在《C++11實現一個自旋鎖》介紹了分別使用TAS和CAS算法實現自旋鎖的方案,以及它們的優缺點。TAS算法雖然實現簡單,但是因為每次自旋時都要導致一場內存總線流量風暴,對全局系統影響很大,一般都要對它進行優化,以降低對全局系統的負面影響,本文討論一下它的優化方案。
下面是使用atomic_flag原子類+TAS算法實現的自旋鎖代碼。
class spin_lock final {atomic_flag lock_var{false}; // 鎖變量
public:void lock() {while (lock_var.test_and_set(memory_order_acquire));}void unlock() {lock_var.clear(memory_order_release);}
};
從上面的代碼可以看到,在調用lock()函數申請鎖時,只要鎖變量lock_var的值不是false,就會無條件的循環執行test_and_set(),執行的太頻繁了,以至于其它CPU的運行都要受到影響。因為一個CPU在test_and_set()執行時要原子事務寫lock_var變量到內存中,每執行一次就導致一場內存總線流量風暴,其它CPU要訪問內存就得競爭內存總線。如果競爭不到,得停下來等待內存總線的釋放,造成CPU一定程度上處于“失速”狀態。如果幾個線程同時在申請鎖,每一次TAS的原子事務寫內存,都會加劇內存總線的競爭程度。
如何進行優化呢?
雙檢查機制
在實現單例模式時,我們知道有一種針對互斥鎖的優化方案,叫做雙檢查鎖機制,它的基本思想是先使用執行成本低的代碼來檢查條件是否滿足,如果條件滿足,再使用執行成本高的代碼,即互斥鎖的方式去檢查條件。
可以借鑒這個思想來對TAS算法進行優化,基本思路是在調用TAS之前,先讀取鎖變量,此過程是只讀內存操作,相比RMW操作是輕量級的操作,沒有全局影響和副作用,執行成本較低。然后對讀取的值進行判斷,如果是true,則繼續循環重復此過程,直到返回false,說明有線程已經釋放鎖了,此時退出循環,再進行重量級的TAS操作。也就是僅在必要的時候才執行TAS操作,這樣,即使TAS操作導致的全局影響很大,但是它發生的次數卻大為降低了。
因為C++11版的atomic_flag原子類沒有提供讀取原子變量的接口,直到C++20版本才提供了成員函數test(),它返回原子變量的值,可以使用這個接口來實現雙檢查操作。下面是修改后的lock()函數代碼:
void lock() {while (true) {// 第一次檢查:使用Test操作while (lock_var.test(memory_order_relaxed));// 第二次檢查并設置:TAS操作if (!lock_var.test_and_set(memory_order_acquire)) {break; // 成功獲得鎖,跳出循環}}
}
與前面的實現相比,多了一個test()循環調用,同時原來的test_and_set()循環調用變成了單次調用,只有在test()檢測到lock_var為false時退出循環之后,才會進行test_and_set()調用。
循環代碼“while (lock_var.test(memory_order_relaxed))”就是上面說的第一次檢查操作,調用atomic_flag::test()接口返回lock_var的值,這里沒有內存順序的需要,因此使用了最松散的內存序,如果返回值是true,則繼續循環,如果是false,則退出循環,立刻進入第二次檢查,這時為什么還要進行檢查呢?因為第一次檢查不能原子地設置lock_var為true,所以還得要使用TAS操作,由于已經檢測到lock_var為false了,這次執行TAS成功的幾率非常高。
由此可見,該方式在自旋鎖中的實現邏輯是Test-Test-And-Set,所以也簡稱為TTAS算法。
為了查看TTAS的實現細節,我們看一下它的匯編指令代碼,下面是使用-std=c++20編譯選項,生成的匯編指令:
spin_lock::lock():mov edx, 1
.L17:
// 從內存中讀取鎖變量的值movzx eax, BYTE PTR [rdi]
// 判斷是否是0,即false,第一次檢查 Testtest al, al
// 如果不是0,則回退jne .L17mov eax, edx
// 第二次檢查并設置:TAS操作xchg al, BYTE PTR [rdi]test al, aljne .L17ret
