一、引言
在深度學習蓬勃發展的今天,卷積神經網絡(Convolutional Neural Network,簡稱 CNN)憑借其在圖像識別、計算機視覺等領域的卓越表現,成為了人工智能領域的核心技術之一。從手寫數字識別到復雜的醫學影像分析,從自動駕駛中的目標檢測到智能安防的人臉識別,CNN 無處不在,深刻改變著我們的生活與工作方式。本文將深入剖析 CNN 的原理、結構組成,并通過實際案例展示其強大的應用能力。
二、原理
1、CNN 的核心思想是利用卷積運算來提取圖像的特征。與傳統的全連接神經網絡不同,CNN 通過卷積層、池化層和激活函數等組件,能夠自動學習圖像中的局部特征和空間層次結構,從而更有效地處理圖像數據。?
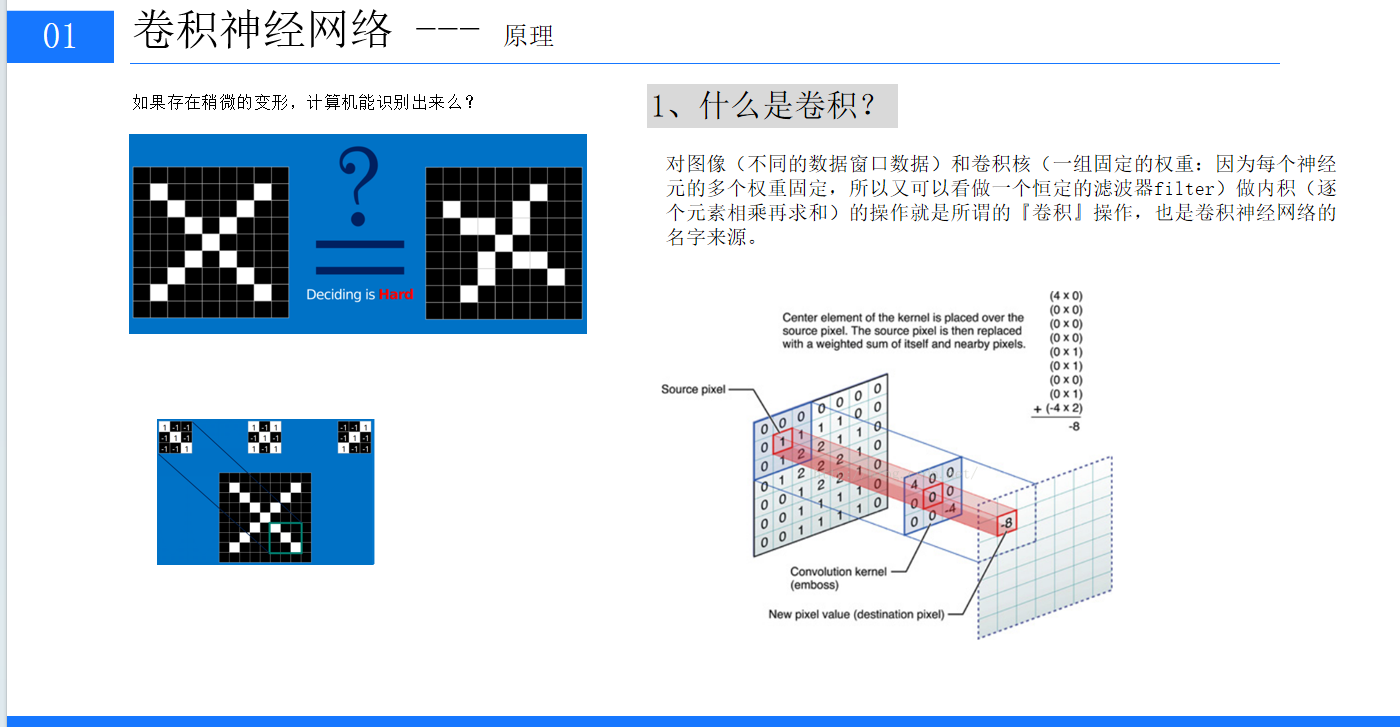
2、卷積層是 CNN 的核心組成部分,負責對輸入圖像進行特征提取。它通過卷積核與輸入圖像進行卷積運算,將圖像與卷積核對應位置的元素相乘并求和,得到卷積結果。例如,一個 3×3 的卷積核在 6×6 的圖像上進行步長為 1 的卷積操作,會生成一個 4×4 的特征圖。卷積層中的參數主要包括卷積核的數量、大小、步長和填充方式,這些參數的設置會直接影響特征圖的尺寸和提取到的特征類型。?
 ?
?
