任務:檢測舌頭上的裂紋和齒痕
已經有了labelme標注的數據集,并且轉為了coco格式
參考:
詳細!正確!COCO數據集(.json)訓練格式轉換成YOLO格式(.txt)_coco數據集的train.txt-CSDN博客
coco數據集轉yolo數據集(簡單易懂)_coco轉yolo-CSDN博客
【模型復現】自制數據集上復現剛發布的最新 yolov9 代碼_yolov9復現-CSDN博客
數據集轉換
首先將coco格式轉為YOLO格式
參考:coco數據集轉yolo數據集(簡單易懂)_coco轉yolo-CSDN博客
我自己備份一下
轉換代碼
#COCO 格式的數據集轉化為 YOLO 格式的數據集
#--json_path 輸入的json文件路徑
#--save_path 保存的文件夾名字,默認為當前目錄下的labels。import os
import json
from tqdm import tqdm
import argparseparser = argparse.ArgumentParser()
#這里根據自己的json文件位置,換成自己的就行
parser.add_argument('--json_path', default='D:/workSpace/pycharm/yolov5/MyTest/SAR_coco/annotations/instances_val2017.json',type=str, help="input: coco format(json)")
#這里設置.txt文件保存位置
parser.add_argument('--save_path', default='D:/workSpace/pycharm/yolov5/MyTest/SAR_coco/Lable/val2017', type=str, help="specify where to save the output dir of labels")
arg = parser.parse_args()def convert(size, box):dw = 1. / (size[0])dh = 1. / (size[1])x = box[0] + box[2] / 2.0y = box[1] + box[3] / 2.0w = box[2]h = box[3]
#round函數確定(xmin, ymin, xmax, ymax)的小數位數x = round(x * dw, 6)w = round(w * dw, 6)y = round(y * dh, 6)h = round(h * dh, 6)return (x, y, w, h)if __name__ == '__main__':json_file = arg.json_path # COCO Object Instance 類型的標注ana_txt_save_path = arg.save_path # 保存的路徑data = json.load(open(json_file, 'r'))if not os.path.exists(ana_txt_save_path):os.makedirs(ana_txt_save_path)id_map = {} # coco數據集的id不連續!重新映射一下再輸出!with open(os.path.join(ana_txt_save_path, 'classes.txt'), 'w') as f:# 寫入classes.txtfor i, category in enumerate(data['categories']):f.write(f"{category['name']}\n")id_map[category['id']] = i# print(id_map)#這里需要根據自己的需要,更改寫入圖像相對路徑的文件位置。