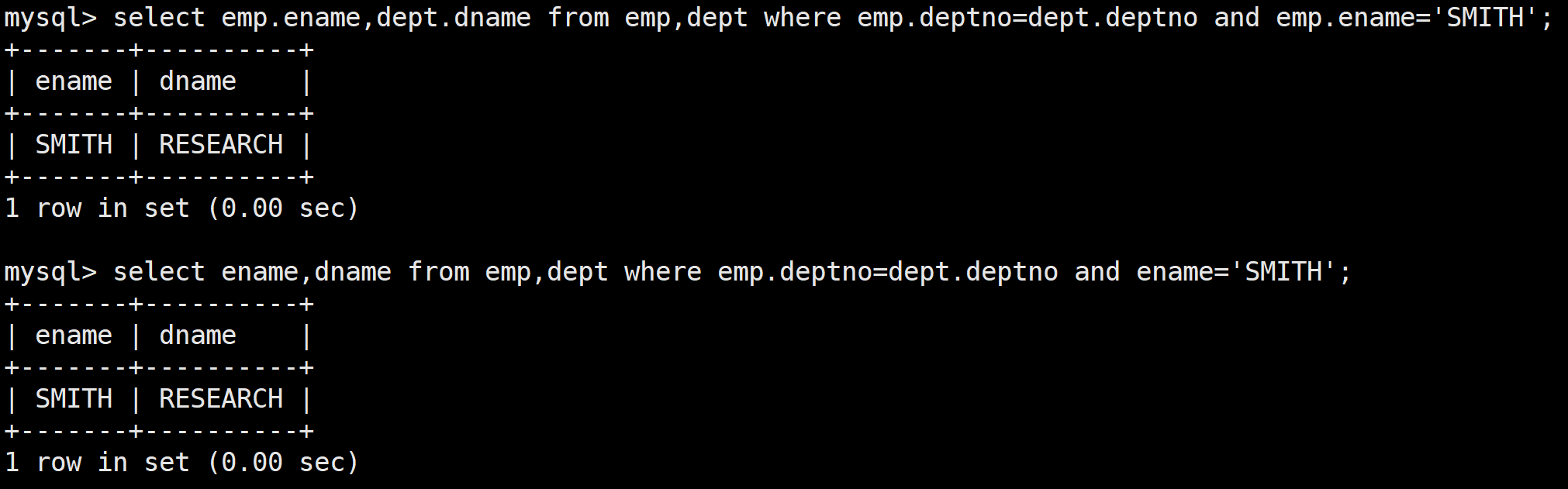
除了笛卡爾積這種寫的方式,我們還可以用內連接的寫法:
select ename,dname from emp inner join dept on emp.deptno=dept.deptno and ename='SMITH';
2、外連接:
左外連接:
如果想讓左側的表完全顯示,右側的表如果和左側的表沒有匹配的就去掉,就使用左外連接,其語法和內連接一模一樣只是將inner這個關鍵字修改為left
select 字段 from 表1 left join 表2 on 連接條件 and 其他條件;示例:
