目錄
?1.掃雷游戲
題解
1.記憶化搜索
解法一:遞歸
解法二:記憶化搜索
解法三:動態規劃
?1.掃雷游戲 (暴力+模擬)
鏈接:529. 掃雷游戲
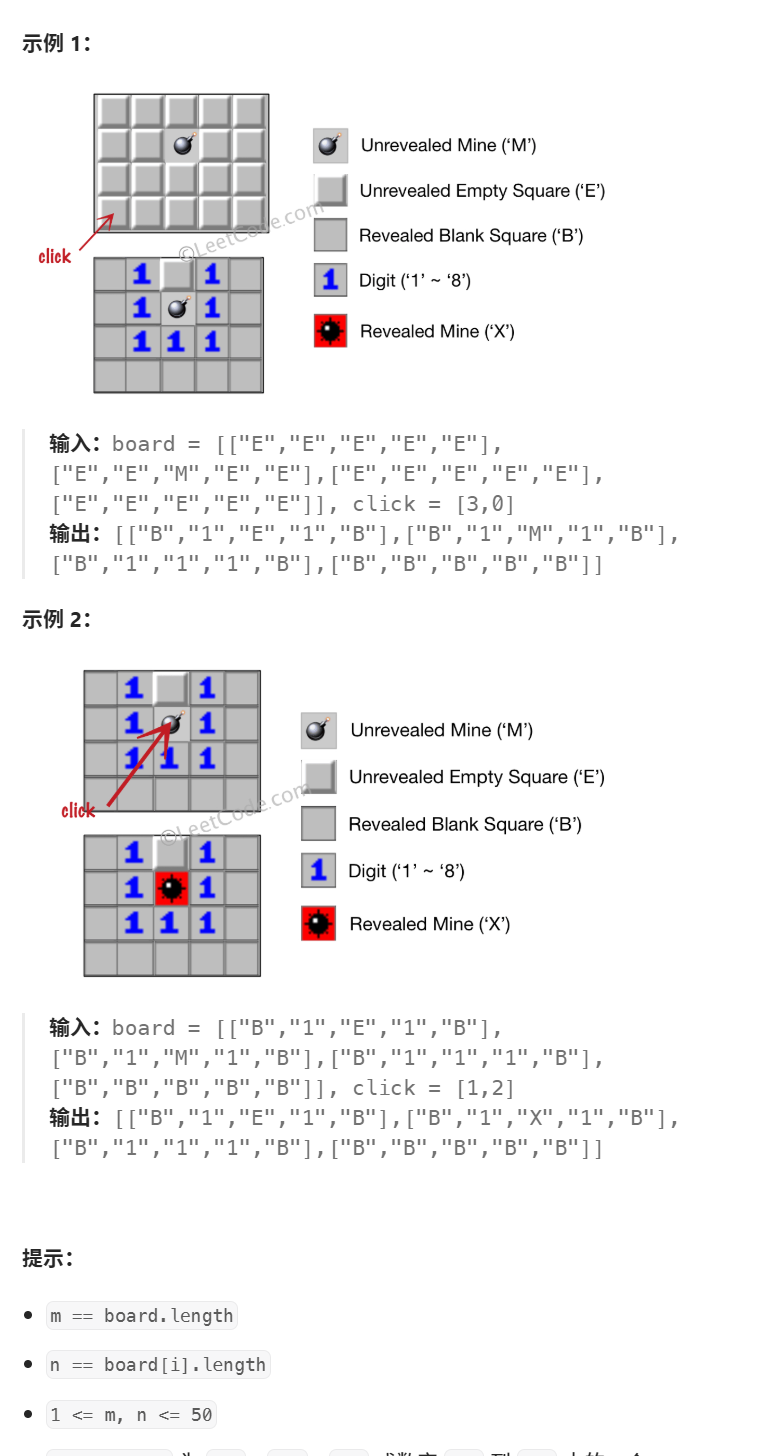
讓我們一起來玩掃雷游戲!