list_file = open(os.path.join(ana_txt_save_path, 'train2017.txt'), 'w')for img in tqdm(data['images']):filename = img["file_name"]img_width = img["width"]img_height = img["height"]img_id = img["id"]head, tail = os.path.splitext(filename)ana_txt_name = head + ".txt" # 對應的txt名字,與jpg一致f_txt = open(os.path.join(ana_txt_save_path, ana_txt_name), 'w')for ann in data['annotations']:if ann['image_id'] == img_id:box = convert((img_width, img_height), ann["bbox"])f_txt.write("%s %s %s %s %s\n" % (id_map[ann["category_id"]], box[0], box[1], box[2], box[3]))f_txt.close()#將圖片的相對路徑寫入train2017或val2017的路徑list_file.write('./images/train2017/%s.jpg\n' %(head))print("convert successful!")list_file.close()?修改json和txt地址即可
轉換完成打開相關文件,檢查一下路徑、文件名之類的有沒有問題。
根目錄/my_datasets/
├─train.txt
├─val.txt
|─test.txt # 這個沒有也OK
├─images
│ ├──train2017
│ │ ├──xxx.jpg
│ │ └──xxx.jpg
│ └──val2017
│ ├──xxx.jpg
│ └──xxx.jpg
│ └──test2017
│ ├──xxx.jpg
│ └──xxx.jpg
└──labels├──train2017│ ├──xxx.txt │ └──xxx.txt |──val2017| ├──xxx.txt | └──xxx.txt └──classes.txtYOLOv9的復現
先下載代碼:GitHub - WongKinYiu/yolov9: Implementation of paper - YOLOv9: Learning What You Want to Learn Using Programmable Gradient Information
下載預訓練文件:YOLOv9-C
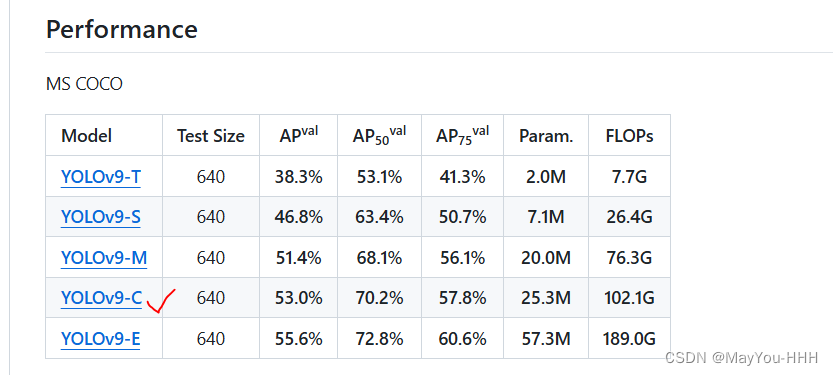
?點這兒下載的是yolov9-c-converted.pt,點下面將yolov9-c.pt下載到根目錄即可。
?搭建虛擬環境
# 創建環境
conda create -n yolov9 python=3.8# 激活環境
conda activate yolov9 # torch 安裝
# 本機 CUDA 為 11.8,故安裝了符合要求的 pytorch==1.13,這里需要自行根據 CUDA 版本安裝適配的 torch 版本
pip install torch==1.13.1+cu117 torchvision==0.14.1+cu117 torchaudio==0.13.1 --extra-index-url https://download.pytorch.org/whl/cu117pip install Pillow==9.5.0
# pip 包
cd yolov9
pip install -r requirements.txt
?修改數據文件
在 yolov9/data 路徑下新建 my_datasets.yaml 文件,以路徑下的 coco.yaml 為標準進行參數配置,
修改 path 為數據存儲路徑
修改 names 為對應的標簽名,編號名稱要對應path: ./datasets # dataset root dir
train: train.txt
val: val.txt
test: test.txt # optional# Classes
names:0: chihen1: liewen22: liewen1
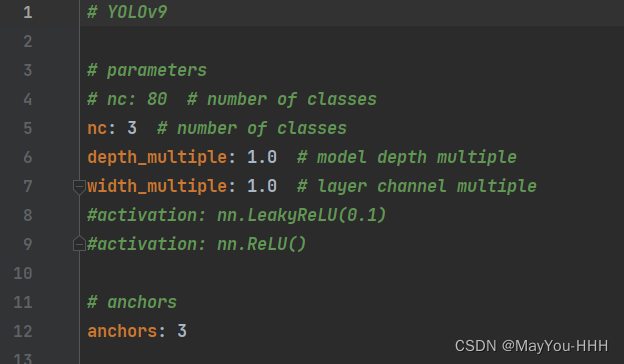
?修改模型配置文件
./models/detect/yolov9-c.yaml
--nc? ? ? ? 類別數量改一下就行
?
