摘要
本畢業生數據分析與可視化系統采用B/S架構,數據庫是MySQL,網站的搭建與開發采用了先進的Java語言、爬蟲技術進行編寫,使用了Spring Boot框架。該系統從兩個對象:由管理員和用戶來對系統進行設計構建。主要功能包括:用戶管理、職位信息管理、系統簡介管理。本系統在一般畢業生數據分析與可視化系統的基礎上增加了數據爬取功能,方便管理員一鍵爬取職位信息,非常方便。 本系統采用的數據庫是MySQL,使用Java技術開發。在設計過程中,很好地發揮了該開發方式的優勢,讓實現代碼有了良好的可讀性,而且使代碼的更新和維護更加的方便,操作方便,對以后的維護減少了很多麻煩。系統的順利開發和實現,對于畢業生數據分析與可視化系統管理這一方面提供巨大的便利服務,無論是用戶還是管理員,都帶來了極大的便利,方便大眾,為社會的進步與發展提供了一些動力。
緒論
1.1背景及意義 隨著社會的快速發展,計算機的影響是全面且深入的。目前,社會的各種類型的網站越來越多,但是有些類型的網站附加了太多的商業元素和虛假信息,而且,用戶在搜索相關信息時需訪問多個網站和大量垃圾廣告,這無疑影響了信息搜索效率且降低了用戶的使用體驗,使用戶很難快速地瀏覽或查詢到自己所需要的相關信息。電子計算機在現代管理中的應用使電子、計算機變成了人類運用現代信息技術的主要工具。可以更高效的處理人類獲取信息中精細化、全面化的問題,從而提高了效率[2]。本系統使用具有獨特且和資源相對優勢的管理方式,來提供一個優秀的畢業生數據分析與可視化系統,用戶可以在網站瀏覽職位信息,進行個人信息和密碼等操作。而隨著互聯網的應用,互聯網也以一種巨大變革力的新形象出現于商務關系領域。 探究根本課題,就是希望能夠實現用戶和所需信息雙方的雙向選擇,便于用戶查找相應信息的同時也可以節省管理員在管理中花費的人力和物力。
1.2 國內外研究概況 在當前飛速發展的時代,無論是國內還是國外,發展都是突飛猛進的,經濟形勢也是一片明朗。在這種背景下,互聯網的這一塊的市場成為了各個國家想要爭奪的香餑餑。于是無論是國內還是國外一些公司把目光投向了互聯網這塊市場,越來越多的人對互聯網有所了解,具備了一些網絡意識。在這種互聯網大浪潮的不斷沖刷下,各種各樣的系統被開發出來。計算機技術無論是在國內還是國外中應用普遍,使計算機這一新型工具成為人們耳熟能詳、婦孺皆知的新技術。計算機和互聯網的廣泛應用,讓國內外的距離變“近”了,這個龐大的地球家園一下變成了地球村。國內國外的互聯網發展也存在一些差距,我國近些年的互聯網發展迅速,躋身于世界前列。 本系統采用B/S架構、采用的數據庫是MySQL,使用Java語言和爬蟲技術進行開發。該系統的開發方式無論在國內還是國外都比較常見,而且開發完成后使用普遍,可以給用戶提供大量的便利[3]。該系統在國內外前景較為良好。
