目錄
一、污點(Taint)
1、污點(Taint)
2、污點組成格式
3、當前taint effect支持如下三個選項:
4、查看node節點上的污點
5、設置污點
6、清除污點
7、示例一
查看pod狀態,模擬驅逐node02上的pod
設置驅逐node02
再次查看pod狀態
此時node02全部被驅逐
二、容忍(Tolerations)
1、容忍的簡介
2、面對污點,創建pod資源的容忍的實例
在兩個 Node 上都設置了污點后,此時 Pod 將無法創建成功
然后在修改pod3.yaml文件創建pod資源的容忍設置
此時pod創建成功
3、其他注意事項
①當不指定 key 值時,表示容忍所有的污點 key
②當不指定 effect 值時,表示容忍所有的污點作用
③有多個 Master 存在時,防止資源浪費,可以如下設置
4、維護操作cordon和drain
5、pod啟動階段(相位phase)
5.1.一般來說,pod 這個過程包含以下幾個步驟:
5.2.phase的可能狀態有
6、如何和刪除UNknown狀態的pod
三、k8s集群的故障排查步驟
1、查看pod事件
2、查看pod日志(Failed狀態下)
3、進入pod(狀態為running,但是服務沒有提供)
4、查看集群信息
5、發現集群狀態正常
6、查看kubelet日志發現
一、污點(Taint)
1、污點(Taint)
①節點親和性,是Pod的一種屬性(偏好或硬性要求),它是Pod被吸引到一類特定的節點。Taint則相反,它使得節點能夠排斥一類特定的pod。
②Taint與Toleration相互配合,可以用來避免pod被分配到不合適的節點上。每個節點上的都可以應用一個或者多個Taint,這表示對于那些不能容忍這些 taint 的 Pod,是不會被該節點接受的。如果將 toleration 應用于 Pod 上,則表示這些 Pod 可以(但不一定)被調度到具有匹配 taint 的節點上。
③使用 kubectl taint 命令可以給某個 Node 節點設置污點,Node 被設置上污點之后就和 Pod 之間存在了一種相斥的關系,可以讓 Node 拒絕 Pod 的調度執行,甚至將 Node 已經存在的 Pod 驅逐出去。
2、污點組成格式
key=value:effect## 每個污點有一個 key 和 value 作為污點的標簽,其中 value 可以為空,effect 描述污點的作用。3、當前taint effect支持如下三個選項:
①NoSchedule:表示 k8s 將不會將 Pod 調度到具有該污點的 Node 上
②PreferNoSchedule:表示 k8s 將盡量避免將 Pod 調度到具有該污點的 Node 上
③NoExecute:表示 k8s 將不會將 Pod 調度到具有該污點的 Node 上,同時會將 Node 上已經存在的 Pod 驅逐出去
4、查看node節點上的污點
格式:kubectl describe nodes <節點名稱> | grep Taints
或者是kubectl describe nodes <節點名稱> | grep -i taints
eg:查看master01的污點
kubectl describe nodes master01 |grep -i taints
5、設置污點
格式kubectl taint node 指定的node key1=value1:NoSchedule
eg:給node01 設置污點進行測試
kubectl taint node node01 abc=a:NoSchedule
