論文:Transfusion: Predict the Next Token and Diffuse Images with One Multi-Modal Model
地址:https://arxiv.org/abs/2408.11039
類型:理解與生成
Transfusion模型?是一種將Transformer和Diffusion模型融合的多模態模型,旨在同時處理離散數據(如文本)和連續數據(如圖像)。該模型由Meta公司開發,能夠在單個模型中預測離散文本token并生成連續圖像,從而實現了語言建模和圖像生成的一體化。
Transfusion模型的核心特點
-
?統一的Transformer架構?:Transfusion使用單一的Transformer模型來處理文本和圖像數據,通過不同的損失函數和注意力機制來實現多模態建模。
-
?雙重訓練目標?:對于文本,采用經典的語言建模目標(LM loss),即預測序列中的下一個token;對于圖像,則引入擴散模型的目標(DDPM loss),通過預測加噪過程中的噪聲分量來逐步生成圖像?12。
-
?模態混合序列?:Transfusion將文本和圖像數據整合成單一輸入序列,使用特殊標記分隔不同模態,確保模型能區分處理對象?2。
-
?注意力機制的創新?:對于文本,保持因果注意力;對于圖像patch,引入雙向注意力,捕捉空間關系,提升生成質量?2。
-
?聯合損失函數?:訓練時,將語言建模損失和擴散模型損失加權組合為一個總損失函數?
一、摘要
我們介紹了Transfusion,這是一種在離散和連續數據上訓練多模態模型的方法。Transfusion將語言建模損失函數(下一個token預測)與擴散相結合,在混合模態序列上訓練單個Transformer。我們在文本和圖像數據的混合上從頭開始預訓練多達7B個參數的多個Transfusion模型,建立了關于各種單模態和跨模態基準的縮放規律。我們的實驗表明,Transfusion的縮放效果明顯優于量化圖像和在離散圖像標記上訓練語言模型。通過引入特定于模態的編碼和解碼層,我們可以進一步提高Transfusion模型的性能,甚至將每張圖像壓縮到只有16個patch。我們進一步證明,將我們的Transfusion配方擴展到7B參數和2T多模態令牌可以產生一個模型,該模型可以生成與類似規模的擴散模型和語言模型相當的圖像和文本,從而獲得兩個世界的好處。
二、介紹
