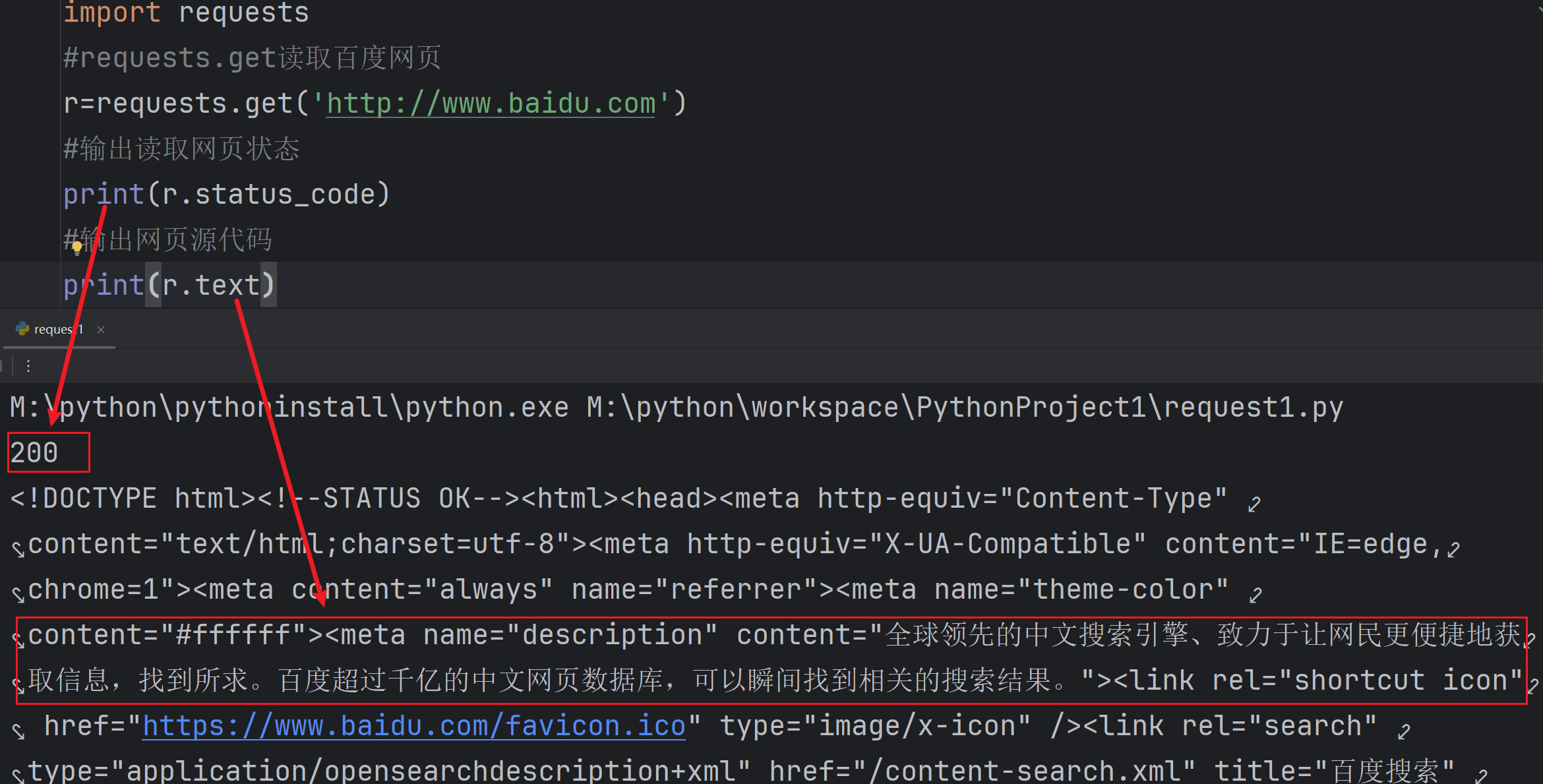
Requests庫初步嘗試
#導入requests庫
import requests
#requests.get讀取百度網頁
r=requests.get('http://www.baidu.com')
#輸出讀取網頁狀態
print(r.status_code)
#輸出網頁源代碼
print(r.text)HTTP 狀態碼是三位數字,用于表示 HTTP 請求的結果。常見的狀態碼有:
200:表示請求成功。404:表示請求的資源不存在。500:表示服務器內部出錯。
所以只有200是成功,其他都是失敗!
運行代碼看到200成功讀取網頁,并解讀了網頁源代碼
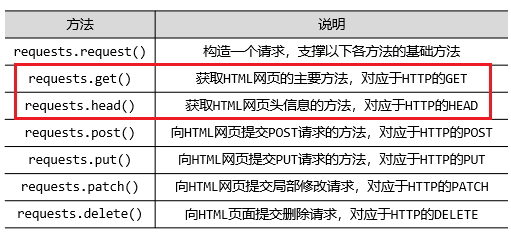
一、Requests庫主要七個方法
 ?
?
1、 requests.get('http://www.baidu.com')
這就是剛開始我們獲取百度網頁的方法,非常常用。
注意這里的網址是要http開頭的,如果只有www則會報錯
#輸出r對象的類型,即requests.models.Response
print(type(r))
#輸出HTTP 頭部信息
print(r.headers)
2、六個方法之間關系

