TL;DR
- 2025 年斯坦福提出的 OpenVLA 工作的續作 OpenVLA-OFT,優化 VLA 能夠有效適應新的機器人平臺和任務,優化的技術主要有并行解碼、動作塊處理、連續動作、L1 回歸和(可選的)FiLM 語言調節
Paper name
Fine-Tuning Vision-Language-Action Models: Optimizing Speed and Success
Paper Reading Note
Paper URL:
- https://arxiv.org/pdf/2502.19645
Introduction
背景
- 為了在新型機器人和新任務中順利部署,微調仍然是關鍵步驟
- 現有方案 OpenVLA 的關鍵限制
- 推理速度慢(3-5赫茲),不適合高頻控制
- 在雙臂操作器上執行任務不可靠
本文方案
-
提出了 OpenVLA-OFT(Optimized Fine-Tuning優化微調配方),結合了并行解碼與動作塊、連續動作表示,以及L1回歸學習目標
- 通過并行解碼結合動作塊(chunking),不僅大幅提升推理效率,還能提高下游任務的成功率,并帶來更靈活的輸入輸出規格;
- 連續動作表示相比離散表示進一步提升了模型質量;
- 采用 L1 回歸目標微調 VLA,與基于擴散的微調方法在性能上相當,但訓練收斂速度更快,推理速度也更高效。
