前言
在?K8s 集群管理中,Pod 的調度約束——親和性(Affinity)與反親和性(Anti-Affinity)這兩種機制允許管理員精細控制 Pod 在集群內的分布方式,以適應多樣化的業務需求和運維策略。本篇將介紹?K8s 集群中 Pod 調度的親和與反親和的概念以及相關案例。
目錄
一、Pod 生命周期
1. 概述
2. 圖示
3. 介紹
二、調度約束
1. 概述
2.?Pod 啟動典型創建過程(工作機制)
2.1 圖示
2.2 創建過程
三、調度過程介紹
1.?關注的問題
2. 調度策略
2.1 分類
2.2 Predicate(預選)常見算法
2.3?priorities(優選)常見算法
3.?指定調度節點
3.1?nodeName 調度
3.2?nodeSelector 調度
3.3 區別
4.?k8s 節點的標簽管理
5. node?親和性
5.1 概述
5.1.1 節點親和性(Node Affinity)
5.1.2 Pod 親和性(Pod Affinity)
5.2 硬策略和軟策略?
5.2.1 硬策略
5.2.2 軟策略
5.3?鍵值運算關系
5.4 示例
示例1:node 硬策略
示例2:node 軟策略?
示例3:node 軟策略權重配置
示例4:node 硬策略軟策略組合
示例5:node 硬策略軟策略組合,硬策略條件不滿足
6.?Pod 親和性與反親和性
6.1 概述
6.2 node 親和性、pod 親和性與反親和性對比
6.3 親和性示例
6.4 反親和性示例
一、Pod 生命周期
1. 概述
Pod 的生命周期是指從 Pod 被創建到最終被銷毀的整個過程,涉及多個階段和狀態轉換,以及可能執行的各種操作。
2. 圖示
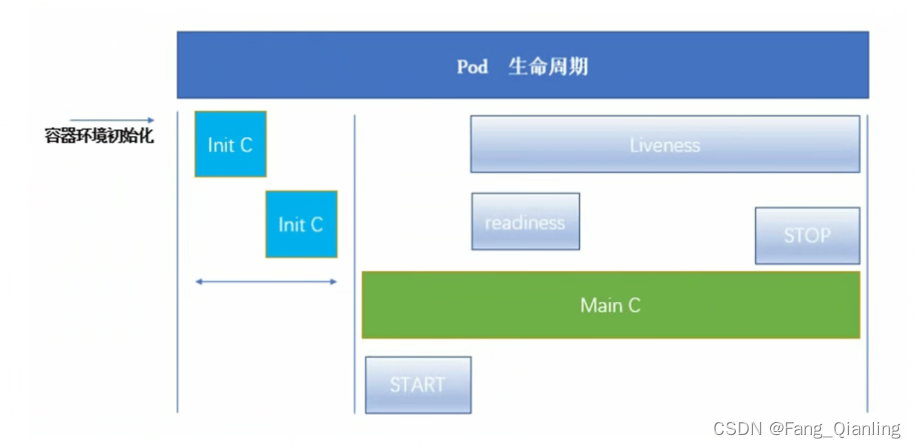
3. 介紹
Pod 生命周期/啟動過程
① 首先,由 pid 為1的 init 容器(pause容器)管理整個容器的初始化
② 接著,init 容器串行啟動
③?容器啟動時執行 postStart 操作
④ 隨后啟動存活探針和就緒探針
⑤ 根據資源限制的 request 和 limit 啟動應用容器
⑥?最后,在容器退出時執行 preStop 操作
二、調度約束
1. 概述
