目錄
一、哈希的定義
二、哈希沖突定義
?三、構造哈希函數的方法
四、四種解決哈希沖突的方法
4.1 開放地址法
4.2 鏈地址法
4.3 再散列函數法
4.4 公共區溢出法
五、鏈地址法結構體設計
六、基本操作的實現
6.1 哈希函數
6.2 初始化
6.3 插入值
6.4 刪除值
6.5 查找值
6.6 打印
6.7 測試用例?
一、哈希的定義
哈希(Hash)是一種將任意長度的輸入數據通過哈希算法轉換成固定長度(通常是固定長度的字符串)輸出的過程。哈希算法通常會將輸入數據映射為一個固定長度的字符串,這個字符串通常稱為哈希值或摘要。
也就是說,我們只需要通過某個函數f ,使得存儲位置=f(關鍵字),那么我們可以通過查找關鍵字不需要比較就可以獲得需要記錄的存儲位置。
哈希函數具有以下特點:
- 輸入數據相同,輸出的哈希值必定相同。
- 不同的輸入數據,哈希值是獨立的,即不會有沖突。
- 哈希值的長度是固定的,不會隨輸入數據的長度變化而變化。
- 哈希值是不可逆的,即無法從哈希值還原出原始的輸入數據。
哈希既是一種存儲方法,也是一種查找方法。
二、哈希沖突定義
兩個或多個關鍵碼key1!=key2,但是通過哈希函數的計算,得出的結果卻相等,這種現象就是發生了哈希沖突。
例如:f(x)=x %10
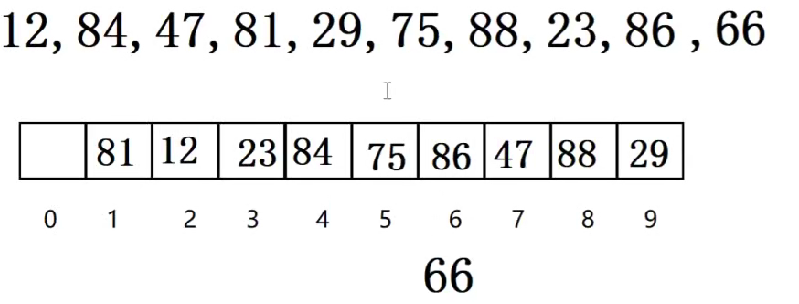
例如上述的86和66,計算得出都應該存放在6號下標,沖突了。?
?三、構造哈希函數的方法
構造哈希函數的方法有很多種。其中一種常見的方法是利用數學運算來將輸入數據映射到固定大小的哈希值。
以下是一些構造哈希函數的方法:
-
直接尋址法:將輸入數據直接作為索引值,獲取對應的哈希值。
-
除留余數法:將輸入數據除以一個數,取余數作為哈希值。
-
平方取中法:對輸入數據進行平方運算,然后取中間幾位作為哈希值。
-
折疊法:將輸入數據分割成固定長度的片段,對每個片段進行加法或異或運算,最終得到哈希值。
-
隨機哈希函數:使用隨機數生成器生成哈希函數,將輸入數據與隨機數進行運算來得到哈希值。
-
加法哈希函數:將輸入數據中的每個字符轉換成ASCII碼,然后求和得到哈希值。
-
乘法哈希函數:將輸入數據乘以一個常數,取乘積的某幾位作為哈希值。
四、四種解決哈希沖突的方法
4.1 開放地址法
? ? ? ? ?線性探測法:

? ? ?但是這種方法會存在一種情況:兩個值本來都不是同義詞卻需要爭奪一個地址,這種現象叫做堆積?。
? ? ?二次探測法:
所以我們想著再探測的時候,盡可能的即向左探測,也向右探測,并且探測的幅度還在呈指數爆炸的趨勢增加。這種方法叫做二次探測法。

? ? ? 隨機探測法:?

