目錄
- 什么是NIO
- 使用場景
- NIO(new IO)相關包路徑
- NIO的實現基礎
- NIO的核心組件
- Buffer
- 緩沖區詳解
- 數據如何從磁盤讀到用戶進程
- Channel
- Channel的使用
- 其他組件
- 字符集和Charset
- 文件鎖
- NIO工具類
- 使用Files的FileVisitor遍歷文件和目錄
- 使用WatchService監控文件變化
- 訪問文件屬性
什么是NIO
NIO是Java提供的一種基于Channel和Buffer的IO操作方式,即:利用內存映射文件方式處理輸入和輸出。NIO具有更加強大和靈活的IO操作能力,提供了非阻塞IO、多路復用等特性,特別適合需要處理大量連接的網絡編程場景
-
在JDK1.4時提出了NIO(New I/O),在BIO模型(Blocking IO)的基礎上,增加了NIO模型(Non-Blocking IO),即同步非阻塞方式
-
JDK7時在NIO包中增加了AIO,NIO也隨之被稱為NIO2.0(即NIO+AIO),NIO是同步非阻塞的,AIO是異步非阻塞的。
NIO官方叫法為New I/O,但是由于后續加入了AIO,導致New IO已經不能表達已有的IO模型,因此NIO也被業界稱為Non-blocking I/O,即非阻塞IO
本文只對Non-blocking IO進行探討,AIO不做過多贅述,AIO詳情請參考AIO(異步IO)
想要詳細了解IO多路復用模型原理參考:IO多路復用模型原理
使用場景
-
對于低負載、低并發的應用程序,可以使用同步阻塞IO來提升開發效率和維護性
-
但是對于高負載、高并發的網絡應用,應該使用NIO的非阻塞模式來開發
NIO(new IO)相關包路徑
其中包下的常用類后續會詳細說明
-
java.nio:主要包含各種與Buffer相關的類
-
java.nio.channels:主要包含與Channel和Selector相關的類
套接字的特別說明(因為也在這個包下)
在該包路徑下,NIO提供了與傳統IO模型中
Socket和ServerSocket相對應的SocketChannel和ServerSocketChannel兩種不同的套接字通道實現新增的這兩種通道都支持阻塞和非阻塞方式
-
java.nio.charset:主要包含與字符集相關的類
-
java.nio.file:主要包含文件處理的工具類
-
java.nio.channels.spi:主要包含與Channel相關的服務提供者編程接口
-
