一、Java 基礎
1.JDK 和 JRE 有什么區別?
jdk:java development kit
jre:java runtime Environment
jdk是面向開發人員的,是開發工具包,包括開發人員需要用到的一些類。
jre是java運行時環境,包括java虛擬機等,是提供給使用java的人用的
2.== 和 equals 的區別是什么?
==比較的是兩個對象,包括對象的地址位,如果比較的兩個對象地址位不同,值相同也會返回false
equals比較的是兩個字符串的值,只要值相同,就會返回true
3.兩個對象的 hashCode()相同,則 equals()也一定為 true,對嗎?
不對,hashCode也是可以重寫的,所以不一定。
反之,如果equals()相同,那么hashCode是一定相等的。
4.final 在 java 中有什么作用?
修飾類不可被繼承;
修飾方法不可被重寫;
修飾變量不能被修改。
5.JAVA 中的 Math.round(-1.5) 等于多少?
-1
向上取整Math.ceil();
向下取整Math.floor();
四舍五入Math.round(x); //==Math.floor(x+0.5)
6.String 屬于基礎的數據類型嗎?
不屬于,是final修飾的Java類。
java中的基本數據類型:byte、char、short、int、long、float、double、boolean
7.java 中操作字符串都有哪些類?它們之間有什么區別?
String、StringBuffer、StringBuilder
String類型的字符串是不可變的,StringBuffer和StringBuilder是可以對同一個對象做更新操作的
StringBuffer是線程安全的,StringBuilder不是線程安全的。
8.String str="i"與 String str=new String("i")一樣嗎?
不一樣。他們不是同一個對象
前者如果定義多個變量都為相同值的話,會共用同一個地址,創建的對象應該放在了常量池中;
后者是創建了一個新的對象,放在的是堆內存中。
9.如何將字符串反轉?
?使用StringBuffer 或 StringBuilder 的 reverse 成員方法。
10.String 類的常用方法都有那些?
"".toCharArray("");
"".charAt();
"".split();
"".indexOf();
"".equals();
"".contains();
"".length();
"".subString("");
"".replace("","");
11.抽象類必須要有抽象方法嗎?
不是。
抽象類可以沒有抽象方法,但是如果你的一個類已經聲明成了抽象類,即使這個類中沒有抽象方法,它也不能再實例化,即不能直接構造一個該類的對象。如果一個類中有了一個抽象方法,那么這個類必須聲明為抽象類,否則編譯通不過。
12.普通類和抽象類有哪些區別?
普通類可以被繼承,不能包含抽象方法,不可以被實現。
抽象類也可被繼承,但是子類必須要實現父類中的抽象方法;
抽象類中的方法不能包含主體。
抽象類中的方法在擴展性和延伸性要比普通類的更好;
抽象類可以應用多態,普通類不可以。
13.抽象類能使用 final 修飾嗎?
不能。
14.接口和抽象類有什么區別?
接口是要被實現的,抽象類是要被繼承;
接口用interface修飾;抽象類使用abstract修飾;
兩者均不能被實例化,方法都不包含主體;
一個類只能繼承一個抽象類,但是可以實現多個接口。
15.java 中 IO 流分為幾種?
字節流:InputStream、OutputStream
字符流:Reader、Writer
字節流是最基本的
1.字節流可用于任何類型的對象,包括二進制對象,而字符流只能處理字符或者字符串;
2.字節流提供了處理任何類型的IO操作的功能,但它不能直接處理Unicode字符,而字符流就可以。
讀文本的時候用字符流,例如txt文件。讀非文本文件的時候用字節流,例如mp3。
16.BIO、NIO、AIO 有什么區別?
BIO:Block IO 同步阻塞式 IO
NIO:Non IO 同步非阻塞 IO
AIO:Asynchronous IO ?異步非阻塞IO
BIO是一個連接一個線程。JDK4之前的唯一選擇
NIO是一個請求一個線程。JDK4之后開始支持,常見聊天服務器
AIO是一個有效請求一個線程。JDK7之后開始支持,常見相冊服務器
17.Files的常用方法都有哪些?
file.getName();
file.getPath();
file.delete();
file.exits();
file.createDirectory();
file.copy();
file.move();
file.size();
file.read();
file.write();
18.重寫和重載的區別
重載:必須有不同的參數列表;可以有不同的訪問修飾符;可以拋出不同的異常;
重寫:參數列表必須要與被重寫的相同;返回的類型必須保持一致;修飾符和拋出的異常不能在被重寫的方法之外
重寫是父類與子類的關系,是垂直關系;重載是同一個類方法中的關系,是水平關系。
19.什么是多態
一種事物的多種表現形態就是多態,比如定義一個類為動物,那么動物可以被子類繼承,從而實現具體動物的方法。
二、容器
1.java 容器都有哪些?
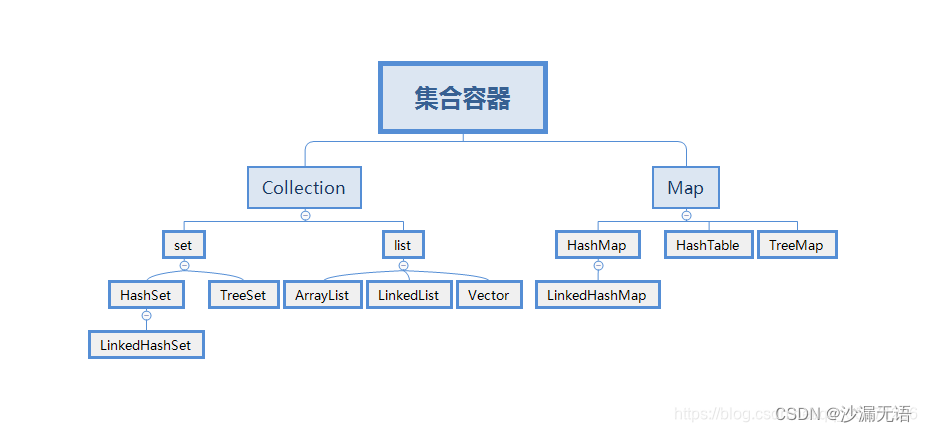
數組、Util下的容器:Collection(Set、List)、Map
2.Collection 和 Collections 有什么區別?
Collection是集合的接口,其實現類有List和Set;
Collections是工具類,包含許多有關集合操作的靜態多態方法,可以直接使用。
3.List、Set、Map 之間的區別是什么?
List:有序集合、元素可重復
Set:元素不可重復,HashSet無序,LinkedHashSet按照插入排序,SortedSet可排序
Map:鍵值對集合,存儲鍵、值之間的映射。key無序,唯一,value可重復
4.HashMap 和 Hashtable 有什么區別?
HashMap不是線程安全的,HashTable是線程安全的
HashMap允許Null Key和Null Value,HashTable不允許
5.如何決定使用 HashMap 還是 TreeMap?
如果需要得到一個有序的結果應該使用TreeMap
如果不需要排序最好選用HashMap,性能更優
6.說一下 HashMap 的實現原理?
HashMap基于Hash算法實現,通過put(key,value)存儲,get(key)來獲取value
當傳入key時,HashMap會根據key,調用Hash(Object key)方法,計算出Hash值,根據Hash值將Value保存在Node對象里,Node對象保存在數組里。
當計算出的Hash值相同時,稱為Hash沖突,HashMap的做法是用鏈表和紅黑樹存儲相同Hash值的value
當Hash沖突的個數:小于等于8使用鏈表,大于8使用紅黑樹解決鏈表查詢慢的問題。
7.說一下 HashSet 的實現原理?
HashSet是基于HashMap實現的,HashSet底層使用HashMap來保存所有元素,因此HashSet的操作相對比較簡單,相關HashSet的操作,基本上都是直接調用底層的HashMap的相關方法來完成,HashSet不允許有重復的值,并且元素是無序的
8.ArrayList 和 LinkedList 的區別是什么?
ArrayList的數據結構是動態數組;LinkedList的數據結構是雙向鏈表。
ArrayList比LinkedList在隨機訪問的時候效率要高,因為LinkedList是線性的數據結構,需要依次往后查找
在非首尾的增刪操作,LinkedList要比ArrayList的效率要高,因為ArrayList在操作增刪時要影響其他元素的下標
總結:需要頻繁讀取集合中的元素時,推薦使用ArrayList;插入和刪除操作較多時,推薦使用LinkedList
9.如何實現數組和 List 之間的轉換?
List轉數組:String[] list = List.toArray(array);//array為List
數組轉List:List list = java.util.Arrays.asList(array);//array為數組
10.ArrayList 和 Vector 的區別是什么?
相同點:都實現了List接口,都是有序集合
區別:Vector是線程安全的,ArrayList不是線程安全的;
當Vector或ArrayList中的元素超過它的初始大小時,Vector會將容量翻倍,而ArrayList只會將容量擴大50%
11.Array 和 ArrayList 有何區別?
Array類型的變量在聲明時必須實例化;ArrayList可以只是先聲明;
Array大小是固定的,而ArrayList的大小是動態變化的;
Array可以包含基本類型和對象類型,ArrayList只能包含對象類型
12.在 Queue 中 poll()和 remove()有什么區別?
Queue中poll()和remove()都是用來從隊列頭部刪除一個元素;
在隊列元素為空的情況下,remove()方法會拋出NoSuchElementException異常,而poll()只會返回null
13.哪些集合類是線程安全的?
Vector:相比ArrayList多了線程安全;
HashTable:相比HashMap多了線程安全;
ConcurrentHashMap:高效且線程安全;
Stack:繼承于Vector,也是線程安全
14.迭代器 Iterator 是什么?
迭代器是一種設計模式,它是一個對象,可以遍歷并選擇序列中的對象。
15.Iterator 怎么使用?有什么特點?
next();
hashNext();
remove();
Iterator接口被Collection接口繼承,Collection接口的iterator()方法返回一個iterator對象。
16.Iterator 和 ListIterator 有什么區別?
ListIterator有add()方法,可以向List中添加對象,而Iterator不能;
ListIterator有hasPrevious()和previous()方法,可以向前遍歷,Iterator不能;
ListIterator可以定位當前的索引位置,nextIndex()和previousIndex()可以實現;
ListIterator可以實現對對象的修改,使用set()實現;而Iterator只能遍歷,不能修改
17.怎么確保一個集合不能被修改?