多模態生成模型需要能夠感知、處理和生成離散元素(如文本或代碼)和連續元素(如圖像、音頻和視頻數據)。雖然在下一個令牌預測目標上訓練的語言模型主導了離散模態,但擴散模型及其推廣Flow matching是生成連續模態的最新技術。已經做出了許多努力來結合這些方法,包括擴展語言模型以使用擴散模型作為工具,無論是明確地還是將預訓練的擴散模型移植到語言模型上。在這項工作中,我們表明,通過訓練一個模型來預測離散文本標記和擴散連續圖像,可以在不損失信息的情況下完全整合這兩種模式。
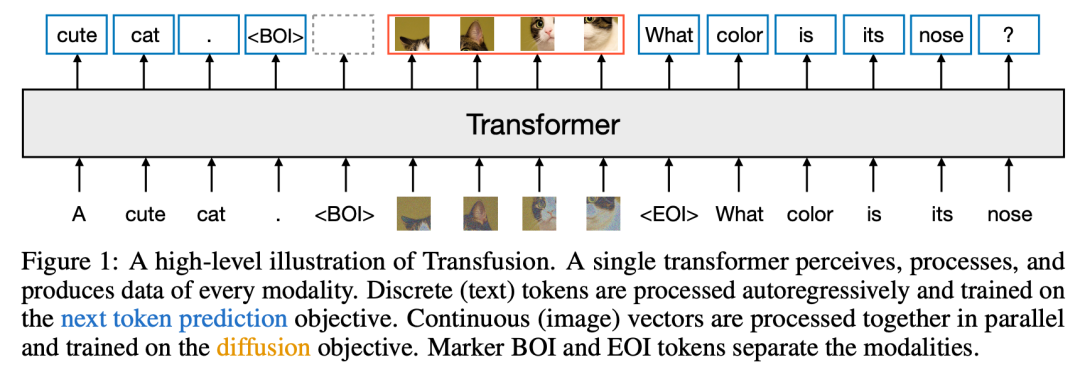
我們介紹了Transfusion,這是一種訓練模型的方法,可以無縫生成離散和連續的模態。我們通過在50%的文本和50%的圖像數據上預訓練一個transformer模型來演示Transfusion,為每種模態使用不同的目標:文本的下一個標記預測和圖像的擴散。該模型在每個訓練步驟中都暴露于模態和損失函數。Standard embedding layers將文本標記轉換為向量,而patchification layer則表示每個圖像作為補丁矢量序列。我們對文本標記應用?causal attention,對image patches應用bidirectional attention。為了進行推理,我們引入了一種解碼算法,該算法結合了從語言模型生成文本和從擴散模型生成圖像的標準實踐。圖1顯示了Transfusion。
消融實驗揭示了Transfusion的關鍵組成部分和潛在的改進。我們觀察到,圖像內雙向注意力很重要,用因果注意力代替它會損害文本到圖像的生成。我們還發現,添加U-Net上下塊來編碼和解碼圖像,使Transfusion能夠以相對較小的性能損失壓縮較大的圖像塊,從而可能將服務成本降低64倍。

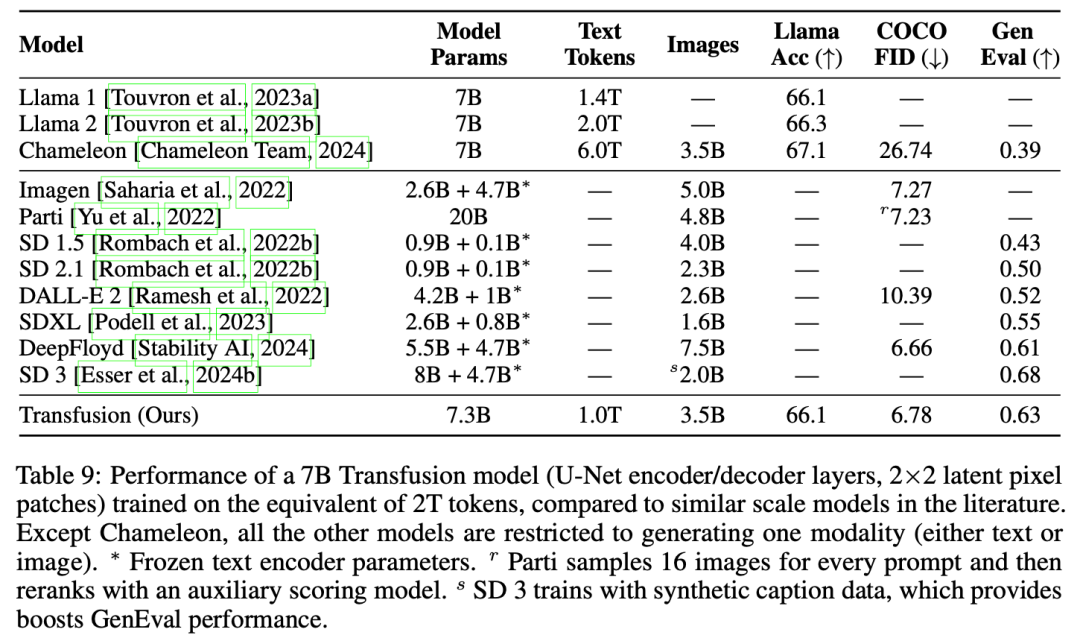
最后,我們證明了Transfusion可以生成與其他擴散模型質量相似的圖像。我們從頭開始訓練一個7B轉換器,該轉換器在2T令牌上增強了U-Net?down/up(0.27B參數):1T文本令牌,以及大約5個epochs 692M圖像及其captions迭代,總計1T patches/tokens。圖2顯示了從模型中采樣的一些生成圖像。在GenEval基準測試中,我們的模型優于其他流行模型,如DALL-E 2和SDXL;與那些圖像生成模型不同,它可以生成文本,在文本基準測試中達到與Llama 1相同的性能水平。因此,我們的實驗表明,Transfusion是一種訓練真正多模態模型的有前景的方法。
GenEval是專門評估生成式AI模型(如文本到圖像生成)性能的基準測試,它定義明確,通過標準化的測試流程,對模型在圖像生成質量、指令遵循度、多模態理解等關鍵指標上進行量化評估。例如,在開源模型Janus-Pro與DALL-E 3、Stable Diffusion的對比中,GenEval的測試結果顯示Janus-Pro-7B的準確率高達80%,顯著優于競品。