Kubernetes 中各組件通過 List-Watch 機制協作,保持數據同步且解耦。用戶通過 kubectl 向 APIServer 發送命令,在 Node 節點上創建 Pod 和 Container。部署過程需要 Controller Manager、Scheduler 和 kubelet 協同工作。所有部署信息存儲在 etcd 中,etcd 向 APIServer 發送 Create 事件,實現信息同步和協作。
2.?Pod 啟動典型創建過程(工作機制)
2.1 圖示
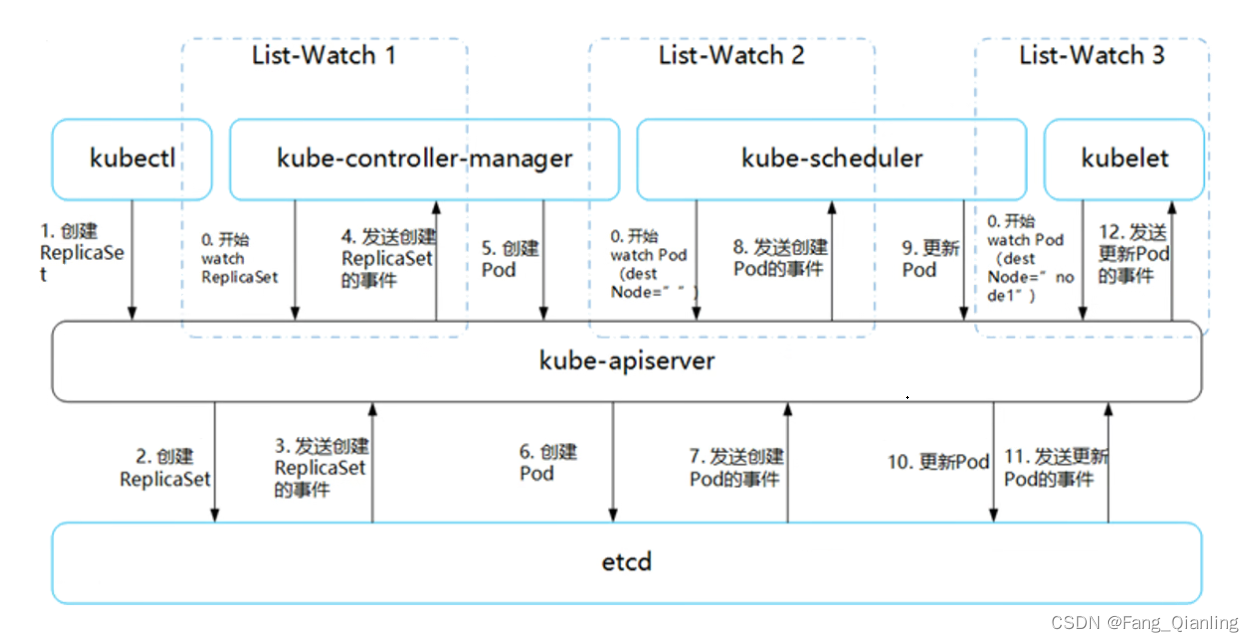
2.2 創建過程
(1)客戶端發出創建指令 ReplicaSet(控制器),通過 kube-apiserver 接口
(2)kube-apiserver 服務將創建 pod 模板這條信息發給 etcd 存儲
(3)etcd 發送 create 事件至?kube-apiserver
(4)kube-apiserver 發送 create 事件至 kube-controller-manager 管理控制器
(5)kube-controller-manager 會根據需要創建的 pod 清單(副本項/容器的內容),并發送創建 cretae pod 的需求至 kube-controller-manager
(6)kube-controller-manager 會將需要創建的信息保存在 etcd 中
(7)etcd 會將發來的事件(數據清單)發送給?kube-apiserver
(8)kube-apiserver 會將 etcd 發出的事件(創建 pod 的事件)給 kube-scheduler 資源調度器
(9)kube-scheduler 通過調度算法(預選、優選)篩選 node 調度 pod,并將調度完成的信息傳給?kube-apiserver
(10)kube-apiserver 會將調度完成的信息保存在 etcd 中?
(11)etcd 會發出更新的 pod 事件至?kube-apiserver
(12)kube-apiserver?會發出更新的 pod 事件至 kubelet
(13)kubelet 會跟容器進行交互創建 pod 及容器,并將 pod 容器的狀態通過?kube-apiserver 存儲到 etcd 中?