首先創建一個測試表:
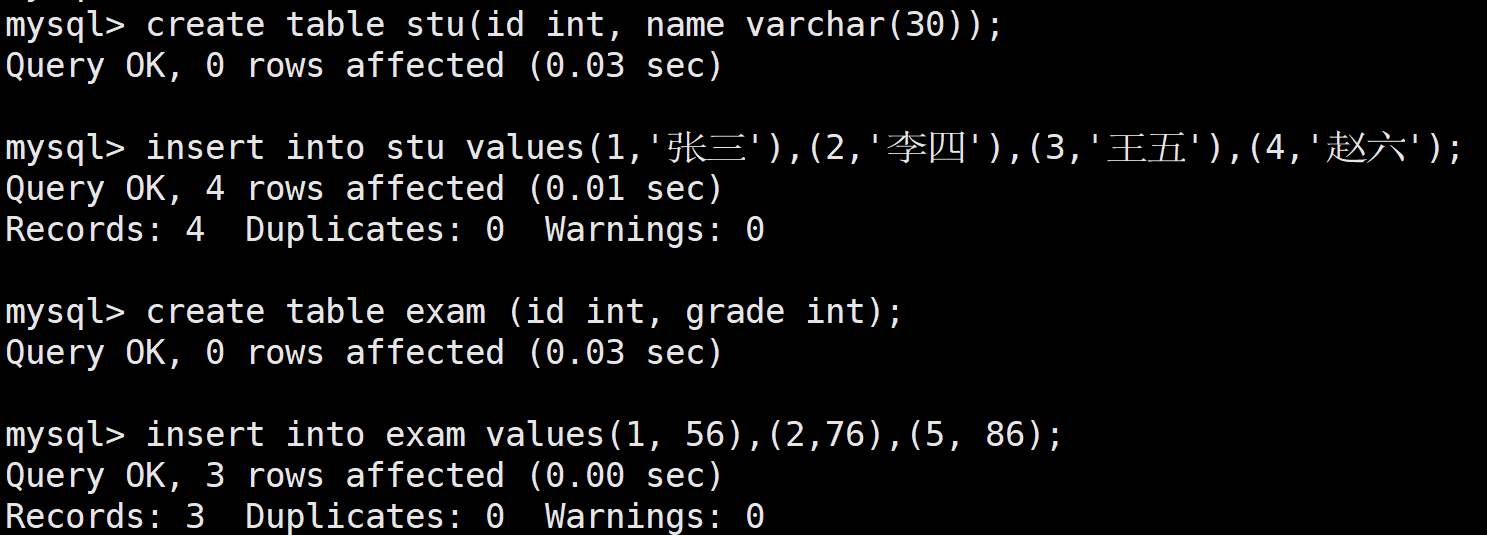
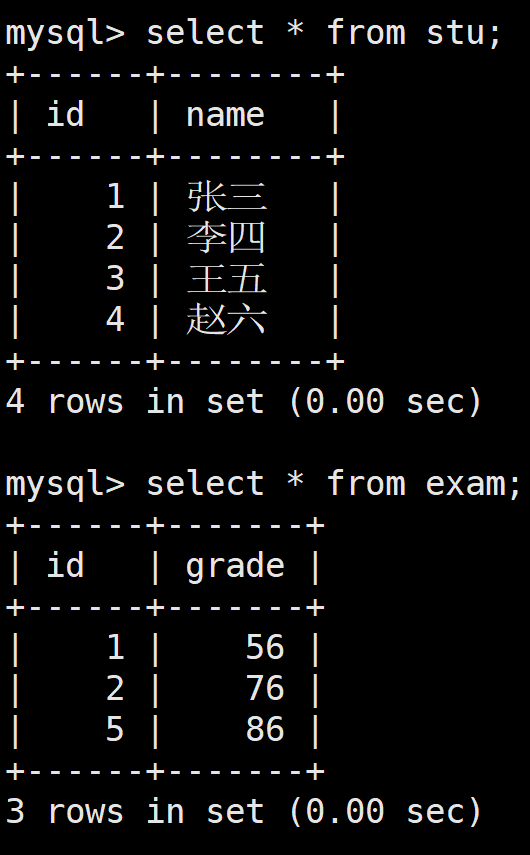
查詢所有學生的成績,如果這個學生沒有成績,也要將學生的個人信息顯示出來
select * from stu left join exam on stu.id=exam.id;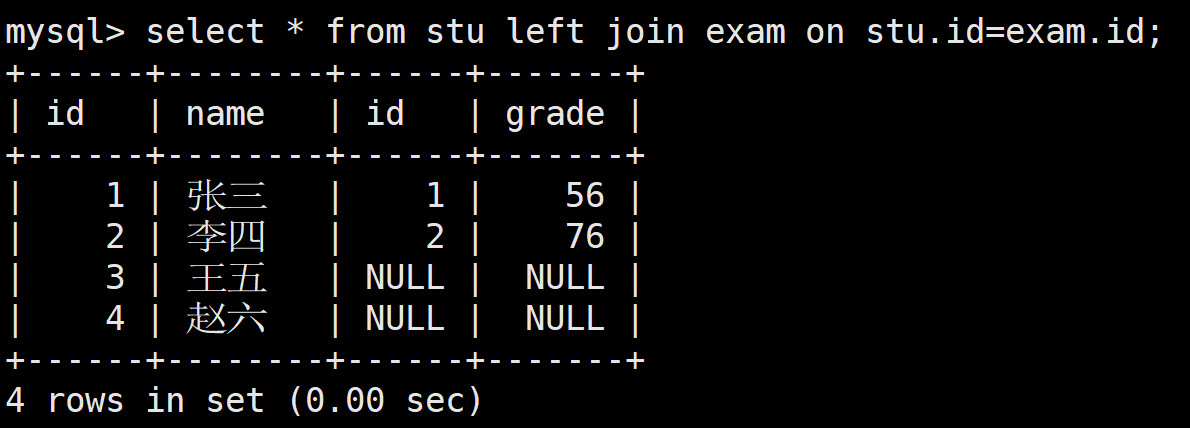
盡管在exam這個右側表中,沒有王五趙六的成績信息,但是他們仍然被顯示出來了,左連接更偏向于左邊的表