可以使用Collections.unmodifiableCollection(Collection c) 方法創建一個只讀集合
這樣改變集合的任何操作都會拋出Java. lang. UnsupportedOperationException異常。
三、多線程
1.并行和并發有什么區別?
并行是指兩個或多個事件在同一時刻發生,是在不同實體上的多個事件;
并發是指兩個或多個事件在同一時間間隔發生,是在同一個實體上的多個事件
2.線程和進程的區別?
進程是資源分配最小單位,線程是程序執行最小單位
每個進程都有相應的線程
進程有獨立的地址空間,線程沒有
線程是指處理機調度的基本單位
進程執行開銷大,線程執行開銷小
3.守護線程是什么?
在java線程開發中,有兩種線程:User Thread(用戶線程);Daemon Thread(守護線程)
普通用戶進程在JVM退出時依然會繼續執行,導致JVM并不能退出
普通進程可以使用setDaemon(true)方法升級為守護進程,守護進程在JVM退出時會自動結束運行。
守護線程擁有自動結束自己生命周期的特性,而非守護線程不具備這個特點
4.創建線程有哪幾種方式?
繼承Thread類并實現run方法,調用繼承類的start方法開啟線程;
通過實現Runnable接口,重寫run方法,調用線程對象的start方法開啟線程;
除此之外,還可以通過實現Callable接口,實現call方法,并用FutureTask類包裝Callable對象開啟線程。
5.說一下 runnable 和 callable 有什么區別?
實現Callable接口的任務線程能返回執行結果,而實現Runnable接口的任務線程并不能返回執行結果
Callable接口的call方法允許拋出異常,而Runnable接口的run方法的異常只能在內部消化,不能繼續上拋
6.線程有哪些狀態?
新建、就緒、運行、阻塞、死亡
7.sleep() 和 wait() 有什么區別?
sleep后程序不會釋放同步鎖,wait后程序會釋放同步鎖
sleep可以指定睡眠時間,自動喚醒,wait可以直接用notify喚醒
sleep的類是Thread,wait的類是Object
8.notify()和 notifyAll()有什么區別?
notify()方法會喚醒對象等待池中的一個線程,進入鎖池;
notifyAll()方法會喚醒等待池中的所有線程,進入鎖池
9.線程的 run()和 start()有什么區別?
調用start()方法是用來啟動線程的,輪到該線程執行時,會自動調用run方法;
直接運行run方法無法達到啟動多線程的目的,相當于調用Thread對象中的run方法
一個線程的start方法只能調用一次,多次調用會拋出異常;而run方法可以多次調用
10.創建線程池有哪幾種方式?
主要使用Excutors提供的通用線程池創建方法,去創建不同配置的線程池
newCachedThreadPool();特點:用來處理大量短時間工作任務的線程池
newFixedThreadPool(int nThreads);特點:重用指定數目(nThreads)的線程
newSingleThreadExecutor();特點:工作線程數目限制為1
newSingleThreadScheduledExecutor()和newScheduledThreadPool(int corePoolSize)可以進行周期或定時性的工作調度
newWorkStealingPool(int parallelism);特點:JDK8以后才加入
11.線程池都有哪些狀態?
RUNNING:線程池被創建,可以接收新線程
SHUTDOWN:線程池被關閉,不接收新線程,但是可以處理已有的線程。通過調用shutdown()方法;
STOP:線程池停止,不接受新線程,中斷當前的線程,并且不會處理已有的線程。通過調用shutdownnow()方法;
TIDYING:線程池等待,當線程池處于SHUTDOWN或者STOP狀態,并且任務隊列為空且執行中任務為空則會轉變;
TERMINATED:線程池徹底終止,線程池在TIDYING狀態中執行完terminated()方法后就會轉變為此狀態。
12.線程池中 submit()和 execute()方法有什么區別?
execute() 參數 Runnable ;submit() 參數 (Runnable) 或 (Runnable 和 結果 T) 或 (Callable)
execute() 沒有返回值;而 submit() 有返回值
submit()的返回值Future調用get方法時,可以捕獲處理異常
13.在 java 程序中怎么保證多線程的運行安全?
JDK Atomic開頭的原子類、synchronized、LOCK,可以解決原子性問題
synchronized、volatile、LOCK,可以解決可見性問題
Happens-Before 規則可以解決有序性問題
14.多線程鎖的升級原理是什么?
鎖的級別:無鎖 => 偏向鎖 => 輕量級鎖 => 重量級鎖
無鎖:沒有對資源進行鎖定,所有線程都可以訪問,但是只有一個能修改成功,其他的線程會不斷嘗試,直至修改成功。
偏向鎖:對象的代碼一直被同一線程執行,不存在多個線程競爭,偏向鎖,指的就是偏向第一個加鎖線程,該線程不會主動釋放偏向鎖,只有當其他線程嘗試競爭偏向鎖時才會被釋放。
偏向鎖的撤銷,需要在某個時間點上沒有字節碼正在執行時,先暫停擁有偏向鎖的線程,然后判斷鎖對象是否處于被鎖定狀態。如果線程不處于活動狀態,則將對象頭設置成無鎖狀態,并撤銷偏向鎖;
如果線程處于活動狀態,升級為輕量級鎖的狀態。
輕量級鎖:輕量級鎖是指當鎖是偏向鎖的時候,被第二個線程 B 所訪問,此時偏向鎖就會升級為輕量級鎖,線程 B 會通過自旋的形式嘗試獲取鎖,線程不會阻塞,從而提高性能。當前只有一個等待線程,則該線程將通過自旋進行等待。但是當自旋超過一定的次數時,輕量級鎖便會升級為重量級鎖;當一個線程已持有鎖,另一個線程在自旋,而此時又有第三個線程來訪時,輕量級鎖也會升級為重量級鎖。
重量級鎖:指當有一個線程獲取鎖之后,其余所有等待獲取該鎖的線程都會處于阻塞狀態。
15.什么是死鎖?
死鎖是指兩個或兩個以上的進程在競爭資源的過程中造成的不可解堵塞。兩個線程都在互相等待。
16.怎么防止死鎖?
預防:資源一次性分配;可剝奪資源;資源有序分配;超時放棄
避免:銀行家算法;
檢測:為每個進程和每個資源建立唯一的ID,建立資源分配表和進程等待表
解除:剝奪資源;撤銷進程
17.ThreadLocal 是什么?有哪些使用場景?
ThreadLocal是線程本地存儲,在每個線程中都創建了一個ThreadLocalMap對象,每個線程可以訪問自己內部ThreadLocal對象內的value。
經典的使用場景是為每個線程分配一個JDBC連接的Connection,這樣就可以保證每個線程都在各自的Connection上進行數據庫的操作,不會出現A線程關了B線程的Connection,還有Session管理等問題。
18.說一下 synchronized 底層實現原理?
同步代碼塊是通過monitorenter和monitorexit指令獲取線程的執行權;
同步方法是通過加ACC_SYNCHRONIZED 標識實現線程的執行權的控制
19.synchronized 和 volatile 的區別是什么?
volatile本質是在告訴vm當前變量在寄存器(工作內存)中的值是不確定的,需要從主存中讀取;
synchronize則是鎖定當前變量,只有當前線程可以訪問該變量,其他線程被阻塞。
volatile僅能實現變量的修改可見性,不能保證原子性;synchronize可以保證變量的修改可見性和原子性。
volatile不會造成線程的阻塞;synchronize可能會造成線程的阻塞。
volatile標記的變量不會被編譯器優化,synchronize標記的變量可以被編譯器優化
20.synchronized 和 Lock 有什么區別?
synchronized是關鍵字,屬于jvm層面;Lock是具體類,是api層面的鎖;
synchronized無法獲取鎖的狀態,Lock可以判斷;
synchronized用于少量同步,Lock用于大量同步。
21.synchronized 和 ReentrantLock 區別是什么?
synchronized代碼執行結束后線程自動釋放對鎖的占用;Reentrantlock需要手動釋放鎖;
synchronized不可中斷,除非拋出異常或者執行完成;Reentrantlock可中斷;
synchronize非公平鎖;Reentrantlock默認非公平鎖,也可公平鎖;
ReentrantLock用來實現分組喚醒需要喚醒的線程,可以精確喚醒,而不是像synchronized要么隨機喚醒一個,要么喚醒全部線程。
22.說一下 atomic 的原理?
作用:多線程下將屬性設置為atomic可以保證讀取數據的一致性。
CAS(Compare And Swap),樂觀鎖的機制,先比較再交換,以實現原子性
23.理解樂觀鎖和悲觀鎖
樂觀鎖:認為每次去拿數據的時候別人不會修改,所以不會上鎖,但是每次要拿數據的時候都會先判斷數據是否被別人修改
悲觀鎖:認為每次去拿數據的時候別人都會修改,所以每次都會上鎖。
使用場景:樂觀鎖使用于多讀少寫的應用類型,這樣可以提高吞吐量;相反的情況則使用悲觀鎖
四、反射
1.什么是反射?
java反射機制是指在運行狀態中,對于任意一個類,都能夠知道這個類的所有屬性和方法,對于任意一個對象,都能夠調用它的任意一個方法和屬性,這種動態獲取的信息以及動態調用對象的方法的功能成為java的反射機制。
2.什么是 java 序列化?什么情況下需要序列化?
序列化:將java對象轉換成字節流的過程。
反序列化:將字節流轉換成java對象的過程。
當java對象需要在網絡上傳輸或者持久化存儲到文件中時,就需要對Java對象進行序列化處理。
序列化的實現:類實現Serializable接口。
3.動態代理是什么?有哪些應用?
在運行時,創建一個新的類,即創建動態代理,可以調用和擴展目標類的方法。動態代理的類是自動生成的。
應用:Spring的AOP,加事務,加權限,加日志
4.怎么實現動態代理?
基于jdk,需要實現InvocationHandler接口,重寫invoke方法。
基于cglib,需要jar包依賴;
基于javassist
五、對象克隆
1.為什么要使用克隆?
如果直接使用=給對象賦值的話,那么兩個對象其實指向的是同一個地址,其中一個值改變時,另一個也會隨之改變。
2.如何實現對象克隆?
1、實現Coloneable接口并重寫Object類中的clone()方法;
2、實現Serializable接口,通過對象的序列化和反序列化實現克隆,可以實現真正的深度克隆。
3.深克隆和淺克隆區別是什么?