(14)最終 etcd 確認信息結束流程
注意:
① 整個過程中,上方的命令、組件均通過 https 6443 監聽?kube-apiserver 接口;
② 在創建 pod 的工作就已經完成了后,kubelet 依然保持監聽。如:擴充 Pod 副本數量、鏡像文件升級等需求。
三、調度過程介紹
1.?關注的問題
Scheduler 是 kubernetes 的調度器,主要的任務是把定義的 pod 分配到集群的節點上。其主要考慮的問題如下:
- 公平:如何保證每個節點都能被分配資源
- 資源高效利用:集群所有資源最大化被使用
- 效率:調度的性能要好,能夠盡快地對大批量的 pod 完成調度工作
- 靈活:允許用戶根據自己的需求控制調度的邏輯
Scheduler 作為獨立程序運行,持續監聽 APIServer,檢索 spec.nodeName 為空的 Pod,并為每個 Pod 創建一個綁定 binding(API 對象),指定其應放置在哪個節點上。?
2. 調度策略
2.1 分類
預選策略:首先是過濾掉不滿足條件的節點,這個過程稱為預算策略(predicate);
優選策略:然后對通過的節點按照優先級排序,這個是優選策略(priorities);
優先級:最后從中選擇優先級最高的節點。若中間步驟有誤,返回錯誤。
2.2 Predicate(預選)常見算法
Predicate 是一種策略函數,用于評估節點是否適合放置特定的 Pod。Predicate 函數會檢查節點的特性和 Pod 的要求,以確定是否可以將 Pod 放置在該節點上
PodFitsResources
- 節點上剩余的資源是否大于 pod 請求的資源nodeName,檢查節點名稱是否和 NodeName 匹配。
PodFitsHost
- 如果 pod 指定了 NodeName,檢查節點名稱是否和 NodeName 匹配。
PodFitsHostPorts
- 節點上已經使用的 port 是否和 pod 申請的 port 沖突。
PodSelectorMatches
- 過濾掉和 pod 指定的 label 不匹配的節點。?
NoDiskConflict
- 已經 mount 的 volume 和 pod 指定的 volume 不沖突,除非它們都是只讀。
如果在 predicate(預選)過程中沒有合適的節點,pod 會一直在 pending(等待 running)狀態,不斷重試調度,直到有節點滿足條件。 經過這個步驟,如果有多個節點滿足條件,就繼續 priorities(優選)過程:按照優先級大小對節點排序。?
2.3?priorities(優選)常見算法
優先級由一系列鍵值對組成,鍵是該優先級項的名稱,值是它的權重(該項的重要性)。常見的優先級選項包括:
LeastRequestedPriority
- 通過計算CPU和Memory的使用率來決定權重,使用率越低權重越高。也就是說,這個優先級指標傾向于資源使用比例更低的節點。
BalancedResourceAllocation
- 節點上 CPU 和 Memory 使用率越接近,權重越高。這個一般和上面的一起使用,不單獨使用。比如 node01 的 CPU 和 Memory 使用率 20:60,node02 的 CPU 和 Memory 使用率 50:50,雖然 node01 的總使用率比 node02 低,但 node02 的 CPU 和 Memory 使用率更接近,從而調度時會優選 node02。
ImageLocalityPriority
- 傾向于已經有要使用鏡像的節點,鏡像總大小值越大,權重越高。
通過算法對所有的優先級項目和權重進行計算,得出最終的結果。
3.?指定調度節點
3.1?nodeName 調度
pod.spec.nodeName 將 Pod 直接調度到指定的 Node 節點上,會跳過 Scheduler 的調度策略,該匹配規則是強制匹配
示例:
3.2?nodeSelector 調度
pod.spec.nodeSelector:通過 kubernetes 的 label-selector 機制選擇節點,由調度器調度策略匹配 label,然后調度 Pod 到目標節點,該匹配規則屬于強制約束
示例:
3.3 區別
①?nodeName?只能指定單個node節點,nodeSelector 可以指定有相同標簽的多個 node 節點
②?nodeName 強制調度,不需要經過?scheduler 資源調度器;nodeSelector?經過?scheduler 資源調度器
4.?k8s 節點的標簽管理
增加標簽:
kubectl label [ -n 命名空間 ] 資源類型 資源名稱 標簽鍵名=鍵值
刪除標簽:
kubectl label [ -n 命名空間 ] 資源類型 資源名稱 標簽鍵名-(減號不能忽略)
修改標簽:
kubectl label [ -n 命名空間 ] 資源類型 資源名稱 標簽鍵名=新的鍵值 --overwrite
查詢標簽:
