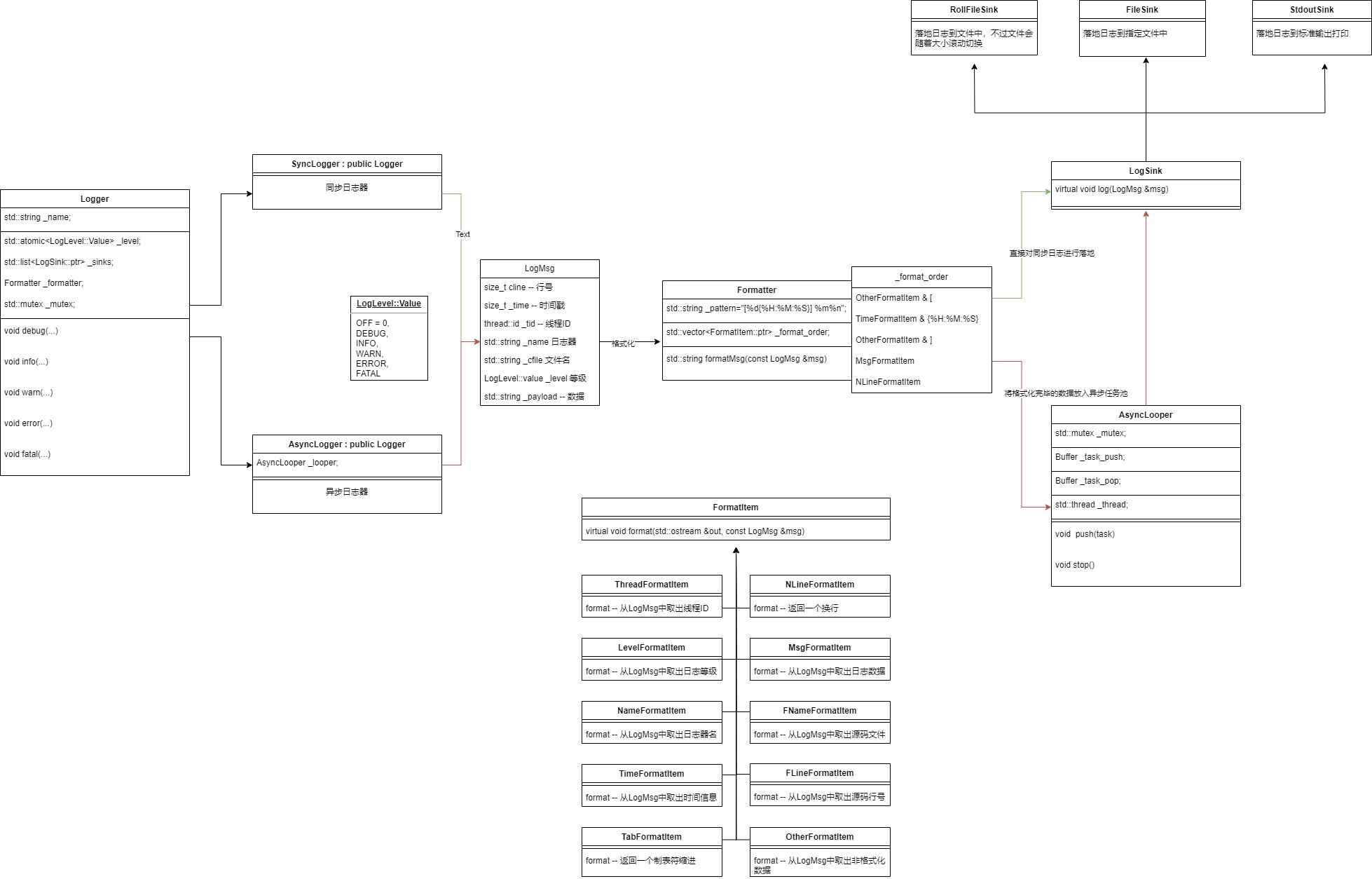
?志系統框架設計
1.?志等級模塊:對輸出?志的等級進?劃分,以便于控制?志的輸出,并提供等級枚舉轉字符串功能。
? OFF:關閉
? DEBUG:調試,調試時的關鍵信息輸出。
? INFO:提?,普通的提?型?志信息。
? WARN:警告,不影響運?,但是需要注意?下的?志。
? ERROR:錯誤,程序運?出現錯誤的?志
? FATAL:致命,?般是代碼異常導致程序?法繼續推進運?的?志
2.?志消息模塊:中間存儲?志輸出所需的各項要素信息
? 時間:描述本條?志的輸出時間。
? 線程ID:描述本條?志是哪個線程輸出的。
? ?志等級:描述本條?志的等級。
? ?志數據:本條?志的有效載荷數據。
? ?志?件名:描述本條?志在哪個源碼?件中輸出的。
? ?志?號:描述本條?志在源碼?件的哪??輸出的。
3.?志消息格式化模塊:設置?志輸出格式,并提供對?志消息進?格式化功能。
? 系統的默認?志輸出格式:%d{%H:%M:%S}%T[%t]%T[%p]%T[%c]%T%f:%l%T%m%n
? -> 13:26:32 [2343223321] [FATAL] [root] main.c:76 套接字創建失敗\n
? %d{%H:%M:%S}:表??期時間,花括號中的內容表??期時間的格式。
? %T:表?制表符縮進。
? %t:表?線程ID
? %p:表??志級別
? %c:表??志器名稱,不同的開發組可以創建??的?志器進??志輸出,?組之間互不影響。
? %f:表??志輸出時的源代碼?件名。
? %l:表??志輸出時的源代碼?號。
? %m:表?給與的?志有效載荷數據
? %n:表?換?
? 設計思想:設計不同的?類,不同的?類從?志消息中取出不同的數據進?處理。
4.?志消息落地模塊:決定了?志的落地?向,可以是標準輸出,也可以是?志?件,
也可以滾動?件輸出....
? 標準輸出:表?將?志進?標準輸出的打印。
? ?志?件輸出:表?將?志寫?指定的?件末尾。
? 滾動?件輸出:當前以?件??進?控制,當?個?志?件??達到指定??,則切換下?個?件進?輸出
? 后期,也可以擴展遠程?志輸出,創建客?端,將?志消息發送給遠程的?志分析服務器。
? 設計思想:設計不同的?類,不同的?類控制不同的?志落地?向。
5.?志器模塊:
? 此模塊是對以上?個模塊的整合模塊,??通過?志器進??志的輸出,有效降低??的使?難度。
? 包含有:?志消息落地模塊對象,?志消息格式化模塊對象,?志輸出等級
6.?志器管理模塊:
? 為了降低項?開發的?志耦合,不同的項?組可以有??的?志器來控制輸出格式以及落地?向,因此本項?是?個多?志器的?志系統。
? 管理模塊就是對創建的所有?志器進?統?管理。并提供?個默認?志器提供標準輸出的?志輸出。
7.異步線程模塊:
? 實現對?志的異步輸出功能,??只需要將輸出?志任務放?任務池,異步線程負責?志的落地輸出功能,以此提供更加?效的?阻塞?志輸出。
一.實用類設計
logs/util.hpp
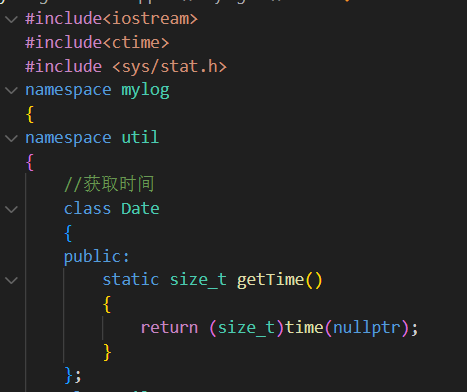
Date類
static size_t getTime()獲取當前時間(靜態函數)
File類
1.判斷文件是否存在
struct stat st;
stat是一個結構體(定義在<sys/stat.h>頭文件中)它會被用來存儲目標文件或目錄的各種信息
比如文件大小、權限、類型(是否是目錄)、最后訪問時間等
int stat(const char *pathname, struct stat *statbuf)?是一個系統調用函數????????獲取路徑 pathname 所指文件的信息,并存儲在 st 變量中
返回值 含義 0成功,說明文件/目錄存在并可訪問 ? 非 0失敗,說明文件/目錄不存在或無權限訪問 ? 2.提取文件路徑
3.遞歸創建多級目錄
找路徑分割符,沒找到說明已經到最底層的目錄了,直接創建目標目錄。
找到了判斷是否存在該目錄,沒有就該目錄創建。


#include<iostream>
#include<ctime>
#include <sys/stat.h>
namespace mylog
{
namespace util
{//獲取時間class Date{public:static size_t getTime(){return (size_t)time(nullptr);}};class File{public://1.判斷文件是否存在static bool exists(const std::string &pathname){struct stat st;//stat(...) 的返回值為:== 0:說明文件存在 != 0:說明文件不存在或無權限訪問return stat(pathname.c_str(),&st)==0;}//2.獲取這個文件所處的路徑static std::string path(const std::string &pathname){//./dir1/dir2/a.txtsize_t pos=pathname.find_last_of("/\\");//查找"/" "\"(windows下路徑分割符)if(pos==std::string::npos) return ".";return pathname.substr(0,pos+1);}//3.在指定路徑下創建目錄static void createDiretory(const std::string &pathname){//./dir1/dir2/dir3 ../dir3//pos 找 / 的位置 idx查找的起始位置size_t pos=0,idx=0;while(pos<pathname.size()){pos=pathname.find_first_of("/\\",idx);//沒找到 到目標路徑下了 直接創建if(pos==std::string::npos){//創建目錄mkdir(pathname.c_str(),0777);break;}//找到了 判斷父目錄是否存在 dir1/else{idx=pos+1; //pos指向/ +1跳過///不存在就創建 pos+1帶上/if(exists(pathname.substr(0,pos+1))==false)mkdir(pathname.substr(0,pos+1).c_str(),0777);}}}};
}
}二.日志等級類
logs/level.hpp
對輸出?志的等級進?劃分,以便于控制?志的輸出,并提供等級枚舉轉字符串功能。
#pragma once
namespace mylog
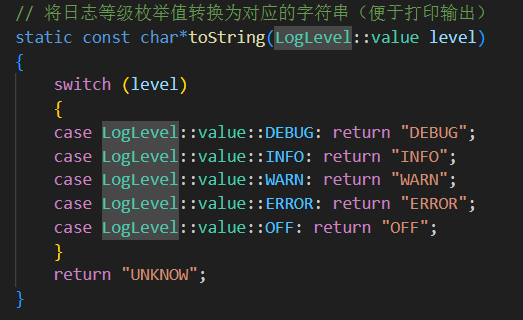
{class LogLevel{public:// 日志等級類,用于表示不同級別的日志輸出控制enum class value{UNKNOW = 0, // 未知等級DEBUG, // 調試信息INFO, // 正常運行的信息WARN, // 警告ERROR, // 錯誤OFF // 關閉日志輸出};// 將日志等級枚舉值轉換為對應的字符串(便于打印輸出)static const char*toString(LogLevel::value level){switch (level){case LogLevel::value::DEBUG: return "DEBUG";case LogLevel::value::INFO: return "INFO";case LogLevel::value::WARN: return "WARN";case LogLevel::value::ERROR: return "ERROR";case LogLevel::value::OFF: return "OFF";}return "UNKNOW";}};}三.日志消息類
message.hpp
在什么時間,那個組的日志器 哪個線程 哪個文件 具體在哪一行,什么等級的日志內容
字段名 類型 含義說明 _ctimesize_t日志創建的時間戳(秒),用于記錄日志生成的時刻 _levelLogLevel::value日志級別,例如 DEBUG/INFO/WARN/ERROR/OFF,用于日志過濾_linesize_t日志語句所在的代碼行號(一般宏傳入 __LINE__)_tidstd::thread::id當前線程的 ID,支持多線程日志追蹤 _filestd::string源文件名(一般傳入 __FILE__),幫助定位日志位置_loggerstd::string日志器名稱(如 "root"、"async_logger"),區分多個 logger _payloadstd::string實際日志內容(要輸出的文字)
#include<iostream>
#include<thread>
#include<string>
#include"level.hpp"
#include"util.hpp"namespace mylog
{struct LogMesg{size_t _ctime;//日志產生的時間戳LogLevel::value _level;//日志等級size_t _line;//行號std::thread::id _tid;//線程idstd::string _file;//文件名std::string _logger;//日志器名std::string _payload;//有效消息數據LogMesg(LogLevel::value level,size_t line,std::string file,std::string logger,std::string msg): _ctime(util::Date::getTime()),_level(level),_line(line),_tid(std::this_thread::get_id()),_file(file),_logger(logger),_payload(msg){}};}四.?志輸出格式化類
format.hpp
按照用戶給的格式/默認格式,把LogMsg里面的信息格式化放到對應的流中。
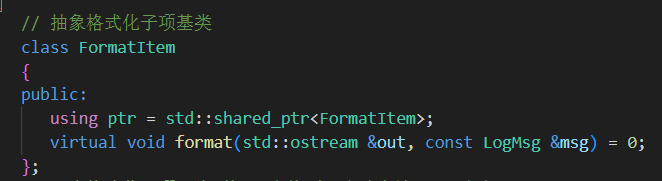
1. FormatItem(抽象基類)
抽象接口,定義日志格式子項的統一接口。
子類會重寫
format(),輸出指定字段內容。
2. 各種子類(繼承自 FormatItem)
不同子類重寫format函數,從LogMsg中取出對應的字段的內容輸出到對應的out流中。
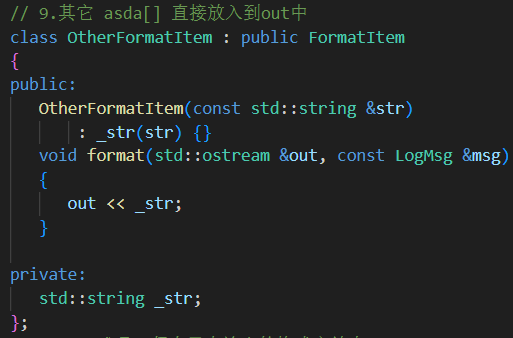
類名 輸出內容 LogMsg來源字段格式 MsgFormatItem日志正文內容 _payload%mLevelFormatItem日志等級 _level(轉為字符串)%pTimeFormatItem時間戳,支持自定義格式 _ctime%d{fmt}FileFormatItem源文件名 _file%fLineFormatItem行號 _line%lThreadFormatItem線程ID _tid%tLoggerFormatItem日志器名稱 _logger%cTabFormatItem制表符 \t無 %TNLineFormatItem換行符 \n無 %nOtherFormatItem原始字符串 構造傳入 _str非 %開頭字符
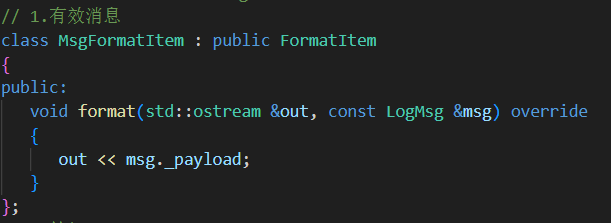
1.消息正文字段
取出消息字段直接輸出到out流中
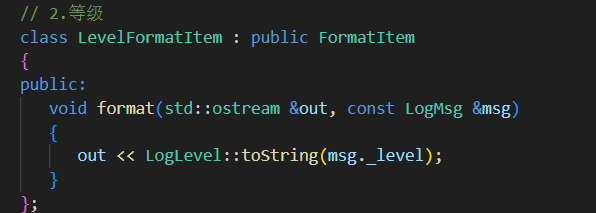
2.等級 調用LogLevel類中的靜態函數 把枚舉類value類型轉換為char*
?
