目錄
目錄
一、隨機森林簡介
(一)隨機森林模型的基本原理如下:
(二)隨機森林模型的優點包括:
(三)森林中的樹的生成規則如下:
(四)在隨機森林中,每棵樹都使用不同的訓練集進行訓練,原因如下
隨機森林的分類性能(即錯誤率)受以下兩個關鍵因素影響:
參數介紹
二、導入數據集
三、對數據進行獨熱編碼轉換
四、選擇特征x和標簽y
五、導入隨機森林模塊并實例化
?六、網格搜索法查找最優參數
一、隨機森林簡介
隨機森林(Random Forest)是一種集成學習(Ensemble Learning)方法,由 Leo Breiman 在2001年提出。隨機森林是一種決策樹(Decision Tree)的集成,它通過構建許多決策樹并結合它們的預測結果來提高模型的準確性和穩定性。
(一)隨機森林模型的基本原理如下:
個體模型(Base Estimator):隨機森林使用決策樹作為基本的學習單元。每個決策樹都是一個獨立的分類或回歸模型。
特征子集(Random Subspace):在構建每棵樹時,隨機森林從原始特征集中隨機抽取一個子集,這個子集的大小通常小于全部特征數。這樣可以減少特征之間的相關性,提高模型的多樣性。
樣本子集(Bootstrap Aggregating,Bagging):在構建每棵樹時,隨機森林使用從原始樣本集中隨機抽取的子集(Bootstrap樣本),這稱為自助采樣(Bootstrap Sampling)。這樣可以減少模型對訓練數據的依賴,提高模型的穩健性。
隨機性(Randomness):除了特征子集和樣本子集,隨機森林在每個節點分裂時也會隨機選擇一個最優特征進行分裂,進一步增加了模型的隨機性。
集成預測:最后,隨機森林通過投票(對于分類問題)或平均(對于回歸問題)來確定最終的預測結果,這提高了模型的預測性能和泛化能力。
(二)隨機森林模型的優點包括:
- 可以處理高維數據和大量特征。
- 可以處理缺失值。
- 自動進行特征選擇,通過特征的重要性評估。
- 不容易過擬合,因為多個決策樹的隨機性和多樣性有助于降低過擬合的風險。
隨機森林廣泛應用于各種機器學習任務,如分類、回歸、特征選擇和異常檢測等,特別是在數據具有復雜關系和非線性關系的情況下,表現得尤為出色。
(三)森林中的樹的生成規則如下:
1)對于每棵樹,我們使用bootstrap sample方法從訓練集中隨機且有放回地抽取N個訓練樣本作為該樹的訓練集。這樣可以確保每棵樹都有不同的訓練數據,從而提高了模型的多樣性。
2)在每個樣本的特征維度為M的情況下,我們指定一個常數m(m遠小于M),并從M個特征中隨機選取m個特征子集。每次樹進行分裂時,我們從這m個特征中選擇最優的特征進行分裂。這種方法可以降低模型的復雜度,提高計算效率。
3)每棵樹都盡最大程度的生長,并且沒有剪枝過程。這樣可以讓每棵樹盡可能地擬合訓練數據,從而提高模型的預測能力。同時,由于我們使用了bootstrap sample方法和隨機特征選擇,所以即使沒有剪枝過程,也不會導致過擬合問題。
(四)在隨機森林中,每棵樹都使用不同的訓練集進行訓練,原因如下
1)隨機抽樣訓練集:如果不進行隨機抽樣,那么每棵樹的訓練集都會完全相同,導致所有樹的分類結果也都會相同。這樣,整個模型就失去了集成學習的意義,因為集成學習的核心在于通過結合多個不同的模型來提高整體的預測性能。
2)有放回地抽樣:如果采用無放回的抽樣,每棵樹的訓練樣本將完全不同,這會導致每棵樹都是從一個“片面”的視角進行學習,從而使得每棵樹的預測結果存在較大的差異。隨機森林的最終預測是通過對多棵樹的預測結果進行投票或平均得到的,這種“求同”的策略旨在綜合多個模型的觀點,以獲得更準確、更穩定的預測。因此,使用完全不同的訓練集來訓練每棵樹并不利于最終的分類結果,這類似于“盲人摸象”,每個模型只了解問題的一部分,無法全面地理解問題。
通過有放回地重新抽樣,我們可以確保每棵樹的訓練集都有所不同,但同時又有一定的重疊,這樣既保證了模型的多樣性,又使得每棵樹都能從整體上對問題有一個較為全面的理解。這種策略有助于提高隨機森林的整體預測性能,使其更加穩健和可靠。
?