深克隆:新舊對象不共享一個地址;
淺克隆:新舊對象共享一個地址,改變一個,另一個也會改變
六、Java Web
1.jsp 和 servlet 有什么區別?
Jsp:Java Server Page,是一種動態頁面技術,其根本是一個簡化的Servlet設計,用來封裝產生動態網頁的邏輯處理。
Servlet:服務器端的Java應用程序,具有獨立于平臺和協議的特性,可以生成動態的Web頁面。它擔當客戶請求與服務器響應的中間層。
相同點:jsp經編譯后就變成了Servlet,jsp本質就是servlet,jvm只能識別java的類,不能識別jsp代碼,web容器將jsp的代碼編譯成jvm能夠識別的java類。
2.jsp 有哪些內置對象?作用分別是什么?
request:用戶端請求(get/post)
response:網頁傳回用戶端的響應
pageContext:管理網頁的屬性
session:與請求有關的會話期
application servlet:正在執行的內容
out:用來傳送回應的輸出
config: servlet的架構部件
page JSP:網頁本身
exception:針對錯誤網頁,未捕捉的例外
3.說一下 jsp 的 4 種作用域?
application:在所有應用程序中有效
session:在當前會話中有效;
request:在當前請求中有效;
page:在當前頁面有效
4.session 和 cookie 有什么區別?
- 存儲位置不同
cookie的數據信息存放在客戶端瀏覽器上
session的數據信息存放在服務器上
- 存儲容量不同
單個cookie保存的數據<=4Kb,一個站點最多保存20個cookie
對于session來說沒有上限
- 存儲方式不同
cookie中只能保管ASCII字符串,并需要通過編碼方式存儲為Unicode字符或者二進制數據;
session中能夠存儲任何類型的數據
- 隱私策略不同
cookie對客戶端是可見的,所以它是不安全的;
session存儲在服務器上,對客戶端是透明的,不會信息泄露
- 有效期不同
可以通過設置cookie的屬性,使cookie長期有效;
session不能達到長期有效的結果
- 服務器壓力不同
cookie保存在客戶端,不占用服務器資源
session是保存在服務器的,如果并發訪問的用戶十分多,會產生很多的session,耗費大量的內存
- 瀏覽器支持不同
cookie是需要瀏覽器支持的,假如客戶端禁用了cookie,或者不支持cookie,則會話跟蹤會失效
session只能在本窗口以及子窗口有效,而cookie可以為本瀏覽器上的一切窗口有效
- 跨域支持不同
cookie支持跨域名訪問
session不支持跨域名訪問
5.說一下 session 的工作原理?
客戶端登錄完成之后,服務器會創建相應的session,session創建完成之后,會把session的id發送給客戶端,客戶端再存儲到瀏覽器中。這樣客戶端每次訪問服務器時,都會帶著sessionid,服務器拿到sessionid之后,在內存找到與之對應的session就可以正常工作了。
6.如果客戶端禁止 cookie,session 還能用嗎?
如果瀏覽器禁用了cookie,那么客戶端訪問服務端時無法攜帶sessionid,服務端無法識別用戶身份,便無法進行會話控制,session就會失效,但是可以通過其他辦法實現:
通過URL重寫,把sessionid作為參數追加的原URL中,后續的瀏覽器與服務器交互中攜帶session
服務器的返回數據中包含sessionid,瀏覽器發送請求時,攜帶sessionid參數
7.spring mvc 和 struts 的區別是什么?
攔截機制不同
Struts2是類級別的攔截,每次請求就會創建一個Action
SpringMVC是方法級別的攔截,一個方法對應一個Request上下文。
底層框架不同
Struts2采用Filter實現,SpringMVC采用Servlet實現
性能不同
Struts2需要加載所有的屬性值注入,SpringMVC實現了零配置,由于SpringMVC基于方法的攔截。
所以,SpringMVC開發效率和性能高于Struts2
配置方面
SpringMVC 和 Spring 是無縫的,從這個項目的管理和安全上也比Struts2高。
8.如何避免 sql 注入?
SQL注入是Web開發中最常見的一種安全漏洞,可以用它來從數據庫獲取敏感信息,進行數據庫的一系列非法操作。
校驗參數的數據格式是否合法
對進入數據庫的特殊字符進行轉義處理,或編碼轉換
預編譯SQL,參數化查詢方式,避免SQL拼接
發布前利用工具進行SQL注入檢測
9.什么是 XSS 攻擊,如何避免?
XSS(Cross Site Scripting)跨站腳本攻擊,它是Web程序中常見的漏洞。
原理:攻擊者往web頁面里插入惡意的HTML代碼,當用戶瀏覽該頁面時,嵌入其這個你的HTML代碼會被執行,從而達到惡意攻擊用戶的目的。
避免措施:
web頁面中可由用戶輸入的地方,對輸入的數據轉義、過濾處理
前端對HTML標簽屬性、css屬性賦值的地方進行校驗
后臺輸出頁面的時候,也需要對輸出內容進行轉義、過濾處理
10.什么是 CSRF 攻擊,如何避免?
CSRF(Cross-site request forgery),也被稱為one-click attack 或者 session riding,通常縮寫為CSRF或XSRF,
是一種挾制用戶在當前已登錄的Web應用程序上執行非本意的操作的攻擊方法。
預防措施:
驗證HTTP Referer字段
驗證碼
添加token驗證
盡量使用post,限制get
七、異常
1.throw 和 throws 的區別?
throw:表示方法內拋出某種異常對象,如果異常對象不是RuntimeException,則需要在方法聲明時加上該異常的拋出,即需要加上throws語句,或者在方法體內try catch異常,否則編譯會報錯;執行到throw語句則后面的語句塊不再執行
throws:方法的定義上使用此關鍵字表示這個方法可能拋出某種異常,需要由方法的調用者進行異常處理。
2.final、finally、finalize 有什么區別?
final:修飾類時表示不能被繼承;修飾方法時表示不能被重載;修飾變量時表示不能被修改。
finally:在異常處理時提供finally代碼塊來執行異常處理。
finalize:是方法名,java允許使用finalize()方法在垃圾收集器將對象從內存中清除之前做必要的清理工作。
3.try-catch-finally 中哪個部分可以省略?
catch 和 finally可以被省略其中一個,finally代碼塊是無論是否捕捉到異常,都會執行finally代碼塊的邏輯。
4.try-catch-finally 中,如果 catch 中 return 了,finally 還會執行嗎?
捕獲到異常后,不會直接返回,會先執行完finally代碼塊的語句繼續執行catch代碼塊中的return。
5.常見的異常類有哪些?
NullPointerException、SQLException、IndexOutOfBoundException、NumberFormatException、FileNotFoundException
IOException、IllegalArgumentException、NoSuchMethodException
八、網絡
1.http 響應碼 301 和 302 代表的是什么?有什么區別?
301:Moved Permanently ——被請求的資源已經永久移動到新位置
302:Found——被請求URL臨時轉移到新的URL
其他的響應碼:
信息響應(100-199)、成功響應(200-299)、重定向(300-399)、客戶端錯誤(400-499)、服務器錯誤(500-599)
2.forward 和 redirect 的區別?
redirect是客戶端發起的請求;forward是服務端發起的請求
redirect瀏覽器顯示被請求的URL;forward瀏覽器地址不顯示被請求的URL
redirect重新開始一個request,原頁面的request生命周期結束;
forward另一個連接的時候,request變量是在其生命周期內的。
redirect實質上是兩次HTTP請求;forward是一次請求
3.簡述 tcp 和 udp的區別?
TCP是面向連接的,TCP提供可靠的服務,通過TCP連接傳輸的數據不會丟失,沒有重復,并且按順序到達。
UDP是無連接的,沒有可靠性,但是速度快,操作簡單,要求系統資源較少,可以實現廣播發送。
TCP是面向字節流的,UDP是面向報文的;TCP是全雙工的可靠信道,UDP是不可靠信道
4.tcp 為什么要三次握手,兩次不行嗎?為什么?
兩次握手只能保證單向連接是暢通的。
只有經過第三次握手,才能確保雙向都可以收到對方發送的數據
5.說一下 tcp 粘包是怎么產生的?
TCP粘包:發送方發送的多個數據包,到接收方緩沖區首尾相連,粘成一包,被接收
產生原因:TCP為提高傳輸效率,發送方往往要收集到足夠多的數據后才發送一包數據。若連續幾次發送的數據都很少,通常TCP會根據優化算法把這些數據合成一包后一次發送出去,這樣接收方就收到了粘包數據。
接收方原因:接收方引起的粘包是由于接收方用戶進程不及時接收數據,從而導致粘包現象。這是因為接收方先把收到的數據放在系統接收緩沖區,用戶進程從該緩沖區取數據,若下一包數據到達時前一包數據尚未被用戶進程取走,則下一包數據放到系統接收緩沖區時就接到前一包數據之后,而用戶進程根據預先設定的緩沖區大小從系統接收緩沖區取數據,這樣就一次取到了多包數據。
6.OSI 的七層模型都有哪些?
OSI(Open System Interconnection Reference Model)開放式系統互聯網通信
應用層、表達層、會話層、傳輸層、網絡層、數據鏈路層、物理層
7.get 和 post 請求有哪些區別?
get是從服務器上獲取數據;post是向服務器傳送數據
get請求通過URL直接請求數據,數據信息可以在URL中看到;post請求是放在請求頭中的,用戶看不到;
get傳送的數據量小,有限制,不能大于2kb,post傳送的數據可以沒有限制
get安全性比較低,post相對較安全
8.如何實現跨域?
使用JSONP,利用了script不受同源策略的限制;
代理跨域請求;
HTML5 postMessage方法;
修改document.domain跨子域;
基于HTML5 websocket協議
9.說一下 JSONP 實現原理?
同源:同協議、同主機、同端口號
json是一種數據格式,jsonp是一種數據調用的方式,帶callback的json就是jsonp。
首先在客戶端注冊一個callback,然后把callback的名字傳給服務器,此時,服務器先生成json數據,然后以JavaScript語法的方式,生成function,返回給客戶端,客戶端解析script,并執行callback函數。
簡單的說,就是利用script標簽沒有跨域限制的"漏洞"來達到與第三方通訊的目的。
10.單工、半雙工、全雙工
單工:只支持數據在一個方向上傳輸;
半雙工:允許數據在兩個方向上傳輸,但在某一時刻,只允許數據在同一個方向上傳輸;
全雙工:允許數據可以同時接收和發送信息,實現雙向通信
九、設計模式
1.說一下你熟悉的設計模式?
