一任宮長驍瘦
臺高冰淚難流
錦書送罷驀回首
無余歲可偷
——知否知否
完整代碼見:6.s081/kernel at util · SnowLegend-star/6.s081 (github.com)
Lecture 01知識點總結
首先透徹理解Lecture01的知識很是重要
①pid=wait((int *) 0);
“wait(int *status)”函數用于等待子進程的終止,它的參數是一個指向整數的指針(通常是 int * 類型),并且通常用來存儲子進程的終止狀態。這里“0”意思是將指針賦值為NULL,表示不關心子進程的退出狀態信息,這意味著不打算獲取子進程的終止狀態。
如果傳遞一個非NULL的指針給wait(int *status)函數,它將用來存儲子進程的退出狀態信息,以便可以檢查子進程的退出狀態,例如子進程是正常終止還是出錯等。在這種情況下,應該確保指針指向一個有效的內存位置,以便存儲子進程的狀態信息。而父進程可以利用status這個指針來獲取子進程的退出狀態。
②exec(char *file, char *argv[])詳解
當調用exec(char *file, char *argv[])函數時,xv6 將會卸載當前進程的代碼和數據,并加載并執行指定路徑的新程序。新程序會接管當前進程的上下文,并開始執行。這意味著 exec 調用后,當前進程的地址空間、堆棧、文件描述符等狀態都會被新程序取代。
這對于實現進程的動態加載和替換,以及執行不同的程序非常重要。例如,當您在命令行中運行一個可執行程序時,實際上是通過 exec 系統調用來執行它,從而替換了當前的 shell 進程。
③文件描述符
文件描述符fd其實就是代表了open操作對應的那個文件。例如
fd = open("example.txt", O_WRONLY | O_CREAT | O_TRUNC, 0644);
int write(int fd, char *buf, int n);
這里的fd就是指“example.txt”這文件;此外,write函數里面的fd不能替換為函數名。因為 write 函數需要一個文件描述符作為其第一個參數,而不是文件名稱。文件描述符是一個整數,用于標識已打開文件或其他 I/O 資源。
每個進程都維護一個獨立的文件描述符表,其中包含了該進程打開的所有文件和I/O資源的引用。

 ?
?

 ?
?
④運行可執行文件的問題
對于一般的可執行文件a,要運行它的命名形式為“./a”,而不是直接在命令行輸入“a”來運行。只有當一個可執行文件位于系統的 PATH 路徑中時,可以直接輸入其文件名來運行它,而不需要指定完整的文件路徑。系統會在 PATH 中的各個目錄中查找這個可執行文件,如果找到了匹配的文件,就會執行它。
⑤管道
⑥return 0與exit(0)
int main()函數其實不用return 0,如果main函數沒有顯式的return語句,編譯器將會隱式地在函數末尾插入一個return 0語句,表示程序正常退出并返回0。但是,在xv6只用return 0則會出問題。
在 xv6 中,要正常終止一個進程,應該使用 exit(0) 系統調用而不是在 main 函數中使用 return 0。這是因為 xv6 通過系統調用來通知內核進程的結束,同時執行一些清理工作,以確保資源的正確釋放。exit(0) 系統調用會觸發這個行為,而簡單的 return 0 并不會。
在你提到的錯誤信息中,"usertrap(): unexpected scause 0x000000000000000d" 是一個異常信息,表明出現了意外的異常類型。當你在 main 函數中使用 return 0 時,進程沒有經過適當的清理,導致 xv6 報告了這個異常。
總結起來,為了正常終止 xv6 進程并避免異常錯誤,應該使用 exit(0) 而不是 return 0。這確保了進程的正確退出并執行必要的清理工作。
Boot xv6 (easy)
我奶奶都能過的lab。注意一點就是得在“xv6-labs-2020”這個文件夾底下運行“make qemu”,而不是在“xv6-labs-2020/user”這個文件夾底下運行它。
sleep
真正意義上夢開始的地方
自己編寫的文件得放在“user”文件夾里面,然后在 “Makefile”的“UPROGS”里面添加這個文件名,最后打開qemu進行運行。當然,我們發現不進入qemu也能運行“sleep”這條命令,但是這里的“sleep”命令和我們自己編寫的“sleep”函數有出入。那是因為“sleep”是系統的內置函數,只有打開qemu才能運行我們自己編寫的“sleep”函數。
今天在linux環境下想直接測試講義上的“fork”函數,結果總是報錯。問了GPT才發現原來書上給的一些函數調用是只有xv6才具有的,在普通的linux系統上并不具備這些函數調用。
sleep()實現如下
#include "kernel/types.h"
#include "user/user.h"int main(int argc, char const *argv[]){if(argc!=2){printf("Error!The function should obtain two argument.\n");exit(1);}sleep(atoi(argv[1]));exit(0);