?配置訓練的超參數
我們使用的是train_dual.py,val_dual.py,detect_dual.py都有_dual,使用train.py的話

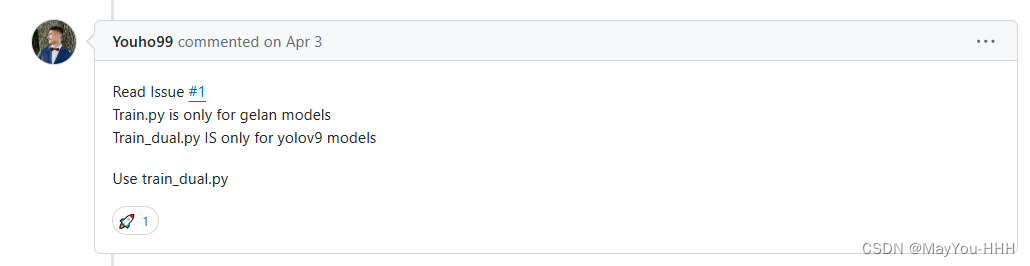
修改train_dual.py,當然更妥當的方式應該是重寫這個py文件
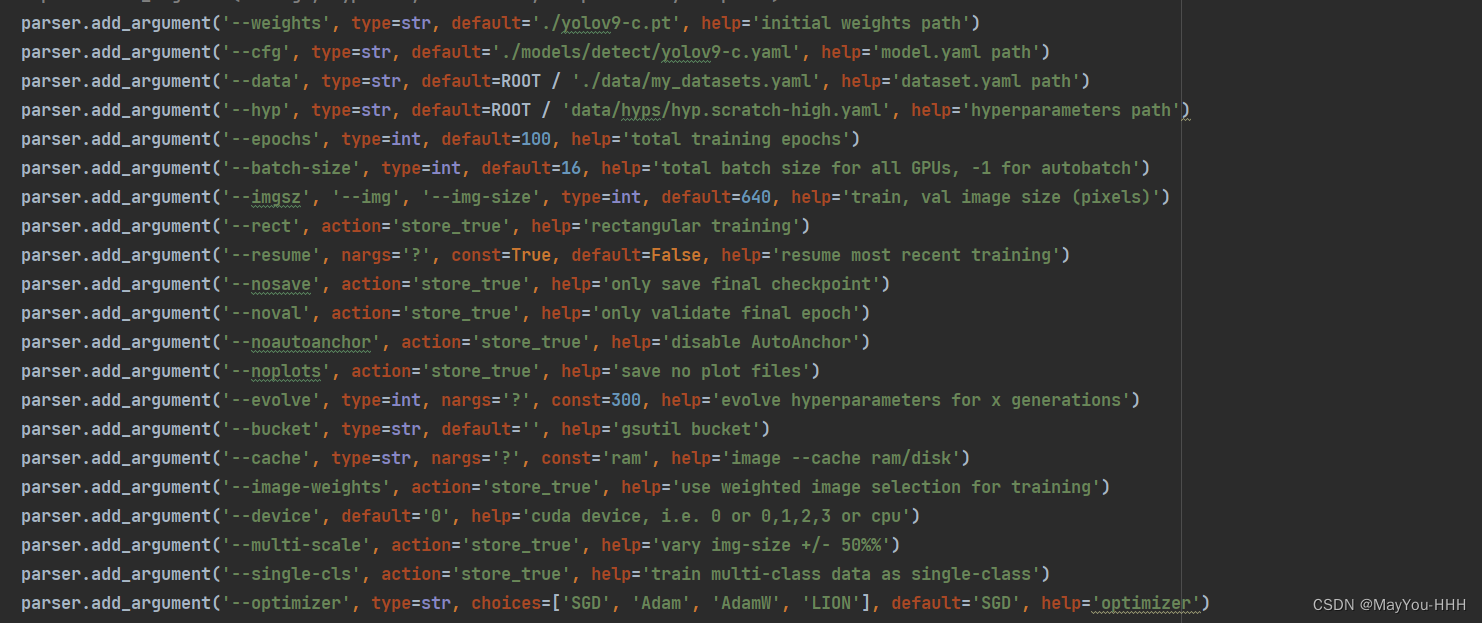 --weights? ? ? ? yolov9-c.pt 預訓練權重文件的地址
--weights? ? ? ? yolov9-c.pt 預訓練權重文件的地址
--cfg? ? ? ?yolov9-c.yaml 文件的地址
--data? ? ? ??my_datasets.yaml文件的地址
--hyp????????data/hyps/hyp.scratch-high.yaml? ?這個文件夾里面應該只有一個high沒有low
--epochs
--batch-size
--imgsz
--dedvice? ? ? ? 看你有幾張卡,改一下
--optimizer????????
?開始訓練
終端輸入命令
單卡訓練指令python train_dual.py多卡訓練指令python -m torch.distributed.launch --nproc_per_node 8 train_dual.py
?看到下述界面,即成功開始訓練!!!
