MySQL SQL 優化專題
1. 插入數據優化
-- 普通插入(不推薦)
INSERT INTO tb_user VALUES(1,'tom');
INSERT INTO tb_user VALUES(2,'cat');
INSERT INTO tb_user VALUES(3,'jerry');-- 優化方案1:批量插入(推薦,不建議超過1000條,500-1000較為合適)
INSERT INTO tb_user VALUES(1,'tom'), (2,'cat'), (3,'jerry');-- 優化方案2:手動事務提交(適用于大數據量)
start transaction;
INSERT INTO tb_user VALUES(1,'tom');
INSERT INTO tb_user VALUES(2,'cat');
commit;-- 優化方案3:主鍵順序插入(減少頁分裂)
-- 有序ID:1,2,3,4...
-- 無序ID:3,1,4,2...-- 優化方案4:LOAD命令(百萬級數據)
-- 客戶端連接服務端時,加上參數 -–local-infile
mysql –-local-infile -u root -p
-- 設置全局參數local_infile為1,開啟從本地加載文件導入數據的開關
set global local_infile = 1;
-- 執行load指令將準備好的數據,加載到表結構中
-- 語法:LOAD DATA LOCAL INFILE '文件路徑' INTO TABLE 表名;
load data local infile '/root/sql1.log' into table tb_user fields terminated by ',' lines terminated by '\n' ;
原理說明:
- 批量插入減少事務提交次數
- 順序插入可減少頁分裂概率
- LOAD指令比INSERT快約20倍
2. 主鍵優化
(1)數據組織方式:
在InnoDB存儲引擎中,表數據都是根據主鍵順序組織存放的,這種存儲方式的表稱為索引組織表 (index organized table IOT)。
- InnoDB采用B+樹索引,數據存儲在葉子節點
- 頁分裂(離散插入導致)和頁合并(刪除數據后觸發)
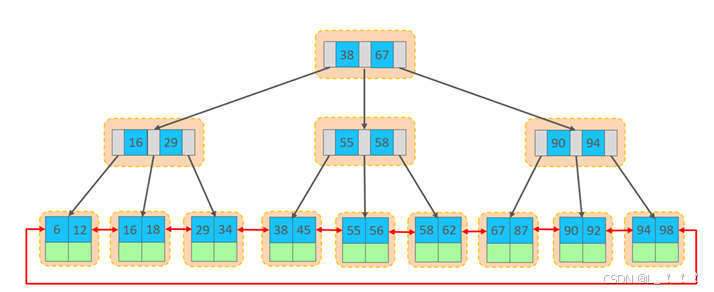
行數據,都是存儲在聚集索引的葉子節點上的。InnoDB的邏輯結構圖:
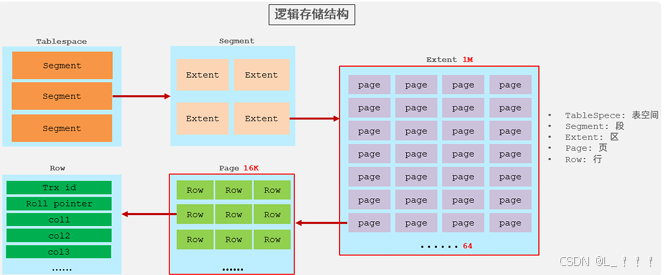
在InnoDB引擎中,數據行是記錄在邏輯結構 page 頁中的,而每一個頁的大小是固定的,默認16K。 那也就意味著, 一個頁中所存儲的行也是有限的,如果插入的數據行row在該頁存儲不小,將會存儲 到下一個頁中,頁與頁之間會通過指針連接。
**(2). 頁分裂 **
頁可以為空,也可以填充一半,也可以填充100%。每個頁至少包含了2行數據(只有一行數據就等于退化成鏈表了)(如果一行數據過大,會行溢出),根據主鍵排列。
A. 主鍵順序插入效果
①. 從磁盤中申請頁, 主鍵順序插入
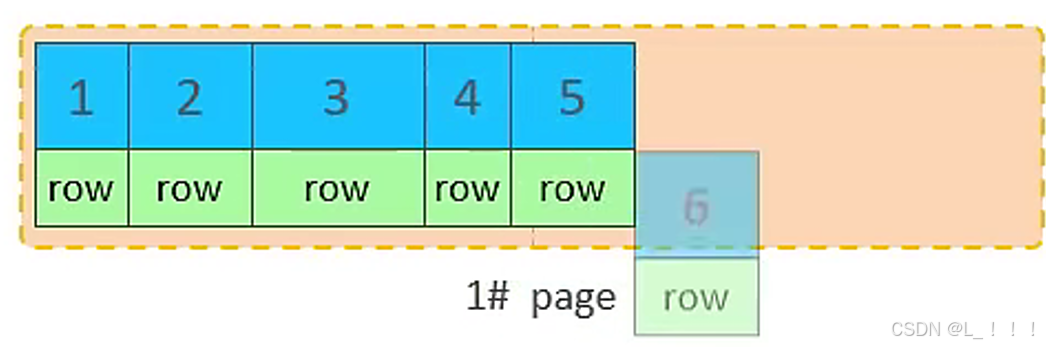
②. 第一個頁沒有滿,繼續往第一頁插入
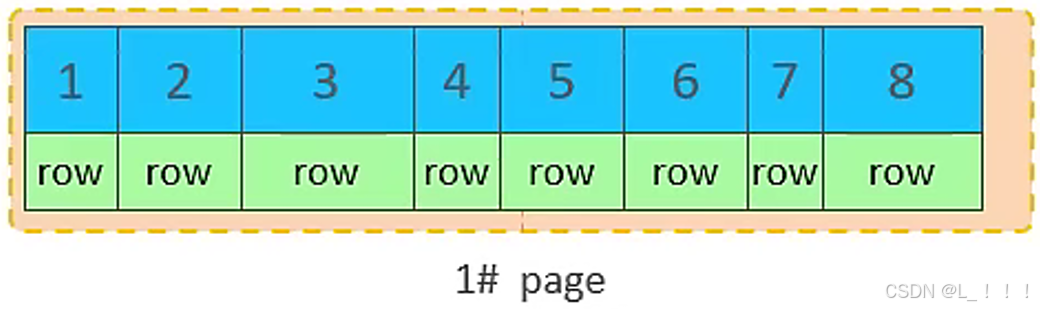
③. 當第一個也寫滿之后,再寫入第二個頁,頁與頁之間會通過指針連接

