🦄個人主頁:修修修也
🎏所屬專欄:C++
??操作環境:Visual Studio 2022

目錄
一.了解項目功能
二.逐步實現項目功能模塊及其邏輯詳解
🎏構建成員變量
🎏實現string類默認成員函數
📌構造函數
📌析構函數
📌拷貝構造函數
📌賦值運算符重載函數
🎏實現string類成員函數
📌c_str()函數
📌size()函數
📌reserve()函數
📌push_back()函數
📌append()函數
📌insert()函數
📌resize()函數
📌erase()函數
📌find()函數
📌substr()函數
📌clear()函數
📌swap()函數
🎏實現string類運算符重載
📌operator []運算符重載
無const修飾的類對象
有const修飾的類對象
📌operator +=運算符重載
📌operator<<運算符重載
📌operator>>運算符重載
📌operator <運算符重載
📌operator ==運算符重載
📌operator <=運算符重載
📌operator >運算符重載
📌operator >=運算符重載
📌operator !=運算符重載
🎏實現string類迭代器
📌begin()函數
📌end()函數
📌迭代器測試
📌迭代器的衍生品——范圍for
三.項目完整代碼
test.cpp文件
string.h文件
結語
一.了解項目功能
????????在上篇博客中我們詳細介紹了C++標準庫string類型,包含它的常用成員函數及其使用示例:【C++】標準庫類型string
https://blog.csdn.net/weixin_72357342/article/details/136852268?spm=1001.2014.3001.5502
而在本次項目中我們的目標是模擬實現一個string類:
該string包含四個成員變量,分別是:
- char*類型成員變量_str,用于存放指向字符串的指針.
- size_t類型成員變量_size,用于存放類對象中的字符數量(不包含末尾的'\0').
- size_t類型成員變量_capacity,用于存放類對象的字符容量.
- static size_t類型靜態成員變量nops,用于標志字符串的末尾位置-1.
模擬實現的成員函數有:
- 構造函數,拷貝構造函數,賦值運算符重載和析構函數
- c_str()函數
- size()函數
- reserve()函數
- resize()函數
- push_back()函數
- append()函數
- insert()函數
- erase()函數
- find()函數
- substr()函數
- clear()函數
- swap()函數
- 運算符重載函數,包括: = , [] , += , < , == , <= , > , >= , != , << , >>
- 迭代器相關函數,包括:begin()函數,end()函數
二.逐步實現項目功能模塊及其邏輯詳解
????????通過第一部分對項目功能的介紹,我們已經對string類的功能有了大致的了解,雖然看似需要實現的功能很多,貌似一時間不知該如何下手,但我們可以分步分模塊來分析這個項目的流程,最后再將各部分進行整合,所以大家不用擔心,跟著我一步一步分析吧!
!!!注意,該部分的代碼只是為了詳細介紹某一部分的項目實現邏輯,故可能會刪減一些與該部分不相關的代碼以便大家理解,需要查看或拷貝完整詳細代碼的朋友可以移步本文第三部分。
🎏構建成員變量
????????構建成員變量部分的邏輯比較簡單,前面我們也分析過string類需要的4個成員變量,基礎問題就不過多贅述了,代碼如下:
//設置命名空間,防止與庫中的string類沖突 namespace mfc {class string{public://成員函數private://成員變量char* _str;size_t _size;size_t _capacity;static size_t npos;};size_t string::npos = -1;//靜態成員變量只在類外初始化一次 };
🎏實現string類默認成員函數
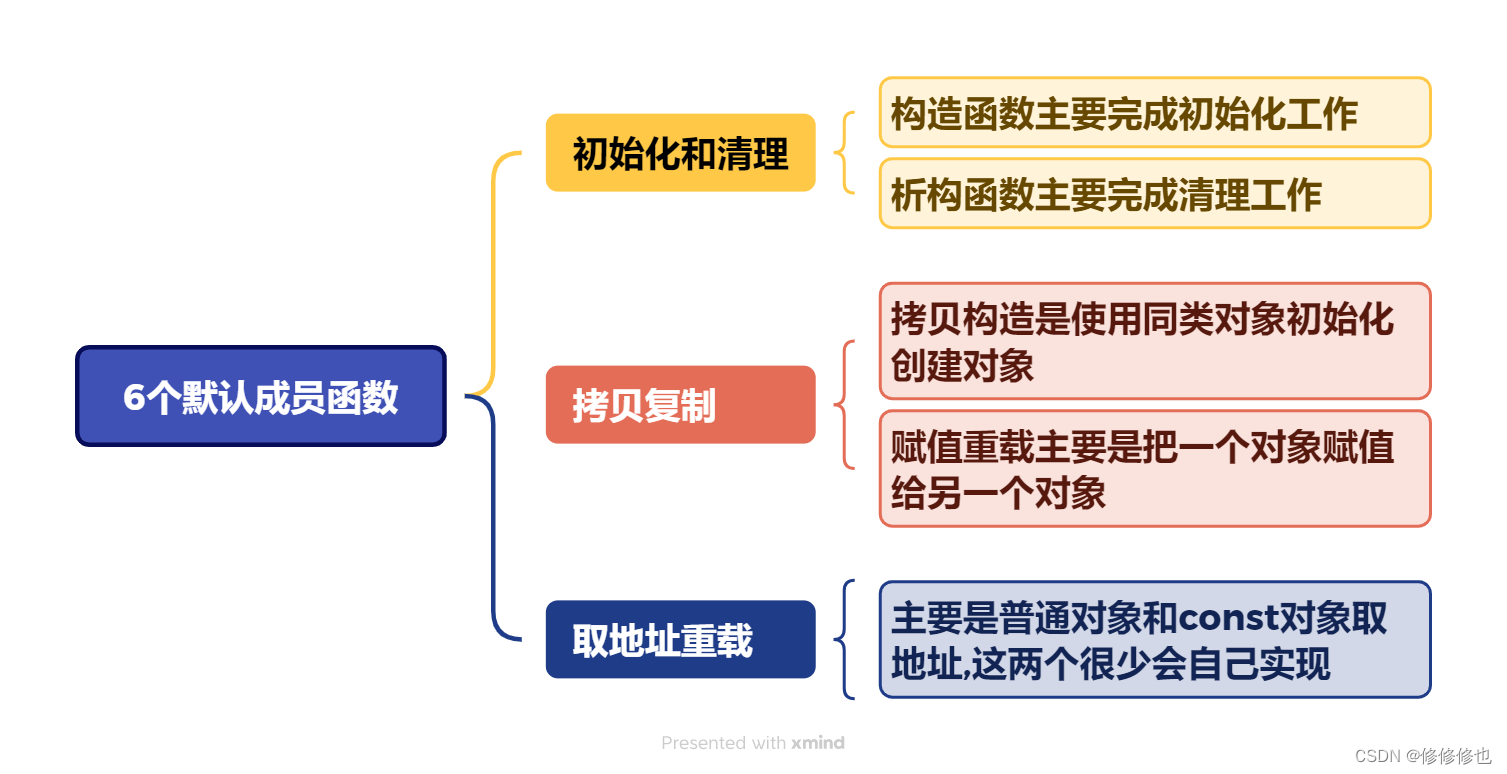
????????一般的類默認成員函數有6個,分別是構造函數,析構函數,拷貝構造函數,賦值運算符重載函數,普通取地址重載函數,和const取地址重載函數:
??????? 對于string類而言,六個默認成員函數我們只需要實現前4個默認成員函數即可,取地址重載函數不需要我們專門手動實現,因為系統自動生成的默認函數就完全可以滿足我們的需求。
📌構造函數
????????注意:
- 初始化列表不是按照代碼編寫的順序執行的,而是按照類成員變量聲明時的順序初始化的,因此如下默認構造函數的代碼是有問題的:
//設置命名空間,防止與庫中的string類沖突 namespace mfc {class string{public://默認構造函數string(const char* str):_size(strlen(str)),_capacity(_size),_str(new char[_capacity + 1]){}private://成員變量char* _str;size_t _size;size_t _capacity;static size_t npos;};size_t string::npos = -1;//靜態成員變量只在類外初始化一次 };
在開完空間后,對于字符串的構造還需要將形參的內容拷貝到類對象成員中,對于string類型的無參構造,我們可以選擇在傳參部分給一個缺省值(即一個空字符串),這樣就可以很好的解決這個問題,因此整合后的代碼如下:
//構造 string(const char* str = ""):_size(strlen(str)),_capacity(_size) {//只是給_str開了空間_str = new char[_capacity + 1];//多開一個空間放'\0'//這步才是給_str放入數據memcpy(_str, str,_size+1); }