1.3 研究的內容 畢業生數據分析與可視化系統是一個便于用戶瀏覽職位信息而進行管理的平臺。因此本文主要闡述了系統實現的功能和完整開發的過程,結合Web開發技術實現了一個畢業生數據分析與可視化系統。本系統以軟件工程理論作為開發的理論基礎,[4]以專業的計算機編程語言實現系統的功能與開發。 該選題原則上力求采用標簽模塊分類等方法,來完成注冊、登錄、對職位信息管理、對頁面的設置和對后臺數據庫中數據的增刪查改等一系列的操作和運行等。在這一系列模塊分類的功能下,達到對畢業生數據分析與可視化系統信息的高效執行和規范管理。
相關技術
2.1 Java簡介 Java主要使用了CORBA技術和安全模型,主要是在網絡使用的信息保障上。它還帶來了對EJB(Enterprise Java Beans)的完全支援[6],Java SERVLET API,JSP(Java Server Pages),還有XML技術等多進步。因此,當在打開蜘蛛紙牌休閑一下玩游戲時,還可以打開一個音樂播放器來播放自己想要聽的歌,于是,既可以一遍玩蜘蛛紙牌放松,也可以挑選播放自己想要聽的歌,兩者來回切換,兩者同時進行無需等待。因為似乎他們都在自己的主機上一起為自己工作。但事實是,對于某個CPU來說,它只是在特定時點進行了某個程序。CPU在這些程序中間,不斷地“跳躍”。而為何人們卻看不到什么破壞呢?這是因為,和人的感應一樣,它的速度太快了。所以,即使人們發現一些同步操作,其實對電腦而言,也只是在特定時點運行了某個進程,除非的電腦是多CPU的。
2.2 Spring Boot框架 現如今后臺開源框架主流的有SSH、SSM、Spring Boot,但是SSH、SSM框架的環境配置項較多,而Spring Boot主要的設計思想就是約定大于配置,故而SpingBoot在設計時幾乎達到零配置。Spring Boot整合了業界上的開源框架。具體采用技術框架描述如下: (1)Mybatis:Mybatis:提供自動映射,動態SQL,級聯,緩存,注解,代碼和SQL分離等特性,使用方便,同時也對SQL進行優化[10]。 (2)SpringMVC:通過一套MVC注解,讓POJO成為處理請求的控制器,無需實現任何接口,同時,SpringMVC還支持REST風格的URL請求[11]。 (3)Spring Boot:從本質上來說,Spring Boot就是Spring,它做了那些沒有它你也會去做的Spring Bean配置[12]。 Spring Boot是一款非常強大后臺框架,因為Spring Boot開發時可以基本不用寫配置文件,所以使用Spring Boot搭建網站的后臺環境,在Spring Boot的yml配置文件中寫入項目啟動端口,項目就可以啟動。項目的Java文件還有靜態文件都是由Spring Boot來管理。
2.3 Idea開發環境 IDEA 全稱IntelliJ IDEA,是用于java語言開發的集成環境(也可用于其他語言),IntelliJ在業界被公認為最好的java開發工具之一,尤其在智能代碼助手、代碼自動提示、重構、J2EE支持、Ant、JUnit、CVS整合、代碼審查、 創新的GUI設計等方面的功能可以說是超常的[7]。 2.4 爬蟲技術 網絡爬蟲是一種很好的自動采集數據的通用手段。它主要分為4種類型,分別是:聚焦網絡爬蟲、增量抓取、表層網頁、深層網頁。 ①聚焦網絡爬蟲是“面向特定主題需求”的一種爬蟲程序,而通用網絡爬蟲則是捜索引擎抓取系統(Baidu、Google、Yahoo等)的重要組成部分,主要目的是將互聯網上的網頁下載到本地,形成一個互聯網內容的鏡像備份。 ②增量抓取意即針對某個站點的數據進行抓取,當網站的新增數據或者該站點的數據發生變化后,自動地抓取它新增的或者變化后的數據。
Web頁面按存在方式可以分為表層網頁(surface Web)和深層網頁(deep Web,也稱invisible Web pages或hidden Web)。 ③表層網頁是指傳統搜索引擎可以索引的頁面,即以超鏈接可以到達的靜態網頁為主來構成的Web頁面。 ④深層網頁是那些大部分內容不能通過靜態鏈接獲取的、隱藏在搜索表單后的,只有用戶提交一些關鍵詞才能獲得的Web頁面。 本次使用的爬蟲技術是聚焦網絡爬蟲,通過搜索引擎,抓取相關信息,下載到本地,形成互聯網內容的鏡像備份,提供用戶瀏覽、查看。