給你一個大小為 m x n 二維字符矩陣 board ,表示掃雷游戲的盤面,其中:
'M'代表一個 未挖出的 地雷,'E'代表一個 未挖出的 空方塊,'B'代表沒有相鄰(上,下,左,右,和所有4個對角線)地雷的 已挖出的 空白方塊,- 數字(
'1'到'8')表示有多少地雷與這塊 已挖出的 方塊相鄰, 'X'則表示一個 已挖出的 地雷。
給你一個整數數組 click ,其中 click = [clickr, clickc] 表示在所有 未挖出的 方塊('M' 或者 'E')中的下一個點擊位置(clickr 是行下標,clickc 是列下標)。
根據以下規則,返回相應位置被點擊后對應的盤面:
- 如果一個地雷(
'M')被挖出,游戲就結束了- 把它改為'X'。 - 如果一個 沒有相鄰地雷 的空方塊(
'E')被挖出,修改它為('B'),并且所有和其相鄰的 未挖出 方塊都應該被遞歸地揭露。 - 如果一個 至少與一個地雷相鄰 的空方塊(
'E')被挖出,修改它為數字('1'到'8'),表示相鄰地雷的數量。 - 如果在此次點擊中,若無更多方塊可被揭露,則返回盤面。
題解
這題說的很多,其實就是給一個mxn的棋盤
再給一個棋盤坐標,點擊這個坐標,把修改后的棋盤返回。
我們要注意一下規則:
- ‘M’ 代表一個 未挖出的 地雷,
- ‘E’ 代表一個 未挖出的 空方塊,
- ‘B’ 代表沒有相鄰(上,下,左,右,和所有4個對角線)地雷的 已挖出的 空白方塊,

前面我們都只研究上下左右,這里還要考慮斜對角線4個位置。
- 也就是說如果當前被挖的空格周圍沒有地雷,就把它標記成B。
- 數字(‘1’ 到 ‘8’)表示有多少地雷與這塊 已挖出的 方塊相鄰,
- 數字 表示這個被挖的格子周圍有多少個地雷
- ‘X ’ 則表示一個 已挖出的 地雷。
根據以下規則,返回相應位置被點擊后對應的盤面:
- 如果一個地雷(‘M’)被挖出,游戲就結束了- 把它改為 ‘X’ 。
- 也就是說如果剛開始給你的這個位置就是雷的話,把這個位置改成‘X’,直接結束即可!
- 處理 E 的話,存在 兩種情況:
- 如果一個 沒有相鄰地雷 的空方塊(‘E’)被挖出,修改它為(‘B’)
- 并且所有和其相鄰的 未挖出 方塊‘E’ 都應該被遞歸地 揭露。
- 如果當前被挖的位置周圍沒有地雷,把它改成’B‘,然后 遞歸 的往周圍走。
- 如果一個 至少與一個地雷相鄰 的空方塊(‘E’)被挖出
- 修改它為數字(‘1’ 到 ‘8’ ),表示相鄰地雷的數量。
- 如果當前被挖的位置周圍有地雷,把它修改成周圍的地雷數,然后就 不要遞歸下去了。直接返回。
如果在此次點擊中,若無更多方塊可被揭露,則返回盤面。
原理:
