🎬個人簡介:一個全棧工程師的升級之路!
📋個人專欄:pytorch深度學習
🎀CSDN主頁?發狂的小花
🌄人生秘訣:學習的本質就是極致重復!
《PyTorch深度學習實踐》完結合集_嗶哩嗶哩_bilibili?
?
目錄
1 卷積神經網絡
2 拆解卷積
3 特征提取+分類
1 卷積神經網絡
CNN,用于特征提取,但是計算量大,卷積算子是一個計算密集型算子,工業界優化卷積算子是一個重大的任務。有LeNet、AlexNet、VGG系列、ResNet、很多深度學習框架都提供了豐富的CNN模型實現個訓練的接口。
- ResNet深度殘差網絡:
Resnet50(深度殘差網絡),圖像分類網絡,2015年何凱明提出。殘差是在正常的神經網絡中加了一個short cut 分支結構,也稱為高速公路。這樣網絡就不是單純卷積的輸出F(x),而是卷積的輸出和前面輸入的疊加F(x)+X,可以很好的解決訓練過程中的梯度消失問題。被證明具有很強的圖像特征提取能力,一般作為一種特征提取器來使用。常用來作為back bone,即骨干網絡。也被用來測試AI芯片的性能指標。
- 為什么重要?
(1)常被用來做back bone,例如 YoLo-v3 ,被用來作為特征提取器,特斯拉的占用網絡
(2)性能標桿

- ResNet包含的算法:
(1)卷積算法
卷積是CNN網絡的核心,對圖片或者特征圖進行進一步的特征提取,從而實現在不同尺度下的特征提取或者特征融合。
(2)激活(relu)
卷積是乘加運算,屬于線性運算,使用激活函數是為了引入非線性因素,提高泛化能力,將一部分神經元激活,而將另一部分神經元關閉。
(3)池化
池化層主要是為了降維,減少運算量,同時可以保證輸出特征圖中的關鍵特征
(4)加法
殘差結構,解決梯度消失問題
(5)全連接
全連接層,稱為Linear層或者FC層,將所有學習到的特征進一步融合,并映射到樣本空間的特征上,輸出與樣本對應。全連接層之后會加一個Softmax,完成多分類。
2 拆解卷積
- 卷積為什么重要
(1)通過卷積核局部感知圖像,感受野(有點像人眼盯著某一個地方看)
(2)滑動以獲取全局特征(有點像人眼左看右看物體)
(3)權重矩陣(記憶)
- 特征圖(Feature Map)
卷積操作從輸入圖像提取的特征圖,即卷積算法的輸出結果,包含了輸入圖像的抽象特征。

- 感受野
卷積核在輸入圖像上的滑動掃描過程,表示一個輸出像素“看到”的輸入圖像中區域的大小,注意是從輸出來看。如果將卷積比作窗戶,那么感受野就是一個輸出像素透過這個窗戶可以看到的輸入圖片的范圍。
感受野影響神經網絡對于圖像的理解和圖像特征的提取。大的感受野可以使得神經網絡理解圖像的全局信息,從而提取全局特征。小的感受野只能捕捉圖像的局部特征。
- 2個3x3卷積替代5x5卷積的意義?
首先可以替代是因為從輸出元素看,2個3x3卷積和1個5x5卷積,具有相同的感受野。
優勢:
(1)2個3x3卷積的卷積核參數量為3x3+3x3=18,而1個5x5=25
(2)一個卷積變成兩個卷積,加深了神經網絡的層數,從而在卷積后面引入更多的非線性層,增加了非線性能力。
- 卷積公式
輸出通道就是卷積核的個數
![]()
- Padding參數
指的是在輸入圖像的周圍添加的額外的像素值,用來擴大輸入圖像的尺寸,這些額外填充的像素值通常設置為0,卷積在這個填充后的圖像上進行。
Padding主要是為了防止邊緣信息的損失,保持輸出大小與輸入大小一致。
需要填充的場景:
(1)相同卷積(輸入和輸出尺寸一致)
(2)處理小物體,邊緣像素卷積運算較少,多次卷積容易丟失在邊緣的小物體,Padding可以提高
(3)網絡設計靈活
- Stride 參數
卷積核在活動過程中每次跳過的像素的數量,可以減少計算量、控制Feature Map輸出的大小,一定程度上防止過擬合,這是通過降低模型的復雜度來實現的。
Dilation 參數和空洞卷積
dilation指的是卷積核元素之間的間距,決定卷積核在輸入數據上的覆蓋范圍。增大dilation,增大感受野,由此引入了空洞卷積。
空洞卷積擴大了卷積核的感受野,但卻不增加卷積核的尺寸,減少運算量;可以解決大尺寸輸入圖像的問題;可以處理遙遠像素之間的關系。
- 卷積長、寬推導