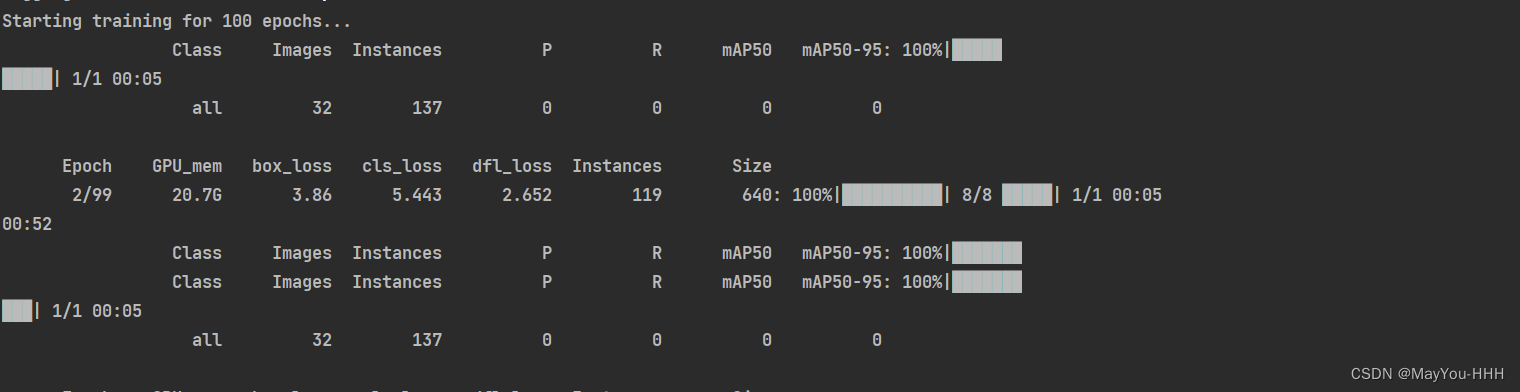
?訓練完
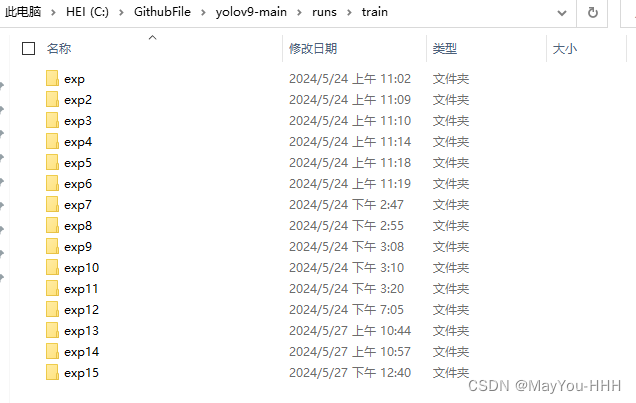
?exp里面會有訓練的一些數據,exp15為例

配置驗證超參數
修改val_dual.py
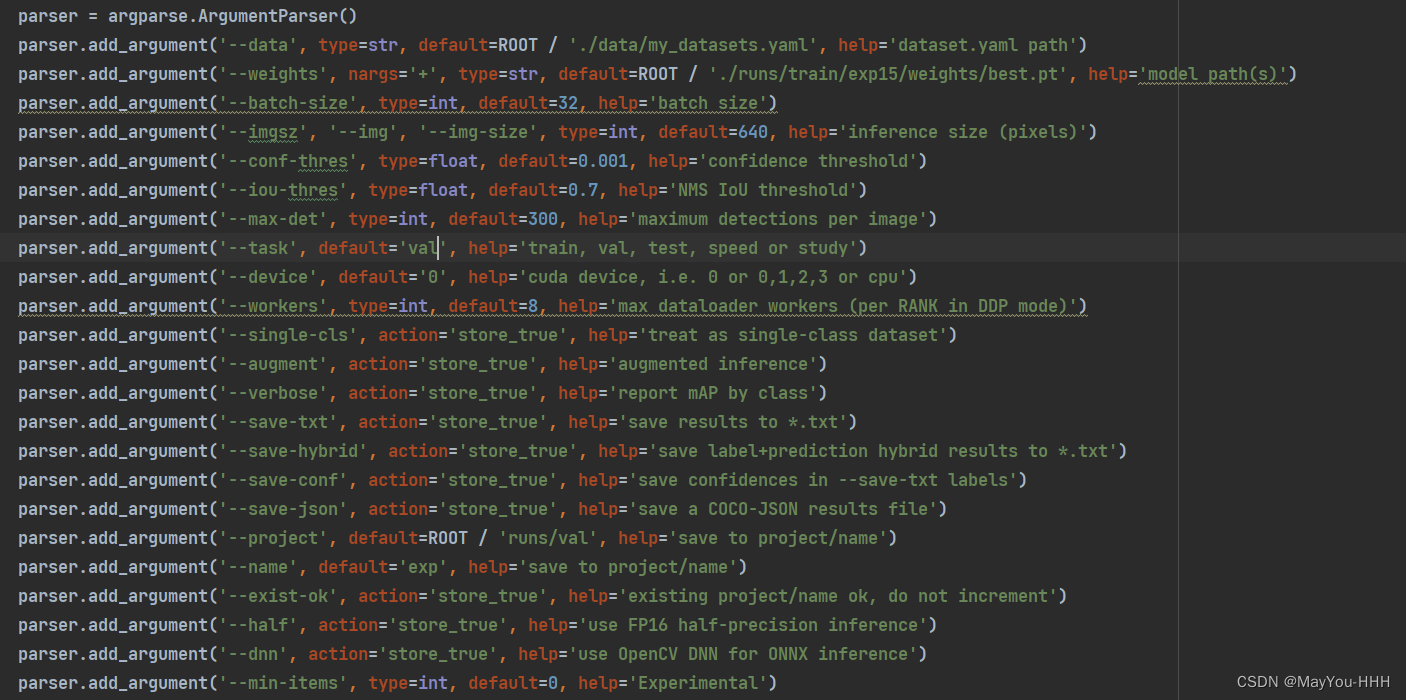
