
?abstract
? ??由于各種社會和貿易網絡的不斷出現,網絡影響力分析引起了研究者的極大興趣。基于不同的影響力傳播模型,人們提出了許多網絡影響力最大化的新模型和方法。作為傳統影響力最大化問題的延伸和擴展,影響力封鎖最大化問題已成為研究熱點,并在物理學、計算機科學和流行病學等多個領域得到廣泛應用。近年來,已經報道了影響塊最大化問題的各種方法。然而,我們仍然缺乏從社交網絡影響力分析方面系統分析影響力阻止最大化問題的方法論和理論進展的全面回顧。本綜述旨在通過對影響力阻止最大化的理論和應用進行全面的調查和分析來填補這一空白。它不僅增進了對影響力最大化問題的理論理解,而且將為未來的研究提供參考。
關鍵詞: 復雜網絡 信息擴散 擴散模型 影響擴散 影響最大化 影響阻塞最大化
1. Introduction
??近年來,隨著復雜網絡的蓬勃發展,網絡拓撲和傳播動力學的研究引起了研究者的極大興趣[1,2]。影響擴散分析是復雜網絡分析的一個重要領域。它提供了復雜網絡中影響力最大化、影響力傳播預測和影響力源定位的模型和方法。例如,影響力最大化(IM)是影響力傳播分析中的一個基本問題[3]。 IM問題的目的是根據節點度或其他中心性度量等一定的度量來識別一些有影響力的節點(稱為種子),以將影響力傳播到復雜網絡中的最大范圍[4]。 IM為企業選擇有說服力的用戶以促使最大數量的顧客接受其商品提供了有效的途徑。政治家可以利用即時通訊技術來選擇有影響力的媒體向公眾傳播他們的政治觀點。
? ?在這篇綜述文章中,我們將重點關注傳統 IM 問題的延伸和擴展,即影響力阻塞最大化 [5,6]。由于復雜網絡的開放性和高速性,各種負面影響,例如虛假信息和謠言,可以在用戶中快速且廣泛地傳播[7]。虛假新聞會對新聞中的個人造成一定程度的傷害,并可能引發社會恐慌[8]。謠言可能會降低企業的信譽,并可能損害個人的聲譽。此外,假新聞的傳播可能會導致社交網絡的聲譽和安全嚴重受損。為了有效阻止復雜網絡上負面影響的傳播,一般的方法是選擇一些有影響力的個體在復雜網絡上傳播真實的消息[9]。如果用戶收到真實信息并改正虛假信息,就不會再受到有害信息的影響。因此,在復雜網絡中,積極信息的傳播可以阻止消極信息的傳播。這就是影響力阻塞最大化問題(IBM)。對于給定的擴散模型,IBM問題的目標是找到一組積極的種子來盡可能地阻止消極影響。
? ?影響力阻斷最大化可以應用于許多領域,例如謠言檢測和控制[10,11]、假新聞監控[12,13]、防疫[14,15]、市場策略設計[16,17]、意見形成[18,19]等等。例如,當有關公司產品的負面信息在社交網絡中傳播時,公司可能會選擇一些有影響力的用戶來傳播對該產品的正面評價,以抵消負面信息。當政治候選人試圖阻止有關他或她的負面謠言時,或者當政府或公職人員試圖阻止恐怖主義對公眾健康和安全的威脅時,有必要在社交網絡中選擇適當的媒體來傳播正面消息,以最大限度地減少負面消息。負面影響的蔓延。在與COVID-19(2019冠狀病毒病)爆發后,我們必須對社交網絡中的一些關鍵人群進行疫苗接種,以阻止病毒的傳播[20]。
? ?除了影響阻止最大化的廣泛應用之外,它在復雜網絡分析中也獲得了突出的作用,主要是由于三個因素:(1)檢測負面影響阻止最大化的正種子需要網絡傳播模型來描述兩者的同時傳播網絡中的積極和消極影響。 (2)網絡負面影響源深刻影響封鎖結果。因此,影響力阻塞最大化問題為影響力源識別提供了重要的研究平臺。 (3)由于影響力阻塞最大化需要估計負面影響和正面影響的傳播,因此影響力阻塞最大化為影響力預測提供了重要手段。
? ? ?近年來,已經報道了影響塊最大化問題的各種方法。然而,我們仍然缺乏從社交網絡影響力分析方面系統分析影響力阻止最大化問題的方法論和理論進展的全面回顧。最近發表了一些關于謠言檢測和阻止的評論文章[21,22]。盡管謠言攔截問題在某種程度上與影響力攔截最大化問題相似,但這些綜述文章的討論并不能涵蓋影響力攔截最大化問題的所有理論和技術問題。這些評論文章中探討的方法在三個方面不適用于影響力阻塞最大化問題:(1)為了解決影響力阻塞最大化問題,必須考慮網絡的結構。但大多數謠言攔截方法只考慮謠言傳播的路徑,而沒有參考網絡的整體拓撲信息。 (2)在影響力阻止最大化問題中,檢測積極種子用戶傳播積極信息以糾正和抵消消極影響。但大多數謠言攔截方法都是通過阻斷謠言源頭來阻止謠言的傳播,而不考慮其傳播的積極影響。 (3)一些謠言攔截工作側重于謠言檢測,如識別假新聞和檢測謠言來源,而不是識別阻斷謠言的積極種子。為了填補這些空白,這篇綜述文章的目標是從物理學和跨學科的角度徹底回顧復雜網絡中影響阻塞最大化的方法和理論方面。將特別強調基于統計物理工具、網絡影響傳播模型和流體力學的方法和理論 發展。
? ?總之,我們的綜述旨在為所有對阻礙最大化的負面影響的實踐和理論方面感興趣的學者提供參考材料,由于該主題的受歡迎程度,這很可能使我們的綜述被廣泛的跨學科受眾閱讀。這個話題是及時的,因為影響力阻止最大化問題的研究近年來對現實社交網絡中的影響力傳播產生了許多引人注目的理論見解,但我們仍然缺乏一篇全面的綜述文章來介紹影響力阻止最大化問題的最新進展和成果系統地。
? ?本評論文章的其余部分組織如下。第 2 節將概述影響阻止最大化的理論基礎,其中將觀察其目標函數的單調性和子模特性。第 3 節將回顧影響力擴散的不同模型并對它們進行分類。第 4 節將回顧影響塊最大化問題的方法,這些方法根據不同的標準分為不同的類別。在本節中,我們還對這些方法的性能進行了詳細的分析和比較。第五節將重點討論影響力封鎖最大化在謠言抑制、疫情控制、競爭營銷、網絡社交媒體、計算機病毒預防、城市路網交通控制等領域的應用。第六節總結了本文,并給出了與本研究主題相關的未來挑戰。
2. Theoretical studies of influence blocking maximization
?2.1. Problem definition
??社交網絡可以建模為圖 G = (V , E),其中 V 表示網絡中的節點集,E 表示節點之間的邊集。設u和v為社交網絡G中的兩個節點,(u,v)εE表示有一條邊連接u和v,它們之間的傳播概率用pu,v表示。令SN為在網絡G中傳播負面影響的負面種子的集合。IBM問題是在網絡中找到k個正面種子節點,使得它們能夠最大限度地阻止網絡中負面影響的傳播。

圖1 負面影響傳播與抑制示意圖。其中,紅色節點代表網絡通信中存在負面影響的節點,綠色節點是未受影響的健康節點,粉色節點是受到負面影響的節點。藍色節點為選中的抑制節點,淺藍色節點為抑制節點可以覆蓋的節點。 (a) 負面影響未傳播時的初始網絡狀態;(b) 隨著時間變化,負面影響傳播后的網絡狀態; (c) 原網絡添加抑制節點后的狀態; (d) 節點阻止負面影響傳播的網絡狀態。?
??IBM 問題還有一些其他的表現形式。例如,Masahiro 等人。 [23,24]將該問題命名為污染最小化,即通過阻止網絡中的一些鏈接來最大程度地減少計算機病毒或惡意謠言等不良對象在網絡中的傳播。布達克等人。 [6]將該問題命名為負面影響力限制,即采用正面影響力來抵消誤導性信息的傳播,使受負面影響力影響的節點最小化。 2012 年,He 等人。 [5]將此類問題稱為影響力阻止最大化,即最大限度地抑制負面影響的傳播。在這篇綜述中,我們將此類問題統一命名為影響力阻塞最大化(IBM)。圖1展示了IBM問題中負面影響傳播與抑制的示意圖。從圖1(b)可以看出,如果不抑制負面影響,網絡中的大多數節點都會受到負面影響。然而,從圖1(c)和(d)可以看出,通過選擇一些積極的種子作為抑制節點,可以減少網絡中負面影響的傳播
定義1. 阻塞集:對于網絡G,在給定的影響力傳播模型下,設負種子集為SN ,正種子集為SP 。集合 SP 中的正種子的阻塞集被定義為當沒有正種子時可以受到 SN 負面影響而當正種子集是 SP 時不能受到 SN 負面影響的節點的集合。我們用 IBS(SP , SN ) 來表示 SP 中的正種子對 SN 的負面影響的阻塞集。
定義2.阻塞影響:正種子集SP對SN的負影響的阻塞影響是阻塞集IBS(SP , SN )大小的期望:

定義3.影響力阻塞最大化:對于給定影響力傳播模型下的網絡G,設負種子集為SN,并設置一個正整數k。影響塊最大化問題是找到滿足 SP ? V 和 |SP | 的正種子集 SP ≤ k,從而使阻塞影響σ (SP , SN )最大化,即找到最優的正種子集S* P ,使得:

2.2. Properties of the problem
??在IBM問題中,影響函數σ(·)在IC和LT擴散模型下與正集SP是單調且子模的[5]。基于 σ (SP , SN ) 的單調性和子模性,利用貪心算法可以得到 (1 ? 1/e) 的近似解
2.2.1. Monotonicity
定義4.單調性:設f(S)是集合的函數。令 S 和 T 為兩個集合,使得 S ? T 。如果滿足以下方程,函數 f(S) 將隨 S 單調遞增。
![]()
?在 IBM 問題中,σ (SP , SN ) 隨 SP 單調遞增。這意味著當新的種子被添加到正種子集SP 時,不會導致阻塞集IBS(SP , SN )的大小減小。
?
2.2.2. Submodularity
??定義 5. 子模性:設 f (S) 是集合的單調遞增函數。令 S 和 T 為兩個集合,使得 S ? T ? V 。如果滿足以下等式,則函數 f (S) 是 S 的子模函數。

?在 IBM 問題中,子模??性是當向集合 SP 添加新的正種子節點時,σ (SP , SN ) 的邊際增益遞減的屬性。也就是說,對于任意節點 v ∈ V \(SP ∪ SN ),將 v 添加到集合 SP ∪ {v} 中的邊際增益小于或等于 SP 的增益。
? ?為了解決 IBM 問題,貪心法采用蒙特卡羅模擬來計算網絡中每個候選種子節點的邊際增益 v / ε (SP ∪ SN )。貪心法的每一步都會選擇邊際增益最大的節點u加入SP作為新的種子節點:

3. Diffusion models
??最近,網絡科學、計算機科學和流行病學等領域報道了大量關于設計擴散模型的文獻。我們將當前的影響力傳播模型分為三大類:基于獨立級聯的擴散模型、基于線性閾值的擴散模型和基于流行病的擴散模型,在本節中,我們將回顧其中一些常見模型。
3.1. Independent cascade diffusion models

??為了研究想法在社交網絡上傳播的方式,Kempe 等人。 [25]基于概率論中相互作用粒子系統的分析提出了獨立級聯(IC)模型。表1總結了基于獨立級聯的擴散模型的理論分析。在表的第 2 列中,我們顯示了模型中節點的可能狀態。第 3 列描述了模型的特征。
(1) Classical Independent Cascade Model
? ?在經典IC模型下,每次影響力傳播時,每個節點都處于活躍或不活躍狀態。受影響的節點處于活動狀態,不受影響的節點處于非活動狀態。初始時,所有影響源節點都處于活躍狀態。如果節點 u 在步驟 t 受到影響,它會在步驟 t + 1 嘗試影響其不活動的鄰居 v。節點 v 是否會受到其鄰居 u 的影響將獨立于 u 對其他節點的影響結果。此外,該模型假設每個受影響的節點 u 只有一次機會影響其鄰居節點。無論成功與否,你都將不再有機會影響其鄰國。當沒有更多的節點可以受到影響時,這種影響傳播的過程就結束了。此時,受影響節點的集合就是源的影響范圍。經典 IC 模型以離散時間步長運行,如下所示:
?(a) 在時間步 t = 0 時,集合 S 中的所有種子節點都處于活動狀態,V\S 中的所有其他節點都處于非活動狀態。
(b) 如果節點 u 在時間 t 被激活,它將嘗試以概率 pu,v 激活其未激活的鄰居節點 v。如果節點 v 被成功激活,則節點 v 在時間 t + 1 處轉入激活狀態。
(c) 這種擴散過程結束,直到不再有節點可以被激活。基于這種經典的IC模型,針對不同類型的網絡和應用,人們提出了許多擴展的IC模型。在這些擴展 IC 模型中,離散時間步驟 (a) 和 (c) 與經典 IC 模型中的離散時間步驟相同,而步驟 (b) 具有不同的操作。
(2) Competitive Independent Cascade Model
? ?陳等人。 [26]將 IC 模型擴展到競爭性社交網絡,其中正面和負面影響在網絡中同時傳播。他們提出了競爭獨立級聯(CIC)模型,其中每個節點都處于非活動、正激活或負激活狀態。在時間步 t = 0 時,所有正(負)種子節點均處于正(負)活動狀態,所有其他節點均處于非活動狀態。在 CIC 模型下,在時間 t 受到正面(或負面)影響激活的節點 u 將嘗試以概率 pP u,v (或 pN u,v)激活其未激活的鄰居節點 v。如果節點 v 被成功激活,則節點 v 在 t + 1 時刻將處于正向(或負向)狀態。如果節點 v 受到正向和負向影響同時激活,則節點 v 在 t 時刻將處于負向激活狀態+ 1。
(3) Homogeneous Competitive Independent Cascade Model
??陳等人。 [26]提出了同質競爭獨立級聯(HCIC),以簡化 CIC 模型中的概率設置。 HCIC 模型假設正面和負面影響在社交網絡中的每條邊 (u, v) 上具有相同的傳播概率 pu,v,即對于 eu,v ∈ E,pP u,v = pN u,v =浦河谷在每個時間步,每個節點都處于非活動、正激活或負激活狀態。在時間步 t = 0 時,所有正(負)種子節點均處于正(負)活動狀態,所有其他節點均處于非活動狀態。在時間 t 受到正面(或負面)影響激活的節點 u 將嘗試以概率 pu,v 激活其不活動的鄰居節點 v。如果節點v被成功激活,那么節點v在t+1時刻將處于正向(或負向)激活狀態。如果節點v同時受到正向和負向影響激活,則節點v在t+1時刻將處于負向激活狀態t + 1。
??(4) Peer-to-Peer Independent Cascade Model
? ?童等人。 [27]擴展了IC模型并提出了點對點IC(PIC)模型,該模型假設有q個級聯C1,C2,…。 。 。 ,網絡中的Cq。第 i 個級聯 Ci 由其自己的種子集 Si 生成。此外,還存在由負種子集 SN 生成的負級聯 CN 。在每個時間步,每個節點都處于以下狀態之一:非活動狀態、第 i 個正激活狀態(i = 1, 2, ..., q)或負激活狀態。在時間步 t = 0 時,所有第 i 個正(負)種子節點均處于第 i 個正(負)活動狀態,所有其他節點均處于非活動狀態。在PIC模型下,在時間t處于第i個正(負)活動狀態的節點u將隨機選擇一個不活動的鄰居節點v來以概率pu,v激活它。如果節點 v 被成功激活,它將在 t + 1 時刻轉入第 i 個正(負)激活狀態。如果節點 v 被兩個或多個不同激活狀態的鄰居成功激活,則它將處于激活狀態最高優先級級聯在時間 t + 1 處獲得最高優先級。
(5) Multi-Campaign Independent Cascade Model
? ?布達克等人。 [6]還考慮到社交網絡中可能存在同時傳播的積極和消極影響,并在經典IC模型的基礎上提出了多活動獨立級聯模型(MCICM)。該模型假設,雖然負面影響開始從網絡中的一個節點傳播,但正面影響也可以傳播到網絡的其他地方,并抵消負面影響的影響。在每個時間步,每個節點都處于非活動、正激活或負激活狀態。在時間步 t = 0 時,所有正(負)種子節點均處于正(負)活動狀態,所有其他節點均處于非活動狀態。在 MCICM 模型中的每個時間步,每個節點都處于非活動、正激活或負激活狀態。在時間 t 受到正面(或負面)影響激活的節點 u 將嘗試以概率 pP u,v (或 pN u,v)激活其不活動的鄰居節點 v。如果節點v被成功激活,則節點v將在t+1時刻變為正值(或負值)。如果兩個或多個節點同時嘗試激活節點v,則最多有一個節點可以成功激活它。只要該節點被激活,其狀態就不再改變。
(6) Campaign-Oblivious Independent Cascade Model
? ?Budak 等人基于 MCICM 模型。 [6]提出了Campaign-Oblivious Independent Cascade Model (COICM),其中正面和負面影響通過每條邊傳播的概率相同。對于到達節點 u 的正面和負面影響,節點 u 以概率 pu,v 激活其鄰居節點 v。在每個時間步,每個節點都處于非活動、正激活或負激活狀態。在時間步 t = 0 時,所有正(負)種子節點均處于正(負)活動狀態,所有其他節點均處于非活動狀態。在時間 t 受到正面(或負面)影響激活的節點 u 將嘗試以概率 pu,v 激活其不活動的鄰居節點 v。如果節點v被成功激活,則節點v將在t+1時刻變為正值(或負值)。如果兩個或多個節點同時嘗試激活節點v,則最多有一個節點可以成功激活它。只要該節點 v 被激活,它的狀態就不再改變。
(7) Temporal Campaign-Oblivious Independent Cascade Model
? ?馬努切里等人。 [28]引入了社交網絡中的節點登錄因素,并提出了Temporal CampaignOblivious獨立級聯模型(TCO-ICM)。 TCO-ICM將節點在每個時刻的登錄概率login(v) ∈ [0, 1]添加到COICM模型中。在TCO-ICM中,每個節點只有在登錄后才能激活其鄰居節點。在每個時間步,每個節點都處于非激活、正激活或負激活狀態。在時間步 t = 0 時,所有正(負)種子節點均處于正(負)活動狀態,所有其他節點均處于非活動狀態。在時間 t 受到正面(或負面)影響激活的節點 u 將嘗試以登錄(u)× pu,v 的概率激活其不活動的鄰居節點 v。如果節點 v 被成功激活,則節點 v 將在 t + 1 時刻變為正值(或負值)。如果節點 v 被正負影響同時激活,則節點 v 將在 t + 1 時刻變為正值。
(8) Independent Cascade Diffusion Model in Signed Network
??劉等人。 [29]提出了符號網絡中的獨立級聯擴散模型(SNIC),以描述符號網絡中兩種影響的傳播。簽名網絡中的節點具有三種狀態:非活動狀態、正激活狀態和負激活狀態。在帶符號的網絡中,每條邊都有一個正號“+”或一個負號“-”。帶有正號的邊意味著它所連接的節點具有正向關系,例如朋友或伙伴。帶有負號的邊意味著它所連接的節點具有負面關系,例如競爭對手或敵人。假設邊 eu,v 具有符號“+”,并且節點 u 在時間 t 被正(或負)激活,它將嘗試以概率 pu,v 激活其不活動的鄰居節點 v。如果節點 v 被成功激活,則節點 v 在時間步 t + 1 內將處于正(或負)激活狀態。假設邊 eu,v 的符號為“-”,節點 u 為正(或負)激活狀態節點 v 在時間 t 被激活,如果它的非活動鄰居節點 v 被成功激活,則節點 v 在時間 t + 1 時將處于負(或正)激活狀態。如果節點 v 在同時,節點 v 將在時間 t + 1 時隨機轉變為正激活狀態或負激活狀態。
(9) Time-dependent Comprehensive Cascade Model
??考慮到社交網絡中信息傳播的動態性質,Hao 等人。 [30]在經典IC模型的基礎上提出了時間相關綜合級聯(TCC)模型。 TCC模型假設網絡是動態的,并將網絡劃分為T個離散時間戳。 t 時刻的網絡表示為 Gt = (Vt , Et ), t ∈ {1, . 。 。 , T },其中每個時間戳 t 中的單個 ut 只能以 Put ,vt 的概率嘗試激活處于非活動狀態的鄰居 vt 一次。 TCC模型根據t時刻之前的歷史活動來設置節點u激活節點v的概率。
在這里,|V|是網絡中節點的數量,K 是狀態變化率的可調參數,|St |是到時間 t 為止未能激活節點 v 的節點數量,fut ,vt 是節點 u 在時間 t 對 v 的影響。?
3.2. Linear threshold diffusion models

