知識來源沉默王二、小林coding、javaguide
1、ArrayList
list.add("66")? ? ? list.get(2)? ? ? list.remove(1)? ? ? list.set(1,"55")
List<String> list=new ArrayList<>();? ?底層是動態數組
添加元素流程:判斷是否擴容,無需擴容則直接加元素。否則計算新容量與10比較,取較大值,然后執行grow()方法,擴容至原來的1.5倍,如果還不夠則擴到指定容量,調用Arrays.copyOf方法最后回到add函數里面。返回boolean
設置元素流程:檢查索引越界,然后替換新值并返回舊值。
刪除元素流程:(下標刪除)檢查索引越界,移動元素使用Syetem.arraycopy(),最后size--,末尾為null讓GC回收,返回刪除的元素。(元素刪除)根據是否為null來分別判斷,null用==,其它用equals方法,返回boolean
查找元素流程:根據是否為null來分別判斷,null用==,其它用equals方法,返回元素索引,未找到為-1
list.add(1,"66")
list.remove("66")
list.indexOf("66")
list.lastIndexOf("66")
2、LinkedList
LinkedList<String> list = new LinkedList();? ?底層是鏈表實現的?
list.add("33")? ? list.addFirst("11")? ?list.addLast("33")??
remove(int):刪除指定位置的節點remove(Object):刪除指定元素的節點- set(0,"33")
- indexOf(Object):查找某個元素所在的位置
- get(int):查找某個位置上的元素
poll()?方法用于刪除并返回第一個元素peekFirst()?方法用于返回但不刪除第一個元素。
3、HashMap
put(1,"11")//增加或修改
remove("1")//刪除
get(1) //查詢
HashMap 是通過拉鏈法來解決哈希沖突的,也就是當哈希沖突時,會將相同哈希值的鍵值對通過鏈表的形式存放起來,采用的是頭插法。
hash方法:hash 方法是用來做哈希值優化的,把哈希值右移 16 位之后與原哈希值做異或運算,增大了隨機性。其中調用了鍵的hashcode方法
擴容機制:
當我們往 HashMap 中不斷添加元素時,HashMap 會自動進行擴容操作(條件是元素數量達到負載因子(load factor)乘以數組長度時),以保證其存儲的元素數量不會超出其容量限制。在進行擴容操作時,HashMap 會先將數組的長度擴大一倍,然后將原來的元素重新散列到新的數組中。由于元素的位置是通過 key 的 hash 和數組長度進行與運算得到的,因此在數組長度擴大后,元素的位置也會發生一些改變。一部分索引不變,另一部分索引為“原索引+舊容量”。
加載因子:
HashMap 的加載因子是指哈希表中填充元素的個數與桶的數量的比值,當元素個數達到負載因子與桶的數量的乘積時,就需要進行擴容。這個值一般選擇 0.75,是因為這個值可以在時間和空間成本之間做到一個折中,使得哈希表的性能達到較好的表現。因為容量是2的n次冪,所以與加載因子乘積后最好是整數,而0.75最合適。
4、ArrayDeque、PriorityQueue
ArrayDeque<String> stack = new ArrayDeque<>();?
offer("6")
String top = stack.peek();? ?//獲取
String pop = stack.poll();? ? //出隊
PriorityQeque:堆
PriorityQueue<String> queue = new PriorityQueue<>();
peek()? ??
offer("s")
poll()? ??
5、HashSet
HashSet<String> set = new HashSet<>();?
set.add("陳清揚");
boolean containsWanger = set.contains("王二");
boolean removeWanger = set.remove("王二");
修改=增加+刪除
6、Java面試算法常用api?
