
讓計算機把真實圖片抽象成簡筆畫,這個任務很有挑戰性,需要模型捕獲最本質的特征
 ?
?
以往的工作是找了素描的數據集,而且抽象程度不夠高,筆畫是固定好的,素描對象的種類不多,使得最后模型的效果十分受限
之所以用CLIP是因為它可以不管圖像的風格,都能把物體的視覺特征編碼的特別好
本模型不僅是生成簡筆畫,還可以通過控制使用筆畫的多少實現不同程度的抽象
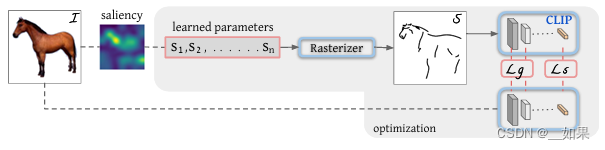
在白紙上隨機初始化曲線,最后不斷訓練成簡筆畫
一個筆畫1~4個點,點在空間中是二維的(x,y),模型訓練更改四個點的位置,從而改變筆畫的形狀
learned parameters就是初始化的筆畫
Rasterizer光柵化器是可導的,是圖形學那邊的工作
這篇文章的貢獻在于前面如何更好的初始化,后面如何選擇損失函數
像ViLD一樣,在這里的ground truth是CLIP模型蒸餾,無論是原圖還是簡筆畫,如果它們描述的是同一物體,那么最后得到的特征應該是差不多的,也就是Ls語義損失
但僅有語義不夠,比如馬頭的位置反了,但還是馬,這是語義相近,但是和原始輸入圖像就不匹配了,因此需要在幾何形狀上對模型的輸出進行限制,即Lg。用前幾層去算幾何形狀的loss,因為前幾層語義空間較低,更關注形狀的特征
做了幾個實驗后發現初始化位置很重要,作者提出saliency的方式:把圖片扔進訓練好的ViT,把最后一層的多頭自注意力取一個加權平均,做成一個saliency map,然后看哪個區域更顯著,到顯著的區域上去采點

局限性:
當圖像有背景的時候效果不好;筆畫數是超參,無法自行調整


|抽象工廠模式)



 實現獲取天氣情況)




![[數據結構] -- 雙向循環鏈表](http://pic.xiahunao.cn/[數據結構] -- 雙向循環鏈表)







到BPTT:詳細數學推導【原理理解】)