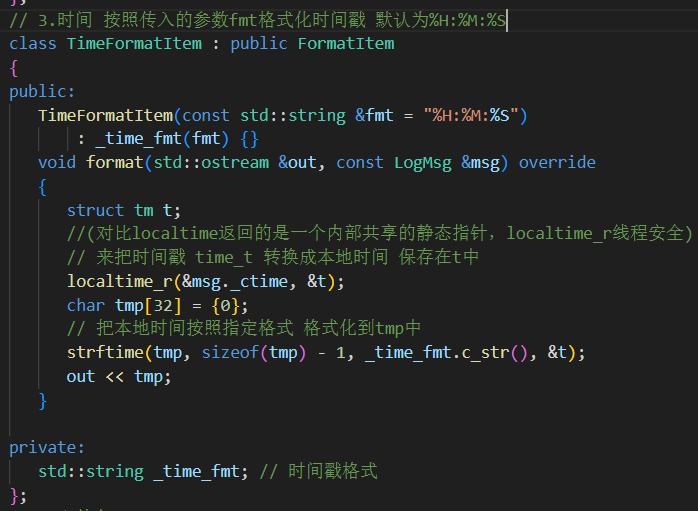
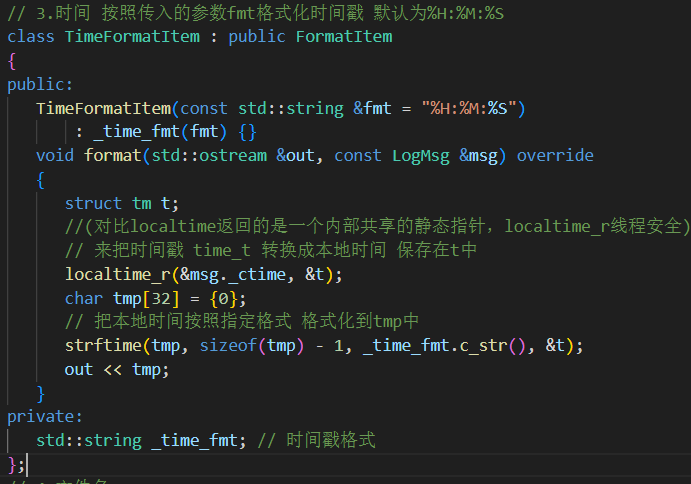
3.時間 可以傳入字符串fmt初始化該子類,表示需要打印的時間格式。
localtime():非線程安全
time_t raw = time(nullptr); struct tm* t = localtime(&raw);
它返回的是一個 指向靜態內存區域的指針。
這塊靜態內存通常是函數內部的一個全局變量或
static變量,在整個進程中只有一份共享的副本。每次調用
localtime(),這個內部的struct tm都會被重寫。localtime_r():線程安全
time_t raw = time(nullptr); struct tm t; localtime_r(&raw, &t);傳入用戶自己定義的
struct tm變量,不會發生數據覆蓋問題。
?其它子類...
// 派生格式化子項子類 從msg中找到對應消息放入out流中// 1.有效消息class MsgFormatItem : public FormatItem{public:void format(std::ostream &out, const LogMsg &msg) override{out << msg._payload;}};// 2.等級class LevelFormatItem : public FormatItem{public:void format(std::ostream &out, const LogMsg &msg){out << LogLevel::toString(msg._level);}};// 3.時間 按照傳入的參數fmt格式化時間戳 默認為%H:%M:%Sclass TimeFormatItem : public FormatItem{public:TimeFormatItem(const std::string &fmt = "%H:%M:%S"): _time_fmt(fmt) {}void format(std::ostream &out, const LogMsg &msg) override{struct tm t;//(對比localtime返回的是一個內部共享的靜態指針,localtime_r線程安全)// 來把時間戳 time_t 轉換成本地時間 保存在t中localtime_r(&msg._ctime, &t);char tmp[32] = {0};// 把本地時間按照指定格式 格式化到tmp中strftime(tmp, sizeof(tmp) - 1, _time_fmt.c_str(), &t);out << tmp;}private:std::string _time_fmt; // 時間戳格式};// 4.文件名class FileFormatItem : public FormatItem{public:void format(std::ostream &out, const LogMsg &msg){out << msg._file;}};// 5.行號class LineFormatItem : public FormatItem{public:void format(std::ostream &out, const LogMsg &msg){out << msg._line;}};// 5.線程idclass ThreadFormatItem : public FormatItem{public:void format(std::ostream &out, const LogMsg &msg){out << msg._tid;}};// 6.日志器名class LoggerFormatItem : public FormatItem{public:void format(std::ostream &out, const LogMsg &msg){out << msg._logger;}};// 7.Tabclass TabFormatItem : public FormatItem{public:void format(std::ostream &out, const LogMsg &msg){out << "\t";}};// 8.換行class NLineFormatItem : public FormatItem{public:void format(std::ostream &out, const LogMsg &msg){out << "\n";}};// 9.其它 asda[] 直接放入到out中class OtherFormatItem : public FormatItem{public:OtherFormatItem(const std::string &str): _str(str) {}void format(std::ostream &out, const LogMsg &msg){out << _str;}private:std::string _str;};3. Formatter 類(格式化核心)
這個類完成的功能就是,根據用戶指定的格式,格式化消息輸出到指定的流中。
比如說用戶傳入的格式是"dasd{}[%%[%d{%H:%M:%S}[%t][%c][%f:%l][%p]%T%m%n]"
先對格式化字符串的字符進行分類:
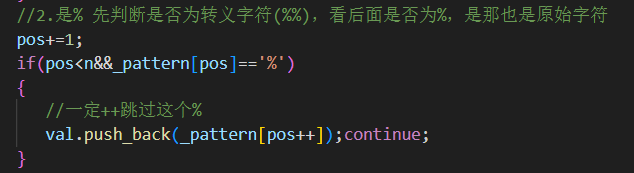
1.dasd{}[ 屬于原始字符2.%% 表示轉義% 屬于原始字符
3.%d d屬于格式化字符
4.格式化字符后面的{%H:%M:%S} 屬于格式化字符的子格式(“{}”也屬于)?
1.原始字符 就保持不動 (為了統一處理 原始字符串也是調用FormatItem子類輸出到流中)
2.格式化字符 就調用對應的FormatItem子類從LogMsg中取出對應的字段輸出到流中。
字段的輸出順序就是用戶傳入的格式從左向右的順序,我們可以用一個vecotr<FormatItem::ptr>按順序保存需要調用的子類,再遍歷vecotr數組完成格式化。
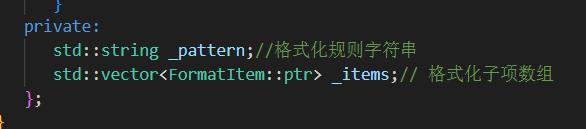
1.構造函數
用戶傳入 格式化規則字符串 初始化_pattern
并完成字符串解析 assert()強斷言
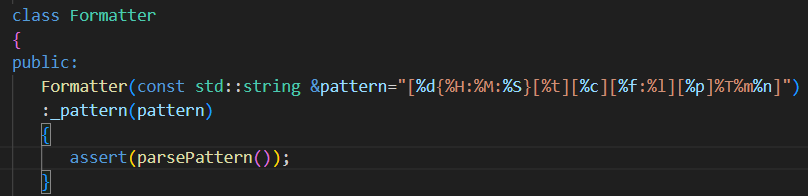
2.createrItem()根據不同的格式化字符?創建不同的子類對象
key格式化字符 val其子格式({ }以及里面的字符串)? 或者key=="" val代表原始字符[ ]adc
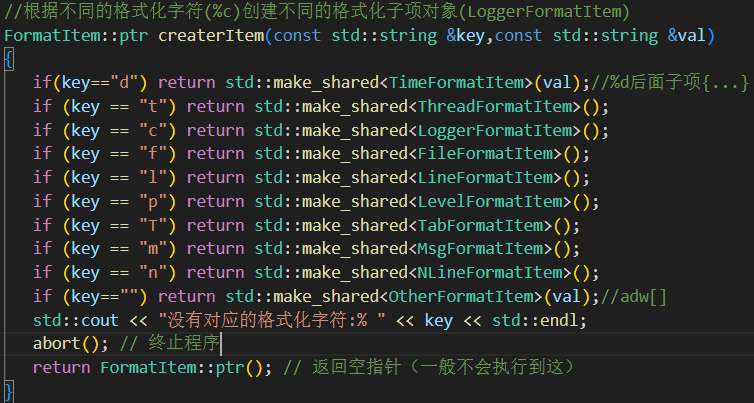
3.bool parsePattern()?對格式化字符串進行解析,將需要調用的子類保存到vector數組中
流程:
輸入字符串: [%d{%H:%M:%S}][%p]%T%m%nHello【第一階段】解析成:("", "[")("d", "%H:%M:%S")("", "][")("p", "")("T", "")("m", "")("n", "")("", "Hello")【第二階段】根據 key 構建對應的 FormatItem 子類
fmt_order: 暫存格式化字符(key)與其子格式(val)的列表
key: 當前格式化符號(如d)
val: 當前格式化符的子格式(如%H:%M:%S),或原始非格式化文本
pos: 當前掃描位置1.非 % 字符 → 原始字符原樣收集?("", "[") key=="" val+=[
2.%% → 視為轉義的 %當作原始字符原樣收集?("", "%")
3.%x → %后面是格式化字符?