??在IC模型中,不活躍節點是否被激活取決于特定的鄰居,而不是由其所有鄰居的共同影響來激活。在現實世界的應用中,如果大多數人周圍有更多接受某種觀點的鄰居,他們就更有可能接受某種觀點。一個人對某種觀點的接受可以被描述為社交網絡中節點的激活,并且一個節點被激活的趨勢隨著更多其鄰近節點被激活而單調增加。也就是說,隨著時間的推移,如果越來越多的節點u的鄰居被激活,則節點u更有可能被激活。線性閾值模型(LT)被提出來精確模擬這種現象。在線性閾值(LT)模型中,網絡中的不同節點有不同的激活閾值。其他模型,例如IC模型,沒有這樣的激活每個節點的閾值,它們隱含地假設所有節點具有相同的激活閾值。因此,LT模型能夠更準確地反映社交網絡中傳播影響力下節點的狀態。 LT模型的另一個優點是,一個節點是否被激活并不取決于一個鄰居的影響,而是取決于其所有鄰居的綜合影響。在其他模型中,例如 IC 模型,節點僅由其鄰居之一激活,而不是由其所有鄰居的聯合效應激活。表2總結了線性閾值模型的理論分析。在表的第2列中,我們分析了模型中節點的可能狀態。第 3 列描述了模型的特征。
(1) Classical Linear Threshold Model
??肯佩等人。 [25]提出了線性閾值(LT)模型。 LT 模型的主要思想是,如果一個不活動的節點有足夠數量的鄰居處于活動狀態,則該節點可以被激活。具體來說,圖 G 中的每個有向邊 eu,v 有權重 bu,v ≤ 1。他們用 Nin(v) 表示節點 v 的近鄰集合。每條邊 (u, v) 上的權重 bu,v 滿足 Σ u∈Nin(v) bu, v ≤ 1。在每個時間步,每個節點都處于非活動或激活狀態。此外,每個節點 v 都有一個閾值 θv ∈ [0, 1] 指示其對信息的接受程度。設 St 為 t 時刻激活節點的集合,當滿足 Σ u∈Nin(v)∩St bu,v ≥ θv 時,非激活節點被激活。只要該節點被激活,其狀態就不再改變。
??經典 LT 模型以離散時間步長運行,如下所示:
(a) 在時間步長 t = 0 時,令 S0 為種子節點集。 S0 中的節點處于活動狀態,所有其他節點處于非活動狀態(種子集)。
(b) 在時間步長 t ≥ 1 時,令 St?1 為在時間步長 t ? 1 之前或在時間步長 t ? 1 時激活的節點的集合。如果滿足以下條件,則非活動節點 v 將被激活: Σ u∈Nin(v)∩St?1 bu,v ≥ θv 。
(c) 當沒有更多的節點可以被激活時,擴散過程結束。
(2) Competitive Linear Threshold Model
? ?他等人。文獻[5]在經典LT模型的基礎上提出了競爭線性閾值(CLT)模型,該模型假設正向和負向影響可以同時在網絡中傳播,并且正向影響可以抵消負向影響。在CLT模型中,節點具有三種狀態:非活動狀態、正激活狀態和負激活狀態。 CLT模型中的每個節點v都有一個正激活閾值θ p v 和負激活閾值θ n v ,分別代表節點對正信息和負信息的接受閾值,θ p v 和θ n v 是從[0 ,1]。每個有向邊 eu,v 還具有權重 bp u,v 和權重 bn u,v,分別表示邊 eu,v 傳播正向影響和負向影響的概率。在時間步 t ≥ 1 時,如果不活動節點 v 滿足 Σ u∈Nin(v)∩Sn bn u,v ≥ θ n v ,則該節點 v 將被負激活。如果節點 v 滿足 Σ u∈Nin(v)∩SP bp u,v ≥ θ p v ,則節點 v 將被積極激活。這里,SN和SP分別是當前正向激活和負向激活的節點的集合。如果節點v同時滿足正激活和負激活條件,則節點v被負激活。在時間 t 負(正)激活的節點加入集合 SN(SP ),并保持負(正)激活狀態。
(3) Competitive Activation Model
?基于經典的 CLT 模型,Zhang 等人。 [31]提出了競爭激活(CA)模型,考慮到社交網絡中的不同用戶往往有不同的受到負面影響的概率。 CA模型引入了偏好參數Pf i v來確定節點v被激活的具體影響。該偏好參數定義為 Pf i v= ( Σ u∈Nin(v)∩S bn u,v ) /θ i v, i ∈ {P, N}。在CA模型中,節點具有三種狀態:不活動狀態、正激活狀態和負激活狀態。在時間步 t = 0 時,正(負)種子集 SP (SN ) 中的節點處于正(負)激活狀態。所有其他節點均處于非活動狀態。在時間步 t ≥ 1 時,如果滿足 Σ u∈Nin(v)∩Sp bp u,v ≥ θ p v ,則失活節點 v 將被主動激活。如果節點 v 滿足 Σ u∈Nin(v)∩Sn bn u,v ≥ θ n v ,那么它將被負激活。當節點v同時滿足正激活和負激活條件時,如果Pf P v ≥ Pf N v則節點v被正激活,反之亦然。正(負)激活的節點加入集合 SP(SN ),并將對其鄰居節點產生正(負)影響。
(4) Linear Threshold Model with One Direction State Transition
??楊等人。 [8]提出了具有單向狀態轉移的線性閾值模型(LT1DT),用于對同一網絡中的兩種競爭影響傳播進行建模。該模型考慮到用戶接受真相的概率會隨著許多復雜的社會因素而變化,并且用戶被負面消息激活的狀態可能會發生逆轉。因此,為每個節點設置影響閾值和決策閾值,影響閾值和決策閾值在激活不活躍節點或說服激活的消極節點將其信念轉變為事實時的不同階段生效。在 LT1DT 模型中,每個節點在每一步都有三種可選狀態:非活動狀態、正激活狀態或負激活狀態。在每個時間步,每個節點都使用自己的節點級自動機來決定它轉換到哪個狀態。節點的狀態轉換取決于其當前狀態及其受到的影響。除了對未激活節點進行激活過程外,同時對消極激活節點進行重新考慮過程。
(5) Multiple Topics Linear Threshold Model
??范等人。 [32]研究了社交網絡中多種類型信息的同時傳播,并在經典LT模型的基礎上提出了多主題線性閾值(MT-LT)模型。 MT-LT模型包含多個不沖突的信息源,因此MT-LT模型中的節點可以同時具有多個狀態。例如,MT-LT模型假設有q個政治、經濟、體育等主題,Si是主題i激活的節點集合。由于每個節點可以被不同的主題激活多次,因此節點的狀態由集合 Q = {inactive, active1, active2,... 表示。 。 。 , 活躍q }。如果節點u沒有被任何topic激活,則處于inactive狀態;如果u已被主題i激活,則處于activei狀態。如果節點u已被主題i和k激活,則其狀態處于activei和activek。不同的節點對不同的主題有不同的接受度,因此節點 u 被分配一組激活閾值 θu = {θ 1 u , θ2 u ,...。 。 。 , θq u },其中 θ i u ∈ [0, 1]。 θ i u 表示節點 u 對主題 i 的激活閾值。他們認為節點u對節點v的影響不僅與邊權值bu,v有關??,還與節點u本身對于不同主題的傳播能量有關。因此,每個節點 u 也被分配一個向量 Pu = {p1 u, p2 u,...。 。 。 , pq u },其中 pi u ∈ [0, 1] 表示主題 i 對其鄰居節點的影響。令Si為處于activei狀態的節點的集合。在每個時間步,當前未被 Si 激活的節點 u 如果滿足: Σ u∈Nin(v)∩Si bu,v × pi u ≥ θi v,則將變為激活 i。
(6) Weight-Proportional Competitive Linear Threshold Model
??鮑羅丁等人。 [33,34]考慮到網絡中影響力傳播存在競爭,節點的激活需要考慮兩個競爭方,提出了權重比例競爭線性閾值(WPCLT)模型。 WPCLT模型假設網絡中存在兩種類型的影響力,并且它們彼此之間處于競爭關系。設 Si 為 i 類影響力 (i = 1, 2) 激活的節點集合,并令 S = S1 ∪ S2。 WPCLT模型中的節點存在三種狀態:未激活、受影響和激活。節點可以通過兩種方式受到 S1 或 S2 的影響而激活。設節點 v 的激活閾值為 θv,Ai t?1 為 t ? 1 時刻之前第 i 類影響力(i = 1, 2)激活的節點集合,At?1 為激活的節點集合在時刻 t ? 1 之前。在每個時間步,如果不活動節點 v 滿足 Σ u∈Nin(v)∩S bu,v ≥ θv,則將其轉換為受影響狀態。然后,受影響的節點 v 將被第 i 類 (i = 1, 2) 影響激活,概率為 Σ u∈Ai t?1 bu,v / Σ u∈At?1 bu,v 。
(7) K -Linear Threshold Model
??盧等人。 [34]考慮了社交網絡影響力傳播的多元競爭性,在經典LT模型的基礎上提出了K線性閾值(K -LT)模型。 K-LT模型將影響力分為K類,節點的激活狀態也分為K類。這樣,影響力傳播過程中的不活躍節點可以同時受到不同類別的活躍節點的影響。與WPCLT模型類似,K-LT模型中的節點具有三種狀態,并且可以通過K種方式激活。令 Ai t?1 為在時間 t ? 1 結束時受 i 類影響激活的節點集合,At?1 為在時間 t ? 1 結束時激活的節點集合。時間步長,如果滿足條件 Σ u∈Nin(v)∩S bu,v ≥ θv,則非活動節點 v 轉變為受影響狀態。然后,受影響的節點 v 將被第 i 類影響激活,概率為 Σ u∈Ai t ?1 \Ai t?2 bu,v / Σ u∈At?1\At?2 bu,v 。
(8) Dynamic Linear Threshold
??李等人。 [35]提出了一種動態線性閾值(DLT)模型,考慮到隨著時間的推移同時傳播和演化的競爭思想。他們估計用戶u對鄰居v的影響不僅基于兩個節點之間的邊權重,還基于時間范圍。他們假設存在一個鄰居最有可能受到影響的時間窗口。此外,與經典的LT模型不同,DLT模型允許用戶根據鄰居的影響改變他們之前的想法。具體來說,放棄rv表示用戶v對放棄已經采納的觀點(可信的或錯誤信息)的懷疑,并且它隨著時間的推移動態更新。表現出高度放棄的用戶在采用和傳播信息時持懷疑態度,而放棄率低的用戶則不太不愿意。在時間步 t,每個受到負面或正面影響的用戶 u 以概率 IF (v|t) 影響其不活動的鄰居 v,該概率是基于邊緣的權重和時間窗口 t 估計的。用戶 v 根據其鄰居的影響而采取信念。如果負面/正面影響超過放棄閾值rv,則用戶v被感染。如果正面影響和負面影響都超過放棄閾值,則節點的狀態不會改變。受到負面影響或正面影響的用戶將被添加到可信組或受感染組中,并且放棄閾值 rv 會被更新。
3.3. Diffusion models based on epidemic
??流行病模型是對傳染病或病毒在人群中傳播的研究。人們發現傳染病的傳播更類似于網絡中影響力的傳播,因此現在也擴展到對信息和影響力的傳播進行建模。經典流行病模型根據節點的狀態對節點進行分類,如易感(S)、感染(I)、康復(R)等,然后根據可行的狀態轉移定義不同的模型。在這篇綜述中,我們將基于流行病的傳播模型分為基于三態的影響力傳播模型(示意圖如圖2所示)、基于四態的傳播模型(示意圖如圖3所示)和基于四態的影響傳播模型。基于節點狀態數量的基于多狀態的傳播模型(示意圖如圖4所示))。
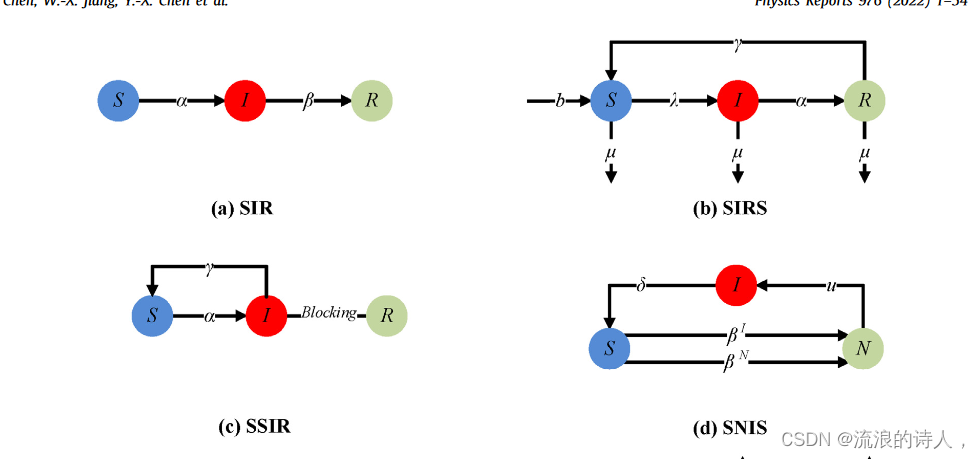
 3.3.1. Three states epidemical models
3.3.1. Three states epidemical models
(1) Classical Susceptible–Infected–Recovered Model
??1927 年,Kermack 等人。 [36]首先應用流行病學模型來研究傳染病的傳播,并開發了易感-感染-康復(SIR)流行病學區室模型。 SIR傳播模型將節點分為三種狀態(如圖2(a)所示):易感者(S),易受病毒感染;感染者(I),接觸病毒后被感染并傳播;康復者 (R) 已從感染中康復。 SIR模型的傳播規則如下:
(1) 被感染節點以概率 α 嘗試感染處于易感狀態 S 的節點,被感染的易感節點的狀態由 S 變為被感染狀態 I。
(2) 被感染節點的狀態由 I 變為恢復狀態R與恢復率β。
(2) Susceptible–Infected–Recovered–Susceptible Model with Birth and Death Rates
??李等人。 [37]提出了一種具有出生率和死亡率的易感-感染-恢復-易感(SIRS)流行病模型來研究復雜異構網絡中的病毒傳播。該模型中,節點狀態主要分為易感(S)、感染(I)和康復(R),其中自然出生和死亡與節點密度成正比,出生率b > 0,死亡率μ > 0(如圖2(b)所示)。 SIRS模型的傳播規則如下:
(1) 易感節點以概率 λ 轉變為感染狀態 I,并以概率 b 產生出生率,以概率 μ 產生死亡率。
(2) 感染節點以概率α轉移到恢復狀態R,且自身存在概率μ的死亡率。
(3) 恢復節點以概率γ轉移到易感S,并以概率μ發生死亡率。
(3) Supervising–Susceptible–Infected–Recovered Model
??譚等人。 [38]通過考慮信息傳播過程中的人為干預因素改進了經典的SIR模型,提出了監督-易感-感染-康復(SSIR)模型。他們認為被感染的節點可以通過自我修復變回易受影響的狀態,而傳播者將完全失去傳播信息的能力,然后通過人為干預改變到恢復的節點。該模型將節點的狀態分為三類(如圖2(c)所示):易感(S)、感染(I)和恢復(R)。 SSIR模型的傳播規則如下:
??(1) 當易感節點暴露于感染節點時,它會以概率α轉變為感染節點。
(2) 被感染的節點會以自愈率γ變回易感節點。
(3)被感染的節點受到隨機的人為干預。一旦被感染的節點被人為干預,該節點就會轉變為恢復節點。
(4) Incubation Epidemic Spreading Model with Continuous Detection
??于等人。 [39]提出了一種具有傳染性潛伏期的新型易感者-感染者-易感流行病(SNIS)模型。該模型在有向網絡和異構網絡上使用 N 交織平均場近似。該模型主要考慮傳染病潛伏期對病毒傳播的影響,即節點不具有傳染性最初是在接觸疾病后。但隨著時間的推移,節點會變得具有傳染性。他們將節點分為三種主要狀態(如圖2(d)所示):易感(S)、傳染性孵化但傳染性(N)和感染(I)。
SNIS模型的傳播規則如下:
(1)易感個體可能被感染者或暴露者感染,感染率分別為βI或βN。
(2) 狀態N的個體在一段時間后以概率u轉變為感染狀態I。
(3) 感染者將以概率 δ 被治愈并轉變為易感狀態 S。
(5) Unknown–Dissemination–Immune Model
??張等人。 [40]考慮了耦合社交網絡中信息的擴散效應,在經典SIR模型的基礎上提出了SI3R模型。 SI3R模型添加了獨立和跨網絡傳播者兩種新型節點狀態,以增強信息傳播。他們將節點分為三種主要狀態(如圖2(e)所示):未暴露于輿論的未知節點(S)、傳播節點包括網絡中的節點。子狀態獨立傳播(I1)、網內傳播(I2)和跨網傳播(I3),以及現在對任何輿情內容不感興趣或傳播信息后免疫的節點(R)
SI3R模型的傳播規則如下:
(1) 對于不感興趣的信息,未知個體將以概率α3變為免疫狀態R。
(2) 未知個體將以轉移概率α1成為獨立傳播狀態節點I1。處于狀態 I1 的節點會將信息傳播到網絡中的鄰居。未知個體將成為網絡間傳播節點I2,轉移概率為α2。處于狀態 I2 的節點不僅對其網絡中的影響感興趣,而且還具有向其他耦合網絡傳播信息的能力。
(3) 跨網傳播節點I2將以傳播概率β轉變為跨網傳播節點狀態I3。
(4) 隨著時間的推移,具有不同狀態 I1、I2 和 I3 的節點將分別以概率 λ1、λ2 和 λ3 變為免疫狀態 R。
(6) 2Spreaders–Ignorant–Stifler Model
王等人。 [41]考慮到同構網絡中存在兩個及以上負面影響的異花授粉,提出了2SI2R影響傳播模型。他們假設網絡中傳播著兩種負面影響,稱為謠言1和謠言2。此外,他們將節點分為三種狀態(如圖2(f)所示):無知(I),沒有聽說過謠言,容易被謠言告知;傳播者(包括傳播者1(S1)和吊具 2 (S2)) 和節流器(包括節流器 1 (R1) 和節流器 2 (R2))。其中,S1和S2分別是傳播Rumor1和Rumor2的個體的集合。 R1 和 R2 分別是聽過謠言 1 和謠言 2 但不會再傳播的個體的集合。 2SI2R模型的傳播規則如下:
(1) 當無知的個體接觸負面影響傳播者 S1 和 S2 時,其成為負面影響傳播者的概率分別為 λ1 和 λ2。 (2) 當一個吊具與另一個吊具接觸時,前者會成為抑制器。同時,當吊具與節流器接觸時,吊具以α + δ 的概率成為節流器。 (3) 所有節點將以概率 g 自主退出網絡。 (4) 如果傳播器S2的傳播能力比傳播器S1強,則傳播器S1與傳播器S2接觸時,會以概率β變為傳播器S2;當節流器 R1 與吊具 S2 接觸時,將以概率 γ 切換到吊具 S2 。
(7) Spreader–Ignorant–Stifler1–Stifler2 Model
王等人。 [42]開發了一種稱為傳播者-無知-Stifler1-Stifler2(SIRaRu)的新傳播模型,其中當無知的個體接觸到負面信息時,他或她要么受到其影響而成為傳播者,要么轉變為傳播者,并且不再傳播負面信息。該模型還采用了遺忘機制,并假設傳播者能夠以一定的概率轉化為負面信息的抑制者。他們將節點分為三種主要狀態(如圖2(g)所示):無知(I),傳播者(S),停滯者(stifler1(Ra)和stifler2(Ru))。其中Ra是接受負面信息但不傳播的人,Ru是不接受負面信息的人。 SIRaRu模型的傳播規則如下:
(1) 一個無知個體在狀態 S 下成為傳播者的概率為 λ,在狀態 Ra 下成為傳播者 1 的概率為 γ;或者在狀態 Ru 下成為 stifler2 的概率 β,其中 λ + β + γ = 1。 (2) 傳播個體在暴露于傳播者、stifler1 或 stifler2 后,將以概率 α 轉變為狀態 Ra 中的 stifler1。另外,模型中存在遺忘機制,傳播者會以概率 δ 直接轉變為 Ra 狀態下的 stifler1。
(8) Spreading Model Considering the Public Opinion Environmental Factor
??潘等人。 [43]設計了影響力傳播模型(S2IM),該模型考慮了有利于傳播的輿論環境。該模型將節點分為三類:確信個體(I1)、客觀個體(I2)和未知個體(S)。模型中加入了輿論環境因子M,它會同時受到I1和I2的影響。此外,該模型還具有I1、I2和M的衰減衰減,衰減率分別為u、v和k(如圖2(h)所示)。 S2IM模型的傳播規則如下:
(1) 當未知節點與確信節點接觸時,未知節點會以概率 a 轉變為確信狀態 I1,并且在轉變過程中會受到觀點環境因子 M 的影響。
(2)當未知節點與客觀節點接觸時,未知節點將以概率b轉變為客觀狀態I2,并且在轉變過程中不會受到輿論環境因素M的影響。
(3) 確信節點和客觀節點將分別以衰減率 u 和 v 轉變為未知狀態 S。
(4) 當目標節點與確信節點接觸時,目標節點將以概率 c 轉變為確信狀態 I1。
(5) 輿論環境影響的程度會受到確信節點和客觀節點的影響,概率分別為r1和r2。而且輿論環境的影響程度也會以概率k下降。