?算法題常用語法(Java篇) - 知乎
Java常用函數總結_java函數-CSDN博客
List<String> rets1 = new ArrayList<>(Arrays.asList(intro));
Arrays.sort()
Arrays.equals()
String[] revised = Arrays.copyOf(intro, 3);
Collections.reverse(list);
Collections.sort(list);
Collections.swap(list, 2,4);
max(Collection coll)
min(Collection coll)
frequency(Collection c, Object o)? ?//返回指定對象出現的頻次
集合通用:
toArray()
size()
isEmpty()
contains()
clear()
數組用nums.length? ? 集合用list.size(),String用length()
面試題
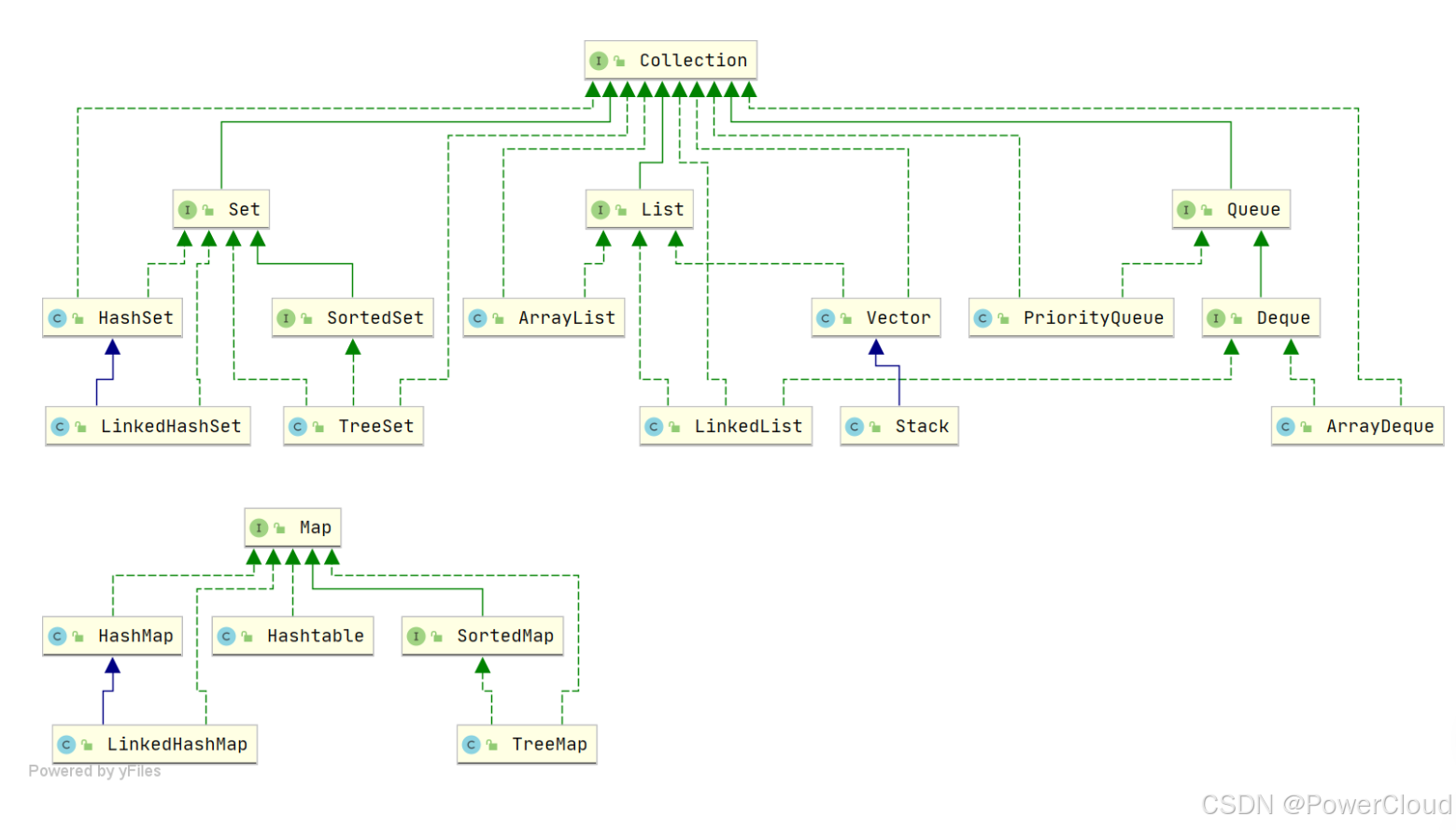
1、 Java集合類有哪些
集合主要有兩條大的支線:
一條是Collection,由List\Set\Queue組成。
List代表有序可重復的集合,有封裝了動態數組的ArrayList,封裝了鏈表的LinkedList
Set代表無序不可重復的集合,主要有HashSet、TreeSet
Queue代表隊列,典型的有雙端隊列ArrayDeque,優先級隊列PriorityDeque
第二條線就是Map,表示鍵值對的集合,主要代表就是HashMap
2、 用過哪些集合類?它們的優劣?