④. 當第二頁寫滿了,再往第三頁寫入

B. 主鍵亂序插入效果
①. 加入1#,2#頁都已經寫滿了,存放了如圖所示的數據

②. 此時再插入id為50的記錄,我們來看看會發生什么現象 ?
會再次開啟一個頁,寫入新的頁中嗎?
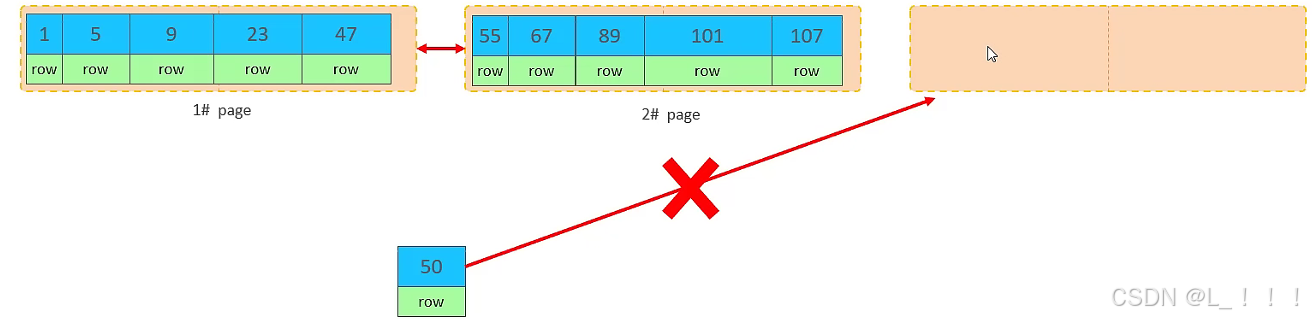
不會。因為,索引結構的葉子節點是有順序的。按照順序,應該存儲在47之后。
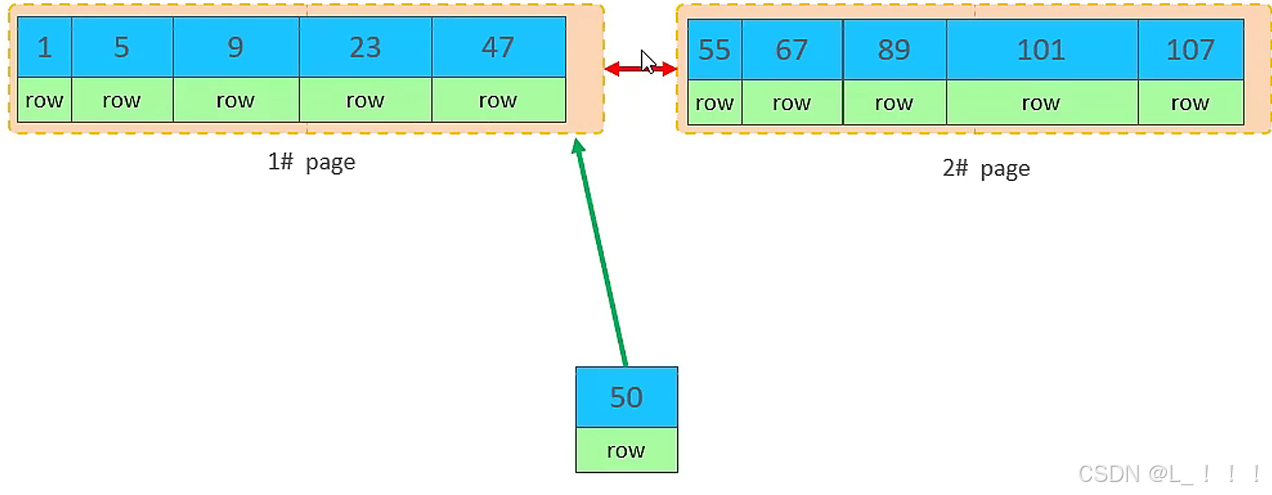
但是47所在的1#頁,已經寫滿了,存儲不了50對應的數據了。 那么此時會開辟一個新的頁 3#。

但是并不會直接將50存入3#頁,而是會將1#頁后一半的數據,移動到3#頁,然后在3#頁,插入50。
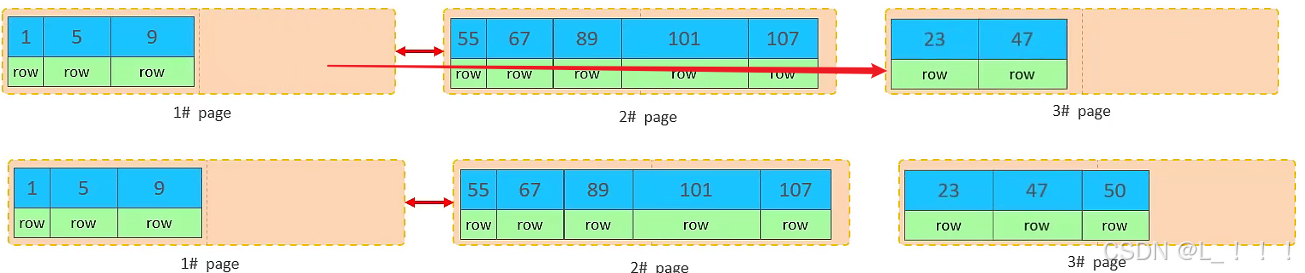
移動數據,并插入id為50的數據之后,那么此時,這三個頁之間的數據順序是有問題的。 1#的下一個 頁,應該是3#, 3#的下一個頁是2#。 所以,此時,需要重新設置鏈表指針。(連接過程類似雙向鏈表的插入過程)