}
pingpong
這個實驗真正意義上把我搞麻了,初次pipe簡直就是惡心至極。開始我一直有一個困擾,就是在父進程進行了pipe(p)之后進行fork(),此時父進程和子進程就都可以訪問這個管道p了。但是我看到好多題解里面明明在一個進程里面關閉了管道的一端比如“close(p[0])”,但是又在另一個進程里面用到了“read(po[0],buf,sizeof(buf))”。我的想法是既然子進程和父進程都可以對管道進行有效操作,那上述的兩個操作不就相悖了嗎?這個疑惑困擾了我兩天,那個時候四處尋找合適的解釋結果都不能很好地解答我的疑惑。然后我又在講義里看到了另一句話“在一個程序中創建子進程后,子進程將會繼承與父進程相同的文件描述符表”,這句話又讓我丈二和尚摸不著頭腦。后來去群里一問才得知這句話的本質和建立軟連接差不多。
?????? 就拿在父進程里面創建的管道來說,子進程自己復制了一份管道的引用。然后close()操作只是作用于這份引用,也就是說子進程自己不能再使用某個端口的引用了,但是這并不影響父進程對兩個端口的操作。領悟到這一層后,我又去測試了一番,果真是這樣。這個困擾我幾天的問題一解決,那pingpong的實現就變得有頭緒了。
?????? 對于實現過程,我最開始想不知道怎么保證父子進程之間的同步關系,在兩個進程里面都是先write()然后接著read()。由于進程執行的異步性必然會導致兩個進程的輸出交雜在一起,就像這樣“43:r:erceecieviev?epo?pnigng”。
后來想到的可能的解決辦法是用wait()來保證子進程和父進程之間的同步關系。但是這個技巧在這題行不通,因為實驗要求我們先打印子進程收到了數據,這就要求父進程自己得先寫入,那把wait()放在父進程部分的開頭就會導致類似死鎖一樣的結果。參考率其他人的結果,他們都是通過控制子進程的write()部分在read()部分后面來保證輸出同步。用wait()一樣可以實現,把wait()放在父進程的wirte()后但是read()之前即可解決。
pingpong()實現如下
?
#include"kernel/types.h"
#include"user/user.h"
#include "kernel/stat.h"int main(){int pipe_ptc[2]; //父進程用來給子進程寫入信息的管道int pipe_ctp[2]; //子進程用來給父進程寫入東西的管道char* ptc_msg="ping",*ctp_msg="pong",ptc[256],ctp[256];if(pipe(pipe_ctp)==-1){printf("There is something wrong with pipe()!");exit(1);}if(pipe(pipe_ptc)==-1){printf("There is something wrong with pipe()!");exit(1);}if(fork()!=0){//子進程的fork()返回0write(pipe_ptc[1],ptc_msg,sizeof(ptc_msg));close(pipe_ptc[1]); //關閉父進程管道的寫入端int parent_pid=getpid();wait((int *)0);if(read(pipe_ctp[0],ctp,256)!=-1){printf("%d: received pong\n",parent_pid);}close(pipe_ctp[0]); //關閉子進程管道的讀入端exit(0);}else{int child_pid=getpid();write(pipe_ctp[1],ctp_msg,sizeof(ctp_msg));close(pipe_ctp[1]); //關閉子進程管道的寫入端if(read(pipe_ptc[0],ptc,256)!=-1){printf("%d: received ping\n",child_pid);}close(pipe_ptc[0]); //關閉父進程的讀入端exit(0); //很重要,要不然子進程不會退出}exit(0);
}
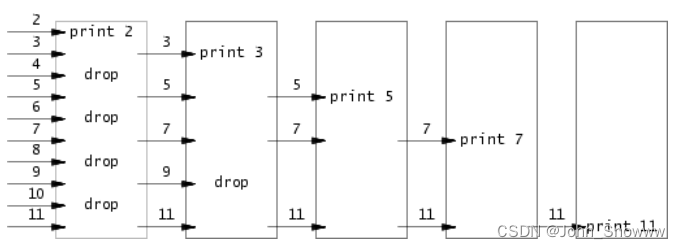
primes
這題主要就是理解文檔給的那個“線程篩”圖——即讓父進程按從小到大的順序把所有的數都傳給子進程,然后子進程排除掉不能被第一個素數2整除的傳遞給孫進程,孫進程再排除掉不能被第二個素數3整除的傳遞給它的子進程,以此類推……很顯然,每個進程傳給它的子進程的那批數字里面第一個是最小的且是素數,遞歸得到的第i個進程可以得到第i-1個素數。
接下來詳細描述下處理過程:
假設最初始的進程p0 對那些數不做任何處理,直接從小到大一股腦傳給第一代子進程p1 。接下的一代代子孫進程對數據的處理就具有一般性了。首先,子進程pi-1 接收從它的父進程pi
傳過來的數據,且pi 傳過來的第一個數n1 為我們得到的第i-1個素數。pi-1 接收完數據后把那些不能被n1 整除的數據傳遞給它的子進程pi-2 ,而后進程pi-2