????????1.如果val中保存有原始字符 就先放入數組vector中,并clear()為后面保存格式化字符的子格式(如
%H:%M:%S)作準備。????????2.給key賦值 保存當前的轉義字符是什么
????????原始字符后面對應的子類
4.判斷格式化字符是否有 {} 子格式 eg.%d{%H:%M:%S} → key = d,val = {%H:%M:%S}
如果找到最后都沒找到與之匹配的 } 說明子規則{}匹配錯誤 返回false
注意此時{ }也被保存到了val中,但這并不影響后面格式的輸出,后面調用對應子類,fmt=val,向流中輸出時也會帶上{ }。所以前面說格式化字符后面的“{}”也屬于子格式,不當作原始字符處理。
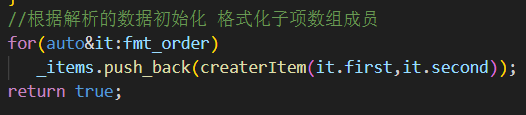
5.保存解析結果?解析完一組 %x{子格式} 或 %x 后,放入 fmt_order
6.字符串解析完 生成格式化項對象?
每組 key/val 通過
createrItem()構建出具體的FormatItem派生類實例,如:
%d{}→TimeFormatItem
%p→LevelFormatItem
%m→MsgFormatItem
"["→OtherFormatItem

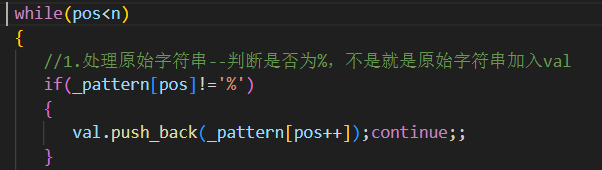


示例分析:[%d{%H:%M:%S}][%p]%T%m%nHello
Step1:fmt_order 內容
[("", "["),("d", "%H:%M:%S"),("", "]["),("p", ""),("T", ""),("m", ""),("n", ""),("", "Hello") ]Step2:生成 _items 內容
[OtherFormatItem("["),TimeFormatItem("%H:%M:%S"),OtherFormatItem("]["),LevelFormatItem(),TabFormatItem(),MsgFormatItem(),NLineFormatItem(),OtherFormatItem("Hello") ]
4.format()
逐個遍歷 _items(每個 item 是 FormatItem 的子類,如 TimeFormatItem、MsgFormatItem 等),每個 item 都負責從 LogMsg 提取對應的信息并寫入 out。
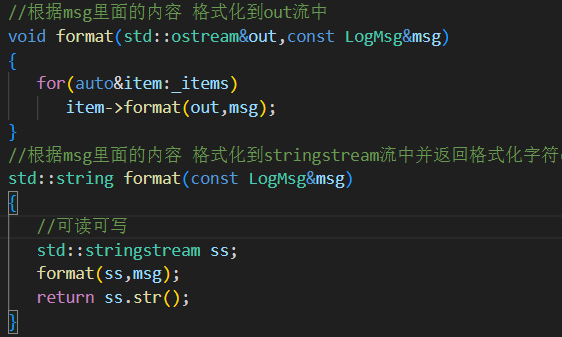
五.?志落地(LogSink)類設計(簡單??模式)
sink.hpp
把日志“落地”(寫入)的位置抽象出來,使得用戶可以靈活指定日志寫到哪里(控制臺?文件?滾動文件?)。同時使用簡單工廠模式簡化使用方式,提升靈活性與擴展性。
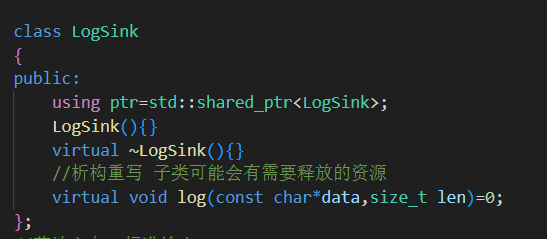
1.LogSink 抽象類設計
定義日志落地的統一接口:只需要實現
log()方法即可。所有具體的日志落地方式都繼承自它,符合面向接口編程原則。
使用
shared_ptr管理對象生命周期,便于在異步或多線程中使用。
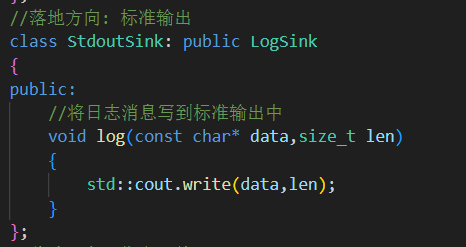
2.三種落地方式的實現
1. 控制臺輸出:StdoutSink
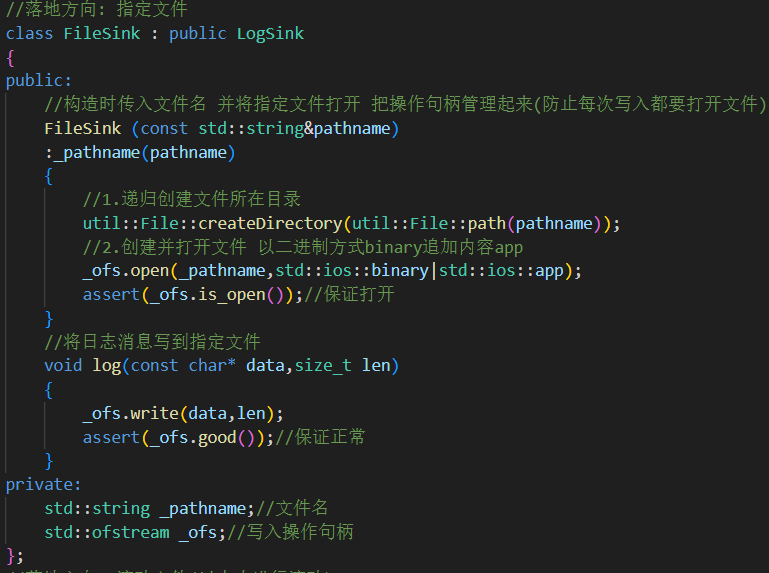
2. 固定文件輸出:FileSink
1.初始化傳入目錄路徑+文件名? ? ? ?
createDirectory(path()) path()取出目錄路徑再進行遞歸創建 ? createDirectory確保目錄路徑存在。open()再在對應路徑下創建指定文件名(如果不存在)并打開。
3. 按大小滾動輸出:RollBySizeSink
文件過大自動滾動,新建文件。
使用時間戳 + 自增后綴保證文件名不重復。
怎么判斷需新建文件?
用_cur_fsize記錄當前文件的大小,如果超過限制的最大文件大小就新建,注意更新_cur_fsize=0,以及關閉原文件寫。
怎么確保新建的文件名不重復?
文件名=base文件名+時間戳(精確到秒)+自增數(新建一個文件++)
這樣即使一秒創建兩個文件,也不用擔心會重復。
//落地方向: 滾動文件(以大小進行滾動)class RollBySizeSink: public LogSink{public:RollBySizeSink(const std::string &basename,const size_t max_size): _basename(basename),_max_fsize(max_size),_cur_fsize(0),_name_count(0){//獲取文件所處的路徑+文件名std::string pathname=createNewFile();// 1.遞歸創建文件所在目錄util::File::createDirectory(util::File::path(pathname));// 2.創建并打開文件_ofs.open(pathname, std::ios::binary | std::ios::app);assert(_ofs.is_open()); // 保證打開}//將日志消息寫到滾動文件中void log(const char* data,size_t len){//超出大小 新建文件if(_cur_fsize>=_max_fsize){//一定要先關閉原文件 防止資源泄漏_ofs.close();_cur_fsize=0;_ofs.open(createNewFile(),std::ios::binary|std::ios::app);assert(_ofs.is_open()); }_ofs.write(data,len);assert(_ofs.good());_cur_fsize+=len;}private://獲取新文件名std::string createNewFile(){//獲取以時間生成的文件名time_t t=util::Date::now();struct tm lt;localtime_r(&t,<);std::stringstream ss;ss<<_basename;ss<<lt.tm_year+1900;ss<<lt.tm_mon+1 ;ss<<lt.tm_mday;ss<<lt.tm_hour;ss<<lt.tm_min;ss<<lt.tm_sec;ss<<'-';ss<<_name_count++;ss<<".log";return ss.str();}private://文件名=基礎文件名+擴展文件名(以時間生成) std::string _basename;//./logs/base-20250421203801 準確到秒size_t _name_count;//防止一秒內生成的文件名重復std::ofstream _ofs;size_t _max_fsize;//文件最大大小size_t _cur_fsize;//當前文件大小 };4. 按時間滾動輸出:RollByTimeSink
枚舉類
TimeGap表示間隔(秒、分、小時、天)。日志會按時間粒度自動切分,比如每分鐘一個文件。
比大小滾動更適合做按時歸檔(日志分析、ELK 系統對接等)。
怎么判斷需要新建文件?
我們是根據時間段進行劃分文件的,比如說我們以 1 分鐘進行劃分,時間段的大小就是60秒,time(NULL)/60 算出來當前時間戳屬于第幾個時間段。初始化時先保存當前時間戳屬于第幾個時間段,每次寫入時再判斷時間段是不是變化了?變化了就,新建并更新當前保存的時間段。
定義一個枚舉類來表示 一個時間段的大小
//時間間隔 枚舉類enum class TimeGap{GAP_SECOND=1,GAP_MINUTE=60,GAP_HOUR=3600,GAP_DAY=3600*24};//落地方向: 滾動文件(以時間為間隔進行滾動)class RollByTimeSink: public LogSink{public:RollByTimeSink(const std::string &basename,const TimeGap gap_type): _basename(basename),_gap_type((size_t)gap_type){//獲取文件所處的路徑+文件名std::string pathname=createNewFile();// 1.遞歸創建文件所在目錄util::File::createDirectory(util::File::path(pathname));_cur_gap=(time(NULL)/_gap_type);//獲取當前是第幾個時間段// 2.創建并打開文件_ofs.open(pathname, std::ios::binary | std::ios::app);assert(_ofs.is_open()); // 保證打開}//將日志消息寫到滾動文件中void log(const char* data,size_t len){//出現新的時間段size_t new_gap=((time(NULL)/_gap_type));if(_cur_gap!=new_gap){//一定要先關閉原文件 防止資源泄漏_ofs.close();_cur_gap=new_gap;//更新當前時間段_ofs.open(createNewFile(),std::ios::binary|std::ios::app);assert(_ofs.is_open()); }_ofs.write(data,len);assert(_ofs.good());}private://獲取新文件名std::string createNewFile(){//獲取以時間生成的文件名time_t t=util::Date::now();struct tm lt;localtime_r(&t,<);std::stringstream ss;ss<<_basename;ss<<lt.tm_year+1900;ss<<lt.tm_mon+1 ;ss<<lt.tm_mday;ss<<lt.tm_hour;ss<<lt.tm_min;ss<<lt.tm_sec;ss<<".log";return ss.str();}private:std::string _basename;std::ofstream _ofs;size_t _gap_type;//時間段大小size_t _cur_gap;//當前是第幾個時間段};3.簡單工廠類 SinkFactory
利用函數模板和完美轉發創建任意
LogSink子類對象。解耦日志使用者與具體實現,符合開放封閉原則。
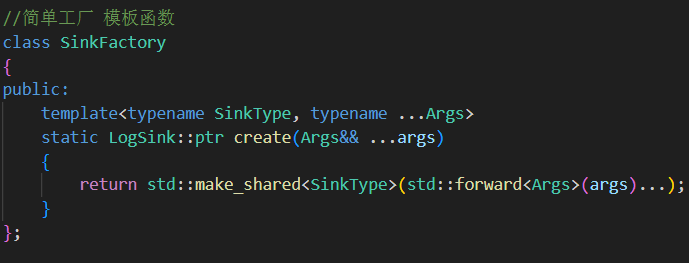
類中定義一個靜態的模板函數,不要寫成模板類,因為可變參數是給create函數的,不是給類的。
六.?志器類(Logger)設計(建造者模式)
logger.hpp
?志器主要是?來和前端交互, 當我們需要使??志系統打印log的時候, 只需要創建Logger對象,調?該對象debug、info、warn、error、fatal等?法輸出??想打印的?志即可,?持解析可變參數列表和輸出格式, 即可以做到像使?printf函數?樣打印?志。
當前?志系統?持同步?志 & 異步?志兩種模式,兩個不同的?志器唯?不同的地?在于他們在?志的落地?式上有所不同:
同步?志器:直接對?志消息進?輸出。
異步?志器:將?志消息放?緩沖區,由異步線程進?輸出。
因此?志器類在設計的時候先設計出?個Logger基類,在Logger基類的基礎上,繼承出SyncLogger同步?志器和AsyncLogger異步?志器。
且因為?志器模塊是對前邊多個模塊的整合,想要創建?個?志器,需要設置?志器名稱,設置?志輸出等級,設置?志器類型,設置?志輸出格式,設置落地?向,且落地?向有可能存在多個,整個?志器的創建過程較為復雜,為了保持良好的代碼?格,編寫出優雅的代碼,因此?志器的創建這?采?了建造者模式來進?創建。
1.Logger類
Logger 類主要負責記錄日志消息并將其輸出到指定的目標(如文件、控制臺)。其構造函數接收日志名稱、日志級別、格式化器以及落地方向(LogSink):
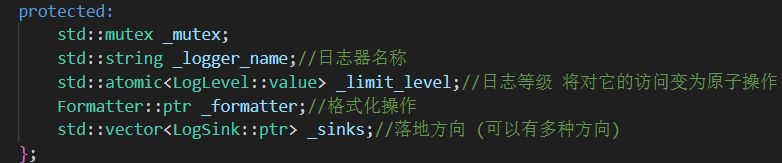
每次我們調用Logger里面函數進行日志輸出時,要判斷當前傳入的日志是否>=限制的日志等級,只有>=才能進行日志輸出。
因此我們保證對日志等級_limit_level的訪問操作必須是原子性的,不能在訪問的過程中被其它線程進行修改。
怎么保證對該變量的操作是原子性的?