隨機森林的分類性能(即錯誤率)受以下兩個關鍵因素影響:
1)森林中任意兩棵樹的相關性:如果森林中的決策樹之間具有較高的相關性,這意味著它們在對數據進行分類時往往會出現相似的錯誤,從而無法通過集成方法有效地降低錯誤率。因此,樹與樹之間的相關性越高,整個森林的錯誤率也就越大。
2)森林中每棵樹的分類能力:另一方面,如果森林中的每一棵樹都具備較強的分類能力,那么整個森林在集成這些樹的預測結果時,錯誤率自然會降低。因此,提高單棵樹的分類能力對于降低整個森林的錯誤率至關重要。
為了優化隨機森林的性能,需要在保持樹與樹之間低相關性的同時,確保每棵樹都具有較強的分類能力。這可以通過調整隨機森林的參數來實現,例如增加樹的數量、調整樹的深度、改變葉節點的最小樣本數等。通過精細地調整這些參數,可以在降低模型錯誤率的同時,提高其整體的泛化能力。
關鍵點:
減小特征選擇個數m,樹的相關性和分類能力也會相應的降低;增大m,兩者也會隨之增大。所以關鍵是如何選擇最優的m(或者是范圍),這也是隨機森林唯一的一個參數。
參數介紹
RandomForestClassifier(n_estimators=10, criterion=’gini’, max_depth=None,
? ? ? ? ? ? ? ? ? ? ? ?min_samples_split=2, min_samples_leaf=1, min_weight_fraction_leaf=0.0,?
? ? ? ? ? ? ? ? ? ? ? ?max_features=’auto’, max_leaf_nodes=None, min_impurity_decrease=0.0,
? ? ? ? ? ? ? ? ? ? ? ?min_impurity_split=None, bootstrap=True, oob_score=False, n_jobs=1,
? ? ? ? ? ? ? ? ? ? ? ?random_state=None,verbose=0, warm_start=False, class_weight=None)
?
參數介紹參考了機器學習5—分類算法之隨機森林(Random Forest)_隨機森林分類-CSDN博客?這篇博客
n_estimators:數值型取值
? ? 含義:森林中決策樹的個數,默認是10
? ??
criterion:字符型取值
? ? 含義:采用何種方法度量分裂質量,信息熵或者基尼指數,默認是基尼指數max_features:?通常情況下取值為int型, float型。
? ? 含義:用于控制在構建每棵決策樹時從原始特征集中隨機選擇的特征子集的大小。
? ? int:表示在構建每棵決策樹時從全部特征中隨機選擇的特征數。例如,如果?max_features=4,則每棵決策樹在構建時從全部特征中隨機選擇 4 個特征。
? ? float:表示在構建每棵決策樹時從全部特征中隨機選擇的特征數的比例。例如,如果?max_features=0.5,則每棵決策樹在構建時從全部特征中隨機選擇 50% 的特征。max_depth:int型取值或者None,默認為None
? ? 含義:樹的最大深度min_samples_split:int型取值,float型取值,默認為2
? ? 含義:分割內部節點所需的最少樣本數量
? ? int:如果是int值,則就是這個int值
? ? float:如果是float值,則為min_samples_split * n_samplesmin_samples_leaf:int取值,float取值,默認為1
? ? 含義:葉子節點上包含的樣本最小值
? ? int:就是這個int值
? ? float:min_samples_leaf * n_samplesmin_weight_fraction_leaf : float,default=0.
? ? 含義:能成為葉子節點的條件是:該節點對應的實例數和總樣本數的比值,至少大于這個min_weight_fraction_leaf值max_leaf_nodes:int類型,或者None(默認None)
? ? 含義:最大葉子節點數min_impurity_split:float取值?
? ? 含義:它用于控制決策樹的早停規則。具體來說,這個參數定義了一個節點在分裂之前必須達到的最小不純度閾值。在決策樹的構建過程中,如果一個節點的信息增益(或基尼不純度減少)小于?
min_impurity_split?設定的閾值,那么這個節點將不再進行分裂,而是被視為一個葉節點。這樣做的目的是為了防止樹的過度生長,從而減少過擬合的風險。需要注意的是,在較新的 scikit-learn 版本中,
min_impurity_split?參數已經被棄用,取而代之的是?min_impurity_decrease?參數。min_impurity_decrease?的工作原理與?min_impurity_split?類似,但它考慮了分裂后每個子節點的樣本數,提供了更精細的控制。min_impurity_decrease:float取值,默認0.