-
微調的效果和模型推理效率都有提升
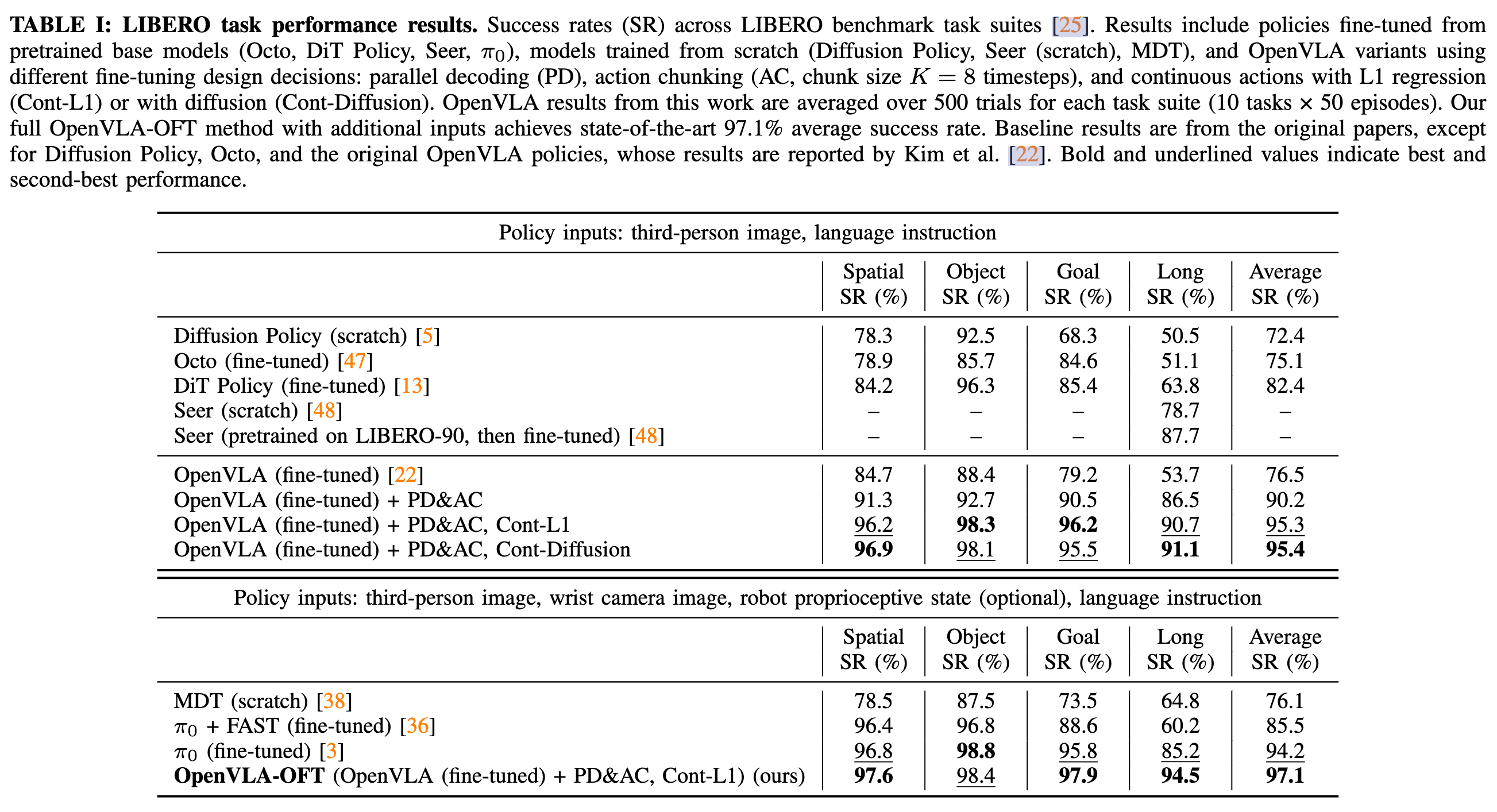
- 在標準的 LIBERO 仿真基準測試和真實雙臂 ALOHA 機器人精細操作任務上進行了實驗。在 LIBERO 中,OpenVLA-OFT 在四個任務組中達到了平均 97.1% 的成功率,超過了微調后的 OpenVLA 策略(76.5%)和 π0 策略
- 在 8 步動作塊設置下實現了 26 倍的動作生成速度提升
- 真實 ALOHA 任務中,結合 FiLM 方法強化了語言指令理解,稱為 OFT+。OpenVLA-OFT+ 成功執行了諸如折疊衣物、根據用戶指令操作食材等復雜雙臂任務。平均成功率上,超越了微調后的VLA(π0 和 RDT-1B)和主流從零訓練的模仿學習策略(Diffusion Policy 和 ACT)多達15%(絕對值)
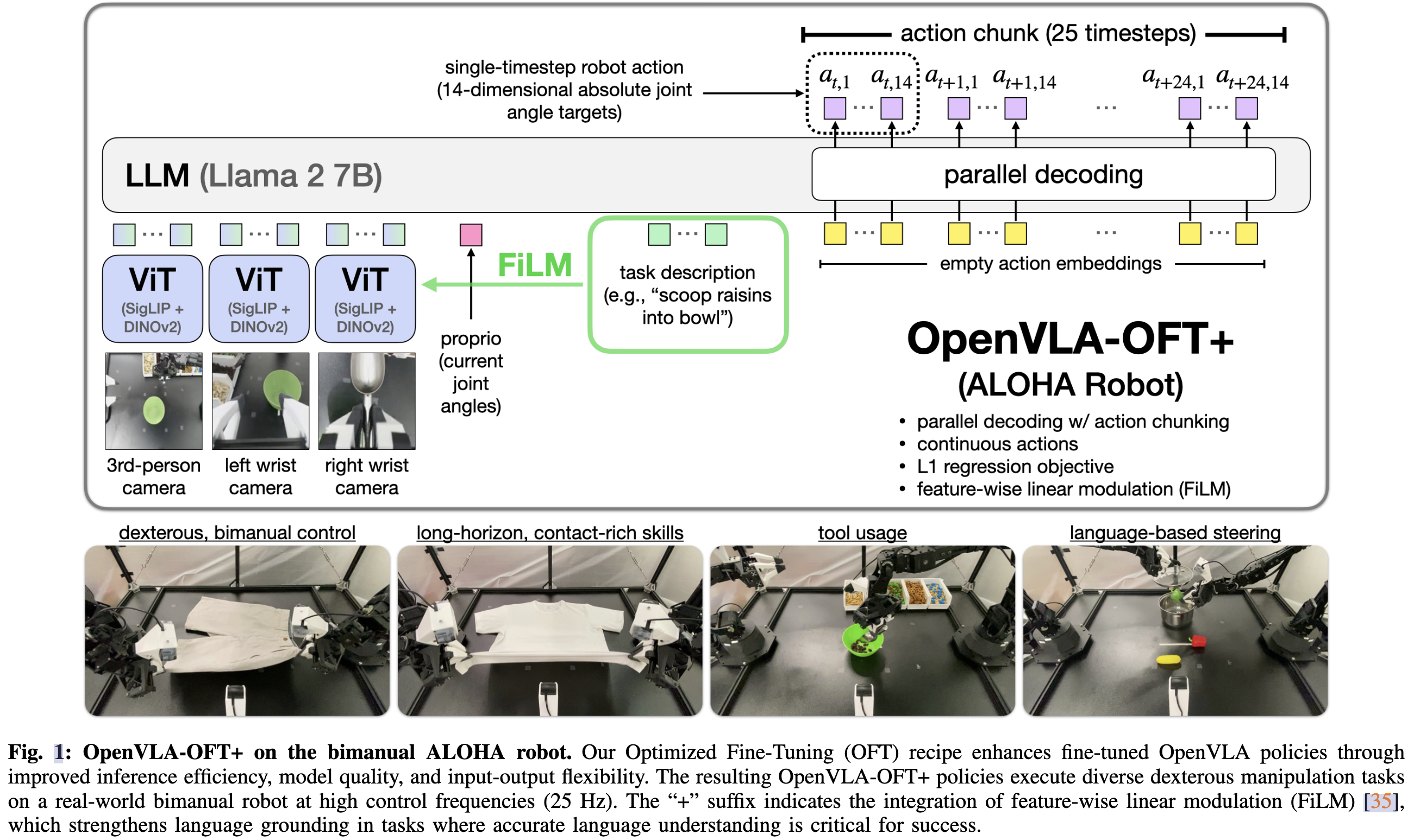
Methods
OpenVLA 回顧
-
在 Open X-Embodiment數據集的 100 萬集數據上微調 Prismatic 視覺語言模型(VLM)而創建的 70 億參數的操作策略
-
每個時間步預測 7 個離散的機器人動作標記:3 個用于位置控制,3 個用于方向控制,1 個用于夾爪控制。
