前言
? ? ? ? 之前對 Spark SQL 的影響一直停留在 DSL 語法上面,感覺可以用 SQL 表達的,沒有必要用 Java/Scala 去寫,但是面試一段時間后,發現不少公司還是在用 SparkSQL 的,京東也在使用 Spark On?Hive 而不是我以為的 Hive On Spark,經過一番了解之后發現,確實 Spark SQL 要比 HQL 靈活太多了。所以必須學學?SparkSQL(我喜歡用 Java 版本,和 Scala 執行速度一樣,只不過代碼復雜了點,對我來說也沒多復雜),之后用 SparkSQL 對之前的離線項目實現一遍。
1、Spark SQL 介紹
????????Hive 是目前事實上離線數倉的標準,它的缺點是底層使用的 MR 引擎,所以執行稍微復雜點的 SQL 就非常慢,不過它支持更換執行引擎,換成 Spark/Tez 就會好很多,而我們實際開發中也幾乎不會有人去用 MR 引擎的?Hive 去跑,一般都是 Hive on Spark 或者 Spark on Hive 的方式。
1.1、SparkSQL 的特點
正如官網描述:Spark SQL 是 Apache Spark 的一個用于處理結構化數據的模塊。(而不是非結構化)
1.1.1、集成

Spark SQL 將 SQL 和 Spark 程序無縫銜接,它允許我們在 Spark 程序中使用 SQL 或者 DataFrame API 來查詢結構化數據。
1.1.2、統一的數據訪問

這也是 Spark SQL 優于 Hive 的一大原因,它支持很多的數據源(比如 hive、avro、parquet、orc、json、csv、jdbc?等),我們可以通過 API 去訪問這些數據源并且可以將通過 API 或者 SQL 這些不同的數據源連接在一起。
1.1.3、集成 Hive?

Spark SQL 可以使用 Hive 的元數據庫、SerDes 和 UDFs,我們可以在現有的數據倉庫上運行 SQL 或 HiveQL 查詢。
1.1.4、標準連接

這里說的是 Spark SQL 的服務器模式為商業智能工具(比如 BI 工具)提供了工業標準的 JDBC/ODBC。
1.2、不同 API 的執行速度

可以看到,Python 在操作?RDD 時的速度要比 Java/Scala 慢幾乎兩倍多。
1.3、數據抽象
Spark SQL提供了兩個新的抽象,分別是 DataFrame 和 Dataset;
Dataset是數據的分布式集合。是Spark 1.6中添加的一個新接口,它提供了RDDs的優點(強類型、使用強大lambda函數的能力)以及Spark SQL優化的執行引擎的優點。可以從 JVM 對象構造數據集(使用 createDataFrame 方法,參數是Java對象集合),然后使用函數轉換(map、flatMap、filter等)操作數據集。數據集API可以在Scala和Java中使用。Python 和 R 并不支持Dataset API。
DataFrame 是組織成命名列的 Dataset。它在概念上相當于關系數據庫中的表或 R/Python中的DataFrame,但在底層有更豐富的優化(這也是為什么 R/Python 操作 DataFrame 的效率能和 SQL、Java/Scala 差不多的原因)。DataFrame 可以從各種各樣的數據源構建,例如: 結構化或半結構化數據文件(json、csv)、Hive中的表、外部數據庫或現有的 rdd。DataFrame API 可以在Scala、Java、Python和 R 中使用。在Scala API中,DataFrame 只是 Dataset[Row] 的類型別名。而在Java API中,使用 Dataset<Row> 來表示DataFrame。
在Spark支持的語言中,只有Scala和Java是強類型的。因此,Python和R只支持無類型的DataFrame API。
1.3.1、DataFrame
DataFrame 可以比作一個表格或電子表格,它有行和列,每一列都有一個名稱和數據類型。它提供了一種結構化的方式來存儲和處理數據。
使用場景:DataFrame 非常適合處理結構化數據,也就是具有明確定義的模式的數據。它支持各種數據源,如 CSV 文件、數據庫、JSON 等。DataFrame 提供了豐富的操作,如篩選、聚合、連接等,使得數據處理變得簡單高效。當我們需要執行 SQL 查詢或進行統計分析時,DataFrame 是首選的數據結構。
1.3.2、DataSet
DataSet 可以比作一個帶有標簽的盒子。每個數據集都包含一組對象,這些對象具有相同的類型,并且每個對象都有一組屬性或字段。與 DataFrame 不同,DataSet 是類型安全的,這意味著 JVM 可以在編譯時捕獲類型錯誤。
使用場景:DataSet 適用于需要類型安全和對象操作的情況。它提供了更強大的類型檢查和編譯時錯誤檢查,以及更豐富的函數式編程接口。當我們需要處理復雜的數據結構、需要執行對象轉換或利用 Lambda 表達式等高級功能時,DataSet 是更好的選擇。但是需要注意的是,DataSet 在某些情況下可能比 DataFrame 更復雜,并且可能需要更多的內存和處理時間。
1.3.3、DataFrame 和 DataSet 的對比
類型安全性