我常用的集合類有 ArrayList、LinkedList、HashMap、LinkedHashMap。
ArrayList 可以看作是一個動態數組,可以在需要時動態擴容數組的容量,只不過需要復制元素到新的數組。訪問速度快但是插入和刪除元素可能需要移動或者復制元素。
LinkedList 是一個雙向鏈表,適合頻繁的插入和刪除操作。缺點是訪問元素時需要遍歷鏈表。
HashMap 是一個基于哈希表的鍵值對集合。可以根據鍵的哈希值快速查找到值,但有可能會發生哈希沖突,并且不保留鍵值對的插入順序。
LinkedHashMap 在 HashMap 的基礎上增加了一個雙向鏈表來保持鍵值對的插入順序
3、隊列和棧說說?有什么區別?
?隊列是先進先出,棧是先進后出的
4、哪些是線程安全的容器,哪些不安全?(后續補充
?Vector:線程安全的動態數組,其內部方法基本都經過synchronized修飾
Hashtable(不推薦):線程安全的哈希表,HashTable 的加鎖方法是給每個方法加上 synchronized 關鍵字,不過現在推薦使用ConcurrentHashMap
還有JUC里有很多線程安全的容器:
ConcurrentHashMap:1.7使用了分段鎖,而1.8 中取消了 Segment 分段鎖,采用 CAS + synchronized 來保證并發安全性,使用了拉鏈法存放沖突節點,當沖突節點超過8時轉為紅黑樹
CopyOnWriteArraySet:是線程安全的Set實現,它是線程安全的無序的集合
CopyOnWriteArrayList:它是 ArrayList 的線程安全的變體,其中所有寫操作(add,set等)都通過對底層數組進行全新復制來實現,允許存儲 null 元素。
ArrayList、LinkedList、HashSet、HashMap: 這些集合類是非線程安全的。在多線程環境中,如果沒有適當的同步措施,對這些集合的并發操作可能導致不確定的結果。
5、ArrayList和Array有什么區別
1、數組創建時必須指定大小且不能更改,而ArrayList是動態數組實現的,會自動擴容
2、數組不支持泛型,ArrayList支持泛型
3、數組元素可以為基本類型也可以為對象,但ArrayList只能為對象
4、ArrayList有豐富的增刪改查的方法,而數組沒有
6、ArrayList和LinkedList區別
?1、ArrayList是基于數組實現的,LinkedList是基于鏈表實現的
2、ArrayList實現了RamdomAccess接口,支持隨機訪問,查找復雜度為O(1),適用于頻繁訪問讀取的場景
而LinkedList不支持隨機訪問,因為他是雙向鏈表,插入刪除效率為O(1),使用于頻繁的增刪場景
3、ArrayList是空間占用少,使用的是連續的內存空間,而LinkedList包含了節點的引用,占用會更多。,一般而言ArrayList性能會更加高一些
7、ArrayList擴容機制
因為它底層是基于數組實現的,所以沒添加元素時它還是個空數組,當添加第一個元素時,默認初始化容量為10.?