看第一次檢查(第3-9行),在每次檢查時都要從內存[rdi]處讀取變量lock_var,然后檢查是否為0,即false,如果不為0,則繼續退回去重新讀取再檢查,一直循環執行“讀取-判斷-回退”的邏輯,直到讀出的lock_var為0為止。注意,這里的讀取指令是“movzx eax, BYTE PTR [rdi]”,是非常簡單的指令,它從內存中加載一個字節的數據到寄存器al中,也是一條原子操作指令,但該指令不會鎖總線。根據MESI緩存一致性協議,如果lock_var的值沒有被別的CPU修改過,那么它就在當前CPU的L1 cache緩存中會一直有效,也就是只要內存中的lock_var的值沒有被更新,該指令執行時就會一直從L1 cache中讀取,即沒有訪問內存,也就不會占用內存總線,不會影響其它CPU,只在本CPU中循環,所以第一次的循環檢查也被稱為“本地自旋”(見匯編指令代碼第5(讀取)、7(判斷)、9(回退)行)。
1、提高了整體吞吐量性能
同TAS算法相比,TTAS算法大大減輕了對內存總線的競爭程度,也降低了TAS執行時為了維持cache一致性而產生的內存總線流量。使用《利用C++11原子操作實現自旋鎖》中的測試代碼,所測試的TTAS以及TAS、CAS算法的性能數據如下:
TTAS所用時鐘周期 TAS所用時鐘周期 CAS所用時鐘周期
337427552 432447222 177915346
394388223 502814284 279384821
390494013 556108365 227520077
401288104 513192991 346827330
可見,在同樣的測試條件,TTAS算法要比TAS算法性能要好,但是仍然比CAS算法要差。
2、增大了個體CPU申請鎖時延遲的可能性
TAS算法實現自旋鎖時,如果返回了false同時也就獲得了鎖,檢查和設置是一個原子操作,而使用TTAS算法時要對鎖變量進行兩次檢查判斷,第一次檢查返回false時,只是有可能會獲得鎖,能否獲得還得要使用后面的TAS算法。因此,使用TTAS算法實現,申請鎖的速度沒有TAS算法快,也就是申請鎖時的延遲要比TAS算法大。
因此,可以把Test和TAS的位置調換一下,先進行TAS算法,當一個線程剛進入lock()時,如果鎖是釋放狀態,可能會馬上通過TAS來獲得鎖,而不用等到從Test循環中退出,再使用TAS來競爭鎖,能降低一點申請鎖的延遲,當然如果第一次沒有競爭到鎖,就進入了本地自旋,等待lock_var變為false,仍然還是存在延遲。代碼如下:
void lock() {while (true) {// 第一次檢查并設置:TAS操作if (!lock_var.test_and_set(memory_order_acquire)) {break; // 成功獲得鎖,跳出循環}// 第二次檢查:使用Test操作while (lock_var.test(memory_order_relaxed));}
}
3、TTAS是比TAS更“忙”的算法
在TTAS算法中,第一個Test檢查過程是本地自旋,它不同于TAS自旋,它的性能更高,執行的速度更快:
首先,先看指令部分,是個微小循環,可以被CPU的循環流檢測器(識別和鎖定微操作指令隊列中小的循環)檢測到,并放入trace-cache中,可以在下一次循環時直接使用。下圖是它的指令流截圖,非常短小精悍,僅有三行指令,指令長度是17-10=7個字節度,被譯碼單元譯碼后的微操作碼應該也不多(其中jne指令和它前面的test指令還會被宏融合為單一的微操作碼),它們存放在CPU的trace-cache里面肯定綽綽有余,注意里面存放的是已經解碼完的微操作碼,可以被執行引擎直接派發和執行。也就是說對于這個本地自旋小循環,不但不需要從指令cache中獲取指令,而且連指令解碼過程也被省掉了,此時不會因為程序流程發生跳轉了,需要重新從指令cache中加載指令和譯碼的過程,導致CPU出現流水線的中斷。
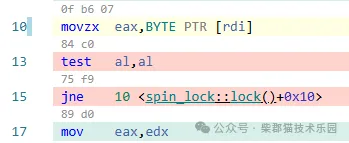
再看數據部分,因為對鎖變量數據lock_var是一個只讀操作,此時作為熱點數據都在L1 cache中,讀取時不需要從內存中獲取,速度極快,因此,在本地自旋時,也不會出現因為需要加載數據導致CPU流水線中斷的情況。此外,因為這個本地自旋運行次數很多,CPU的分支預測單元會發揮作用,知道下一步要跳轉到第10行去執行,CPU就會預測執行,這樣這三條指令就可以并行執行,即test指令在判斷當前lock_ver值的同時,又在讀取下一次的lock_var值為下一次test指令做準備,這是指令級的并行化(因為有寄存器重命名機制,第10行更新eax(al是它的低8位)寄存器和第13行測試al寄存器不會沖突,這個寫后讀是假依賴,可以同時執行)。