- DataFrame 不是類型安全的。它的每一行是一個Row對象,字段的類型是在運行時解析的。因此,如果在處理數據時類型不匹配,可能會遇到運行時錯誤。
- 相比之下,DataSet 是強類型的分布式集合。當你定義一個 DataSet 時,你需要為其提供一個case class(使用 Scala API 時),這個 case class定義了數據的結構。由于DataSet的每個元素都由這個 case class 的實例表示,因此每個字段的類型在編譯時就是已知的。這提供了更好的類型安全性,允許在編譯時捕獲許多類型錯誤。
數據源和兼容性
- DataFrame可以很容易地從各種數據源中創建,如CSV文件、JSON、數據庫等,并且它提供了與這些數據源的直接兼容性。
- DataSet也可以從這些數據源創建,但通常需要通過DataFrame作為中間步驟,或者需要更多的代碼來定義數據的結構。
優化和性能:
DataFrame 和 DataSet在處理大量數據時都非常快,但有時候,DataFrame可能會因為它的結構更簡單而得到更多的優化,跑得更快一些。但是同樣對于 DataSet ,因為提前知道了每一列的數據類型,所以在某些情況下,它也可以進行優化,讓處理速度更快。
1.4、Spark on Hive /?Hive on Spark
1.4.1、Spark on Hive
Spark on Hive是Hive只作為存儲角色,Spark負責sql解析優化,執行。這里可以理解為Spark通過Spark SQL使用Hive語句操作Hive表,底層運行的還是Spark RDD。具體步驟如下:
- 通過SparkSQL,加載Hive的配置文件,獲取到Hive的元數據信息;
- 獲取到Hive的元數據信息之后可以拿到Hive表的數據;
- 通過SparkSQL來操作Hive表中的數據。
1.4.2、Hive on Spark
與Spark on Hive不同,Hive on Spark則是Hive既作為存儲又負責sql的解析優化,Spark負責執行。這里Hive的執行引擎變成了Spark,不再是MR。實現這個模式比Spark on Hive要麻煩得多,需要重新編譯Spark和導入jar包。
1.4.3、性能對比
相比之下,Spark on Hive 應該是要更好一些,畢竟 Spark on Hive 更加 "原生",底層就是 RDD 計算,只有元數據用了Hive,對SQL的解析,轉換,優化等都是Spark完成(而且 Spark SQL 相比 Hive 在執行計劃上做了更多的優化)。而 Hive on Spark 只有計算引擎是Spark,前期解析,轉換,優化等步驟都是 Hive 完成。
2、Spark SQL 編程
導入依賴:
<dependency><groupId>org.apache.spark</groupId><artifactId>spark-sql_2.12</artifactId><version>3.3.1</version></dependency><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId><version>1.18.22</version></dependency>
2.1、SparkSession
在 RDD 編程中,我們使用的是SparkContext 接口,但在 Spark SQL中,我們將使用SparkSession接口。Spark2.0 出現的 SparkSession 接口替代了 Spark 1.6 版本中的 SQLContext 和 HiveContext接口,來實現對數據的加載、轉換、處理等功能。
SparkSession內部封裝了SparkContext,所以計算實際上是由SparkContext完成的
2.2、Spark SQL 語法
先創建一個 json 文件作為數據源:
{"name": "李大喜", "age": 20, "dept": "農民"}
{"name": "燕雙鷹", "age": 20, "dept": "保安"}
{"name": "狄仁杰", "age": 40, "dept": "保安"}
{"name": "李元芳", "age": 40, "dept": "保安"}
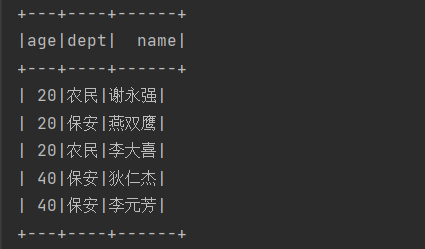
{"name": "謝永強", "age": 20, "dept": "農民"}2.2.1、SQL 語法
package com.lyh;import com.lyh.domain.User;
import org.apache.spark.SparkConf;