其實這就是一個模擬,已經告訴怎么去操作了。
當點擊這個位置之后,我們要先統計一下點擊的這個位置周圍有沒有地雷。
- 周圍沒有地雷,就把這個位置改成’B‘,然后遞歸的把周圍所有位置都找一遍。
- 如果周圍有地雷的話,就把這個位置改成地雷數,然后就不要從這個位置在遞歸下去了,返回即可。
- 同理遞歸進去也是如上面一樣先統計周圍有沒有地雷。。。。
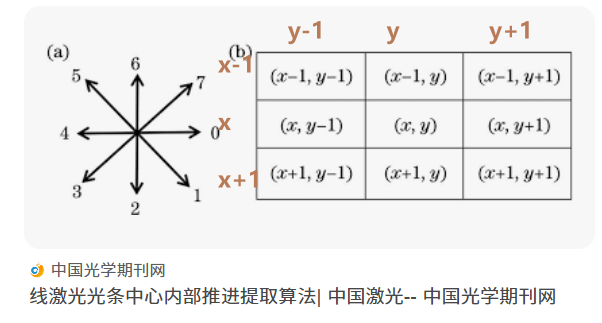
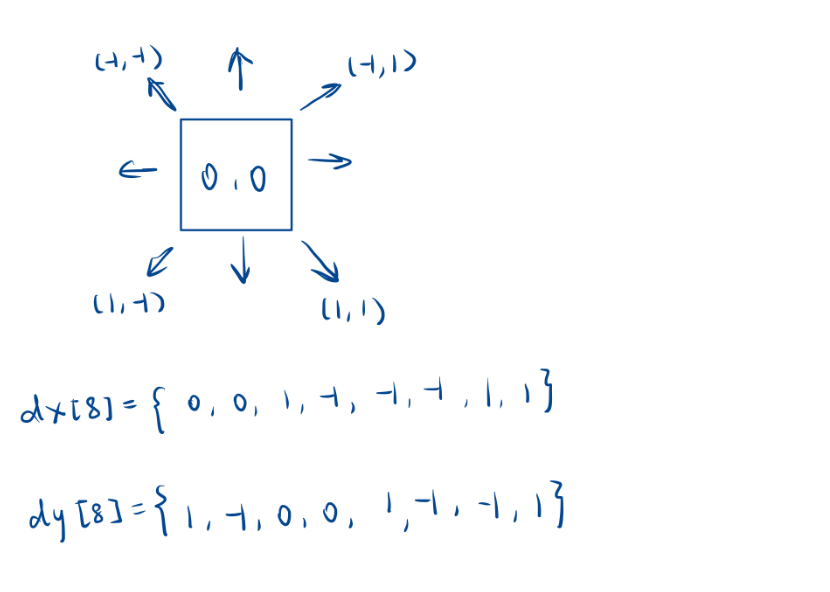
不過這里有個細節問題,我們之前是沿著一個位置上下左右找4個位置。但是這個位置要找一圈8個位置。
- 我們還是和之前一樣,我們直接把向量數組擴展一下就可以了。
- 可以寫兩個-1,1之后然后給它們分別匹配-1,1。
八鄰域搜索
初始時只有M和E
- 我們查找到E的時候進行遞歸
- 標記為B和數字的時候,已經幫我們實現cheak功能啦?
E要么變為B(遞歸),要么變為數字(統計,不遞歸)
class Solution {
public:int dx[8] = {0,0,1,-1,-1,-1,1,1};int dy[8] = {1,-1,0,0,1,-1,1,-1};int m, n;vector<vector<char>> updateBoard(vector<vector<char>>& board, vector<int>& click) {m = board.size();n = board[0].size();int i = click[0], j = click[1];if (board[i][j] == 'M') {board[i][j] = 'X';return board;}dfs(board, i, j);return board;}void dfs(vector<vector<char>>& board, int i, int j) {int count = 0;//先計算周圍地雷數量for (int k = 0; k < 8; ++k) {int x = i + dx[k], y = j + dy[k];if (x >= 0 && x < m && y >= 0 && y < n && board[x][y] == 'M') {++count;}}if (count > 0) {board[i][j] = count + '0'; // 顯示地雷數后停止遞歸} else {board[i][j] = 'B'; for (int k = 0; k < 8; ++k) {int x = i + dx[k], y = j + dy[k];if (x >= 0 && x < m && y >= 0 && y < n && board[x][y]=='E') {dfs(board, x, y); //數字停止遞歸//B標記以掃描,停止遞歸//不斷對未掃描的E進行掃描}}}}