4.2 鏈地址法
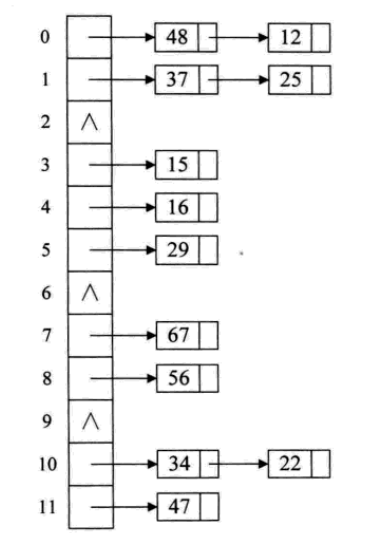
當哈希表用鏈地址法處理沖突時,每個槽位都存儲一個鏈表或其他數據結構,該鏈表用于存儲哈希值相同的鍵值對。當需要查找、插入或刪除一個鍵值對時,首先計算對應的哈希值,然后根據哈希值找到對應的槽位,最后在該槽位上的鏈表中進行操作。
優點:鏈地址法的優點是容易實現和理解,可以有效地處理哈希沖突,適用于存儲大量數據的情況。
缺點:鏈地址法可能會浪費一定的空間用于存儲鏈表的指針,同時在遍歷鏈表時可能會引起緩存未命中。
4.3 再散列函數法
當發生哈希沖突時,再散列函數法會根據一個特定的規則選擇另一個哈希函數,將原始的關鍵字重新哈希,生成一個新的哈希值。然后,再檢查新的哈希值對應的槽位是否為空,如果為空則將數據插入該位置,如果不為空則繼續使用再散列函數生成新的哈希值,直到找到一個合適的位置為止。
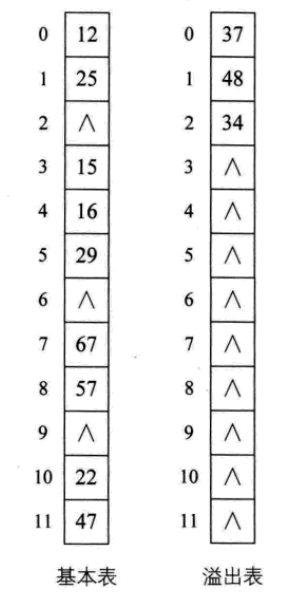
4.4 公共區溢出法
公共區溢出法與鏈地址法不同的是,公共區溢出法在哈希表的每個槽位中直接存儲鍵值對,當發生哈希沖突時,會在其他空槽位中尋找可用的位置來存儲沖突的鍵值對。
具體來說,當插入一個鍵值對時,如果計算得出的哈希值對應的槽位已經被占用,那么就會根據某種探測序列在哈希表中查找下一個可用的空槽位,并將鍵值對存儲在該位置上。具體的探測序列可以是線性探測、二次探測、雙重散列等。