java.nio.charset.spi:主要包含與字符集相關的服務提供者編程接口
NIO的實現基礎
NIO是基于Linux IO模型的IO多路復用模型實現的,netty、tomcat5及以后的版本的實現都是基于NIO,想要理解Linux的IO模型參考:Linux的五種網絡IO模型
IO復用模型圖解
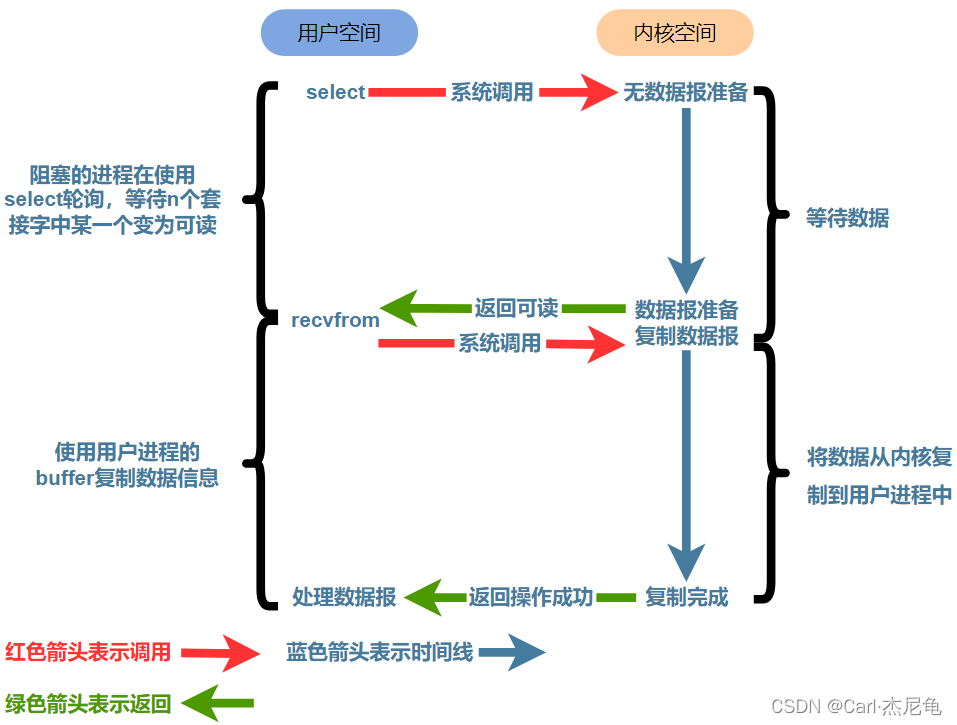
這里的多路是指N個連接,每一個連接對應一個channel,或者說多路就是多個channel,是指多個連接復用了一個線程或者少量線程(在tomcat中是少量線程)
NIO的核心組件
JavaNIO主要包含三個核心組件:
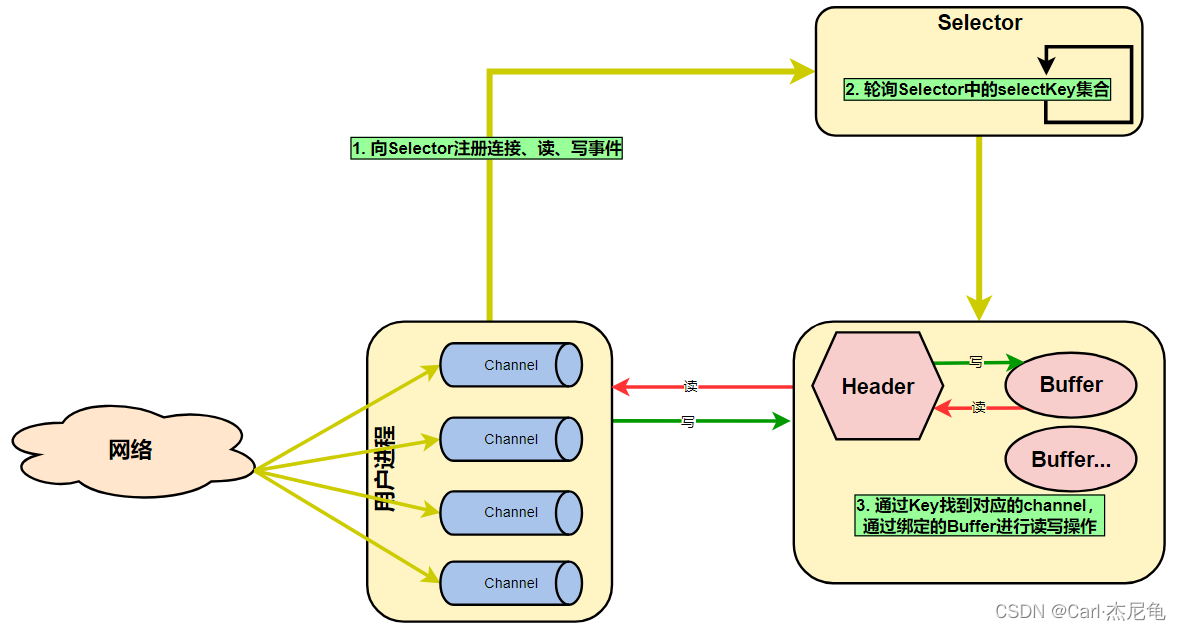
**Selector:**多路復用器(選擇器),是NIO的基礎,也可以稱為輪詢代理器、事件訂閱器或Channel容器管理器。Selector提供選擇已經就緒的任務的能力,允許一個線程同時監聽多個通道上的事件,即:單線程同時管理多個網絡連接,并在某個通道上有數據可讀或可寫時及時做出響應,是Java NIO實現非阻塞IO的關鍵組件
**Channel:**是所有數據的傳輸通道,通道可以是文件、網絡連接等。Channel提供了一個map()方法,通過該map()方法可以直接將“一塊數據”映射到內存中
**Buffer:**是一個容器(類似數組),發送到Channel中的所有對象都必須首先放到Buffer中,從Channel中讀取的數據也會先放到Buffer中
為什么要將傳統IO模型中stream的概念換成channel+buffer的概念?
-
Stream與Channel對比
-
傳統的阻塞IO模型中,
stream是用于在程序和數據源之間進行數據傳輸的抽象概念,流的特點就是順序的、逐個訪問。 -
Java NIO中提出的Channel也是進行數據傳輸的抽象概念,區別在于stream是單向數據傳輸,而channel是雙向數據傳輸,
從這個角度看,Channel是全雙工通信,Stream是單工通信,那么Channel必然就會比Stream更加高效
-
-
為什么傳統IO沒有提出Buffer的概念?
緩沖區以及緩沖區是如何工作的,這是所有IO實現的基礎,即輸入和輸出就是把數據移進 or 移出緩沖區
進程執行IO操作,就是向操作系統發出請求,將數據從緩沖區取出(寫操作),或者將數據寫入緩沖區(讀操作)
既然Buffer是所有IO實現的基礎,傳統IO模型并沒有Buffer,是不是說錯了或者傳統IO并不是IO?