進行類似的處理。顯然,我們如果要完成上述進程的兩個通信過程,就勢必得用到兩個管道。同時,由于xv6的文件描述符有限,我們就要及時關閉用不到的管道端(即文件描述符)。這里提一句,務必養成及時關閉文件描述符的好習慣,不然最后總是會有各種輸出卡住的問題。
還有些實現的細節需要注意。我遇到的問題是一開始習慣性地創建了個讀緩沖區的數組buf[40],然后讀取管道中的數據就是read(0,buf,sizeof(buf))。乍一看沒問題,但是考慮到如果管道里面的數據沒有40個,那這個進程就會被阻塞在這里,等著管道的寫入端繼續寫入數據直到把40個數據讀滿。所以這題應當是一個整形一個整形地讀入數據。
?
?primes()實現如下
?
#include"kernel/types.h"
#include"user/user.h"
#include "kernel/stat.h"void child(int pipe_p2c[]){// int buf[40]; //buf[0]里面的元素應該是最小的int elem,min; int pipe_s2g[2]; //子進程給孫進程通信的管道close(pipe_p2c[1]);// for(i=0;i<40;i++)// buf[i]=0;// if(read(pipe_p2c[0],buf,40)==0){ //如果沒東西可以讀了就可以開始退出了 不能一下子讀入sizeof(buf),因為管道里面的元素沒有這么多if(read(pipe_p2c[0],&min,sizeof(int))==0){close(pipe_p2c[0]);exit(0);}printf("prime %d\n",min);pipe(pipe_s2g);if(fork()!=0){//子進程準備給孫子進程寫東西了close(pipe_s2g[0]); //把管道的讀入端關掉再說// for(i=1;buf[i]!=0;i++){// if(buf[i]%buf[0]!=0) //不能相除的才傳給下一輩// write(pipe_s2g[1],&buf[i],1); //一個字節一個字節地寫入管道// }while(read(pipe_p2c[0],&elem,sizeof(int))!=0){if(elem%min!=0)write(pipe_s2g[1],&elem,sizeof(int));}close(pipe_p2c[0]);close(pipe_s2g[1]);wait(0);exit(0);}else{//孫子進程child(pipe_s2g);}
}int main(){int i;int pipe_p2c[2];pipe(pipe_p2c);if(fork()!=0){close(pipe_p2c[0]);for(i=2;i<=35;i++){//把這些數字依次寫入管道里面準備讓子進程讀write(pipe_p2c[1],&i,sizeof(int));}close(pipe_p2c[1]);//及時關閉文件描述符,不然輸出會在這里卡住wait(0);exit(0); }else{child(pipe_p2c);}exit(0);
}find
這題主要是對題目的要求思考了很久,一開始沒理解find命令在類unix機器上是怎么用的。查閱了下資料,發現這里的find命令大概格式如下“find path filename”,這里的path既可以是一個目錄如“./a/b”,也可以是一個具體的文件路徑“./a/c.txt”。
然后第二個困擾了我很久的點是題目的hint3:Don't recurse into "." and ".."我心想平時在windows系統或者是linux系統里面查看文件夾的內容時從來就沒有看到過“.”和“..”這兩個特殊的文件啊?后來問GPT說是用ls打開文件目錄就可以看到這兩個特殊的目錄項,嘗試了一番依然沒有發現。直到后面進入qemu的時候再調用ls發現上來就把這兩個特殊的目錄項給列出來了。對于命令中要含有“.”和“..”我也不理解是個怎樣的形式,問了GPT半天才發現形式可以如下“ls -l /path/to/some/directory/./../another/directory”。解決了這兩個疑惑,就可以著手完成find了。
根據hint1先看一遍lc.c很容易搞得自己一頭霧水,我看了兩遍之后還有些不得要領,遂直接開始照著lc.c來實現find的功能,邊寫邊理解。其實兩個最后先出來大同小異,就是find傳過去的參數不僅有“path”,還有“filename”。在lc.c原有的基礎上適當加上對“filename”的匹配處理即可。
從ls.c中我們可以看到先是用open()打開傳過去的“path”,看用戶給出的“path”是否能夠被訪問。然后用fstat()把這個文件的信息存入stat結構體中。處理完這個“path”后,如果path是個目錄,就開始對該目錄底下的目錄項進行遍歷,目錄項有文件和目錄兩種類型。對于目錄項是目錄的情況,我們又可以把這個子目錄信息存入dirent這個結構體中進行遞歸遍歷。
