第1關:邏輯回歸算法大體思想
#encoding=utf8import numpy as np#sigmoid函數
def sigmoid(t):#輸入:負無窮到正無窮的實數#輸出:轉換后的概率值#********** Begin **********#result = 1.0 / (1 + np.exp(-t))#********** End **********#return round(result,12)
if __name__ == '__main__':pass
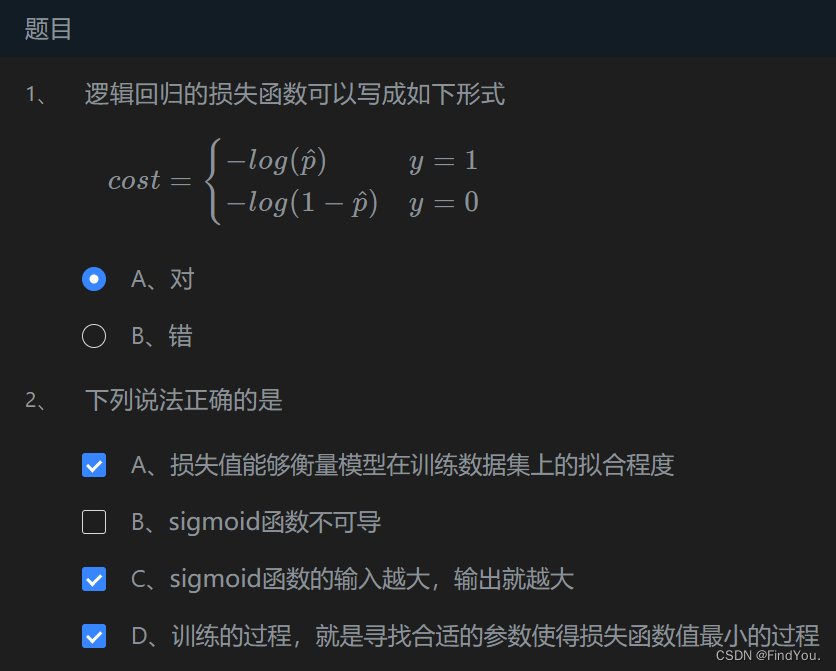
第2關:邏輯回歸的損失函數?
第3關:梯度下降
# -*- coding: utf-8 -*-import numpy as np
import warnings
warnings.filterwarnings("ignore")#梯度下降,inital_theta為參數初始值,eta為學習率,n_iters為訓練輪數,epslion為誤差范圍
def gradient_descent(initial_theta,eta=0.05,n_iters=1e3,epslion=1e-8):# 請在此添加實現代碼 ##********** Begin *********#theta = initial_thetai_iter = 0while i_iter < n_iters:gradient = 2*(theta-3)last_theta = thetatheta = theta - eta*gradientif(abs(theta-last_theta)<epslion):breaki_iter +=1#********** End **********#return theta
第4關:邏輯回歸算法流程
# -*- coding: utf-8 -*-import numpy as np
import warnings
warnings.filterwarnings("ignore")
#定義sigmoid函數
def sigmoid(x):return 1/(1+np.exp(-x))#梯度下降,x為輸入數據,y為數據label,eta為學習率,n_iters為訓練輪數
def fit(x,y,eta=1e-3,n_iters=1e4):# 請在此添加實現代碼 ##********** Begin *********#theta = np.zeros(x.shape[1])i_iter = 0while i_iter < n_iters:gradient = (sigmoid(x.dot(theta))-y).dot(x)theta = theta -eta*gradienti_iter += 1#********** End **********#return theta
?第5關:sklearn中的邏輯回歸
#encoding=utf8
import warnings
warnings.filterwarnings("ignore")
from sklearn.linear_model import LogisticRegression
from sklearn import datasets
from sklearn.model_selection import train_test_split
def cancer_predict(train_sample, train_label, test_sample):'''實現功能:1.訓練模型 2.預測:param train_sample: 包含多條訓練樣本的樣本集,類型為ndarray:param train_label: 包含多條訓練樣本標簽的標簽集,類型為ndarray:param test_sample: 包含多條測試樣本的測試集,類型為ndarry:return: test_sample對應的預測標簽'''#********* Begin *********#cancer = datasets.load_breast_cancer()#X表示特征,y表示標簽X = cancer.datay = cancer.target##劃分訓練集和測試集X_train,X_test,y_train,y_test=train_test_split(X,y,test_size=0.20)logreg = LogisticRegression(solver='lbfgs',max_iter =200,C=10)logreg.fit(X_train, y_train)result = logreg.predict(test_sample)# print(result)return result#********* End *********#



















--Ribbon默認負載輪詢算法原理及源碼解析)