};1.記憶化搜索
什么是記憶化搜索,下面我們以一道比較常見的 509. 斐波那契數 來演示一下什么是記憶化搜索。
- 關于這個斐波那契數,我們很早之前就碰到過如循環、遞推、遞歸
- 不過它 還可以用動態規劃,記憶化搜索來解決。矩陣快速冪也可以解決。
時間復雜度:
- 循環、遞推、遞歸,時間復雜度O(N^2)
- 動態規劃、記憶化搜索,時間復雜度O(N)
- 矩陣快速冪,時間復雜度O(logN)
因為記憶化搜索是基于遞歸代碼來實現的,所以我們先用遞歸寫這道題。

解法一:遞歸
dfs要干的事情就是給我一個數我把它第n個斐波那契數返回來。
關于函數體怎么寫,很簡單求。
- F(0) = 0,F(1) = 1,F(n) = F(n - 1) + F(n - 2),其中 n > 1。
- 求第n個斐波那契數先把n-1和n-2斐波那契數求出來。
- 遞歸出口 n<=1 返回n就可以了。
int fib(int n)
{return dfs(n);
}int dfs(int n){if(n <= 1) return n; return dfs(n-1)+dfs(n-2);}我們先分析一下這個遞歸過程。
- 當n=5的時候,我們分析一下這個遞歸展開過程。
- 就像一顆二叉樹。
- 有多少節點就要遞歸多少次。時間復雜度O(2^N)
我們先分析一下為什么這個遞歸它會這么慢。
慢其實就慢在我們會重復計算一些問題,如d(3)我們會重復進入兩次,但是這兩個d(3)的遞歸展開樹是完全一樣的!
這兩個d(3)向上返回的值是完全一樣的!
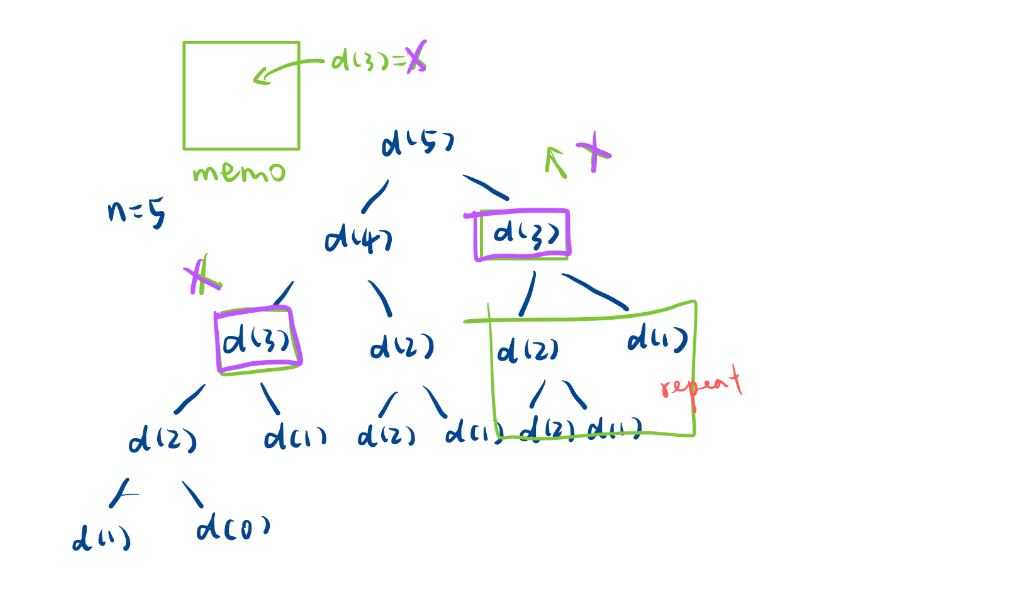
那我們想一下能不能這樣優化一下,來一個備忘錄
- 就是當我從d(5)來深度優先遍歷的時候,先去左邊
- 然后當我從d(3)這顆遞歸樹返回時是一個返回值,(x為返回值)
- 此時把d(3)=x這個f信息丟到備忘錄里。以此來避免之后的重復計算
(備忘錄可能是一個數組、哈希表)。
- 然后當從左邊回來然后去右邊的時候,當我們又一次進入d(3)的時候,此時我就不把d(3)展開了。
- 因為此時我去備忘錄里找找我發現d(3)=x這個消息在左邊就已經計算過了。
- 所以在這里不展開了,直接在備忘錄里把x給拿出來(爽了家人們),然后返回就可以了。
當有一個備忘錄的時候,相同子樹不在展開的時候,是不是就對遞歸做優化了。
像這樣一種方式就叫做記憶化搜索!