6、清除污點
格式:kubectl taint node 指定的node key:NoSchedule-
eg:清除node01 設置的污點
kubectl taint node node01 abc:NoSchedule-
7、示例一
查看pod狀態,模擬驅逐node02上的pod
[root@master01 ~]]#kubectl get pods -owide
查看pod狀態
設置驅逐node02
kubectl taint node node02 check=mycheck:NoExecute
再次查看pod狀態
kubectl get pods -owide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
affinity 1/1 Running 0 20h 10.244.2.24 node01 <none> <none>
myapp-699655c7fd-rnfzg 1/1 Running 0 20h 10.244.2.23 node01 <none> <none>
myapp-699655c7fd-v2dtt 1/1 Running 0 20h 10.244.2.22 node01 <none> <none>
myapp-699655c7fd-vxbz9 1/1 Running 0 20h 10.244.2.21 node01 <none> <none>
myapp1-58794f76cb-6twr4 1/1 Running 0 20h 10.244.2.27 node01 <none> <none>
myapp1-58794f76cb-75gzs 1/1 Running 0 20h 10.244.2.25 node01 <none> <none>
myapp1-58794f76cb-v5gcz 1/1 Running 0 20h 10.244.2.26 node01 <none> <none>
myapp10 1/1 Running 0 19h 10.244.2.28 node01 <none> <none>
myapp20 1/1 Running 0 19h 10.244.2.29 node01 <none> <none>
nginx-deployment-797d747cf6-nldj2 1/1 Running 0 29s 10.244.2.31 node01 <none> <none>
nginx-deployment-797d747cf6-sqcm9 1/1 Running 0 29s 10.244.2.32 node01 <none> <none>
nginx-deployment-797d747cf6-t4tsk 1/1 Running 0 29s 10.244.2.30 node01 <none> <none>
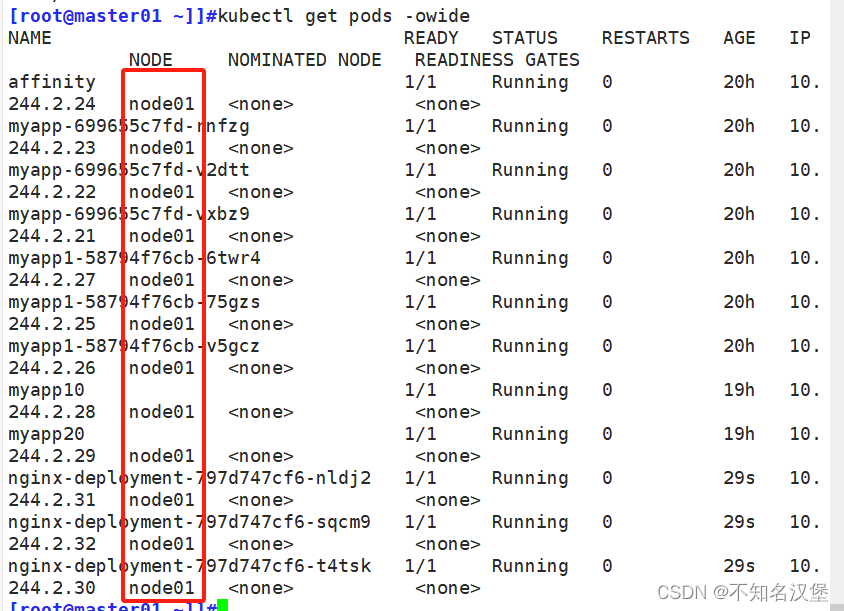
此時node02全部被驅逐
二、容忍(Tolerations)
1、容忍的簡介
設置了污點的 Node 將根據 taint 的 effect:NoSchedule、PreferNoSchedule、NoExecute 和 Pod 之間產生互斥的關系,Pod 將在一定程度上不會被調度到 Node 上。但我們可以在 Pod 上設置容忍(Tolerations),意思是設置了容忍的 Pod 將可以容忍污點的存在,可以被調度到存在污點的 Node 上。
2、面對污點,創建pod資源的容忍的實例