📌析構函數
????????因為string類對象在構造時動態開辟了存儲字符的空間,因此我們就需要手動在析構函數里完成對動態開辟空間的釋放,故析構函數代碼如下:
~string() {//判斷_str不是空指針再釋放if (_str){delete[] _str; //釋放動態開辟空間_str_str = nullptr;_size = 0;_capacity = 0;} }
📌拷貝構造函數
??????? 和我們之前實現的Date類不同,string類是一個典型的需要實現深拷貝的類(【C++】詳解深淺拷貝的概念及其區別),系統默認生成的淺拷貝不能滿足我們的需求,因此我們需要自己手動實現深拷貝:
??????? 深拷貝的邏輯不難,共有三步:
- 動態開辟內存空間
- 拷貝原類對象動態開辟空間內容到新開辟的空間中
- 拷貝原類對象的其他內置類型的成員變量
??????? 綜上,實現深拷貝的拷貝構造函數代碼如下:
//拷貝構造 string(const string& s) {_str = new char[s._capacity + 1];memcpy(_str, s._str, _size + 1);_size = s._size;_capacity = s._capacity; }??????? 對于拷貝構造函數,如果我們想要利用swap()來實現更簡便的寫法,就要面臨兩個無法解決的問題:
//利用swap()函數拷貝構造 string(const string& s):_str(nullptr),_size(0),_capacity(0) {string tmp(s);//會無窮遞歸調用拷貝構造導致棧溢出swap(tmp); }??????? 而如果我們解決了第一個問題,就會出現第二個問題:
//利用swap()函數拷貝構造 string(const string& s):_str(nullptr), _size(0), _capacity(0) {string tmp(s._str);//會拷不到\0后的內容swap(tmp); }
📌賦值運算符重載函數
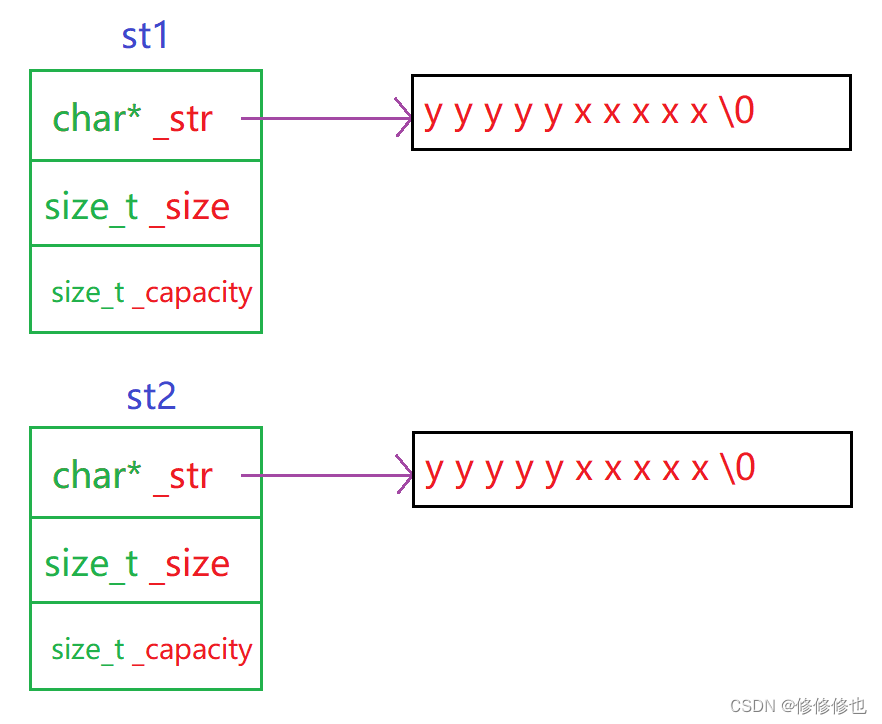
??????? 首先,我們使用一個真實的場景來分析賦值運算符所要完成的功能,如:
string st1("Hello"); string st2("yyyyyxxxxx");st1 = st2;??????? 在還未賦值前,兩個類對象的狀態是下圖這樣的:
??????? 而當我們想要把st2賦值給st1時,我們期望達到的效果是這樣的:
??????? 和拷貝構造的邏輯類似,我們同樣期望賦值操作實現的是"深賦值",即st1和st2賦值后都有各自獨立的空間存儲相同的內容.
??????? 基于這樣的功能訴求,我們大概可以設計賦值操作符重載的傳統函數邏輯了,即
- 先開一段新的內存空間
- 再拷貝內容到新的空間去
- 釋放原空間,指向新空間
- 修改_size和_capacity
??????? 綜上思路,代碼如下:
//傳統思路代碼 string& operator=(const string& s) {if (this != &s){//開辟新空間char* tmp = new char[s._capacity + 1];//拷貝內容到新空間memcpy(tmp, s._str, s._size + 1);//釋放舊空間delete[] _str;//指向新空間_str = tmp;//調整_size和_capacity_size = s._size;_capacity = s._capacity;}return *this; }??????? 但是,我們下面還要介紹一種更為先進的思路,先上代碼給大家體驗一下:
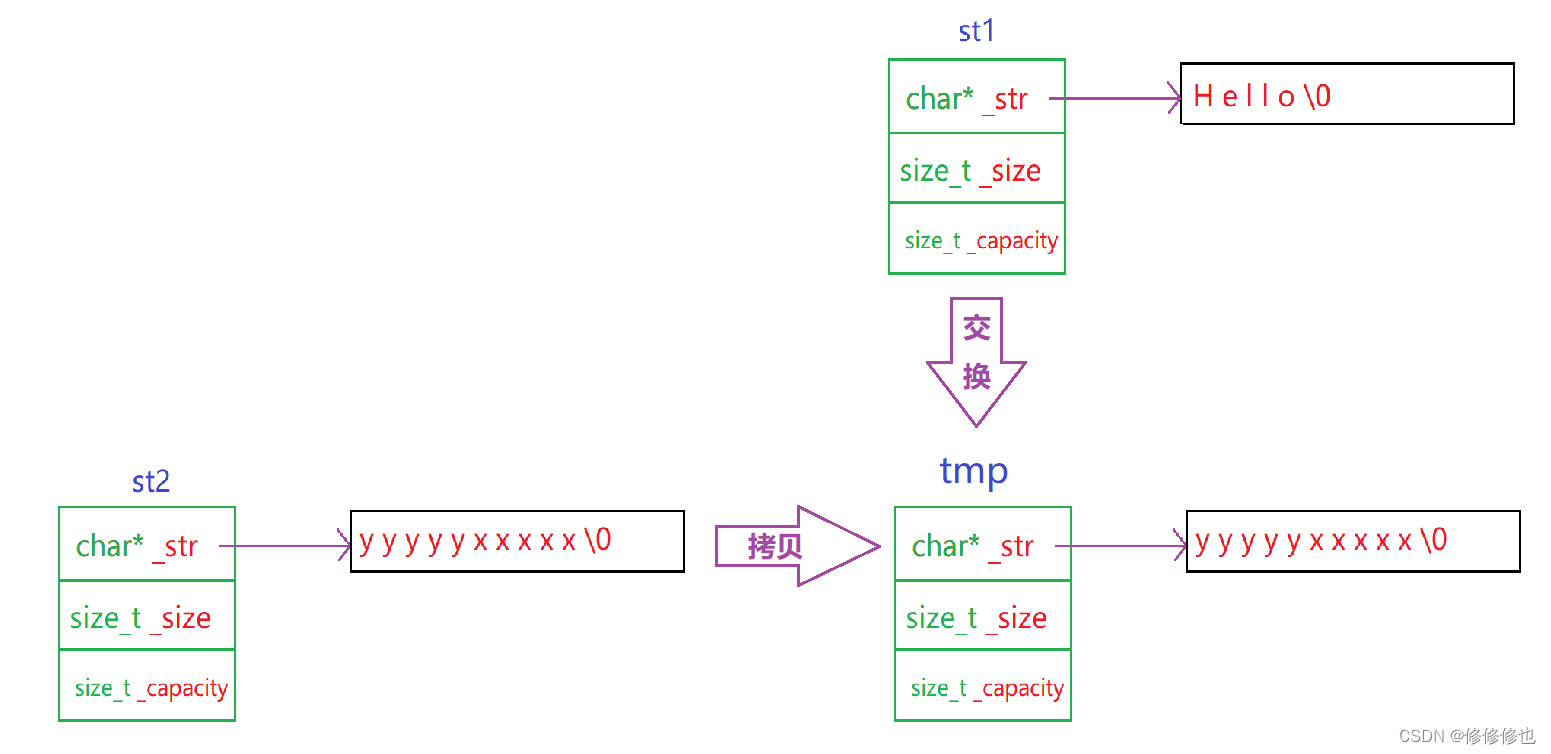
//先進思路寫法 string& operator=(const string& s) {if (this != &s){string tmp(s);swap(tmp);}return *this; }??????? 這個思路是先使用s拷貝構造一個局部臨時變量tmp,再將tmp的內容和this的內容做交換,這樣交換后的this的內容就是我們想要得到的s賦值后的內容了,并且由于類對象出了作用域自動銷毀,因此我們也不需要再手動銷毀交換后的tmp了,因為編譯器會自動幫助我們處理掉,該思路圖示如下:
??????? 上面的代碼似乎足夠簡潔并且無可挑剔了,但仔細觀察一下,其實還有可以優化的點,如:
//最終優化版 string& operator=(string tmp) {swap(tmp);return *this; }??????? 這段代碼利用了形參是實參的一份臨時拷貝這個特點,巧妙的將this指針和待賦值的參數的形參做交換,這樣就可以簡化代碼少做一次局部變量的深拷貝構造和銷毀,對比上面的代碼無論是簡潔度還是效率都又提高了不少.