3.3.2. Four states epidemical models
(1) Susceptible–Exposed–Infected–Removed Model
?在現實網絡中,個體由于自身特點或社會因素,在接觸到負面信息時,會處于優柔寡斷的狀態,因為他們不確定信息是否正確。因此,它們有可能變成感染節點或者變成不受影響的節點。基于此,劉等人。 [44]提出了一種新的易感-暴露-感染-移除(SEIR)影響傳播模型,將節點分為四類(如圖3(a)所示):易感(S)是那些尚未感染的節點信息中,暴露(E)的是那些已經被感染,但不散布謠言的人,被感染(I),被移除(R)。
SEIR模型的傳播規則如下:
(1)易感個體在與感染節點接觸后,將以概率λ轉變為暴露狀態E。
(2) 暴露個體以β(1?h)的概率被治愈,并轉變為去除狀態R。也可能以βh的概率轉變為感染狀態I。
(3) 被感染個體將以概率 δ(1 ? m) 被治愈并轉變為移除狀態 R。它也將以概率 δm 重新轉移回暴露狀態 E。
(2) Improve Susceptible–Infected–Quarantined–Recovered Model
在實際網絡中,往往會因病毒等負面影響的突然爆發而導致隔離措施滯后,導致隔離效果不佳。為了解決這個問題,Li 等人。 [45]在SIQR模型[46]的基礎上考慮無效隔離因素,開發了一種改進易感-感染-隔離-恢復(Improve-SIQR)模型,該模型具有新的加入率和非自愿退出率。該模型將節點分為四類(如圖3(b)所示):易感(S)、感染(I)、隔離(Q)和恢復(R)。
Improve-SIQR模型的傳播規則如下:
(1)可以將節點以新加入率b加入到易受影響的節點集合中。易受影響的節點可以以概率 d 自主退出該狀態。易受影響的節點可以以概率 m 轉換為隔離節點。一些易感節點可能會因傳播率λ和接觸率β的影響而轉變為感染節點。
(2) 感染節點可以以概率 p 自主退出狀態,并以概率 α 轉變為隔離狀態 Q。
(3) 隔離節點無法轉變為恢復節點并退出的概率為γ,隔離節點成功轉變為恢復狀態R的概率為μ。每個被隔離節點自主退出網絡的概率為δ。
(4) 隔離節點轉變為恢復狀態R后,不會再被感染,恢復的節點也會以概率δ自主退出網絡。
(3) Susceptible–Infective–Counterattack–Refractory Model
??贊等人。 [47]考慮了反擊機制對負面信息傳播的影響,提出了易感-感染-反擊-難治(SICR)模型。該模型在經典SIR模型的基礎上增加了一類反攻擊者節點來反駁負面信息。 SICR模型將節點分為四類(如圖3(c)所示):易感性(S)、感染性(I)、反擊性(C)和難治性(R)。其中,頑固節點是那些聽到謠言但失去傳播謠言興趣的人。一旦節點轉變為反擊狀態,該節點的狀態將不會再次改變,直到傳播結束。
SICR模型的傳播規則如下:
(1)當易感節點接觸感染節點時,易感節點可能會出現三種結果:以概率α成為感染節點;成為難熔節點的概率為β;成為反擊節點的概率為 θ 。我們假設狀態 C 是一個常量狀態,即一旦節點變為狀態 C ,它將保持狀態 C 直到結束,這與狀態 R 類似。
(2) 當一個感染節點接觸另一個感染節點或難治節點時,它以概率 γ 變為難治狀態 R 。
(3) 如果反擊節點有感染性鄰居節點,則感染性鄰居以概率 η 變為難治狀態 R。
(4) Credulous–Spreader–Rumor Killer–Recovery Model
李等人。 [48]提出了一種Credulous-Spreader-Rumor Killer-Recovery(CSER)影響力傳播模型,考慮到網絡中存在一些類似于警察的節點,通過某種策略控制負面信息的傳播。該模型將節點分為四類(如圖3(d)所示):輕信者(C)、傳播者(S)、謠言殺手(E)和理性者(R)。 CSER模型的傳播規則如下:
(1) 當輕信個體接觸傳播者時,輕信個體將以概率 λ 轉變為傳播狀態 S。同時,如果輕信的個體對負面信息不感興趣,他/她將以概率β轉變為理性狀態R。
(2)當傳播者在傳播負面影響的過程中接觸到謠言殺手時,就會以概率α轉變為謠言殺手狀態E,并積極嘗試阻止負面信息的進一步傳播。
(3)如果傳播者在傳播過程中對負面信息失去興趣,就會以概率δ轉變為理性狀態R。此外,當一個傳播者與其他傳播者、謠言殺手或理性者進行交流時,他們會以概率 σ 轉化為理性狀態 R 。
(5) Susceptible–Infected–Hibernator–Removed Model
趙等人。 [49]考慮了遺忘和記憶機制對影響傳播的影響,在經典SIR模型的基礎上提出了易感-感染-冬眠者-移除模型(SIHR)模型。 SIHR模型將節點分為四類(如圖3(e)所示):易感者(S)、感染者(I)、冬眠者(H)和移除者(R)。該模型添加了從易感性到恢復狀態的直接聯系。還添加了一組新的冬眠者來體現遺忘和記憶機制。 SIHR模型的傳播規則如下:
(1) 當易感節點與感染節點接觸時,易感節點將分別以概率 λ 和 β 轉變為感染狀態 I 和恢復狀態 R。
(2) 為了體現遺忘機制,受感染節點將以遺忘概率δ轉變為休眠狀態H。另外,為了體現記憶機制,冬眠節點會以自發記憶概率 ψ 轉變為感染狀態 I。如果休眠節點接觸到傳播節點,它將轉變為感染狀態 I,喚醒記憶率概率為 η。
(3)當一個感染節點與另一個感染節點、休眠節點或恢復節點接觸時,它會以概率α轉變為恢復狀態R。
(6) Susceptible–Indifferent–Propagating–Recovery Model
朱等人。 [50]提出了基于沉默機制的敏感-無關-傳播-恢復(SAIR)模型。該模型監控網絡中的負面信息,進而防止某些節點受到負面信息的影響。該模型將節點分為四類(如圖3(f)所示):易受影響(S)、無關(A)、傳播者(I)和恢復者(R)。冷漠的個體相信負面信息,但不傳播它。 SAIR模型的傳播規則如下:
(1) 新個體以概率 B 進入網絡,處于網絡不同狀態的個體以相同的概率 μ 移出網絡。
(2) 冷漠個體和擴散個體有自主恢復概率ρ。
(3)易感個體分別以概率θ1和θ2轉移到無差異狀態A和傳播狀態I。易受影響的個體以 1 ? θ1 ? θ2 的概率轉移到恢復狀態 R。另外,從傳播個體到易感個體的傳播率為φ。
(4) 受強制沉默策略影響的傳播者將以 h 的概率進入冷漠狀態 A。
(7) Ignorant–Weak spreader–Strong spreader–Removal Model
??冉等人。 [51]提出了基于個體興趣程度差異和虛假信息機制的無知-弱傳播者-強傳播者-移除(IWSR)模型。他們認為個體對同一信息有不同的興趣,可以主動傳播它,否則他們可能對該信息不感興趣,成為弱傳播者。該模型根據節點的通信方式將節點分為四種狀態(如圖3(g)所示):無知(I)、弱傳播者(W)、強傳播者(S)和恢復(R)。
IWSR模型的傳播規則如下:
(1)網絡中的新個體以概率δ變得無知。
(2)強傳播者在不同信息的影響下以概率β轉變為弱傳播者。
(3) 強傳播者以概率 λ2 影響無知者成為強傳播者;弱傳播者以概率 λ1 影響無知者成為弱傳播者。
(4) 傳播者以概率 α 停止傳播負面影響,進入狀態 R。
(5) 處于網絡不同狀態的個體可能以概率 δ 移出網絡
(8) Ignorant–Spreader–Recovery–Critical Model
王等人。 [52]觀察到,一個人在多次受到負面信息的影響后,可能會成為負面影響傳播者。他們提出了一種基于自進化機制的無知-傳播-恢復-關鍵(ISRC)影響傳播模型。該模型將節點分為四類(如圖3(h)所示):無知者(I)、傳播者(S)、批評者(C)和恢復者(R)。 ISRC模型的傳播規則如下:
(1)當無知的個體接觸到傳播者時,他們會以概率α變成傳播者。同時,無知者具有自我凈化機制,會以a2+b2的概率轉變為批評狀態C;無知者也會以a1+b1的概率改變到恢復狀態R。
(2)批評者將以概率β改變到恢復狀態R。但隨著批評者接觸到越來越多的負面信息,批評者將以概率a3轉變為傳播者狀態S。
(3) 吊具將以θ + β 的概率改變到恢復狀態R。
(9) Disseminate & Discriminate–Spread–Exposed–Ignorant–Recover Model
李等人。 [53]提出了一種基于用戶傳播能力和判別能力的動態信息傳播模型,稱為傳播和辨別-傳播-暴露無知-恢復(DDSEIR)。 DDSEIR模型將節點分為四類(如圖3(i)所示):ignorant(I)、expose(E)、spreader(S)和recover(R)。 DDSEIR模型的傳播規則如下:
(1) 當無知節點與高級身份傳播者接觸時,將以概率 p 轉變為暴露狀態 E。類似地,當一個無知的節點與一個共同的身份傳播者接觸時,它會以 (1 ? p)α 的概率轉變為暴露狀態 E。其中,p和1?p分別為高級用戶和普通用戶占用戶總數的比例。 (2) 暴露節點會對接收到的信息進行識別,如果判斷是否定的,則直接以概率 ω(1 ? F ) 轉變為恢復狀態 R。如果結果不為負,則以概率 ωF 轉變為擴散狀態 S。 (3)如果傳播者遇到了那些已經收到信息的人(E、R、S狀態),則它以概率α轉入恢復狀態R,因為用戶評估該信息沒有價值。在自衛機制下,傳播者可能會忘記其傳播信息的動機。如果信息偽裝得很好,導致用戶難以做出是否發送的決定,則傳播者將以概率δm轉入暴露狀態E,并繼續規則2)中的過程,否則將轉入恢復狀態 R 的概率為 δ(1?m)。
3.3.3. Multiple states epidemical models

