

🌈個人主頁: 鑫寶Code
🔥熱門專欄: 閑話雜談| 炫酷HTML | JavaScript基礎
?💫個人格言: "如無必要,勿增實體"

文章目錄
- Python中的決策樹算法探索
- 引言
- 1. 決策樹基礎理論
- 1.1 算法概述
- 1.2 構建過程
- 2. Python中實現決策樹的庫介紹
- 2.1 Scikit-Learn
- 2.2 XGBoost & LightGBM
- 3. 實戰案例分析
- 3.1 數據準備與預處理
- 3.2 模型構建與訓練
- 3.3 預測與評估
- 4. 模型評估與調優方法
- 4.1 評估指標
- 4.2 調優策略
- 5. 局限性與未來展望
- 5.1 局限性
- 5.2 未來展望
- 結語
Python中的決策樹算法探索
引言
決策樹作為機器學習中的一種基礎且強大的算法,因其易于理解和實現、能夠處理分類和回歸任務的特性而廣受歡迎。本文旨在深入淺出地介紹決策樹算法的基本原理,并通過Python編程語言實踐其應用,幫助讀者掌握如何利用Python構建及優化決策樹模型。本文預計分為以下幾個部分:決策樹基礎理論、Python中實現決策樹的庫介紹、實戰案例分析、模型評估與調優方法,以及決策樹算法的局限性與未來展望。
1. 決策樹基礎理論
1.1 算法概述
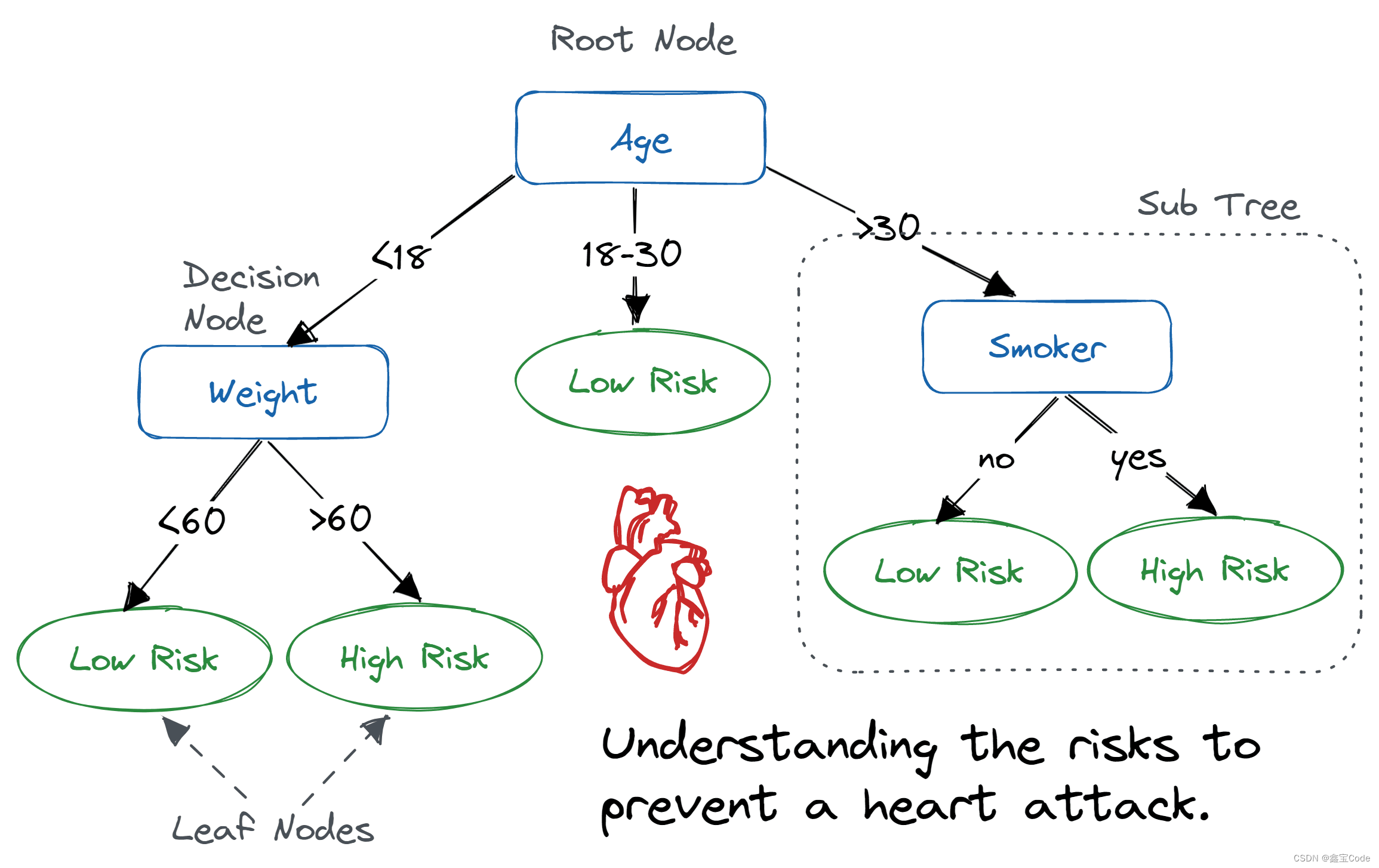
決策樹是一種樹形結構,其中每個內部節點表示一個特征上的測試,每個分支代表一個測試結果,而每個葉節點則代表一種類別或輸出值。通過一系列的特征判斷,決策樹從根到某個葉節點的路徑就對應了一個實例的分類或回歸預測。
1.2 構建過程
- 特征選擇:信息增益、基尼不純度等指標用于衡量特征的重要性。
- 樹的生成:遞歸地選擇最優特征進行分割,直到滿足停止條件(如節點純凈度達到閾值、達到最大深度等)。
- 剪枝:為防止過擬合,通過預剪枝和后剪枝減少樹的復雜度。
2. Python中實現決策樹的庫介紹
2.1 Scikit-Learn