也就是說,當CPU處于本地自旋時,無論是指令還是數據,它們都處于CPU的內部,不會發生因為cache miss而中斷CPU流水線去等待它們,而且還可以進行指令級的并行化,會一直處于高速運轉中,也就是它更“忙”了,當然副作用就是耗電量非常大,這是TTAS算法不好的一面。
4、一旦進入本地自旋,大概率是要空轉
再看TTAS算法的代碼實現,當第一次檢查時,如果一個CPU從本地自旋中退出,說明此時已經有別的CPU把這個lock_var變量置為false了,即別的線程已經把鎖釋放了。當接著使用TAS操作進行第二次檢查時,如果沒有設置成功,說明在第一次檢查結束和第二次檢查開始之間出現了狀況:第一種可能它是和別的CPU在執行時間上有重疊,但別的CPU搶先獲得了鎖;第二種可能是執行流程被中斷后又返回了,即有中斷或者優先級更高的線程把它搶占了,這個CPU也就暫時沒有參與自旋鎖的競爭。
我們現在討論第一種情況,別的CPU搶先獲得了鎖,然后進入臨界區進行業務處理,這也暗示著自旋鎖不會馬上被釋放,那么本CPU肯定會再次進入“本地自旋”并且會持續一段時間。我們不妨估算一下大概需要自旋多長時間:如果想讓CPU從本地自旋中退出,至少要等到另一個CPU執行完臨界區代碼后,調用unlock把false值寫入內存變量lock_var,本CPU讀取lock_var變量時發現緩存和內存中的值不一致,重新從內存中加載;假設臨界區的最小執行時間為t,也就是說最少也要等待CPU一次原子事務寫內存的時間,加上一次讀內存的時間,再加上t,小于這個時間是不會從循環中退出的,這段時間CPU一直處于空轉狀態。
也就是說,只要進入本地自旋,大概率是要一直空轉的,一直到別的線程執行完臨界區代碼釋放鎖后才有可能停止空轉。那么,這個空轉既然避免不了,在這期間CPU有什么優化措施嗎?
x86的pause指令
現代CPU大多提供了超線程技術(即邏輯CPU),即在一個物理核上有兩個邏輯核,它們有自己獨享的寄存器,但是需要共享執行單元、系統總線和緩存等硬件資源。如果執行自旋操作的CPU是一個邏輯核,當它進入本地自旋的時候,會加劇物理核中的執行資源和系統總線的競爭程度,從而影響其它同一個邏輯核的執行效率。
我們再分析一下TTAS的lock代碼的結構特點:代碼雖然不多,但是嚴重同質化,有兩次數據傳輸操作,兩次test操作,一次比較交換操作,也就是它們使用相同執行單元的可能性非常大。如果處于自旋的兩個線程剛好被分配到同一個物理核的兩個邏輯核上運行,兩個邏輯核共享執行單元和系統總線,它們在自旋操作時可能會遭遇資源沖突,反而導致整體性能下降。
為了改善這種情況,Intel開發者手冊建議使用pause指令優化。intel的CPU針對自旋等待的場景提供了一個指令:pause,該條指令的功能是給CPU一個提示:當前正在進行自旋等待,可以暫停一下,比如等待一個或幾個內存總線操作周期的時間之后,然后再繼續運行(因為在這期間,CPU是大概率獲取不到自旋鎖的,與其讓CPU自旋忙等,不如停下來休息一下)。因此,一個邏輯核進入了pause狀態,也就不再使用系統資源了,這樣,同物理核的另一個邏輯核就可以獨享物理核的全部資源了,提高了申請鎖時響應速度,也降低了CPU的電量消耗。
因為C++中沒有相應的函數來執行pause指令,可以在代碼中嵌入匯編指令,下面是基于TTAS算法修改后的代碼(同樣也可以使用pause指令優化基于CAS算法實現的自旋鎖):
void lock() {while (true) {if (!lock_var.test_and_set(memory_order_acquire)) {break;}while (lock_var.test(memory_order_relaxed)) {asm("pause");}}
}
這情況下能夠大大降低CPU執行資源和電量的消耗。不過,這種方法會進一步增加獲取鎖的延遲性,因為每次自旋條件不符合時就得先pause一段時間,如果在pause期間,鎖被釋放了,也不會及時的獲取鎖,只能等到CPU從pause中退出時才有可能。而且這個延遲的時間也不固定:有可能CPU剛剛開始pause,鎖就釋放了,顯然此時延遲最大;也有可能CPU從pause退出時,恰好鎖就釋放了,顯然此時延遲最小,這是最理想的場景。如果應用場景是對響應性能敏感的場景,就得要慎重考慮了,能否容忍使用pause指令帶來的延遲損失。