類似train_ dual.py,額外多一個
task:驗證數據集選擇,如val,test
開始驗證
單卡驗證指令python val_dual.py多卡驗證指令python -m torch.distributed.launch --nproc_per_node 8 val_dual.py
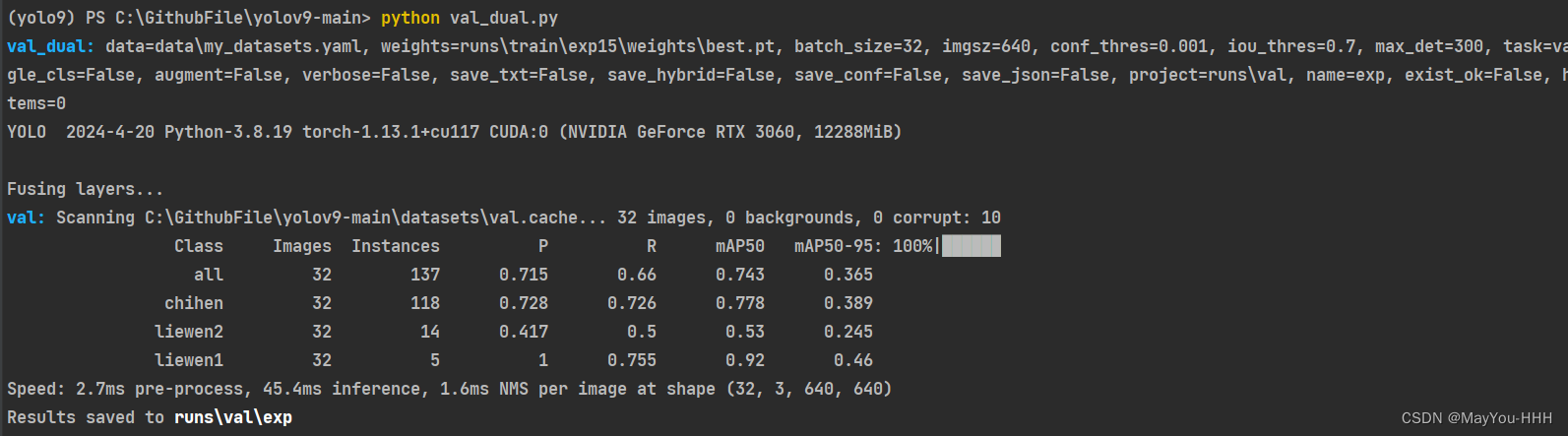