Scikit-Learn是Python中最廣泛使用的機器學習庫之一,提供了簡單易用的API來實現決策樹算法。主要類包括DecisionTreeClassifier用于分類任務,DecisionTreeRegressor用于回歸任務。
2.2 XGBoost & LightGBM
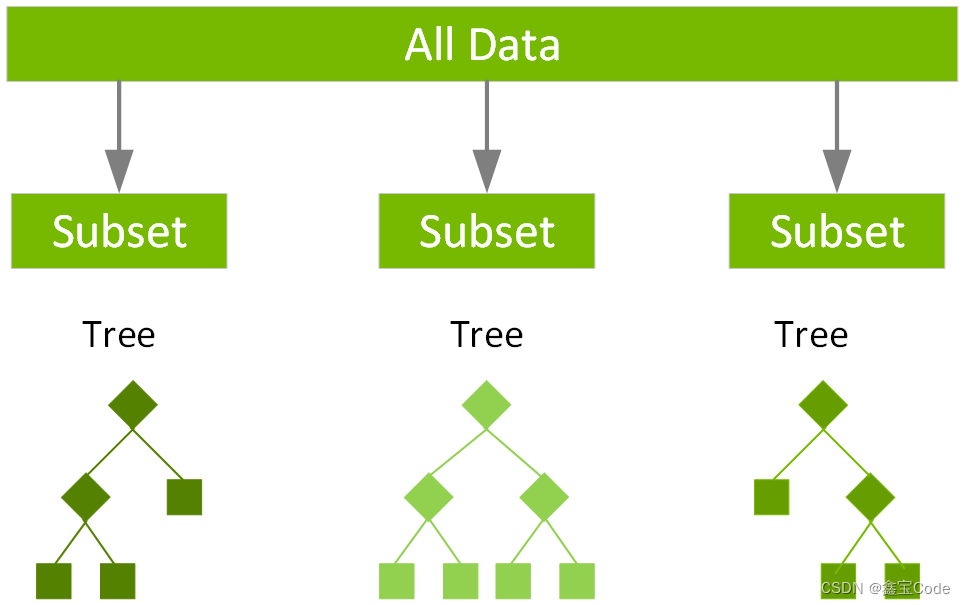
XGBoost和LightGBM是兩個高級的梯度提升框架,它們雖不是直接的決策樹庫,但通過集成多棵決策樹實現了更強大的學習能力。這些庫特別適合大規模數據集和高維度特征空間。
3. 實戰案例分析
3.1 數據準備與預處理
以經典的Iris數據集為例,首先導入必要的庫并加載數據:
import pandas as pd
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifieriris = load_iris()
X = iris.data
y = iris.target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
3.2 模型構建與訓練
接著,創建決策樹分類器并擬合數據:
dt_classifier = DecisionTreeClassifier(random_state=42)
dt_classifier.fit(X_train, y_train)
3.3 預測與評估
對測試集進行預測,并評估模型性能:
from sklearn.metrics import accuracy_scorey_pred = dt_classifier.predict(X_test)
print("Accuracy:", accuracy_score(y_test, y_pred))
4. 模型評估與調優方法
4.1 評估指標
- 準確率是最直觀的評價標準,但對于類別不平衡的數據集可能不適用。
- 混淆矩陣提供更詳細的分類情況。
- ROC曲線與AUC值對于二分類問題尤其有用。
4.2 調優策略
- 調整樹的深度與復雜度:通過設置
max_depth、min_samples_leaf等參數控制模型復雜度。 - 交叉驗證:使用
GridSearchCV或RandomizedSearchCV尋找最佳參數組合。 - 特征重要性分析:利用決策樹提供的特征重要性進行特征選擇。
5. 局限性與未來展望
5.1 局限性
- 易于過擬合,特別是在樹深較大時。
- 對連續特征的處理不如其他模型靈活。
- 可解釋性雖然強,但當樹變得非常復雜時,解釋也會變得困難。
5.2 未來展望
- 集成學習:結合多種決策樹的模型(如隨機森林、梯度提升樹)可以進一步提高預測性能。
- 自動化與可解釋性的平衡:研究如何在保持高效與準確的同時,提高決策樹模型的可解釋性。
- 深度學習融合:探索決策樹與深度神經網絡的結合方式,挖掘兩者優勢。
結語
決策樹算法以其直觀、靈活的特點,在眾多領域展現出強大的應用潛力。通過Python及其豐富的機器學習庫,我們可以輕松實現并優化決策樹模型,解決實際問題。隨著技術的不斷進步,決策樹及其衍生算法將繼續在數據科學領域扮演重要角色。希望本文能為讀者在決策樹的學習與應用上提供有價值的參考。


)









)





![【Linux】-Spark分布式內存計算集群部署[20]](http://pic.xiahunao.cn/【Linux】-Spark分布式內存計算集群部署[20])
:.NET Core 各個版本的特性)