import org.apache.spark.sql.*;import java.util.Arrays;public class Main {public static void main(String[] args) {// 1. 創建配置對象SparkConf conf = new SparkConf().setMaster("local[*]").setAppName("test1");// 2. 創建 SparkSessionSparkSession spark = SparkSession.builder().config(conf).getOrCreate();spark.sparkContext().setLogLevel("WARN"); // 只在 Spark Application 運行時有效// 通過 json 文件創建 DataFrame// 在 Java 的 API 中并沒有 DataFrame 這種數據類型, DataSer<Row> 指的就是 DataFrame Dataset<Row> lineDF = spark.read().json("src/main/resources/json/user.json");lineDF.createOrReplaceTempView("users"); // 支持所有的hive sql語法,并且會使用spark的優化器spark.sql("select * from users order by age").show();// 關閉 SparkSessionspark.close();}
}
運行結果:
2.2.2、DSL 語法
lineDF.select("*").orderBy("age").show();效果和上面是一樣的,但是一般能用 SQL 就不用 DSL 。
2.3、自定義函數
2.3.1、UDF
一進一出(傳一個參數進去,返回一個結果)
import org.apache.spark.SparkConf;
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.SparkSession;
import org.apache.spark.sql.api.java.UDF1;
import org.apache.spark.sql.expressions.UserDefinedFunction;
import org.apache.spark.sql.types.DataTypes;import java.util.Locale;import static org.apache.spark.sql.functions.udf;public class MyUdf {public static void main(String[] args) {SparkConf conf = new SparkConf().setAppName("udf").setMaster("local[*]");SparkSession spark = SparkSession.builder().config(conf).getOrCreate();Dataset<Row> df = spark.read().json("src/main/resources/json/user.json");df.createOrReplaceTempView("users");UserDefinedFunction up = udf((UDF1<String, String>) str -> str.toUpperCase(Locale.ROOT), DataTypes.StringType);spark.udf().register("up",up);spark.sql("SELECT up(name),age FROM users").show();spark.close();}}上面,我們定義了一個函數,實現把英文全部大寫,測試:

2.3.2、UDAF
輸入多行,返回一行,一般和 groupBy 配合使用,其實就是自定義聚合函數。
- Spark3.x推薦使用extends Aggregator自定義UDAF,屬于強類型的Dataset方式。
- Spark2.x使用extends UserDefinedAggregateFunction,屬于弱類型的DataFrame
package com.lyh.udf;import lombok.Data;
import org.apache.spark.SparkConf;
import org.apache.spark.sql.*;
import org.apache.spark.sql.api.java.UDF1;
import org.apache.spark.sql.expressions.Aggregator;
import org.apache.spark.sql.expressions.UserDefinedFunction;
import org.apache.spark.sql.types.DataTypes;import java.io.Serializable;
import java.util.Locale;import static org.apache.spark.sql.functions.udaf;
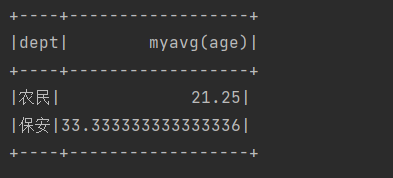