? ? 含義:這個參數定義了一個節點在分裂之前必須達到的最小不純度減少量。bootstrap:布爾類型取值,默認True
? ? 含義:是否采用有放回式的抽樣方式oob_score:布爾類型取值,默認False
? ? 含義:是否使用袋外樣本來估計該模型大概的準確率它在隨機森林模型訓練時啟用或禁用一種稱為“袋外(Out-of-Bag,OOB)估計”的特性。
當?
oob_score=True?時,隨機森林在構建過程中,每次建立樹時都會隨機抽取一部分樣本(通常為樣本總數的一定比例,如 1/3)作為驗證集,剩下的樣本用于訓練。這樣,每個決策樹都會有一部分樣本(即“袋外”樣本)在訓練過程中未被使用。在每個決策樹訓練完成后,可以使用袋外樣本來評估該樹的性能,比如計算準確率、精確率、召回率等。通過所有決策樹的袋外樣本評估,我們可以得到一個整體的模型性能估計,即?
oob_score。這對于評估模型的泛化能力、選擇合適的參數,以及防止過擬合非常有幫助。oob_score?是一種無監督的模型評估方法,因為它不需要額外的驗證集。請注意,
oob_score?可能會消耗額外的計算資源,尤其是在數據集很大或者樹的數量很多時。如果計算資源有限,可能需要權衡是否開啟這個參數。也就是說
OOB(Out-of-Bag)評估方法不需要額外的數據集來評估模型的性能。
在訓練一些機器學習模型時,我們通常需要將數據集分成訓練集和驗證集(或測試集)。訓練集用于訓練模型,而驗證集用于評估模型的性能。這種方法被稱為監督式學習(supervised learning),因為我們需要事先知道輸入和輸出之間的關系。
然而,OOB評估方法不需要額外的數據集,因為它在訓練過程中自動地將一部分數據抽出作為袋外樣本。這些袋外樣本在訓練過程中沒有被使用,因此可以用作評估模型性能。這種評估方法不需要額外的數據集,也不需要事先知道輸入和輸出之間的關系,因此被稱為無監督的(unsupervised)。
總之,OOB評估方法是一種在訓練過程中自動生成袋外樣本的方法,可以用來評估隨機森林模型的性能,而無需額外的數據集。
n_jobs:int類型取值,默認1
? ? 含義:擬合和預測過程中并行運用的作業數量。如果為-1,則作業數設置為處理器的core數。
n_jobs?是隨機森林模型中的一個參數,用于控制并行計算的數量。在訓練隨機森林模型時,會構建多個決策樹。如果?
n_jobs?的取值大于 1,則會嘗試使用多個 CPU 核心來并行構建這些決策樹,從而加速訓練過程。具體來說,n_jobs?參數指定了可以并發執行的 CPU 核心數量。如果?
n_jobs?的取值為 -1,則表示使用所有可用的 CPU 核心。如果?n_jobs?的取值為 1,則表示不使用并行計算,只使用一個 CPU 核心來訓練模型。需要注意的是,如果?
n_jobs?的取值大于 1,則可能會增加內存使用量,因為每個 CPU 核心都需要保留一份模型的副本。因此,如果內存有限,可以嘗試降低?n_jobs?的取值,以減少內存使用量。重要:
class_weight:dict, list or dicts, "balanced"
? ? 含義:class_weight?是一個用于處理不平衡數據集的參數。它用于指定分類任務中各個類別的權重,從而幫助模型更好地學習不平衡數據集中的信息。在不平衡數據集中,某些類別的樣本數量可能遠遠少于其他類別,這可能導致模型在訓練過程中更傾向于預測樣本數量較多的類別,而忽略樣本數量較少的類別。為了解決這個問題,可以使用?
class_weight?參數來為不同類別分配不同的權重,使得模型在訓練過程中更加關注樣本數量較少的類別。
class_weight?參數的取值可以是一個字典,其中鍵是類別標簽,值是對應的權重。例如,如果數據集中有兩個類別,類別標簽分別為 0 和 1,可以使用以下方式指定權重:class_weight = {0: 1, 1: 2}
如果沒有給定這個值,那么所有類別都應該是權重1
? ? 對于多分類問題,可以按照分類結果y的可能取值的順序給出一個list或者dict值,用來指明各類的權重。
class_weight?參數允許用戶為不同的類別設置不同的權重,以此來調整模型對各個類別的關注度。當?class_weight?被設置為?'balanced'?時,模型會自動調整權重,使得權重與每個類別的樣本數成反比。具體來說,如果類別?i?的樣本數為?n_i,那么類別?i?的權重?w_i?將按照以下公式計算:w_i = n_samples / (n_classes * n_i)
其中?n_samples?是總樣本數,n_classes?是類別總數。"balanced_subsample"模式和"balanced"模式類似,只是它計算使用的是有放回式的取樣中取得樣本數,而不是總樣本數?