除了以上的三個tensor,還有計算卷積的三個參數,Padding、stride、dilation,這樣才構成一個完整的卷積運算。
無參數推導:
![]()
加padding推導:
![]()
加上stride推導:
![]()
加上dilation推導:
![]()

3 特征提取+分類
?

輸入->卷積->輸出

一個簡單的神經網絡:

一些代碼說明:
代碼說明:
1、torch.nn.Conv2d(1,10,kernel_size=3,stride=2,bias=False)
1是指輸入的Channel,灰色圖像是1維的;10是指輸出的Channel,也可以說第一個卷積層需要10個卷積核;kernel_size=3,卷積核大小是3x3;stride=2進行卷積運算時的步長,默認為1;bias=False卷積運算是否需要偏置bias,默認為False。padding = 0,卷積操作是否補0。
2、self.fc = torch.nn.Linear(320, 10),這個320獲取的方式,可以通過x = x.view(batch_size, -1) # print(x.shape)可得到(64,320),64指的是batch,320就是指要進行全連接操作時,輸入的特征維度。
CPU代碼:
import torch
from torchvision import transforms
from torchvision import datasets
from torch.utils.data import DataLoader
import torch.nn.functional as F
import torch.optim as optim# prepare datasetbatch_size = 64
transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.1307,), (0.3081,))])train_dataset = datasets.MNIST(root='../dataset/mnist/', train=True, download=True, transform=transform)
train_loader = DataLoader(train_dataset, shuffle=True, batch_size=batch_size)
test_dataset = datasets.MNIST(root='../dataset/mnist/', train=False, download=True, transform=transform)
test_loader = DataLoader(test_dataset, shuffle=False, batch_size=batch_size)# design model using classclass Net(torch.nn.Module):def __init__(self):super(Net, self).__init__()self.conv1 = torch.nn.Conv2d(1, 10, kernel_size=5)self.conv2 = torch.nn.Conv2d(10, 20, kernel_size=5)self.pooling = torch.nn.MaxPool2d(2)self.fc = torch.nn.Linear(320, 10)def forward(self, x):# flatten data from (n,1,28,28) to (n, 784)batch_size = x.size(0)x = F.relu(self.pooling(self.conv1(x)))x = F.relu(self.pooling(self.conv2(x)))x = x.view(batch_size, -1) # -1 此處自動算出的是320x = self.fc(x)return xmodel = Net()# construct loss and optimizer
criterion = torch.nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.5)# training cycle forward, backward, updatedef train(epoch):running_loss = 0.0for batch_idx, data in enumerate(train_loader, 0):inputs, target = dataoptimizer.zero_grad()outputs = model(inputs)loss = criterion(outputs, target)loss.backward()optimizer.step()running_loss += loss.item()if batch_idx % 300 == 299:print('[%d, %5d] loss: %.3f' % (epoch+1, batch_idx+1, running_loss/300))running_loss = 0.0def test():correct = 0total = 0with torch.no_grad():for data in test_loader:images, labels = dataoutputs = model(images)_, predicted = torch.max(outputs.data, dim=1)total += labels.size(0)correct += (predicted == labels).sum().item()print('accuracy on test set: %d %% ' % (100*correct/total))if __name__ == '__main__':for epoch in range(10):train(epoch)test()
GPU代碼:
import torch
from torchvision import transforms