import static org.apache.spark.sql.functions.udf;public class MyUdf {public static void main(String[] args) {SparkConf conf = new SparkConf().setAppName("udaf").setMaster("local[*]");SparkSession spark = SparkSession.builder().config(conf).getOrCreate();Dataset<Row> df = spark.read().json("src/main/resources/json/user.json");df.createOrReplaceTempView("users");spark.udf().register("myavg",udaf(new MyAvg(),Encoders.LONG()));spark.sql("SELECT dept,myavg(age) FROM users group by dept").show();spark.close();}@Datapublic static class Buffer implements Serializable{private Long sum;private Long count;public Buffer(){}public Buffer(Long sum,Long count){this.sum = sum;this.count = count;}}public static class MyAvg extends Aggregator<Long,Buffer,Double> {@Overridepublic Buffer zero() {return new Buffer(0L,0L);}@Overridepublic Buffer reduce(Buffer buffer, Long num) {buffer.setSum(buffer.getSum() + num);buffer.setCount(buffer.getCount()+1);return buffer;}@Overridepublic Buffer merge(Buffer b1, Buffer b2) {b1.setSum(b1.getSum()+b2.getSum());b1.setCount(b1.getCount()+b2.getCount());return b1;}@Overridepublic Double finish(Buffer reduction) {return reduction.getSum().doubleValue()/reduction.getCount();}// 序列化緩沖區的數據@Overridepublic Encoder<Buffer> bufferEncoder() {// 用kryo進行優化return Encoders.kryo(Buffer.class);}@Overridepublic Encoder<Double> outputEncoder() {return Encoders.DOUBLE();}}}Aggregator 有三個泛型參數,分別是輸入類型,緩存類型和輸出類型,需要重寫的方法很好理解,其中,?bufferEncoder 和 outputEncoder 這兩個方法是用來序列化緩沖區和輸出端的數據,這對于分布式處理環境尤為重要,因為數據需要在網絡中傳輸或存儲到磁盤上。
運行結果:
3、Spark SQL 數據的加載和保存
????????Spark SQL 會把讀取進來的文件封裝為一個 DataFrame 對象(DataSet<Row>),所以 Spark SQL 加載數據源的過程就是創建 DataFrame 的過程。
3.1、創建 DataFrame
這里省去公共的環境代碼:
public class Main {public static void main(String[] args) {// 1. 創建配置對象SparkConf conf = new SparkConf().setMaster("local[*]").setAppName("Spark Application名稱");// 2. 創建 SparkSessionSparkSession spark = SparkSession.builder().config(conf).getOrCreate();// 只在提交 Spark Application 時有效spark.sparkContext().setLogLevel("WARN");// 3. 業務代碼// 4. 關閉 sparkSessionspark.close();}
}3.1.1、通過 JVM 對象創建
User user1 = new User("湯姆", 11L);User user2 = new User("李大喜", 18L);User user3 = new User("燕雙鷹", 18L);User user4 = new User("狄仁杰", 11L);Dataset<Row> df = spark.createDataFrame(Arrays.asList(user1, user2, user3, user4), User.class);df.show();?這里的 df.show 就相當于注冊了一張臨時表然后 select * from 這張表。
運行結果:

3.1.2、csv 文件
注意:Spark 讀取 csv 文件時,讀進來的字段都是 String 類型,所以如果有需求需要把 csv 中的數據封裝轉為 Bean 的時候,對于任何類型的數據都必須使用 getString 來讀取,讀取進來再做轉換。比如下面,我們把讀取進來的 csv 文件使用 map 函數轉為 dataset 再做查詢