GenEval的框架設計包含多維度評估體系,覆蓋圖像生成質量(如分辨率、色彩準確性)、指令響應能力(如地標識別、文字生成)、多模態任務處理(如視覺問答、圖像標注)等核心模塊。其測試方法結合了自動化指標(如FID分數、CLIP匹配度)與人工評審,確保評估的全面性與可靠性。
三、背景
Transfusion是一個單一的模型,有兩個目標:語言建模和擴散(language modeling and diffusion)。這些目標分別代表了離散和連續數據建模的最新技術。本節簡要定義了這些目標,以及潛在表示的背景。
3.1 Language Modeling
給定離散令牌序列y=y1...yn,語言模型預測序列P(y)的概率。標準語言模型將P(y)分解為條件概率的乘積如下公式,這創建了一個自回歸分類任務,其中每個令牌yi的概率分布是在序列y<i的前綴的條件下,使用由θ參數化的單個分布Pθ進行預測的。該模型可以通過最小化Pθ和數據經驗分布之間的交叉熵來優化,從而產生標準的下一個令牌預測目標,俗稱LM損失:
![]()
![]()
一旦經過訓練,語言模型還可以通過從模型分布Pθ中逐個采樣來生成文本,通常使用溫度和top-P截斷。
溫度參數用于控制生成文本的隨機性,其值通常介于0.1到2.0之間;
Top-P截斷是一種動態限制采樣范圍的方法,僅考慮概率最高的前P%的詞匯
3.2 Diffusion
去噪擴散概率模型(也稱為DDPM或擴散模型)的工作原理是學習如何逆轉逐漸增加噪聲的過程。與通常使用離散標記(y)的語言模型不同,擴散模型在連續向量(x)上運行,使其特別適合涉及圖像等連續數據的任務。擴散框架涉及兩個過程:一個描述原始數據如何轉化為噪聲的正向過程,以及模型學習執行的去噪反向過程。
Forward Process。從數學的角度來看,正向過程定義了如何創建噪聲數據(作為模型輸入)。給定一個數據點x0,Ho等人定義了一個馬爾可夫鏈,該鏈在T步上逐漸增加高斯噪聲,從而產生一個噪聲越來越大的序列x1,?x2, ...,?xT,這個過程的每一步都由
![]()
其中βt根據預定義的噪聲時間表隨時間增加(見下文)。該過程可以重新參數化,使我們能夠使用高斯噪聲ε~N(0,I)的單個樣本直接從x0中采樣xt:
![]()
![]()
它提供了對原始馬爾可夫鏈的有用抽象。事實上,訓練目標和噪聲調度器最終都以這些術語表示(和實現)。