(1) Ignorant–Latent–Spreader–Cooled–Removed Model
??陳等人。 [54]提出了一種稱為無知-潛在-傳播-冷卻-移除(ILSCR)的影響傳播模型來控制緊急情況下的負面影響傳播。該模型認為,傳播者在成為窒息者之前可能會經歷一段冷靜期,而且人員流動主要集中在某一區域。 ILSCR模型將節點分為五類(如圖4(a)所示):無知者(I)對負面信息一無所知,潛伏者(L)在接觸負面信息后無法立即做出決定,負面信息傳播者(S)、通過本地信息確認負面信息捏造后停止向他人傳播負面信息的冷酷者(C)、屬于被剔除階層的扼殺者(R)。 ILSCR模型的傳播規則如下:
(1) 新個體可能以概率ε在網絡中變得無知。不同狀態節點以概率 ρ 從網絡中移除。
(2)當無知者與潛在者或傳播者接觸時,無知者將分別以γ1或γ2的概率轉變為潛在狀態L。
(3) 潛在變量將以概率 α 轉變為擴展器狀態 S。
(4)負面影響傳播較長時間后,傳播者不再愿意相信負面信息,會以概率δ1轉變為較冷狀態C。另外,由于遺忘機制,傳播器將以概率λ轉變為恢復狀態R。
(5) 當負面信息被證明錯誤后,冷卻器將以δ2的概率轉變為恢復狀態R。
(2) Suspect–Dangerous–Infective–Latent–Recovered
?姚等人。 [55]認為在社交網絡中,易感節點在負面信息出現后立即成為感染節點是不合理的,因為負面信息傳播到易感節點需要一定的時間。另外,由于傳播者的頑固性,當負面信息被證明是虛假的時,他們會處于一種特殊的狀態,可能傳播負面信息,或者可能對負面信息免疫。基于這些因素,他們設計了一個可疑-危險-感染-潛伏-恢復(SDILR)模型來模擬影響的傳播。該模型將節點分為六類(如圖4(b)所示):未接觸過負面信息的易感者(S),有網友傳播負面信息且面臨迫在眉睫危險的危險者(D)。被欺騙、傳染性(I)、傳播負面信息、潛伏性(L)、傳播負面信息但暫時停止傳播、恢復性(R),SDILR模型的傳播規則如下:
(1) 新個體以概率μ在網絡中變得無知,并且不同狀態節點以概率μ從網絡中移除。
(2) 當易感節點與感染節點接觸時,易感節點將以概率β轉變為危險狀態D。
(3) 危險節點以概率ρ轉變為感染狀態I。而且,它們可以以概率 δ 轉變為恢復狀態 R。
(4) 被感染的節點可能以概率 γ 轉變為潛在狀態 L 。同時,潛在節點可能以概率 θ 恢復到受感染狀態 S 。
(5) 潛在節點可以以概率 φ 轉變為恢復狀態 R。
(3) Susceptible–Exposed–Trusted–Questioned–Recovered Model
?張等人。 [56]提出了敏感-暴露-可信-質疑-恢復(SETQR)影響力傳播模型,以確保模型與實際情況密切相關。該模型考慮了以下因素:受感染的節點可以選擇性地傳播信息;網絡中的某些節點是免疫的;信息處理存在時間滯后;并且有可能免疫節點再次被激活。該模型將節點分為以下五類(如圖4(c)所示):易受影響(S)、暴露(E)、可信(T)、質疑(Q)和恢復(R)。其中,暴露節點是那些接收到信息但不確定信息是否被傳播的節點。可信節點是那些相信接收到的信息并傳播該信息的節點。被質疑的節點是那些不相信收到的信息但傳播該信息的節點。
張等人。 [56]提出了敏感-暴露-可信-質疑-恢復(SETQR)影響力傳播模型,以確保模型與實際情況密切相關。該模型考慮了以下因素:受感染的節點可以選擇性地傳播信息;網絡中的某些節點是免疫的;信息處理存在時間滯后;并且有可能免疫節點再次被激活。該模型將節點分為以下五類(如圖4(c)所示):易受影響(S)、暴露(E)、可信(T)、質疑(Q)和恢復(R)。其中,暴露節點是那些接收到信息但不確定信息是否被傳播的節點。可信節點是那些相信接收到的信息并傳播該信息的節點。被質疑的節點是那些不相信收到的信息但傳播該信息的節點。
(4) Suspect–Exposed–Symptomatic–Infected–Asymptomatic–Infected–Recovered-Death Model
基于現有的流行病分區模型,Chen 等人。 [57]提出了考慮有癥狀和無癥狀感染者的實際傳播路徑的隔室動態模型(SEI1I2RD)。他們的結論是,病毒的傳播潛伏期長、無癥狀感染者數量多。傳播模型將節點分為五類(如圖4(d)所示):易感(S)、暴露(E)、感染(I)、恢復(R)和死亡(D)。其中,感染節點由有癥狀感染者(I1)和無癥狀感染者(I2)組成。 SEI1I2RD模型的傳播規則如下:
(1) 當易感節點暴露于有癥狀的感染者 I1 時,將以概率 α 轉變為暴露狀態 E;或以概率 β 達到無癥狀感染狀態 I2。 (2) 暴露的節點將以概率 σ 轉變為有癥狀的感染狀態 I1 。 (3) 有癥狀的感染節點將以概率 u 轉變為死亡狀態,或者以概率 γ1 轉變為恢復狀態 R。 (4) 無癥狀感染節點將以γ2的概率轉變為恢復狀態R。
3.4. Other types of diffusion models
??除了上述常用的擴散模型外,最近文獻報道了一些影響力擴散模型。范等人。 [58]介紹了機會性一激活一(OPOAO)和確定性一激活多(DOAM)模型。這兩個模型都描述了網絡中同時演化的兩個級聯的擴散。在 OPOAO 模型中,影響力傳播過程類似于移動社交網絡中人與人之間的聯系機制,即每個人同時只能與一個人進行交流,而在該模型中,影響力傳播速度較慢,原因是重復選擇的存在。 DOAM影響力傳播機制類似于信息廣播過程,每一步,新激活的節點數量都會大幅增加,影響力傳播的速度相比OPAO模型相當快。郭等人。 [59]提出了多特征擴散模型(MF模型),該模型假設信息具有多維特征,并且信息擴散過程不是簡單的一維擴散,而是多維、逐個特征的擴散。盡管每個特征對于不同用戶的重要性不同,但該模型通過平等對待這些特征來簡化模型。范等人。 [60]基于IC和LT模型提出了兩種模型來捕獲競爭影響力擴散過程,即帶有會議事件的謠言-保護者獨立級聯模型(RPICM)和帶有會議事件的謠言-保護者線性閾值模型(RPLT-M) 。在這兩個模型中,存在兩種類型的級聯擴散:保護者和謠言。此外,這些模型還具有三個特征,包括時間期限、信息交換之間的隨機時間延遲以及接受信息的個人興趣。
? ?王等人。 [61]在伊辛模型[62]的基礎上提出了影響力擴散的動態模型,他們認為信息擴散的成功取決于話題的全球流行度和個體對信息的傾向,這可以看作是伊辛模型的概括特征。
4. Methods
??近年來,文獻報道了影響力阻斷最大化方法。這些方法主要分為三類:基于中心性的方法、基于啟發式的方法和基于社區檢測的方法。除了回顧這三類主要方法之外,我們還回顧了一些解決具有一定約束的 IBM 問題的方法,例如成本約束 IBM 問題,它不僅考慮了抑制效應,還考慮了使用正種子的成本。另一個例子是IBM關于來源不確定的問題。該問題假設負信息的來源未知,我們只知道每個節點成為負種子源的概率。
4.1. Methods based on centrality
??基于中心性測度的方法主要評估網絡中節點和邊的重要性,選擇重要的節點或邊來阻斷或抑制負面影響。
4.1.1. Node centrality measurements
? ?基薩克等人。 [14]認為網絡的拓撲結構對節點的傳播起著重要作用,最有效的傳播者往往存在于網絡的核心區域。因此,他們提出了k-shell分解方法來選擇有影響力的節點。該方法中,k-殼分解的步驟如下:在第一步k-殼分解中,將度數k=1的節點全部移除,這可能使得剩余的度數k≤1的節點出現。繼續刪除所有度數 k ≤ 1 的節點,直到所有剩余節點的度數 k > 1。所有刪除節點的 k-shell 值設置為 1。第二步,刪除所有度數 k = 2 的節點,直到所有節點剩余節點的度k > 2。將第二步中所有移除節點的k-shell值設置為2。對剩余節點重復此剪枝過程,直到所有節點被移除。最后,為每個節點分配一個 k-shell 值。實驗結果表明,k-shell方法具有較強的魯棒性,但在存在多個傳播源且影響傳播范圍重疊的情況下,該方法的有效性值得懷疑。于等人。 [63]研究了幾種結構措施來確定靜態和動態社交網絡中的最佳攔截器,并觀察到它們的刪除將大大降低網絡中的交流程度。他們發現,對于靜態和動態網絡,簡單的局部指標(例如節點度)是非常好的指標,并且可以作為出色的攔截器。馬等人。 [64]發現,如果節點的鄰居具有較高的k-shell值,則該節點的影響力較高[14,65],并且節點之間的影響力隨著距離的增加而減小。受引力公式思想的啟發,他們提出了重心指數來衡量網絡中節點的傳播影響力。該方法將節點i的k殼值作為其質量,并將節點之間的距離定義為節點之間的最短路徑。由此,網絡G中節點i的影響力G(i)計算如下:

? ?這里,dij是節點i和j之間的最短距離,ks(i)、ks(j)分別是節點i和j的k殼值。 ψi 是到節點 i 的最短路徑不超過閾值 r 的節點集合。為了降低算法的計算復雜度,他們將r設置為3。因此,擴展重力指數的定義如下:

??這里,Λi是節點i的最近鄰集。實驗結果表明,該方法比度中心性、介數中心性等指標更有效,在SIR模型中也取得了更好的效果。在一些在線消息社交網絡中,人們更容易受到親密朋友的影響,傳統上認為一個節點擁有的朋友越多,即度越大,該節點在社交網絡中的重要性就越高。然而,很多時候,人們的影響力不僅僅取決于好友的數量,還取決于好友的重要性,即好友越重要的節點,在信息傳播中會發揮越重要的作用。姚等人。 [66]提出了一種基于特征向量中心性的算法,其中特征向量中心性的值用于衡量網絡中節點的重要性,這也是社交網絡中節點重要性的重要衡量標準。如果某個節點的特征向量中心性值較大,則可以表明該節點與特征向量中心性值較大的節點的聯系更加緊密。令 c(vi) 為節點 vi 的特征向量中心性 (EVC),定義為:

??這里,A是社交網絡圖G的鄰接矩陣,N(vi)是節點vi的鄰居集,λ是給定的常數。設C = (c(v1), c(v2), ..., c(vn))T為圖G中所有節點的中心向量,n為節點數,則式(1) (10) 可以轉化為如下形式:

從等式可以看出。 (11) 根據Perron-Frobenius定理[67],C是矩陣AT的最大特征值對應的特征向量,λ是矩陣AT的最大特征值。該算法選擇負面種子節點的鄰居集中EVC值最大的節點作為抑制節點,阻止負面影響的傳播。
阿拉茲哈尼等人。 [68]研究了用戶的社會地位對影響力封鎖的影響,提出了Centrality_IBM算法,該算法使用三種不同的中心性策略,包括接近中心性、介數中心性和度中心性,找到k個正節點來阻止負面影響的傳播。度中心性方法從所有非負種子節點中選擇度數最大的節點作為候選正種子節點。緊密中心性方法通過計算該節點與圖中所有其他節點之間的最短路徑長度之和的倒數來對節點進行排序。節點介數中心性方法通過計算經過目標節點的所有節點之間的最短路徑條數來衡量目標節點。在不同類型數據集上的實驗結果表明,三種不同中心性度量的效果有所不同,但總體效果優于隨機選擇種子節點的方法。
??王等人。 [69]提出了一種基于最大邊際增益規則的貪心算法來尋找最優種子節點集來阻止負面影響的傳播。實驗發現,與基于中心性的出度、介數和PageRank方法相比,該算法取得了更好的性能。維賈延托等人。 [70]將圖連接性與中心性結合起來作為一種稱為保護度量的測量。他們提出了PowerShield方法來選擇陽性種子。該方法中,連通性是通過圖鄰接矩陣的最大特征值對應的特征向量來衡量的。中心性準則是通過節點的度來衡量的,即具有更多鄰居的節點被認為更重要。因此,節點i的Protection Metric可以通過式(1)計算: (12) 式中,ηi 為矩陣最大特征值對應的特征向量第 i 個元素,d(i) 為節點 i 的度數。
![]()
張等人。 [71]發現在一些在線社交網絡如新浪微博中,有影響力的節點的出度通常遠高于其入度。此外,他們認為我們不應該簡單地選擇最有影響力的節點來阻止負面影響,因為這可能會導致其追隨者或其他用戶的不滿。他們基于信息熵理論,提出了一種利用用戶容忍度的負面影響阻斷方法的節點選擇機制。該方法中,pin u和pout u分別為節點u的入度和出度的比例概率。

