B+樹和B*樹
- 一、B+樹的簡單介紹
- 二、B+樹的插入過程
- 三、B*樹的簡單介紹
- 四、B樹、B+樹、B*樹總結
- 五、B樹的應用
- 1、MyISAM索引實現
- 2、InnoDB索引實現
一、B+樹的簡單介紹
B+樹是B樹的變形,是在B樹基礎上優化的多路平衡搜索樹,B+樹的規則跟B樹基本類似,但是又在B樹的基礎上做了以下幾點改進優化:
分支節點的子樹指針與關鍵字個數相同
分支節點的子樹指針p[i]指向關鍵字值大小在[k[i],k[i+1])區間之間
所有葉子節點增加一個鏈接指針鏈接在一起
所有關鍵字及其映射數據都在葉子節點出現
B+樹的特性:
- 所有關鍵字都出現在葉子節點的鏈表中,且鏈表中的節點都是有序的。
- 不可能在分支節點中命中。
- 分支節點相當于是葉子節點的索引,葉子節點才是存儲數據的數據層。
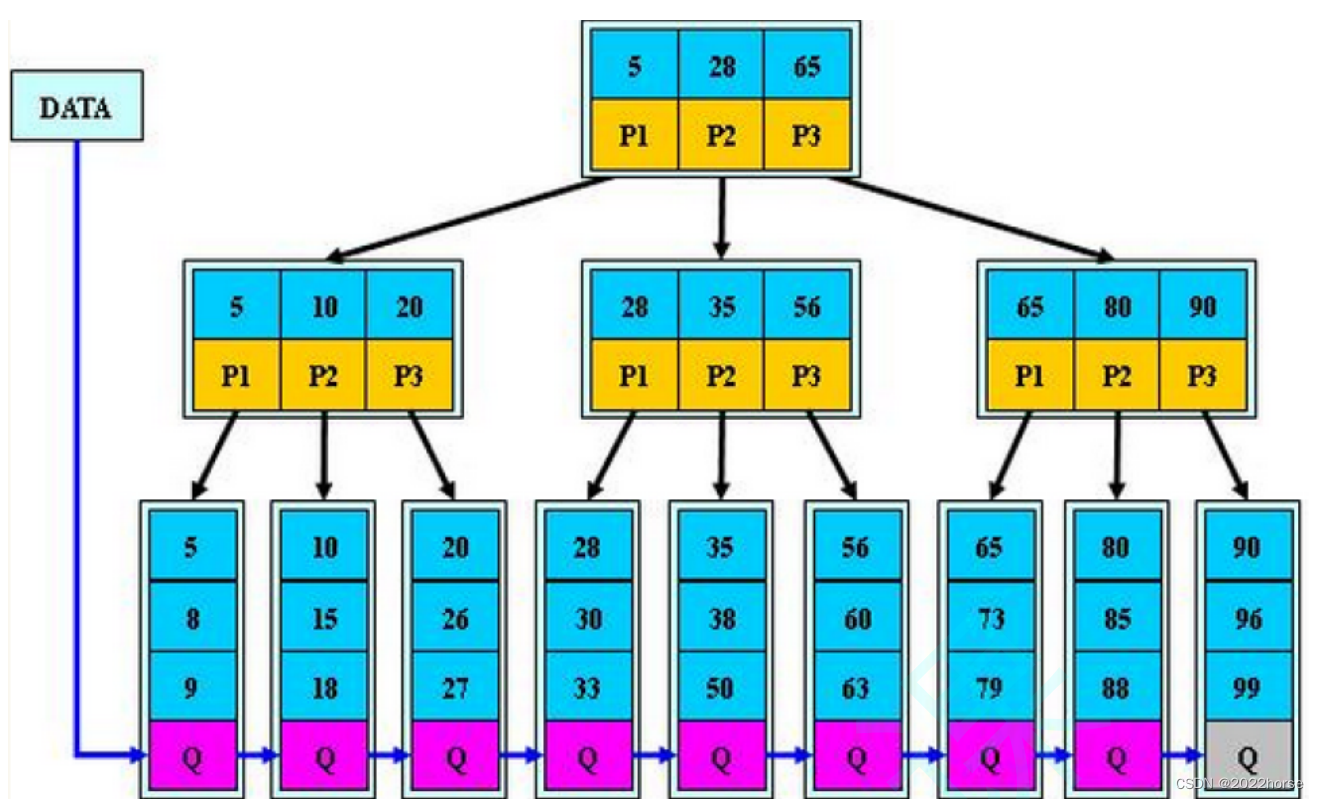
二、B+樹的插入過程

三、B*樹的簡單介紹
B*樹是B+樹的變形,在B+樹的非根和非葉子節點再增加指向兄弟節點的指針。
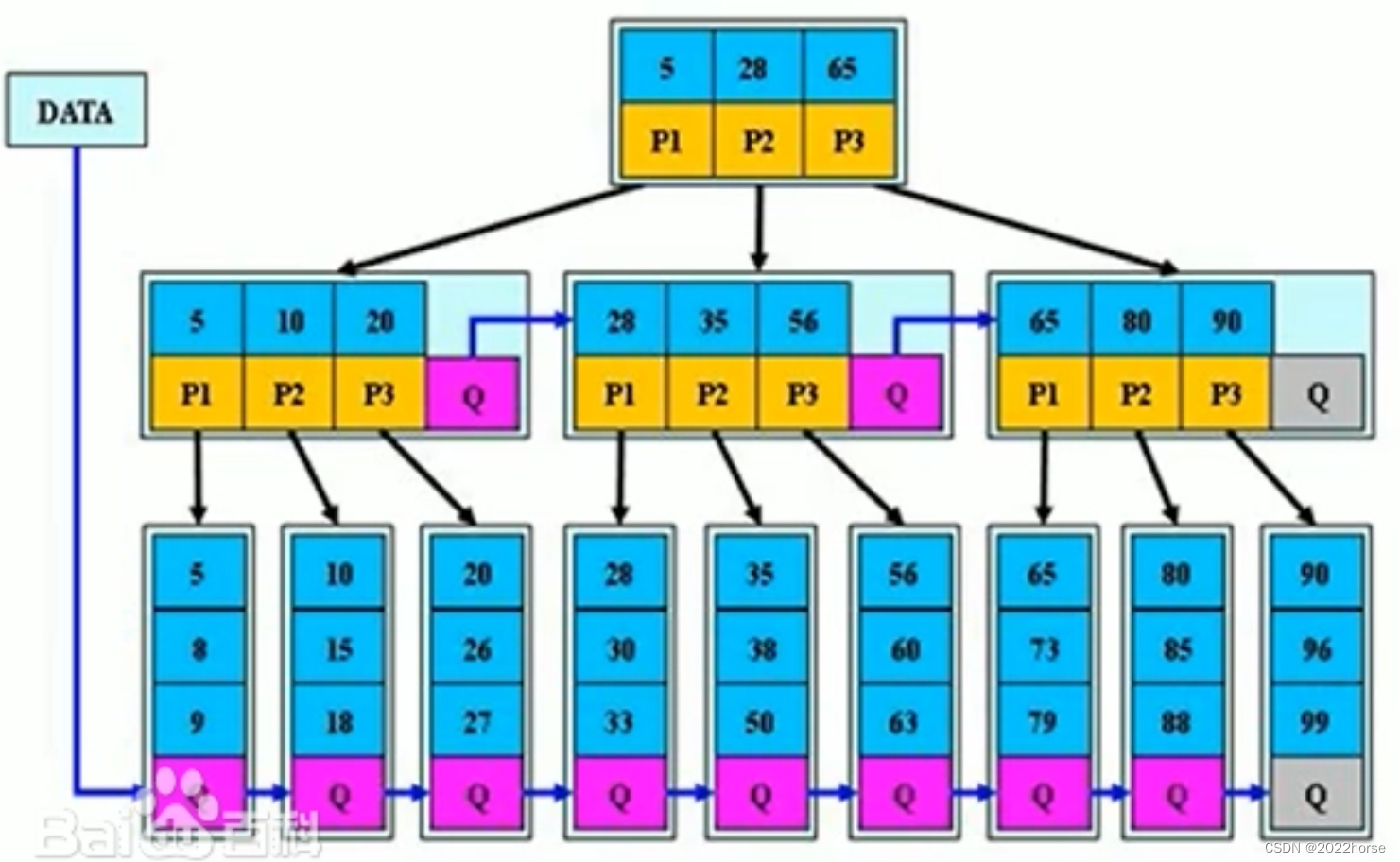
B*樹的分裂:
當一個結點滿時,如果它的下一個兄弟結點未滿,那么將一部分數據移到兄弟結點中,再在原結點插入關鍵字,最后修改父結點中兄弟結點的關鍵字(因為兄弟結點的關鍵字范圍改變了);如果兄弟也滿了,則在原結點與兄弟結點之間增加新結點,并各復制1/3的數據到新結點,最后在父結點增加新結點的指針。
四、B樹、B+樹、B*樹總結
B樹:有序數組+平衡多叉樹;
B+樹:有序數組鏈表+平衡多叉樹;
B*樹:一棵更豐滿的,空間利用率更高的B+樹。
五、B樹的應用
1、MyISAM索引實現
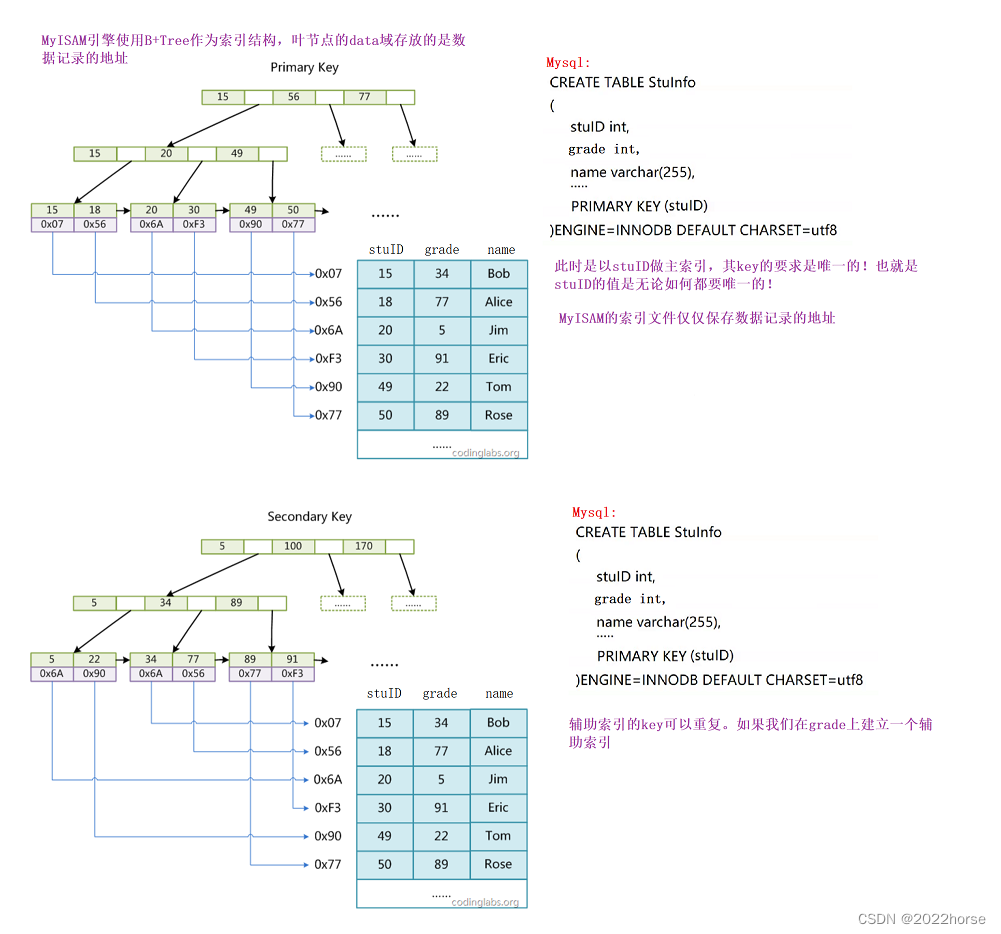
思考一個問題,我們按照stuID查找快還是name查找更快?