Reverse Process。對擴散模型進行訓練,以執行逆過程pθ(xt?1|xt),學習逐步對數據進行去噪。有幾種方法可以做到這一點;在這項工作中,我們遵循Ho等人的方法,將方程2中的高斯噪聲ε建模為步驟t處累積噪聲的代理。具體來說,在給定噪聲數據xt和時間步長t的情況下,訓練一個具有參數θ的模型εθ(·)來估計噪聲ε。在實踐中,該模型通常在生成圖像時以附加的上下文信息c為條件,例如caption。因此,通過最小化均方誤差損失來優化噪聲預測模型的參數:
![]()
Noise Schedule。在創建有噪聲的示例xt時,α?t確定了時間步長t的噪聲方差。在這項工作中,我們采用了常用的余弦調度器,該調度器在很大程度上遵循sqrt(αt)≈cos(t/T·π/2),并進行了一些調整。
Inference。解碼是迭代完成的,每一步都會消除一些噪聲。從xT處的純高斯噪聲開始,模型εθ(xT,t,c)預測時間步長t處累積的噪聲。然后根據噪聲調度對預測的噪聲進行縮放,并從xT中去除預測噪聲的比例量以產生xT-1。在實踐中,推理的時間步比訓練少。無分類器引導(CFG)通常用于通過對比基于上下文c的模型預測和無條件預測來改進生成,代價是計算量加倍。
3.3 Latent Image Representation
早期的擴散模型直接在像素空間pixel-space中工作,但這被證明計算成本很高。變分自編碼器(VAEs)可以通過將圖像編碼到低維潛在空間來節省計算。作為深度卷積神經網絡實現,現代VAE在重建和正則化損失的組合上進行訓練,允許潛在擴散模型(LDM)等下游模型在緊湊的圖像塊嵌入上高效運行;例如,將每個8×8像素的補丁表示為8維向量。對于自回歸語言建模方法,必須對圖像進行離散化。離散自編碼器,如矢量量化VAE(VQ-VAE),通過引入將連續潛在嵌入映射到離散標記的量化層(和相關的正則化損失)來實現這一點。
四、方法
Transfusion是一種訓練單個統一模型以理解和生成離散和連續模態的方法。我們的主要創新是證明,我們可以對不同的模態使用單獨的損失——文本的語言建模、圖像的擴散——而不是共享的數據和參數。圖1顯示了Transfusion。
Data Representation。我們實驗了兩種模式的數據:離散文本和連續圖像。每個文本字符串都被標記為來自固定詞匯表的離散標記序列,其中每個標記都表示為整數。使用VAE將每個圖像編碼為潛在patch,其中每個patch表示為連續向量;patch從左到右從上到下排序,以從每張圖像中創建patch向量序列。對于混合模態示例,我們在將每個圖像序列插入文本序列之前,用特殊的圖像開始(BOI)和圖像結束(EOI)標記包圍每個圖像序列;因此,我們得到一個可能包含離散元素(表示文本標記的整數)和連續元素(表示圖像塊的向量)的單一序列。