4.1.2. Edge centrality measurements
??戴伊等人。 [74]觀察到中心節點在信息傳播中發揮著重要作用,但是封鎖這些中心節點,例如中間性和接近中心性最高的節點,在影響力抑制方面并沒有取得更好的效果,因為刪除特定節點可能會導致增加另一個節點的重要性。基于對 Twitter 網絡的觀察,他們發現邊介數方法優于一類基于節點中心性的方法[75]。卡里爾等人。 [76]提出了一種基于貪婪邊緣刪除的算法來解決謠言阻塞問題,即刪除一組k條邊緣,從而在LT模型下最小化謠言傳播。他們表明,這種基于邊緣刪除的謠言阻止問題具有超模塊化目標函數,因此可以通過具有可證明的近似保證的貪婪方法來解決。 Yao 等人的目標是阻止 k 個鏈接以最大程度地減少最終受感染的用戶規模。 [77]提出了一種保證精度的貪心算法和兩種基于介數和出度的有效啟發式算法來尋找該問題的近似解,其中邊e的介數b(e)計算為:

??這里,N(u,v)是節點u和v之間的最短路徑的數量,n(e;u,v)是節點u和v之間通過邊e的最短路徑的數量。如果 N(u, v) = 0,則 b(e) = 0。在兩個真實網絡上的實驗結果表明,貪心算法在最小化負面影響方面更有效。但就運行時間而言,基于介數和出度的啟發式算法比貪心算法快幾個數量級。
??阿莫魯索等人。 [78]提出了一種啟發式方法,在網絡節點中放置多個監視器來控制可疑節點傳播的信息,并在錯誤消息到達網絡的大部分之前阻止錯誤消息對其余節點的影響。他們提出了切點的概念,切點是負面影響節點和單個目標節點之間的邊。如果將剪切中的所有邊都從網絡中刪除,則負面影響節點和目標節點之間將不存在可達路徑。因此,如果將監視器放置在剪切的末尾,則可以在傳播到目標節點之前阻止節點 s 的負面影響。
??嚴等人。 [79]證明了從網絡中移除某些邊集以抑制負面影響傳播的問題的目標函數不滿足子模型,因此他們提出了一個子模下限界和目標函數的子模上限,并設計了一種啟發式方法 MDS 來計算目標函數。該方法根據每個節點的邊際減量來選擇種子節點,可以通過從網絡中去除邊來準確計算種子節點。該問題的目標函數相當于最大化總邊際減量。令 θE\{est }(v) 表示當邊 est 從當前網絡 E 中移除時,節點 v 被種子集 S 激活的概率。令 ΔεθE\ε(υ) 為移除后節點 v 的邊際減量邊集 ε,則總邊際減量為:

嚴等人。 [80]提出了一種由生成候選集和選擇阻塞階段兩個階段組成的方法。第一階段是尋找散射影響最大的前a×k節點作為候選集,其中a是閾值參數。該階段可以有效減少后期貪心算法的時間消耗。第二階段基于貪心策略,從候選集中選擇k個節點來阻止負面影響的傳播。為了選擇候選集,應通過式(1)估計所有節點的負面影響傳播能力。 (19) 式中,A為網絡的鄰接矩陣,I為單位列向量,r為傳播路徑的長度限制。 σ中各元素的值對應于相應節點的負面影響傳播能力。
![]()
木村等人。文獻[24]利用密鑰滲流法的思想估計了節點 v ∈ V 的影響度 σ (v;G),比傳統的鏈接刪除啟發式算法有較大的性能提升。他們將圖 G 邊界處的滲透過程稱為隨機過程,其中信息以概率 pe (e ∈ E) 通過每條邊 e 傳播。給定一個正整數M,該方法執行M次邊緣滲濾過程并構成M張圖,用Gm=(V,Em)(m=1,...,M)表示。根據文獻[81],圖上的概率問題可以映射為邊界滲流過程。因此節點v的影響程度σ(v;G)可以用式(1)中的s(v;G,M)來近似。 (20),其中F(v;Gm)是圖Gm中從節點v可到達的所有節點的集合。

如果 M 很大,那么每個圖都可以分解為強連通分量(SCC),如下所示:

4.2. Methods based on heuristic
??啟發式算法是指通過歸納推理和對過去經驗的實驗分析來解決問題的方法。啟發式算法借助于某種直觀的判斷或試探性的方法,能夠得到問題的次優解或以一定的概率找到其最優解。通用性、穩定性和更快的收斂速度是衡量啟發式算法性能的主要標準。
4.2.1. Network sampling-based methods
??陳等人。 [84]提出了度折扣啟發式,并且還改進了其他級聯模型中基于度的啟發式。算法的思想是這樣的:如果u是種子節點,那么它的鄰居節點v的度應該打1。同樣,如果v在種子節點集中有m個鄰居節點,那么v的度應該折扣為 m。在IC模型中,當傳播概率p較小時,該方法只關心v對其直接鄰居的影響,而忽略節點v的多跳鄰居。雖然該方法適用于大規模社交網絡,其準確率不高,該方法在LT等其他模型中的有效性尚不清楚。陳等人。 [85]通過為每個節點構建局部樹結構來對影響力傳播進行建模,并設計了一種新的啟發式算法,可以擴展到數百萬個節點和邊,該算法具有一個簡單的可調參數,可供用戶控制運行時間和影響力之間的平衡算法的范圍。該算法首先使用 Dijkstra 的最短路徑算法計算網絡中節點對之間的最大影響路徑 (MIP)。為了有效限制對局部區域的影響,可以忽略概率小于影響閾值θ的MIP。然后,在每個節點開始或結束的 MIP 被合并到表示每個節點的局部影響區域的樹結構中。因此,只需要考慮通過這些局部樹結構傳播的節點的影響,作者將該模型稱為最大影響樹結構(MIA)模型。在基本的 MIA 模型中,如果從種子節點 sj 到節點 v 的 MIP 上存在一個種子節點 si,則 si 會阻擋 sj 對 v 的影響。因此,為了更好地模擬原圖中的影響傳播,作者提出了一種擴展前綴排除MIA(PMIA)模型來尋找從sj到v的路徑中不存在節點si的替代路徑。在擴展模型中,當選擇下一個種子時,對于每個節點v,其在需要重新計算圖表。最后,所有被選中的種子按照選擇順序形成一個序列S,并且S中的任意種子s都有到所有節點v的替代路徑。因此,節點v的MIA結構由兩部分組成,分別是并集PMIIA(v,到 v 的 MIP 的 θ ) 和從 v 到其他節點的最大影響路徑的并集 PMIOA(v, θ ),其中 θ 是影響傳播概率的閾值。該方法可擴展到數百萬種大小的圖表,并且在大多數情況下,它顯著優于所有其他可擴展啟發式方法,將影響范圍增加 100% 至 260%。為了解決效率問題,He 等人。 [5]利用LT模型對有向無環圖(DAG)的高效計算特性,針對CLT模型下的IBM問題設計了一種高效的啟發式CLDAG。實驗結果表明,CLDAG算法在阻塞效果上與貪婪算法相當,同時顯著提高了運行時間。
? ?李等人。 [86]設計了一種快速近似算法,使用2跳方法來模擬從節點開始的影響傳播。然后,為了加速貪婪算法,他們提出了基于節點刪除的啟發式算法來檢測最佳種子節點,以最大化負數上的阻塞。童等人。 [87]提出了一種基于反向元組的隨機負面影響分塊算法,該算法利用反向采樣技術來獲得IBM問題的目標函數的估計值。該方法中,節點v的隨機反向元組TV=(V*,Et,Ef,B)構造如下:從節點v開始,采用廣度優先搜索順序檢測其鄰居是否可以添加到其可達節點集V*,直到負種子或沒有節點可以進一步到達。其中 Et 和 Ef 是邊集,B 是布爾變量。該算法在IC模型下具有良好的分塊效果,但模型參數較多,難以優化。基于 MIA 結構,Chen 等人。 [88]設計了兩種啟發式CMIA-H和CMIA-O,分別在MCICM和COICM兩種競爭傳播模型下有效地解決IBM問題。實驗結果表明,CMIA-H 和 CMIA-O 都實現了與貪婪算法相同的阻塞性能,并且始終優于其他基線啟發式算法。 CMIA-H 和 CMIA-O 都比貪婪算法快幾個數量級。為了計算被阻止的負面影響,CMIA-H利用正向傳播的高效特性,可以輕松判斷負面種子對其他節點的影響是否被完全阻止或不被阻止。 CMIA-O中的計算過程采用動態規劃方法來高效計算每個節點的負激活概率,進而計算被阻止的負影響。盡管這兩種算法對阻塞性能的影響與貪婪算法相似,但它們缺乏近似保證。林等人。 [89]提出了Block Influence Out Graph(BIOG)算法,通過使用新的圖結構Maximum Influence Out-Graph(MIOG)來建模負面影響的傳播區域,從而有效地阻止負面影響的傳播。該算法計算網絡中每個節點的全局阻塞分數,將分數最高的節點作為正向影響節點,然后更新負向影響節點的傳播區域,直到負向影響被阻塞或滿足終止條件。目前大多數算法都是基于一維擴散模型設計的。事實上,一個節點有多個特征,用戶對每個節點的影響力不僅取決于其中一個特征,還取決于其對與該節點相關的所有特征的整體評價。因此,一個節點的影響力傳播可以分解為該節點多個特征的影響力傳播。在此基礎上,郭等人。 [59]定義了多特征傳播模型,并設計了多層網絡結構的多重采樣方法。然后,基于多重采樣和鞅分析提出了一種改進的Revised-IMM算法[90]。
? ?郭等人。 [91]提出了兩種有效的解決方案:貪婪和通用TIM,以保護網絡中的特定節點免受負面影響。其中,貪心算法采用爬山策略,得到了理論界,但時間復雜度較高。 General-TIM算法基于反向最短路徑(Random-RS-Path)的隨機采樣,大大降低了時間復雜度。具體來說,如果邊越多,則可以保護更多的節點覆蓋隨機 RS 路徑被刪除。因此問題轉化為最大覆蓋問題,即選擇最少的邊來覆蓋盡可能多的隨機RS路徑。該算法首先需要采樣Random-RS-Paths的數量,然后通過貪心法求解最大覆蓋問題。為了降低算法的復雜度,基于真實網絡的社團結構,提出了一種貪心算法。如果負面影響節點集合和目標節點集合沒有出現在同一個社區中,則不需要考慮這些不相關社區中的邊。去除不相關的社區后,貪心算法和General-TIM算法都可以得到顯著的改進。實驗結果表明,General-TIM算法雖然不能保證精確的逼近率,但在實際應用中可以獲得良好的效果。
4.2.2. Methods for location aware IBM
??在解決 IBM 問題時,一些算法利用節點的位置信息來估計影響的傳播。朱等人。 [92]開展了位置感知影響塊最大化(LIBM)研究,提出了兩種基于四叉樹索引和最大影響樹狀結構的啟發式算法LIBM-H和LIBM-C[18]。給定一組負面影響節點,LIBM問題是選擇正面影響節點來抑制負面影響在指定區域的傳播。 LIBM-H中采用四叉樹索引來存儲節點的位置信息,并采用深度優先遍歷從四叉樹的根節點開始搜索位于查詢區域的節點,最終得到最大影響力樹結構(MIA)用于計算影響傳播過程。 LIBM-H算法需要計算網絡中所有具有阻塞負面影響的候選節點。但事實上,很多不重要的節點不應該被選為候選種子,因此不需要計算它們的阻塞負面影響。也就是說,為了提高種子選擇的效率,我們只需要關注影響力大的節點,刪除影響力小的節點即可。因此,他們提出了單元索引和節點索引來有效存儲節點阻塞的負面影響,并提出了一種基于四叉樹單元的更高效的算法LIBM-C。該算法首先將整個空間劃分為小單元,并預先計算每個單元中節點的負面影響。然后,對于給定的查詢區域,它聚合所有相應的單元格并使用上限方法來估計 top-k 正種子。
? ?朱等人。 [93]還研究了競爭性社交網絡(LTIBM)下的位置感知影響阻塞最大化問題,并提出了一種啟發式算法LTIBM-H。該算法的目標是在給定的社交網絡中找到一組正種子,以盡可能阻止負種子對位于給定區域中對某些主題有偏好的目標節點的影響傳播。在LTIBM-H算法中,作者設計了一個QT樹來獲取給定查詢區域的目標節點。接下來,利用 MIA 來近似種子的正面和負面影響傳播。給定正負影響種子節點 SP 和 SN ,采用動態規劃算法計算節點 v 的負激活概率 nap(v, SP , SN )。將節點 u 添加到正種子集中后,負激活概率的變化節點v的激活概率Bni(u, v)可以根據nap計算:

? ?這里,β(v, T ) = Σzi=1 tiθi 是節點 v 對主題集的傾向。二元變量ti = 1表示阻止節點v對主題ti的負面影響的傳播;相反,ti = 0 表示不需要阻止節點 v 對主題 ti 的負面影響的傳播。在該算法中,只有影響力能夠傳入N(T,R)的節點才可以作為候選節點,N(T,R)是對主題T有偏好且位于R中的節點集合。讓這些候選節點 Ca(T , R) 定義為:

??最后,從 Ca(T , R) 中迭代選擇 Bni(u, T , R) 最大的 k 個節點作為正種子集。實驗結果表明,該算法能夠達到與貪心算法相媲美的阻塞效果。 LTIBM-H 的結果優于其他基線算法。此外,LTIBM-H算法比貪心算法快四個數量級。 Zhu等人為了識別指定區域RQ中的k個節點來阻止RB區域中的負面影響傳播。 [94]提出了IS-LSS算法,使用同花競爭獨立級聯模型來模擬影響傳播。該算法對查詢區域中的所有節點一視同仁,將所有節點視為正種子候選,主要分為兩個步驟:第一步,使用四叉樹索引結構來存儲節點的位置信息,并使用深度優先遍歷方法識別位于給定查詢區域中的候選節點。第二步,最大堆用于存儲候選節點及其被阻止的負面影響。然后使用MIA方法計算每個候選集的影響力,并使用動態規劃算法計算它們的阻塞負面影響。最后,迭代選擇最大堆中具有最大值的候選節點作為正種子節點。在此基礎上,作者提出了改進算法IS-LSS+,它也使用最大堆來存儲候選節點及其阻塞負面影響,但它使用上限方法和四叉樹單元列表來刪除不重要的候選節點。實驗結果表明,隨著正種子數量的增加,兩種算法都實現了與貪婪算法類似的阻塞效果,同時運行速度比貪婪算法快四個數量級。
4.2.3. Hybrid technology-based methods
??劉等人。 [95]設計了一種基于模擬退火的高效算法SA-min。他們將適應函數 c(G(D)) 定義為正種子集 D 對圖 G 的影響。問題的目標是盡可能減少 c(G(D)) 的值。設系統初始溫度T=T0,初始解為A,其鄰域解為A*。如果滿足 Δc = c(G(A*)) ? c(G(A)) < 0,則表示解 A* 優于解 A,應將 A 替換為解 A*。如果 Δc ≥ 0,且 exp(?Δc/Tt ) 大于隨機生成的閾值 ε,則 A 也應替換為解 A*。當迭代次數達到 q 時,當前溫度 Tt 應減少 Tt = Tt ? ΔT 。 Tt 是當前溫度,當溫度達到下限 Tf 時算法終止。如果使用蒙特卡洛模擬來計算影響力傳播,SA-min算法的計算成本仍然較大,因此作者提出了一種高效的啟發式算法ML_CS來模擬影響力傳播,該算法僅計算節點的影響力距節點 v.
? ?Jia 等人最多 m 跳。 [96]將IBM問題視為Stackelberg博弈問題,以負面影響節點為攻擊者,抑制節點為防御者,尋求抑制節點的最優策略。作者首先提出了一種基于整數規劃和約束生成相結合的方法。接下來,為了提高該方法的可擴展性,他們開發了一種近似解決方案,將問題視為整數規劃,然后將松弛與對偶相結合以產生防御者目標的上限,以便可以使用混合整數線性規劃進行計算。最后,他們提出了一種更具可擴展性的啟發式方法,可以根據節點的度數從考慮集中修剪節點。
? ?蔡等人。 [97]將IBM問題的研究與雙預言機方法[98,99]結合起來,創建了一種新穎的啟發式預言機。該策略中雙預言機算法的優點之一是可以輕松更改預言機以生成現有算法的新變體。該算法還具有很強的能力來模擬各種攻擊者/防御者的最佳響應策略,并更徹底地測試啟發式算法的性能。
? 楊等人。 [8]提出了基于擴散動力學的啟發式算法貢獻者識別(ContrId)和ProxContrId來解決IBM問題。基于負面影響傳播的動態,他們通過識別對負面影響傳播貢獻最大的節點(稱為貢獻者)并阻斷從負面影響種子到其余網絡節點的重要路徑來抑制負面影響傳播。他們根據正種子的搜索空間將啟發法分為兩類:無約束和約束。在無約束方法中,可以在集合V\SR中任意選擇一個節點作為正種子節點,其中SR是負種子集。假設tv時刻激活的節點v的貢獻是通過在任意t>tv時該節點激活的節點Nout v的數量來衡量的。假設影響傳播在時間Ts達到穩定狀態,則每個時間段受負面影響激活的節點集合定義為φRt(t=1,...,Ts)。令 L 為網絡中最長簡單路徑的長度,并滿足 Ts ≤ L。因此,對于每個節點 v ∈ φR t ,其貢獻 Ctr(v) 定義如下:

??將不活躍節點的貢獻度設置為0。最后,ContrId算法選擇貢獻度最高的k個節點Ctr(v)作為候選種子節點。 ProxContrId算法將負種子的影響傳播空間限制在區域Nout (SR) = ((? v∈SR N out v ) \ SR)。由于搜索空間較小,受約束方法的時間復雜度比無約束方法低。張等人。 [31]提出了一種主導影響算法,由兩個子算法組成:DI-網關節點檢測和DI-候選選擇。 DI-網關節點檢測識別網關節點,對于擴大錯誤信息的影響力具有重要意義。在錯誤信息的擴散自然終止之前,DI-候選選擇找到不同搜索輪次的候選種子集,這些種子集由網關節點集確定。最后,支配影響算法獲得積極信息的最佳種子。實驗結果表明,Domining Influence算法比MinGreedy、Random等啟發式算法取得了更好的性能,更適合大規模網絡。
4.3. Methods simulating immunology process
??IBM問題通常采用常見的免疫控制策略。基于免疫學的IBM方法可以分為兩類:基于全局信息的免疫策略和基于局部信息的免疫策略。基于全局信息的免疫策略需要了解網絡結構的完整信息。中心性越高的節點往往具有更大的傳播影響力。基于免疫學的算法首先根據節點的中心性對節點進行排序。然后,可以選擇合適的免疫靶點來阻止疾病的傳播[14,100–108]。
??黃等人。 [109]提出了一種頂點著色的免疫策略,將著色節點分為不同的集合,然后從包含最多節點的集合中選擇免疫節點。然而,在連接免疫節點的邊之后,網絡被劃分為多個子圖,并且免疫策略將許多資源分配到小尺寸的子圖中。針對這種情況,陳等人。 [110]提出了一種等圖劃分的免疫策略,通過將原始圖劃分為大小幾乎相同的連通子圖,大大減少了需要免疫的節點數量。例如,對于流行病傳播的動態過程,Zhang等人。 [111]提出了三種有效的多項式時間啟發式算法DAVA、DAVA-prune和DAVA-fast,可以幫助公共衛生專家根據當前的疫情分布做出實時場景。主特征向量(PEV)在不同網絡子圖上的位置是重要的信息,可用于修改和控制由網絡拓撲介導的動態過程。帕斯托-薩托拉斯等人。 [112]提出,根據PEV的位置,高免疫個體的效果可能完全不同
? ?雖然基于全局信息的免疫策略可以更準確地識別關鍵節點,但隨著網絡數據多源異構的趨勢,對于大規模網絡我們很難及時獲取網絡的全部信息,而且網絡結構的計算復雜度也較高。而基于局部信息的免疫策略由于只利用節點周圍的局部信息,因此更加實用和可操作。該策略可以快速高效地識別免疫目標,阻斷疾病在全網的傳播。隨機免疫策略是一種局部信息免疫策略,通過隨機選擇網絡中的部分節點來進行免疫。無論是單層網絡還是多層網絡,都需要免疫大量個體來阻止負面影響的傳播,并且可能需要免疫80%以上的節點來阻止負面影響的傳播[113,114] 。比如在病毒傳播方面,對于像新冠病毒這樣傳播能力強的流行病,很多國家都實施了成本高昂的全民免疫策略。為了解決這種情況,科恩等人。 [115]提出熟人免疫策略,首先隨機選擇一個節點進行免疫,在下一次節點選擇過程中,僅隨機選擇免疫節點的鄰居,直到達到設定的免疫比例。為了避免對同一組鄰居進行過度免疫,Holme 等人。 [116]通過用最大連接邊數來免疫鄰居,對熟人免疫策略進行了相關改進。夏等人。 [117]使用節點的度和聚類系數作為免疫節點選擇的標準。郭等人。 [118]提出了一種歐幾里德距離首選(EDP)模型,它產生了一個小世界網絡。在此基礎上,他們提出了免疫半徑的概念,將免疫節點的選擇限制在有感染節點的半徑r范圍內。實驗表明,免疫半徑能夠有效抑制疫情,并且對EDP模型參數變化具有魯棒性。
? ?然而,通過節點免疫策略,免疫實體與網絡的其余部分完全隔離,網絡的連接性被破壞[119]。因此,仍有部分研究通過對網絡的重要邊緣進行免疫來實現疫情傳播阻斷[120-129]。為了阻止疫情在復雜的社交網絡上傳播,張等人。 [130]提出了一種根據邊緣重要性刪除邊緣的方法。邊的重要性是連接該邊的兩個節點度的乘積。與其他方法如隨機免疫、比例免疫、定向免疫、熟人免疫等主要關注如何去除節點以實現對復雜網絡上疫情傳播的控制相比,該方法更能有效地實現對復雜網絡上疫情傳播的控制。復雜網絡,并且能夠更好地維護復雜網絡的完整性。張等人。 [131]將邊的重要性定義為它所連接的兩個節點的強度的乘積。節點的強度可以是連接該節點的所有邊的權重之和,也可以是通過該節點的最短路徑數量的總和或乘積[132]。庫爾曼等人。 [133]提出了離散動力系統模型下的邊緣覆蓋啟發式算法。該算法識別并去除網絡組的邊緣,以阻止負面影響的傳播。進行實驗來模擬阻塞前后受感染節點數量的影響。實驗結果表明,與基于閾值的啟發式算法[83]和高度啟發式算法[130]相比,邊緣覆蓋方法在阻止未加權圖和加權圖的負面影響傳播方面更有效。此外,作者發現,在平均度和平均聚類系數較低的網絡中阻止傳播更加困難。
? ??為了抑制流量驅動的負面影響的爆發,楊等人。 [134]發現,可以通過阻止大度節點之間的連接邊或阻止具有較大邊緣網格的連接邊來減少負面影響的傳播。與去除介數最大的邊相比,阻塞連接大度節點的鏈路對于提高流行度閾值更有效。受免疫學的啟發,陳等人。 [135]提出了一種近似最優可擴展算法NetShield和相應的改進算法NetShield+來尋找一組具有最高屏蔽值得分的節點。該算法首先利用網絡鄰接矩陣的最大特征值λ來衡量網絡的脆弱性。然后,利用矩陣微擾理論的結果定義每組節點的屏蔽值得分Sv。最后,使用子模塊理論來找到一組具有最高屏蔽值得分的節點。網絡的脆弱性與網絡中邊的數量和位置信息密切相關。采用鄰接矩陣A的最大特征值λ作為網絡的脆弱性測度,即λ值越大,表明網絡的脆弱性越高。
4.4. Methods exploiting community structures
? ?基于社團結構的IBM方法認為網絡中的節點之間具有一定的聚類特征,相似度較高的節點被分到同一社團中(如圖5所示),該方法一般可以反應關系更有效地構建社交網絡模型。為了提高 IBM 算法的效率,基于社交網絡中影響擴散的局部性,Lv 等人。 [139]提出了一種基于社區結構的IBM算法CB_IBM。根據社區Ci中影響力種子節點的分布情況,首先確定種子節點ki的數量。然后選擇影響力最大的 ki 節點作為正向影響力的種子節點。兩個實驗結果真實網絡表明,CB_IBM 的阻塞效果與 Greedy 的性能一致,并且 CB_IBM 比 Greedy 快得多。
? ?阿拉茲哈尼等人。 [140]提出了一種名為 FC_IBM 的基于社區的算法,使用模糊聚類和中心性度量來尋找候選節點的良好子集,以傳播解決 IBM 問題的積極信息。該算法首先使用基于局部隨機游走的新度量來比較每個節點之間的相似性。其次,為了盡可能保持原始節點距離,通過多維縮放將網絡結構映射到低維空間。接下來,使用模糊 c 均值將節點聚類成社區。最后根據中心度高的原則選擇有影響力的節點。與沒有進行社區檢測的算法相比,該算法可以有效降低節點被負面影響節點感染的概率。與傳統的影響力抑制問題不同,Nguyen 等人。 [141]解決了信息可以以任意概率傳播的問題。他們不僅考慮了防御者是否知道被錯誤信息污染的初始節點集,而且還考慮了防御者遏制錯誤信息傳播的時間余量。阮等人。改進了爬山算法[142],提出了貪婪病毒停止器(GVS)算法,將每輪邊際增益最大的節點作為候選種子節點,直到滿足終止條件。但該方法時間復雜度較高,不適合大規模網絡。因此,他們提出了一種基于社區結構的啟發式算法。該算法首先通過Blondel算法[143]將網絡劃分為社區,并根據社區所包含的節點數量將社區按降序排列,然后對每個社區應用GVS算法,找到一組有影響力的節點來抑制負面影響。最后,在每個社區中貪婪地選擇提供最大邊際收益的節點,作為候選種子節點。實驗結果表明,該算法雖然可以取得較高的效果,但如果應用在沒有社團結構的網絡上,效果未知。
??通過觀察網絡中社區的結構特性,Fan 等人。 [58]發現存在一組稱為橋端的節點。每個橋端在與其相鄰的負面影響節點所在社區中至少有一個直接相連的鄰居,并且該社區內的負面影響節點可達。 OPOAO模型下,通過保護部分橋端來抑制負面影響。對于每個負面影響節點,通過廣度優先搜索(BFS)方法構建謠言前向搜索樹(RFST)來找到所有橋端,然后將它們放入候選集中。他們證明了問題的目標函數具有子模性,最后利用貪心算法選擇對橋端保護貢獻最大的節點作為抑制種子節點。此外,在DOAA模型下,他們將IBM問題等同于集合覆蓋(SC)問題,并提出了基于集合覆蓋的貪婪(SCBG)算法。其主要思想是:給定謠言發起者集合SR和橋端集合B,對于任意v∈B,使用BFS方法構造v的以v為根的橋端向后搜索樹(BBST)Qv。用 Q1、Q2、... 表示。 。 。 , Q|B|所有橋端對應的 BBST。然后對于每個 u ∈ Qi, 1 ≤ i ≤ |B|,檢查所有其他 BBST,即 Qj (j ?= i, and1 ≤ j ≤ |B|) 找到包含 u 的并記錄它們,然后連接它們的根到節點u。這樣一棵1跳樹就形成了,u被標記為新創建的1跳樹的根。讓 SWu 表示這棵樹中的所有葉子。然后他們應用貪心算法從SWu覆蓋B中所有節點的集合中選擇最少數量的集合。最后,這些節點構成了保護者發起者的集合。鄭等人。 [144]認為,在負面影響節點的鄰域社區中,橋端會比社區其他部分更早傳播到負面影響節點。如果橋端節點受到保護,那么負面影響節點將不會傳播到社區的其他節點。然后,IBM 問題被概括為通過從網絡中刪除子集中的節點及其輸入和輸出邊來識別最小節點的問題。為了解決這個問題,他們提出了基于貪婪的最小頂點覆蓋算法(MVCBG)。為了保護所有橋端免受負面影響,直觀的方法是使用深度優先搜索方法獲得負面影響節點與橋端集合之間的所有簡單路徑,然后嘗試以最小的長度阻塞所有這些簡單路徑節點數。然而,由于這些簡單路徑的數量非常多,因此很難在短時間內全部識別出來。因此,為了簡單起見,它們僅屏蔽所有起點為負面影響發起者或可能受到負面影響的節點、終點為橋端的邊,屏蔽最少數量的節點,從而防止謠言不影響任何橋端。該算法在某些數據集中效果良好,但運行時間較長,不適合大規模網絡。
4.5. Methods for specific constraints
4.5.1. Resource cost constraint
??在現實應用中,為了阻止負面影響的傳播,選擇每個正面種子節點通常需要一定的成本。例如,企業通過明星代言擴大影響力,擊敗競爭對手,占領市場份額。但每個明星的出場費都不同,公司的廣告費用也有限。如何以有限的成本發揮最大的影響力是一個值得研究的問題。利頭等人。 [35]利用模擬退火方法在有限的成本下確定最合適的種子。該方法基于貪心策略,迭代地選擇種子節點加入集合S。當達到所需的種子數k,或者滿足終止條件時,迭代終止。模擬退火在尋找最優解的過程中引入了隨機因素。它以一定的概率接受比當前解更差的解,因此可以避免局部最優解而達到全局最優解。實驗結果表明,該方法能夠逼近最優解。當應用于實時應用時,選擇1000個種子節點的時間不超過23分鐘。陳等人。 [148]研究了具有成本約束的復雜網絡的影響傳播模型。他們使用疊加隨機游走策略來衡量網絡的影響傳播。為了降低算法的時間復雜度,將影響傳播控制在某個子圖的范圍內,并提出了抑制負面影響傳播的有效方法。在此基礎上,引入滲流的思想來確定約束節點集合的大小。實驗結果表明,該算法不僅能夠有效限制負面效應的傳播,而且在成本約束下取得了較好的性能。施等人。 [149]通過有限成本下的自適應資源配置策略來抑制負面影響。他們的結論是,負面影響傳播過程中的不同時間段可能會出現不可預見的特殊情況,因而不同時間段所需的鎮壓資源成本也不同。例如,在t時刻,負面影響傳播緩慢,因此只需要少量的成本來抑制負面影響,即剩余的資源可以用于后期的分配。圖6示出了自適應資源分配的示意圖,其中網絡拓撲如圖6(a)所示,感染節點用紅色表示,抑制節點用綠色表示,黃色節點受到抑制節點的保護,紅色箭頭為負面影響傳播路徑。假設S在第一輪傳播中以1/2的概率感染節點A、B、C和D,在第二輪傳播中,被感染的節點將以100%的概率感染其鄰居。從圖 6(b)可以看出,如果 S 在第一輪感染節點 A 和 B,并選擇節點 A 和 B 作為抑制節點,則節點 A 和 B 可以保護 14 個節點免受感染。然而,如果S在第一輪中感染了節點C和E(如圖6(c)),則可以看出節點A和B在第一輪中未能保護其余節點。此時,我們可以釋放資源A和B,并將D和F設置為第二輪傳播的抑制節點,即可完成對剩余節點的有效保護。
4.5.2. Uncertain influence source
? ?現有算法的設計通常假設在 IBM 問題的種子節點選擇過程中負種子集的來源始終是已知的。然而,在真實的社交網絡環境中,由于社交網絡的隱私規則,很多時候我們只知道負種子的分布情況以及每個節點成為負種子的概率,很難知道負種子的確切來源。負面影響。負面影響源的分布用來描述負面種子的不確定性,可以通過經驗知識或用戶行為觀察來估計。在這種情況下,如何最大限度地阻斷來自不確定來源的負面影響傳播,引起了學者們的關注。陳等人。 [150]將該問題定義為不確定源的負影響塊最大化問題(IBM-US),并提出了一種基于采樣的IBM-US-SB-Seed算法來實現IBM-US問題的近似解。設H為分布概率p?下所有可能的負種子集的集合,C和D分別為正種子節點和負種子節點。定義g(c)為正、負種子聯合影響下的負影響阻止期望值,計算公式為:
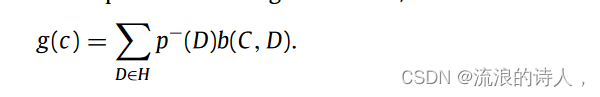
這里,負面影響阻止 b(C , D) 是正面種子集 C 減少負面激活節點。因此,IBM-US問題是找到一個滿足以下條件的最優正種子集C*:
因為H的大小與種子節點的數量有關,即:H = 2|V|,如果節點總數很大,那么H呈指數增長。由于直接優化方程是不切實際的。 (31)式中,根據節點v的概率分布p?(v),采用采樣的方法來選擇負種子節點集合。設N為采樣到的負種子節點集合的個數,用HN = { D1、D2、. 。 。 , DN } 分別。令C*N為基于HN中的負種子集獲得的最優種子集。 C * N 用于近似C * 。 HN 中集合 Di 的概率 p?(Di) 選擇為:
4.5.3. On signed networks
??目前大多數關于 IBM 問題的研究都集中在未簽名的社交網絡上,而忽略了節點之間關系的極性。在簽名的社交網絡中,每個鏈接可能代表其連接的用戶之間的積極關系(例如,朋友或喜歡)或消極關系(例如,敵人或不喜歡)。忽視用戶之間關系的這種極性可能會導致高估積極影響,并在實際應用中造成不利影響。因此,一些學者也針對簽名網絡上的IBM問題進行了相關研究。一些研究使用貪婪算法來解決簽名社交網絡中正面影響或負面影響最大化的問題[29,153–155]。盡管貪心算法可以實現良好的近似,但它們的計算成本很高并且效率不夠。李等人。 [156]提出了一種基于模擬退火的種子節點集選擇方法,以解決簽名社交網絡中擴展獨立級聯模型下的積極影響最大化問題。除此之外,他們還開發了兩種啟發式,即距離限制和單節點積極影響啟發式,以加快其方法的收斂過程。近年來,人們提出了許多新的相反影響擴散模型和在符號網絡中最大化積極影響擴散的方法[157,158]。積極影響最大化算法的效率和準確性得到了極大的提高。然而,在上述現有工作中,有兩個因素阻止他們在簽名網絡中的積極影響最大化問題上獲得高質量的結果,第一個是因為很少有人考慮負邊在影響傳播中的重要性。第二點是,許多方法在選擇候選種子集時通過蒙特卡羅模擬來估計影響傳播。因此,為了解決這個問題,盛等人。 [159]觀察到負邊沿比正邊沿發揮更重要的作用。他們提出了基于傳播規則的反向影響傳播模型,并定義了影響傳播函數,以避免模擬正向影響并減少計算時間。最后,提出了一種種子節點選擇算法PIM-SC,以獲得符號網絡中最大的正向影響傳播。該算法通過影響力傳播函數計算種子節點的傳播增量,然后采用貪心策略依次選擇種子節點。具體流程如下。令 d+ t (S, u, +) 和 d+ t (S, u, ?) 為節點 u 的正邊和負邊??在時間 t 收集的正向影響。類似地,令 d? t (S, u, +) 和 d? t (S, u, ?) 為節點 u 的正邊和負邊??在時間 t 收集到的負面影響。根據本文定義的相反影響傳播規則,如果邊(v,u)是正邊,則節點u將在時間t以概率P(v,u)被激活為正(或負)狀態。類似地,如果邊 (v, u) 是負邊,則節點 u 將以概率 P(v, u) 在時間 t 被激活為負(或正)狀態。則可以得到節點u在不同情況下受到的影響:

4.5.4. On dynamic network?
??斯卡曼等人。 [160]研究了使用實時信息在網絡中分配治療資源以抑制病毒的擴散。首先,他們提出了一個動態資源分配問題(DRA)的模型公式。然后,他們提出了感染邊緣最大減少(LRIE)控制策略,該策略最小化抑制病毒擴散成本的二階近似。他們分析說,這種方法最大限度地減少了可以將感染傳播到健康節點的感染邊緣的數量,從而減少了感染在網絡中的分散。對各種隨機生成的網絡和現實世界網絡的模擬表明,所提出的 LRIE 策略是比較策略中最有效和最魯棒的。此外,盡管IBM問題已被廣泛研究,但現有的大多數工作都忽略了截止日期和影響傳播延遲的影響。在許多現實情況下,例如總統選舉,必須遵守最后期限,以盡量減少錯誤信息的傳播。受到安全帶解決方案的啟發,Manouchehri 等人。 [28]研究了時間IBM并提出了一種基于采樣的算法TIBM-M。該算法首先計算所需樣本的數量,然后通過生成樣本將IBM問題轉化為最大覆蓋問題。最后利用貪心法尋找抑制影響節點。實驗表明,TIBM-M算法在效果上與貪心算法一致,能夠顯著提高效率。在社交網絡中,當受感染節點的百分比隨著時間的推移達到一定閾值時,就會引起相關當局的注意,進而發現網絡中負面影響的傳播者。一旦發現有負面影響的節點,相關部門就會對其進行封殺。圖7顯示了基于從新浪微博提取的數據的幾個典型的主題演化曲線。 Wang 等人基于 Ising 模型 [62]。 [61]提出了一種結合全球負面影響流行率和個人傾向的動態負面影響擴散模型。他們還引入了用戶體驗效用的概念,并提出了效用函數的修改版本來衡量效用與阻塞時間之間的關系。然后,他們利用生存理論來分析在用戶體驗效用的約束下節點被激活的可能性。最后提出了基于節點選擇策略和最大似然策略的貪心算法和動態分塊算法。該算法提出謠言全局話題流行度的概念來描述一種常見的社會現象,即當負面影響傳播一段時間后,可能會產生一種“負面影響氛圍”,影響網絡社交的判斷或決策。網絡用戶。假設在時間 t0 檢測到負面影響,貪心算法的目標是最小化激活的節點數量在時間 t1 受到負面影響。在t1時刻,根據生存理論,節點被激活的概率定義如下:
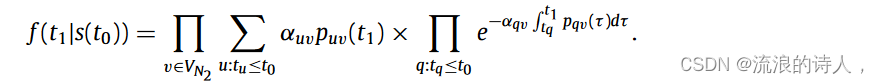
?5. Applications of influence blocking maximization
??IBM 的問題是識別一小部分節點,以在給定的擴散模型下最大化阻止負面影響傳播。它在謠言抑制、疫情控制、競爭性營銷、識別意見領袖、預防交通擁堵等許多應用中都有明確的實際動機。下面我們將回顧近年來的一些進展。
5.1. Rumor suppression
??由于在線社交網絡促進了信息的快速、廣泛傳播,網絡上也出現了不同形式的謠言[21,161]。與真實消息相比,謠言的傳播速度更快、范圍更廣,更容易影響用戶的判斷。因此,這種在網上呈現的虛假信息可以迅速改變輿論并引起社會恐慌[9,22]。 IBM 的一個重要應用是社交網絡中的謠言控制。因此,一些學者對社交網絡中抑制謠言等負面影響的方法進行了廣泛的研究,包括謠言傳播模型和抑制算法。其中,謠言傳播模型的過程與網絡中病毒傳播的過程類似。因此,謠言傳播主要基于經典流行病模型或其改進版本[??10,11,50,54,162,163]。謠言抑制算法主要包括屏蔽謠言節點[14,58,61,63,64,69,72,73]、屏蔽謠言鏈接[8,23,24,75–77,80,83,160,164]和抑制謠言的方法通過積極影響[5,6,38,87,165–169]。張等人。 [170]認為用戶是謠言的被動接受者,謠言應該通過用戶的瀏覽行為傳播,并基于隨機游走模型對謠言的傳播進行建模。基于此,提出了一種基于 RanSel 的排序方法,選擇 k 個節點作為“保護者”,以保護盡可能多的節點免受謠言的影響。李等人。 [165]認為,在謠言傳播過程中,被謠言污染的節點并不一定成為謠言傳播者,因為后來出現在互聯網上的正確信息使他們做出正確的判斷。比如,如果有學生在班里散布“因為疫情,期末考試取消了”的虛假信息,整個班級就會被謠言污染,但每個學生也會有自己的判斷關于該消息。當網絡中受保護的節點發布“下周期末考試”的正確信息時,受污染的節點就會做出自己的決定,并可能傳播真實的信息。基于這個想法,他們提出了γ?k謠言抑制問題,通過在污染集中找到γ×k個保護器和在未污染集中找到(1?γ)×k個保護器來保護網絡,如圖8所示。 ,分別為線性閾值模型和獨立級聯模型設計了近似比率為 1 ? 1/e 的貪婪近似算法。該算法在三個真實的社交網絡上進行了測試:NetHEPT (http://arXiv.org)、WikiVote (http://snap.stanford.edu/data/wiki-Vote.html.)和Slashdot0811(http://snap.stanford.edu/data/soc-Slashdot0811.html.),實驗結果表明可以實現更好的性能。他等人。 [168]提出了一種實時優化策略,能夠在預期時間段內以最小成本抑制謠言的傳播。為了避免謠言傳播對社會造成巨大威脅,他們還提出了脈沖策略,能夠定期在網絡中傳播積極影響。這兩種策略在digg2009數據集上都取得了優異的性能(http://www.isi.edu/lerman/downloads/digg2009.html)。
? ?童等人。 [27]研究了存在多個正級聯時的謠言阻止問題。通過制定謠言感知博弈和謠言遺忘博弈,他們表明在最佳響應和近似響應下,均衡策略和博弈策略都提供了 2 近似和 (2e + 1/e + 1) 近似社會效用,即不受謠言影響的節點數量。霍斯尼等人。 [166]提出了傳播過程的HISB模型,該模型描述了多路在線社交網絡中謠言的傳播(如圖9所示)。基于該模型,他們從網絡推理的角度并運用生存理論,提出了一種真相運動策略,以最大限度地減少多重在線社交網絡中謠言的影響。該策略通過在檢測到謠言后立即選擇最有影響力的節點并開展真相活動來提高對謠言的認識來防止謠言的影響。霍斯尼等人。 [167]發現社交網絡中的每個用戶對于謠言都有不同的態度和想法。他們可以根據自己的經驗和知識來支持、質疑和反對謠言,這種態度對謠言的傳播起著重要作用。例如,推特上對于“奧巴馬是穆斯林”的謠言有不同的看法,每個用戶都有不同的態度和想法,如圖10所示。
? ?基于這種考慮,Hosni 等人。 [167]提出了一種基于馬爾可夫鏈模型的新方法,將個體對謠言的不同態度整合到HISB模型中。這個過程考慮兩個極點:支撐并拒絕極點。然后,他們假設從一極到另一極的轉變至少應該通過對謠言的中立或質疑意見。提出一種動態阻塞期(DBP)方法來求解多謠言影響最小化問題。每個選定節點的阻塞時間是根據其在社交網絡中的活動來估計的。該解決方案是利用生存理論從網絡推理問題的角度制定的。因此,提出了一種基于似然原理的算法來選擇最有可能被感染的節點并支持謠言。這種方法屏蔽了對大量謠言傳播貢獻最大的節點。這些節點將被封鎖一段時間,以避免對用戶在 OSN 中的體驗造成負面影響。該算法可以保證最優解的逼近率在63%以內。圖11是DBP算法的性能圖。
? ??圖 11 給出了當謠言數量 RN 分別為 2、4、6 和 8 時,最終受到謠言影響的個體數量比例。從圖11中可以看出,被選為阻塞節點的比例K值越大,受謠言影響的比例越小。圖12顯示了不同算法可以減少謠言傳播中感染人數的百分比。
??可以看出,算法DBPA在不同場景下都比其他算法有更好的性能,并且可以最大限度地減少謠言對傳播的影響。
5.2. Epidemic controlling
? ?IBM問題的另一個重要應用是預防流行病傳播[15,70,171–178]。新冠肺炎疫情在不到兩個月的時間里席卷全球,病毒在人群中肆意傳播,并呈現不斷擴大的趨勢。這次疫情的蔓延導致了世界經濟的巨大危機,歧視疫情嚴重國家的人民將是對人類的巨大挑戰。在各種疫情防控措施中,疫苗接種是最有效的策略之一。更高的疫苗接種覆蓋率可以提高疾病傳播和控制的臨界閾值,或中斷病毒在復雜網絡上的傳播[135,179–182]。
? ?薛等人。 [183]??研究了在缺乏全局網絡結構信息的情況下控制網絡上疫情傳播的分布式鏈路運行問題。他們將原始問題近似為涉及相鄰矩陣特征向量的問題。通過事件觸發通信的設計,分布式PI估計算法最終賦予局部個體特征向量的全局知識。圖13顯示了三個隨機數據集中不同策略的流行閾值隨邊緣刪除的變化趨勢。馬塔馬拉斯等人。 [124]提出了一組離散時間控制方程來評估邊緣對復雜網絡中傳播過程的貢獻。結果用于制定流行病遏制策略,該策略基于遞歸地停用具有最大鏈接流行病重要性的鏈接,同時保持整個網絡的連接性,即避免碎片化。圖14是航空運輸網絡中不同策略的疫情防控示意圖。結果開辟了一種在邊緣而不是節點級別分析復雜網絡動態擴散模型的新方法。巴薩拉斯等人。 [120]考慮了流行病傳播的動態因素,提出了一種名為關鍵邊緣檢測器(CED)的算法,該算法根據關鍵連接的擴散能力來檢測關鍵連接。通過每一步中有限數量的動作刪除,這些邊將構成免疫目標,以保存復雜網絡的最大可能部分。圖 15 顯示了不同方法的性能與兩個數據集(http://konect.unikoblenz.de/ 和 http://snap.stanford.edu/data/index.html)中影響概率 λ 的函數關系。 。李等人。 [121]提出了一種獨立于初始感染源的Limited-Temporary-Links-Removed策略。無論初始感染源是單個還是多個、同時還是分散,該策略通過暫時移除或調節網絡中病毒傳播最短路徑上的重要邊緣,使病毒繞過或被阻斷。可以有效減緩病毒傳播、控制病毒傳播范圍,同時保證網絡系統的基本功能不受影響。古斯里亞迪等人。 [128]提出了一種分布式算法來估計特征向量并驗證網絡的連通性。通過模仿在每次迭代中從網絡中刪除一個或多個鏈接的基于梯度的方法,可以有效地計算次優解決方案,以解決維持網絡連接性同時減慢或停止網絡中疾病傳播的問題。圖 16 顯示了隨著隨機數據集中刪除的鏈接數量增加,不同策略的傳播閾值的趨勢。目前,疫情傳播網絡大多呈現社區結構,社區中心和橋梁是影響力節點,在疫情傳播中發揮關鍵作用[184-190]。在疫情傳播網絡中,存在重疊的社區和重疊的節點,它們在疫情傳播中發揮著重要作用。因此,可以考慮每個社區中重疊節點的數量來進行免疫節點選擇[191]。嚴等人。 [192]認為全局或局部策略的選擇取決于網絡社區之間的緊密程度。如果社區聯系緊密,則全局政策效果更好,否則本地政策效果更好。
5.3. Competitive marketing
??在線社交網絡的日益普及促進了信息、觀點和新產品的廣泛傳播,為“病毒式營銷”提供了巨大的機會。在現實的市場場景中,往往會有多家企業銷售同類型的產品,不同的企業都希望通過開展有競爭力的營銷策略來獲得口碑效應的利益最大化,從而擊敗競爭對手,占領市場份額。 193-198]。例如,當蘋果、華為和三星等公司生產最新的手機時。每家公司都試圖說服客戶購買其產品,并在新興市場中占據比競爭對手更大的地位。因此,IBM技術可以用來在競爭市場中最大化利益[85,86,89,93,97,145,199,200]。在病毒式營銷中存在兩種或兩種以上競爭產品的情況下,企業可以利用用戶之間的信息交互來傳播其產品的認知度。吳等人。 [201]通過選擇網絡中對產品營銷有影響力的種子集,最大化社交網絡中競爭影響力的傳播。首先,根據網絡中邊的傳播概率建立可能性圖[202,203],然后設計競爭影響力傳播模型(CISM)來模擬可能性圖下的競爭傳播。基于這個可能性圖,作者使用成本有效的惰性前向(CELF)算法[204]來選擇競爭種子節點。吳等人。 [88]提出了一種啟發式算法CMIA-H來尋找一組傳播對自己有利的信息的用戶。他們還提出了一種啟發式算法CMIA-O,通過最大限度地封鎖競爭對手的信息范圍來抵消競爭對手信息的傳播。該算法在四個真實數據集上進行了測試和驗證:EMAIL(包含1.13K節點)、NetHEPT(包含15.2K節點)、NetPHY(包含37.2K節點)和DBLP(包含65.5K節點)。例如,圖 17 中 EMAIL 數據集的實驗結果表明,隨著正種子(有利于自己的節點)數量的增加,不同的算法可以減少負種子(有利于對手的節點)激活的節點數量。因此,從圖中可以看出,該策略可以有效阻斷不良影響在網絡中的傳播。這也充分說明該方法在市場競爭的場景中具有時效性,能夠快速為商家提供優秀的策略。
? ?在市場經濟中,經常存在一種現象,企業新開發的產品只在某個地區銷售,而不是在全國范圍內推廣。因此,企業需要做的就是如何讓產品能夠在指定區域的競爭中擊敗競爭對手,從而占領該區域的市場份額。朱等人。 [92]將這種情況轉化為如圖18所示的位置感知影響阻塞最大化(LIBM)問題,并提出了兩種基于四叉樹索引和最大樹結構的啟發式算法LIBM-H和LIBM-C。他們在三個真實世界數據集 Ego-Facebook、Brightkite 和 Gowalla(http://snap.stanford.edu/data) 中進行了實驗。 Ego-Facebook 是一個源自 Facebook 應用程序的小型社交地圖。數據集中,每個節點對應一個用戶,而邊則對應彼此之間的好友關系。 Brightkite和Gowalla都是一種數據集,用戶通過簽到來共享他們的位置,其中節點是用戶,兩個節點之間的邊意味著他們具有朋友關系。由于貪心算法在大型網絡中運行速度非常慢,因此作者在 ego Facebook 數據集(包含 4039 個節點)上選取度數最高的 50 個節點作為負種子,來模擬不同算法在小、中、大網絡中阻止負效應的效果地區。實驗結果如圖19所示。從圖19(a)到(f)可以看出,LIBM-H和LIBM-C算法在所有條件下都比其他啟發式算法具有更好的效果。另外,從圖19(g)到(h)可以看出,在任何模型下,LIBM-H和LIBM-C算法的運行時間只需要幾秒,超過四個數量級比貪心算法更快。類似地,在大型社交網絡Brightkite(包含58K節點)和Gowalla(包含197K節點)上的實驗結果如圖1和2所示。 20 和 21. 從從圖中可以看出,LIBM-H和LIBM-C算法在設定的查詢區域內具有優異的分塊效果,這意味著企業可以通過該方法選擇積極的影響力節點,在降低影響力的同時擴大自家產品的影響力從而占領特定領域的市場份額。