🎏實現string類成員函數
📌c_str()函數
????????c_str()函數的作用是返回string類c語言形式的字符串,即string類對象中的_str成員,該函數邏輯較為簡單,但還有一些細節需要注意:
????????首先,函數的返回值是需要拿const修飾的,這樣函數返回的內容就不能夠被修改.
????????其次,我們需要給參數列表的括號后面加上一個const,這個const是用來修飾形參部分的this指針的,而作用是為了便于const修飾的類對象也可以調用這個函數.因為權限可以縮小,但不能放大.
????????綜上,代碼如下:
const char* c_str() const//使const對象也可以調用 {return _str; }
📌size()函數
??????? size()函數的作用是返回當前string對象中字符的個數,該函數邏輯較為簡單,我們直接返回類對象中的_size成員即可,但也要注意給形參this指針加上const 修飾,以便于const對象也可以調用函數.
????????代碼如下:
size_t size() const//使const對象也可以調用 {return _size; }
📌reserve()函數
??????? reserve()函數的作用是接收一個無符號整型值n,然后修改string類對象的容量大小為n.
在實現reserve()函數時,我們首先要判斷n是否大于當前類對象的容量,即判斷這次reserve()函數的調用目的是"擴容"還是"縮容",因為調整容量的代價是需要重新開辟目標大小的空間并拷貝原本空間中的數據,會導致效率變低.相比于這個,未縮容導致的空間浪費幾乎可以忽略,因此我們的實現策略是只在需要擴容時才調整容量大小,如果是縮容,則不做任何處理.
擴容實現邏輯如下:
- 動態開辟比目標容量大一個字節(這個字節用于存放'\0')的空間.
- 拷貝原空間內容到新開辟的空間.
- 釋放原空間.
- 修改_str指針,使其指向新開辟的空間.
- 修改容量_capacity的大小為n.
????????綜上所述,reserve()函數實現代碼如下:
void reserve(size_t n) {if (n > _capacity){char* tmp = new char[n + 1];memcpy(tmp, _str, _size + 1);//這里使用strcpy拷貝的話就可能出現對于有\0的字符串的拷貝錯誤現象delete[] _str;//一定要記得釋放_str!!!!!!!_str = tmp;_capacity = n ;} }
📌push_back()函數
??????? push_back()函數的作用是在字符串尾部插入一個字符ch,但在插入字符前,我們要先判斷類對象的容量空間是否足夠,只有容量夠,才能進行尾插,否則要先執行擴容邏輯.擴容時我們只需要調用reserve()函數進行2倍擴容即可,但在reserve()函數參數部分,不能直接傳入_capacity*2,因為如果當前字符串是一個空串,容量為0,則*2后還是0,會導致擴容失敗.
當擴好容后,我們就可以直接在字符串的_size位置插入字符ch了,插入完成后,給_size++,并在字符串++后的_size位置放入一個'\0'字符作為終止標識符.
????????push_back()函數代碼如下:
void push_back(char ch) {//查滿擴容if (_size == _capacity){//2倍擴容reserve(_capacity == 0 ? 4 : _capacity * 2);}//尾插一個字符_str[_size] = ch;++_size;_str[_size] = '\0'; }
📌append()函數
??????? append()函數的作用是在string類對象后追加一個字符串.在追加字符串前,我們要先判斷當前類對象的容量是否夠用,即待插入的字符串的長度len是否大于類對象容量_capacity,如果小于,則要先將容量擴到_size+len,再將待插入的字符串拷貝到類對象字符串后面.如果大于,則可以直接將待插入的字符串拷貝到類對象字符串后面.
????????綜上,append()函數實現代碼如下:
void append(const char* str) {size_t len = strlen(str);if (_size + len > _capacity){//擴容,且至少到_size+len,不能是二倍擴容!reserve(_size + len );//不+1,在reserve內部考慮}memcpy(_str + _size, str,len + 1);_size += len; }
📌insert()函數
??????? insert()函數的作用是在string類對象字符串中插入內容.C++標準庫中insert()函數實現了7個重載版本:
????????有些過于冗余,我們這里只實現兩種版本:
- 往pos位置插入n個char.
- 往pos位置插入一個字符串.
??????? insert()函數的算法邏輯為:
- 判斷pos位置是否合理,不合理需要拋出異常
- 判斷容量是否夠用,如果不夠需要擴容
- 挪動后面的數據
- 插入數據到挪出來的位置上
- _size變為_size+n
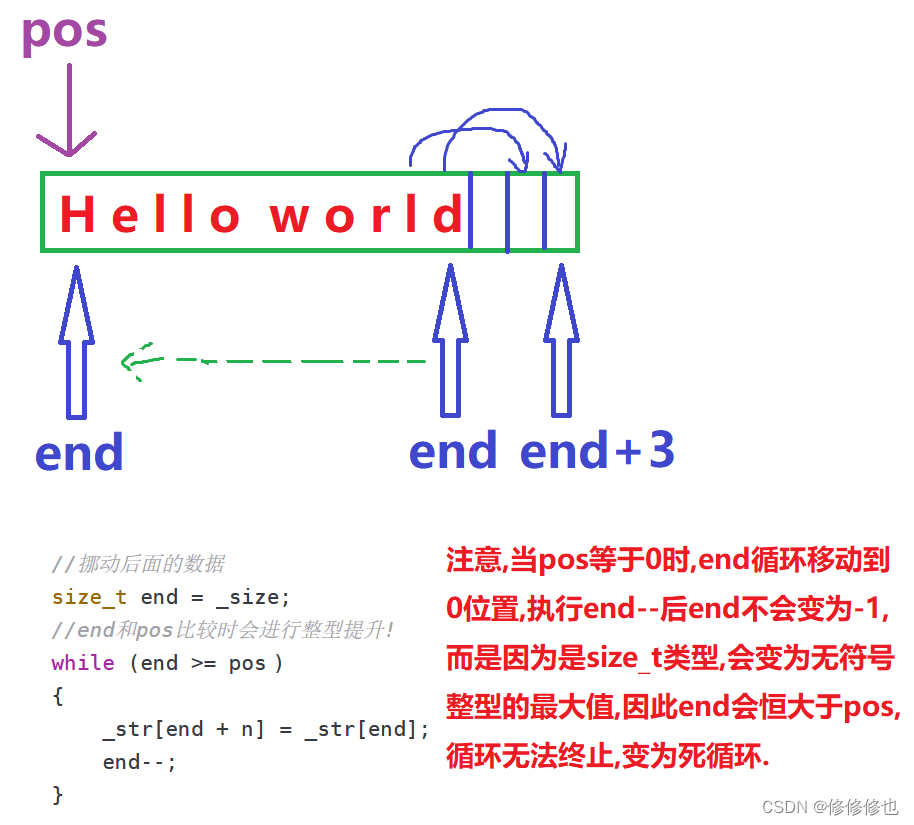
??????? 在insert()函數的挪動數據過程中,有一點需要我們注意,就是如果end是size_t類型的,那么如果while循環只設定一個判斷條件(end >= pos),那么就會出現以下問題:
??????? 而如果我們在這里將end設置成int型,那么整型end與size_t型pos在比較時又會進行整型提升,我們可以編寫一個程序測試一下整型提升:
如下程序可以看到,在內存中,整型的-1是比size_t型的0要大的:
??????? 對于以上問題,解決方式很多,我們可以選擇在比較前就將pos強轉為int型,也可以選則從后一個位置挪前一個的數據,思路如下圖:
????????還可以選擇設置一個靜態成員變量用來表示end已經走到末尾了的那個位置,即size_t型的"-1":
static size_t npos; //靜態成員變量在類外初始化 size_t string::npos = -1;??????? 這樣,我們就可以在循環的判定條件中加入&& end != npos這個判斷條件,就可以有效防止上面出現的問題了.
//pos位置插入n個char void insert(size_t pos, size_t n, char ch) {//判斷pos是否合理assert(pos <= _size);//判斷容量if (_size + n > _capacity){reserve(_size + n);}//挪動后面的數據size_t end = _size;//end和pos比較時會進行整型提升!while (end >= pos && end != npos){_str[end + n] = _str[end];end--;}//插入數據for (size_t i = 0; i < n; i++){_str[pos + i] = ch;}_size += n; }//pos位置插入一個字符串 void insert(size_t pos,const char* str) {//判斷pos是否合理assert(pos <= _size);//判斷容量size_t len = strlen(str);if (_size + len > _capacity){reserve(_size + len);}//挪動后面的數據size_t end = _size;//end和pos比較時會進行整型提升!while (end >= pos && end != npos){_str[end + len] = _str[end];end--;}//插入數據for (int i = 0; i < len; i++){_str[pos + i] = str[i];}_size += len; }