-
采用下一個標記預測作為學習目標,并使用交叉熵損失,類似于語言模型
-
動作分塊
- 先前的研究表明,動作分塊——即預測并執行一系列未來動作而不進行中間重規劃——可以提高許多操作任務中策略的成功率。然而,OpenVLA 的自回歸生成方案使得動作分塊不切實際,因為即使生成單個時間步的動作在 NVIDIA A100 GPU 上也需要 0.33 秒。對于大小為 K 個時間步的動作分塊和動作維度 D,OpenVLA 需要 KD 次順序解碼器前向傳播,而不是沒有分塊時的 D 次傳播。這種 K 倍的延遲增加使得在原始公式下,動作分塊對于高頻機器人不切實際。本文將介紹一種并行生成方案,以實現高效的動作分塊。
VLA 微調設計優化
模型結構及訓練策略優化
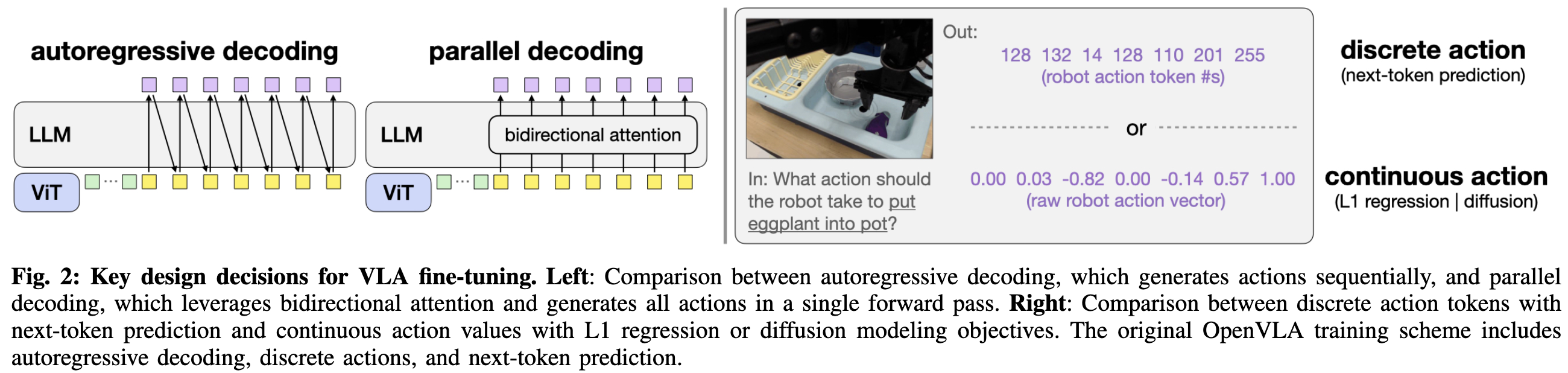
- 并行解碼:利用雙向 attention,一次性生成所有 actions
- 以空動作嵌入作為輸入,并用雙向注意力替換因果注意力掩碼,從而使解碼器能夠同時預測所有動作。從 D 次順序傳播減少到單次傳播,其中 D 是動作維度