?3、激活函數層:為了引入非線性因素,使網絡能夠學習到復雜的函數關系,在卷積層之后通常會連接激活函數層。常見的激活函數有 ReLU(Rectified Linear Unit)、Sigmoid、Tanh 等。以 ReLU 函數為例,其公式為 f (x) = max (0, x),它能夠有效緩解梯度消失問題,加快網絡的訓練速度,并且計算簡單,在現代 CNN 模型中被廣泛應用。
4、池化層:池化層的主要作用是對特征圖進行下采樣,降低數據的維度,減少計算量,同時還能增強模型的魯棒性。常見的池化操作有最大池化(Max Pooling)和平均池化(Average Pooling)。最大池化會選取池化窗口內的最大值作為輸出,能夠保留最顯著的特征;平均池化則計算池化窗口內的平均值,對特征進行平滑處理。例如,在一個 2×2 的最大池化窗口下,4×4 的特征圖會被下采樣為 2×2 的特征圖。
 ?
?
5、全連接層:經過多層卷積和池化操作后,網絡提取到的特征被展平并輸入到全連接層。全連接層中的每個神經元都與上一層的所有神經元相連,它將提取到的特征進行整合,并通過激活函數進行非線性變換,最終輸出分類結果或回歸值。在圖像分類任務中,全連接層的輸出節點數量通常等于類別數,例如在 MNIST 手寫數字識別任務中,全連接層的輸出節點數為 10,分別對應 0 - 9 這 10 個數字類別。?
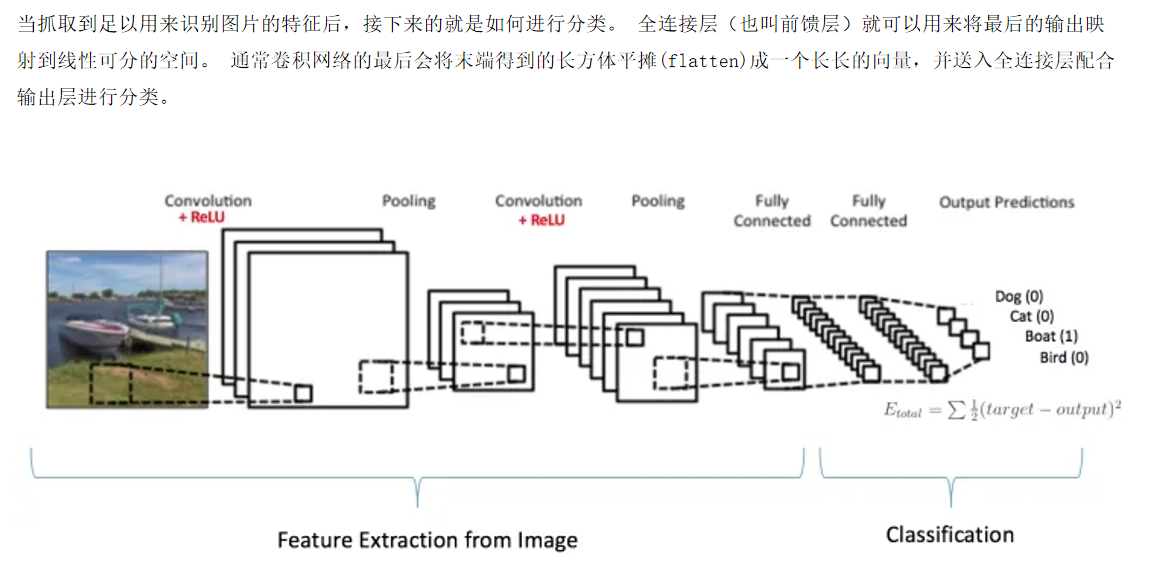 ?
?
6、輸出層:輸出層根據具體的任務類型進行設計。在分類任務中,通常使用 Softmax 函數作為激活函數,將全連接層的輸出轉換為每個類別的概率分布,概率最大的類別即為預測結果;在回歸任務中,輸出層直接輸出連續的數值
三、案例實現?
1、環境準備與數據加載
在開始之前,我們需要安裝 PyTorch 和 torchvision。PyTorch 是一個強大的深度學習框架,而 torchvision 提供了許多與圖像相關的數據集和工具。
import torch
from torch import nn #導入神經網絡模塊,
from torch.utils.data import DataLoader #數據包管理工具,打包數據,
from torchvision import datasets #封裝了很多與圖像相關的模型,數據集
from torchvision.transforms import ToTensor #數據轉換,張量,將其他類型的數據轉換為tensor張量?2、下載MNIST數據集
'''下載訓練數據集(包含訓練圖片+標簽)'''
training_data=datasets.MNIST(root='data', #表示下載的手寫數字 到哪個路徑。60000train=True, #讀取下載后的數據 中的 訓練集download=True, #如果你之前已經下載過了,就不用再下載transform=ToTensor(), #張量,圖片是不能直接傳入神經網絡模型
) #對于pytorch庫能夠識別的數據一般是tensor張量。'''下載測試數據集(包含訓練圖片+標簽)'''
test_data=datasets.MNIST(root='data', #表示下載的手寫數字 到哪個路徑。60000train=False, #讀取下載后的數據中的訓練集download=True, #如果你之前已經下載過了,就不用再下載transform=ToTensor(), #Tensor是在深度學習中提出并廣泛應用的數據類型
) #NumPy數組只能在CPU上運行。Tensor可以在GPU上運行,這在深度學習應用中可以顯著提高計算速度
print(len(training_data))
3、數據可視化?