kubectl taint node node01 check=mycheck:NoExecute
vim pod3.yaml
apiVersion: v1
kind: Pod
metadata:name: myapp01labels:app: myapp01
spec:containers:- name: with-node-affinityimage: nginx:1.14tolerations:- key: "abc"operator: "Equal"value: "a"effect: "NoExecute"tolerationSeconds: 3600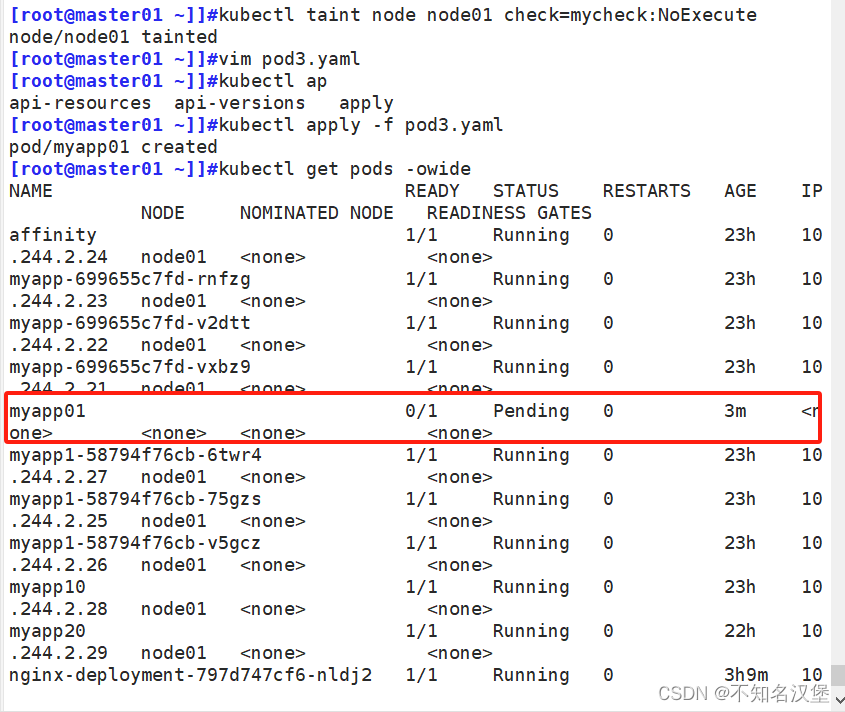
在兩個 Node 上都設置了污點后,此時 Pod 將無法創建成功
然后在修改pod3.yaml文件創建pod資源的容忍設置
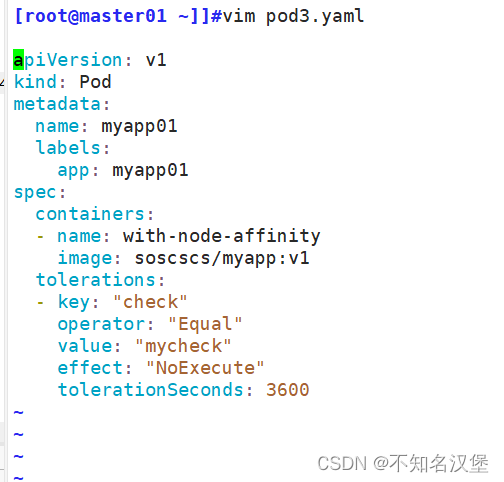
vim pod3.yaml
apiVersion: v1
kind: Pod
metadata:name: myapp01labels:app: myapp01
spec:containers:- name: with-node-affinityimage: soscscs/myapp:v1tolerations:- key: "check"operator: "Equal"value: "mycheck"effect: "NoExecute"tolerationSeconds: 3600
[root@master01 ~]]#kubectl delete -f pod3.yaml
pod "myapp01" deleted
[root@master01 ~]]#kubectl apply -f pod3.yaml
pod/myapp01 created
[root@master01 ~]]#kubectl get pods -owide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
affinity 1/1 Running 0 23h 10.244.2.24 node01 <none> <none>
myapp-699655c7fd-rnfzg 1/1 Running 0 23h 10.244.2.23 node01 <none> <none>
myapp-699655c7fd-v2dtt 1/1 Running 0 23h 10.244.2.22 node01 <none> <none>
myapp-699655c7fd-vxbz9 1/1 Running 0 23h 10.244.2.21 node01 <none> <none>
myapp01 1/1 Running 0 87s 10.244.1.18 node02 <none> <none>
myapp1-58794f76cb-6twr4 1/1 Running 0 23h 10.244.2.27 node01 <none> <none>
myapp1-58794f76cb-75gzs 1/1 Running 0 23h 10.244.2.25 node01 <none> <none>
myapp1-58794f76cb-v5gcz 1/1 Running 0 23h 10.244.2.26 node01 <none> <none>
myapp10 1/1 Running 0 23h 10.244.2.28 node01 <none> <none>