驗證成功
配置推理超參數
修改detect_dual.py
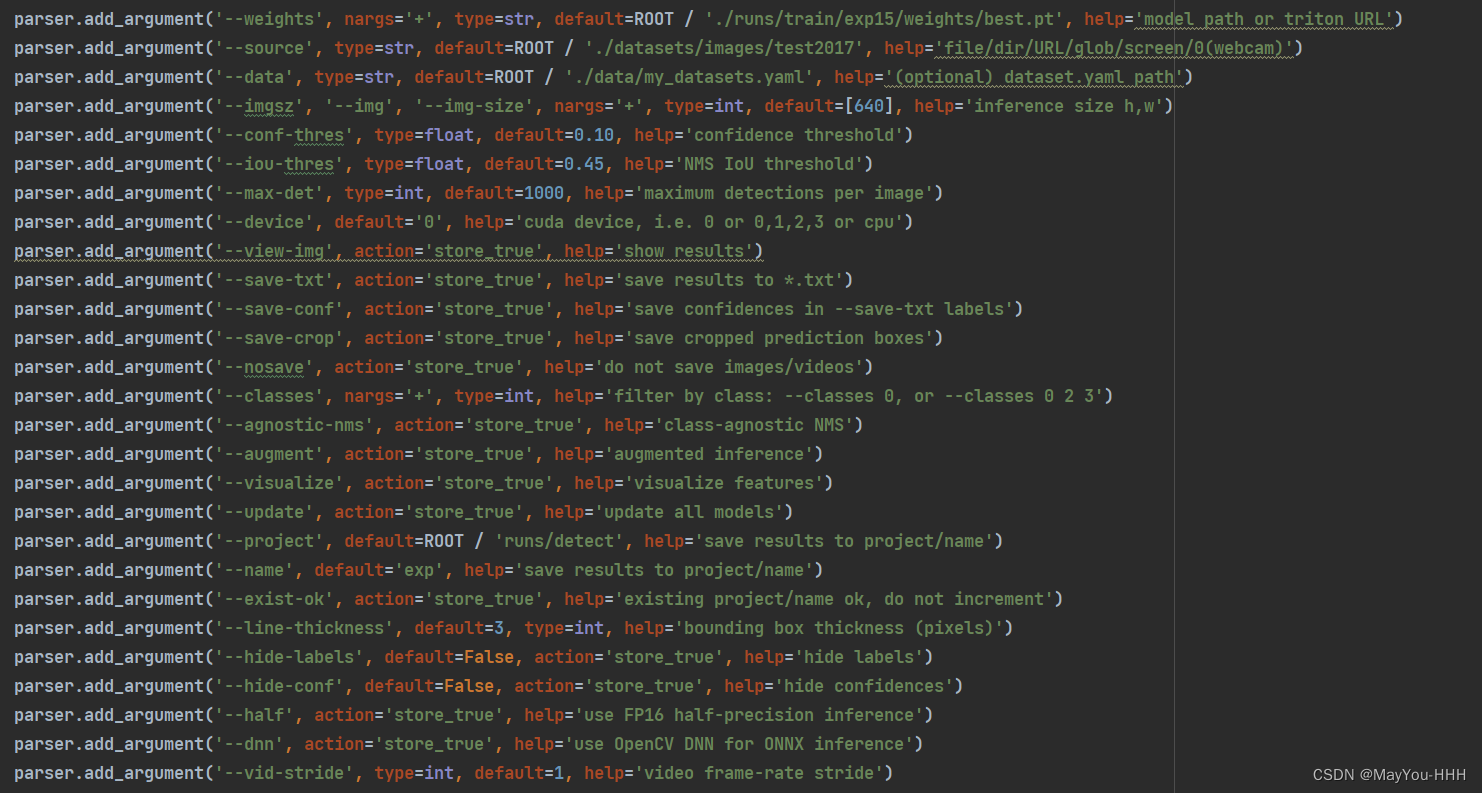
?開始推理
單卡推理指令python detect_dual.py多卡推理指令python -m torch.distributed.launch --nproc_per_node 8 detect.py