當往ArrayList中添加元素時,如果超過當前容量的限制則會進行擴容(如果已經達到了Integer,MAX_VALUE則拋出異常)。擴容是通過一個grow方法,擴容后新數組的長度是原來的1.5倍,如果1.5倍不夠,則直接擴容到當前所需的大小。最后再把原數組的值拷貝到新數組中。
8、有哪幾種實現ArrayList線程安全的方法?
?常用的有兩種
1、使用Collections的synchronizedList,會返回一個線程安全的集合,其內部是通過synchronized加鎖來實現的
2、使用JUC的CopyOnWriteArrayList,使用寫時復制技術,每當對列表進行修改時,都會創建一個新副本,這個新副本會替換舊的列表,而對舊列表的所有讀取操作仍然在原有的列表上進行,這樣并發讀時無需加鎖就實現了線程安全。
9、ArrayList和Vector的區別
?Vector是線程安全的,是1.0時期的遺留類,現在基本已經不使用了。所有方法都使用synchronized進行同步,單線程環境效率很低。
ArrayList是1.2時期引入的,不支持多線程安全,但在單線程下效率很高
10、Map接口有哪些實現類
?比較常用的有 HashMap、LinkedHashMap、TreeMap、ConcurrentHashMap。
如果無需排序則使用HashMap,因為它的性能最好。
如果考慮到多線程安全的問題則使用ConcurrentHashMap,使用了分段鎖和CAS機制,性能好于Hashtable
如果考慮到順序則可以用LinkedhashMap,因為它額外維護了一個雙向鏈表記錄插入和訪問順序。
如果需要范圍查詢按自定義順序排列則可以用TreeMap,因為它是基于紅黑樹實現的。
11、詳細說說HashMap及其底層原理?
?HashMap是將數據以鍵值對的形式存儲的,是線程不安全的。
jdk7是使用數組+鏈表來實現的,Hash沖突時會使用拉鏈法將沖突元素放進一個鏈表中。
jdk8引入了紅黑樹,鏈表長度超過8會將鏈表轉換為紅黑樹,具有更好的性能。
HashMap 的初始容量是 16,如果傳入的容量參數不為2的冪次方,則會增大到2的冪次方
隨著元素的不斷添加,HashMap 就需要進行擴容,閾值是capacity * loadFactor,capacity 為容量,loadFactor 為負載因子,默認為 0.75
12、了解紅黑樹嗎?簡單說說
?紅黑樹是一種自平衡的二叉查找樹,每個節點只能是紅色或黑色其中一種。其中根和葉子節點必須是黑色。從任一節點到葉子節點的簡單路徑都包含相同數目的黑色節點。紅色節點的子節點一定是黑色。
13、為什么超過8會變為紅黑樹小于6變為鏈表?
?因為它鏈表節點數量遵從泊松分布,當超過8時概率小于百萬分之一,然后才轉換為紅黑樹。如果數量變少的話使用鏈表更加方便,而如果7就轉換的話會產生不小開銷,甚至容易產生鏈表與紅黑樹的不斷轉換你。選擇6的話是兼顧時間和空間比較合適的數字。
14、為什么使用紅黑樹,不使用二叉搜索樹和AVL樹?
?二叉樹容易出現極端情況,比如插入的數據是有序的,那么二叉樹就會退化成鏈表,查詢效率就會變成 O(n)
而AVL樹每個節點的左右子樹的高度最多相差 1,這種高度的平衡保證了極佳的查找效率,但在進行插入和刪除操作時,可能需要頻繁地進行旋轉來維持樹的平衡,維護成本更高
使用紅黑樹更像是一種折中的方案,查找插入刪除的效率都是O(logN)
15、HashMap的put流程
?先判斷數組是否為空,為空則進行初始化。
然后計算哈希值,(n-1)&hash計算下標位置,構造Node節點放入
如果發生哈希沖突則判斷是否為同一個key,如果key不同就要根據數據結構放入節點
如果是紅黑樹就構造樹形節點插進去,鏈表的化就是Node節點插進去,這里看看是否需要轉為紅黑樹。
最后判斷節點數是否大于閾值,大于則擴容為原數組的兩倍。
16、為什么hashMap的容量是2的冪次方?