其實并不是,只是傳統IO中Buffer是開發者自己創建的,也就是byte[]數組,這個byte數組設置多大都是開發者自己決定,因此沒有提出Buffer的概念
Java byte[] input = new byte[1024]; /* 讀取數據 */ socket.getInputStream().read(input);
而在JavaNIO中,緩沖區是一個固定大小的,連續內存塊,用于暫時存儲數據,為緩沖區也提供了一系列的操作API,因此在NIO特意強調了Buffer的概念
NIO注冊、輪詢等待、讀寫操作協作關系如下圖:
Buffer
Buffer是Channel操作讀寫的組件,包含了寫入和讀取得數據。在NIO庫中,所有數據都是用緩沖區處理的,緩沖區實際上就是一個數組,并提供了對數據結構化以及維護讀寫位置等信息。
Buffer是一個抽象類,我們在網絡傳輸中大多數都是使用ByteBuffer,它可以在底層字節數組上進行get/set操作。除了ByteBuffer之外,對應于其他基本數據類型(boolean除外)都有相應的Buffer類(CharBuffer、ShortBuffer、IntBuffer、LongBuffer、FloatBuffer、DoubleBuffer)。
這些Buffer類沒有提供構造器訪問,因此創建Buffer類就必須使用靜態方法allocate(int capacity),即:ByteBuffer buffer = ByteBuffer.allocate(10)表示創建容量為10的ByteBuffer對象
ByteBuffer類的子類:MappedByteBuffer用于表示Channel將磁盤文件的部分或全部內容映射到內存中后得到的結果。MappedByteBuffer對象是由Channel的map()方法返回
-
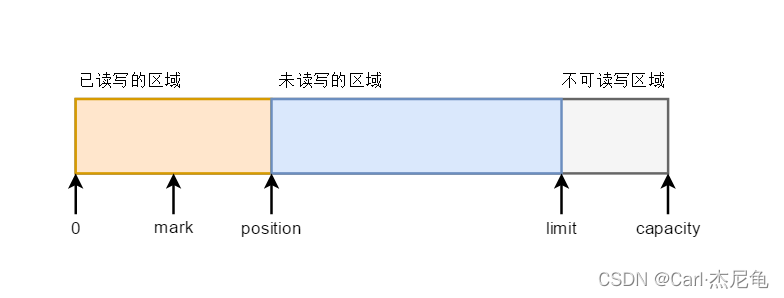
容量(capacity):緩沖區的容量,表示該Buffer的最大數據容量,創建后不可改變,不能為負值
-
界限(limit):第一個不應該被讀出或寫入的緩沖區位置索引,位于limit后的數據既不可被讀也不可被寫
-
位置(position):用于指明下一個可以被讀出或寫入的緩沖區位置索引,索引從0開始,即如果從Channel中讀了兩個數據后(0,1),position指向的索引應該是2(第三個即將讀取數據的位置)
position可以自己設置,即設置從索引為mark處讀取數據
/*** XxxBuffer方法:* put():向Buffer中放入一些數據--一般不使用,都是從Channel中獲取數據* get():向Buffer中取出數據* flip():當Buffer裝入數據結束后,調用該方法可以設置limit為當前位置,避免后續數據的添加--為輸出數據做準備* clear():對界限、位置進行初始化,limit置為capacity,position設置為0,為下一次取數做準備* int capacity():返回Buffer的容量大小* boolean hasRemaining():判斷當前位置和界限之間是否還有元素可供處理* int limit():返回Buffer的界限(limit)的位置* Buffer mark():設置Buffer的標記(mark)位置,只能在0-position之間做標記* int position():返回Buffer中的position值* Buffer position(int newPs):設置Buffer的position,并返回position被修改后的Buffer對象* int remaining():返回當前位置和界限之間的元素個數* Buffer reset():將位置轉到mark所在的位置* Buffer rewind():將位置設置為0,取消設置的mark* @Param: * @return: void*/
public void BufferTest(){//創建一個CharBuffer緩沖區,設置容量為20CharBuffer buff= CharBuffer.allocate(20);//測試方法://獲取當前容量、界限、位置System.out.println("初始值:"+buff.capacity()+"\n"+buff.limit()+"\n"+buff.position());//20、20、0buff.put('1');buff.put('2');buff.put('3');buff.position(1).mark();//標記位置索引處buff.rewind();//將position設置為0,并將mark清除,此時再調用reset()將會報錯java.nio.InvalidMarkExceptionbuff.mark().reset();//將position轉移到標記處buff.put("abc");buff.put("java");//abcjava//設置界限值buff.limit(buff.position());System.out.println("添加數據后:"+buff.capacity()+"\n"+buff.limit()+"\n"+buff.position());//20、7、7//初始化容量、界限、位置int position = buff.position();buff.position(0);System.out.println("修改后:"+buff.capacity()+"\n"+buff.limit()+"\n"+buff.position());//20、7、0//遍歷Buffer數組的數據for (int i = 0; i < position; i++) {System.out.print(buff.get());}System.out.println();//hasRemaining判斷是否可繼續添加元素,position >= limit返回false,position < limit返回trueSystem.out.println(buff.remaining());//0System.out.println(buff.hasRemaining());//falsebuff.limit(15);System.out.println(buff.hasRemaining());//trueSystem.out.println(buff.position());//7System.out.println("remaining="+buff.remaining());//8 還可以添加8個元素buff.clear();System.out.println("clear后:"+buff.capacity()+"\n"+buff.limit()+"\n"+buff.position());//20、20、0