- 并行解碼自然擴展到動作分塊:要預測多個未來時間步的動作,我們只需在解碼器的輸入中插入額外的空動作嵌入,這些嵌入隨后被映射為一系列未來動作。對于大小為K的分塊,模型在一次前向傳播中預測KD個動作,吞吐量增加了K倍,同時幾乎不影響延遲。并行解碼在理論上可能不如自回歸方法具有表現力,但本文的實驗表明,在各種任務中并沒有性能下降。
- 離散 action token 改為連續的 action 設計,對比以下兩種設計
- 基于softmax的標記預測處理的離散動作:每個動作維度被歸一化到[?1, +1]并均勻離散化為256個bin。語言模型解碼器的最終隱藏狀態被線性投影為logits,然后通過softmax操作形成動作標記的概率分布
- 由多層感知機(MLP)動作頭直接生成的連續動作:最終隱藏狀態則通過一個單獨的動作頭MLP直接映射為歸一化的連續動作
- 學習目標,對比以下:
- 離散動作:next-token prediciton
- 連續動作:L1 回歸,最小化預測動作和真實動作之間的平均 L1 差異
- 連續動作:diffusion (和 diffusion policy 文章類似),策略通過逆向擴散逐漸去除噪聲動作樣本以產生真實動作
- 采用了特征線性調制(FiLM)增強語言跟隨能力:將語言嵌入注入到視覺表示中,使模型更多地關注語言輸入
- 計算任務描述中的語言嵌入 x 的平均值,并將其投影以獲得縮放和偏移向量 γ 和 β。這些向量通過仿射變換對視覺特征F進行調制:FiLM(F|γ, β) = F? = (1 + γ) ⊙ F + β