單例模式:懶漢式(先聲明變量,等到實際用到時再創建對象)餓漢式(直接創建對象)
工廠模式:工廠類可以根據條件生成不同的子類實例,這些子類有一個公共的抽象父類并且實現了相同的方法,但是這些方法針對不同的數據進行了不同的操作。
適配器模式:把一個類的接口變換成客戶端所期待的另一種接口,從而使原本因接口不匹配而無法在一起使用的類能夠在一起工作。
模板方法模式:提供一個抽象類,將部分邏輯以具體方法或構造器的形式實現,然后聲明一些抽象方法來迫使子類實現剩余的邏輯,不同的子類可以從不同的方式實現這些抽象方法,從而實現不同的業務邏輯。
2.簡單工廠和抽象工廠有什么區別?
簡單工廠
由一個工廠對象創建產品實例,簡單工廠模式的工廠類一般是使用靜態方法,通過不同的參數創建不同的對象的實例。可以生產結構中的任意產品,不能增加新的產品。
抽象工廠
提供一個創建一系列相關或相互依賴對象的接口,而無需制定他們具體的類,生產多個系列產品,生產不同產品族的全部產品,不能新增產品,可以新增產品族。
十、Spring/Spring MVC
1.為什么要使用 spring?
方便解耦,便于開發
支持aop編程
聲明式事務的支持
方便程序的測試
方便集成各種優秀的框架
降低JavaEE API的使用難度
2.解釋一下什么是 aop?
AOP(Aspect Oriented Programming)面向切面編程
通過預編譯方式和運行期動態代理實現程序功能的統一維護的一種技術。
通俗的解釋:在運行時,動態的將代碼切入到類的指定方法、指定位置的編程思想就是面向切面的編程。
3.解釋一下什么是 ioc?
IOC(Inversion Of Control)控制反轉
它是一種設計思想,在java開發中,將設計好的對象交給容器控制,而不是顯示地用代碼進行對象的創建。
把創建和查找依賴對象的控制權交給IOC容器,由IOC容器進行注入、組合對象,這樣對象與對象之間是松耦合,便于測試,功能可復用,使得程序的整個體系結構可維護,靈活性、擴展性變高。
4.spring 有哪些主要模塊?
Spring Core
框架的基礎部分,提供IOC容器,對bean進行管理。
Spring Context
基于bean,提供上下文信息,擴展出JNDI、EJB、電子郵件、國際化、校驗和調度等功能。
Spring DAO
提供了JDBC的抽象層,它可消除冗長的JDBC編碼和解析數據庫廠商特有的錯誤代碼,還提供了聲明性事務管理方法
Spring ORM
提供了常用的“對象/關系”映射APIs的集成層。其中包括JPA、JDO、hibernate、Mybatis等。
Spring AOP
提供了面向切面編程。
Spring Web
提供了基礎的Web開發的上下文信息,可與其他Web進行集成。
Spring Web MVC
提供了Web應用的Model-View-Controller 全功能實現。
5.spring 常用的注入方式有哪些?
構造方法注入、setter注入、基于注解的注入
6.spring 中的 bean 是線程安全的嗎?
Spring 中的Bean本身不具備線程安全的特性
7.spring 支持幾種 bean 的作用域?
singleton:單例,默認作用域
prototype:原型,每次創建一個新對象
request:請求,每次Http請求創建一個新對象,適用于WebApplicationContext環境下
session:會話,同一個會話共享一個實例,不同會話使用不同的實例
global-session:全局會話,所有會話共享一個實例
8.spring 自動裝配 bean 有哪些方式?
default:默認的方式和no方式一樣
no:不自動裝配,需要使用<ref/>節點或參數
byName:根據名稱進行裝配
byType:根據類型進行裝配
constructor:根據構造函數進行裝配
9.spring 事務實現方式有哪些?
編程式事務管理,需要在代碼中調用beginTransaction()、commit()、rolback()等事務管理相關的方法
基于TransactionProxyFactoryBean的聲明式事務管理
基于@Transactional的聲明式事務管理
基于Aspectj AOP配置事務
10.說一下 spring 的事務隔離?
事務產生的問題
名稱?? ?數據的狀態?? ?實際行為?? ?產生原因
臟讀?? ?未提交?? ?打算提交但是數據回滾了,讀取了提交的數據?? ?數據的讀取
不可重復讀?? ?已提交?? ?讀取了修改前的數據?? ?數據的修改
幻讀?? ?已提交?? ?讀取了插入前的數據?? ?
數據的插入事務隔離級別
名稱結果?? ?臟讀?? ?不可重復讀?? ?幻讀
Read UnCommitted(讀未提交)?? ?什么都不解決?? ?√?? ?√?? ?√
Read Committed(讀提交)?? ?解決了臟讀的問題?? ?–?? ?√?? ?√
Repeatable Read(重復讀)?? ?解決了不可重復讀?? ?–?? ?–?? ?√
Serializable(序列化)?? ?解決所有問題?? ?–?? ?–?? ?–
11.說一下 spring mvc 運行流程?
用戶向服務器發送請求,請求被 Spring 前端控制 Servelt DispatcherServlet 捕獲。(捕獲)
DispatcherServlet對請求 URL進行解析,得到請求資源標識符(URI)。然后根據該 ?URI,調用 HandlerMapping獲得該Handler配置的所有相關的對象(包括 ?Handler對象以及 ? Handler對象對應的攔截器),最后以 HandlerExecutionChain對象的形式返回;(查找 ? handler)
DispatcherServlet ?根據獲得的 Handler,選擇一個合適的 ?HandlerAdapter。提取Request 中的模型數據,填充 Handler 入參,開始執行 Handler(Controller), Handler執行完成后,向 DispatcherServlet 返回一個 ModelAndView 對象(執行 handler)
DispatcherServlet ?根據返回的 ModelAndView,選擇一個適合的 ViewResolver(必須是已經注冊到 Spring 容器中的 ViewResolver) (選擇 ViewResolver)
通過 ViewResolver 結合 Model 和 View,來渲染視圖,DispatcherServlet 將渲染結果返回給客戶端。(渲染返回)
總結:核心控制器捕獲請求、查找Handler、執行Handler、選擇ViewResolver,通過ViewResolver渲染視圖并返回
12.spring mvc 有哪些組件?
前端控制器(DispatcherServlet)
處理器映射器(HandlerMapping)
處理器適配器(HandlerAdapter)
攔截器(HandlerInterceptor)
視圖解析器(ViewResolver)
文件上傳處理器(MultipartResolver)
異常處理器(HandlerExceptionResolver)
消息轉換器(HttpMessageConverter)
...
13.@RequestMapping 的作用是什么?
@RequestMapping是一個用來處理請求地址映射的注解,可用于類或者方法上,用來標識 http 請求地址與 Controller 類的方法之間的映射。
14.@Autowired 的作用是什么?
@Autowired是一個注解,他可以對類成員變量、方法及構造函數進行標注,讓spring完成bean自動裝配的工作。
十一、Spring Boot/Spring Cloud
1.什么是 spring boot?
SpringBoot是Spring開源框架下的子項目,是Spring的一站式解決方案,主要是簡化了spring的使用難度,降低了對配置文件的要求,使得開發人員更容易上手。
2.為什么要用 spring boot?
簡化了Spring配置文件
沒有代碼和XML文件的生成
內置tomcat
能夠獨立運行
簡化監控
3.spring boot 核心配置文件是什么?
SpringBoot有兩種類型的配置文件,application和Bootstrap文件
4.spring boot 配置文件有哪幾種類型?它們有什么區別?
SpringBoot會自動加載classpath下的這兩個文件,文件格式為properties或yml格式
*.properties 是 key = value 的形式
*.yml 是 key : value 的形式
Bootstrap配置文件是系統級別的,用來加載外部配置,也可以用來定義系統不會變化的屬性,.bootstrap文件的加載要先于application文件
5.spring boot 有哪些方式可以實現熱部署?
Spring Loaded
spring-boot-devtools
JRebel插件
使用調試模式Debug實現熱部署
模板熱部署
6.jpa 和 hibernate 有什么區別?
JPA(Java Persistence API)
Hibernate是JPA規范的一個實現。
hibernate有JPA沒有的特性
hibernate的效率更高
JPA有更好的移植性,通用性
7.什么是 spring cloud?
spring cloud是在SpringBoot基礎上構建的,用于快速構建分布式系統的通用模式的工具集。
SpringCloud是一個微服務框架,提供全套的分布式系統解決方案。
8.spring cloud 斷路器的作用是什么?
當一個服務調用另一個服務,由于網絡原因或者自身原因出現問題時,調用者就會等待被調用者的響應,當更多的服務請求到這些資源時,導致更多的請求等待,這樣就會發生連鎖效應,斷路器就是為了解決這個問題。
全開:
一定時間內,達到一定的次數無法調用,并且多次檢測沒有恢復的跡象,斷路器完全打開,那么下次請求就不會請求到該服務
半開:
短時間內有恢復跡象,斷路器會將部分請求發給該服務,當能正常調用時,斷路器關閉。
關閉:
當服務一直處于正常狀態,能正常調用,斷路器關閉
9.spring cloud 的核心組件有哪些?
服務發現——Netflix Eureka
客戶端負載均衡——Netflix Ribbon
斷路器——Netflix Hystrix
服務網關——Netflix Zuul
分布式配置——Spring Cloud Config
10.SpringBoot的啟動流程
主要分為兩個步驟:
1、創建SpringApplication對象。
2、調用SpringApplication對象的run()方法實現啟動,并且返回當前容器的上下文。
詳細步驟:
一、創建SpringApplication對象,SpringBoot容器的初始化操作。
二、獲取當前應用的啟動類型。
三、setInitializers讀取springboot包下的META-INF/spring.factories獲取到對應的ApplicationContextInitializer裝配到集合中
四、setListeners讀取springboot包下面的META-INF/spring.factories獲取到對應的ApplicationListener裝配到集合中
五、mainApplicationClass獲取當前運行的主函數
六、調用SpringApplication的run()方法實現啟動
七、stopWatch.start();開始記錄項目的啟動時間
八、getRunListeners(args);讀取META-INF/spring.factories,將SpringApplicationRunListeners類型存入帶集合中
九、listeners.starting();循環調用starting()方法
十、ConfigurableEnvironment environment = prepareEnvironment(listeners, applicationArguments);
listeners.environmentPrepared(environment);循環讀取配置文件到springboot容器中,因為配置文件可以自定義,就會存在多個。
十一、Banner printedBanner = printBanner(environment);打印Springboot啟動標志
十二、context = createApplicationContext();創建springboot上下文
十三、prepareContext(context, environment, listeners, applicationArguments, printedBanner);為springboot上下文設置environment屬性。
十四、refreshContext(context);刷新上下文
十五、開始創建Tomcat容器
十六、開始加載SpringMVC
十七、afterRefresh(context,applicationArguments);定義一個空的模板給其他子類實現重寫
十八、listeners.started(context);使用廣播和回調機制通知監聽器springboot容器啟動成功
十九、listeners.running(context);使用廣播和回調機制通知監聽器springboot容器已成功running
二十、最后返回當前的上下文
十二、Hibernate
1.為什么要使用 hibernate?