二、導入數據集
import pandasdata = pandas.read_csv('隨機森林.csv', encoding='utf8', engine='python')
三、對數據進行獨熱編碼轉換
import pandas as pd
df = pd.get_dummies(data, columns=['性別',"父母鼓勵"])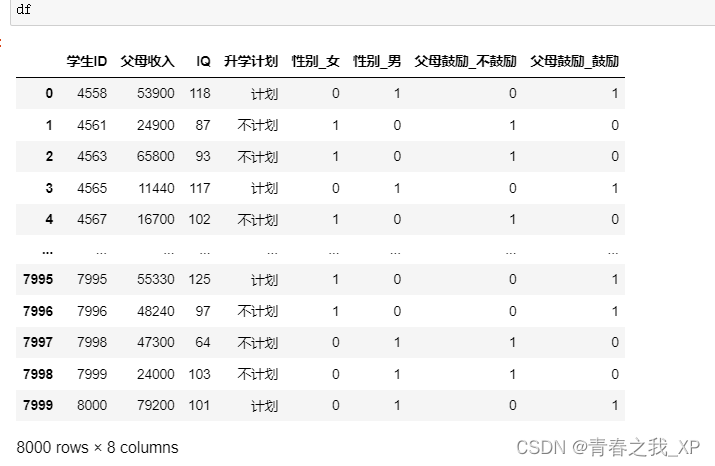
四、選擇特征x和標簽y
x=df.drop(["升學計劃"],axis=1)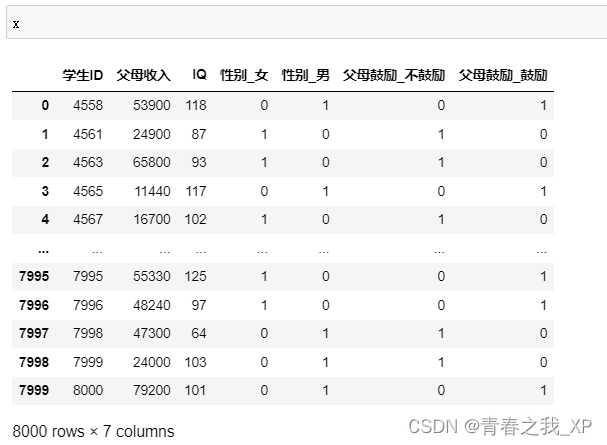
data['升學計劃'] = data['升學計劃'].replace({'計劃': 1, '不計劃': 0})
y=data["升學計劃"]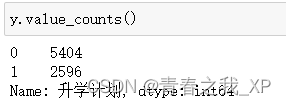
五、導入隨機森林模塊并實例化
from sklearn.ensemble import RandomForestClassifierrfClassifier = RandomForestClassifier()?六、網格搜索法查找最優參數
from sklearn.model_selection import GridSearchCV#網格搜索,尋找最優參數
paramGrid = dict(max_depth=[1, 2, 3, 4, 5],criterion=['gini', 'entropy'], max_leaf_nodes=[3, 5, 6, 7, 8],n_estimators=[10, 50, 100, 150, 200], # n_estimators為隨機森林使用的樹的數量,默認是100
)gridSearchCV = GridSearchCV(rfClassifier, paramGrid, cv=10, verbose=1, n_jobs=10, # verbose 執行過程中調試信息的等級,等級越高,輸出信息越多。n_jobs 并行運算的模型數,默認為1,可根據CPU設置return_train_score=True # 是否返回訓練得分
)
grid = gridSearchCV.fit(df, y)print('最好的得分是: %f' % grid.best_score_)
print('最好的參數是:')
for key in grid.best_params_.keys():print('%s=%s'%(key, grid.best_params_[key]))










:圖像距離變換)