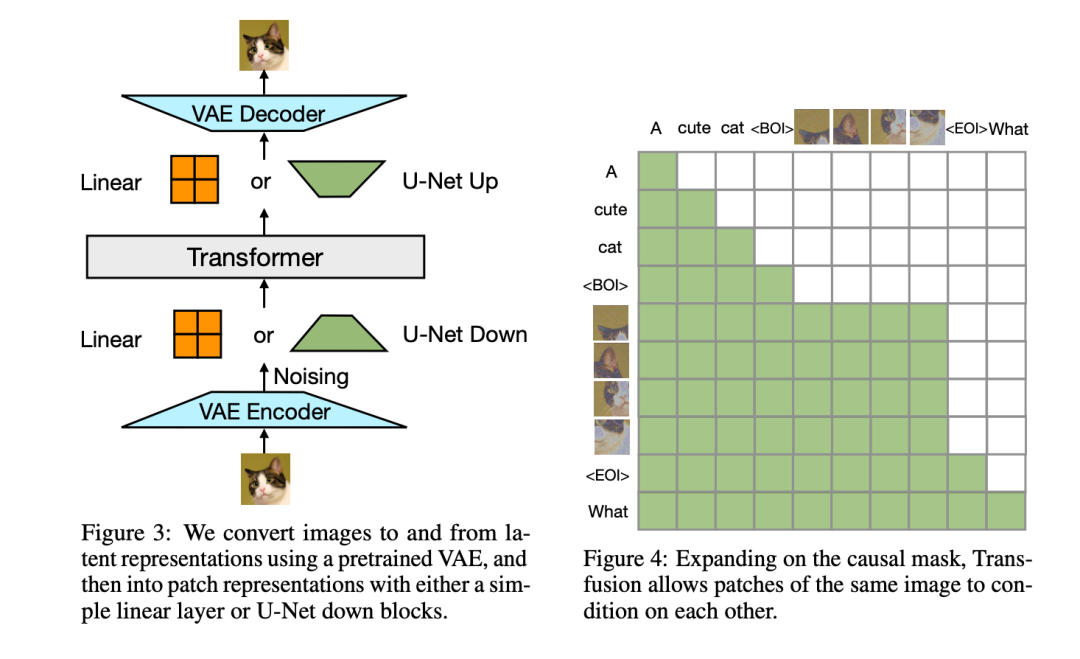
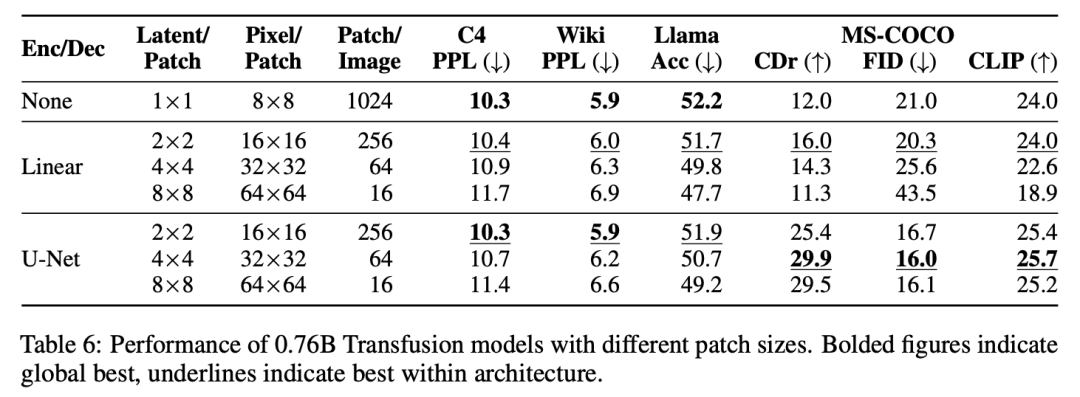
Model Architecture。模型的絕大多數參數屬于一個Transformer,該Transformer處理每個序列,而不管模態如何。Transformer將R^d中的一系列高維向量作為輸入,并產生相似的向量作為輸出。為了將我們的數據轉換到這個空間,我們使用具有非共享參數的輕量級模態特定組件。對于文本,這些是嵌入矩陣,將每個輸入整數轉換為向量空間,將每個輸出向量轉換為詞匯表上的離散分布。對于圖像,我們嘗試了兩種將k×k個patch向量的局部窗口壓縮為?single transformer vector的替代方案:(1)簡單線性層;(2)UNet上下塊,圖3顯示了整體架構。
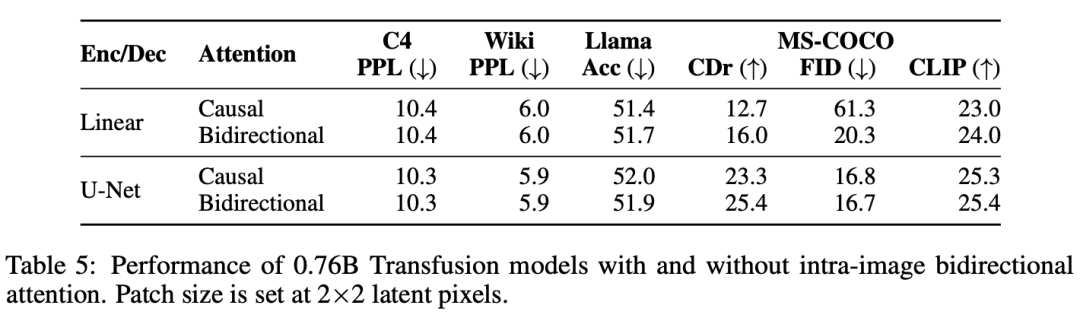
Transfusion Attention。語言模型通常使用causal masking來有效地計算單個前向后向傳遞中整個序列的損失和梯度,而不會從未來的token中泄露信息。雖然文本是自然順序的,但圖像不是,并且通常以不受限制的(雙向)注意力進行建模。Transfusion通過對序列中的每個元素應用因果注意力,以及在每個單獨圖像的元素內應用雙向注意力,將兩種注意力模式結合在一起。這允許每個圖像補丁處理同一圖像中的其他補丁,但只處理序列中之前出現的其他圖像的文本或補丁。我們發現,啟用圖像內注意力可以顯著提高模型性能。圖4顯示了?Transfusion attention mask。
Training Objective。為了訓練我們的模型,我們將語言建模目標L-LM應用于文本標記的預測,將擴散目標L-DDPM應用于圖像塊的預測。LM損失按每個標記計算,而擴散損失按每個圖像計算,這可能跨越序列中的多個元素(圖像塊)。具體來說,我們根據擴散過程將噪聲ε添加到每個輸入的潛像x0中,以在diffusion之前產生xt,然后計算圖像級擴散損失。我們通過簡單地將每種模態上計算的損失與平衡系數λ相加,將這兩種損失結合起來:
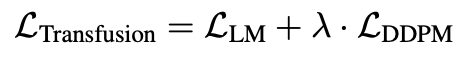
這個公式是一個更廣泛想法的具體實例:將離散分布損失與連續分布損失相結合,以優化同一模型。我們將對這一領域的進一步探索,例如用flow matching取代擴散,留給未來的工作。
一、Flow Matching的核心原理與應用
1. 數學本質:連續概率流的“路徑規劃”
- ?