kubectl get [ -n 命名空間 ] 資源類型 --show-label [ -l 標簽鍵名 ]或[ -l 標簽鍵名=鍵值 ](篩選)5. node?親和性
官方文檔:將 Pod 指派給節點 | Kubernetes
5.1 概述
節點親和性允許你指定Pod應當(preferred)或必須(required)調度到具有某些標簽的節點上,可以實現Pod調度的精細化控制,確保Pod被安排在具有特定特性的節點上,從而滿足應用的部署需求或優化資源利用。
5.1.1 節點親和性(Node Affinity)
節點親和性指定了 Pod 可以被調度到哪些節點上。
pod.spec.nodeAffinity
● preferredDuringSchedulingIgnoredDuringExecution:軟策略
● requiredDuringSchedulingIgnoredDuringExecution:硬策略5.1.2 Pod 親和性(Pod Affinity)
Pod 親和性指定了 Pod 應該與哪些其他 Pod 一起調度到同一節點上。
pod.spec.affinity.podAffinity/podAntiAffinity
● preferredDuringSchedulingIgnoredDuringExecution:軟策略
● requiredDuringSchedulingIgnoredDuringExecution:硬策略5.2 硬策略和軟策略?
5.2.1 硬策略
硬策略,正式名稱為 requiredDuringSchedulingIgnoredDuringExecution,表示必須滿足的條件。如果無法找到滿足條件的節點來調度 Pod,則 Pod 將不會被調度。這意味著硬策略是強制性的。
5.2.2 軟策略
軟策略,正式名稱為 preferredDuringSchedulingIgnoredDuringExecution,表示傾向于滿足但不是必須的條件。與硬策略不同,即使沒有節點完全符合軟策略的所有偏好,Pod仍然會被調度。
軟策略通常會附帶一個權重值(范圍1~100),用來表示偏好的強度。當存在多個節點可以選擇時,調度器會根據這些偏好和它們的權重來決定最佳的調度位置。
5.3?鍵值運算關系
- In:label 的值在某個列表中 ?pending ??
- NotIn:label 的值不在某個列表中
- Gt:label 的值大于某個值
- Lt:label 的值小于某個值
- Exists:某個 label 存在
- DoesNotExist:某個 label 不存在
5.4 示例
示例1:node 硬策略
指定 Kubernetes 調度器在部署這個 Pod 時,要求 Pod 不會被調度到主機名為"node02"的節點上。
① 編輯 yaml 文件
[root@master01 affinity]# vim pod1.yaml
apiVersion: v1 # Kubernetes API版本
kind: Pod # 資源類型為Pod
metadata: # Pod的元數據信息name: affinity # Pod的名稱為labels: # 為Pod定義了標簽app: node-affinity-pod
spec: # 定義了Pod的規格,包括容器和親和性設置 containers: # 定義了Pod中的容器- name: with-node-affinity # 容器的名稱image: soscscs/myapp:v1 # 容器要運行的鏡像affinity: # 定義了Pod的親和性設置nodeAffinity: # 指定了節點親和性requiredDuringSchedulingIgnoredDuringExecution: # 硬策略nodeSelectorTerms: # 節點選擇器的條件- matchExpressions: # 指定了匹配表達式,用于匹配節點的標簽- key: kubernetes.io/hostname # 指定了要匹配的節點標簽的鍵值operator: NotIn # 表示不在指定的值列表中values:- node02
# 指定了不在值列表["node02"]中的節點,即Pod不會被調度到主機名為"node02"的節點上② 啟動 pod
[root@master01 affinity]# kubectl apply -f pod1.yaml
pod/affinity created
③ 查看 pod 節點詳情信息
[root@master01 affinity]# kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
affinity 1/1 Running 0 5s 10.244.1.30 node01 <none> <none>
由于集群中就兩個 node 節點(),所有新建的 pod 會被調度到 node01 上。?另外,如果硬策略不滿足條件,Pod 狀態一直會處于 Pending 狀態,比如:?operator: In? values: [node03]
示例2:node 軟策略?