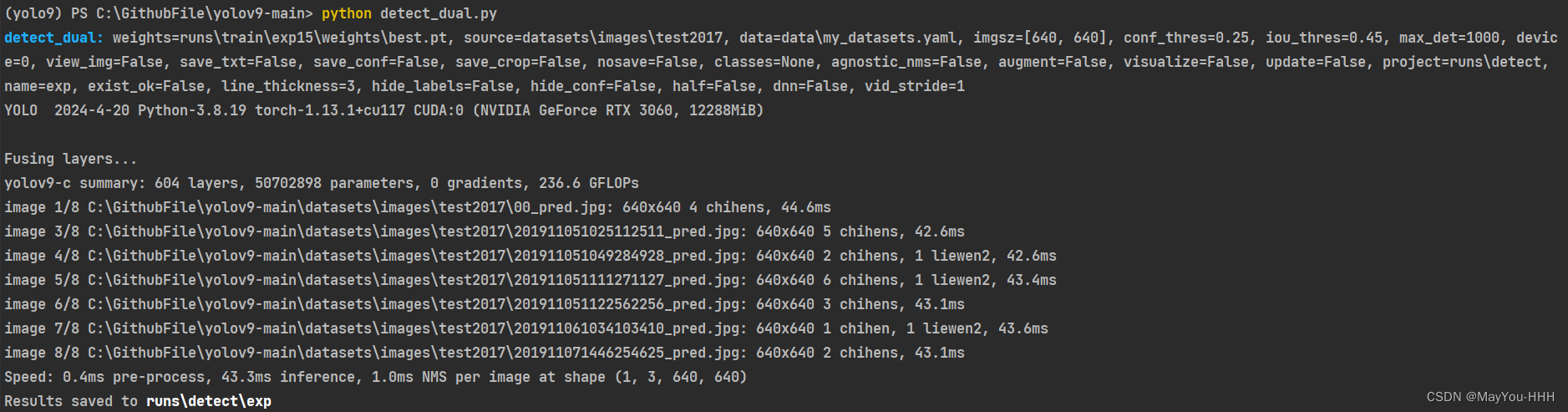
只要把需要推理的圖片放在./datasets/images/test2017文件夾中,運行推理命令即可
推理的結果保存在runs\detect\exp?
可以查看評估一下
一些問題
遇到問題首先去官方issues里面查查
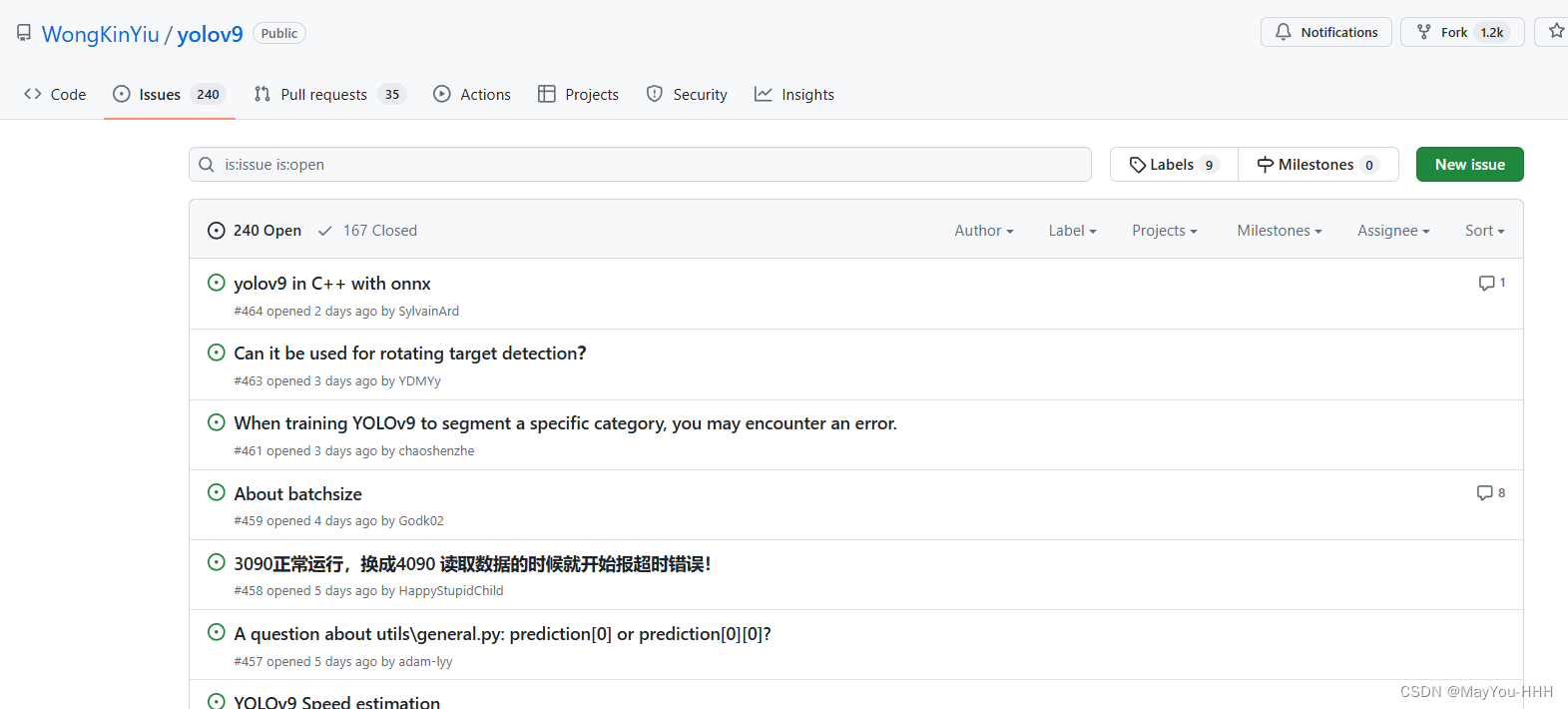