對JDBC訪問數據庫的代碼做了封裝,大大簡化了數據訪問層繁瑣的重復性代碼
基于jdbc的主流持久化框架,是一個優秀的ORM實現,很大程度的簡化了dao層的編碼工作
使用java的反射機制
性能好,是一個輕量級框架,映射靈活,支持很多關系型數據庫,從一對一到多對多的各種復雜關系
2.什么是 ORM 框架?
ORM(Object Relation Mapping)對象關系映射
通過類與數據庫表的映射關系,將對象持久化到數據庫中
常見的ORM框架有Hibernate、Mybatis、EclipseLink、JFinal
3.hibernate 中如何在控制臺查看打印的 sql 語句?
在hibernate的配置文件中添加配置:hibernate.show_sql=true
4.hibernate 有幾種查詢方式?
HQL,QBC(Query By Criteria),原生SQL查詢
5.hibernate 實體類可以被定義為 final 嗎?
可以,但是這種做法不好。因為Hibernate會使用代理模式在延遲關聯的情況下提高性能,如果把實體類定義成final類之后,因為java不允許對final類進行擴展,所以hibernate就無法再使用代理了,從而影響性能。
6.在 hibernate 中使用 Integer 和 int 做映射有什么區別?
如果使用基本類型變量int,如果數據庫中對應的存儲數據是null,使用PO類進行獲取數據會出現類型轉換異常。
如果使用你的是對象類型Integer則不會報錯。
7.hibernate 是如何工作的?
讀取并解析配置
讀取并解析映射信息
創建Session Factory
打開Session
創建事務Transaction
持久化操作
提交事務
關閉Session
關閉SessionFactory
8.get()和 load()的區別?
get:get方法被調用時會立即發出SQL語句
load:當調用load方法的時候會返回一個目標對象的代理對象,在這個代理對象中只存儲了目標對象的ID值,只有當調用除ID值以外的屬性值的時候才會發出SQL查詢。
9.說一下 hibernate 的緩存機制?
Hibernate中的緩存分為一級緩存和二級緩存
一級緩存就是Session級別的緩存,在事務范圍內有效,內置的不能被卸載。
二級緩存是SessionFactory級別的緩存,從應用啟動到應用結束有效,是可選的。默認沒有二級緩存,需要手動開啟。
10.hibernate 對象有哪些狀態?
Transient(瞬時):對象剛new出來,還沒設ID,設了其他值
Persistent(持久):調用了save()、saveOrUpdate(),就變成Persistent
Detached(托管):當session close()完之后,變成Detached
11.在 hibernate 中 getCurrentSession 和 openSession 的區別是什么?
openSession:每次使用都是打開一個新的對象,而且使用完需要調用close方法關閉session
getCurrenctSession:如果已經有session,就使用舊的,如果沒有再打開新的。
一般情況下都是使用getCurrenctSession
12.hibernate 實體類必須要有無參構造函數嗎?為什么?
必須,因為hibernate框架會調用這個默認構造方法來構造實例對象。
如果沒有提供任何構造方法,虛擬機會自動提供默認構造方法,如果開發人員提供了其他有參數的構造方法的話,虛擬機就不再提供默認構造方法,這時必須手動把無參構造器寫出來。
十三、Mybatis
1.mybatis 中 #{}和 ${}的區別是什么?
#{}是預編譯處理,${}是字符串替換
使用#{}可以預防SQL注入
2.mybatis 有幾種分頁方式?
數組分頁
SQL分頁
攔截器分頁
RowBounds分頁
3.RowBounds 是一次性查詢全部結果嗎?為什么?
不是。Mybatis是JDBC的封裝,在jdbc驅動中有一個Fetch Size的配置,它規定了每次最多從數據庫查詢多少條數據,假如要查詢更多的數據,它會在執行next的時候,去查詢更多的數據。這樣可以有效的防止內存溢出。
4.mybatis 邏輯分頁和物理分頁的區別是什么?
邏輯分頁是一次性查詢很多數據,然后再在結果中檢索分頁的數據,這樣做的弊端是需要消耗大量的內存,有內存溢出的風險,對數據庫壓力較大。
物理分頁是從數據庫查詢指定條數的數據,彌補了一次性查出所有數據的種種缺點。
5.mybatis 是否支持延遲加載?延遲加載的原理是什么?
支持。設置lazyLoadingEnable=true即可
延遲加載的原理是調用的時候觸發加載,而不是在初始化的時候就加載信息。
6.說一下 mybatis 的一級緩存和二級緩存?
一級緩存:一級緩存的作用域是一個sqlsession對象,第一次查詢數據時會保存到sqlsession對象中,第二次如果查詢相同的數據,則直接從sqlsession獲取,直接獲取的前提是這期間這個對象中的數據沒有改變,即增刪改操作;反之,若有改變,則會自動清除sqlsession緩存,重新進行查詢,這并不代表我們關閉了sqlsession。
二級緩存:二級緩存是多個sqlsession共享的,是sqlsession factory 級別的,根據 mapper 的 namespace 劃分區域 的,相同 namespace 的 mapper 查詢的數據緩存在同一個區域,如果使用 mapper 代理方法每個 mapper 的 namespace 都不同,此時可以理解為二級緩存區域是根據 mapper 劃分。每次查詢會先從緩存區域查找,如果找不到則從數據庫查詢,并將查詢到數據寫入緩存。Mybatis 內部存儲緩存使用一個 HashMap,key 為 hashCode+sqlId+Sql 語句。value 為從查詢出來映射生成的 java 對象。sqlSession 執行 insert、update、delete 等操作 commit 提交后會清空緩存區域,防止臟讀數據。
緩存更新機制:當某一個作用域(一級緩存Session/二級緩存Mapper)進行了C/U/D操作后,默認該作用域下所有select中的緩存將被clear。
7.mybatis 和 hibernate 的區別有哪些?
Mybatis入門比較簡單,使用門檻也更低
SQL直接優化上,Mybatis要比Hibernate方便
Hibernate數據庫移植性遠大于Mybatis
緩存機制上,hibernate要比mybatis更好一些
8.mybatis 有哪些執行器(Executor)?
SimpleExecutor:每執行一次update或select,就開啟一個Statement對象,用完立刻關閉Statement對象。
ReuseExecutor:執行update或select,以sql作為key查找Statement對象,存在就使用,不存在就創建,用完后,不關閉Statement對象,而是放置于Map內,供下一次使用。簡言之,就是重復使用Statement對象。
BatchExecutor:執行update(沒有select,JDBC批處理不支持select),將所有sql都添加到批處理中(addBatch()),等待統一執行(executeBatch()),它緩存了多個Statement對象,每個Statement對象都是addBatch()完畢后,等待逐一執行executeBatch()批處理。與JDBC批處理相同。
9.mybatis 分頁插件的實現原理是什么?
分頁插件的基本原理是使用Mybatis提供的插件接口,實現自定義插件,在插件的攔截方法內攔截待執行的sql,然后重寫sql,根據dialect方言,添加對應的物理分頁語句和物理分頁參數。
10.mybatis 如何編寫一個自定義插件?
Mybatis自定義插件主要借助Mybatis四大對象:
? ?(Executor、StatementHandler 、ParameterHandler 、ResultSetHandler)進行攔截?Executor:攔截執行器的方法(log記錄)?
StatementHandler:攔截Sql語法構建的處理?
ParameterHandler:攔截參數的處理?
ResultSetHandler:攔截結果集的處理
十四、RabbitMQ
1.rabbitmq 的使用場景有哪些?
跨系統的異步通信,所有需要異步交互的地方都可以使消息隊列
多個應用之間的耦合
應用內的同步變異步
消息驅動的架構
跨局域網,甚至跨城市的通訊
2.rabbitmq 有哪些重要的角色?
生產者:消息的創建者,負責創建和推送消息到消息服務器
消費者:消息的接收方,用于處理數據和確認消息
代理:RabbitMQ本身,本身不生產消息,只是扮演“快遞員”的角色
3.rabbitmq 有哪些重要的組件?
ConnectionFactory(連接管理器):應用程序與RabbitMQ之間建立連接的管理器,程序代碼中使用。
Chanel(信道):消息推送使用的通道。
Exchange(交換器):用于接收、分配消息。
Queue(隊列):用于存儲生產者的消息。
RoutingKey(路由鍵):用于把生產者的數據分配到交換器上。
BindingKey(綁定鍵):用于把交換器的消息綁定到隊列上。
4.rabbitmq 中 vhost 的作用是什么?
vhost 可以理解為虛擬 broker ,即 mini-RabbitMQ server。其內部均含有獨立的 queue、exchange 和 binding 等,但最最重要的是,其擁有獨立的權限系統,可以做到 vhost 范圍的用戶控制。當然,從 RabbitMQ 的全局角度,vhost 可以作為不同權限隔離的手段(一個典型的例子就是不同的應用可以跑在不同的 vhost 中)。
5.rabbitmq 的消息是怎么發送的?
首先客戶端必須連接到 RabbitMQ 服務器才能發布和消費消息,客戶端和 rabbit server 之間會創建一個 tcp 連接,一旦 tcp 打開并通過了認證(認證就是你發送給 rabbit 服務器的用戶名和密碼),你的客戶端和 RabbitMQ 就創建了一條 amqp 信道(channel),信道是創建在“真實” tcp 上的虛擬連接,amqp 命令都是通過信道發送出去的,每個信道都會有一個唯一的 id,不論是發布消息,訂閱隊列都是通過這個信道完成的。
6.rabbitmq 怎么保證消息的穩定性?