設置了節點親和性,優先選擇主機名為"node03"的節點來調度這個 Pod。
① 節點增加標簽
[root@master01 affinity]# kubectl label nodes node01 fql=a
node/node01 labeled
[root@master01 affinity]# kubectl label nodes node02 fql=b
node/node02 labeled
[root@master01 affinity]# kubectl get nodes --show-labels
NAME STATUS ROLES AGE VERSION LABELS
master01 Ready control-plane,master 12d v1.20.11 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetes.io/arch=amd64,kubernetes.io/hostname=master01,kubernetes.io/os=linux,node-role.kubernetes.io/control-plane=,node-role.kubernetes.io/master=
node01 Ready <none> 11d v1.20.11 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,fql=a,kubernetes.io/arch=amd64,kubernetes.io/hostname=node01,kubernetes.io/os=linux
node02 Ready <none> 11d v1.20.11 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,fql=b,kubernetes.io/arch=amd64,kubernetes.io/hostname=node02,kubernetes.io/os=linux
② 編輯 yaml 文件
[root@master01 affinity]# vim pod2.yaml
apiVersion: v1
kind: Pod
metadata:name: affinitylabels:app: node-affinity-pod
spec:containers:- name: with-node-affinityimage: soscscs/myapp:v1affinity: # 定義了Pod的親和性設置nodeAffinity: # 指定了節點親和性preferredDuringSchedulingIgnoredDuringExecution: # 軟策略- weight: 1 # 權重為1preference: # 定義了節點親和性的偏好設置matchExpressions: # 定義了匹配表達式,用于指定節點選擇的條件- key: fql # 指定了匹配的鍵operator: In # 節點的主機名必須在指定的值列表中values:- a
# 指定了匹配的值列表,這里只有一個值"node03",表示偏好選擇主機名為"node03"的節點③ 啟動 pod
[root@master01 affinity]# kubectl delete -f pod1.yaml④ 查看 pod 節點詳情信息
[root@master01 affinity]# kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
affinity 1/1 Running 0 8s 10.244.1.31 node01 <none> <none>
⑤ 修改 volume 值
values:- c # 實際上不存在c
⑥ 啟動 pod 并查看詳情信息
[root@master01 affinity]# kubectl apply -f pod2.yaml
pod/affinity created
[root@master01 affinity]# kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
affinity 1/1 Running 0 4s 10.244.1.32 node01 <none> <none>
這里得到的結果并不明顯,軟策略下無法選擇主機名為"node03"的節點來調度這個,會選擇其他可用的節點。
示例3:node 軟策略權重配置
設置多條軟策略不同的權重,查看調用情況。
對應調度標簽鍵值為:fql:a 的權重為10;對應調度標簽鍵值為:fql:b 的權重為20;
①?編輯 yaml 文件
[root@master01 affinity]# vim pod3.yaml
apiVersion: v1
kind: Pod
metadata:name: affinitylabels:app: node-affinity-pod
spec:containers:- name: with-node-affinityimage: soscscs/myapp:v1affinity:nodeAffinity:preferredDuringSchedulingIgnoredDuringExecution:- weight: 10preference:matchExpressions:- key: fqloperator: Invalues:- apreferredDuringSchedulingIgnoredDuringExecution:- weight: 20preference:matchExpressions:- key: fqloperator: Invalues:- b
② 創建 pod
[root@master01 affinity]# kubectl apply -f pod3.yaml
pod/affinity created
③ 查看 pod 詳情信息?