?因為hashmap計算下標使用hash&(n-1),n為數組大小,n-1之后恰好產生低位全是1的掩碼,保證能很好利用容量空間,并盡量的均勻分布。
(計算hash時利用高16位與低16位異或運算)
實際這里hashmap是將取模運算優化成了位運算,而容量只有為2的冪次方時,兩者結果才一致,由于位運算比取模運算快,所以采用位運算+2的冪次方來完美替代取模運算
17、 Hash沖突有哪些解決方式?
有線性探測法:如果發生沖突則順序查看該下標的下一個位置,直到該下標未被使用
二次探測法:發生沖突則交替變化正負x的平方移動,x從1開始遞增。
偽隨機探測法:預先生成一個偽隨機序列,根據序列的值來進行移動
最后還有鏈地址法,HashMap就是基于這種方法實現的,沖突的話會放在對應下標的鏈表上。
這里沖突的判斷方式是先判斷hashcode,再判斷equals,如果都一樣則認為key一樣,更新value
18、HashMap的擴容機制說說?
?jdk1.8中擴容會先生成新數組,其容量是原來的兩倍,然后遍歷舊哈希表元素
如果是鏈表的話,則重新計算下標放入新數組中,放置的結果等效于hash&(n-1),n為新的容量大小。
如果是紅黑樹的話,會遍歷紅黑樹計算出新的下標位置。
如果該位置下元素超過8則生成新的紅黑樹放進去。
如果沒超過8則生成一個鏈表將元素放進去
最后將新數組賦值給HashMap的table屬性
?19、負載因子是多少?為什么用這個數?
負載因子是0.75,當HashMap里元素的數量超過容量*負載因子時會發生擴容至原來的2倍。
負載因子如果太低,比如0.5則會浪費很多空間,如果是0.9則會發生太多沖突導致性能下降。
0.75 是 JDK 作者經過大量驗證后得出的最優解,能夠最大限度減少 rehash 的次數。
而且由于容量是2的冪,所以算出來的數恰好都為整數。雖然0.625,0.875也能整除,但折中考慮0.75更加恰當
20、jdk8對HashMap做了哪些優化
?1、底層數據結構由數組+鏈表轉為數組+鏈表+紅黑樹
2、鏈表的插入方式由頭插法改為尾插法,能不改變鏈表的順序
3、擴容的時機由插入時判斷改為插入后判斷,避免了覆蓋舊值時不必要的擴容問題
4、hash算法進行了優化,原來是多次移位和異或實現,jdk8則是高16位與低16位異或實現
21、HashMap是線程安全的嗎?
?不是線程安全的,多個線程同時讀寫時可能會出現并發修改問題。而且它的一些操作不是原子性的,在多線程下可能會出現竟態條件。
比如Jdk7里會出現死鎖問題,因為多線程操作HashMap并觸發擴容時,可能會形成環形鏈表,后續遍歷鏈表則會發生死循環。
jdk雖然使用頭插法解決了死鎖問題,但并發修改導致的數據異常依然沒有解決
22、HashMap如何實現線程安全?
?1、使用Collections下的synchronizedMap來創建,返回一個同步的Map包裝器,所有的Map操作都是同步的。內部是通過 synchronized 對象鎖來保證線程安全的
2、使用ConcurrentHashMap,使用了分段鎖機制,允許多個線程同時讀,提高并發性能。
使用了CAS和synchronized來保證線程安全
3、自己使用顯式的鎖,比如ReentrantLock來保證線程安全
23、 講講HashMap和TreeMap
①、HashMap 是基于數組+鏈表+紅黑樹實現的,put 元素的時候會先計算 key 的哈希值,然后通過哈希值計算出元素在數組中的存放下標,然后將元素插入到指定的位置,如果發生哈希沖突,會使用鏈表來解決,如果鏈表長度大于 8,會轉換為紅黑樹。
②、TreeMap 是基于紅黑樹實現的,put 元素的時候會先判斷根節點是否為空,如果為空,直接插入到根節點,如果不為空,會通過 key 的比較器來判斷元素應該插入到左子樹還是右子樹。
在沒有發生哈希沖突的情況下,HashMap 的查找效率是?