提供了事務的功能
通過將channel設置為confirm(確認)模式
7.rabbitmq 怎么避免消息丟失?
消息持久化
ACK確認機制
設置集群鏡像模式
消息補償機制
8.要保證消息持久化成功的條件有哪些?
聲明隊列必須設置持久化durable設置為true
消息推送投遞模式必須設置持久化,deliveryMode設置為2(持久)
消息已經到達持久化交換器
消息已經到達持久化隊列
9.rabbitmq 持久化有什么缺點?
缺點是降低了服務器的吞吐量,因為使用的是磁盤而非內存存儲,從而降低了吞吐量。
可盡量使用ssd硬盤來緩解吞吐量的問題。
10.rabbitmq 有幾種廣播類型?
fanout::所有bind到此exchange的queue都可以接收消息(純廣播,綁定到RabbitMQ的接收者都能收到消息);
direct::通過routingKey和exchange決定的那個唯一的queue可以接收消息;
topic:所有符合routingKey(此時可以是一個表達式)的routingKey所bind的queue可以接收消息
11.rabbitmq 怎么實現延遲消息隊列?
消息過期后進入死信交換器,再由交換器轉發到延遲消費隊列,實現延遲功能
使用RabbitMQ-delayed-message-exchange 插件實現延遲功能。
12.rabbitmq 集群有什么用?
高可用:某個服務器出現問題,整個RabbitMQ還可以繼續使用
高容量:集群可以承載更多的消息量
13.rabbitmq 節點的類型有哪些?
磁盤節點:消息會存儲到磁盤
內存節點:消息都存儲在內存中,重啟服務器消息會丟失,但性能要高于磁盤類型
14.rabbitmq 集群搭建需要注意哪些問題?
各節點之間使用“–link”連接,此屬性不能忽略。
各節點使用的 erlang cookie 值必須相同,此值相當于“秘鑰”的功能,用于各節點的認證。
整個集群中必須包含一個磁盤節點。
15.rabbitmq 每個節點是其他節點的完整拷貝嗎?為什么?
不是,原因有以下兩個:
存儲空間的考慮:如果每個節點都擁有所有隊列的完全拷貝,這樣新增節點不但沒有新增存儲空間,反而增加了更多的冗余數據;
性能的考慮:如果每條消息都需要完整拷貝到每一個集群節點,那新增節點并沒有提升處理消息的能力,最多是保持和單節點相同的性能甚至是更糟。
16.rabbitmq 集群中唯一一個磁盤節點崩潰了會發生什么情況?
不能創建隊列
不能創建交換器
不能創建綁定
不能添加用戶
不能更改權限
不能添加和刪除集群節點
唯一磁盤節點崩潰了,集群是可以保持運行的,但是不能更改任何東西。
17.rabbitmq 對集群節點停止順序有要求嗎?
RabbitMQ 對集群的停止的順序是有要求的,應該先關閉內存節點,最后再關閉磁盤節點。如果順序恰好相反的話,可能會造成消息的丟失。
十五、Kafka
1.kafka 可以脫離 zookeeper 單獨使用嗎?為什么?
kafka不能脫離zookper單獨使用,因為kafka使用zookper管理和協調kafka的節點服務器。
2.kafka 有幾種數據保留的策略?
按照過期時間保留;按照存儲的消息大小保留
?3.kafka 同時設置了 7 天和 10G 清除數據,到第五天的時候消息達到了 10G,這個時候 kafka 將如何處理?
執行數據清除工作,時間和大小不論哪個滿足條件,都會清空數據。
4.什么情況會導致 kafka 運行變慢?
CPU性能瓶頸
磁盤讀寫瓶頸
網絡瓶頸
5.使用 kafka 集群需要注意什么?
集群的數量不是越多越好,最好不要超過 7 個,因為節點越多,消息復制需要的時間就越長,整個群組的吞吐量就越低。
集群數量最好是單數,因為超過一半故障集群就不能用了,設置為單數容錯率更高。
十六、Zookeeper
1.zookeeper 是什么?
zookper是一個分布式的,開放源碼的分布式應用程序協調服務。是 google chubby 的開源實現,是 hadoop 和 hbase 的重要組件。它是一個為分布式應用提供一致性服務的軟件,提供的功能包括:配置維護、域名服務、分布式同步、組服務等。
2.zookeeper 都有哪些功能?
集群管理:監控節點存活狀態、運行請求等。
主節點選舉:主節點掛掉了之后可以從備用的節點開始新一輪選主,主節點選舉說的就是這個選舉的過程,使用 zookeeper 可以協助完成這個過程。
分布式鎖:zookeeper 提供兩種鎖:獨占鎖、共享鎖。獨占鎖即一次只能有一個線程使用資源,共享鎖是讀鎖共享,讀寫互斥,即可以有多線線程同時讀同一個資源,如果要使用寫鎖也只能有一個線程使用。zookeeper可以對分布式鎖進行控制。
命名服務:在分布式系統中,通過使用命名服務,客戶端應用能夠根據指定名字來獲取資源或服務的地址,提供者等信息。
3.zookeeper 有幾種部署模式?
單機部署:一臺機器上運行
集群部署:多臺機器運行
偽集群部署:一臺機器啟動多個zookper實例運行
4.zookeeper 怎么保證主從節點的狀態同步?
zookeeper 的核心是原子廣播,這個機制保證了各個 server 之間的同步。實現這個機制的協議叫做 zab 協議。 zab 協議有兩種模式,分別是恢復模式(選主)和廣播模式(同步)。當服務啟動或者在領導者崩潰后,zab 就進入了恢復模式,當領導者被選舉出來,且大多數 server 完成了和 leader 的狀態同步以后,恢復模式就結束了。狀態同步保證了 leader 和 server 具有相同的系統狀態。
5.集群中為什么要有主節點?
在分布式環境中,有些業務邏輯只需要集群中的某一臺機器進行執行,其他的機器可以共享這個結果,這樣可以大大減少重復計算,提高性能,所以就需要主節點。
6.集群中有 3 臺服務器,其中一個節點宕機,這個時候 zookeeper 還可以使用嗎?
可以繼續使用,單數服務器只要沒超過一半的服務器宕機就可以繼續使用。
7.說一下 zookeeper 的通知機制?
客戶端會對某個 znode 建立一個 watcher 事件,當該 znode 發生變化時,這些客戶端會收到 zookeeper 的通知,然后客戶端可以根據 znode 變化來做出業務上的改變。
十七、MySql
1.數據庫的三范式是什么?
第一范式:強調的是列的原子性,即數據庫表的每一列都是不可分割的原子數據項
第二范式:要求實體的屬性完全依賴于主關鍵字,所謂完全依賴是指不能存在僅依賴主關鍵字一部分的屬性。
第三范式:任何非主屬性不依賴于其他非主屬性
2.一張自增表里面總共有 7 條數據,刪除了最后 2 條數據,重啟 mysql 數據庫,又插入了一條數據,此時 id 是幾?
表類型如果是MyISAM,那ID就是8
表類型如果是InnoDB,那ID就是6
3.如何獲取當前數據庫版本?
select version()
4.說一下 ACID 是什么?
Atomicity(原子性):一個事務(transaction)中的所有操作,或者全部完成,或者全部不完成,不會結束在中間某個環節。事務在執行過程中發生錯誤,會被恢復(Rollback)到事務開始前的狀態,就像這個事務從來沒有執行過一樣。即,事務不可分割、不可約簡。
Consistency(一致性):在事務開始之前和事務結束以后,數據庫的完整性沒有被破壞。這表示寫入的資料必須完全符合所有的預設約束、觸發器、級聯回滾等。
Isolation(隔離性):數據庫允許多個并發事務同時對其數據進行讀寫和修改的能力,隔離性可以防止多個事務并發執行時由于交叉執行而導致數據的不一致。事務隔離分為不同級別,包括讀未提交(Read uncommitted)、讀提交(read committed)、可重復讀(repeatable read)和串行化(Serializable)。
Durability(持久性):事務處理結束后,對數據的修改就是永久的,即便系統故障也不會丟失。
5.char 和 varchar 的區別是什么?
char(n) :固定長度類型。優點:效率高;缺點:占用空間;
varchar(n) :可變長度,存儲的值是每個值占用的字節再加上一個用來記錄其長度的字節的長度。
所以,從空間上考慮 varcahr 比較合適;從效率上考慮 char 比較合適,二者使用需要權衡。
6.float 和 double 的區別是什么?
float 最多可以存儲 8 位的十進制數,并在內存中占 4 字節。
double 最可可以存儲 16 位的十進制數,并在內存中占 8 字節。
7.mysql 的內連接、左連接、右連接有什么區別?
內連接是把匹配的關聯數據顯示出來;
左連接是左邊的表全部顯示出來,右邊的表顯示出符合條件的數據,如果沒有就顯示為NULL
右連接正好相反。
8.mysql 索引是怎么實現的?
索引是滿足某種特定查找算法的數據結構,而這些數據結構會以某種方式指向數據,從而實現高效查找數據。
目前主流的數據庫引擎的索引都是 B+ 樹實現的,B+ 樹的搜索效率,可以到達二分法的性能,找到數據區域之后就找到了完整的數據結構了,所有索引的性能也是更好的。
9.怎么驗證 mysql 的索引是否滿足需求?
explain select * from table where column=''
使用 explain 查看 SQL 是如何執行查詢語句的,從而分析你的索引是否滿足需求。
10.說一下數據庫的事務隔離?