[root@master01 affinity]# kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
affinity 1/1 Running 0 3s 10.244.2.11 node02 <none> <none>
由此可見,即使標簽鍵值為:fql:b 的調度任務在 yaml 文件下面,只要權重大,則會被調用。
示例4:node 硬策略軟策略組合
硬策略對應調度標簽鍵值為:fql:a 的 node;軟策略對應調度標簽鍵值為:fql:b 的 node;
①?編輯 yaml 文件
[root@master01 affinity]# vim pod4.yaml
apiVersion: v1
kind: Pod
metadata:name: affinitylabels:app: node-affinity-pod
spec:containers:- name: with-node-affinityimage: soscscs/myapp:v1affinity:nodeAffinity:requiredDuringSchedulingIgnoredDuringExecution:nodeSelectorTerms:- matchExpressions:- key: fqloperator: Invalues:- apreferredDuringSchedulingIgnoredDuringExecution:- weight: 1preference:matchExpressions:- key: fqloperator: Invalues:- b② 創建 pod
[root@master01 affinity]# kubectl apply -f pod4.yaml
pod/affinity created
[root@master01 affinity]# kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
affinity 1/1 Running 0 3s 10.244.1.33 node01 <none> <none>
?由于優先滿足硬策略,可以看見調到到 node01上。
③ 再次創建新的 pod
[root@master01 affinity]# vim pod4.yaml
metadata:name: affinity-01[root@master01 affinity]# kubectl apply -f pod4.yaml
pod/affinity-01 created
[root@master01 affinity]# kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
affinity 1/1 Running 0 27s 10.244.1.33 node01 <none> <none>
affinity-01 1/1 Running 0 3s 10.244.1.34 node01 <none> <none>
[root@master01 affinity]# vim pod1.yaml
由于優先滿足硬策略,可以看見并未輪詢調度,依然調到到 node01上。?
示例5:node 硬策略軟策略組合,硬策略條件不滿足
硬策略對應調度標簽鍵值為:fql:c 的 node(實際并不存在);軟策略對應調度標簽鍵值為:fql:b 的 node;
①?編輯 yaml 文件
[root@master01 affinity]# kubectl delete -f pod4.yaml
[root@master01 affinity]# kubectl delete -f pod4.yaml[root@master01 affinity]# vim pod4.yaml
apiVersion: v1
kind: Pod
metadata:name: affinitylabels:app: node-affinity-pod
spec:containers:- name: with-node-affinityimage: soscscs/myapp:v1affinity:nodeAffinity:requiredDuringSchedulingIgnoredDuringExecution:nodeSelectorTerms:- matchExpressions:- key: fqloperator: Invalues:- cpreferredDuringSchedulingIgnoredDuringExecution:- weight: 1preference:matchExpressions:- key: fqloperator: Invalues:- b② 創建 pod
[root@master01 affinity]# kubectl apply -f pod4.yaml
pod/affinity created
③ 查看 pod 詳情信息
[root@master01 affinity]# kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
affinity 0/1 Pending 0 3s <none> <none> <none> <none>
如果把硬策略和軟策略合在一起使用,則要先滿足硬策略之后才會滿足軟策略;這里硬策略不滿足,所以處于?Pending 狀態。
6.?Pod 親和性與反親和性
6.1 概述
在 Kubernetes 中,親和性是一種指導 Pod 如何與節點進行交互的機制。親和性可以幫助您控制 Pod 的調度行為,包括節點親和性(Node Affinity)、Pod 親和性(Pod Affinity)。可以約束一個 Pod 以便限制其只能在特定的節點上運行, 或優先在特定的節點上運行。
節點反親和性與節點親和性相反,它用來避免 Pod 被調度到具有特定標簽的節點上,這有助于實現高可用性和資源隔離。
6.2 node 親和性、pod 親和性與反親和性對比
| 調度策略 | 匹配標簽 | 操作符 | 拓撲域支持 | 調度目標 |
| nodeAffinity | 主機 | In, NotIn, Exists,DoesNotExist, Gt, Lt | 否 | 指定主機 |
| podAffinity | Pod | In, NotIn, Exists,DoesNotExist | 是 | Pod與指定Pod同一拓撲域 |
| podAntiAffinity | Pod | In, NotIn, Exists,DoesNotExist | 是 | Pod與指定Pod不在同一拓撲域 |
6.3 親和性示例
使用 Pod 親和性調度,創建多個 Pod 資源。
topologyKey 是節點標簽的鍵。如果兩個節點使用此鍵標記并且具有相同的標簽值,則調度器會將這兩個節點視為處于同一拓撲域中。 調度器試圖在每個拓撲域中放置數量均衡的 Pod。