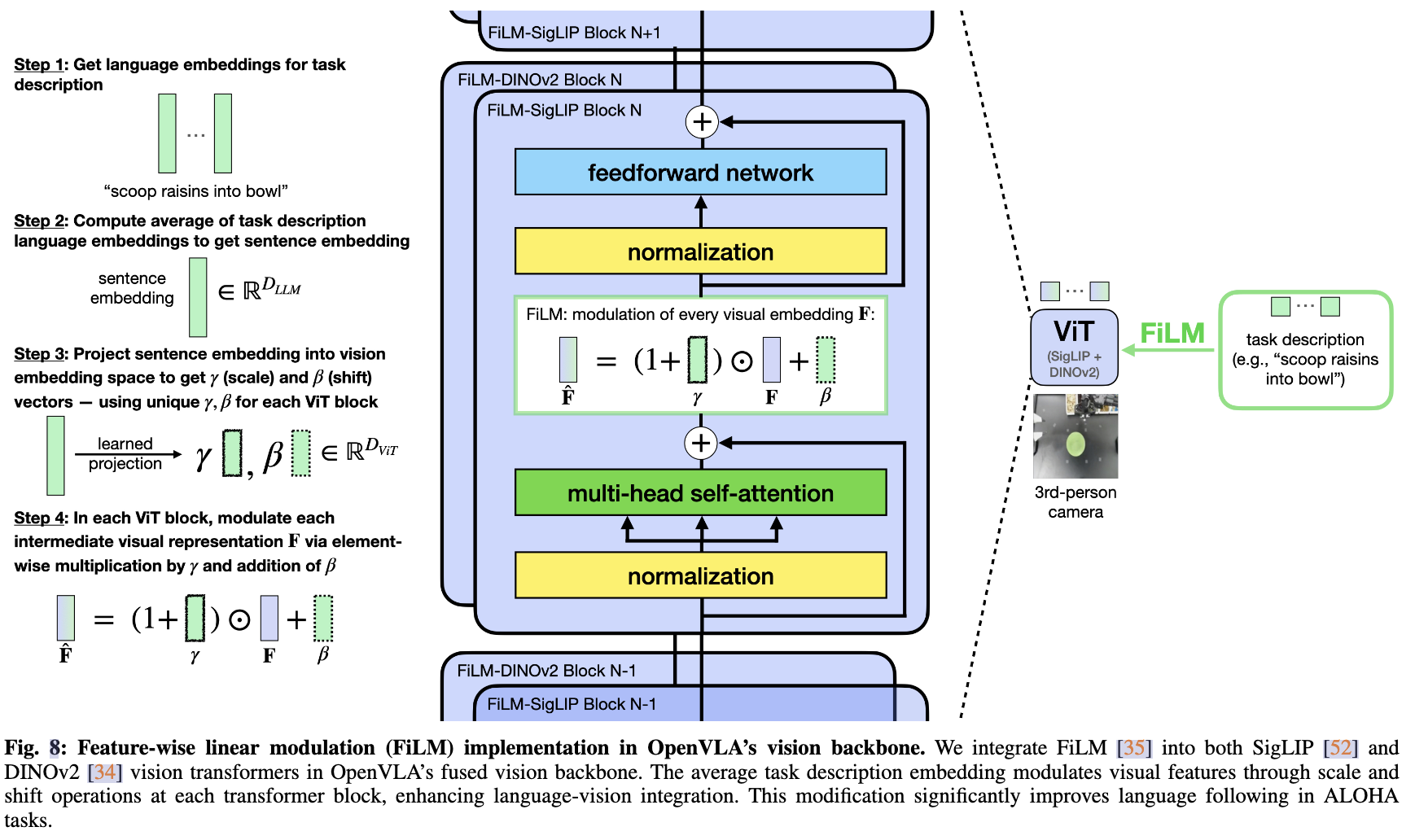
- 計算任務描述中的語言嵌入 x 的平均值,并將其投影以獲得縮放和偏移向量 γ 和 β。這些向量通過仿射變換對視覺特征F進行調制:FiLM(F|γ, β) = F? = (1 + γ) ⊙ F + β
Experiments
LIBERO 實驗
-
使用四個任務套件:LIBERO-Spatial、LIBERO-Object、LIBERO-Goal 和 LIBERO-Long,每個套件在 10 個任務中各提供 500 個專家演示,以評估策略在不同空間布局、物體、目標和長程任務上的泛化能力

-
實驗配置
- 為非擴散方法訓練 5 萬至 15 萬次梯度更新,擴散方法(由于收斂較慢)訓練 10萬至25萬次,批量大小為 64-128,使用 8 張 A100 或 H100 GPU。
- 每隔 5萬步測試一次模型,并報告每次運行的最佳表現。
- 策略的輸入為一張第三人稱圖像和一條語言指令。
- 使用動作分塊(action chunking)的方法,分塊大小 K=8
-
模型效果評測