5.4. Online social media monitoring
??在線社交媒體是人們相互分享意見、見解、經驗和觀點的工具和平臺。在線用戶能夠通過他們在網上看到的新的、有趣的事物或關于自己的博客來傳播信息。例如,Twitter目前擁有超過3.5億活躍用戶,每天有近1.9億用戶訪問。 Twitter 上的用戶不知疲倦地在 Twitter 上發布新的、有趣的想法、網站、新聞、音樂和視頻鏈接,這些鏈接在各個層面上得到轉發,并迅速傳播到世界各地。當一個想法突然在社交媒體上流傳時,無論這個想法是好是壞,都需要找到該想法傳播中的一些重要節點或重要路徑,因為這些信息可能會對正面信息的傳播產生負面影響[12]。其中重要的一項研究策略是找到一些被稱為意見領袖的人。這些意見領袖可以在網絡信息傳播過程中對大多數其他個體的意見、決策和行動產生影響。即使普通個人的最初意見與意見領袖的意見不同,意見領袖最終也能引導普通個人接受他們想要的意見[19,205-207]。例如,用戶在網絡中擁有的關注者越多,該用戶就越有可能成為意見領袖,而如果用戶只是保持運行記錄,則根本沒有人愿意關注他/她。因此,要想正確的觀點獲得更多的支持者,控制負面觀點的傳播,最重要的方法之一就是挖掘網絡中的意見領袖,并獲得他們的支持。
? ?雷曼等人。 [208]通過使用各種基于中心性的指標和基于社區的檢測方法,在推特上確定了關于“發現新粒子”主題的意見領袖。如圖22所示,Twitter上的用戶之間存在三種類型的交互,即回復、轉發和提及,作者將Twitter數據集分為三個子網絡:回復網絡、轉發網絡和提及網絡。此外,根據用戶的入度和出度之間的關系,區分出五個關鍵用戶:對話發起者用戶、影響者用戶、活躍參與者用戶、網絡構建者和信息橋梁用戶。不同的用戶及其交互模型如圖 1 和 1 所示。 23和24。其中,對話發起者用戶幾乎都是入度節點,而影響者用戶是具有更多入度和一些出度的節點,并且影響者充當網絡中的意見領袖,因為其他用戶在網絡中轉發并在推文中評論影響者。網絡中的活躍參與用戶是具有大量出度而很少或沒有入度的用戶。網絡構建者用戶是鏈接兩個或多個影響者的節點。信息橋梁用戶是連接影響者和活躍參與者的節點.
? ?如圖所示。如圖25-27所示,這三個網絡都有社區結構,有助于網絡中信息的快速傳播[209]。從圖中可以看出,許多低度節點與對話發起者或影響者連接,這些節點不與其他節點共享信息,因為它們只想從意見領袖那里獲取最新信息。例如,在圖25(a)中,可以看出Reply Network被Yifan Hu算法[210]劃分為10696個社區。圖的邊緣是離散的小社區,圖中心的一些彩色社區是對話發起者和影響者所在的社區,社區內的信息由于這些意見領袖的存在而傳播得非常快。
??圖25(b)顯示了從網絡中刪除離散節點和社區后的過濾網絡,雖然只剩下8個社區,但仍然包含超過15%的節點和21%的邊。圖25(c)顯示了不同社區的顏色以及該社區中節點的百分比。因此,在識別出意見領袖后,可以將其作為正向種子節點,影響競爭網絡中的其他節點,阻斷負面影響的傳播。此外,還可以利用信息橋梁節點切斷負面影響者與個人之間的聯系,阻斷負面影響的傳播。大多數關于競爭性信息傳播及相關問題的研究都集中在傳統社交媒體,例如 Twitter 和 Facebook [74]。近年來,出現了一些基于消息的社交網絡(Msg-SN),例如微信,它們通過在朋友圈中發布圖片、文本和網絡鏈接來傳播信息[211]。
??聯系人列表中的朋友。由于Msg-SN中大多數用戶的好友數量較少,僅憑好友數量很難找到擁有數百萬粉絲的關鍵意見領袖。為了找到這樣的關鍵意見領袖來阻止負面影響信息的傳播,姚等人。 [66]提出了一種基于特征向量中心性的啟發式算法,在競爭線性閾值模型下選擇用于阻止負面影響的正種子集。他們收集了超過 24,000 個用戶和 42,000 條瀏覽和分享記錄的真實微信數據,并將數據按照時間段分為 WM 數據集 1 和 WM 數據集 2。 WM數據集1涵蓋了2016年1月8日至14日的數據,WM數據集2涵蓋了2017年10月1日至7日的數據。在微信數據集1中,作者將度數最大的前50個節點作為負節點,并使用他們傳播負面影響,然后通過選擇正面種子來封鎖負面信息。實驗結果如圖28所示。
??從圖28(a)中我們可以看出,當選擇的正種子數量較少時,基于度中心性的策略可以取得更好的效果。這是因為微信的網絡圖比較稀疏,信息很難在網上大規模傳播,而大度節點在阻斷負面種子的擴散路徑中發揮著重要作用。隨著正種子節點數量的增加,雖然所有計數策略的阻塞效果越來越好,但大度節點并不總是出現在負種子的影響力擴散路徑中。在這種情況下,特征向量中心性算法和CLDAG算法可以獲得更好的分塊效果。圖28(b)顯示了通過不同策略選擇150個積極種子以防止網絡中負面影響傳播的運行時間。從結果可以看出,貪心算法需要10多個h才能完成阻塞,而特征向量中心性算法只需要50.84 s。接下來,他們在兩個具有較大負種子集的 WM 數據集上進行了實驗。在每個數據集上,分別通過最大度策略選擇節點和隨機選擇節點策略生成300個節點的負種子集。測試不同策略的阻塞效果的結果如圖29所示。在WM數據集1上,當選擇大節點作為負種子集時,特征向量中心性算法的平均性能比CLDAG算法好39.55%。當正向種子節點為 300 個時,特征向量中心性算法和 CLDAG 算法分別可以正向激活 450 個和 318 個節點,并分別減少 383 個和 319 個負向影響激活的節點。當隨機選擇節點作為負種子集時,特征向量中心性算法的平均性能比 CLDAG 算法提高了 9.03%。 WM 數據集 2 的結果如圖 29(c) 和 (d) 所示。當選擇度最大的節點作為負種子集時,當從圖中選擇300個正種子時,特征向量
6. Summary and outlook
??近年來,IBM問題得到了廣泛的研究,并報道了許多有效的方法。在這篇綜述中,我們簡要回顧了IBM問題的最新研究進展。據我們所知,我們對 IBM 問題方法進行了最全面的研究,這些研究在方法數量和所采用的傳播模型方面都已提出。這些方法已根據基于其理論方法的自定義分類法進行了分類。還描述和比較了支持特定 IBM 問題技術和影響傳播模型的最重要結果。該綜述為病毒傳播、政府部門輿情管控、虛假信息管控、信息溯源等提供了理論支撐,也為社會經濟發展安全穩定提供了有力的理論支撐和現實保障。我們希望這篇綜述能夠幫助來自不同背景的研究人員帶來新的想法和見解。然而,IBM問題的進一步研究仍然存在挑戰。 IBM 問題是一個相對年輕的研究領域,仍然存在許多開放的挑戰。需要進一步的研究來理解為什么某些方法效果更好或比其他人更差取決于網絡的屬性。研究哪些特定的網絡結構特性可以為每種技術帶來更好的性能是一個開放的研究問題。此外,適應網絡時間因素的技術很少,也沒有適應網絡動態變化結構的技術。在實踐中處理復雜網絡時的另一個主要困難是阻塞成本,這限制了可以應用的技術種類。因此,IBM未來研究的主要挑戰是:
(1) More realistic and efficient diffusion models are needed
? ?近年來,大多數關于 IBM 問題的研究都是基于節點以單一類型相互鏈接的網絡。然而,在真實的網絡環境中,用戶之間可能存在多種類型的關系。例如,在社交關系網絡中,人與人之間可能存在朋友、親戚、同學等多種關系。在演員-導演-編劇-電影網絡中,存在著合作、編劇和導演等關系。在引文網絡中,存在協作和引文等關系。網絡中的各種關系類型相互補充,傳統的影響力傳播模型已經無法描述這種多元關系網絡。因此,如何為這些由多種關系類型的鏈接組成的多關系網絡[237,238]設計影響力傳播模型是值得研究的。此外,在當前的影響傳播模型中,當正面和負面影響都到達網絡中的節點時,該節點接受它們的概率不會隨時間變化。然而,在真實情況下,個人接受積極或消極影響的概率可能會因許多復雜的社會因素而異。例如,在商品推銷中,涉及商品的屬性包括價格、性能、外觀、品牌等,用戶是否會購買該產品取決于他/她對這些屬性的總體評價,例如,高價格的負面影響很難被接受。用戶接受,品牌和性能的積極影響使得用戶更容易接受產品。因此,如何融合節點的屬性特征和網絡拓撲特征也是未來值得研究的問題[61]。
(2) Consideration of the cumulative factors of negative influence
??目前的研究都是在初始階段進行影響抑制,與實際情況有些出入。在現實網絡中,存在一種現象,在負面影響傳播過程中,只有當被感染節點的比例達到一定閾值時,才會引起相關部門的關注,進而檢測是否存在負面影響。影響網絡中的謠言等節點。如果是負面影響節點,則啟動相關策略進行壓制或封鎖。例如,謠言或病毒通常在初始階段不會被壓制。相反,在對謠言或病毒采取防控行動之前,它們可能已經傳播到了一定階段。因此,有必要考慮考慮負面影響的累積因素的IBM解決策略[239,240]。
(3) Influence of time factor on strategy design
??現有的解決IBM問題的方法大多是基于在負面影響傳播的初始階段制定抑制策略,而沒有考慮時間因素。然而,在現實世界的應用中,許多可預測和不可預見的事件隨著時間的變化而發生:網絡中節點之間的鏈接不斷生成或刪除,影響概率隨時間變化,網絡拓撲不斷更新。例如,在社交關系網絡中,朋友可能會變成敵人;隨著時間的推移,同事可能會成為競爭對手。以前的策略沒有考慮負面影響隨著影響力傳播而隨時間的變化。此外,這些模型假設節點的狀態在被負面影響激活后不再改變。然而,在現實生活中,每個節點的意圖可能會隨著時間而改變。例如,人們對政治活動或新聞事件的態度可能會隨著網絡的整體風向而改變[8],其中負面種子的分布可能會隨著時間的推移而改變。在這種情況下,需要實時修改陽性種子識別方法。因此,現有算法不能滿足實時性要求,需要隨著時間的變化采取更合理的抑制策略。例如,可以研究自適應抑制策略,以便在負面影響傳播期間自適應調整策略,以優化資源和成本。
(4) Blocking the negative influence from uncertain sources
??IBM現有的研究假設,當我們檢測到正種子集來抵消負種子集時,負種子集,即負信息的來源,總是已知的。然而,在真實的社交網絡中,很難知道負面影響的確切來源[150]。由于社交網絡的隱私規則,很難確定社交網絡中傳播的謠言或錯誤信息的來源。很多情況下,我們只知道負種子的分布以及每個節點成為負種子的概率。負面影響源的分布用于描述負面種子的不確定性,可以通過經驗知識或對用戶行為的觀察來估計。關于IBM不確定負源問題的研究相對較少。如何最大限度地防范不確定來源的負面影響也是未來研究的一個具有挑戰性的課題。
(5) Integrating the heterogeneous data of multi-source influence
??隨著社交網絡信息量的不斷增加和網絡結構的日益復雜,從多學科角度對網絡影響力的傳播機制和抑制最大化進行協作研究具有重要的理論意義。例如,在網絡傳播信息獲取的研究中,輿情是由事件產生的,持續時間長、范圍廣。來自單一來源的數據已不能滿足數據分析的豐富性、實時性、準確性的要求。此外,在多源數據的抓取、存儲和處理過程中,由于數據標準的多樣性和信息內容的重復,難以對多源異構數據進行分析。傳統的數據處理技術無法滿足從海量數據中快速提取關鍵信息的需求。而且原始數據缺乏明確的含義,多源數據之間往往難以集成和共享。因此,為了增強異構資源之間的互操作性,可以利用人工智能、大數據等最新的跨學科技術對數據進行標注,進行信息描述,滿足協同數據交互的需求。
(6) IBM problems under cost constraints
??疫苗是全球抗擊流行病傳播的有力工具。越多的人能夠越早接種疫苗,國家就能越快地控制疫情并避免病毒廣泛傳播。然而,在一些發達國家大量儲備疫苗的同時,大多數發展中國家卻陷入嚴重的疫苗短缺。在COVID-19疫情依然嚴重、各種變異毒株給全球抗疫增添更多不確定性之際,疫苗是抗擊疫情的關鍵。世界衛生組織表示,COVID-19 在全球的傳播速度比疫苗的分發速度還要快。這個問題在發展中國家尤其是非洲國家尤為嚴重。疫苗分發問題,即如何以有限的成本最大限度地抑制疫情的傳播,也是IBM應用未來研究的重要領域。總之,考慮到 IBM 問題在許多應用中的重要性,它仍然是許多開放研究問題。預計在不久的將來將提出具有更好準確性和性能權衡的新技術。








)
~~封裝)






)

)
)