std::atomic可以應用于不同的基本類型,如整數、指針、布爾值等。它的作用是提供一種方式來保證對這些類型的訪問是 線程安全的,不需要顯式的互斥鎖。
1.構造函數
2.日志記錄方法
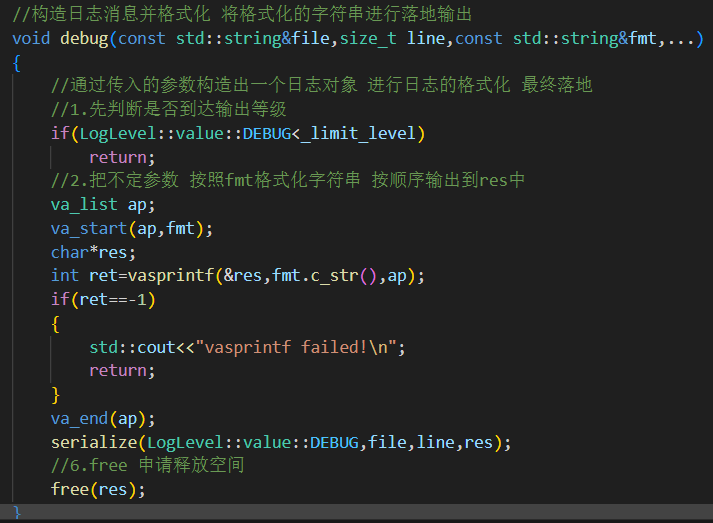
Logger類中定義了多個日志記錄方法:debug、info、warn、error、fatal,它們接收文件名、行號、格式化字符串和可變參數。所有這些方法都遵循相似的邏輯:
檢查日志級別:首先判斷當前日志級別是否符合輸出條件,如果不符合則直接返回,不進行日志記錄。
格式化日志消息:使用
vasprintf將可變參數格式化成日志消息字符串。調用
serialize方法:serialize方法將格式化后的日志消息封裝成LogMsg對象,然后通過指定的格式化器對消息進行格式化,并最終輸出到日志目標。eg.debug等級日志輸出
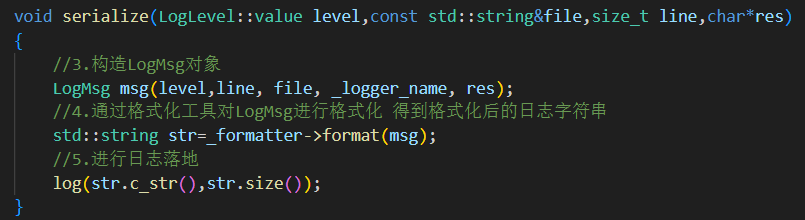
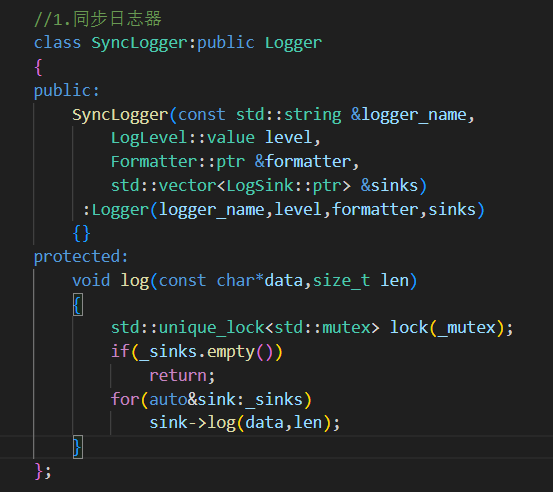
3.具體向哪里輸出 log() 由繼承的子類日志器(同步 異步)完成

1.SyncLogger 同步日志器類
根據傳入的參數初始化Logger日志器
1.先保證落地方向存在
2.遍歷落地方向 一個一個打印日志進行輸出
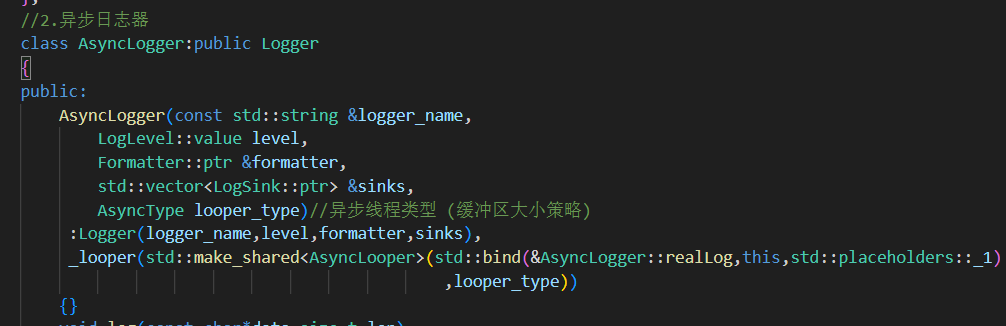
2.AsyncLogger異步日志器類
繼承 Logger,重寫了 log() 方法,實現了異步寫入。
1.構造
創建了異步線程對象
_looper,傳入一個回調realLog();當異步線程從緩沖區中取出日志后,會自動調用
realLog(buf)寫入文件。
2.log 只向緩沖區中寫入數據
主線程只寫入緩沖區(非阻塞、線程安全);
具體向哪里?I/O 寫入交由
AsyncLooper在線程中處理。
3.realLog?
異步線程中處理緩沖區數據的具體邏輯,將內存緩沖區中的日志數據寫入到所有配置的落地目標中

2.LoggerBuilder 類(建造者模式)
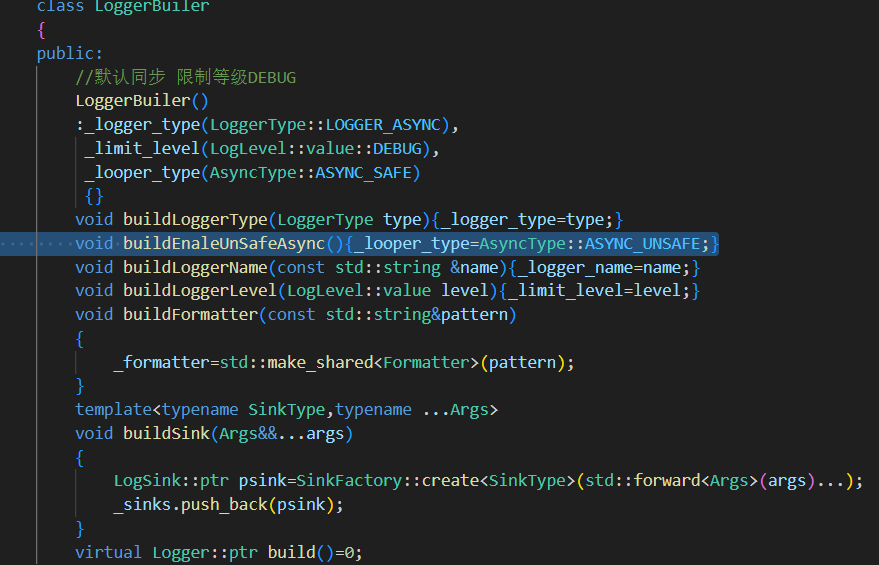
使用建造者模式來構造日志器 不讓用戶一個個構造成員變量再構造日志器
1.抽象一個日志器建造者類 (完成日志器對象所需零部件的構建&&日志器的構建)
? ? ? ? 1.設置日志器類型(異步 同步)
? ? ? ? 2.將不同的日志器的創建放到同一個日志器構建者類中完成
2.派生出具體的構造者類 ?局部日志器的構造者&全局的日志器構造者
構建對應成員遍歷的build__函數
在LoggerBuiler進行初始化時完成對日志器類型 日志限制等級的默認構造 異步線程緩沖區的策略(緩沖區大小是否固定,默認固定)
具體創建Logger日志器并返回的build函數,由其子類完成。
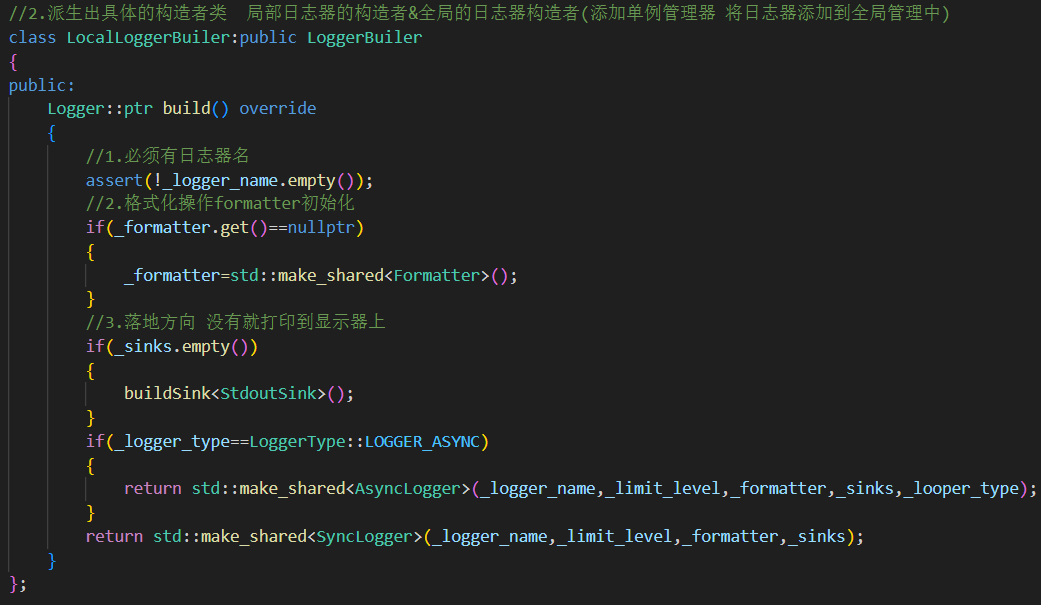
1.LocalLoggerBuiler 局部(本地)日志器類
日志器名稱必須有,格式化操作 落地方向可以給默認值
使用方法:
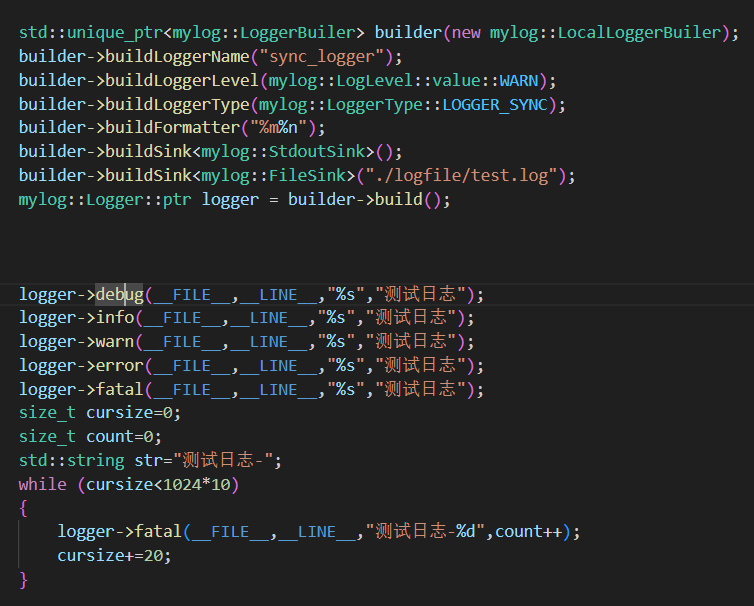
2.GlobalLoggerBuilder全局日志器類
全局日志器其實就是用單例對象管理的局部日志器。單例對象延長了日志器的生命周期,通過獲取單例對象查找里面對應的日志器,進行操作。
關鍵詞 含義 局部日志器 是指通過 LoggerBuilder(尤其是LocalLoggerBuilder)手動創建、管理的日志器實例全局日志器 是指通過 GlobalLoggerBuilder創建,并自動注冊到單例 LoggerManager 中的日志器單例對象 LoggerManager是懶漢模式的全局單例,統一管理所有日志器,提供注冊/查找接口本質 所有日志器(無論本地創建或全局注冊)最終其實都是 Logger實例,只是有沒有放入LoggerManager的_loggers容器里
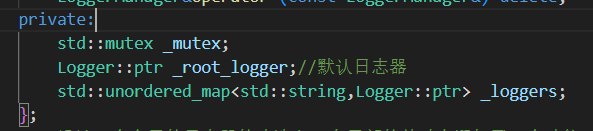
LoggerManager日志器管理類 (懶漢模式)