同時我們也知道,當CPU處于pause狀態時,什么也不做,不像操作系統提供的yield命令,可以讓CPU執行別的任務。讓CPU資源處于閑置狀態,可能會感覺有點可惜,不過在支持超線程技術的CPU架構體系中可以利用這個特點,在一定程度上緩解邏輯核的資源競爭問題,提高超線程的執行速度,因為一個邏輯核執行pause而處于暫停狀態,也在一定程度上緩解了CPU的耗電問題。
不過需要指出的是,當自旋鎖保護的臨界區執行時間很短時,比如只是簡單的幾個內存訪問和計算,可以使用pause機制;如果自旋鎖保護的臨界區執行時間很長時,或者一個線程獲得自旋鎖后接著被搶占了,使用pause機制會讓其它申請自旋鎖的CPU長時間處于暫停狀態,也是一種資源浪費。顯然這種情況下不如把CPU分配給別的線程使用,此時涉及到線程被調度的情況了,就得考慮讓操作系統參與進來了,比如調用yield,把CPU調度給別的任務,或者直接把當前線程掛起,等到解鎖時再喚醒它。
總結
1、TAS算法實現自旋鎖,會導致內存總線流量風暴,全局系統影響大。
2、TTAS雖然抑制了流量風暴的產生,減輕了全局內存總線的競爭程度,但是又導致CPU耗電量大、發熱等情況。
3、使用pause指令緩解了超線程核心的系統資源競爭和降低了耗電量,但是又增長了獲取鎖時的延遲。
4、TTAS算法和pause指令是在程序和CPU上面對自旋鎖的優化,如果獲取不到鎖時,線程仍然處于自旋中,不會發生調度和阻塞現象,沒有改變自旋鎖的本質特征。
參考:
1、https://zh.cppreference.com/w/cpp/atomic/atomic_flag/test
2、Intel? 64 and IA-32 Architectures Software Developer’s Manual
3、《現代x86匯編語言程序設計》 丹尼爾-卡斯沃姆
附錄:
下面內容是Intel手冊對pause指令的描述。
PAUSE—Spin Loop Hint
Improves the performance of spin-wait loops. When executing a “spin-wait loop,” processors will suffer a severe performance penalty when exiting the loop because it detects a possible memory order violation. The PAUSE instruction provides a hint to the processor that the code sequence is a spin-wait loop. The processor uses this hint to avoid the memory order violation in most situations, which greatly improves processor performance. For this reason, it is recommended that a PAUSE instruction be placed in all spin-wait loops.
An additional function of the PAUSE instruction is to reduce the power consumed by a processor while executing a spin loop. A processor can execute a spin-wait loop extremely quickly, causing the processor to consume a lot of power while it waits for the resource it is spinning on to become available. Inserting a pause instruction in a spinwait loop greatly reduces the processor’s power consumption.







)


字符設備開發)



)