MySQL 的事務隔離是在 MySQL. ini 配置文件里添加的,在文件的最后添加:transaction-isolation = REPEATABLE-READ
可用的配置值:READ-UNCOMMITTED、READ-COMMITTED、REPEATABLE-READ、SERIALIZABLE。
READ-UNCOMMITTED:未提交讀,最低隔離級別、事務未提交前,就可被其他事務讀取(會出現幻讀、臟讀、不可重復讀)。
READ-COMMITTED:提交讀,一個事務提交后才能被其他事務讀取到(會造成幻讀、不可重復讀)。
REPEATABLE-READ:可重復讀,默認級別,保證多次讀取同一個數據時,其值都和事務開始時候的內容是一致,禁止讀取到別的事務未提交的數據(會造成幻讀)。
SERIALIZABLE:序列化,代價最高最可靠的隔離級別,該隔離級別能防止臟讀、不可重復讀、幻讀。
臟讀 :表示一個事務能夠讀取另一個事務中還未提交的數據。比如,某個事務嘗試插入記錄 A,此時該事務還未提交,然后另一個事務嘗試讀取到了記錄 A。
不可重復讀 :是指在一個事務內,多次讀同一數據。
幻讀 :指同一個事務內多次查詢返回的結果集不一樣。比如同一個事務 A 第一次查詢時候有 n 條記錄,但是第二次同等條件下查詢卻有 n+1 條記錄,這就好像產生了幻覺。發生幻讀的原因也是另外一個事務新增或者刪除或者修改了第一個事務結果集里面的數據,同一個記錄的數據內容被修改了,所有數據行的記錄就變多或者變少了。
11.說一下 mysql 常用的引擎?
Mysql在V5.1之前默認存儲引擎是MyISAM;在此之后默認存儲引擎是InnoDB
InnoDB 引擎:
? ? ? ? 提供了ACID事務的支持;
? ? ? ? 提供了行級鎖和外鍵的約束;
? ? ? ? 不支持全文搜索,啟動較慢;
? ? ? ? 不會保存表的行數,執行 select count(*) from table 指令時,需要進行掃描全表;
? ? ? ? 效率高,在高并發場景下使用。
MyIASM 引擎:
? ? ? ? 不提供ACID事務的支持;
? ? ? ? 不提供行級鎖和外鍵的約束;
? ? ? ? 保存了表的行數,執行select count(*) 的時候,可以直接讀取保存的結果;
? ? ? ? 不需要事務支持可以選擇MyIASM引擎。
InnoDB 引擎提供了對數據庫 acid 事務的支持,并且還提供了行級鎖和外鍵的約束,它的設計的目標就是處理大數據容量的數據庫系統。MySQL 運行的時候,InnoDB 會在內存中建立緩沖池,用于緩沖數據和索引。但是該引擎是不支持全文搜索,同時啟動的也比較慢,它不會保存表的行數,所以當執行 select count(*) from table 指令的時候,需要進行掃描全表。由于鎖的粒度小,寫操作不會鎖定全表,所以在并發度較高的場景下使用可以提升效率。
MyIASM 引擎:不提供事務的支持,也不支持行級鎖和外鍵。因此當執行插入和更新語句時,即執行寫操作的時候需要鎖定這個表,所以會導致效率降低。不過和 InnoDB 不同的是,MyIASM 引擎是保存了表的行數,于是當進行 select count(*) from table 語句時,可以直接的讀取已經保存的值而不需要進行掃描全表。所以,如果表的讀操作遠遠多于寫操作時,并且不需要事務的支持的,可以將 MyIASM 作為數據庫引擎的首選。
12.說一下 mysql 的行鎖和表鎖?
MyISAM 只支持表鎖,InnoDB 支持表鎖和行鎖,默認為行鎖。
表級鎖:開銷小,加鎖快,不會出現死鎖。
? ? ? ? ? ? ? 鎖力度大,發生鎖沖突的概率高,并發量最低。
行級鎖:開銷大,加鎖慢,會出現死鎖。
? ? ? ? ? ? ? 鎖力度小,發生鎖沖突的概率小,并發度最高。
13.說一下樂觀鎖和悲觀鎖?
樂觀鎖:每次去拿數據的時候都認為別人不會修改,所以不會上鎖,但是在提交更新的時候會判斷一下在此期間別人有沒有去更新這個數據。
悲觀鎖:每次去拿數據的時候都認為別人會修改,所以每次在拿數據的時候都會上鎖,這樣別人想拿這個數據就會阻止,直到這個鎖被釋放。
14.mysql 問題排查都有哪些手段?
使用 show processlist 命令查看當前所有連接信息。
使用 explain 命令查詢 SQL 語句執行計劃。
開啟慢查詢日志,查看慢查詢的 SQL。
15.如何做 mysql 的性能優化?
為搜索字段創建索引。
避免使用 select *,列出需要查詢的字段。
垂直分割分表。
選擇正確的存儲引擎。
16.什么是數據庫分區?
根據一定邏輯規則,將一個表拆成多個更小更容易管理的部分。
其主要目的是為了在特定的SQL操作中減少數據讀寫的總量以縮減響應時間。
查看是否支持分區命令:
5.6以下的版本:show variables like '%partition%';
5.6以上的版本:show plugins; ? 當看到有partition并且status是active時表示支持。
17.為什么要分區?
分區可以在一個表中存儲比單個磁盤或文件系統分區上的數據更多的數據,因為我們可以將分區表存儲在不同物理磁盤上
對已過期或者不需要保存的數據,可以通過刪除與這些數據有關的分區來快速刪除數據,他的效率遠比delete高;
優化查詢,在where子句中包含分區條件時,可以只掃描必要的一個或者多個分區來提高查詢效率;
例如:SELECT * FROM t PARTITION(p0,p1)WHERE c <5 ?僅選擇與WHERE條件匹配的分區p0和p1中的那些行。
在這種情況下,MySQL不檢查表t的任何其他分區;
憑借在多個磁盤上傳播數據,實現更高的查詢吞吐量。
注:一個表最多只能有1024個分區,同一個分區表的所有分區必須使用相同的存儲引擎
18.怎樣分區?
RANGE分區:基于一個給定連續區間范圍,把數據分配到不同的分區;
LIST分區:類似RANGE分區,區別在LIST分區是基于枚舉出的值列表分區,RANGE是基于給定連續區間范圍分區;
HASH分區:基于用戶定義的表達式返回值來選擇分區,該表達式對要插入到表的行中列值操作;
KEY分區:類似HASH,但是HASH允許使用用戶自定義表達式,而KEY分區不允許,它需要使用MySQL服務器提供的HASH函數,同時HASH分區只支持整數分區,而KEY分區支持除BLOB和TEXT類型外其他列
創建分區語句
十八、Redis
1.redis 是什么?都有哪些使用場景
Redis是一個開源的,使用ANSI C語言編寫,支持網絡,可基于內存,可持久化的日志型,key-value數據庫。
數據高并發的讀寫
海量數據的讀寫
對擴展性要求高的數據
2.redis 有哪些功能?
數據緩存功能
分布式鎖的功能
支持數據持久化
支持事務
支持消息隊列
3.redis 和 memcache 有什么區別?
memcache所有的值均是簡單的字符串,redis作為其替代者,支持更為豐富的數據類型
redis的速度比memcache快很多
redis可以持久化其數據
4.redis 為什么是單線程的?
因為 cpu 不是 Redis 的瓶頸,Redis 的瓶頸最有可能是機器內存或者網絡帶寬。既然單線程容易實現,而且 cpu 又不會成為瓶頸,那就順理成章地采用單線程的方案了。
關于 Redis 的性能,官方網站也有,普通筆記本輕松處理每秒幾十萬的請求。
而且單線程并不代表就慢。 nginx 和 nodejs 也都是高性能單線程的代表。
5.什么是緩存穿透?怎么解決?
緩存穿透:指查詢一個一定不存在的數據,由于緩存是不命中時需要從數據庫查詢,查不到數據則不寫入緩存,這將導致這個不存在的數據每次請求都要到數據庫去查詢,造成緩存穿透。
解決方案:最簡單粗暴的方法如果一個查詢返回的數據為空(不管是數據不存在,還是系統故障),我們就把這個空結果進行緩存,但它的過期時間會很短,最長不超過五分鐘。
6.redis 支持的數據類型有哪些?
String、List、Hash、Set、ZSet
7.redis 支持的 java 客戶端都有哪些?
Redisson、Jedis、lettuce等等,官方推薦使用Redisson。
8.jedis 和 redisson 有哪些區別?
Jedis是Redis的Java實現的客戶端,其API提供了比較全面的Redis命令的支持。
Redisson實現了分布式和可擴展的Java數據結構,和Jedis相比,功能較為簡單,不支持字符串操作,不支持排序、事務、管道、分區等Redis特性。Redisson的宗旨是促進使用者對Redis的關注分離,從而讓使用者能夠將精力更集中地放在處理業務邏輯上。
9.怎么保證緩存和數據庫數據的一致性?
合理設置緩存的過期時間。
新增、更改、刪除數據庫操作時同步更新 Redis,可以使用事物機制來保證數據的一致性。
10.redis 持久化有幾種方式?
RDB(Redis Database):指定的時間間隔能對你的數據進行快照存儲。
AOF(Append Only File):每一個收到的寫命令都通過write函數追加到文件中。
11.redis 怎么實現分布式鎖?
Redis 分布式鎖其實就是在系統里面占一個“坑”,其他程序也要占“坑”的時候,占用成功了就可以繼續執行,失敗了就只能放棄或稍后重試。
占坑一般使用 setnx(set if not exists)指令,只允許被一個程序占有,使用完調用 del 釋放鎖。
12.redis 分布式鎖有什么缺陷?
Redis 分布式鎖不能解決超時的問題,分布式鎖有一個超時時間,程序的執行如果超出了鎖的超時時間就會出現問題。
13.redis 如何做內存優化?
盡可能使用散列表(hashes),散列表(是說散列表里面存儲的數少)使用的內存非常小,所以你應該盡可能的將你的數據模型抽象到一個散列表里面。
比如你的web系統中有一個用戶對象,不要為這個用戶的名稱,姓氏,郵箱,密碼設置單獨的key,而是應該把這個用戶的所有信息存儲到一張散列表里面。
14.redis 淘汰策略有哪些?
volatile-lru:從已設置過期時間的數據集(server. db[i]. expires)中挑選最近最少使用的數據淘汰。
volatile-ttl:從已設置過期時間的數據集(server. db[i]. expires)中挑選將要過期的數據淘汰。
volatile-random:從已設置過期時間的數據集(server. db[i]. expires)中任意選擇數據淘汰。
allkeys-lru:從數據集(server. db[i]. dict)中挑選最近最少使用的數據淘汰。
allkeys-random:從數據集(server. db[i]. dict)中任意選擇數據淘汰。
no-enviction(驅逐):禁止驅逐數據。
15.redis 常見的性能問題有哪些?該如何解決?