解法二:記憶化搜索
在遞歸過程中,發現有一些 完全相同的問題 時
- 我們就可以把完全相同問題的結果放到備忘錄里
- 然后遞歸進入相同問題的時候直接往備忘錄里拿結果就可以了。
- 這就是記憶化搜索,因此又稱作帶備忘錄的遞歸。
此時你會發現其實并不止d(3)會被做優化其實就是剪枝,d(2)也會被優化。
這么多分支都不用進去。
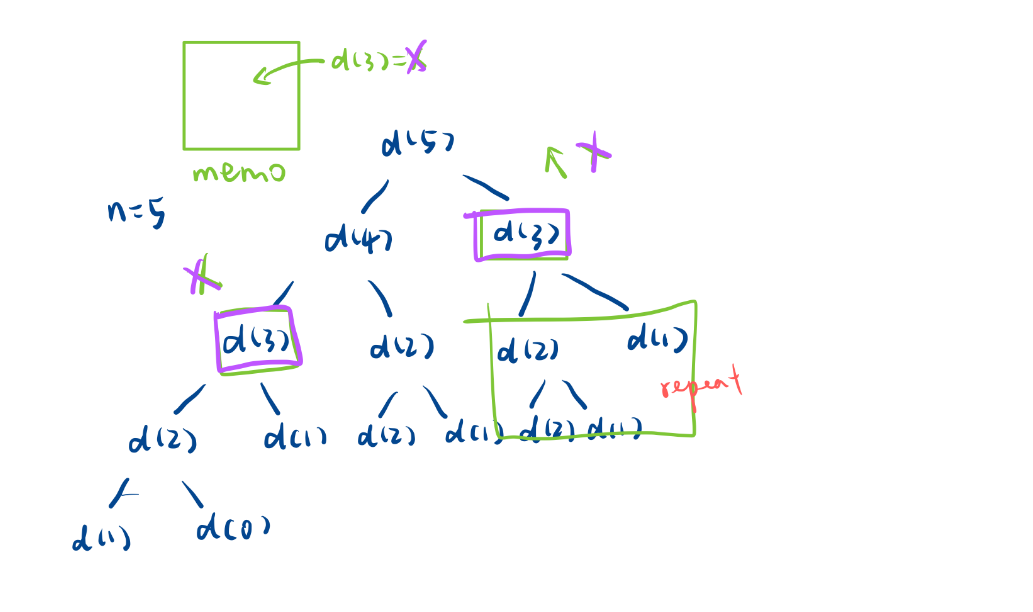
- 時間復雜度直接從O(2^N)變成O(N)。
- 所以添加一個備忘錄可以極大優化我們的搜索過程。
- 這也是記憶化搜索名字的由來,帶著記憶去做dfs,這些重復的地方就不要重復進去了就實現了大量的剪枝
時間復雜度從指數級別降到線性級別!
如何實現記憶化搜索呢?
- 添加一個備忘錄 memo
- 遞歸每次返回的時候,將結果放到備忘錄里面
- 在每次進入遞歸的時候,往備忘錄里面瞅一瞅
開始前瞅一瞅,返回前存一存~
那添加一個什么樣的備忘錄呢?
緊盯這樣一個原則,先找可變參數,然后將<可變參數,返回值>的映射關系存起來。
- 在這個dfs遞歸函數里。可變參數就是n,返回值就是第幾個斐波那契數。
- 所以在這里僅需<int,int> 前面是第幾個斐波那契數的第幾,后面是存的是具體的斐波那契數。
這個備忘錄搞什么數據結構呢?