優點:
- 公共區溢出法不需要額外的數據結構來存儲沖突的鍵值對,節省了額外的空間開銷。
- 可以提高數據的局部性,減少緩存未命中的可能性。
- 插入、查找和刪除操作時,不需要額外的指針操作,節省了內存。
缺點:
- 當哈希表變滿時,可能會增加插入操作的復雜度,可能導致性能下降。
- 如果探測序列選擇不當,可能會導致產生大量的聚集現象,影響查找效率。
- 刪除操作可能較為繁瑣,需要標記刪除的鍵值對。
五、鏈地址法結構體設計
鏈地址法中有效節點的結構體設計:1.數據域? 2.指針域
//鏈地址法有效節點的結構體設計
typedef int ElemType;
typedef struct List_Node
{ElemType data; //數據域struct List_Node* next; //指針域
}List_Node, *PList_Node;
鏈地址法中輔助節點的結構體設計: 1. 數組,有INIT_SIZE個格子,每一個格子存放的是單鏈表的輔助節點。
//鏈地址法輔助節點的結構體設計
#define INITSIZE 12
typedef struct List_address
{struct List_Node arr[INITSIZE];
}List_address;六、基本操作的實現
6.1 哈希函數
哈希函數實現,就是計算給定元素的哈希值。其中,ElemType代表元素的類型,INITSIZE代表哈希表的初始大小。
哈希函數采用了取余運算符%來計算元素的哈希值,具體操作是將給定元素val除以INITSIZE后取余數。取余運算可以將元素的值映射到一個較小的范圍內,使得得到的哈希值在哈希表的合法索引范圍內。
代碼實現如下:
//哈希函數
int Hash(ElemType val)
{return val % INITSIZE;
}
6.2 初始化
通過for循環,調用單鏈表中的初始化函數即可完成初始化。
//初始化
void Init_List_Address(List_address* pla)
{for (int i = 0; i < INITSIZE; i++){InitList(&pla->arr[i]);}
}
6.3 插入值
-
首先,函數接受一個指向哈希表的指針
pla和待插入的元素值val作為參數。 -
通過調用之前提到的哈希函數
Hash(val)來計算元素val的哈希值,并將其賦值給index變量。 -
接著,通過調用
malloc()函數動態分配內存,創建一個新的節點pnewnode,用于存儲待插入的元素。 -
如果內存分配成功(即
pnewnode不為NULL),則將元素值val賦給新節點的數據域data。 -
將新節點的
next指針指向哈希表中對應索引位置的鏈表頭節點,以實現在鏈表頭插法的方式將新節點插入到哈希表中。 -
最后,返回
true表示插入成功。
代碼實現如下:
//插入值
bool Insert(List_address* pla, ElemType val)
{assert(pla != NULL);int index = Hash(val);Node* pnewnode = (Node*)malloc(sizeof(Node));if (NULL == pnewnode)return false;pnewnode->data = val;pnewnode->next = pla->arr[index].next;pla->arr[index].next = pnewnode;return true;
}
6.4 刪除值
-
首先,函數接受一個指向哈希表的指針
pla和待刪除的元素值val作為參數。 -
通過調用哈希函數
Hash(val)計算元素val的哈希值,并將其賦值給index變量。 -
調用
Hash_List_Address_Search()函數來查找哈希表中是否存在值為val的節點,將返回的節點賦給指針 q。 -
如果節點
q為NULL,即未找到待刪除的元素,則返回false表示刪除失敗。 -
如果找到了值為
val的節點q,則進入循環,遍歷哈希表中索引為index的鏈表,找到節點q的前驅節點,即節點p。 -
在找到節點
q的前驅節點p后,將前驅節點的next指針指向節點q的后繼節點,實現刪除節點q的操作。 -
通過調用
free(q)釋放節點q占用的內存空間,并將指針q設為NULL,避免懸空指針。 -
最后,返回
true表示刪除成功。
代碼實現如下:
bool Delete(List_address* pla, ElemType val)
{assert(pla != NULL);int index = Hash(val);Node* q = Hash_List_Address_Search(pla, val);if (q == NULL)return false;//此時代碼執行到這,證明val值節點存在在index下標里面的單鏈表上Node* p = &pla->arr[index];for (; p->next != q; p = p->next);//此時代碼執行到這里,證明p和q都就位p->next = q->next;free(q);q = NULL;return true;
}
6.5 查找值
-
首先,函數接受一個指向哈希表的指針
pla和待查找的元素值val作為參數。 -
通過調用哈希函數
Hash(val)計算元素val的哈希值,并將其賦值給index變量。 -
查找哈希表中索引為
index的單鏈表的起始節點,并將其賦給指針p。 -
進入循環,遍歷哈希表中索引為
index的鏈表,逐個比較節點中存儲的數據值是否等于待查找的元素值val。 -
如果找到與待查找的元素值相等的節點,則返回該節點的指針p,表示找到了目標節點。
-
如果在整個鏈表中都沒有找到與待查找的元素值相等的節點,則循環結束后,返回NULL,表示未找到目標節點。
代碼實現如下:
struct Node* Hash_List_Address_Search(List_address* pla, ElemType val)
{assert(pla != NULL);int index = Hash(val);Node* p = pla->arr[index].next;for (; p != NULL; p = p->next){if (p->data == val){return p;}}return NULL;
}
6.6 打印
void Show(List_address* pla)
{for (int i = 0; i < INITSIZE; i++){printf("第%d行:", i);Node* p = pla->arr[i].next;for (; p != NULL;p = p->next){printf("%d->", p->data);}printf("\n");}
}6.7 測試用例?
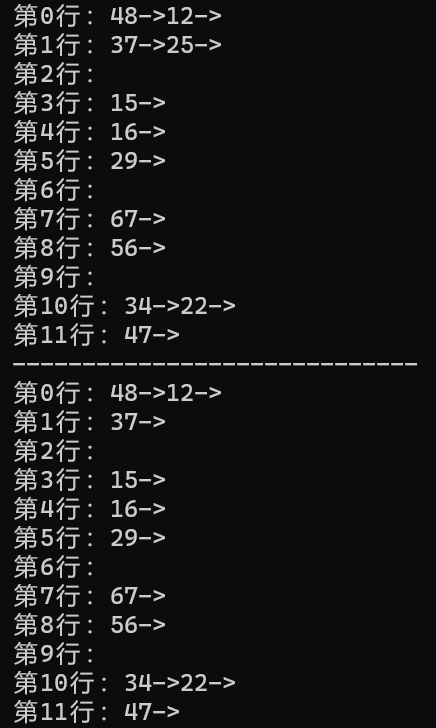
int main()
{List_address head;Init_List_Address(&head);Insert(&head, 12);Insert(&head, 67);Insert(&head, 56);Insert(&head, 16);Insert(&head, 25);Insert(&head, 37);Insert(&head, 22);Insert(&head, 29);Insert(&head, 15);Insert(&head, 47);Insert(&head, 48);Insert(&head, 34);Show(&head);printf("-----------------------------\n");Delete(&head, 25);Delete(&head, 12345);Show(&head);return 0;
}運行結果如下:
)





詳細講解)






)



)