3、PATCH和PUT區別
? 假設URL位置有一組數據UserInfo,包括UserID、UserName等20個字段
需求:用戶修改了UserName,其他不變
- 采用PATCH,僅向URL提交UserName的局部更新請求(局部改)
- 采用PUT,必須將所有20個字段一并提交到URL,未提交字段被刪除(整體改)
PATCH的最主要好處:節省網絡帶寬
二、Response對象的屬性

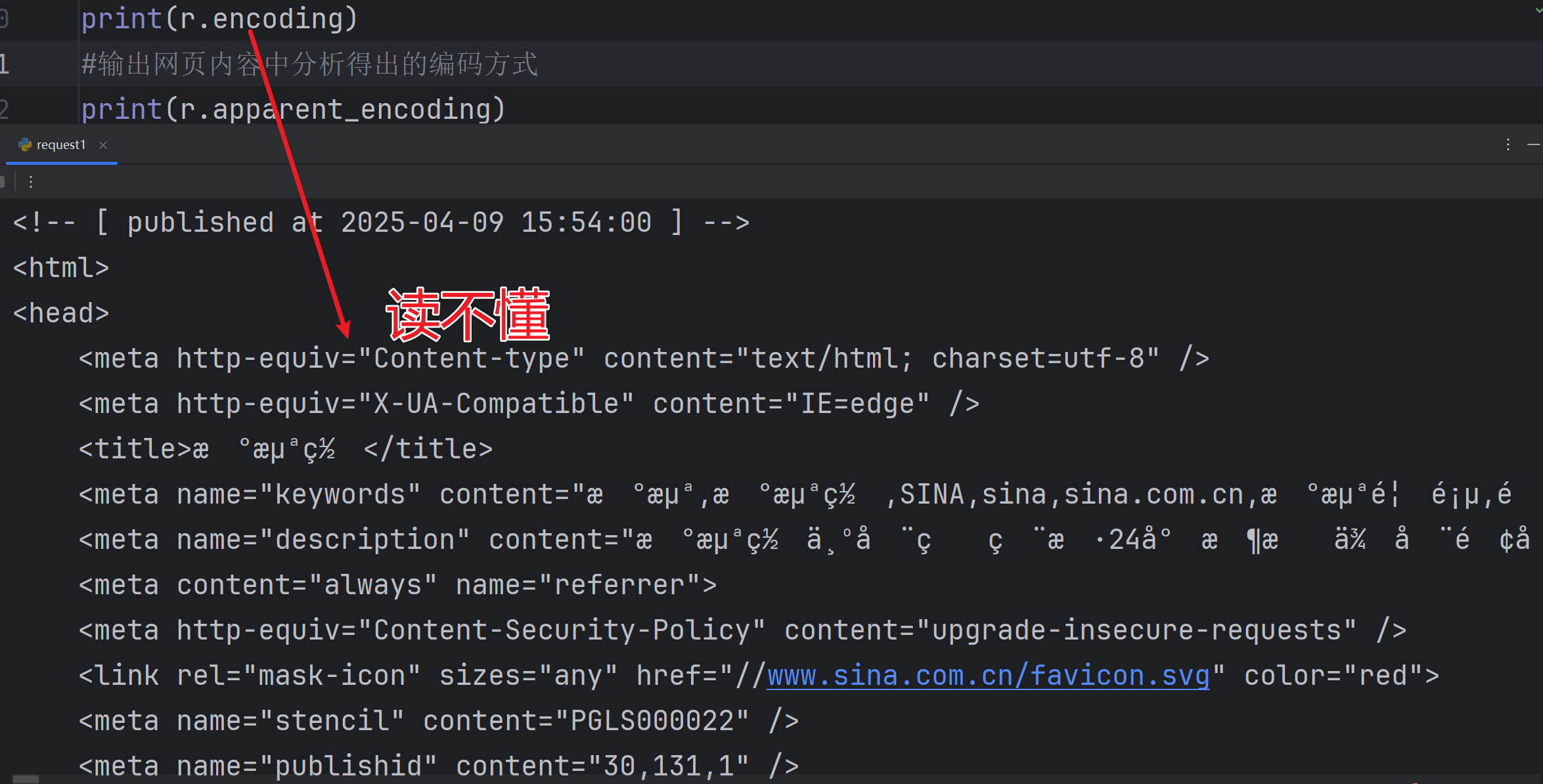
?讓我們來解讀一下網頁的編碼方式:
import requests
r=requests.get('https://www.sina.com.cn/')
print(r.status_code)
print(r.text)
#輸出網頁header中得出的編碼方式
print(r.encoding)
#輸出網頁內容中分析得出的編碼方式
print(r.apparent_encoding)可以看到解析內容看不懂
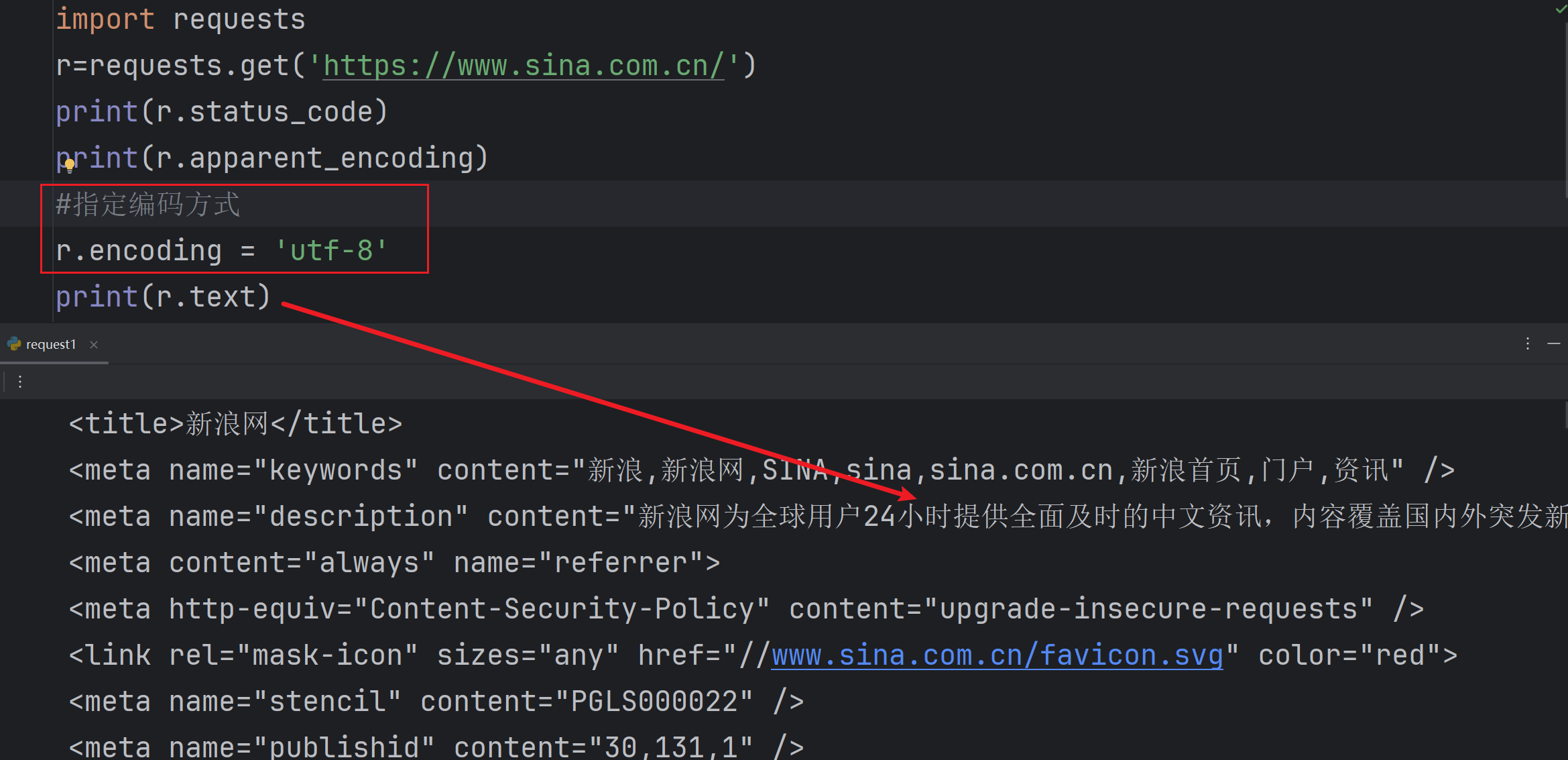
r.encoding得出新浪的編碼方式 ISO-8859-1
r.apparent_encoding分析出新浪推測的編碼方式utf-8
在中文網頁中只有utf-8才能讀出內容
當我們在代碼中添加r.encoding = 'utf-8' 才可以解讀出網頁內容
?
三、Response庫可能發生的異常
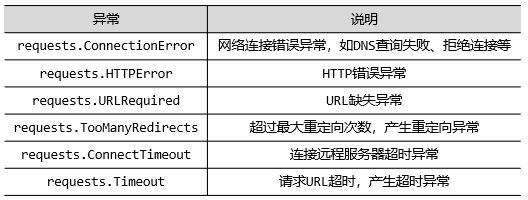
?
四、★★★爬取網頁的通用代碼框架
這是一個通用的代碼:
import requestsdef getHTMLText(url):try:r=requests.get(url,timeout=30)r.raise_for_status() #如果狀態不是200,引發HTTPError異常r.encoding=r.apparent_encodingreturn r.textexcept:return "產生異常"if __name__=='__main__':url='https://www.sina.com.cn/'print(getHTMLText(url))
運行代碼可得