右外連接:
右外連接和左外連接就是相反的了,比如上述要求我們改為:
查詢所有成績,如果這個成績沒有對應的學生,也要將這個成績顯示出來
select * from stu right join exam on stu.id=exam.id;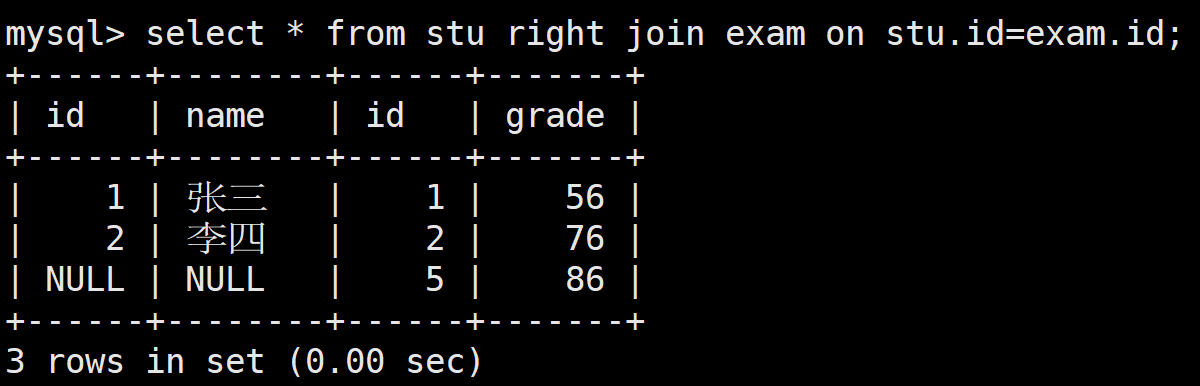
但事實上,左外連接和右外連接是可以相互轉換的
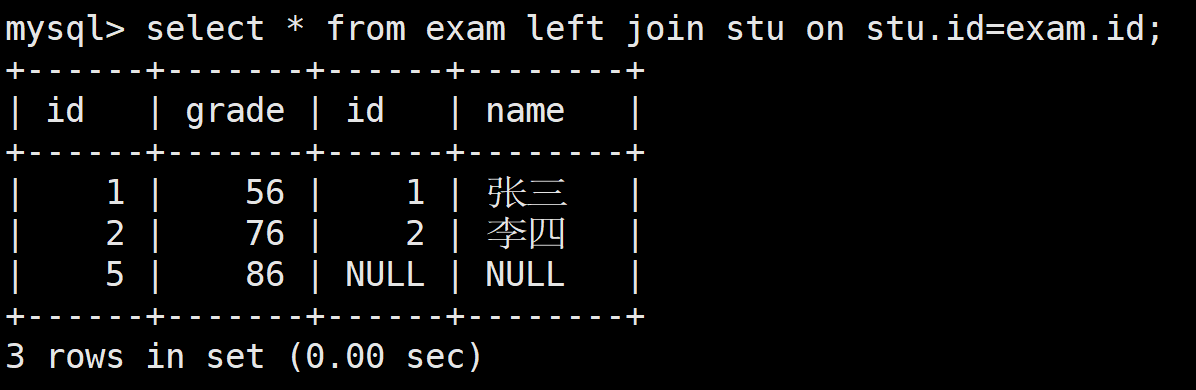



)




)


)
)