📌resize()函數
????????resize()函數的作用是調整字符串的大小_size為n,其函數定義如下:
????????該函數在執行的時候會面臨三種情況,如下圖所示:
??????? 對于情況1,我們直接在n位置填入'\0'即可,對于情況2和3,我們選擇先擴容,再在后面填入數據,綜上,代碼如下:
void resize(size_t n, char ch = '\0') {if (n < _size){_size = n;_str[_size] = '\0';}else{reserve(n);for (size_t i = _size; i < n; i++){_str[i] = ch;}_size = n;_str[_size] = '\0';} }

📌erase()函數
??????? erase()函數的作用是擦除字符串中pos位置的n個字符.
????????我們可能會遇到兩種情況:一種是從pos擦除n個字符后后面還有有效字符,這種情況下我們要考慮挪動數據,另一種是直接從pos位置刪除掉后面的所有字符,這種情況下我們可以考慮直接在pos位置放上'\0'即可.
??????? 綜上,erase()函數實現代碼如下:
void erase(size_t pos, size_t len = npos) {assert(pos <= _size);//判斷len是不是為缺省參數 或者 pos+len已經超出了_size的范圍,如果是,那么就代表要刪完if (len == npos || pos + len >= _size){//要刪完,直接在這個位置放一個\0就行_str[pos] = '\0';_size = pos;_str[_size] = '\0';}else{size_t end = pos + len;while (end <= _size){_str[pos++] = _str[end++];}_size -= len;} }
📌find()函數
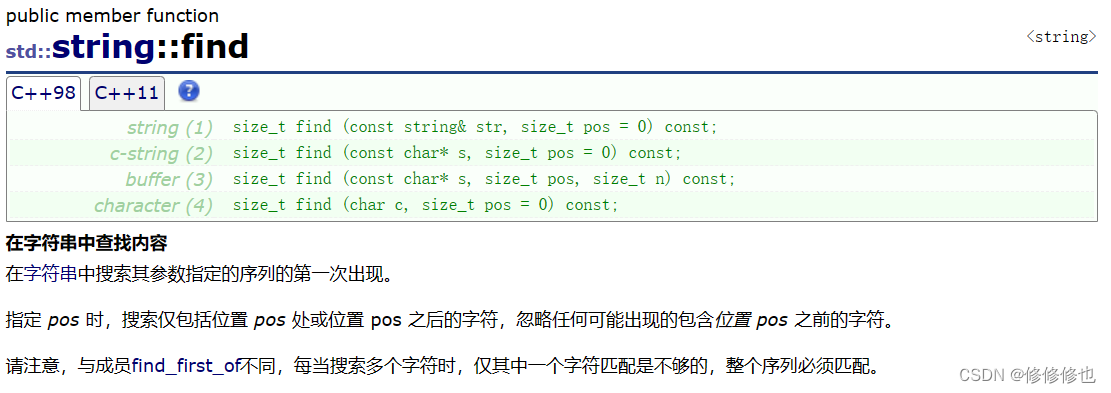
??????? find()函數定義如下:
????????find()函數實現兩個,一個用于在pos位置之后查找一個字符,一個用于在pos位置查找一個字串(利用庫函數strstr()實現,有興趣的朋友可以研究一下BM算法和KMP算法).
????????綜上,代碼如下:
//查找某一字符的位置 //check some character's position size_t find(char ch, size_t pos = 0) {assert(pos < _size);for (size_t i = pos; i < _size; i++){if (_str[i] == ch){return i;}}//沒找著,返回npos//if character is not in this string,return nposreturn npos; }//查找子串 //check some substring's position size_t find(const char* str, size_t pos = 0) {assert(pos < _size);//相關算法:BM算法和KMP算法const char* ptr = strstr(_str + pos, str);if (ptr){//if substring is in this string,return this substring's posisionreturn ptr - _str;}else{//沒找著,返回npos//if substring is not in this string,return nposreturn npos;} }
📌substr()函數
??????? substr()函數定義如下:
??????? substr()函數的實現算法邏輯是:
- 先確定好截取字串的個數,因為n不一定完全有效
- 創建string變量用于存儲字串
- 設置變量容量為n
- 使用循環將主串需要的字符逐一+=到子串上去
- 返回存儲了子串的變量
????????代碼如下:
//獲取一個子串 string substr(size_t pos = 0, size_t len = npos) {assert(pos < _size);size_t n = len;if (len == npos || pos + len > _size)//如果len的長度是npos(非常大)或者pos+len的長度已經超出了_size的大小//這兩種情況都意味著要獲取的字串是從pos開始直到字符串結尾{n = _size - pos;}string tmp;tmp.reserve(n);//i不是從0開始的,但是n長度是絕對長度的,所以判斷條件要注意for (size_t i = pos; i < pos + n; i++){tmp += _str[i];}return tmp; }