O(1)。適用于查找操作比較頻繁的場景。TreeMap 的查找效率是?
O(logn)。并且保證了元素的順序,因此適用于需要大量范圍查找或者有序遍歷的場景。
24、講講HashMap和Hashtable
1、?Hashtable 是同步的,即它的方法是線程安全的。這是通過在每個方法上添加同步關鍵字來實現的,而HashMap 不是同步的,因此它不保證在多線程環境中的線程安全性。
2、Hashtable 不允許鍵或值為 null。 HashMap 允許鍵和值都為 null
3、現在HashTable已經不常用了,一般考慮線程安全都會使用ConcurrentHashMap
25、講講HashSet的底層實現
?HashSet 是由 HashMap 實現的,只不過值由一個固定的 Object 對象填充,而鍵用于操作。
實際上HashSet并不常用,如果需要去重會考慮使用它,否則會用HashMap或ArrayList來替代它
26、HashSet和ArrayList區別?
- ArrayList 是基于動態數組實現的,HashSet 是基于 HashMap 實現的。
- ArrayList 允許重復元素和 null 值。HashSet 保證每個元素唯一,不允許重復元素,基于元素的 hashCode 和 equals 方法來確定元素的唯一性。
- ArrayList 保持元素的插入順序,可以通過索引訪問元素;HashSet 不保證元素的順序,元素的存儲順序依賴于哈希算法,并且可能隨著元素的添加或刪除而改變。
27、HashMap和HashSet的區別?
?1、HashMap 使用鍵值對的方式存儲數據,通過哈希表實現。 ?HashSet 實際上是基于 HashMap 實現的,它只使用了 HashMap 的鍵部分,將值部分設置為一個固定的常量。
2、HashMap 用于存儲鍵值對,其中每個鍵都唯一,每個鍵關聯一個值。 ?HashSet 用于存儲唯一的元素,不允許重復。
28、HashMap和ConcurrentHashMap區別?
?1、HashMap 不是線程安全的。在多線程環境中,如果同時進行讀寫操作可能會導致數據不一致。 ConcurrentHashMap 是線程安全的,它使用了分段鎖的機制,將整個數據結構分成多個段,每個段都有自己的鎖。這樣不同的線程可以同時訪問不同的段,提高并發性能。
2、HashMap 在實現上沒有明確的同步機制,需要在外部進行同步,例如通過使用 Collections.synchronizedMap() 方法。
3、在單線程或低并發環境下,HashMap 的性能會比 ConcurrentHashMap 稍好,因為 ConcurrentHashMap 需要維護額外的并發控制。 ?在高并發情況下,ConcurrentHashMap 的性能通常更好,因為它能夠更有效地支持并發訪問。
高頻自測:
- Java的集合類有哪些
- 哪些是線程安全的?哪些是線程不安全的?
- ArrayList 和 Array 有什么區別?
- ArrayList 和 LinkedList 的區別是什么?底層實現是怎么樣的?
- ArrayList 擴容機制
- Map 接口有哪些實現類
- Java中的HashMap了解嗎?HashMap 的底層實現 【重要】
- Hash 沖突有什么解決方式? HashMap 是如何解決 hash 沖突的
- HashMap 的 put 方法流程
- HashMap 的擴容機制
- HashMap 為什么是線程不安全的? 如何實現線程安全? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ??
- concurrentHashMap 如何保證線程安全
- HashSet 和 HashMap 和 HashTable 的區別? ? ? ? ? ? ??
- HashMap和ConcurrentHashMap







)








)