項目 說明 類型 單例類(懶漢式,局部靜態變量) 主要作用 統一管理所有日志器,包括 root 日志器和自定義日志器 核心功能 創建默認 root 日志器、添加日志器、查詢日志器、獲取日志器 線程安全性 采用 std::mutex加鎖保護_loggers容器
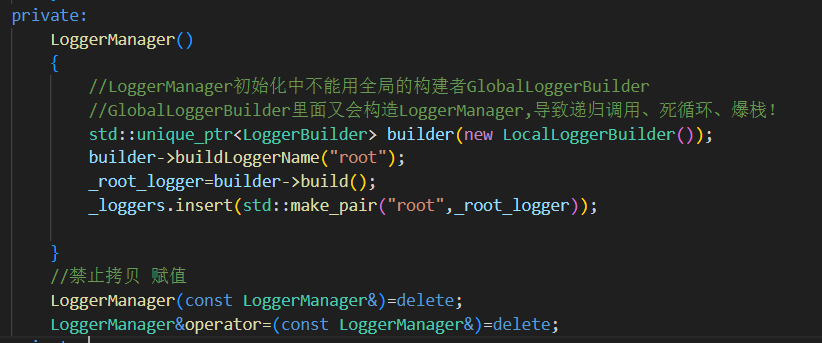
構造函數
在
LoggerManager構造時,創建了一個 root 日志器。使用 LocalLoggerBuilder,避免遞歸調用(GlobalLoggerBuilder里面又會構造LoggerManager,導致遞歸調用)。
直接 insert 到
_loggers,保證程序最初始至少有一個可用日志器。
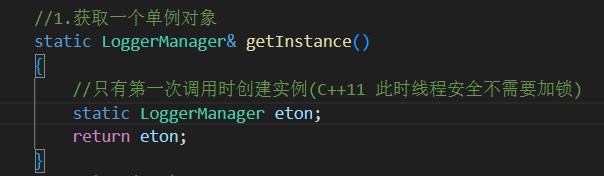
static LoggerManager& getInstance()
采用 C++11 之后線程安全的局部靜態變量初始化機制
懶漢模式(第一次用到時再初始化)
線程安全,不會因為多線程導致多次創建
addLogger(Logger::ptr& logger)
加鎖保護
_loggers將 logger 插入
_loggers映射表中注意:因為在持鎖狀態下又調用了 hasLogger(),原來存在死鎖風險,所以注釋掉了 hasLogger()調用,改為直接 insert
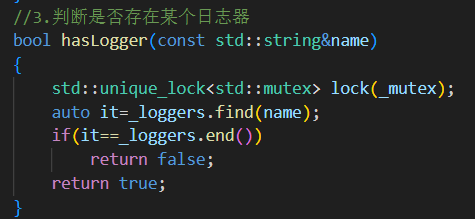
hasLogger(const std::string& name)
單獨加鎖判斷
_loggers中是否存在某名字注意:如果在 addLogger 內部調用,需要避免加鎖兩次問題(最好解耦鎖邏輯)
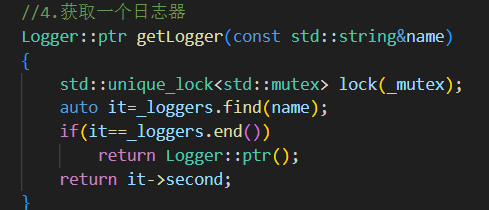
getLogger(const std::string& name)
加鎖安全地查詢并返回 logger
如果找不到,返回空指針
Logger::ptr()
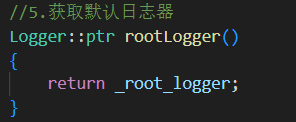
rootLogger()
返回默認的 root 日志器
root 是程序啟動時創建的,名字為
"root"

GlobalLoggerBuilder
項目 說明 類型 日志器構建器(Builder模式) 主要作用 幫助用戶構建自定義日志器,并自動注冊到 LoggerManager 特點 build()后不僅返回日志器,還自動 addLogger 線程安全性 依賴 LoggerManager 內部加鎖
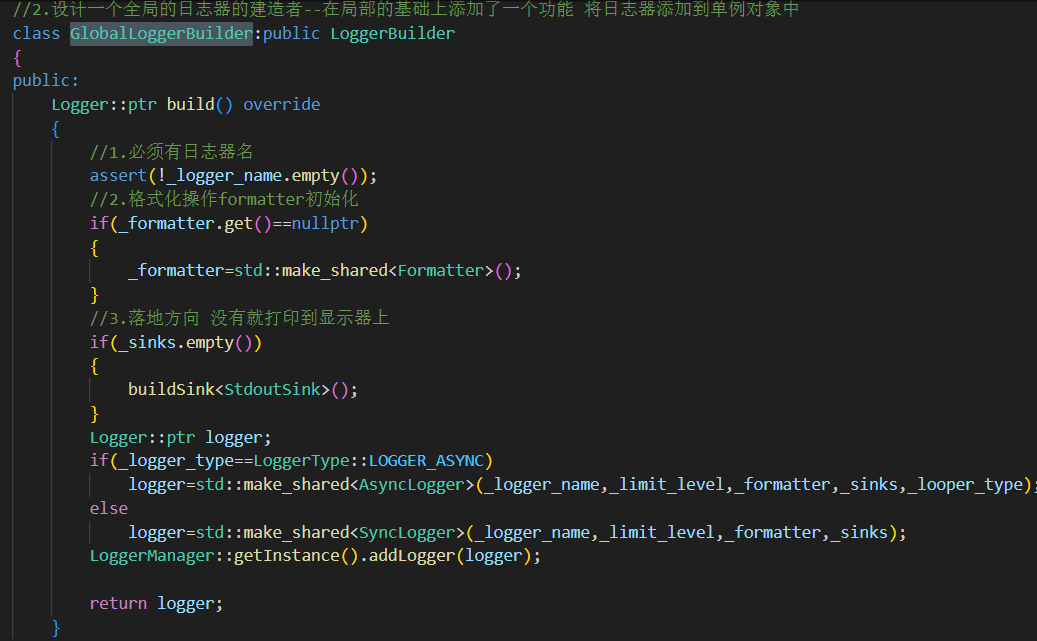
Logger::ptr build() override
校驗日志器名字不為空
如果沒有設置 formatter,默認使用一個新建 formatter
如果沒有設置 sinks,默認加一個 StdoutSink
根據同步/異步選擇創建 SyncLogger 或 AsyncLogger
構建完成后,注冊到 LoggerManager 單例中
返回 logger 指針,方便外部繼續操作
七.異步工作器設計
1. 為什么要異步輸出日志消息?
問題:
同步輸出(例如
send()、write())一旦對端或磁盤緩沖區滿了會阻塞主線程。頻繁系統調用開銷大,影響主線程性能。
解決:
業務線程僅負責將日志寫入內存緩沖區(生產者角色)。
另有專屬異步線程負責將日志落地(寫文件、send到網絡等),主線程立刻返回,不阻塞。
避免主線程陷入IO,提升系統吞吐量與響應能力。
通常一個日志器對應一個異步處理線程,再多反而浪費系統資源(尤其CPU與上下文切換成本)。
2. 緩沖區存儲結構用什么?
隊列,因為先進入的消息要先處理.
3. 每次寫入/讀取都申請釋放內存效率太低?
?問題:
new/delete太頻繁,容易導致內存碎片與系統開銷。?解決:
提前申請一整塊連續內存,作為環形緩沖區或雙緩沖區的底層存儲空間。
用
_read_index和_write_index控制寫入/讀取位置,復用空間而不頻繁分配。
4.業務線程寫數據相當于生產者 異步處理線程取數據相當于消費者,寫數據取數據每次進入緩沖區都需要加鎖,太過于頻繁怎么辦? 先分析一下,生產者會有多個線程 而消費者一般一個日志器對應一個,所以主要是生產者和生產者 生產者和消費者沖突.