📌clear()函數
??????? clear()函數的功能是清空當前類對象的內容,它實現起來非常簡單,就是給類對象的首字符插入一個'\0',然后將類對象的_size置為0即可.
??????? 代碼如下:
void clear() {_str[0] = '\0';_size = 0; }
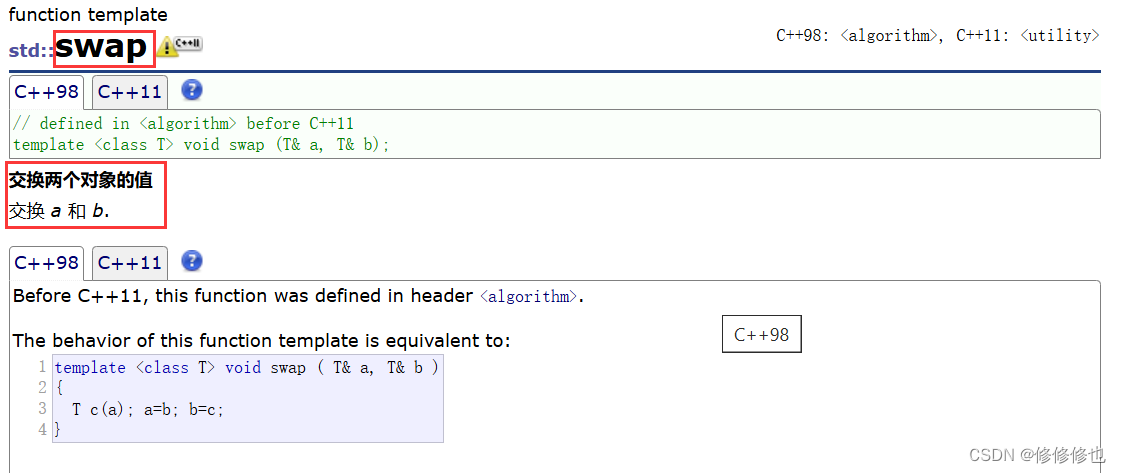
📌swap()函數
??????? swap()函數需要完成的是將兩個string類對象的內容做交換,而string類對象又包含三個內容:1._str 2._size 3._capacity ,所以我們分別交換這三個內容即可完成兩個string類的交換
,我們可以借助庫函數swap()函數來完成這一功能:
??????? 綜上,swap()代碼如下:
void swap(string& s) {std::swap(_str, s._str);std::swap(_size, s._size);std::swap(_capacity, s._capacity); }
🎏實現string類運算符重載
📌operator []運算符重載
??????? operator []運算符的作用是讓string類對象變得可以像數組一樣訪問,它接收一個size_t類型的值作為參數pos,并返回string類_str字符串中pos位置的字符.
無const修飾的類對象
??????? 對于非const修飾的類對象調用operator []運算符,我們返回的是可以讀也可以修改的pos位置的字符的引用.代碼如下:
char& operator[](size_t pos)//非const修飾類對象,可以讀寫 {assert(pos < _size);//在一開始判斷pos位置是否在_size范圍內,如果不是,則說明訪問越界return _str[pos]; }
有const修飾的類對象
??????? 對于const修飾的類對象調用operator []運算符,我們返回的是可以讀但不能修改的pos位置的字符的引用.代碼如下:
const char& operator[](size_t pos) const //const修飾類對象,只能讀 {assert(pos < _size);//在一開始判斷pos位置是否在_size范圍內,如果不是,則說明訪問越界return _str[pos]; }
📌operator +=運算符重載
??????? operator +=運算符的作用是在當前值的末尾附加其他字符來拓展字符或字符串.我們分別實現兩個operator +=重載函數,一個用于追加字符,一個用來追加字符串.需要注意的是,+=運算符的返回值是+=后的結果類對象,所以+=運算符重載函數的返回值是字符串引用類型,即string&.
????????由于我們之前已經實現過push_back()函數和append()函數了,所以這里只需要復用一下這兩個函數即可,綜上,代碼如下:
//+=一個字符 string& operator+=(char ch) {push_back(ch);return *this; }//+=一個字符串 string& operator+=(const char* str) {append(str);return *this; }
📌operator<<運算符重載
??????? 我們曾經在Data類中詳細分析過對自定義類如何重載流插入和流提取函數,如下:
??????? 對于string類的流插入函數,我們只需要將string類對象中的字符逐一插入到ostream(流插入)對象中即可,然后因為流插入運算符是有返回值的,因此我們將流插入對象作為返回值返回.
綜上,代碼如下:
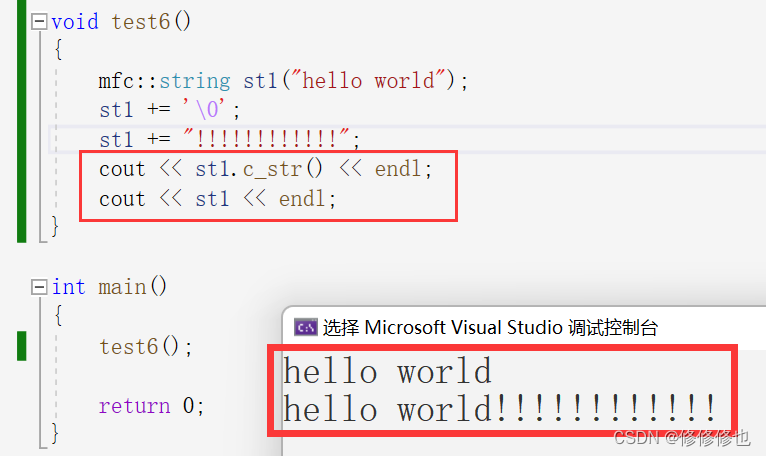
//注意,ostream必須使用&返回,因為采用傳值返回的話ostream會拷貝 //而ostream類型是禁止拷貝的 ostream& operator<<(ostream& out, const string& s) {for (auto ch : s){out << ch;}return out; }??????? 注意,使用c_str()函數和使用流插入函數打印主要區別如下:
- C的字符數組,以'\0'為終止算長度
- string不看'\0',以_size為終止算長度