'''展示手寫字圖片,把訓練數據集中的前59000張圖片展示一下'''
from matplotlib import pyplot as plt
figure = plt.figure()
for i in range(9):img,label=training_data[i+59000]#提取第59000張圖片figure.add_subplot(3,3,i+1)#圖像窗口中創建多個小窗口,小窗口用于顯示圖片plt.title(label)plt.axis("off") # plt.show(I)#是示矢量,plt.imshow(img.squeeze(),cmap="gray") #plt.imshow()將Numpy數組data中的數據顯示為圖像,并在圖形窗口中顯貢a = img.squeeze()# img.squeeze()從張量img中去掉維度為1的。如果該維度的大小不為1則張量不會改變。#cmap="gray
plt.show()4、創建數據加載器和配置設備?
"""創建數據DataLoader(數據加載器)
batch_size:將數據集分成多份,每一份為batch_size個數據
優點:可以減少內存的使用,提高訓練速度。"""train_dataloader=DataLoader(training_data,batch_size=64)
test_dataloader=DataLoader(test_data,batch_size=64)for X, y in test_dataloader:#X時打包的的每一個數據包print("Shape of X [N, C, H, W]: {X.shape}")print(f"shape of y: {y.shape} {y.dtype}")break'''斷當前設備是否支持GPU,其中mps是蘋果m系列芯片的GPU。'''
device = "cuda" if torch.cuda.is_available() else "mps" if torch.backends.mps.is_available() else "cpu"
print(f"Using {device} device") #字符串的格式化
?5、搭建神經網絡模型?
'''定義神經網絡 類的繼承'''
class CNN(nn.Module):#類的名稱def __init__ (self): #python基礎關于類,self類自已本身super(CNN,self).__init__() #繼承的父類初始化self.conv1 = nn.Sequential( #將多個層組合成一起,創建了一個容器,將多個網絡合在一起nn.Conv2d( #2d一般用于圖像,3d用于視頻數據(多一個時間維度),1d一般用于結構化的序列數據in_channels=1, #圖像通道個數,1表示灰度圖(確定了卷積核 組中的個數)out_channels=16, # 要得到多少個特征圖,卷積核的個數kernel_size=5, # 卷積核大小,5*5stride=1, # 步長padding=2, #一般希望卷積核處理后的結果大小與處理前的數據大小相同,效果會比較好。那padding改如何), # 輸出的特征圖為(16,28,28)nn.ReLU(), # 激活函數,relu層,不會改變特征圖的大小(16,28,28)nn.MaxPool2d(kernel_size=2), #池化層,進行池化操作(2x2 區域),輸出結果為:(16,14,14))self.conv2 = nn.Sequential( #輸入(16, 14, 14)nn.Conv2d(16,32,5,1,2), # 輸出(32,14,14)nn.ReLU(), # (32*14*14)#nn.Conv2d(32, 32, 5, 1, 2), # 輸出(32,14,14)nn.ReLU(), #(32 14 14)nn.MaxPool2d(2), #輸出(32,7,7))self.conv3 = nn.Sequential( #輸入(32 7 7)nn.Conv2d(32,64,5,1,2), #(64,7,7)nn.ReLU(),)self.out=nn.Linear(64*7*6,10) #全連接層得到的結果def forward(self,x): #這里必須要寫 forward是來自于父類nn里面的函數 要繼承父類的功能x=self.conv1(x)x=self.conv2(x)x=self.conv3(x) #輸出(64,64,7,7)x=x.view(x.size(0),-1)#把x的數據變成2維的output=self.out(x)return outputmodel = CNN().to(device)#類的初始化完成,就會創建一個對象,model
print(model)
定義了一個繼承自nn.Module的CNN類,用于構建卷積神經網絡模型。模型包含多個卷積層、激活函數層和池化層:
conv1層:首先通過nn.Conv2d進行卷積操作,將輸入的 1 通道圖像轉換為 16 個特征圖;然后使用nn.ReLU激活函數引入非線性;最后通過nn.MaxPool2d進行最大池化操作,降低數據維度。
conv2層:包含兩個卷積層和激活函數層,進一步提取圖像特征,并通過池化操作降低維度。
conv3層:進行卷積和激活操作,繼續提取更高級的特征。
out層:全連接層,將卷積層輸出的特征圖展平后映射到 10 個類別(對應 0 - 9 這 10 個數字)。