這樣 我們采用雙緩沖區的方案,生產者 消費者各一個緩沖區,每當消費者把消費者緩沖區的數據消費完 且生產者緩沖區內有數據 就交換兩個緩沖區。就減少了生產者和消費者的鎖沖突。
5.我們在緩存區存儲的是一個個日志消息結構體 LogMsg嗎?不這樣頻繁創建和析構LogMsg會,降低效率,我們在緩沖區存入的是格式化的日志字符串,這樣不用new delete LogMsg對象,而且異步線程一次性把緩沖區的多條日志消息落地減少write次數。
傳統方式:
LogMsg結構體直接格式化字符串
每條日志需要創建
LogMsg對象每條日志直接格式化為字符串
內存頻繁
new/delete造成碎片寫入緩沖區是連續內存操作
異步線程還需重新 format 后輸出
異步線程直接寫入文件,無需處理
每條日志都需一次 write()
可一次性 write 多條,提高吞吐量
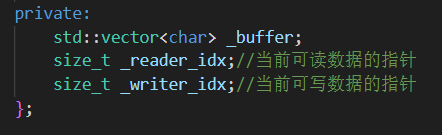
buffer.hpp
Buffer 類
目的: 在內存中維護一塊連續的日志寫入緩沖區,支持動態擴容、雙緩沖交換、快速讀寫操作,并為異步日志器提供數據中轉。
+-------------------------------+
|....已讀....|....待讀....|....可寫....|
0 _reader _writer _buffer.size()
生產者從_writer_idx位置寫入到內存中
消費者從_reader_idx位置讀取并寫入到文件中
當_reader_idx==_writer_idx時 說明已經把緩沖區的數據都寫入文件,之后就交換緩沖區繼續處理
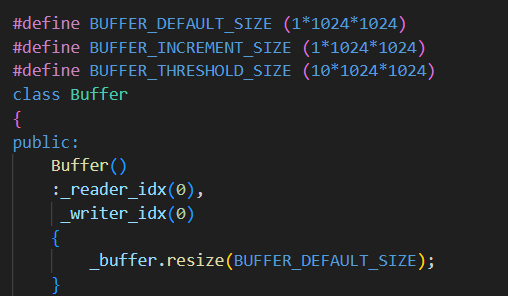
1.構造函數
默認創建一個 1MB 的緩沖區。
使用
std::vector<char>管理內存,避免裸指針和手動new/delete。
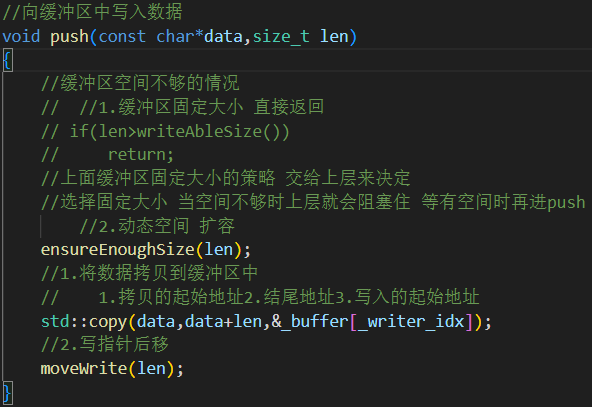
2.push()? 生產者寫入內存
調用
ensureEnoughSize()確保空間夠用(如不夠則擴容)。用
std::copy進行內存拷貝(性能高于memcpy在泛型容器中)。更新
_writer_idx寫指針。
buffer只考慮擴容,緩沖區大小是否固定由上層進行控制,空間不夠上層就會阻塞,不夠還不阻塞說明就需要擴容。
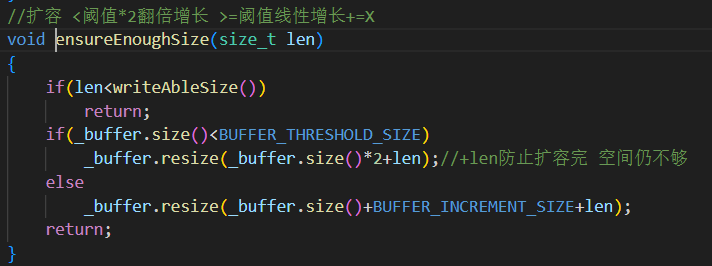
設定閾值
10MB:
小于時采用倍增擴容:性能高、增長快。
大于時改為線性擴容:防止內存爆炸。
總會額外加上
len,確保本次寫入不會失敗。
3.writeAbleSize() 獲取還有多少空間給生產者寫入
返回當前緩沖區還剩多少空間可以寫。
在異步日志中用于判斷是否“生產者需要阻塞等待”。

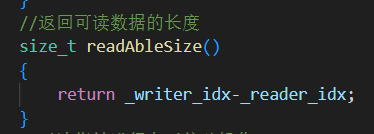
4.readAbleSize() 獲取還剩多少數據給消費者處理
返回還未消費的數據長度。
被消費者線程用于“一次性取出所有待寫日志數據”。
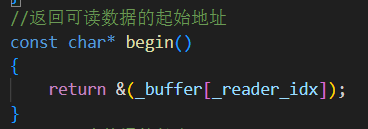
5.begin() 獲取數據處理的起始地址給消費者
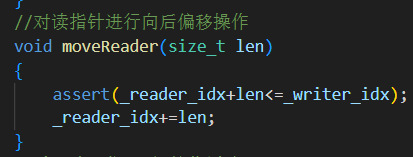
6.moveReader(size_t len)
消費者從緩沖區中讀了多少數據,可讀指針就向后面偏移多少。但確保不能超過可寫指針的位置
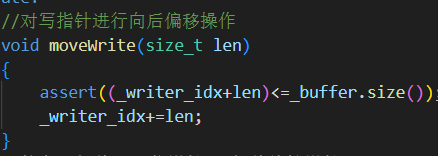
7.moveWrite(size_t len)
同理生產者向緩沖區寫了多少數據 可寫指針就向后面偏移多少,不能超出緩沖區大小。
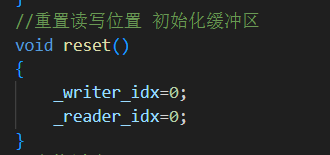
8.reset() 重置緩沖區
表示消費完數據后,清空整個緩沖區,準備下次復用。
重要特性:不重新分配內存,只是重置兩個指針,極大減少內存抖動。
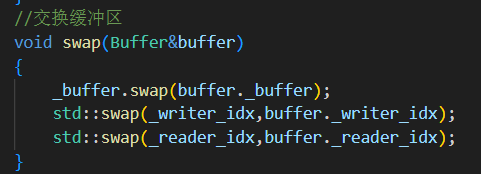
9.swap()?
消費者處理完數據 并且生產者緩沖區中有數據才進行交換緩沖區
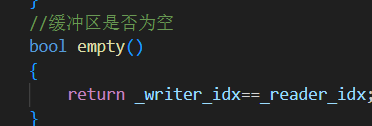
9.empty()
Buffer 是一個高性能、支持自動擴容的環形日志緩沖區,結合 read/write 指針操作和雙緩沖技術,能極大降低內存申請與鎖粒度,是異步日志系統中極其重要的性能核心模塊。
looper.hpp
AsyncLooper類

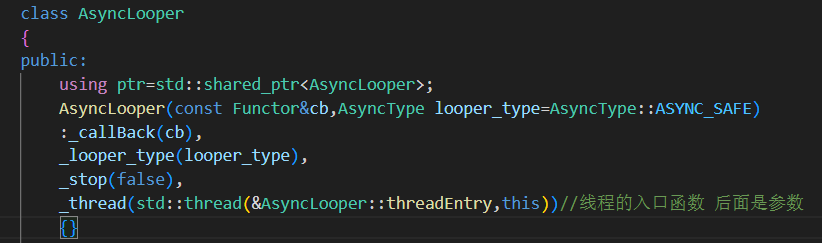
1.構造函數
傳入處理日志消息的回調函數cb 以及緩沖區的策略模式
并設置線程的入口函數啟動線程
創建時立即啟動工作線程,由
threadEntry()開始處理緩沖區數據。線程通過回調函數處理日志內容,完全解耦主邏輯和落地邏輯。
ASYNC_SAFE 安全策略 緩沖區大小固定,空間不夠時生產者會wait阻塞直到可寫入
ASYNC_UNSAFE 非安全策略 緩沖區可擴容 ,空間不夠時會擴容寫入不阻塞

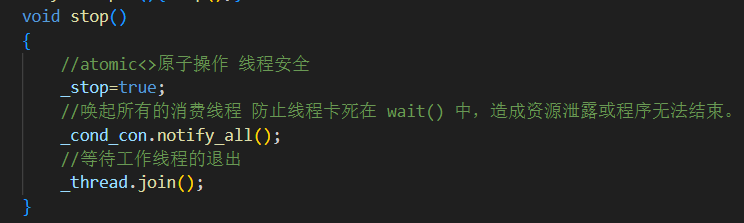
2.stop():安全終止線程
_thread.join等待異步線程處理完數據再退出,。沒有它,異步線程可能中途被殺,數據丟失,資源泄漏。
必須喚醒消費者線程(可能正
wait()阻塞),否則線程可能掛死。退出條件為
_stop == true && _pro_buf.empty(),確保剩余數據處理完。
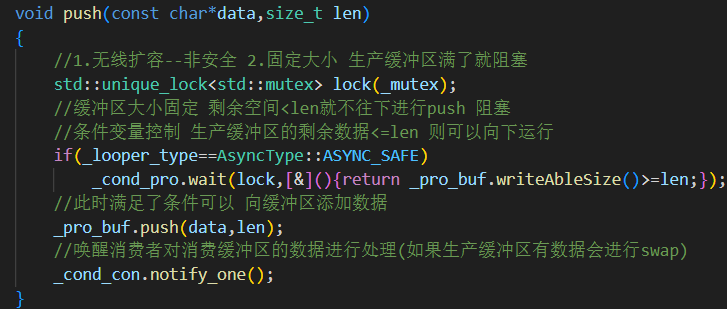
3.push():生產者寫入緩沖區
加鎖保護
_pro_buf,確保線程安全。如果是安全模式(ASYNC_SAFE),寫不下就阻塞等待消費者釋放空間,直到可以寫入。
寫入完成后
notify_one()喚醒消費線程處理。
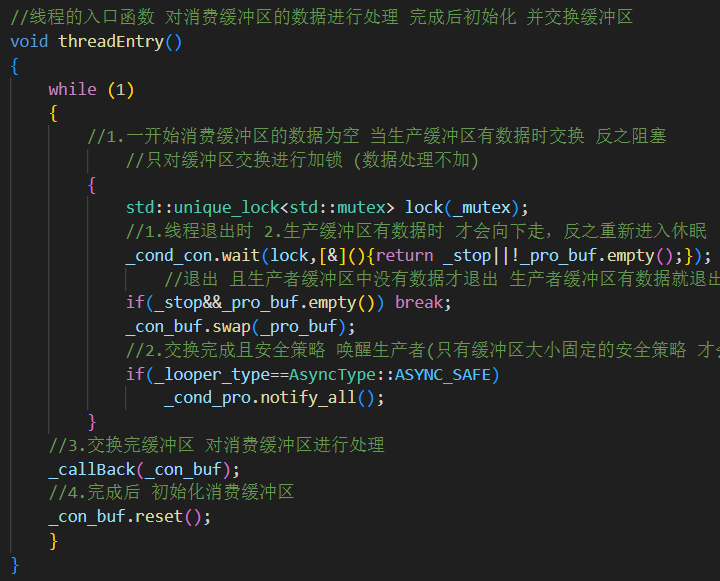
4.threadEntry(): 消費者線程主循環
步驟 動作 1?? 等待 _pro_buf有數據,或者收到_stop信號2?? 如果滿足退出條件(且沒有殘留數據)→ break 3?? 否則交換緩沖區: _pro_buf→_con_buf,如果是安全策略 喚醒可能阻塞住的生產者4?? 解鎖后執行 _callBack(_con_buf)?把內存數據寫入文件5?? 最后 reset()清空消費緩沖區
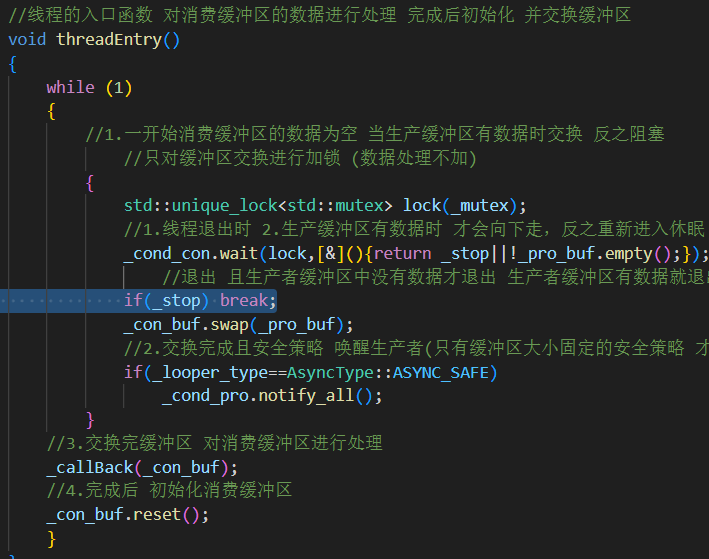
異步線程的退出時機設計
第一次編寫時,當我選擇向顯示器打印日志,按理來說while()循環會打印1000條fatal等級的日志。但為什么只打印了460條就終止了呢?