myapp20 1/1 Running 0 23h 10.244.2.29 node01 <none> <none>
nginx-deployment-797d747cf6-nldj2 1/1 Running 0 3h20m 10.244.2.31 node01 <none> <none>
nginx-deployment-797d747cf6-sqcm9 1/1 Running 0 3h20m 10.244.2.32 node01 <none> <none>
nginx-deployment-797d747cf6-t4tsk 1/1 Running 0 3h20m 10.244.2.30 node01 <none> <none>
#其中的 key、vaule、effect 都要與 Node 上設置的 taint 保持一致
#operator 的值為 Exists 將會忽略 value 值,即存在即可
#tolerationSeconds 用于描述當 Pod 需要被驅逐時可以在 Node 上繼續保留運行的時間

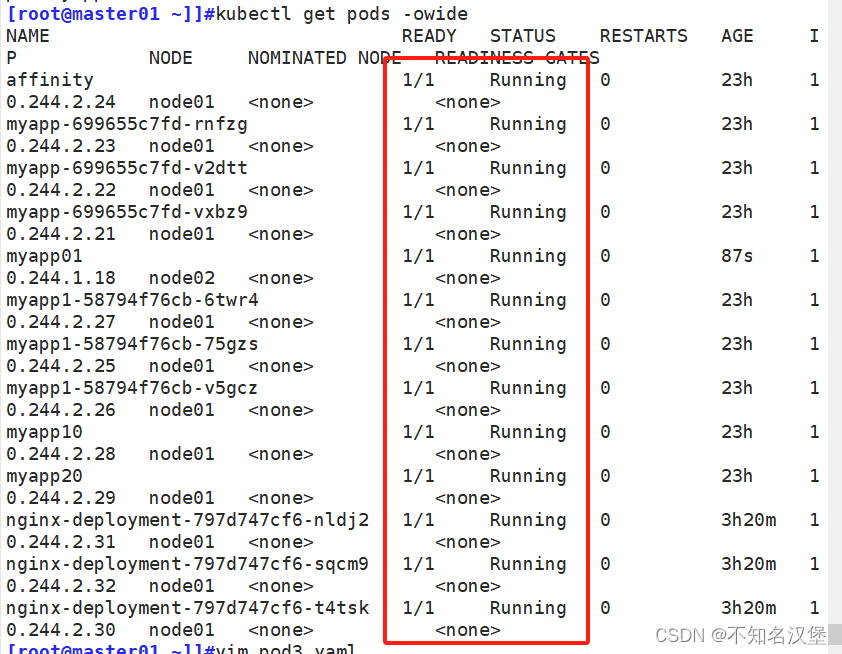
此時pod創建成功
3、其他注意事項
①當不指定 key 值時,表示容忍所有的污點 key
tolerations:
? - operator: "Exists"
②當不指定 effect 值時,表示容忍所有的污點作用
tolerations:
? - key: "key"
? ? operator: "Exists"
③有多個 Master 存在時,防止資源浪費,可以如下設置
kubectl taint node Master-Name node-role.kubernetes.io/master=:PreferNoSchedule
//如果某個 Node 更新升級系統組件,為了防止業務長時間中斷,可以先在該 Node 設置 NoExecute 污點,把該 Node 上的 Pod 都驅逐出去
kubectl taint node node01 check=mycheck:NoExecute
//此時如果別的 Node 資源不夠用,可臨時給 Master 設置 PreferNoSchedule 污點,讓 Pod 可在 Master 上臨時創建
kubectl taint node master node-role.kubernetes.io/master=:PreferNoSchedule
//待所有 Node 的更新操作都完成后,再去除污點
kubectl taint node node01 check=mycheck:NoExecute-
4、維護操作cordon和drain
##對節點執行維護操作:
kubectl get nodes//將 Node 標記為不可調度的狀態,這樣就不會讓新創建的 Pod 在此 Node 上運行
kubectl cordon <NODE_NAME> #該node將會變為SchedulingDisabled狀態//kubectl drain 可以讓 Node 節點開始釋放所有 pod,并且不接收新的 pod 進程。drain 本意排水,意思是將出問題的 Node 下的 Pod 轉移到其它 Node 下運行
kubectl drain <NODE_NAME> --ignore-daemonsets --delete-emptydir-data --force--ignore-daemonsets:無視 DaemonSet 管理下的 Pod。
--delete-emptydir-data:如果有 mount local volume 的 pod,會強制殺掉該 pod。