2.5 MySQL數據庫 MySQL是一種關系型的數據庫管理系統,屬于Oracle旗下的產品。MySQL的語言是非結構化的,使用的用戶可以在數據上進行工作。這個數據庫管理系統一經問世就受到了社會的廣泛關注。在各個方面,與同等的數據庫相比,MySQL的優點極為突出,它的運行速度快,適用的范圍廣泛,而且數據庫的安全性這一方面獨樹一幟。在語言a結構方面,MySQL的語言簡單,其他數據庫需要一大段代碼來實現的操作,MySQL僅需要一小部分代碼甚至幾行。綜上所述,MySQL這種關系型數據庫管理系統,已經成為了開發者進行項目的數據開發、存儲的不二之選。MySQL的功能也多種多樣,如數據操縱和數據庫的建立維護等。而且該數據庫的數據共享性高、冗余度低而且容易擴充。MySQL在安全性這一方面也具有自身的特點,它應用了用戶的標識和鑒別技術,對試圖和數據進行加密,確保資料信息的可靠性。介于數據庫系統的功能與強大等性質之間,本數據庫系統的設計中主要使用了MySQL實現對數據的處理。基于Web的基于Hadoop的畢業生數據分析與可視化系統運用MySQL數據庫,在Web應用這一塊,MySQL是最好的選擇。對于該系統整個的開發、搭建、運行和維護具有極其重要的作用[9]。
系統整體功能圖
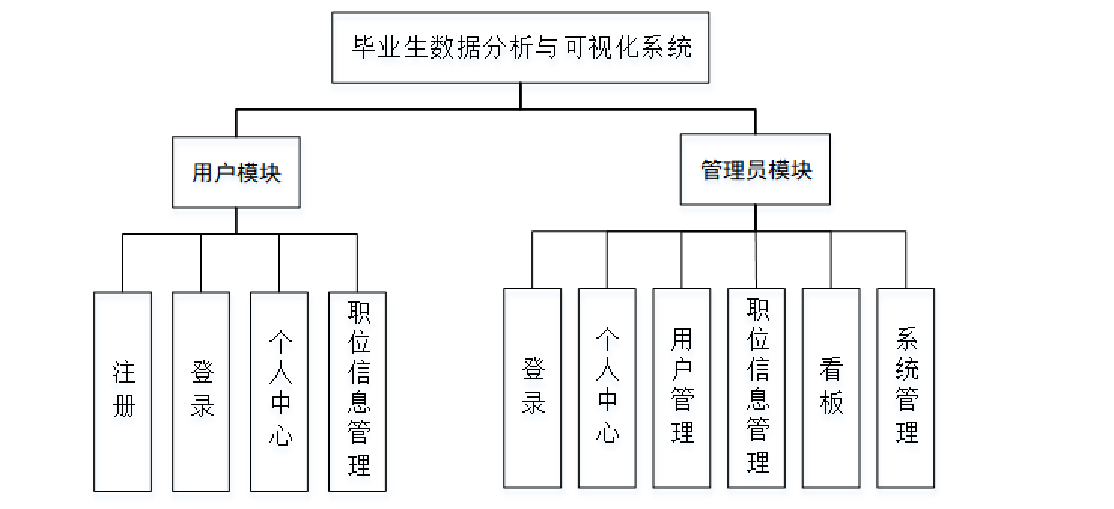
用戶注冊界面圖
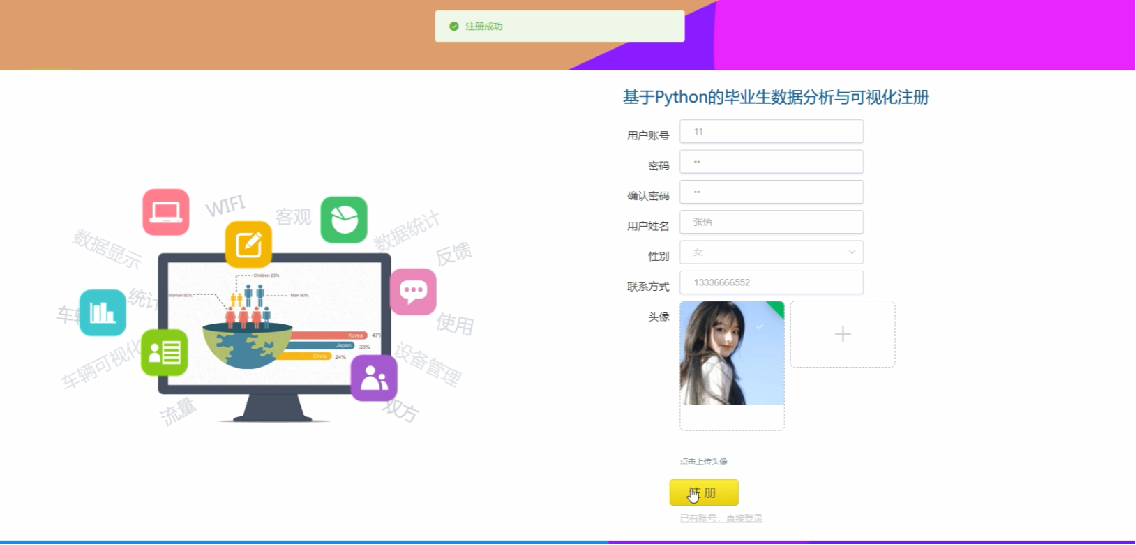
用戶登錄界面圖
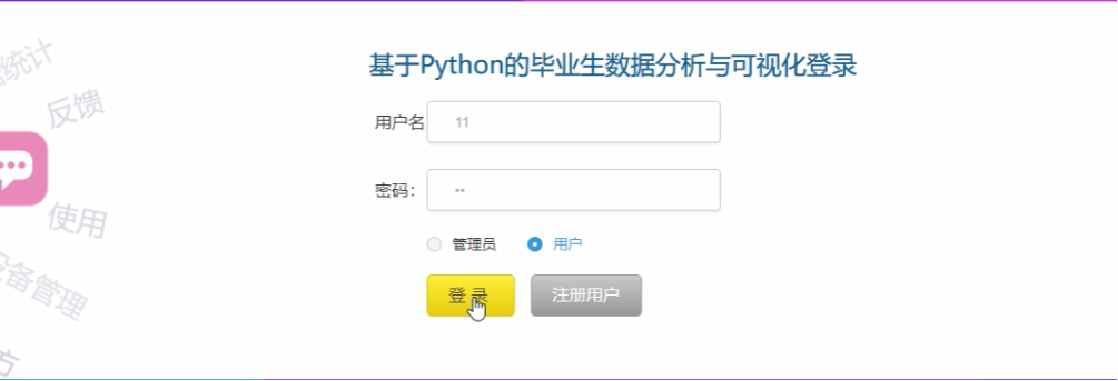
用戶功能界面圖
管理員功能界面圖
看板界面圖
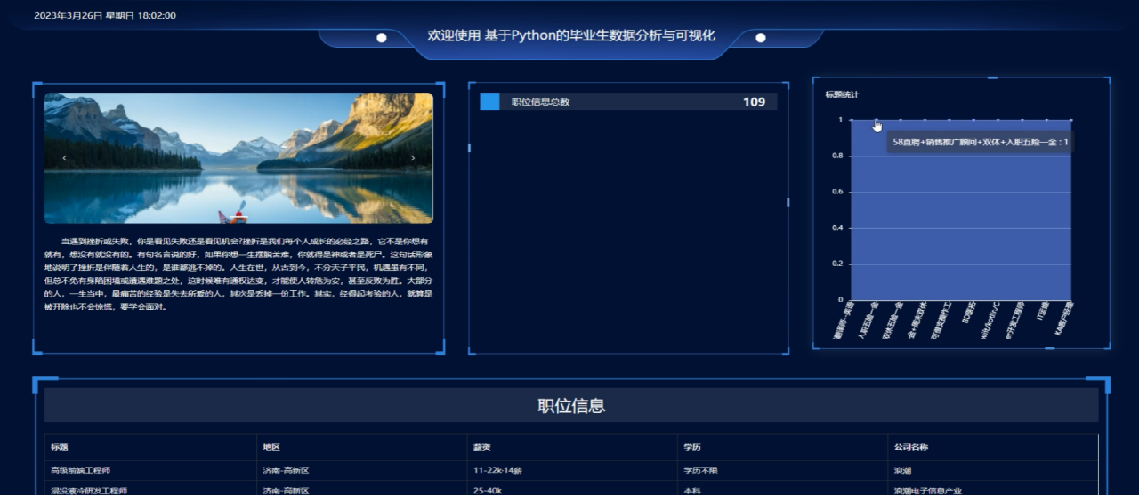
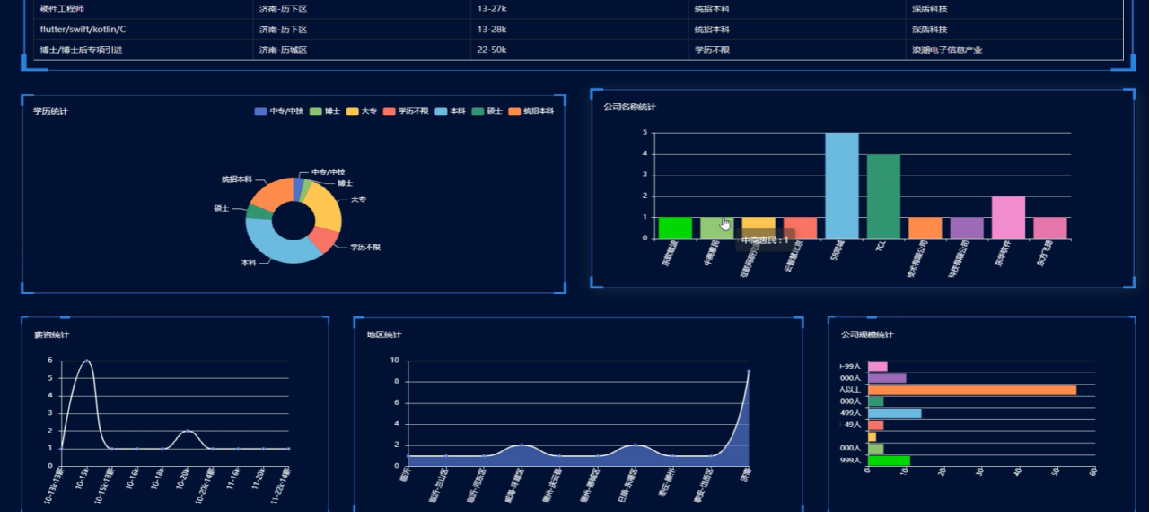
看板界面圖
部分數據庫表
| 字段名稱 | 類型 | 長度 | 字段說明 | 主鍵 | 默認值 |
| id | bigint | 主鍵 | 主鍵 | ||
| addtime | timestamp | 創建時間 | CURRENT_TIMESTAMP | ||
| laiyuan | longtext | 4294967295 | 來源 | ||
| biaoti | varchar | 200 | 標題 | ||
| dq | varchar | 200 | 地區 | ||
| xinzi | varchar | 200 | 薪資 | ||
| jingyan | varchar | 200 | 經驗 | ||
| xueli | varchar | 200 | 學歷 | ||
| gsmc | varchar | 200 | 公司名稱 | ||
| gsgm | varchar | 200 | 公司規模 | ||