from torchvision import datasets
from torch.utils.data import DataLoader
import torch.nn.functional as F
import torch.optim as optim
import matplotlib.pyplot as plt# prepare datasetbatch_size = 64
transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.1307,), (0.3081,))])train_dataset = datasets.MNIST(root='./dataset/mnist/', train=True, download=True, transform=transform)
train_loader = DataLoader(train_dataset, shuffle=True, batch_size=batch_size)
test_dataset = datasets.MNIST(root='./dataset/mnist/', train=False, download=True, transform=transform)
test_loader = DataLoader(test_dataset, shuffle=False, batch_size=batch_size)# design model using classclass Net(torch.nn.Module):def __init__(self):super(Net, self).__init__()self.conv1 = torch.nn.Conv2d(1, 10, kernel_size=5)self.conv2 = torch.nn.Conv2d(10, 20, kernel_size=5)self.pooling = torch.nn.MaxPool2d(2)self.fc = torch.nn.Linear(320, 10)def forward(self, x):# flatten data from (n,1,28,28) to (n, 784)batch_size = x.size(0)x = F.relu(self.pooling(self.conv1(x)))x = F.relu(self.pooling(self.conv2(x)))x = x.view(batch_size, -1) # -1 此處自動算出的是320# print("x.shape",x.shape)x = self.fc(x)return xmodel = Net()
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)# construct loss and optimizer
criterion = torch.nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.5)# training cycle forward, backward, updatedef train(epoch):running_loss = 0.0for batch_idx, data in enumerate(train_loader, 0):inputs, target = datainputs, target = inputs.to(device), target.to(device)optimizer.zero_grad()outputs = model(inputs)loss = criterion(outputs, target)loss.backward()optimizer.step()running_loss += loss.item()if batch_idx % 300 == 299:print('[%d, %5d] loss: %.3f' % (epoch+1, batch_idx+1, running_loss/300))running_loss = 0.0def test():correct = 0total = 0with torch.no_grad():for data in test_loader:images, labels = dataimages, labels = images.to(device), labels.to(device)outputs = model(images)_, predicted = torch.max(outputs.data, dim=1)total += labels.size(0)correct += (predicted == labels).sum().item()print('accuracy on test set: %d %% ' % (100*correct/total))return correct/totalif __name__ == '__main__':epoch_list = []acc_list = []for epoch in range(10):train(epoch)acc = test()epoch_list.append(epoch)acc_list.append(acc)plt.plot(epoch_list,acc_list)plt.ylabel('accuracy')plt.xlabel('epoch')# plt.show()plt.savefig('./data/pytorch9.png')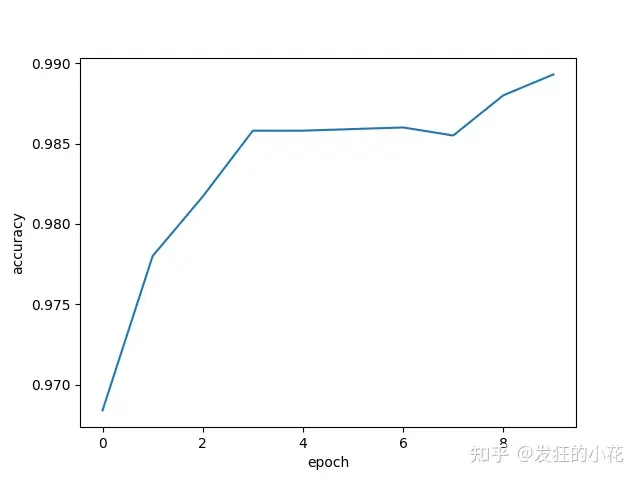
🌈我的分享也就到此結束啦🌈
如果我的分享也能對你有幫助,那就太好了!
若有不足,還請大家多多指正,我們一起學習交流!
📢未來的富豪們:點贊👍→收藏?→關注🔍,如果能評論下就太驚喜了!
感謝大家的觀看和支持!最后,?祝愿大家每天有錢賺!!!歡迎關注、關注!
)



手把手教你內網穿透,實現外網主機訪問內網服務器)












)