📌operator>>運算符重載
??????? 流提取函數的作用是從終端輸入設備提取字符到類對象中,但在一開始我們就面臨一個問題,就是我們對輸入的數據是未知的,即不知道它的內容,也不知道它有多長,所以穩妥的方法就是我們一個字符一個字符從流中提取內容,然后按照我們正常的擴容邏輯,可能如果插入128個字符就要擴容7次,而擴容又每次都要拷貝轉移數據到新開辟的空間,這樣會導致非常多的浪費,所以我們先開一個128的字符數組,然后將讀取到的字符數據先累積到字符數組里,當字符數組滿了之后,再統一一次性開容量,然后加入到類對象的空間中去,這樣比較節省資源.
??????? 流提取這里相比于流插入邏輯復雜一些,有很多細節需要我們注意,見代碼注釋:
istream& operator>>(istream& in, string& s) {//因為我們要實現每次流提取的內容都對之前的內容是覆蓋過的,并且這里的string類對象參數s是引用//它不會隨著函數退出而銷毀,所以這里需要手動調用一下clear()函數s.clear();//正常in對象是讀不到空格/換行的,因為它在設計的時候自動的將空格符和換行符當成了字符輸入的分割符//所以在in對象讀的時候就會忽略空格/換行,導致我們的空格/換行符判定無效,要解決就使用get()函數//get()函數就是無論是什么內容它都認為是有效字符然后讀取出來char ch = in.get();//處理掉緩沖區前面的空格或者換行:一開始讀到換行或者空格不處理繼續往后讀就行while (ch == ' ' || ch == '\n'){ch = in.get();}//in>>ch;//上面這行代碼不適用,因為in對象認為接收到空格或者換行本個字符串的輸入就截止了,所以要用get()函數char buff[128];int i = 0;while (ch != ' ' && ch != '\n'){buff[i++] = ch;if (i == 127){buff[i] = '\0';s += buff;//in>>ch;//ch = in.get();i = 0;}ch = in.get();}if (i != 0){buff[i] = '\0';s += buff;}return in; }
📌operator <運算符重載
??????? 注意:后面的6個比較運算符重載函數都屬于類的只讀函數,對于只讀函數我們應該主動在函數后面加上const修飾this指針,以便const修飾的對象也可以正常調用該類型的函數!
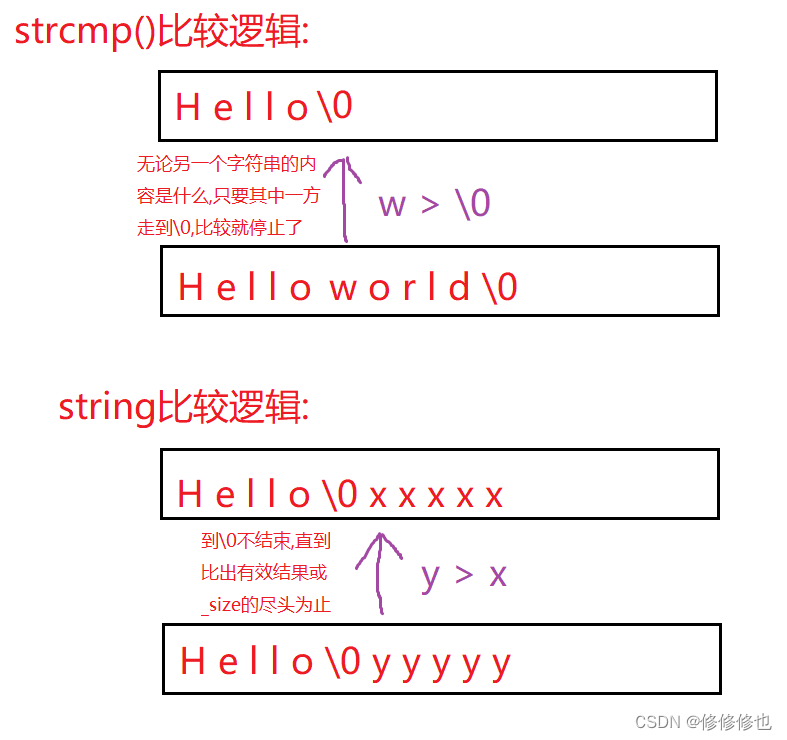
??????? string類的比較大小和C語言字符串一樣,是通過ascii碼來比較的.但是我們不能使用C語言庫中的strcmp()直接來比較string類的大小,因為strcmp()的比較邏輯是按照'\0'為終止字符的,
但string類并不是以'\0'為終止,而是以_size的大小為終止的.兩種比較邏輯如下圖所示:
??????? 綜上所述,代碼如下:
bool operator<(const string& s)const {//return strcmp(_str, s._str) < 0;//會有中間含'\0'的字符串比較的問題,所以用memcmp//memcmp比較的長度應該是短的字符串長度+1// 不能用size+1,因為'\0'不一定算小字符,有些漢字的u16/u18編碼可能會是負數//return memcmp(_str,s._str,_size < s._size ? _size : s._size);//先比較短的字符串長度范圍內的值size_t i1 = 0;size_t i2 = 0;while (i1 < _size && i2 < s._size){if (_str[i1] < s._str[i2]){return true;}else if (_str[i1] > s._str[i2]){return false;}else{i1++;i2++;}}//當走到這個位置時,說明至少其中一個結束了,并且另一個在前面部分一直和它是相等的//那么如果此時i1走到盡頭,但i2沒走到盡頭,就說明i1是小于i2的,因此返回ture//否則i1>=i2,返回false//注意,在這里也不能比較size+1,因為'\0'不一定算小字符//雖然在ascii編碼中它是0,但有些漢字的u16/u18編碼可能會是負數return (i1 == _size && i2 != s._size);}??????? 還有一種復用庫函數memcpy()函數版本的實現方式:
bool operator<(const string& s)const {//先比較短的字符串長度范圍內的值bool ret = memcmp(_str,s._str,_size < s._size ? _size : s._size);//ret==0說明前面部分兩個字符串都相等,這時候比長度就行//否則說明兩個字符串前面都不相等,返回前面的比較結果ret是否<0就行return ret == 0 ? _size < s._size : ret < 0;}
📌operator ==運算符重載
??????? operator ==運算符重載的作用是判斷兩個string類對象是否相等,我們可以先判斷兩個string類的長度是否相等,再復用memcpy()函數判斷其中的字符串是否相等.
????????代碼如下:
bool operator==(const string& s)const {return _size==s._size && memcmp(_str, s._str, _size) == 0; }
📌operator <=運算符重載
??????? 因為我們前面已經實現<和==運算符了,下面我們只需要復用前面實現過的邏輯就可以完成<=運算符重載了,代碼如下:
bool operator<=(const string& s)const {return (*this < s || *this == s); }
📌operator >運算符重載
????????因為我們前面已經實現<=運算符了,下面我們只需要復用前面實現過的邏輯就可以完成>運算符重載了,代碼如下:
bool operator>(const string& s)const {return !(*this <= s); }
📌operator >=運算符重載
???????? 因為我們前面已經實現<運算符了,下面我們只需要復用前面實現過的邏輯就可以完成>=運算符重載了,代碼如下:
bool operator>=(const string& s)const {return !(*this < s); }
📌operator !=運算符重載
???????? 因為我們前面已經實現==運算符了,下面我們只需要復用前面實現過的邏輯就可以完成!=運算符重載了,代碼如下:
bool operator!=(const string& s)const {return !(*this == s); }
🎏實現string類迭代器
??????? C++中,我們也可以使用迭代器來訪問string對象的字符,在string中,迭代器的底層是使用指針來實現的,如下,我們使用typedef重命名char*類型為iterator:
typedef char* iterator;????????當然,我們也需要考慮到為const修飾類對象實現迭代器,如下,我們使用typedef重命名const char*類型為const_iterator:
typedef const char* const_iterator;
定義好迭代器類型后,接下來,就可以實現迭代器相關的函數了:
📌begin()函數
????????begin()函數的作用是返回指向_str字符串第一個字符的迭代器,如下圖所示,即_str的首地址:
????????代碼如下:
iterator begin() {return _str; }????????對于const修飾對象而言,begin()函數返回的迭代器也要是const類型的,同時,形參this指針也要加上const修飾才能夠和const修飾的類對象參數匹配,綜上,代碼如下:
const_iterator begin()const {return _str; }

📌end()函數
????????end()函數的作用是返回指向_str字符串最后一個有效字符(即不包括'\0')后一個理論字符位置的迭代器,如下圖所示,即_str+_size位置的地址:
????????代碼如下:
iterator end() {return _str + _size ; }????????對于const修飾對象而言,end()函數返回的迭代器也要是const類型的,同時,形參this指針也要加上const修飾才能夠和const修飾的類對象參數匹配,綜上,代碼如下:
const_iterator end()const {return _str + _size; }