}
Buffer的缺點:
-
XxxBuffer使用
allocate()方法創建的Buffer對象是普通的Buffer–創建在Heap上的一塊連續區域–間接緩沖區 -
ByteBuffer還有一個
allocateDirect()方法創建的Buffer是直接Buffer–創建在物理內存上開辟空間–直接緩沖區
1. 間接緩沖區:易于管理,垃圾回收器可回收,但是空間有限,讀寫文件速度較慢(從磁盤讀到內存)2. 直接緩沖區:空間較大,讀寫速度快(從磁盤讀到磁盤的速度),但是不受垃圾回收器的管理,創建和銷毀都極耗性能
-
直接Buffer的創建成本高于間接Buffer,所以直接Buffer只用于生存期長的Buffer。
-
直接Buffer只有ByteBuffer才能創建,因此如果需要其他的類型,只能使用創建好的ByteBuffer轉型為其他類型
重要注意事項:
flip()方法可以將Buffer從寫模式切換到讀模式,flip()方法會將position設回到0,并將limit設置成之前position的值
緩沖區詳解
數據如何從磁盤讀到用戶進程
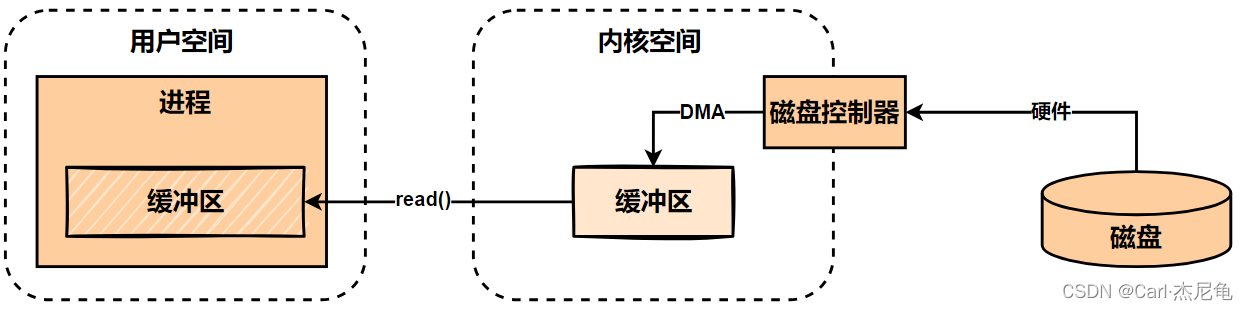
上圖解析
該圖描述了數據從外部磁盤向運行中的進程的內存區域移動的過程
-
進程使用read()系統調用,要求從指定目標處獲取數據
-
此時CPU會通過特定的指令將磁盤控制器初始化,包括設置數據傳輸的起始地址、目的地址、數據長度等
-
外部設備發起直接內存訪問請求,請求磁盤控制器來執行數據傳輸操作
-
磁盤控制器根據初始化的參數直接在外設和內核內存緩沖區之間進行數據傳輸,不需要CPU干預
-
當數據傳輸完成后,磁盤控制器會發送一個信號中斷給CPU,通知傳輸完成
-
一旦內核的內存緩沖區數據傳輸完成,內核就會立即把數據從內核空間的臨時緩沖區拷貝到用戶進程執行read()系統調用時指定的緩沖區內
Channel
Channel表示打開到IO設備的連接,可以直接將指定的文件的部分或全部直接映射為Buffer–映射,程序不能直接訪問Channel中的數據(讀取、寫入都不行),必須通過Buffer進行承載后從Buffer中操作這些數據
Channel有兩種實現:SelectableChannel1用于網絡讀寫;FileChannel用于文件操作
其中SelectableChannel有以下幾種實現:
-
ServerSocketChannel:應用服務器程序的監聽通道。只有通過了這個通道,應用程序才能向操作系統注冊支持多路復用IO的端口監聽。同時支持UDP協議和TCP協議
-
SocketChannel:TCP Socket套接字的監聽通道,一個Socket套接字對應了一個客戶端IP:端口 → 服務端IP:端口的通信連接
-
DatagramChannel:UDP數據報文的監聽通道
Channel相比于IO中的Stream流更加高效2,但是必須和Buffer一起使用。
Channel的使用
-
Channel不能使用構造器來創建,只能通過字節流InputStream,OutputStream(節點流)來調用getChannel()方法來創建
-
不同的節點流調用getChannel()方法創建的Channel對象不一樣。
如:FileInputStream/FileOutputStream->FileChannel
PipedInputStream/PipedOutputStream->Pip.SinkChannel/Pip.SourceChannel -
Channel常用的三個方法:
-
MappedByteBuffer map(FileChannel.MapMode mode,long position,long size)
將Channel對應的部分或全部的數據映射成ByteBuffer
參數說明:
mode:映射模式-三種:READ_ONLY(只讀)、PRIVATE(私有(寫時復制))、READ_WRITE(讀寫)
position:Buffer的初始化位置
size:Buffer的容量
-
read():用于讀取Buffer中的數據
-
write():用于將數據寫入Buffer
-
FileChannel inChannel = null;
FileChannel outChannel = null;
try {//1.創建文件對象--指定讀取和寫入的文件File src=new File("E:\\Documents\\java.txt");File dest=new File("E:\\Documents\\java1.txt");//2.使用FileInputStream進行文件讀取、FileOutputStream進行文件寫入//不一樣的是采用管道的方式--這里就需要getChannel()創建Channel對象inChannel = new FileInputStream(src).getChannel();//只能讀outChannel = new FileOutputStream(dest).getChannel();//只能寫//3.將管道數據通過map()方法傳遞給MappedByteBuffer對象進行緩沖承載MappedByteBuffer buffer=inChannel.map(FileChannel.MapMode.READ_ONLY, 0, src.length());//4.將獲取的內容buffer交給Channel寫回到指定文件java1.txt中outChannel.write(buffer);//將文件內容打印到控制臺//1.初始化position和limitbuffer.clear();//2.設置輸出編碼格式Charset charset=Charset.forName("UTF-8");//3.將ByteBuffer轉換成字符集的BufferCharsetDecoder decoder=charset.newDecoder();CharBuffer cb=decoder.decode(buffer);//4.輸出字符集bufferSystem.out.println(cb);