①?創建一個標簽為 app=myapp01 的 Pod
創建一個帶有標簽的 Pod,觀察調度在哪個節點上。
[root@master01 affinity]# vim demo01.yaml
apiVersion: v1
kind: Pod
metadata:name: myapp01labels:app: myapp01
spec:containers:- name: with-node-affinityimage: soscscs/myapp:v1② 啟動 pod?myapp01
[root@master01 affinity]# kubectl apply -f demo01.yaml
pod/myapp01 created
[root@master01 affinity]# kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
myapp01 1/1 Running 0 3s 10.244.1.35 node01 <none> <none>
③ 采用硬策略關聯標簽為 app: myapp01 的 pod
Pod 之間的調度約束,要求在調度 Pod 時,必須滿足以下條件:Pod 的標簽中包含 app=myapp01。這樣的設置可以確保在調度 Pod 時,只有滿足特定標簽條件的節點才會被考慮。
[root@master01 affinity]# vim demo02.yaml
apiVersion: v1
kind: Pod
metadata:name: myapp02labels:app: myapp02
spec:containers:- name: myapp02image: soscscs/myapp:v1affinity: # Pod的親和性設置,用于指定Pod的調度約束podAffinity: # Pod的親和性規則requiredDuringSchedulingIgnoredDuringExecution: # 硬策略- labelSelector: # 用于選擇標簽的規則matchExpressions: # 這是匹配表達式的列表- key: app # 要匹配的標簽鍵operator: In # 匹配標簽鍵值中的任意一個values: # 匹配的標簽值列表- myapp01 # 要匹配的標簽值topologyKey: fql # 用于指定拓撲域的鍵,用于確定在哪些節點上進行親和性約束④ 啟動 pod?myapp02
[root@master01 affinity]# kubectl apply -f demo02.yaml
pod/myapp02 created
[root@master01 affinity]# kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
myapp01 1/1 Running 0 35m 10.244.1.35 node01 <none> <none>
myapp02 1/1 Running 0 3s 10.244.1.36 node01 <none> <none>
⑤ 再次創建新的 pod?myapp03
[root@master01 affinity]# vim demo02.yaml
metadata:name: myapp03[root@master01 affinity]# kubectl apply -f demo02.yaml
pod/myapp03 created
[root@master01 affinity]# kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
myapp01 1/1 Running 0 38m 10.244.1.35 node01 <none> <none>
myapp02 1/1 Running 0 3m10s 10.244.1.36 node01 <none> <none>
myapp03 1/1 Running 0 2s 10.244.1.37 node01 <none> <none>
⑥ 修改 node02 標簽,使得與 node01 在同一拓撲域
[root@master01 affinity]# kubectl label nodes node02 --overwrite fql=a
node/node02 labeled
[root@master01 affinity]# kubectl get node --show-labels
NAME STATUS ROLES AGE VERSION LABELS
master01 Ready control-plane,master 12d v1.20.11 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetes.io/arch=amd64,kubernetes.io/hostname=master01,kubernetes.io/os=linux,node-role.kubernetes.io/control-plane=,node-role.kubernetes.io/master=
node01 Ready <none> 12d v1.20.11 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,fql=a,kubernetes.io/arch=amd64,kubernetes.io/hostname=node01,kubernetes.io/os=linux
node02 Ready <none> 12d v1.20.11 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,fql=a,kubernetes.io/arch=amd64,kubernetes.io/hostname=node02,kubernetes.io/os=linux
⑦ 再次創建新的?pod?myapp04,觀察調度情況
[root@master01 affinity]# kubectl apply -f demo02.yaml
pod/myapp04 created
[root@master01 affinity]# kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
myapp01 1/1 Running 0 49m 10.244.1.35 node01 <none> <none>
myapp02 1/1 Running 0 13m 10.244.1.36 node01 <none> <none>
myapp03 1/1 Running 0 10m 10.244.1.37 node01 <none> <none>
myapp04 1/1 Running 0 6s 10.244.2.12 node02 <none> <none>
在同一拓撲域,按照輪詢的機制,此時新的 pod 將調度到 node02。?