📌迭代器測試
??????? 我們創建一個string變量st1,然后創建一個迭代器變量it,給它賦值為st1.begin(),接著設置while循環,判斷it是否!=st1.end(),如果不相等,則it繼續向后遍歷,直到2者相等,代碼如下:
void test1() {mfc::string st1("hello world");mfc::string::iterator it = st1.begin();while (it != st1.end()){cout << *it << " ";it++;}cout << endl; }int main() {test1();return 0; }????????代碼測試結果如下,我們成功使用迭代器遍歷了string類對象:
????????接下來我們再測試以下使用迭代器修改string類對象的內容:
void test2() {mfc::string st1("hello world");mfc::string::iterator it = st1.begin();while (it != st1.end()){(*it)++;cout << *it << " ";it++;}cout << endl; }int main() {test2();return 0; }????????代碼測試結果如下,我們成功使用迭代器遍歷并修改了string類對象:
????????最后我們測試一下const修飾的string類對象的迭代器遍歷,代碼如下:
void test3() {mfc::string const st1("hello world");mfc::string::const_iterator it = st1.begin();while (it != st1.end()){cout << *it << " ";it++;}cout << endl; }int main() {test3();return 0; }????????測試結果如下,我們成功使用const迭代器遍歷了const修飾的類對象:


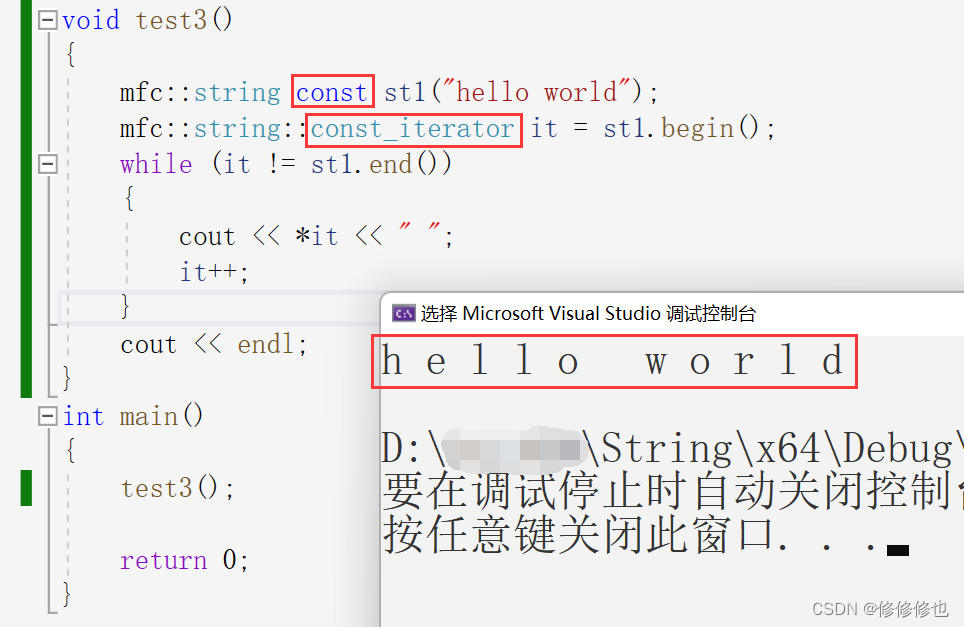
📌迭代器的衍生品——范圍for
??????? c++中范圍for的定義如下:
??????? 因為范圍for的底層實現原理是依靠迭代器來實現的,所以當我們實現的類支持迭代器時,就自動支持了范圍for,我們可以直接使用范圍for來遍歷類對象成員,如:
void test4() {mfc::string st1("hello world");for(auto ch : st1){cout << ch << " ";}cout << endl; }int main() {test4();return 0; }????????范圍for測試結果如下:

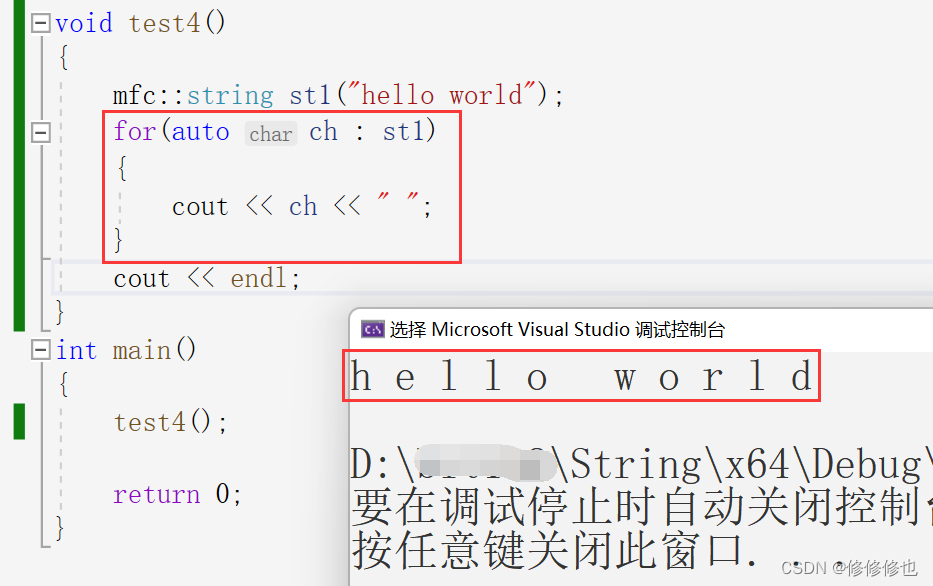
三.項目完整代碼
我們將程序運行的代碼分別在兩個工程文件中編輯,完整代碼如下:
test.cpp文件
注:該文件主要是用來測試我們已完成的代碼是否能夠合理的完成我們的想要的功能,主要是看個人需求,因此不同的人的測試代碼可能不相同,以下代碼僅供參考.
#include"string.h"void test1()
{mfc::string st1("hello world");mfc::string::iterator it = st1.begin();while (it != st1.end()){cout << *it << " ";it++;}cout << endl;
}void test2()
{mfc::string st1("hello world");mfc::string::iterator it = st1.begin();while (it != st1.end()){(*it)++;cout << *it << " ";it++;}cout << endl;
}void test3()
{mfc::string const st1("hello world");mfc::string::const_iterator it = st1.begin();while (it != st1.end()){cout << *it << " ";it++;}cout << endl;
}void test4()
{mfc::string st1("hello world");for(auto ch : st1){cout << ch << " ";}cout << endl;
}
void test5()
{int a = -1;size_t b = 0;if (a > b){cout << "a>b:"<<a<<">"<<b << endl;}else{cout << "a<b:" << a << "<" << b << endl;}
}void test6()
{mfc::string st1("hello world");st1 += '\0';st1 += "!!!";cout << st1.c_str() << endl;cout << st1 << endl;
}void test7()
{mfc::string st1("hello");mfc::string st2("yyyyyyyyxxxxxxx");cout << st1 << endl;cout << st2 << endl << endl;st1 = st2;cout << st1 << endl;cout << st2 << endl;
}int main()
{test7();return 0;
}string.h文件
注:該文件中包含了string類的完整模擬實現代碼,如需使用,請留意命名空間的限制.
#define _CRT_SECURE_NO_WARNINGS 1#pragma once
#include<iostream>
#include<string>
#include<assert.h>
using namespace std;namespace mfc
{class string{public://迭代器typedef char* iterator;typedef const char* const_iterator;iterator begin(){return _str;}iterator end(){return _str + _size ;}const_iterator begin()const{return _str;}const_iterator end()const{return _str + _size;}//構造string(const char* str = ""):_size(strlen(str)),_capacity(_size){//只是給_str開了空間_str = new char[_capacity + 1];//多開一個空間放'\0'//這步才是給_str放入數據memcpy(_str, str,_size+1);}//拷貝構造string(const string& s){_str = new char[s._capacity + 1];memcpy(_str, s._str, s._size + 1);_size = s._size;_capacity = s._capacity;}//拷貝構造(這個遇到中間有'\0'的時候會有bug,后面的不會拷貝)/*string(const string& s):_str(nullptr),_size(0),_capacity(0){string tmp(s._str);swap(tmp);}*/傳統寫法//string& operator=(const string& s)//{// if (this != &s)// {// char* tmp = new char[s._capacity + 1];// memcpy(tmp, s._str, s._size + 1);// delete[] _str;// _str = tmp;// _size = s._size;// _capacity = s._capacity;// }// return *this;//}void swap(string& s){std::swap(_str, s._str);std::swap(_size, s._size);std::swap(_capacity, s._capacity);}//現代//string& operator=(const string& s)//{// if (this != &s)// {// string tmp(s);// //this->swap(tmp);// swap(tmp);// }// return *this;//}//未來string& operator=(string tmp){swap(tmp);return *this;}~string(){//不是空再釋放if (_str!=nullptr){delete[] _str;_str = nullptr;_size = 0;_capacity = 0;}}const char* c_str() const//使const對象也可以調用{return _str;}size_t size() const//使const對象也可以調用{return _size;}char& operator[](size_t pos)//讀寫{assert(pos < _size);return _str[pos];}const char& operator[](size_t pos) const//只讀{assert(pos < _size);return _str[pos];}//增刪查改void reserve(size_t n){if (n > _capacity){char* tmp = new char[n + 1];memcpy(tmp, _str, _size + 1);//這里使用strcpy拷貝的話就可能出現對于有\0的字符串的拷貝錯誤現象delete[] _str;//一定要記得釋放_str!!!!!!!_str = tmp;_capacity = n ;}}void resize(size_t n, char ch = '\0'){if (n < _size){_size = n;_str[_size] = '\0';}else{reserve(n);for (size_t i = _size; i < n; i++){_str[i] = ch;}_size = n;_str[_size] = '\0';}}void push_back(char ch){//查滿擴容if (_size == _capacity){//2倍擴容reserve(_capacity == 0 ? 4 : _capacity * 2);}//尾插一個字符_str[_size] = ch;++_size;_str[_size] = '\0';}void append(const char* str){size_t len = strlen(str);if (_size + len > _capacity){//擴容,且至少到_size+len,不能是二倍擴容!reserve(_size + len );//不+1,在reserve內部考慮}memcpy(_str + _size, str, len + 1);_size += len;}string& operator+=(char ch){push_back(ch);return *this;}string& operator+=(const char* str){append(str);return *this;}//pos位置插入n個charvoid insert(size_t pos, size_t n, char ch){//判斷pos是否合理assert(pos <= _size);//判斷容量if (_size + n > _capacity){reserve(_size + n);}//挪動后面的數據size_t end = _size;//end和pos比較時會進行整型提升!while (end >= pos && end != npos){_str[end + n] = _str[end];end--;}//插入數據for (size_t i = 0; i < n; i++){_str[pos + i] = ch;}_size += n;}//pos位置插入一個字符串void insert(size_t pos,const char* str){//判斷pos是否合理assert(pos <= _size);//判斷容量size_t len = strlen(str);if (_size + len > _capacity){reserve(_size + len);}//挪動后面的數據size_t end = _size;//end和pos比較時會進行整型提升!while (end >= pos && end != npos){_str[end + len] = _str[end];end--;}//插入數據for (int i = 0; i < len; i++){_str[pos + i] = str[i];}_size += len;}void erase(size_t pos, size_t len = npos){assert(pos <= _size);//判斷len是不是為缺省參數 或者 pos+len已經超出了_size的范圍,如果是,那么就代表要刪完if (len == npos || pos + len >= _size){//要刪完,直接在這個位置放一個\0就行_str[pos] = '\0';_size = pos;_str[_size] = '\0';}else{size_t end = pos + len;while (end <= _size){_str[pos++] = _str[end++];}_size -= len;}}//查找某一字符的位置//check some character's positionsize_t find(char ch, size_t pos = 0){assert(pos < _size);for (size_t i = pos; i < _size; i++){if (_str[i] == ch){return i;}}//沒找著,返回npos//if character is not in this string,return nposreturn npos;}//查找子串//check some substring's positionsize_t find(const char* str, size_t pos = 0){assert(pos < _size);//相關算法:BM算法和KMP算法const char* ptr = strstr(_str + pos, str);if (ptr){//if substring is in this string,return this substring's posisionreturn ptr - _str;}else{//沒找著,返回npos//if substring is not in this string,return nposreturn npos;}}//獲取一個子串string substr(size_t pos = 0, size_t len = npos){assert(pos < _size);size_t n = len;if (len == npos || pos + len > _size)//如果len的長度是npos(非常大)或者pos+len的長度已經超出了_size的大小//這兩種情況都意味著要獲取的字串是從pos開始直到字符串結尾{n = _size - pos;}string tmp;tmp.reserve(n);//i不是從0開始的,但是n長度是絕對長度的,所以判斷條件要注意for (size_t i = pos; i < pos + n; i++){tmp += _str[i];}return tmp;}void clear(){_str[0] = '\0';_size = 0;}bool operator<(const string& s)const{//return strcmp(_str, s._str) < 0;//會有中間含'\0'的字符串比較的問題,所以用memcmp//memcmp比較的長度應該是短的字符串長度+1// 不能用size+1,因為'\0'不一定算小字符,有些漢字的u16/u18編碼可能會是負數//return memcmp(_str,s._str,_size < s._size ? _size : s._size);//先比較短的字符串長度范圍內的值size_t i1 = 0;size_t i2 = 0;while (i1 < _size && i2 < s._size){if (_str[i1] < s._str[i2]){return true;}else if (_str[i1] > s._str[i2]){return false;}else{i1++;i2++;}}//當走到這個位置時,說明至少其中一個結束了,并且另一個在前面部分一直和它是相等的//那么如果此時i1走到盡頭,但i2沒走到盡頭,就說明i1是小于i2的,因此返回ture//否則i1>=i2,返回false//注意,在這里也不能比較size+1,因為'\0'不一定算小字符//雖然在ascii編碼中它是0,但有些漢字的u16/u18編碼可能會是負數return (i1 == _size && i2 != s._size);}//bool operator<(const string& s)const//{// //先比較短的字符串長度范圍內的值// bool ret = memcmp(_str,s._str,_size < s._size ? _size : s._size);// //ret==0說明前面部分兩個字符串都相等,這時候比長度就行// //否則說明兩個字符串前面都不相等,返回前面的比較結果ret是否<0就行// return ret == 0 ? _size < s._size : ret < 0;//}//后面復用小于得到其他六個bool operator==(const string& s)const{return _size==s._size && memcmp(_str, s._str, _size) == 0;}bool operator<=(const string& s)const{return (*this < s || *this == s);}bool operator>(const string& s)const{return !(*this <= s);}bool operator>=(const string& s)const{return !(*this < s); }bool operator!=(const string& s)const{return !(*this == s);}private:char* _str;size_t _size;size_t _capacity;static size_t npos;};size_t string::npos = -1;ostream& operator<<(ostream& out, const string& s){for (auto ch : s){out << ch;}return out;}istream& operator>>(istream& in, string& s){s.clear();char ch = in.get();//處理掉緩沖區前面的空格或者換行:一開始讀到換行或者空格不處理繼續往后讀就行while (ch == ' ' || ch == '\n'){ch = in.get();}//in>>ch;//因為in對象認為接收到空格或者換行本個字符串的輸入就截止了char buff[128];int i = 0;while (ch != ' ' && ch != '\n'){buff[i++] = ch;if (i == 127){buff[i] = '\0';s += buff;//in>>ch;//ch = in.get();i = 0;}ch = in.get();}if (i != 0){buff[i] = '\0';s += buff;}return in;}
};結語
希望這篇string類的模擬實現詳解能對大家有所幫助,歡迎大佬們留言或私信與我交流.
學海漫浩浩,我亦苦作舟!關注我,大家一起學習,一起進步!
相關文章推薦
【C++】詳解深淺拷貝的概念及其區別
【C++】動態內存管理
【C++】標準庫類型string
【C++】構建第一個C++類:Date類
【C++】類的六大默認成員函數及其特性(萬字詳解)
【C++】內聯函數
【C++】函數重載
【C++】什么是類與對象?
【C++】缺省參數(默認參數)
【C++】內聯函數
 ?
?




)


:貪心算法——最大子數組和)






)


)
系統架構之系統能力的內存隔離和保護)