- 并行解碼(Parallel Decoding, PD)和動作分塊(Action Chunking, AC) 是實現高頻率控制(25-50+ Hz)的必要條件。并行解碼和動作分塊不僅提高了吞吐量,還顯著提升了性能,相比自回歸 OpenVLA 策略,平均成功率提高了 14%(絕對值)。在 LIBERO-Long 套件上提升尤為明顯,表明動作分塊有助于捕捉時間依賴性并減少累積誤差,從而使任務執行更加平滑和可靠。
- 連續動作變體比離散動作變體的成功率又提高了 5%(絕對值),這可能是因為連續動作預測具有更高的精度。
- L1 回歸和擴散變體性能相當,說明高容量的 OpenVLA 模型即便使用簡單的 L1 回歸,也能有效建模多任務動作分布。
-
模型性能評估
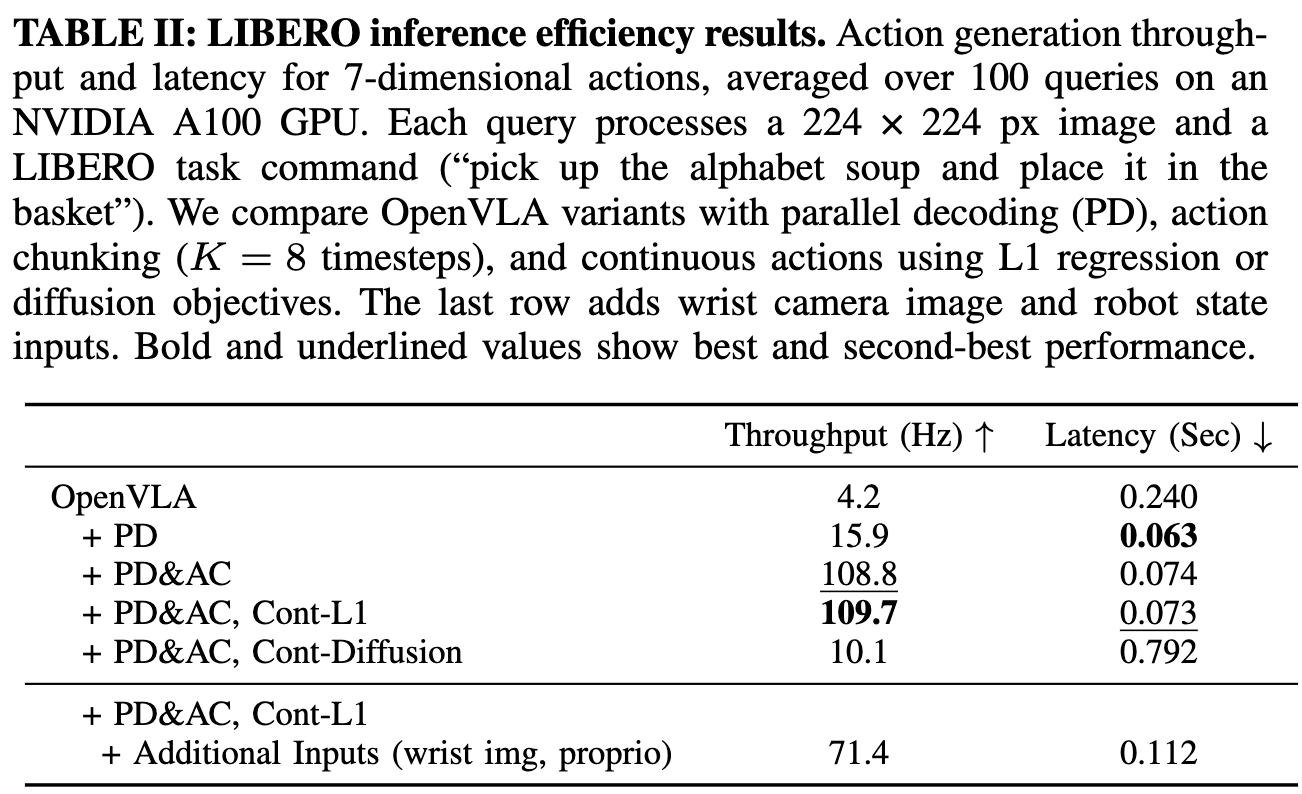
- 在 NVIDIA A100 GPU 上對每種模型變體進行 100 次查詢,測量平均延遲(生成一個動作或動作塊的時間)和吞吐量(每秒生成的動作數)。輸入是一張 224x224 像素的圖像和一條示例語言指令(例如:“撿起字母湯罐頭放進籃子里”)。
- 并行解碼將 7 次順序前向傳遞合并為一次,從而使延遲減少、吞吐量提高了 4 倍。
增加動作分塊(K=8)雖然使延遲增加了 17%(因為解碼器的注意力序列更長),但結合并行解碼后,總體吞吐量提升達 26 倍。 - 連續動作(L1 回歸)變體效率變化微小,而擴散變體由于需要 50 次去噪步驟,導致延遲是其他方法的 3 倍,但通過并行解碼和分塊,仍然實現了 2 倍以上的吞吐量提升。