因為我一開始寫的時候,異步處理線程中收到終止信號就直接break,打破循環,此時處理完消費者緩沖區的數據就直接退出了,但此時生產者緩沖區的數據并沒有swap處理完,進而導致了數據沒有處理完全。
我用 join() 保證主線程等待異步線程結束再退出,但日志還是只打了一半,最后發現是線程收到 stop() 后立刻退出,后面只處理完了消費者緩沖區的數據,沒處理完生產者緩沖區的數據,所以把while循環的退出條件再加上消費者緩沖區為空才解決。
八.日志系統的全局接口和宏封裝
九.性能測試
#include "../logs/mylog.h"
#include <chrono>namespace mylog
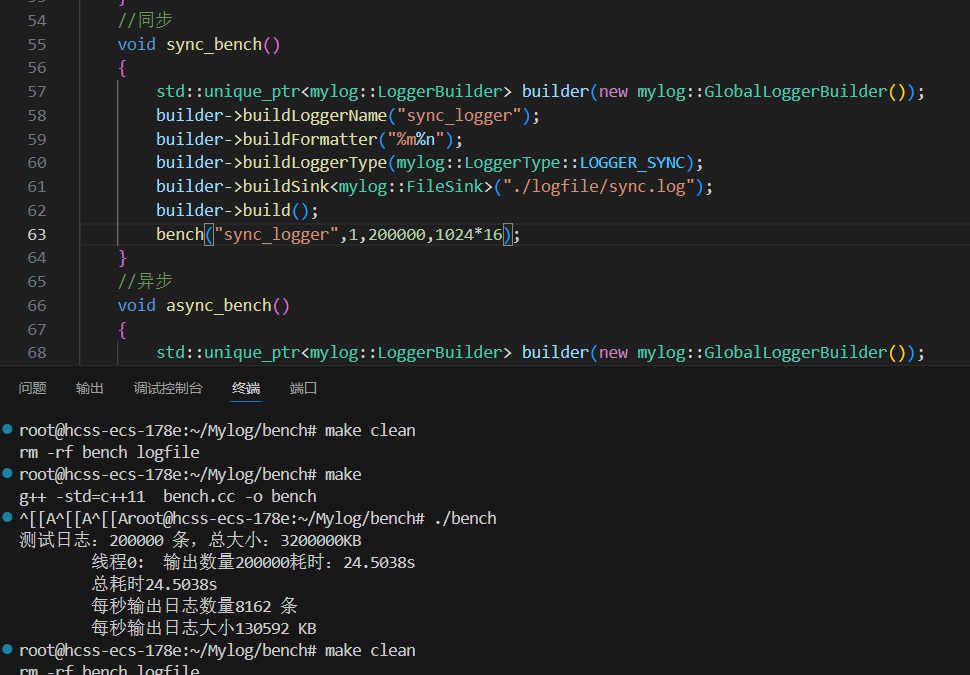
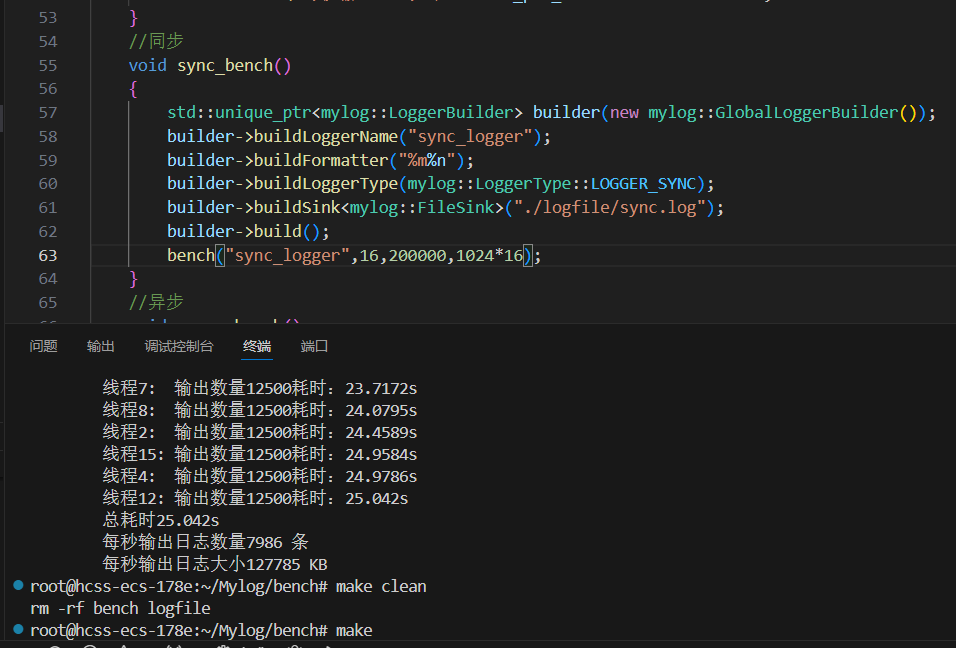
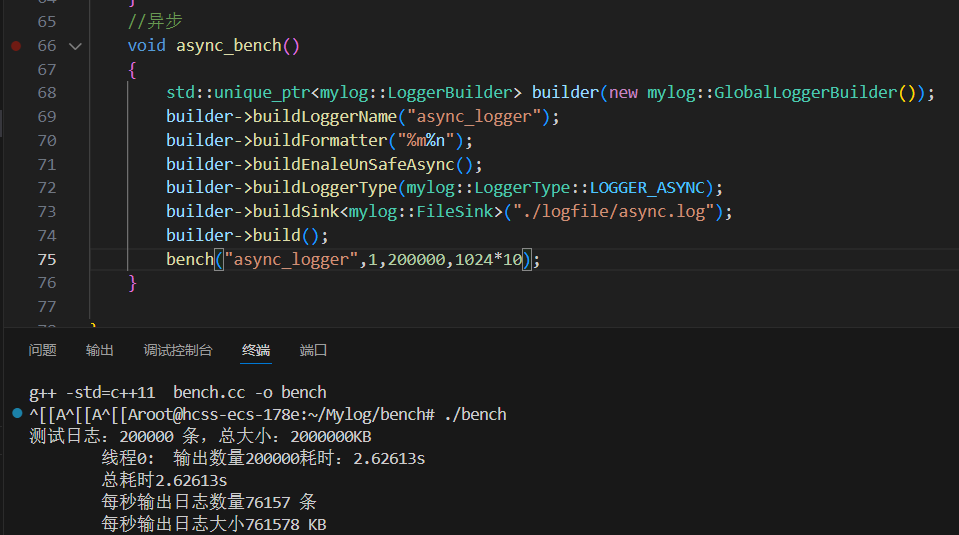
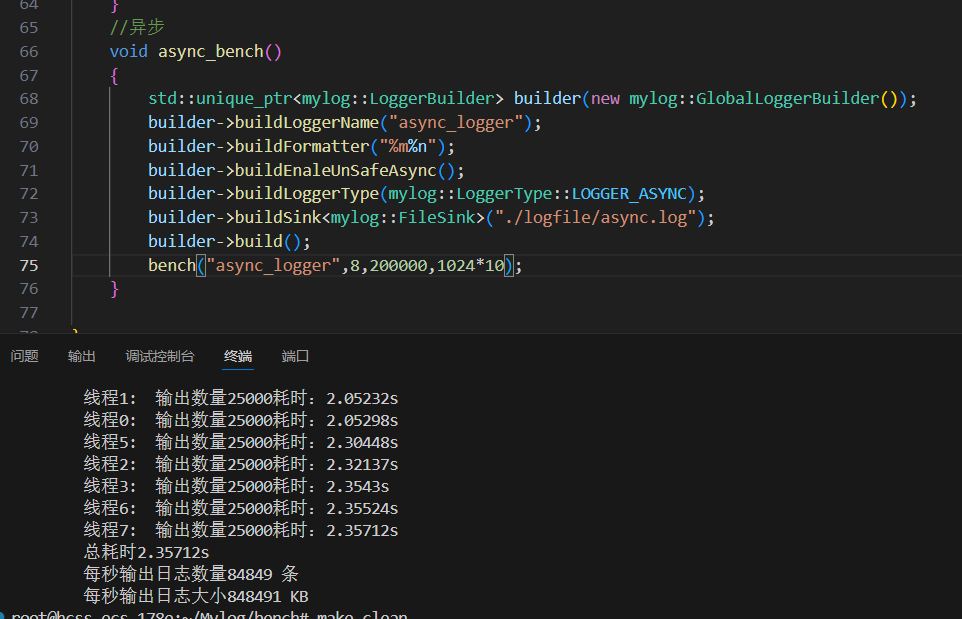
{//1.線程名稱 2.線程個數 3.日志條數 4.一條日志大小void bench(const std::string &logger_name,size_t thr_count,size_t msg_count,size_t msg_len){//1.獲取日志器mylog::Logger::ptr logger=mylog::getLogger(logger_name);if(logger.get()==nullptr)return;std::cout<<"測試日志:"<<msg_count<<" 條,總大小:"<<(msg_count*msg_len)/1024<<"KB\n";//2.組織指定長度的日志消息std::string msg(msg_len-1,'A');// \n占一個字節//3.創建指定數量的線程std::vector<std::thread> threads;std::vector<double> cost_arry(thr_count); //每個線程的寫日志的時間size_t msg_per_thr=msg_count/thr_count; //每個線程平均要寫的日志條數for(int i=0;i<thr_count;i++){//i按值捕獲 不引用(每個線程保存自己的i)threads.emplace_back([&,i](){//4.線程函數內部開始計時auto start=std::chrono::high_resolution_clock::now();//5.開始循環寫日志for(int j=0;j<msg_per_thr;j++)logger->fatal("%s",msg.c_str());//6.結束計時auto end=std::chrono::high_resolution_clock::now();std::chrono::duration<double> cost=end-start;cost_arry[i]=cost.count();//.count得到時間長度(單位秒)std::cout<<"\t線程"<<i<<":\t輸出數量"<<msg_per_thr<<"耗時:"<< cost_arry[i]<<"s\n";});}//等待所有線程退出for(int i=0;i<thr_count;i++){threads[i].join();}//7.計算總時間 (因為線程并行 所有總時間為最長的線程運行時間)double max_cost=0;for(int i=0;i<thr_count;i++)max_cost=max_cost>cost_arry[i]?max_cost:cost_arry[i];//每秒輸出日志數=總條數/總時間size_t msg_per_sec=msg_count/max_cost;//每秒輸出日志大小=總大小/(總時間*1024 ) 單位KBsize_t size_per_sec=(msg_count*msg_len)/(max_cost*1024);//8.進行輸出打印std::cout<<"\t總耗時"<<max_cost<<"s"<<std::endl;std::cout<<"\t每秒輸出日志數量"<<msg_per_sec<<" 條"<<std::endl;std::cout<<"\t每秒輸出日志大小"<<size_per_sec<<" KB"<<std::endl;}//同步void sync_bench(){std::unique_ptr<mylog::LoggerBuilder> builder(new mylog::GlobalLoggerBuilder());builder->buildLoggerName("sync_logger");builder->buildFormatter("%m%n");builder->buildLoggerType(mylog::LoggerType::LOGGER_SYNC);builder->buildSink<mylog::FileSink>("./logfile/sync.log");builder->build();bench("sync_logger",16,200000,1024*16);}//異步void async_bench(){std::unique_ptr<mylog::LoggerBuilder> builder(new mylog::GlobalLoggerBuilder());builder->buildLoggerName("async_logger");builder->buildFormatter("%m%n");builder->buildEnaleUnSafeAsync();builder->buildLoggerType(mylog::LoggerType::LOGGER_ASYNC);builder->buildSink<mylog::FileSink>("./logfile/async.log");builder->build();bench("async_logger",8,200000,1024*10);}}
int main()
{mylog::async_bench();return 0;
}同步寫入磁盤的過程
在開始前我們先了解一下同步模式下,日志數據寫入磁盤的全過程。
1.程序格式化日志內容(用戶態)
先把日志內容組織好,變成一塊連續的內存數據
2.調用 write() 系統調用
這時候,程序要做一件重要的事:
從用戶態切換到內核態(陷入系統內核)
調用內核的
sys_write系統調用3.數據寫入內核緩沖區(Page Cache)
注意:向內核緩沖區寫完就返回了,繼續執行。后面是Linux后臺異步寫回線程 完成阻塞并刷新到磁盤的過程。日志線程不會卡在等待flush磁盤上!(只有你顯式調用fsync(),線程才會因為刷新磁盤而阻塞)
內核接收到
write請求,不是直接寫磁盤!它首先把數據寫到Page Cache,也就是內核管理的一塊內存緩存區。
4.Page Cache 決定什么時候真正寫磁盤
內核什么時候把 Page Cache 里的內容同步到磁盤呢?