類比理解:如同用黏土塑形,Flow Matching通過構建一個連續的速度場(Velocity Field),將隨機噪聲(先驗分布)逐步“引導”至目標圖像分布。
- ?
技術實現:定義從噪聲到數據的平滑路徑(如線性插值或動態學習路徑)。通過神經網絡直接預測每個時空點的速度向量(而非噪聲),形成確定性軌跡。滿足概率質量守恒(連續性方程),確保轉換過程中信息不丟失。
2. 訓練與采樣優勢
- ?
模板函數:直接優化速度場與預定義路徑的匹配度(均方誤差MSE),無需馬爾可夫鏈假設。
?采樣效率:采用高階ODE求解器(如RK45),10-100步即可生成高質量圖像,支持實時應用(如直播、游戲場景)。
靈活性:允許自定義路徑(直線、曲線或動態路徑),適合復雜分布建模。二、DDPM的核心原理與應用
1. 數學本質:離散擴散的“噪聲逆轉”
- 類比理解
:類似沙堡被侵蝕后重建,DDPM通過逐步添加高斯噪聲破壞圖像,再學習逆轉此過程的去噪步驟。
- 技術實現:
前向過程:按固定噪聲調度(如線性β_t)將圖像逐步轉化為純噪聲。
反向過程:用U-Net預測每一步的噪聲分量,通過迭代去噪還原圖像。2. 訓練與采樣特點
- 目標函數
:間接優化變分下界(ELBO),依賴馬爾可夫鏈分解。
- 采樣效率
:需1000步以上(即使通過DDIM加速仍受限于離散步數)。
- 生成質量
:擅長建模復雜數據(如高分辨率圖像),與U-Net結合可捕捉細節。
Flow Matching:
優勢場景:需要快速生成(如實時互動、低延遲應用)或路徑可控的場景(如風格遷移中的漸變控制)。
案例:條件Flow Matching(CFM)在文本到圖像生成中,通過定義噪聲與數據間的連續路徑,提升生成速度。
DDPM:
優勢場景:追求高質量圖像生成(如藝術畫作、超分辨率重建)或復雜數據分布建模。
案例:Stable Diffusion通過潛在空間擴散生成高分辨率圖像,支持文本引導和圖像修復。
