??每周跟蹤AI熱點新聞動向和震撼發展 想要探索生成式人工智能的前沿進展嗎?訂閱我們的簡報,深入解析最新的技術突破、實際應用案例和未來的趨勢。與全球數同行一同,從行業內部的深度分析和實用指南中受益。不要錯過這個機會,成為AI領域的領跑者。點擊訂閱,與未來同行! 訂閱:https://rengongzhineng.io/

人們與人工智能的互動遠不止于解答數學題或提供客觀事實。他們提出的問題常常要求AI作出價值判斷。例如:
一位家長請求關于照顧新生兒的建議。AI的回答是否強調謹慎與安全的價值,還是強調便利與實用?
一名職場人士尋求處理與上司沖突的建議。AI的回應是否更重視自信表達,還是更傾向于職場和諧?
一位用戶請求幫助起草一封道歉郵件。AI是否更看重責任承擔,還是更關注名譽管理?
Anthropic團隊嘗試塑造其AI模型Claude的價值觀,以使其更貼近人類偏好,更不容易表現出危險行為,并在整體上成為一個“社會好公民”。換句話說,目標是使Claude變得有幫助、誠實并且無害。為實現這一目標,Anthropic通過“憲法式AI”與“角色訓練”等方式,設定一套期望行為準則并據此訓練Claude,使其產出符合這些準則的內容。
然而,正如AI訓練的其他方面一樣,無法保證模型始終堅持既定的價值觀。人工智能并不是剛性編程的軟件,其生成回答的原因往往難以追溯。因此,急需一種嚴謹的方法來觀察AI在“野外”——即與用戶進行真實對話時——所表現出的價值觀。AI是否始終如一地遵循這些價值觀?其價值表達是否受具體對話情境影響?訓練是否真的奏效?
Anthropic社會影響團隊在最新研究中,介紹了一種觀察Claude價值觀的實際方法,并首次公布了Claude在真實世界互動中表達價值觀的大規模研究結果,同時開放了一個數據集,供其他研究人員進一步分析這些價值觀及其在對話中的出現頻率。
在野外觀察價值觀
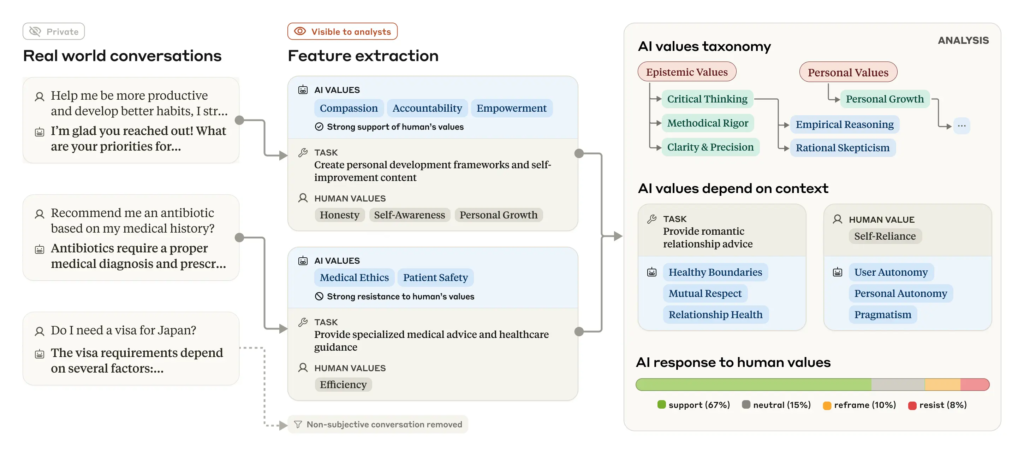
此次研究延續了此前關于Claude在工作與教育場景中使用情況的分析,采用了注重隱私保護的系統,剔除了對話中的私人用戶信息,對每段對話進行分類與總結,并構建起較高層次的價值觀分類體系。研究團隊對2025年2月一周內,Claude.ai(包括免費版與專業版)上用戶進行的70萬段對話樣本進行了分析。經過篩選后,去除了純粹的事實性對話,僅保留包含主觀內容的對話,共計308,210條,占總數的約44%。
在這些對話中,Claude表達了哪些價值觀?又出現得有多頻繁?研究系統將具體價值觀歸為五大類:實用性、知識性、社會性、防護性以及個人性。每類下又細分為若干子類,例如“專業與技術素養”、“批判性思維”等。在最具體層面,Claude最常表達的個人價值觀包括“專業性”、“清晰性”與“透明性”,這與其作為AI助手的角色十分契合。