--force:強制釋放不是控制器管理的 Pod。注:執行 drain 命令,會自動做了兩件事情:
(1)設定此 node 為不可調度狀態(cordon)
(2)evict(驅逐)了 Pod//kubectl uncordon 將 Node 標記為可調度的狀態
kubectl uncordon <NODE_NAME>5、pod啟動階段(相位phase)
Pod 創建完之后,一直到持久運行起來,中間有很多步驟,也就有很多出錯的可能,因此會有很多不同的狀態。
5.1.一般來說,pod 這個過程包含以下幾個步驟:
①調度到某臺 node 上。kubernetes 根據一定的優先級算法選擇一臺 node 節點將其作為 Pod 運行的 node
②拉取鏡像
③掛載存儲配置等
④運行起來,如果有健康檢查,會根據檢查的結果來設置其狀態
5.2.phase的可能狀態有
①Pending:表示APIServer創建了Pod資源對象并已經存入了etcd中,但是它并未被調度完成(比如還沒有調度到某臺node上),或者仍然處于從倉庫下載鏡像的過程中。
②Running:Pod已經被調度到某節點之上,并且Pod中所有容器都已經被kubelet創建。至少有一個容器正在運行,或者正處于啟動或者重啟狀態(也就是說Running狀態下的Pod不一定能被正常訪問)。
③Succeeded:有些pod不是長久運行的,比如job、cronjob,一段時間后Pod中的所有容器都被成功終止,并且不會再重啟。需要反饋任務執行的結果。
④Failed:Pod中的所有容器都已終止了,并且至少有一個容器是因為失敗終止。也就是說,容器以非0狀態退出或者被系統終止,比如 command 寫的有問題。
⑤Unknown:表示無法讀取 Pod 狀態,通常是 kube-controller-manager 無法與 Pod 通信。
6、如何和刪除UNknown狀態的pod
①從集群中刪除有問題的 Node。使用公有云時,kube-controller-manager 會在 VM 刪除后自動刪除對應的 Node。 而在物理機部署的集群中,需要管理員手動刪除 Node(kubectl delete node <node_name>)。
②被動等待 Node 恢復正常,Kubelet 會重新跟 kube-apiserver 通信確認這些 Pod 的期待狀態,進而再決定刪除或者繼續運行這些 Pod。
③主動刪除 Pod,通過執行 kubectl delete pod <pod_name> --grace-period=0 --force 強制刪除 Pod。但是這里需要注意的是,除非明確知道 Pod 的確處于停止狀態(比如 Node 所在 VM 或物理機已經關機),否則不建議使用該方法。特別是 StatefulSet 管理的 Pod,強制刪除容易導致腦裂或者數據丟失等問題
三、k8s集群的故障排查步驟
1、查看pod事件
kubectl describe TYPE NAME_PREFIX 2、查看pod日志(Failed狀態下)
kubectl logs <POD_NAME> [-c Container_NAME]
3、進入pod(狀態為running,但是服務沒有提供)
kubectl exec –it <POD_NAME> bash
4、查看集群信息
kubectl get nodes5、發現集群狀態正常
kubectl cluster-info6、查看kubelet日志發現
journalctl -xefu kubelet


