緩沖區滿了(比如寫入太多數據)
過了一定時間(定時flush)(比如默認5秒一次)
用戶調用 fsync() 強制刷盤
系統負載很低,后臺自動同步
?真正觸發刷盤時,內核才會:
把緩存中的數據,提交給磁盤驅動
磁盤控制器接收數據,最終物理寫入磁盤
細節 解釋 write() 返回了,是不是代表數據已經寫到磁盤? 不是!只是到了內核Page Cache里,真正落盤可能還要等一段時間 write() 過程慢不慢? 通常快(因為只是內存拷貝),除非Page Cache滿了或I/O很忙 真正慢的是哪一步? Page Cache flush到磁盤時才真正慢,但通常不是同步日志線程在等待 調用fsync()會怎樣? 強制刷新Page Cache到磁盤,非常慢(阻塞)
單線程同步vs多線程同步
在同步模式下,我們一般會選擇單線程,因為多線程會出現鎖沖突導致效率下降。
但在我的2核4G服務器測試中,發現多線程反而比單線程更快。
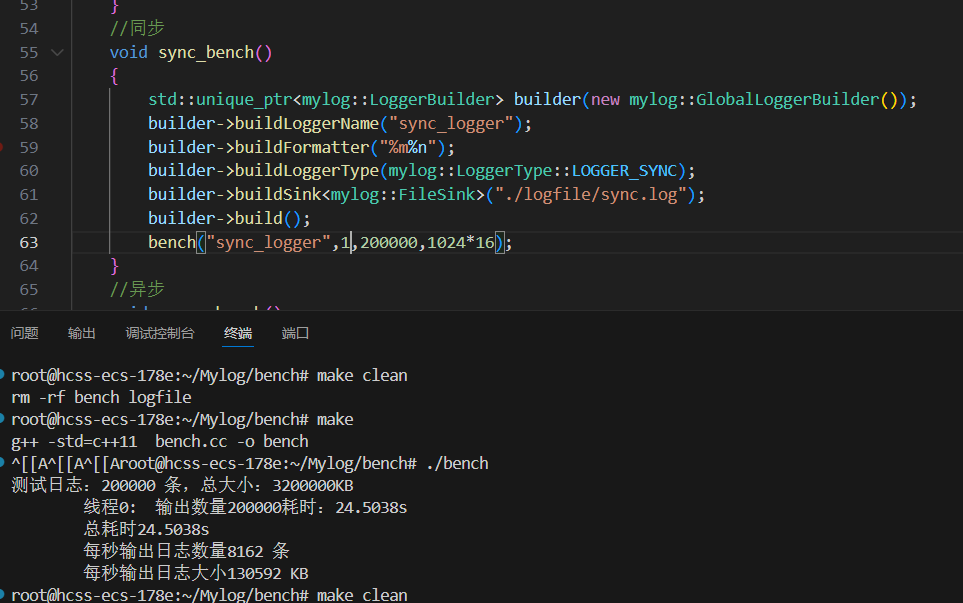
1.單線程同步
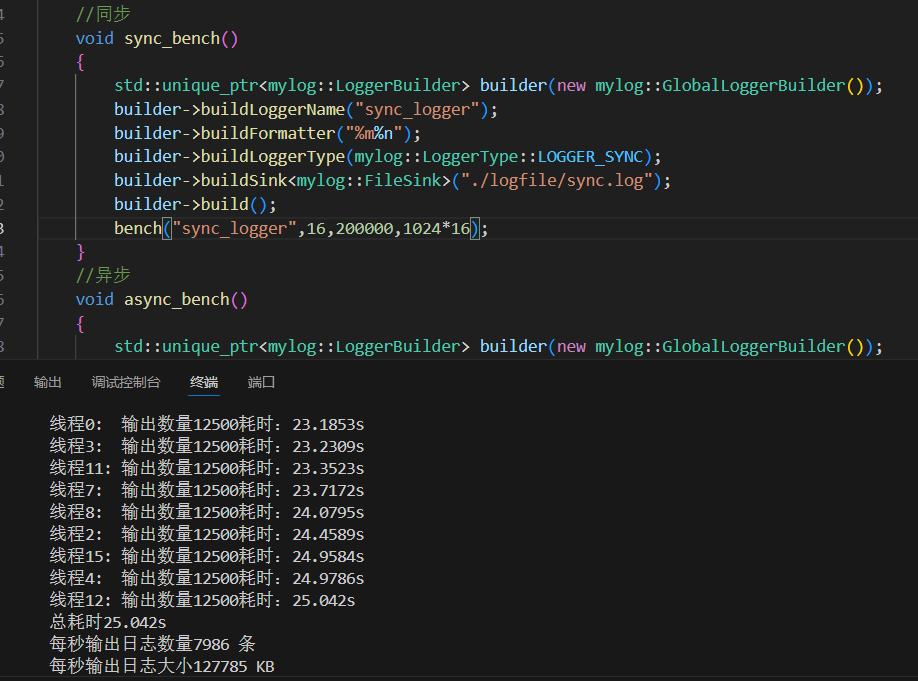
2.多線程同步
接下來我們進行原因分析,為什么同步模式下多線程有鎖沖突還是比單線程快?
簡單來說:多線程充分利用CPU提高的效率大,且鎖沖突降低的效率低
1. 單條日志很小
每條日志體積只有幾十到一百字節。
write()寫入過程極短,鎖持有時間非常短。所以即使多線程競爭鎖,每次持鎖時間很快釋放,鎖沖突不明顯。
2. 總日志數據量小
總寫入數據量只有幾十MB到100MB左右。
內核Page Cache能完全hold住所有數據。
向磁盤真正flush的次數很少(內核異步回寫)(這個過程也需要加鎖)
沒有真正暴露磁盤I/O延遲,系統調用
write()只拷貝到內存,很快返回。
3. 多線程數量適中
只開了2~4個線程,并未遠遠超出CPU核心數(2核)。
多線程合理分攤到不同CPU核上執行,CPU利用率提升。
并行執行帶來的加速效果,大于鎖競爭導致的損失。
鎖沖突分類:
反過來我們也可以從這三點入手,1.增加單條日志大小 2.增加日志總量 3.增加線程數量
類型 解釋 特點 鎖持有時間長型沖突(Lock Holding Contention) 一個線程拿著鎖很久,其他線程只能苦等 比如一次write操作太慢,鎖持有時間過長 鎖等待排隊型沖突(Lock Waiting Contention) 很多線程搶鎖,排隊搶占,雖然每次持鎖很短 比如多線程短寫日志,鎖很快釋放,但搶鎖的人太多
方法 目的 ① 增加單條日志大小 加重單次write開銷 ② 增加日志總量 提高Page Cache壓力、增加flush次數 ③ 增加線程數量 提高鎖競爭和CPU切換開銷 總結:起到兩個方面的作用
1.增加鎖沖突
? ? ? ? 1.增加鎖持有時間 1.增加單條日志大小 write()寫入內核緩沖區速度下降。2.日志總量增加,增加write()寫入緩沖區阻塞的概率,以及增加緩沖區數據向磁盤刷新的次數。
? ? ? ? 2.增加線程排隊時間,增加線程數量 線程搶鎖排隊,等待時間變長,整體吞吐下降。
2.增加CPU切換開銷 (降低CPU利用率)
? ? ? ? 增加線程,因為CPU輪詢機制,每個線程都會被調用且運行一段時間換下一個。導致CPU在不同線程之間頻繁切換,浪費大量CPU時間,總耗時增加,吞吐下降。
1.單線程
2.多線程
有的線程17秒就輸出完了,有的線程24秒多才完成。 為什么同步多線程測試中,不同線程完成時間差很多?
項目 單線程同步日志 多線程同步日志(16線程) 總日志條數 200,000條 200,000條 每條大小 16KB 16KB 總數據量 3.2GB 3.2GB 總耗時 24.5038秒 25.042秒 每秒輸出條數 8162條/s 7986條/s 每秒輸出日志大小 130592 KB/s 127785 KB/s
多線程同步日志,大家寫日志都要搶一把鎖(通常是
std::mutex保護的)。
std::mutex在Linux底層是非公平鎖(搶到就用,不保證排隊順序)。結果就是:
某些線程運氣好,連續搶到鎖,瘋狂輸出
某些線程運氣差,總在鎖外苦等,一直排隊
原因 現象 影響 鎖搶占不公平 有的線程連續拿鎖,有的線程苦等 導致完成時間天差地別 CPU調度不均 某些線程搶到CPU多,跑得快 執行速率不同 Page Cache刷盤堵塞 后期線程write變慢 后期線程完成時間普遍更長
異步寫入磁盤的過程
1. 【主線程】格式化日志內容
2.【主線程】push日志到異步緩沖區
在
log()函數內部做的事情:
加鎖(保護緩沖區,通常是
std::mutex)把日志數據拷貝到生產緩沖區(內存區域)
解鎖
條件變量 notify_one 通知異步線程:有新日志來了
push動作只涉及:
加鎖保護
內存拷貝(拷貝到內部緩沖區)
通知后臺線程
沒有系統調用(沒有write())
push很快完成,主線程立刻繼續跑業務,不受I/O影響。
3. 【異步線程】被喚醒
4. 【異步線程】交換緩沖區
5. 【異步線程】處理消費緩沖區數據
????????這一步才真正發生了系統調用(write)
6. 【內核】處理write動作
7. 【異步線程】處理完成,繼續睡眠等待下一波日志
所以說異步日志,就是讓異步線程完成耗費時間多的write(),但為了讓異步線程獲取到數據,還得再建一個緩沖區,多一步拷貝到緩沖區的內容。對比同步,異步主線程相當于把write()換成了一次push拷貝(以及其它的細節開銷 比如說緩沖區交換時會加鎖 喚醒線程的系統調用notify等)。
對比同步模式,可以理解為:
同步日志主線程需要:
格式化 + write()(系統調用,可能慢)
異步日志主線程需要:
格式化 + push拷貝 + notify異步線程(全在用戶態完成,極快)
? 異步日志相當于把主線程的 write() 開銷換成了一次輕量級的 push拷貝,
? 再加上一些很輕的鎖和notify開銷。
單線程同步vs單線程異步
如果需要調用的write()次數很少,那么單線程異步 同步差距不明顯,但需要頻繁調用write()才能處理完數據,還是異步更快一點 。
單線程異步vs多線程異步
異步模式下 單線程和多線程對比,和同步模式一樣,異步模式下多線程也會出現鎖競爭,但不用自己調用write() push寫入buffer緩沖區不夠會自動擴容不會阻塞住,push寫入速度很快,導致鎖競爭并不大 只有在push寫入時加鎖,速度很快。
多線程異步最主要的優勢在于:對日志消息格式化的過程多線程是并行的,雖然push串行有細微鎖開銷,但總體的效率還是比單線程快的。單線程push寫入少穩定 多線程短時間push大量數據。
利用多核CPU,加速日志格式化
格式化(如:時間戳、線程ID、日志級別、文本拼接)本身是有一定開銷的。
單線程異步時,所有格式化工作由一個線程做,受限于單核CPU速度。
多線程異步時,不同線程可以在不同核上并行進行格式化。
格式化速率大大提高,總體日志生產能力上升。
1.單線程異步
2.多線程異步 8
測試 線程數 總日志條數 總大小 總耗時 每秒輸出條數 每秒輸出大小 第一次 1線程(單線程異步) 200,000條 2GB 2.62613秒 76,157條/s 761,578 KB/s 第二次 8線程(多線程異步) 200,000條(每線程25,000條) 2GB 2.35712秒 84,849條/s 848,491 KB/s
總結:
條件 推薦日志模式 原因 每秒日志量小(≤幾千條) 同步單線程 系統開銷最小,結構最簡單 每秒日志量中等(幾萬條) 異步單線程 主線程減少阻塞,異步線程批量處理 每秒日志量大(十萬條以上) 異步多線程 并行格式化 + 快速push + 批量write,極限提升吞吐
總結:
| 模塊 | 功能 |
|---|---|
| Logger類 | 日志器,統一管理日志級別、格式化器、輸出目的地 |
| Formatter類 | 日志消息格式化(支持自定義格式) |
| Sink類 | 日志落地(支持stdout/file等多種輸出) |
| Builder模式 | 統一構建日志器(配置LoggerName、LoggerType、Formatter、Sink等) |
| LoggerManager(單例) | 全局日志器管理中心,負責創建、查找日志器實例 |
| 異步模塊(AsyncLogger) | 實現緩沖區管理、異步push和write,減少主線程I/O阻塞 |
| 同步模塊(SyncLogger) | 簡單直接的日志同步落地,適合小量數據低延遲需求 |
難點:
異步模式下push和write之間的速率平衡問題
由于push本身非常快(只是內存拷貝),
而異步線程的write動作相對慢(需要系統調用,將數據從用戶態寫入內存緩沖區),
如果主線程push頻率太高,異步線程write跟不上,就會導致緩沖區積壓,最終push阻塞(安全模式),影響主線程業務流程。針對這個問題,我做了幾層優化設計:
1. 雙緩沖區結構?
減少消費者和生產者的鎖沖突,提高異步線程write()處理速率。
主線程push到生產緩沖區;
異步線程消費交換后的緩沖區;
交換期間加鎖,數據處理期間無鎖,減少鎖沖突時間。
2. 條件變量+批處理機制
push完成數據立刻用條件變量notify通過異步線程處理,異步線程一次性批量write,減少系統調用次數,提升磁盤寫入效率。
主線程push時,用
std::condition_variable::notify_one()喚醒異步線程;異步線程wait時只在緩沖區有數據或stop信號時醒來;
一次消費整個緩沖區內所有日志,批量write,減少系統調用次數,提升磁盤寫入效率。
3. 支持安全異步與非安全異步模式
生產者push太快就選安全模式 阻塞push,等有空間時再push
在業務量爆發時,可以選擇:
安全異步模式(生產緩沖區滿了就阻塞push,保護內存)
非安全異步模式(無限擴容緩沖區,保證主線程push不卡頓,犧牲內存)
把思維鏈推理過程圖結構化)












)