} catch (IOException e) {e.printStackTrace();
} finally {try {inChannel.close();} catch (IOException e) {e.printStackTrace();}try {outChannel.close();} catch (IOException e) {e.printStackTrace();}
}
使用RandomAccessFile創建Channel對象
-
管道的寫數據的方式是追加–但是重新執行程序就是覆蓋–這種情況需要修改position的位置
-
源文件的隨機訪問對象創建的管道必須可讀,目標文件的隨機訪問對象創建的管道必須可寫
-
源文件的隨機訪問對象創建的管道使用map()方法生成buffer后,目標文件的隨機訪問對象創建的管道使用write()方法寫出buffer
-
最后一定要關閉流
FileChannel channel = null;
FileChannel channel1 = null;
try {File srcPath=new File("E:\\Documents\\java.txt");File destPath=new File("E:\\Documents\\java1.txt");channel = new RandomAccessFile(srcPath,"r").getChannel();channel1 = new RandomAccessFile(destPath,"rw").getChannel();ByteBuffer map = channel.map(FileChannel.MapMode.READ_ONLY, 0, srcPath.length());channel1.position(destPath.length());channel1.write(map);
} catch (IOException e) {e.printStackTrace();
} finally {try {channel.close();} catch (IOException e) {e.printStackTrace();}
}
File src=new File("E:/Documents/java.txt");
FileChannel channel = new FileInputStream(src).getChannel();
ByteBuffer bf=ByteBuffer.allocate(256);
int len=0;
while ((len=channel.read(bf))!=-1) {//limit設置為position,避免操作空白區域。如果覆蓋到指定位置后,后續還有內容也不可讀取,這樣避免覆蓋不完全出現錯誤數據bf.flip();System.out.println(bf);Charset charset=Charset.forName("UTF-8");CharsetDecoder decoder = charset.newDecoder();CharBuffer cb = decoder.decode(bf);System.out.println(cb);//重置buffer的參數,內容依舊是采用覆蓋的方式,clear不會修改Buffer中的內容bf.clear();
}
其他組件
**Charset類:**用于將Unicode字符映射成為字節序列以及逆映射操作
字符集和Charset
由于計算機的文件、數據、圖片文件底層都是二進制存儲的(全部都是字節碼)
編碼:將明文的字符序列轉換成計算機理解的二進制序列稱為編碼
解碼:將二進制序列轉換成明文字符串稱為解碼
java默認使用Unicode字符集,當從操作系統中讀取數據到java程序容易出現亂碼
當A程序使用A字符集進行數據編碼(二進制)存儲到硬盤,B程序采用B字符集進行數據解碼,解碼的二進制數據轉換后的字符與A字符集轉換后的字符不一致就出現了亂碼的情況。
JDK1.4提供了Charset來處理字節序列和字符序列之間的轉換關系
-
該類包含了用于創建編碼器和解碼器的方法
-
獲取Charset所支持的字符集的方法availableCharsets()
forName(String charsetName):創建Charset對應字符集的對象實例
newDecoder():通過Charset對象獲取對應的解碼器
newEncoder():通過Charset對象獲取對應的編碼器CharBuffer encode(ByteBuffer bb):將ByteBuffer中的字節序列轉換為字符序列
ByteBuffer decode(CharBuffer cb):將CharBuffer中的字符序列轉換為字節序列
ByteBuffer encode(String str):將String中的字符序列轉換為字節序列
// SortedMap<String, Charset> stringCharsetSortedMap = Charset.availableCharsets();