.forward方法定義了數據在模型中的前向傳播過程,確保數據按照正確的順序通過各個層。
?6、模型訓練與測試
def train(dataloader,model,loss_fn,optimizer):model.train() #告訴模型,現在要進入訓練模式,模型中w進行隨機化操作,已經更新w。在訓練過程中,w會被修改的
#pytorch提供2種方式來切換訓練和測試的模式,分別是:model.train()和 model.eval()。
#一般用法是:在訓練開始之前寫上model.trian(),在測試時寫上 model.eval()batch_size_num=1for X,y in dataloader: #其中batch為每一個數據的編號X,y=X.to(device),y.to(device) #把訓練數據集和標簽傳入cpu或GPUpred=model.forward(X) #.forward可以被省略,父類中已經對次功能進行了設置。自動初始化loss=loss_fn(pred,y) #通過交叉熵損失函數計算損失值loss# Backpropagation 進來一個batch的數據,計算一次梯度,更新一次網絡optimizer.zero_grad() #梯度值清零loss.backward() #反向傳播計算得到每個參數的梯度值woptimizer.step() #根據梯度更新網絡w參數loss_value=loss.item() #從tensor數據中提取數據出來,tensor獲取損失值if batch_size_num %100 ==0:print(f'loss:{loss_value:>7f} [number:{batch_size_num}]')batch_size_num+=1def test(dataloader,model,loss_fn):size=len(dataloader.dataset)num_batches=len(dataloader) #打包的數量model.eval() #測試,w就不能再更新。test_loss,correct=0,0with torch.no_grad(): #一個上下文管理器,關閉梯度計算。當你確認不會調用Tensor.backward()的時候。for X,y in dataloader:X,y=X.to(device),y.to(device)pred=model.forward(X)test_loss+=loss_fn(pred,y).item() #test_loss是會自動累加每一個批次的損失值correct+=(pred.argmax(1)==y).type(torch.float).sum().item()a=(pred.argmax(1)==y) #dim=1表示每一行中的最大值對應的索引號,dim=0表示每一列中的最大值b=(pred.argmax(1)==y).type(torch.float)test_loss /=num_batchescorrect /=sizeprint(f'Test result: \n Accuracy: {(100*correct)}%, Avg loss: {test_loss}')7、定義損失函數和優化器?
loss_fn=nn.CrossEntropyLoss() #創建交叉熵損失函數對象,因為手寫字識別中一共有10個數字,輸出會有10個結果
optimizer=torch.optim.Adam(model.parameters(),lr=0.01) #創建一個優化器
# #params:要訓練的參數,一般我們傳入的都是model.parameters()
# lr:learning_rate學習率,也就是步長nn.CrossEntropyLoss是交叉熵損失函數,適用于多分類任務,用于計算模型預測結果與真實標簽之間的差距。torch.optim.Adam是一種常用的優化器,用于更新模型的參數,以最小化損失函數。lr=0.01設置學習率,控制參數更新的步長。?
6、模型訓練與測試流程
epoch=9
for i in range(epoch):print(i+1)train(train_dataloader, model, loss_fn, optimizer)test(test_dataloader,model,loss_fn)通過循環進行多個 epoch 的訓練,每個 epoch 都會調用train函數對模型進行訓練,訓練完成后調用test函數對模型在測試集上的性能進行評估。隨著訓練的進行,可以觀察到損失值逐漸降低,準確率逐漸提高,最終得到一個在 MNIST 數據集上表現良好的手寫數字識別模型。
四、總結
本文詳細介紹了利用 PyTorch 構建卷積神經網絡實現 MNIST 手寫數字識別的全過程。從數據集的準備、模型的構建,到訓練和測試的各個環節,都進行了深入的代碼解析和原理講解。通過實踐,我們可以看到卷積神經網絡在圖像識別任務中的強大能力,同時也掌握了 PyTorch 框架的基本使用方法。希望本文能夠幫助讀者更好地理解和應用卷積神經網絡,在深度學習領域不斷探索前進。?








![青少年編程與數學 02-018 C++數據結構與算法 10課題、搜索[查找]](http://pic.xiahunao.cn/青少年編程與數學 02-018 C++數據結構與算法 10課題、搜索[查找])
Linux基礎指令(上))



:PPO 原理與實踐)

)