這意味著盡管動作塊之間的暫停更長,但擴散變體仍比原始自回歸 (OpenVLA) 更快完成機器人任務。
- 在 OpenVLA 中引入額外輸入(如機器人本體感知狀態和腕部攝像頭圖像)進行驗證,使視覺 patch 嵌入數從 256 翻倍到 512。盡管輸入序列長度大幅增加,微調后的 OpenVLA 策略仍保持了高吞吐量(71.4 Hz)和低延遲(0.112 秒)
真實機器人平臺測試
-
ALOHA 是一個真實的雙臂操作平臺,具有高頻控制能力。包含兩只 ViperX 300 S 機械臂、三個攝像頭視角(一個俯視,一個安裝在每只手腕上)以及機器人狀態輸入(14 維關節角)組成。控制頻率為 25 Hz(從原始的 50 Hz 降低,以加快訓練速度,同時保持平滑控制),動作表示為目標絕對關節角。這種設置與 OpenVLA 的預訓練條件有顯著差異,后者只包括單臂數據、單一第三人稱攝像視角、無機器人狀態輸入、低頻率控制(3-10 Hz)以及相對末端執行器位姿動作。這種分布變化對模型適應性提出了挑戰。
-
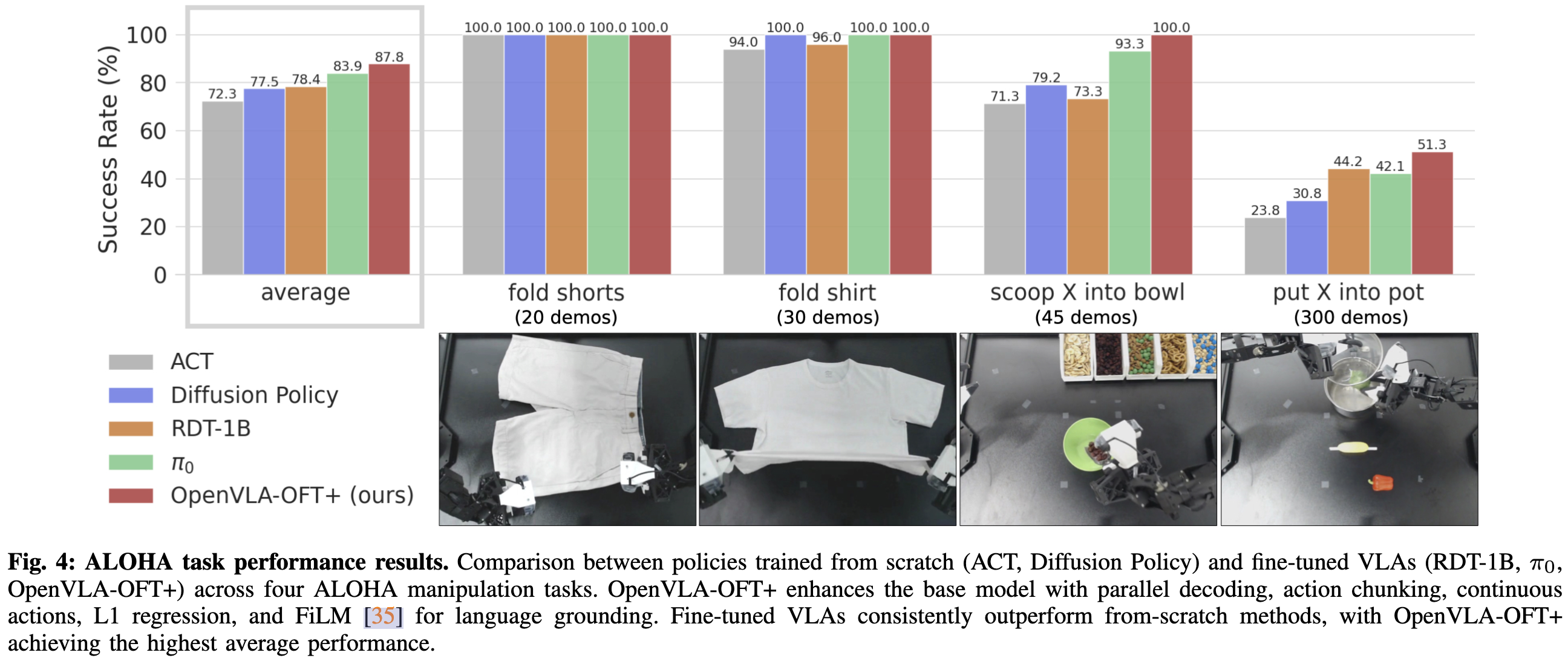
設計了四個任務,用于測試可變形物體操作、長時間技能、工具使用和基于語言的控制能力