如果在網站中刪除http則會報錯
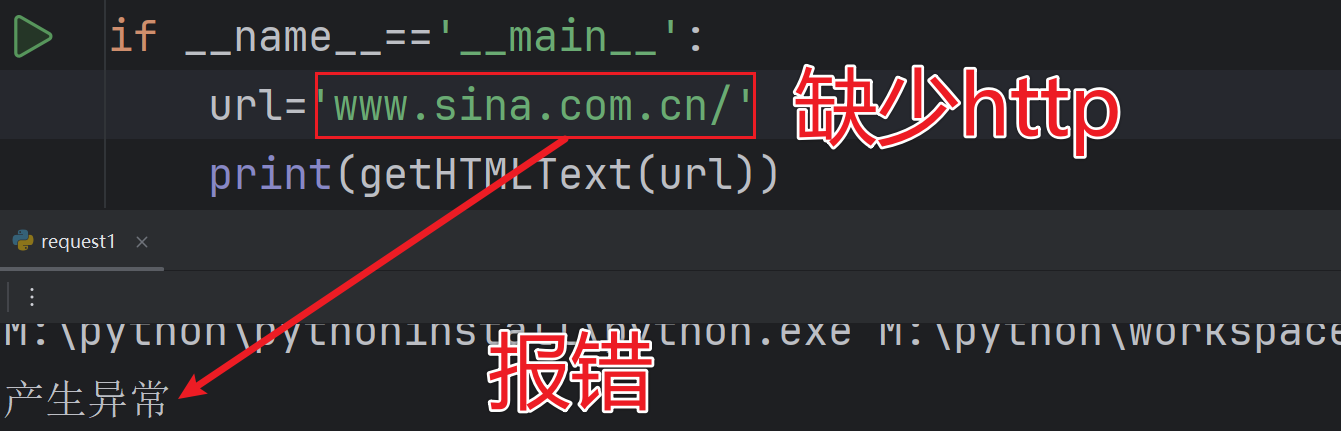 ?
?
五、HTTP協議
HTTP是一個基于“請求與響應”模式的、無狀態的應用層協議
HTTP協議采用URL作為定位網絡資源的標識,URL格式如下:
http://host[:port][path]
- host: 合法的Internet主機域名或IP地址
- port: 端口號,缺省端口為80
- path: 請求資源的路徑
URL是通過HTTP協議存取資源的Internet路徑,一個URL對應一個數據資源
六、總結
- r.status_code:200是成功
- requests.get('http://www.baidu.com')
- PATCH局部更新?? /? PUT全局更新
- r.encoding得出編碼方式
- r.apparent_encoding推測編碼方式
- 添加r.encoding = 'utf-8' 才可以解讀出網頁內容
- 爬蟲通用代碼框架:
import requests
def getHTMLText(url):
??? try:
??????? r=requests.get(url,timeout=30)
??????? r.raise_for_status()??? #如果狀態不是200,引發HTTPError異常
??????? r.encoding=r.apparent_encoding
??????? return r.text
??? except:
??????? return "產生異常"
if __name__=='__main__':
??? url='https://www.sina.com.cn/'
??? print(getHTMLText(url))


:PSI5 —— 汽車安全傳感器的“抗干擾狙擊手”)
)
)


【詳細自用版】)


)



)


安裝streamlit(虛擬環境py3.9))

![[漏洞篇]SSRF漏洞詳解](http://pic.xiahunao.cn/[漏洞篇]SSRF漏洞詳解)