? 我的問題都能在這里解決
Q1
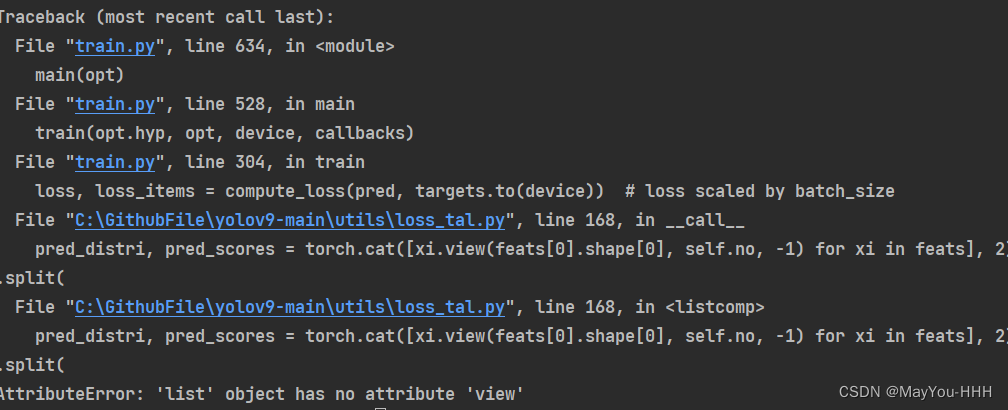
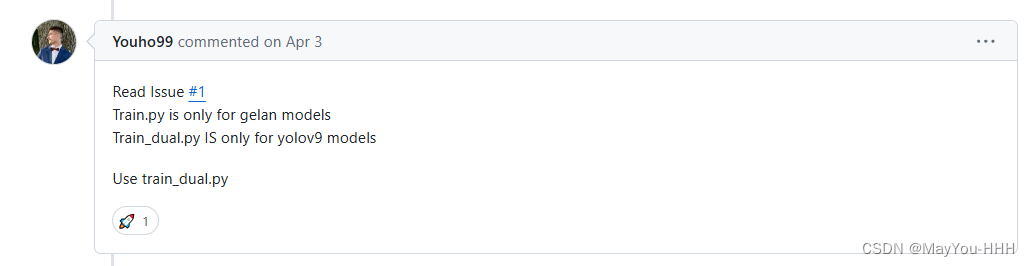
Q2
![]()





【二進制在運算中的說明】)


——游戲陰陽師介紹網頁(4個頁面))







)