// stringCharsetSortedMap.forEach((key,value)-> System.out.println(key+"<->"+value));Charset charset = Charset.forName("UTF-8");ByteBuffer bb = charset.encode("中文字符");System.out.println(bb);//java.nio.HeapByteBuffer[pos=0 lim=12 cap=19]//編碼解碼方式一:CharBuffer decode1 = charset.decode(bb);System.out.println(decode1);//中文字符ByteBuffer encode1 = charset.encode(decode1);System.out.println(encode1);//java.nio.HeapByteBuffer[pos=0 lim=12 cap=19]//編碼解碼方式二:CharsetDecoder decoder = charset.newDecoder();CharsetEncoder encoder = charset.newEncoder();CharBuffer decode = decoder.decode(encode1);System.out.println(decode);//中文字符ByteBuffer encode = encoder.encode(decode);System.out.println(encode);//java.nio.HeapByteBuffer[pos=0 lim=12 cap=19]}
文件鎖
-
文件鎖是在多個運行的程序需要并發修改同一個文件時所必須的
-
使用文件鎖可以有效地阻止多個進程并發的修改同一個文件,但是并不是所有平臺都提供了文件鎖機制
-
文件鎖能控制文件的全部或部分字節的訪問
-
文件鎖在不同的操作系統的差別較大
NIO中java提供了FileLock來支持文件鎖定功能,在FileChannel中提供的lock()/tryLock()方法可以獲取文件鎖FileLock對象
-
lock(long position,long size,boolean shared):如果未獲取文件鎖,則會導致線程阻塞
-
tryLock(long position,long size,boolean shared):如果未獲取文件鎖直接返回null,獲取返回該文件鎖
-
上述兩個方法參數解析:
-
position:從文件的position位置開始
-
size:給長度為size的內容加鎖
-
shared:true表示為共享鎖:允許多個進程來讀取該文件,但是其他進程獲得該文件的排他鎖;false表示該鎖為排他鎖,自己讀取時其他線程不能獲取鎖
-
-
直接使用lock()或tryLock()方法獲取的文件鎖是排他鎖,即shared默認值為false
FileLock fileLock = null;
try {FileOutputStream fileOutputStream = new FileOutputStream("E:/Documents/java.txt");FileChannel channel = fileOutputStream.getChannel();fileLock = channel.tryLock();//創建鎖以后,其他程序將無法對該文件進行修改Thread.sleep(1000);
} catch (IOException e) {e.printStackTrace();
} catch (InterruptedException e) {e.printStackTrace();
} finally {try {fileLock.release();} catch (IOException e) {e.printStackTrace();}
}
雖然文件鎖可以用于控制并發訪問,但是還是推薦使用數據庫來保存程序信息,而不是文件
注意:
-
對于部分平臺,文件鎖即使可以被獲取,文件依舊是可以被其他線程操作的
-
對于部分平臺,不支持同步地鎖定一個文件并把它映射到內存中
-
文件鎖是由java虛擬機持有的,如果兩個java程序使用同一個java虛擬機,則不能對同一個文件進行加鎖操作
-
對于部分平臺,關閉FileChannel時,會釋放java虛擬機在該文件上的所有鎖,因此應該避免對同一個被鎖定的文件打開多個FileChannel
NIO工具類
NIO問題:
-
File類功能有限
-
File類不能利用特定文件系統的特性
-
File類的方法性能不高
-
File類大多數方法出錯時不會提供異常信息
升級NIO.2:
-
提供了Path接口和Paths實現工具類
-
提供了Files工具類
public class Nio2Test {@Testpublic void pathsTest(){Path path = Paths.get("E:/Documents/java.txt");//path包含的路徑數量System.out.println(path.getNameCount());//2=>(Document,java.txt)//獲取根目錄System.out.println(path.getRoot());//E:\//獲取絕對路徑System.out.println(path.toAbsolutePath());//E:\Documents\java.txtPath path1 = Paths.get("E:", "Documents", "java.txt");System.out.println(path1);//E:\Documents\java.txt}@Testpublic void File() throws IOException {//復制文件Files.copy(Paths.get("E:","Documents","java1.txt"), new FileOutputStream("E:/Documents/java2.txt"));//檢查文件是否為隱藏文件System.out.println("Nio2Test.java:"+Files.isHidden(Paths.get("out.txt")));//falseList<String> list = Files.readAllLines(Paths.get("E:/Documents/java2.txt"), Charset.forName("UTF-8"));System.out.println(list);//獲取文件大小long size = Files.size(Paths.get("E:/Documents/java2.txt"));System.out.println(size);//寫數據到文件中ArrayList<String> poem = new ArrayList<>();poem.add("今天搞完IO沒得問題吧");poem.add("明天搞完網絡編程第一章沒得問題吧");poem.add("后天搞完網絡編程第二章搞完IO沒得問題吧");poem.add("大后天搞完網絡編程第三章搞完IO沒得問題吧");Path write = Files.write(Paths.get("E:/Documents/java2.txt"), poem, Charset.forName("UTF-8"));//覆蓋System.out.println(write);//按行獲取文件內容,使用Stream接口中的forEache方法遍歷Files.lines(Paths.get("E:/Documents/java2.txt"),Charset.forName("UTF-8")).forEach(ele-> System.out.println(ele));//獲取目錄下文件,使用Stream接口中的forEache方法遍歷Files.list(Paths.get("E:/Documents")).forEach(ele-> System.out.println(ele));//獲取當前文件的根目錄別名FileStore fileStore = Files.getFileStore(Paths.get("E:/Documents/java2.txt"));System.out.println(fileStore);//E盤總空間long totalSpace = fileStore.getTotalSpace();System.out.println(totalSpace);//E盤可用空間long unallocatedSpace = fileStore.getUnallocatedSpace();System.out.println(unallocatedSpace);}
}
使用Files的FileVisitor遍歷文件和目錄
不使用Files,通常想要遍歷指定目錄下的所有文件和子目錄都是使用遞歸的方式,這種方式不僅復雜,靈活性也不高
在Files類中提供了兩個方法來遍歷文件和子目錄
walkFileTree(Path start,FileVisitor<? super Path> visitor):遍歷start路徑下的所有文件和子目錄
walkFileTree(Path start,Set options,int maxDepth,FileVisitor<? super Path> visitor):遍歷start路徑下的所有文件和子目錄,但是可根據maxDepth控制遍歷深度
兩個方法都使用了FileVisitor作為入參,FileVisitor代表一個文件訪問器,walkFileTree()方法會自動遍歷start路徑下的所有文件和子目錄,遍歷文件和子目錄都會觸發FileVisitor中相應的方法
FileVisitor中定義的四個方法:
FileVisitResult postVisitDirectory(T dir,IOException exc):訪問子目錄之后觸發該方法
FileVisitResult preVisitDirectory(T dir,BasicFileAttributes attrs):訪問子目錄之前觸發該方法
FileVisitResult visitFile(T file,BasicFileAttributes attrs):訪問file文件時觸發該方法
FileVisitResult visitFileFailed(T file,IOException exec):訪問file文件失敗時觸發該方法
FileVisitResult是一個枚舉類,代表訪問之后的后續行為:
CONTINUE:代表繼續訪問
SKIP_SIBLINGS:代表繼續訪問,但不訪問該文件或目錄的兄弟文件或目錄
SKIP_SUBTREE:代表繼續訪問,但不訪問該文件或目錄的子目錄樹
TERMINATE:代表中止訪問
如果想要實現自己的文件訪問器,可以通過繼承SimpleFileVisitor來實現,SimpleFileVisitor是FileVisitor的實現類,這樣就可以根據需要、選擇性的重寫指定方法了
public class FileVisitorTest{public static void main(String[] args) throws Exception{Files.walkFileTree(Paths.get("G:","publish","codes","15"),new SimpleFileVisitor<Path>(){@Overridepublic FileVisitResult visitFile(Path file,BasicFileAttributes attrs) throws IOException{System.out.println("正在訪問"+file+"文件");//找到了FileVisitorTest.java文件if(file.endsWith("FileVisitorTest.java")){System.out.println("--已經找到目標文件--");return FileVisitResult.TERMINATE;}return FileVisitResult.CONTINUE;}@Overridepublic FileVisitResult preVisitDirectory(Path dir,BasicFileAttributes attrs) throws IOException{System.out.println("正在訪問"+dir+"路徑");return FileVisitResult.CONTINUE;}})}