Inference。為了反映訓練目標,我們的解碼算法還可以在兩種模式之間切換:LM和diffusion。在LM模式下,我們遵循從預測分布中逐個采樣的標準做法。當我們對BOI令牌進行采樣時,解碼算法會切換到擴散模式,在那里我們遵循從擴散模型解碼的標準過程。具體來說,我們以n個圖像塊的形式將純噪聲xT附加到輸入序列中(取決于所需的圖像大小),并在T步內進行降噪。在每個步驟t,我們進行噪聲預測并使用它來產生xt-1,然后覆蓋序列中的xt;即,該模型總是以噪聲圖像的最后一個時間步長為條件,而不能關注之前的時間步長。一旦擴散過程結束,我們將EOI令牌附加到預測圖像中,并切換回LM模式。該算法能夠生成文本和圖像模態的任何混合。
五、實驗
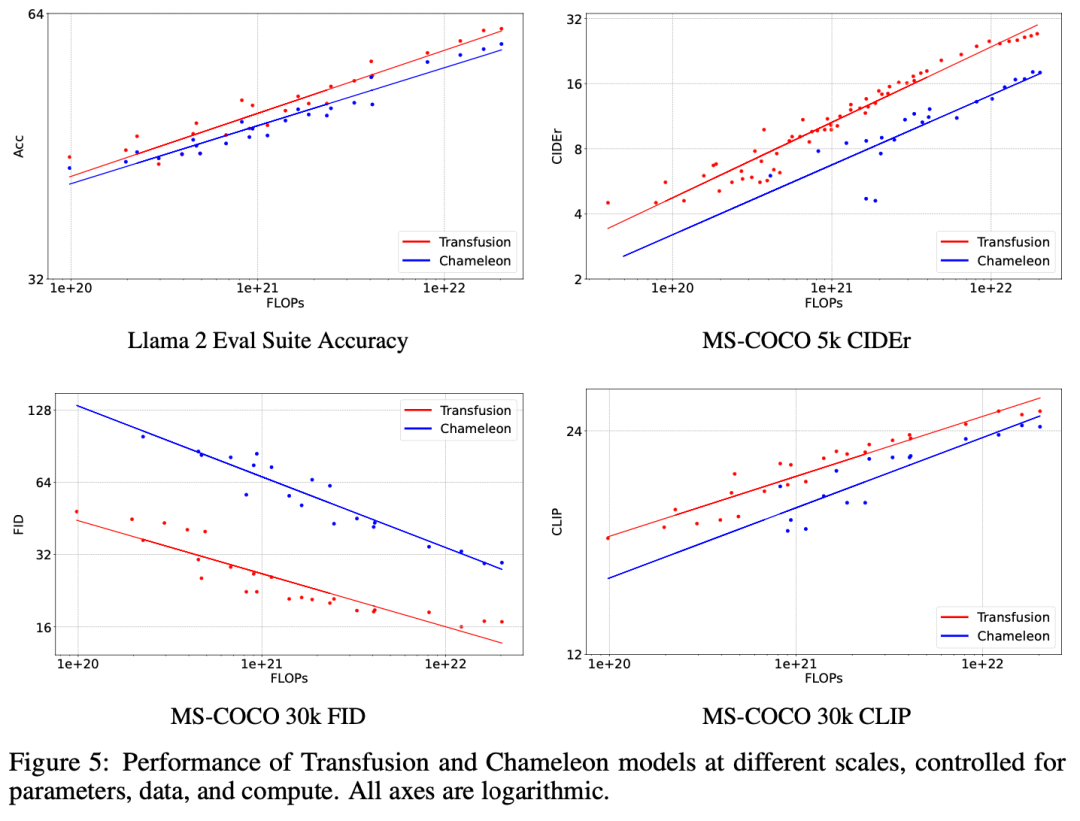
我們在一系列對照實驗中證明,transfusion是一種可行的、可擴展的訓練統一多模態模型的方法。
Evaluation。我們在一系列標準uni-modal\cross-modal benchmarks基準上評估模型性能,如表1所示。包括Wikipedia\MS-COCO,覆蓋文生圖、與文本生成。指標包括FID、CLIP、Perplexity等。
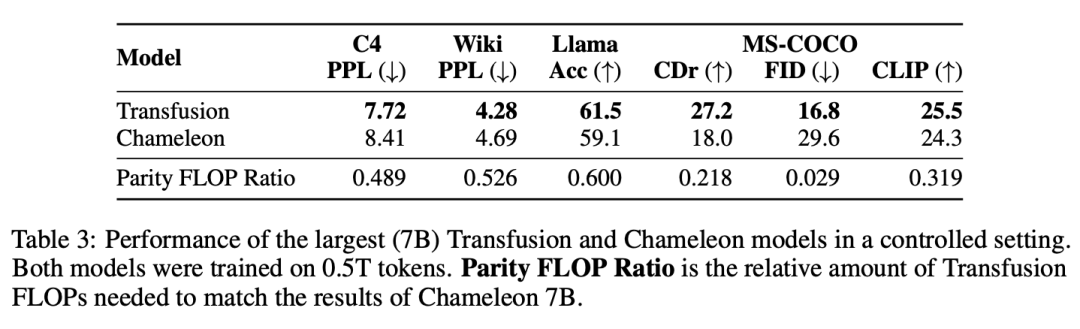
Baseline。Chameleon和Transfusion之間的關鍵區別在于,雖然Chameleon將圖像離散化并將其作為token進行處理,但Transfusion將圖像保持在連續空間中,消除了量化信息瓶頸。
Data。對于我們幾乎所有的實驗,我們以1:1的token比率從兩個數據集中采樣0.5T令牌(補丁)。對于文本,我們使用Llama 2標記器和語料庫,其中包含跨不同域分布的2T標記。對于圖像,我們使用一組3.8億張獲得許可的Shutterstock圖像和字幕。每幅圖像都經過中心裁剪和調整大小,以產生256×256像素的圖像。我們隨機排列圖像和字幕,80%的時間先排列字幕。
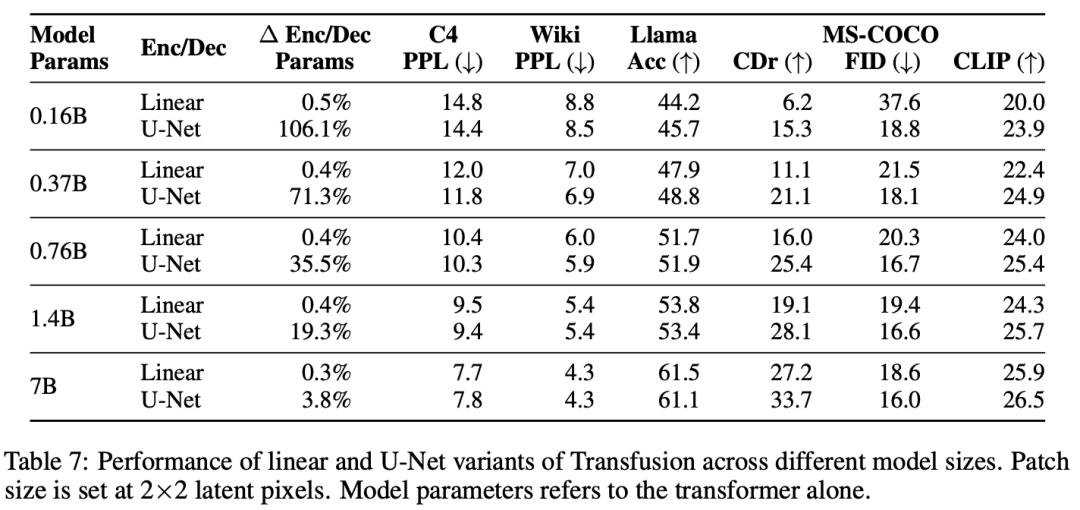