答案肯定是stuID更快,因為這個是主索引,直接使用B+樹本身的搜索能夠搜索到了,而用name查找的話要暴力遍歷B+樹的所有葉子結點去找地址后到表中查找。
如果找不到主建的話,就用一個自增的整數做主建(自增主建)~~
2、InnoDB索引實現
第一個重大區別是InnoDB的數據文件本身就是索引文件。從上文知道,MyISAM索引文件和數據文件是分離的,索引文件僅保存數據記錄的地址。而在InnoDB中,表數據文件本身就是按B+Tree組織的一個索引結構,這棵樹的葉節點data域保存了完整的數據記錄。這個索引的key是數據表的主鍵,因此InnoDB表數據文件本身就是主索引。這種索引叫做聚集索引。因為InnoDB的數據文件本身要按主鍵聚集,所以InnoDB要求表必須有主鍵(MyISAM可以沒有),如果沒有顯式指定,則MySQL系統會自動選擇一個可以唯一標識數據記錄的列作為主鍵,如果不存在這種列,則MySQL自動為InnoDB表生成一個隱含字段作為主鍵,這個字段長度為6個字節,類型為長整形。
第二個與MyISAM索引的不同是InnoDB的輔助索引data域存儲相應記錄主鍵的值而不是地址。換句話說,InnoDB的所有輔助索引都引用主鍵作為data域。
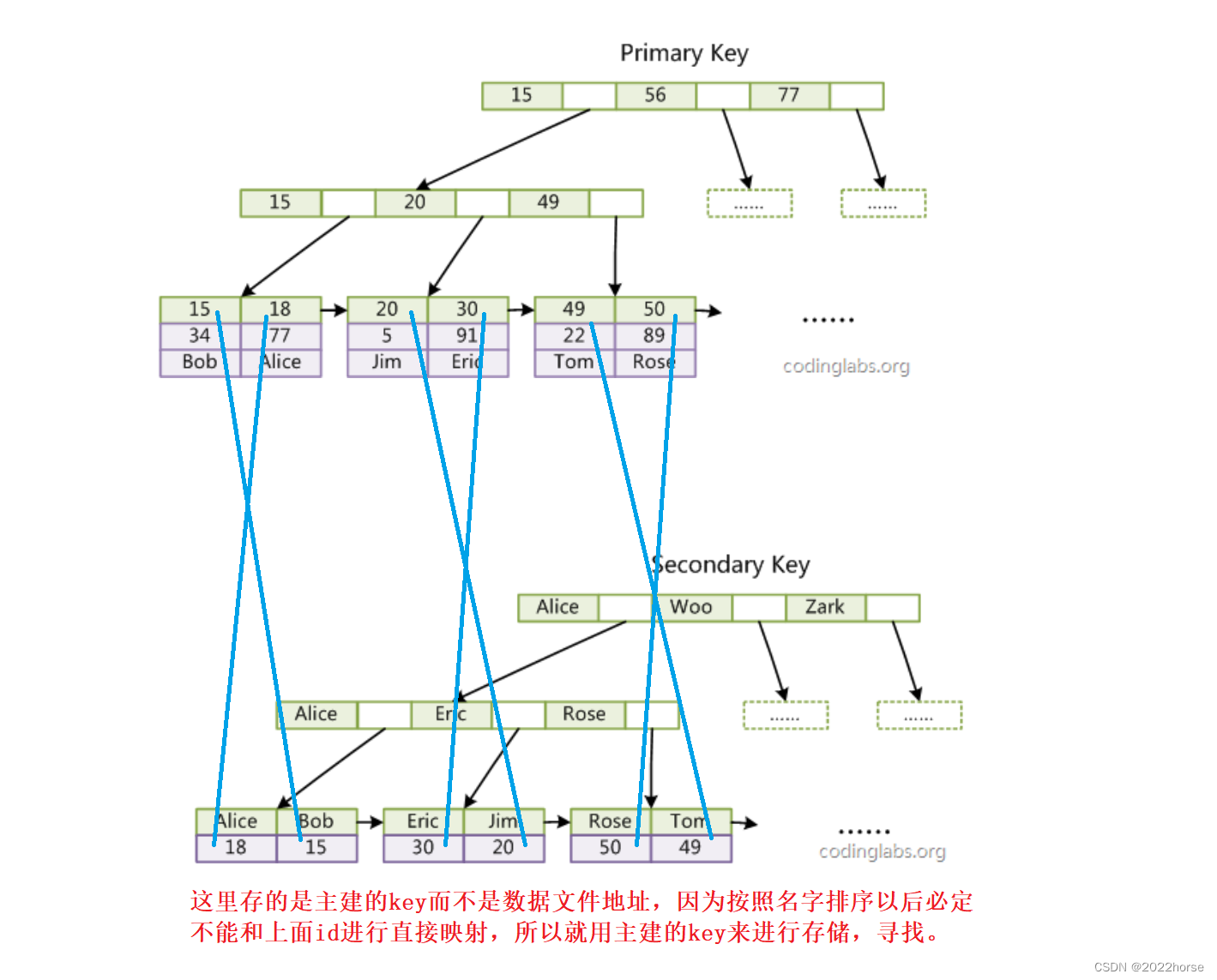
這里以英文字符的ASCII碼作為比較準則。聚集索引這種實現方式使得按主鍵的搜索十分高效,但是輔助索引搜索需要檢索兩遍索引:首先檢索輔助索引獲得主鍵,然后用主鍵到主索引中檢索獲得記錄。



 —— 字符流)



![[9] CUDA性能測量與錯誤處理](http://pic.xiahunao.cn/[9] CUDA性能測量與錯誤處理)




ref)
)


)