在完成實驗要求的find功能之后,我心血來潮統計了下qemu當前存在的目錄項。一個有趣的結果是“.”和“..”并沒有被計入在目錄項里面。這我就有一個猜測了,“.”和“..”本質就是軟連接。又發現了個很奇怪的問題,把“dir_ItemNum”放在if(de.inum)前面就會導致輸出結果總是為64,而且就算在xv6內部繼續添加文件也還是如此,這是為什么呢?但是如果再在當前目錄創建./a/b這個子目錄,統計結果又正常了。這時在使用命令“find . a”會發現dir_ItemNum的值增加了3。難不成xv6的當前目錄內置了文件上限是64且都已經被創建好了,只不過沒有內容導致這些目錄項的inum是0,但是遍歷當前文件夾的時候還是會遍歷之?
find()如下
?
#include"kernel/types.h"
#include"kernel/stat.h"
#include"user/user.h"
#include"kernel/fs.h"char *fmtname(char *path){static char buf[DIRSIZ+1];char *p;//find first character after last slashfor(p=path+strlen(path);p>path&&*p!='/';p--);p++;//return blank-padded nameif(strlen(p)>=DIRSIZ)return p;memmove(buf,p,strlen(p));memset(buf+strlen(p),' ',DIRSIZ-strlen(p));return buf;
}int flag=0;
int dir_ItemNum=0; //看一下當前目錄底下有多少條信息 “.”和“..”沒被統計進去void find(char *directory,char *filename){char buf[512],*p; //p作為定位指針int fd;struct dirent de;struct stat st;if((fd=open(directory,0))<0){printf("find: cannot open %s\n",directory);exit(1);}if(fstat(fd,&st)<0){printf("find: cannot stat %s\n",directory);close(fd);exit(1);}struct stat stat_temp; //這句話不能定義在case內部嗎? switch(st.type){case T_DEVICE:case T_FILE:if(strcmp(fmtname(directory),filename)==0){printf("%s\n",directory);flag=1;}exit(0);case T_DIR:if(strlen(directory)+1+DIRSIZ+1>sizeof(buf)){printf("find: path too long\n");break;}strcpy(buf,directory); //buf用來存當前正在訪問目錄的路徑p=buf+strlen(buf);*p++='/'; //把p挪到buf的最后一個元素上while(read(fd,&de,sizeof(de))==sizeof(de)){// dir_ItemNum++; //怎么把這句放在if(d.inum)前面只能輸出64呢? if(de.inum==0) //如果 inum 字段等于 0,通常表示該目錄項無效或未使用continue ;memmove(p,de.name,DIRSIZ); //把文件名都存在buf剛添上的“/”后面p[DIRSIZ]=0;if(stat(buf,&stat_temp)<0){ //這不是多此一舉嗎 有用的,可以判斷當前目錄下打開的文件是什么類型printf("find: cannot stat %s\n",buf);continue;}if(stat_temp.type==T_FILE) //如果是文件類型if(strcmp(de.name,filename)==0){printf("%s\n",buf);flag=1; }if(stat_temp.type==T_DIR){if((strcmp(de.name,".")==0)||(strcmp(de.name,"..")==0)) //得排除掉“.”和“..”這兩個目錄防止無限遞歸continue ;find(buf,filename); //遞歸訪問這個目錄 開始把buf寫成de.name了,有點小丑 }}}return ;
}int main(int argc,char *argv[]){if(argc!=3){printf("Usage: find <directory> <filename>\n");exit(1);}find(argv[1],argv[2]);printf("%d\n",dir_ItemNum);if(flag==0)printf("Fail to find the file '%s'!\n",argv[2]);exit(0);
}xargs