- 可以搞一個哈希表,這里我們可以來一個數組就行
- 這個數組可以搞成全局的,也可以當成dfs參數。
有時候備忘錄可能需要初始化一下。
- 搞成全局的備忘錄里都是0,但是我們備忘錄里有一個規則,備忘錄里面初始存的值不能跟最終結果的值是一樣的。
- 也就是說要去備忘錄找這個值的時候,我得先判斷一下你這個值是不是已經被計算過了
- 如果這個備忘錄里面d(3)本來就存在X值,但是我還沒有進入過d(3)里呢,就可能會導致誤差。
- 所有要把備忘錄初始化為這個dfs里永遠都不會出現得返回值!
class Solution {
public:int memo[31];int fib(int n) {memset(memo,-1,sizeof memo);//初始化return dfs(n);}int dfs(int n){//先 備忘錄里 瞅瞅if(memo[n]!=-1) return memo[n];//剪枝if(n<=1){memo[n]=n;//return 前就memo存一下return n;}memo[n]=dfs(n-1)+dfs(n-2);return memo[n]; }
};解法三:動態規劃
動態規劃我們一般思路是盯著5個方向。
- 確定狀態表示
- 推導狀態轉移方程
- 初始化
- 確定填表順序
- 確定返回值
解決動態規劃問題現創建一個表格。可能是一維的也可能是二維的。稱為dp表。
我們會賦予現賦予dp表一個含義。
如果有一個i下標,我們會賦予dp[i] 一個含義。
- 其中這個dp[i]的含義就是狀態表示。
- 推導這個狀態轉移方程就我想求這個dp[i]的值的時候,我們會從前面填的表格的值來推導dp[i]是多少。
- 相當于是避免了重復做一件事情,實現了一個從前到后有邏輯的推導,進行線性的優化計算
具體推導處理的公式就是狀態轉移方程。
- 初始化就是我們填dp[i]是依賴之前填的表格,但是0這個位置狀態沒有辦法搞。
因此必須先把0這個位置的值先初始化放后序填表。
- 確定填表順序 如果填dp[i]狀態依賴于之前的狀態,就必須是從左到右。
- 確定返回值 根據題目要求確定最后返回的是這個表中那一個數。

其實我們可以從之前的遞歸和記憶化搜索直接推出這5步,因為它們是一一對應的關系。
- dfs函數頭就是給我一個數n我返回數n的斐波那契數。
- 填寫備忘錄的順序,我們是做了深度優先遍歷因此會一直遞歸下去,所以先會把d(1),dp(0)先放到備忘錄里然后在往上返回一依次放。
- 對應dp表就是從左到右。
- 主函數是dfs(n)調用的,對應dp表返回的就是dp[n]的值。
為什么動態規劃和記憶化搜索這些都是一一對應的?
因為動態規劃和記憶化搜索本質都是一樣的:
- 暴力求解(暴搜),動態規劃要求dp[i]也要把前面都算出來,也是暴搜。
- 無非就是動態規劃和記憶化搜索是對暴搜的優化。
對暴力解法的優化是一樣的:把已經計算過的值,存起來。 記憶化搜索算d(5),因為d(4)和d(3)已經放進備忘錄里面了。
- 直接去備忘錄里找拿d(4)和d(3)就看可以。
- 動態規劃求dp[i]的時候是已經把前面dp[i-1]和dp[i-2]的值已經放到這個表里面了,然后求dp[i]的時候,直接去表里拿就就可以了。
《算法導論》這本書就是把記憶化搜索和常規的動態規劃 歸為 動態規劃。
無法就是
- 記憶化搜索是遞歸(借助 OS 棧來返回)形式的 動態規劃
- 而 常規的動態規劃 是一個 遞推(循環) 存儲的 動態規劃。
class Solution {
public:int fib(int n) {//dp//方程//初始化//順序//返回值int dp[31];dp[0]=0,dp[1]=1;for(int i=2;i<=n;i++){dp[i]=dp[i-1]+dp[i-2];}return dp[n];}
};下面我們總結幾個問題。
1.所有的遞歸(暴搜、深搜),都能改成記憶化搜索嗎?