- “fold shorts”(疊短褲):在桌子上進行連續兩次雙臂折疊,將白色短褲疊好
- “fold shirt”(疊T恤):通過多次同步雙臂折疊,將白色 T 恤疊好,考驗接觸豐富的長時操作。
- “scoop X into bowl”(把 X 舀入碗中):左臂將碗移動到桌子中央,右臂用金屬勺舀指定的配料(葡萄干、杏仁和綠 M&M 糖,或椒鹽卷餅)。
- “put X into pot”(把 X 放入鍋中):左臂打開鍋蓋,右臂放入指定物品(青椒、紅椒或黃玉米),然后合上鍋蓋。
-
微調后能取得最優效果,需要注意的是 FiLM 在這里的重要性非常大

Conclusion
- OpenVLA 的續作,主要優化 VLA 能夠有效適應新的機器人平臺和任務,優化的技術主要有
- 并行解碼、動作塊處理、連續動作、L1 回歸和(可選的)FiLM 語言調節
- 本文的實驗主要是在微調任務中做的,尚不清楚 OFT 的優勢能否有效擴展到預訓練階段
- 仿真平臺和實際平臺中對模型有不同的需求
- 在 ALOHA 平臺的實驗中,發現 OpenVLA 在沒有 FiLM 的情況下表現出較差的語言理解能力,盡管在 LIBERO 仿真基準測試中并未出現此類問題。



)




)




)
——競態條件競爭導致的一致性問題)
)


——DeepSeek系列概覽與發展背景)