| suoshuhangye | varchar | 200 | 所屬行業 |
結論
經過這幾個月的努力,在老師和同學的幫助與指導下,對系統順利完成。對于該系統的研究和開發雖然沒有耗費大量的時間,但為了成功完成該畢業生數據分析與可視化系統,消耗了大量的精力和汗水去了解學習這方面涉及到的專業知識以及開發環境的應用。 該系統的設計與實現,是經過了很長時間的分析、觀察、調研和研究分析并整理資料實施的。畢業生數據分析與可視化系統采用B/S架構、Java開發語言、爬蟲技術、Spring Boot框架以及MySQL數據庫等技術開發與設計。該系統主要分為用戶和管理員個角色。用戶的主要功能為向注冊、登錄的用戶展示職位信息,用戶可以修改個人信息和登錄密碼,并對一些數據進行記錄。后端管理員的主要任務是爬取職位信息,管理用戶、系統信息等。每個功能在完成各自任務的同時也相互合作,一起來處理各個任務以及進程。 盡管該系統對用戶可以滿足一些基本的畢業生數據分析與可視化系統的需求,但該系統還存在尋多問題和有待完善的地方。主要分為以下兩點:
(1)該畢業生數據分析與可視化系統的適用面比較局限。頁面的設置還是過于繁瑣,不夠簡潔。加上社會方面的飛速發展,用戶的條件也在發生新的變化。該系統還存在大數據下的并發和并行操作的不穩定性,當一個時間段內或者同一時刻時,過量的用戶訪問該網站會讓網站的服務器出現崩潰的現象,一些操作無法正常的運行。種種原因使得該系統存在一些局限性。 (2)需要人工來處理的數據模塊太多,需要減少大量的人工操作。在對畢業生數據分析與可視化系統信息處理的程序中,難免會出現各種各樣的錯誤數據或者是異常數據,一旦這些數據大量積累存在過多時,系統自我調節修復能力有限就不得不需要人工的干預了。但是人工如果經常去進行操作的話,就會造成該系統的運行速度變慢,對其余正確的數據產生干擾,而且有可能對正確數據的損害以及泄露,從而將會減少該系統的穩定性。對于人力和財力都造成了不必要的浪費。 從上述可以看出該畢業生數據分析與可視化系統還有很多不足之處,在日后要結合具體項目問題進行修改和研究。






顏色空間轉換-----將 NV12 格式的圖像數據轉換為 BGR 顏色空間函數NV12toBGR())

![Linux[基本指令]](http://pic.xiahunao.cn/Linux[基本指令])
,抓取和拉取,推送(注意點,抓取更新+合并的三種方法,解決沖突,對比),移除)

問題深度解析與實戰調優)




)

)