這個這個函數的實驗要求十分怪異,我看半天沒理解到底要實現哪些功能,還以為得實現到“find xx xx | xargs echo xxx”這種程度。誰知它只需要實現和echo的組合功能即可,這就簡單不少了。
下面來簡單介紹下管道命令“|”和“xargs”在類unix系統里的用法。用
$ echo “hello” | grep root
管道命令的作用,是將左側命令(cat “hello”)的標準輸出轉換為標準輸入,提供給右側命令(grep root)作為參數。但是,大多數命令都不接受標準輸入作為參數,只能直接在命令行輸入參數,這導致無法用管道命令傳遞參數。舉例來說,echo命令就不接受管道傳參。而xargs命令的作用,是將標準輸入轉為命令行參數。所以一般情況下“|”和“xargs”是穿一條褲子的。
實驗給出的hint是用fork和exec兩個調用來實現這個功能。我們得注意一點,我們正在實現的函數是“xarg.c”!所以agrc和argc[]兩個參數是以命令行中的xagrs命令以及它后面跟著的參數為操作對象的,千萬不要以為這兩個參數讀取的是整個命令行的全部命令和參數!我開始就因為弄混了又搞半天才發現問題所在。如果想要讀取整個命令行的數據,我們可以利用“read(0,p,1)”來一個字符一個字符地讀取所有內容,直到讀取到“\0”為止。因為在許多操作系統中,標準輸入(stdin)的文件描述符通常默認已經打開,因此可以直接調用 read(0, buf, sizeof(buf)) 來從標準輸入讀取數據。
這里又有個小坑,開始問GPT“假如char p=' ',那while(p)會直接跳出嗎?”GPT回答說是,我開始信以為真,直到去dev c++上去測試了下并不然。只有p=‘\0’時while(p)才能直接退出。
踩完以上兩個坑后,思路就明了了起來。當前進程是實現xargs,那就得再fork()一個子進程,子進程調用exec()來實現整個命令行的命令。需要注意的是題目中要求為每一行執行一個命令,所以用數組char** arguments來存儲命令行的命令的時候是一行一行地讀取,即一行讀一個命令或者參數。這里用不用管道都可以實現父進程給子進程傳遞xargs跟著的相應參數。
xargs代碼如下
#include"kernel/types.h"
#include"kernel/stat.h"
#include"user/user.h"
#include"kernel/fs.h"
#include"kernel/param.h"int main(int argc,char *argv[]){int i;char buf[128]={0};int len;char* arguments[32];//用來讀入命令行的輸入if(argc==1){printf("Usage: xagrs [Command] [para1] ...[para n]");exit(1);}for(i=1;i<argc;i++){len=sizeof(argv[i])+1;arguments[i-1]=(char *)malloc(sizeof(char)*len);strcpy(arguments[i-1],argv[i]); //不能簡單地用“=”來賦值,兩者的類型是不一樣的}i--; //因為這里i已經到了agrc那么大,但實際上arguments數組的下標才記到i-1char *p=buf;read(0,p,1);while(*p){ //苦也,GPT誤我!if(*p=='\n'){ //如果讀到一行末尾*p='\0'; //加上'\0'從而構成字符串len=sizeof(buf)+1;arguments[i]=(char*)malloc(sizeof(char)*len);strcpy(arguments[i],buf);i++;memset(buf,0,128); //將buf置為初始狀態p=buf; //將p指針重新定位到buf開頭read(0,p,1);continue;}p++;read(0,p,1);}arguments[i]=0;if(fork()==0){if(exec(argv[1],arguments)==-1){printf("xargs: exec failed.\n");exit(1);}}wait(0); //回收子進程exit(0);
}If you fail a test, make sure you understand why your code fails the test. Insert print statements until you understand what is going on.
今天剛在群里看到說相比于gdb,直接用printf檢查代碼的執行情況會更為簡單方便。經歷了CSAPP的拷打之后,我對此深以為然。還記得proxy lab就是printf大法立功。今天第一次打開s081的Lab guidance,發現了上面那句話,看來printf的好用之處已經廣為人知了。無知時詆毀printf,成長時理解printf,成熟時加入printf。
最后為了先把項目上傳到github的倉庫里面,也是折騰了一晚上,索性終有所得。
?







:圖像距離變換)