上述的這種現象,稱之為 “頁分裂”,是比較耗費性能的操作。
3). 頁合并
目前表中已有數據的索引結構(葉子節點)如下:

當我們對已有數據進行刪除時,具體的效果如下:
當刪除一行記錄時,**實際上記錄并沒有被物理刪除,只是記錄被標記(flaged)**為刪除并且它的空間 變得允許被其他記錄聲明使用。

當我們繼續刪除2#的數據記錄

當頁中刪除的記錄達到 MERGE_THRESHOLD(默認為頁的50%),InnoDB會開始尋找最靠近的頁(前或后)看看是否可以將兩個頁合并以優化空間使用。
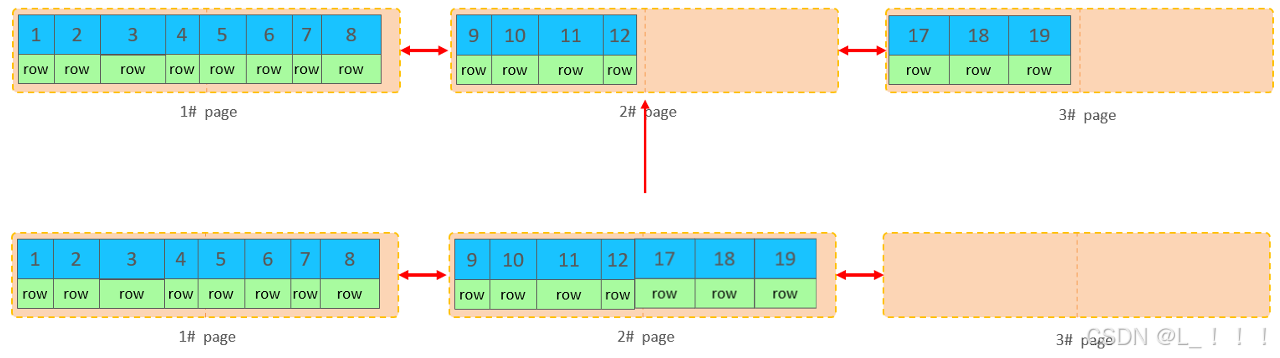
刪除數據,并將頁合并之后,再次插入新的數據21,則直接插入3#頁

這個里面所發生的合并頁的這個現象,就稱之為 “頁合并”。
知識小貼士: MERGE_THRESHOLD(threshold:閾值):合并頁的閾值,可以自己設置,在創建表或者創建索引時指定。
4). 主鍵設計原則
- 滿足業務需求情況下,盡量
降低主鍵長度 - 插入數據時盡量選擇
順序插入,使用AUTO_INCREMENT主鍵 - 盡量不要使用
UUID(無序,插入可能產生頁分裂現象,影響性能)或其他自然主鍵(如身份證號:長度比較長,檢索時會浪費大量的磁盤IO時間) - 避免對主鍵進行
修改(修改主鍵還需要修改對應的索引)
3. ORDER BY 優化
MySQL的排序,有兩種方式:
Using filesort : 通過表的索引或全表掃描,讀取滿足條件的數據行,然后在排序緩沖區sort buffer中完成排序操作,所有不是通過索引直接返回排序結果的排序都叫 FileSort 排序。
Using index : 通過有序索引順序掃描直接返回有序數據,這種情況即為 using index,不需要 額外排序,操作效率高。
對于以上的兩種排序方式,Using index的性能高,而Using filesort的性能低,我們在優化排序 操作時,盡量要優化為 Using index。
-- 需要優化的查詢(出現Using filesort)
explain select id,age,phone from tb_user order by age ;
explain select id,age,phone from tb_user order by age, phone ;
--由于 age, phone 都沒有索引,所以此時再排序時,出現Using filesort, 排序性能較低。-- 創建索引
CREATE INDEX idx_age_phone ON tb_user(age, phone);--創建索引后,根據age, phone進行升序排序
-- 優化后查詢(Using index)
explain select id,age,phone from tb_user order by age, phone ;
--建立索引之后,再次進行排序查詢,就由原來的Using filesort, 變為了 Using index,性能就是比較高的了。
--根據age, phone進行降序一個升序,一個降序
explain select id,age,phone from tb_user order by age desc , phone desc ;
--因為創建索引時,如果未指定順序,默認都是按照升序排序的,而查詢時,一個升序,一個降序,此時
--就會出現Using filesort。
為了解決上述的問題,我們可以創建一個索引,這個聯合索引中 age 升序排序,phone 倒序排序。
創建聯合索引(age 升序排序,phone 倒序排序)
create index idx_user_age_phone_ad on tb_user(age asc ,phone desc);
優化后查詢(Using index)。
升序/降序聯合索引結構圖示:


--根據phone,age進行升序排序,phone在前,age在后。(易錯細節)
explain select id,age,phone from tb_user order by phone , age;
--排序時,也需要滿足最左前綴法則,否則也會出現 filesort。因為在創建索引的時候, age是第一個
--字段,phone是第二個字段,所以排序時,也就該按照這個順序來,否則就會出現 Using filesort。
排序類型:
- Using index:直接通過索引返回數據(性能最佳)
- Using filesort:需要將結果集加載到內存排序(需要優化)
order by優化原則:
A. 根據排序字段建立合適的索引,多字段排序時,也遵循最左前綴法則。(where 后的連表條件只要存在即可,無所謂順序,但order by后面的書寫有順序要求)
B. 盡量使用覆蓋索引。(減少使用select * ,不用回表)
C. 多字段排序, 一個升序一個降序,此時需要注意聯合索引在創建時的規則(ASC/DESC)。
D. 如果不可避免的出現filesort,大數據量排序時,可以適當增大排序緩沖區大小 sort_buffer_size(默認256k)。
4. GROUP BY 優化
-- 未優化(出現Using temporary)
EXPLAIN SELECT profession, COUNT(*) FROM tb_user
GROUP BY profession;-- 創建索引后優化
CREATE INDEX idx_pro_age_sta ON tb_user(profession,age,status);
EXPLAIN SELECT profession, COUNT(*) FROM tb_user
GROUP BY profession; -- 使用索引
優化方法:
A. 在分組操作時,可以通過索引來提高效率。
B. 分組操作時,索引的使用也是滿足最左前綴法則的。
5. LIMIT 優化
在數據量比較大時,如果進行limit分頁查詢,在查詢時,越往后,分頁查詢效率越低。
我們一起來看看執行limit分頁查詢耗時對比:

通過測試我們會看到,越往后,分頁查詢效率越低,這就是分頁查詢的問題所在。 因為,當在進行分頁查詢時,如果執行 limit 2000000,10 ,此時需要MySQL排序前2000010 記 錄,僅僅返回 2000000 - 2000010 的記錄,其他記錄丟棄,查詢排序的代價非常大 。
(因為葉子排序是雙鏈表,要依次遍歷,越向后時間越長。)
優化思路: 一般分頁查詢時,通過創建 覆蓋索引 能夠比較好地提高性能,可以通過覆蓋索引加子查詢形式進行優化。
explain select * from tb_sku t , (select id from tb_sku order by id
limit 2000000,10) a where t.id = a.id;
-- 低效寫法(耗時隨偏移量增加)
SELECT * FROM tb_sku LIMIT 9000000,10;-- 優化方案:記錄上次查詢的最大ID
SELECT * FROM tb_sku WHERE id > 9000000 LIMIT 10;-- 子查詢優化(需覆蓋索引)
SELECT * FROM tb_sku t,
(SELECT id FROM tb_sku ORDER BY id LIMIT 9000000,10) a
WHERE t.id = a.id;
優化原理:
- 避免全表掃描,使用索引覆蓋
- 使用ID分段查詢替代大偏移量
6. COUNT 優化
select count(*) from tb_user ;
我們發現,如果數據量很大,在執行count操作時,是非常耗時的。
MyISAM 引擎把一個表的總行數存在了磁盤上,因此執行 count(*) 的時候會直接返回這個數,效率很高; 但是如果是帶條件的count,MyISAM也慢。
InnoDB 引擎就麻煩了,它執行 count(*) 的時候,需要把數據一行一行地從引擎里面讀出來,然后累積計數 。