不是的,只有在遞歸過程中,出現大量完全相同的問題時,才能用記憶化搜索的方式優化。
2.帶備忘錄的遞歸、帶備忘錄的動態規劃、記憶化搜索 都是一回事。
3.自頂向下 vs 自底向上 有什么不同
- 無法就是解決一個問題時思考方向不同而已。
- 自頂向下就是思考決策樹時是按照從上往下的順序來思考的,我想求d(5),我要先求出d(4)和d(3) 。。。。。
- 自底向上就是從下往上思考,求d(5),我可以從最初開始看,由0 1 2推出 5
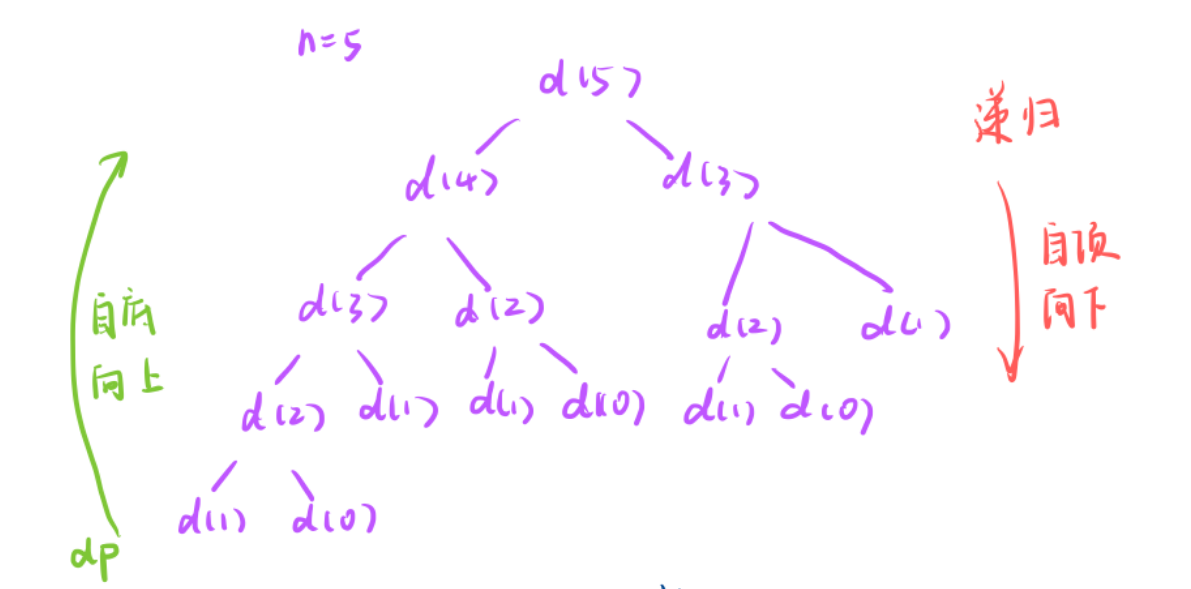
而這兩種方式就正好對應記憶化搜索和常規動態規劃。
- 記憶化搜索是遞歸加一個備忘錄所以記憶化搜索方式就是從上往下。
- 常規動態規劃是遞推方式,先求dp[0],自下往上對推導dp[n]是多少。
4.我們在解決這個問題的時候發現了一個流程
我可以先寫出暴搜,然后改成記憶化搜索,然后把記憶化搜索東西抽象處理就是動態規劃。
- 好像發現解決動態規劃問題的全新流程,暴搜->記憶化搜索->動態規劃。
- 以前是 常規動態規劃。
- 碰到一道動態規劃的題先寫成暴搜,然后改成記憶化搜索,在抽象成成動態規劃。
一般這樣搞也沒錯,但是有些題你直接寫出暴搜會比你用常規動態規劃成本高的多。
- 暴搜->記憶化搜索->動態規劃 和 常規動態規劃 都是解決動態規劃的方式。
- 那個更好, 因人而異,因題而異。
- 在我看來暴搜可以為我們確定狀態表示,提供一個方向。
而且記憶化搜索就已經是一個動態規劃了,從暴搜改到記憶化搜索時間復雜度已經是線性級別了,沒有必要在搞成動態規劃了。














)