主服務器寫內存快照,會阻塞主線程的工作,當快照比較大時對性能影響是非常大的,會間斷性暫停服務,所以主服務器最好不要寫內存快照。
Redis 主從復制的性能問題,為了主從復制的速度和連接的穩定性,主從庫最好在同一個局域網內。
十九、JVM
1.說一下 jvm 的主要組成部分?及其作用?
類加載器(ClassLoader)
運行時數據區(Runtime Data Area)
執行引擎(Execution Engine)
本地庫接口(Native Interface)
組件的作用: 首先通過類加載器(ClassLoader)會把 Java 代碼轉換成字節碼,運行時數據區(Runtime Data Area)再把字節碼加載到內存中,而字節碼文件只是 JVM 的一套指令集規范,并不能直接交給底層操作系統去執行,因此需要特定的命令解析器執行引擎(Execution Engine),將字節碼翻譯成底層系統指令,再交由 CPU 去執行,而這個過程中需要調用其他語言的本地庫接口(Native Interface)來實現整個程序的功能。
2.說一下 jvm 運行時數據區域?
程序計數器
虛擬機棧
本地方法棧
堆(創建的對象)
方法區(類的屬性、成員變量、構造函數等)
有的區域隨著虛擬機進程的啟動而存在,有的區域則依賴用戶進程的啟動和結束而創建和銷毀。
3.說一下堆棧的區別?
棧內存存儲的是局部變量;堆內存存儲的是實體;
棧內存的更新速度要快于堆內存,因為局部變量的生命周期很短;
棧內存存放的變量生命周期一旦結束就會被釋放,而堆內存存放的實體會被垃圾回收機制不定時的回收。
4.隊列和棧是什么?有什么區別?
隊列和棧都是被用來預存儲數據的。
隊列允許先進先出檢索元素。但也有例外的情況,Deque 接口允許從兩端檢索元素。
棧和隊列很相似,但它對元素進行后進先出的檢索。
5.什么是雙親委派模型?
對于任意一個類,都需要由加載它的類加載器和這個類本身一同確立在 JVM 中的唯一性,每一個類加載器,都有一個獨立的類名稱空間。類加載器就是根據指定全限定名稱將 class 文件加載到 JVM 內存,然后再轉化為 class 對象。
雙親委派模型:如果一個類加載器收到了類加載的請求,它首先不會自己去加載這個類,而是把這個請求委派給父類加載器去完成,每一層的類加載器都是如此,這樣所有的加載請求都會被傳送到頂層的啟動類加載器中,只有當父加載無法完成加載請求(它的搜索范圍中沒找到所需的類)時,子加載器才會嘗試去加載類。
6.說一下類加載的執行過程?
加載:根據查找路徑找到相應的 class 文件然后導入;
檢查:檢查加載的 class 文件的正確性;
準備:給類中的靜態變量分配內存空間;
解析:虛擬機將常量池中的符號引用替換成直接引用的過程。符號引用就理解為一個標識,而在直接引用直接指向內存中的地址;
初始化:對靜態變量和靜態代碼塊執行初始化工作。
7.怎么判斷對象是否可以被回收?
引用計數器:為每個對象創建一個引用計數,有對象引用時計數器 +1,引用被釋放時計數 -1,當計數器為 0 時就可以被回收。它有一個缺點不能解決循環引用的問題;
可達性分析:從 GC Roots 開始向下搜索,搜索所走過的路徑稱為引用鏈。當一個對象到 GC Roots 沒有任何引用鏈相連時,則證明此對象是可以被回收的。
8.java 中都有哪些引用類型?
強引用
? ? ? ?默認的引用類型。只要強引用存在,垃圾回收器將永遠不會回收被引用的對象,哪怕內存不足時,JVM也會直接拋出OutOfMemoryError,不會去回收。如果想中斷強引用與對象之間的聯系,可以顯示的將強引用賦值為null。
軟引用
? ? ? ?軟引用是用來描述一些非必需但仍有用的對象。在內存足夠的時候,軟引用對象不會被回收,只有在內存不足時,系統則會回收軟引用對象,如果回收了軟引用對象之后仍然沒有足夠的內存,才會拋出內存溢出異常。這種特性常常被用來實現緩存技術,比如網頁緩存,圖片緩存等。
弱引用
? ? ? ?弱引用的引用強度比軟引用要更弱一些,無論內存是否足夠,只要 JVM 開始進行垃圾回收,那些被弱引用關聯的對象都會被回收。
虛引用(幽靈引用/幻影引用)
? ? ? ?虛引用是最弱的一種引用關系,如果一個對象僅持有虛引用,那么它就和沒有任何引用一樣,它隨時可能會被回收
9.說一下 jvm 有哪些垃圾回收算法?
標記-清除算法:只回收,不整理
標記-整理算法:標記-清楚算法的優化,解決了內存碎片的問題
復制算法:解決內存碎片
分代回收算法(常用):年輕代以復制為主,老年代以標記-整理為主
10.說一下 jvm 有哪些垃圾回收器?
Serial:最早的單線程串行垃圾回收器,新生代垃圾回收器,使用復制算法。
Serial Old:Serial 垃圾回收器的老年版本,同樣也是單線程的,可以作為 CMS 垃圾回收器的備選預案,老年代垃圾回收器,使用標記-整理算法。
ParNew:是 Serial 的多線程版本,新生代垃圾回收器,使用復制算法。
Parallel 和 ParNew 收集器類似是多線程的,但 Parallel 吞吐量優先,可以犧牲等待時間換取系統的吞吐量,新生代垃圾回收器,使用復制算法。
Parallel Old 是 Parallel 老年版本,Parallel 使用的是復制算法,Parallel Old 使用的是標記-整理的內存回收算法,是老年代垃圾回收器。
CMS:一種以獲得最短停頓時間為目標的收集器,非常適用 B/S 系統,老年代垃圾回收器,使用標記-清除算法。
G1:一種兼顧吞吐量和停頓時間的 GC 實現,是 JDK 9 以后的默認 GC 選項,是整堆回收器,使用標記-整理算法。
垃圾回收器?? ?使用算法?? ?線程支持?? ?新生代/老年代
Serial?? ?復制?? ?單線程?? ?新生代
Serial Old?? ?標記-整理?? ?單線程?? ?老年代
ParNew?? ?復制?? ?多線程?? ?新生代
Parallel Scavenge?? ?復制?? ?多線程?? ?新生代
Parallel Old?? ?標記-整理?? ?多線程?? ?老年代
CMS?? ?標記-清除?? ?多線程?? ?老年代
G1?? ?標記-整理?? ?多線程?? ?整堆
11.詳細介紹一下 CMS 垃圾回收器?
CMS(Concurrent Mark-Sweep),是以犧牲吞吐量為代價來獲得最短回收停頓時間的垃圾回收器。對于要求服務器響應速度的應用上,這種垃圾回收器非常適合。在啟動 JVM 的參數加上“-XX:+UseConcMarkSweepGC”來指定使用 CMS 垃圾回收器。
CMS 使用的是標記-清除算法,所以在 gc 的時候會產生大量的內存碎片,當剩余內存不能滿足程序運行要求時,系統將會出現 Concurrent Mode Failure,臨時 CMS 會采用 Serial Old 回收器進行垃圾清除,此時的性能將會被降低。
12.新生代垃圾回收器和老年代垃圾回收器都有哪些?有什么區別?
新生代回收器:Serial、ParNew、Parallel Scavenge
老年代回收器:Serial Old、Parallel Old、CMS
整堆回收器:G1新生代垃圾回收器一般采用的是復制算法。復制算法的優點是效率高,缺點是內存利用率低;
老年代垃圾回收器一般采用的是標記-整理算法。
13.簡述分代垃圾回收器是怎么工作的?
分代回收器有兩個分區:老生代和新生代。
新生代的默認空間是 1/3,老生代的默認占比是 2/3。
新生代使用的是復制算法,新生代里有 3 個分區:Eden、To Survivor、From Survivor,它們的默認占比是 8:1:1,它的執行流程如下:
把 Eden + From Survivor 存活的對象放入 To Survivor 區;
清空 Eden 和 From Survivor 分區;
From Survivor 和 To Survivor 分區交換,From Survivor 變 To Survivor,To Survivor 變 From Survivor。每次在 From Survivor 到 To Survivor 移動時都存活的對象,年齡就 +1,當年齡到達 15(默認配置是 15)時,升級為老生代。大對象也會直接進入老生代。
老生代當空間占用到達某個值之后就會觸發全局垃圾收回,一般使用標記整理的執行算法。以上這些循環往復就構成了整個分代垃圾回收的整體執行流程。
14.說一下 jvm 調優的工具?
JDK 自帶了很多監控工具,都位于 JDK 的 bin 目錄下,其中最常用的是 jconsole 和 jvisualvm 這兩款視圖監控工具。
jconsole:用于對 JVM 中的內存、線程和類等進行監控;
jvisualvm:JDK 自帶的全能分析工具,可以分析:內存快照、線程快照、程序死鎖、監控內存的變化、gc 變化等。
15.常用的 jvm 調優的參數都有哪些?
-Xms2g:初始化堆大小為 2g;
-Xmx2g:堆最大內存為 2g;
-XX:NewRatio=4:設置年輕代和老年代的內存比例為 1:4;
-XX:SurvivorRatio=8:設置新生代 Eden 和 Survivor 比例為 8:2;
–XX:+UseParNewGC:指定使用 ParNew + Serial Old 垃圾回收器組合;
-XX:+UseParallelOldGC:指定使用 ParNew + ParNew Old 垃圾回收器組合;
-XX:+UseConcMarkSweepGC:指定使用 CMS + Serial Old 垃圾回收器組合;
-XX:+PrintGC:開啟打印 gc 信息;
-XX:+PrintGCDetails:打印 gc 詳細信息。
16.內存溢出、內存泄露、GC的基本概念
內存溢出:out of memory,是指程序在申請內存時,沒有足夠的內存空間供其使用,出現out of memory;比如申請了一個integer,但給它存了long才能存下的數,那就是內存溢出。
內存泄露:memory leak,是指程序在申請內存后,無法釋放已申請的內存空間,一次內存泄露危害可以忽略,但內存泄露堆積后果很嚴重,無論多少內存,遲早會被占光。其實說白了就是該內存空間使用完畢之后未回收。
gc分為full gc 跟 minor gc(Young GC也就是Minor GC),當每一塊區滿的時候都會引發gc。

)



)






)



)


)