如果說要大幅度提升InnoDB表的count效率,主要的優化思路:
自己計數(可以借助于redis這樣的數 據庫進行,但是如果是帶條件的count又比較麻煩了)。
count用法
count() 是一個聚合函數,對于返回的結果集,一行行地判斷,如果 count 函數的參數不是 NULL,累計值就加 1,否則不加,最后返回累計值。
用法:count(*)、count(主鍵)、count(字段)、count(數字)
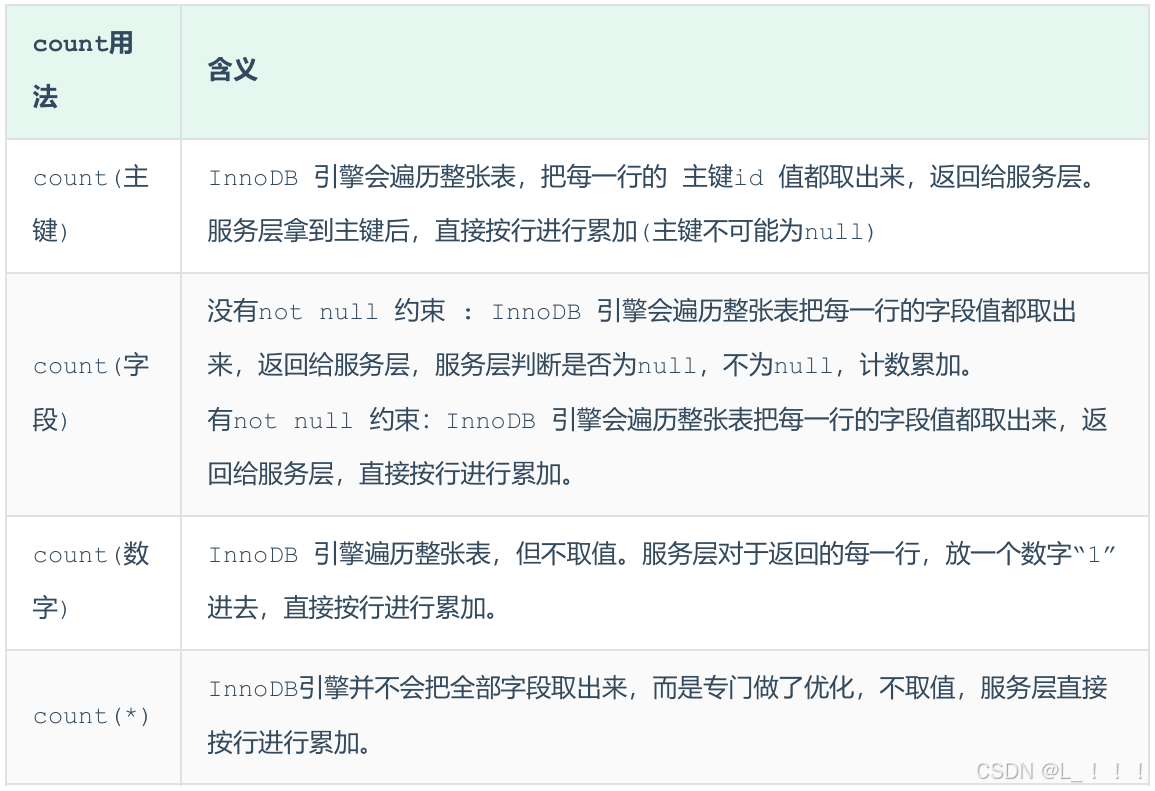
--按照效率排序的話,所以盡量使用count(*),因為專門做了優化。
count(字段)(需要做判斷是否為空)< count(主鍵 id) < count(1) ≈ count(*)-- 統計有效數據條數
SELECT COUNT(1) FROM tb_user; -- 推薦寫法
SELECT COUNT(*) FROM tb_user; -- 官方優化寫法
不同COUNT區別:
- COUNT(字段):統計不為NULL的記錄數
- COUNT(主鍵):遍歷主鍵索引
- COUNT(1):不取值直接累加1
- COUNT(*):MySQL優化過的特殊計數器
7. UPDATE 優化
回憶:InnoDB的三大特性:事務,外鍵,行級鎖
? start transaction; 或者是begin來開啟事務;
我們主要需要注意一下update語句執行時的注意事項。
update course set name = 'javaEE' where id = 1 ;
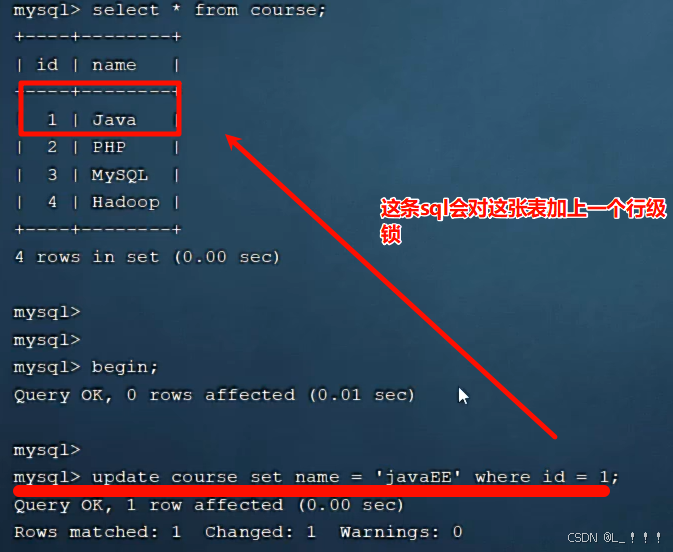
當我們在執行更新的SQL語句時,會鎖定id為1這一行的數據,然后事務提交之后,行鎖釋放。
但是當我們在執行如下SQL時。
update course set name = 'SpringBoot' where name = 'PHP' ;