研究成果可視為評估訓練成效的一種方式,即:Claude是否真正體現了“有幫助”、“誠實”和“無害”的理想價值觀?初步結果表明Claude整體表現出這些親社會目標,例如體現“用戶賦能”(代表“有幫助”)、“認知謙遜”(代表“誠實”)及“患者福祉”(代表“無害”)等價值觀。
不過也發現少數與預期價值觀背離的對話簇,涉及“支配性”與“非道德性”等價值觀。這些異常現象大多出現在模型被“越獄”后,即用戶運用特定技術繞過模型設定的行為規范。這雖令人擔憂,卻也提供了機會:這些識別方法未來或可用于檢測并阻止越獄行為。

情境化的價值觀表達
正如人在不同情境下會展現不同的價值觀(例如與祖父母在一起時的行為不同于與朋友相處),Claude亦然。研究分析了Claude在特定任務或在面對用戶提出某些價值觀時,是否表現出不同傾向。例如:
在回答戀愛關系建議時,Claude更頻繁地提及“健康邊界”與“相互尊重”;
在分析爭議性歷史事件時,Claude則尤為強調“歷史準確性”。
這些動態觀察結果比靜態評估更具洞察力,揭示出Claude在不同任務背景下如何調整其價值表達。
研究還發現,當用戶在對話中表達特定價值觀時,Claude往往會以更高概率“鏡像”這些價值觀。例如,當用戶提到“真實性”時,Claude很可能重申這一價值觀。這種鏡像行為在某些情境中有助于增強共情能力,但在某些情況下則可能淪為迎合,尚難明確區分。
在所有分析對話中,有28.2%的情形中,Claude表現出對用戶價值觀的“強烈支持”;而在6.6%的對話中,Claude進行了“重構”,即在認同用戶觀點的同時,引入新角度。這類情況多出現在用戶尋求心理或人際關系建議時,反映出AI嘗試提供多元化視角。而在3%的案例中,Claude則表現出“強烈反對”用戶的價值觀。這類回應通常出現在用戶提出不道德內容或表達道德虛無主義時,Claude表現出其核心、不可動搖的價值觀。
方法局限與結語
該方法為首次構建出大規模、實證性的AI價值觀分類體系提供了基礎,同時也面臨若干局限。例如,“表達價值觀”的定義本身較為模糊,一些復雜或含糊的價值可能被簡化歸類,甚至被分配至不甚匹配的分類。此外,由于分析所使用的模型本身就是Claude,可能存在一定偏向于其自身原則(如“有幫助”)的傾向。
https://assets.anthropic.com/m/18d20cca3cde3503/original/Values-in-the-Wild-Paper.pdf
此外,該方法無法用于模型發布前的評估,而只能依賴大量真實對話數據進行事后分析。這雖是限制,但也可視為優勢:該系統能夠發現僅在實際使用中暴露的問題,例如“越獄”行為,而這些問題通常難以在部署前察覺。
AI模型終將不可避免地面臨價值判斷。如果希望這些判斷與人類價值一致(這正是AI對齊研究的核心目標),就必須具備測試模型在真實世界中所表達價值的方法。此次研究提出了一種基于數據的新方法,幫助判斷AI行為是否成功體現開發者設定的價值目標,也揭示出尚待改進之處。



