6.4 反親和性示例
Pod 反親和性(Pod Anti-Affinity)是用來確保 Kubernetes 中的 Pod 不會與某些特定標簽的 Pod 調度到同一節點上的規則。
示例1:軟策略
① 創建 yaml?
[root@master01 affinity]# vim demo03.yaml
apiVersion: v1
kind: Pod
metadata:name: myapp10labels:app: myapp10
spec:containers:- name: myapp10image: soscscs/myapp:v1affinity: # 定義了Pod之間的親和性設置podAntiAffinity: # Pod之間的反親和性規則preferredDuringSchedulingIgnoredDuringExecution: # 軟策略- weight: 100 # 優先級權重為100podAffinityTerm: # 指定了關于Pod親和性的條件labelSelector: # 標簽選擇器,用于選擇具有特定標簽的PodmatchExpressions: # 匹配表達式列表- key: app # 要匹配的標簽鍵為appoperator: In # 標簽的值必須在指定的值列表中values: - myapp01 # 標簽的值必須為myapp01topologyKey: fql # 指定拓撲域的鍵
② 創建 pod
[root@master01 affinity]# kubectl label nodes node02 --overwrite fql=b[root@master01 affinity]# kubectl apply -f demo03.yaml
[root@master01 affinity]# kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
myapp01 1/1 Running 0 51s 10.244.1.41 node01 <none> <none>
myapp02 1/1 Running 0 24s 10.244.1.42 node01 <none> <none>
myapp10 1/1 Running 0 4s 10.244.2.13 node02 <none> <none>如果節點處于 Pod 所在的同一拓撲域且具有鍵“app”和值“myapp01”的標簽, 則該 pod 不應將其調度到該節點上。 (如果 topologyKey 為 fql,則意味著當節點和具有鍵 “app”和值“myapp01”的 Pod 處于相同的拓撲域,Pod 不能被調度到該節點上。)
示例2:硬策略
① 創建 yaml?
[root@master01 affinity]# vim demo4.yaml
apiVersion: v1
kind: Pod
metadata:name: myapp20labels:app: myapp20
spec:containers:- name: myapp20image: soscscs/myapp:v1affinity:podAntiAffinity:requiredDuringSchedulingIgnoredDuringExecution:- labelSelector:matchExpressions:- key: appoperator: Invalues:- myapp01topologyKey: fql② 創建 pod
[root@master01 affinity]# kubectl label nodes node02 --overwrite fql=a[root@master01 affinity]# kubectl apply -f demo4.yaml
pod/myapp20 created
[root@master01 affinity]# kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
myapp01 1/1 Running 0 9m2s 10.244.1.41 node01 <none> <none>
myapp02 1/1 Running 0 8m35s 10.244.1.42 node01 <none> <none>
myapp10 1/1 Running 0 8m15s 10.244.2.13 node02 <none> <none>
myapp20 0/1 Pending 0 5s <none> <none> <none> <none>
由于指定 Pod 所在的 node01 節點上具有帶有鍵 fql 和標簽值 a 的標簽,node02 也有這個 kgc=a的標簽,所以 node01 和 node02 是在一個拓撲域中,反親和要求新 Pod 與指定 Pod 不在同一拓撲域,所以新 Pod 沒有可用的 node 節點,即為 Pending 狀態。













項目)