name這個字段沒有索引,此時加的就不再是行鎖了,而是表鎖。一旦鎖表了,我們的并發性能就會降低!!!
當我們開啟多個事務,在執行上述的SQL時,我們發現行鎖升級為了表鎖。 導致該update語句的性能大大降低。
InnoDB的行鎖是針對索引加的鎖,不是針對記錄加的鎖 ,并且該索引不能失效,否則會從行鎖 升級為表鎖 。
-- 使用索引字段更新(行級鎖)
UPDATE tb_user SET name = 'zhangsan' WHERE id = 1;-- 無索引更新(表級鎖,需要避免!)
UPDATE tb_user SET name = 'lisi' WHERE name = 'wangwu';
優化重點:
- 更新條件必須
走索引,避免行鎖升級為表鎖 - 事務要及時提交,減少鎖持有時間
總結
| 優化類型 | 核心方法 | 典型案例 |
|---|---|---|
| 插入優化 | 批量插入+手動事務提交+主鍵順序插入 | 萬級數據使用LOAD DATA |
| 主鍵優化 | 自增主鍵+避免修改+盡量短 | UUID導致頁分裂問題 |
| ORDER BY | 盡量建立覆蓋索引+避免filesort | 多字段排序注意索引順序 |
| GROUP BY | 利用索引減少臨時表(多字段分組滿足最左前綴法則) | 分組字段建立聯合索引 |
| LIMIT | 覆蓋索引+子查詢(使用ID分段替代大偏移量) | 百萬級分頁優化方案 |
| COUNT | 優先使用COUNT(*)或COUNT(1) | 統計全表數據時避免COUNT(字段) |
| UPDATE | WHERE條件必須走索引 | 無索引更新導致表鎖問題 |
通過以上優化手段,通常可以使MySQL查詢性能提升1-3個數量級,特別是在大數據量場景下效果尤為顯著。實際優化中需要結合EXPLAIN執行計劃進行分析,針對性優化關鍵瓶頸點。
)









)




基于 Vue 3 和 Mapbox GL 實現的坐標拾取器組件示例)