}
使用WatchService監控文件變化
不使用WatchService的情況下,想要監控文件的變化,則需要考慮啟動一條后臺線程,這條后臺線程每隔一段實踐去遍歷一次指定目錄的文件,如果發現此次遍歷結果與上次遍歷結果不同,則認為文件發生了變化,這種方式不僅十分繁瑣,而且性能也不好
Path類提供了一個方法用于監聽文件系統的變化
register(WatchService watcher,WatchEvent.Kind<?>… events):用watcher監聽該path代表的目錄下的文件變化。events參數指定要監聽哪些類型的事件
這個方法最核心的就是WatchService,它代表一個文件系統監聽服務,它負責監聽path代表的目錄下的文件變化,一旦使用register()方法完成注冊之后,接下來就可以調用WatchService的如下三個方法來獲取監聽目錄的文件變化事件
WatchKey poll():獲取下一個WatchKey,如果沒有WatchKey發生就立即返回null;
WatchKey poll(long timeout,TimeUnit unit):嘗試等待timeout實踐去獲取下一個WatchKey;
WatchKey take():獲取下一個WatchKey,如果沒有WatchKey發生就一直等待
public class WatchServiceTest{public static void main(String[) args) throws Exception{//獲取文件系統atchService對象WatchService watchService = FileSystems.getDefault() .newWatchService(); //為C:盤根路徑注冊監昕Paths.get("C:/").register(watchService , StandardWatchEventKinds.ENTRY_CREATE , StandardWatchEventKinds.ENTRY_MODIFY , StandardWatchEventKinds.ENTRY_DELETE) ; while(true){//獲取下一個文件變化事件WatchKey key = watchService.take(); //①for (WatchEvent<?> event : key.pollEvents()){System.out.println(event.context() + "文件發生了" + event.kind() + "事件!" ) ; }//重設 WatchKeyboolean valid = key.reset(); // 如果重設失敗 退出監聽if (!valid){break;}}}
}
代碼說明:
在①處試圖獲取下一個WatchKey,如果沒有發生就等待,因此C盤路徑下的每次文件的變化都會被該程序監聽到
訪問文件屬性
在未使用NIO工具類的情況下,以前的File類可以訪問一些簡單的文件屬性,比如文件大小、修改時間、文件是否隱藏、是文件還是目錄等。如果程序需要獲取或修改更多的文件屬性,必須利用運行所在的平臺的特定代碼來實現。
NIO.2在java.nio.file.attribute包下提供了大量的工具類,通過這些工具類,開發者可以非常簡單的讀取、修改文件屬性。這些工具類主要分為兩類:
-
XxxAttributeView:代表某種文件屬性的視圖
-
XxxAttributes:代表某種文件屬性的集合,一般通過XxxAttributeView獲取XxxAttributes
FileAttributeView是其他XxxAttributeView的父接口,以下是一些常用的FileAttributeView的實現類
AclFileAttributeView:通過AclFileAttributeView,可以為特定文件設置ACL(Access Control List)及文件所有者屬性。其中getAcl()方法返回List對象,代表了該文件的權限集合;通過setAcl(List)方法可以修改該文件的ACL
BasicFileAttributeView:它可以獲取或修改文件的基本屬性,包括文件的最后修改時間、最后訪問時間、創建時間、大小、是否為目錄、是否為符號鏈接等。其中readAttributes()方法返回一個BasicFileAttributes對象,對文件夾基本屬性的修改是通過BasicFileAttributes對象來完成的
DosFileAttributeView:它主要用于獲取或修改文件的DOS相關屬性,比如文件是否只讀、是否隱藏、是否為系統文件、是否為存檔文件等。其中readAttributes()方法返回一個DosFileAttributes對象,對這些屬性的修改是通過DosFileAttributes對象來完成的
FileOwnerAttributeView:它主要用于獲取或修改文件的所有者。其中getOwner()方法返回一個UserPrincipal對象來代表文件所有者,也可以調用setOwner(UserPrincipal owner)方法來改變文件的所有者
PosixFileAttributeView:它主要用于獲取或修改POSIX(Portable Operating System Interface of INIX)屬性,其中readAttributes()方法返回一個PosixFileAttributes對象,該對象可用于獲取或修改文件的所有者、組所有者、訪問權限信息(可以看作是UNIX中chmod所作的事情)。注意:這個View只在Unix、Linux等系統上有用
UserDefinedFileAttributeAttributeView:它可以讓開發者為文件設置一些自定義屬性
所有被Selector注冊的通道,只能是繼承了SelectableChannel類的子類 ??
底層操作系統的通道一般都是全雙工的,可以異步雙向傳輸,所以全雙工的Channel比流能更好的映射底層操作系統的API ??








)






)



)