Model Configuration。為了研究縮放趨勢,我們按照Llama的標準設置,以五種不同的尺寸(0.16B、0.37B、0.76B、1.4B和7B參數)訓練模型。表2詳細描述了每種設置。在使用線性補丁編碼的配置中,附加參數的數量微不足道,在每個配置中占總參數的不到0.5%。當使用U-Net補丁編碼時,這些參數在所有配置中加起來總共為0.27B的額外參數;雖然這是對較小模型的大量參數添加,但這些層僅比7B配置增加了3.8%,幾乎與嵌入層中的參數數量相同。
Optimization。我們隨機初始化所有模型參數,并使用學習率為3e-4的AdamW(β1=0.9,β2=0.95,ε=1e-8)對其進行優化,warmed up ?4000步,使用cosine scheduler衰減到1.5e-5。我們在4096個token的序列上進行訓練,每批2M個token,每次250k步,總共達到0.5T個令牌。在我們的大規模實驗中,我們在500k步內使用4M令牌的批量進行訓練,總共2T令牌。
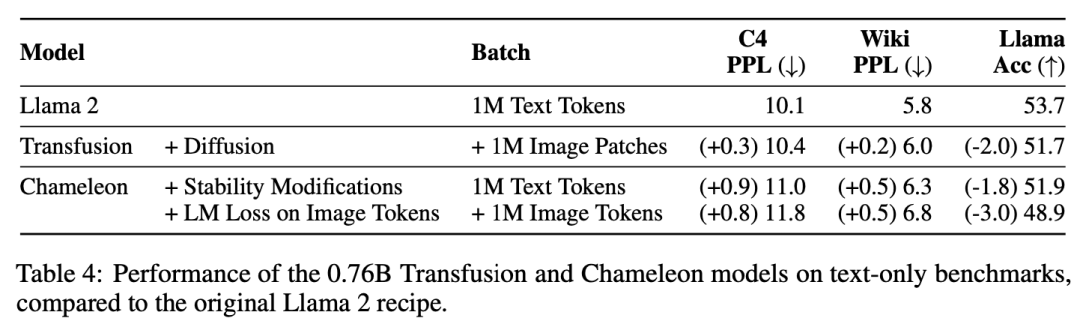
實驗主要探索了Controlled Comparison with Chameleon, Architecture Ablations(Attention Masking,Patch Size,Patch Encoding/Decoding Architecture, Image Noising), Comparison with Image Generation Literature, Image Editing等,具體實驗結果如下表分析所示。

這項工作探討了如何縮小離散序列建模(下一個token預測)和連續媒體生成(擴散)之間的差距。我們提出了一個簡單但以前未被探索的解決方案:在兩個目標上訓練一個聯合模型,將每種模式與其首選目標聯系起來。我們的實驗表明,Transfusion可以有效地擴展,幾乎不產生參數共享成本,同時能夠生成任何模態。
求解CEC2018(DF1-DF14))
)



)






)


)