注意:通過 csv 讀取進來的 DataFrame 并沒有 schema 信息,也不能通過 as 方法轉為 DataSet 方法,因為 DataFrame 的列名和類型都是 _c0 string , _c1 string ... ?和 User 的屬性名根本匹配不上,所以只能通過 map 函數來把 DataFrame 轉為 DataSet ,這樣它才有了類型信息。
// 加載 csv 文件Dataset<Row> df = spark.read().option("seq", ",").option("header", false).csv("src/main/resources/csv/user.csv");// 轉為 dataset 展示df.map((MapFunction<Row, User>) row -> new User(row.getString(0),Long.parseLong(row.getString(1)),row.getString(2)),Encoders.bean(User.class)).show();運行結果:

將結果寫入到 csv 文件中:
寫入到 csv 文件不能通過 DataFrame 直接寫,因為現在它連 schema 都沒有,sql 中的字段它都識別不了。所以必須先轉為 DataSet 再去查詢出結果寫入到文件:
// 加載 csv 文件Dataset<Row> df = spark.read().option("seq", ",").option("header", false).csv("src/main/resources/csv/user.csv");df.printSchema();// 不能這么轉 因為 DataFrame 沒有模式信息 字段名默認是 _c0,_c1 ... 和 User 的屬性名完全匹配不上 會報錯!// Dataset<User> ds = df.as(Encoders.bean(User.class));Dataset<User> ds = df.map((MapFunction<Row, User>) row -> new User(row.getString(0), Long.parseLong(row.getString(1)), row.getString(2)),Encoders.bean(User.class));ds.printSchema();ds.createOrReplaceTempView("users");spark.sql("SELECT CONCAT(name,'大俠') name, age FROM users WHERE age > 18").write().option("header",true).option("seq","\t").csv("output");運行結果:


3.1.3、json 文件
注意:Spark 在讀取 json 文件時,默認把 int 類型的值當做 bigint ,如果我們使用 row.getInt 去解析時就會直接報錯(因為是小轉大),所以我們的 Bean 的整型應該升級為長整型?Long 才不會報錯。此外,Spark 讀取 json 文件后封裝成的 Row 對象是以 json 的字段作為索引的(是根據索引的 ASCII 碼進行排序之后再從 0 開始排的),而不是按照 json 文件中的字段順序,這也是一個坑點。
Dataset<Row> df = spark.read().json("src/main/resources/json/user.json");Dataset<User> ds = df.map((MapFunction<Row, User>) row -> new User(row.getString(2),row.getLong(0),row.getString(1)),Encoders.bean(User.class));ds.show();????????所以一般不會用上面的這種方式去讀取 json,因為我們無法自己預估排序后的字段索引值。我們一般直接把 json 轉為 DataFrame 之后立即轉為 DataSet 進行操作,或者直接把 DataFrame 對象注冊為臨時表,然后使用 SQL 進行分析。
將結果寫入到 json 文件:
? ? ? ? 下面我們把 json 讀取進來解析為 DataFrame 之后直接注冊為臨時表——用戶表,然后用 sql 進行分析(Spark SQL 支持 HQL 中的所有語法,所以這里試用一下窗口函數):
Dataset<Row> df = spark.read().json("src/main/resources/json/user.json");df.createOrReplaceTempView("users");spark.sql("SELECT name,ROW_NUMBER() OVER(PARTITION BY dept ORDER BY age) rk FROM users").write().json("users_rk");這里的 "user_rk" 是輸出文件的目錄名,最終會生成四個文件:兩個 CRC 校驗文件,一個 SUCCESS 和 生成的 json 文件。
運行結果:


我們這里直接用 DataFrame 來將分析出結果寫入到 json 文件,但是上面的 csv 就不可以,因為 json 文件自帶字段名,而字段類型 Spark 是可以識別的。
3.2、與 MySQL 交互
導入 MySQL 依賴:
<dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId><version>8.0.31</version></dependency>public static void main(String[] args) {// 1. 創建配置對象SparkConf conf = new SparkConf().setMaster("local[*]").setAppName("read from mysql");// 2. 創建 SparkSessionSparkSession spark = SparkSession.builder().config(conf).getOrCreate();Dataset<Row> df = spark.read().format("jdbc").option("url", "jdbc:mysql://127.0.0.1:3306/spark").option("user", "root").option("password", "Yan1029.").option("dbtable", "student").load();df.select("*").show();spark.close();}3.3、與 Hive 交互
導入依賴:
<dependency><groupId>org.apache.spark</groupId><artifactId>spark-hive_2.12</artifactId><version>3.3.1</version></dependency>拷貝?hive-site.xml到resources目錄(如果需要操作Hadoop,需要拷貝hdfs-site.xml、core-site.xml、yarn-site.xml),然后啟動 Hadoop 和 Hive。
public static void main(String[] args) {System.setProperty("HADOOP_USER_NAME","lyh");// 1. 創建配置對象SparkConf conf = new SparkConf().setMaster("local[*]").setAppName("spark sql operate hive");// 2. 獲取 SparkSessionSparkSession spark = SparkSession.builder().enableHiveSupport() // 添加 hive 支持.config(conf).getOrCreate();spark.sql("show tables").show();// 4. 關閉 SparkSessionspark.close();}?運行結果:
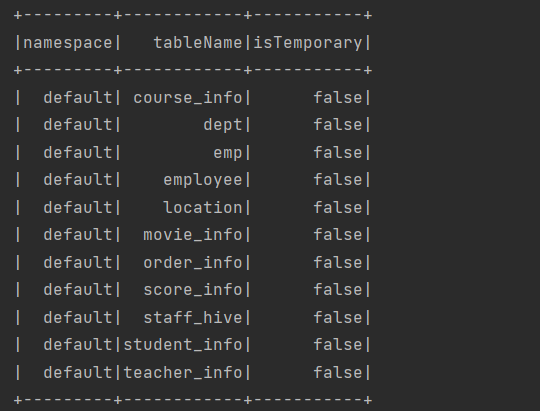
4、Spark SQL 練習
4.1、統計每個商品的銷量最高的日期
從訂單明細表(order_detail)中統計出每種商品銷售件數最多的日期及當日銷量,如果有同一商品多日銷量并列的情況,取其中的最小日期:
public static void main(String[] args) {System.setProperty("HADOOP_USER_NAME","lyh");// 1. 創建配置對象SparkConf conf = new SparkConf().setMaster("local[*]").setAppName("spark sql operate hive");// 2. 獲取 SparkSessionSparkSession spark = SparkSession.builder().enableHiveSupport() // 添加 hive 支持.config(conf).getOrCreate();spark.sql("use db_hive2");// order_detail_id order_id sku_id create_date price sku_num// 每件商品的最高銷量spark.sql("SELECT sku_id, create_date, sum_num FROM (SELECT sku_id, create_date, sum_num, ROW_NUMBER() OVER(PARTITION BY sku_id ORDER BY sum_num DESC,create_date ASC) rk FROM (SELECT sku_id, create_date, sum(sku_num) sum_num FROM order_detail GROUP BY sku_id,create_date)t1)t2 WHERE rk = 1").show();// 4. 關閉 SparkSessionspark.close();}上面個的代碼就像在寫 HQL 一樣,我們可以把其中的子表提出來創建為臨時表:
public static void main(String[] args) {System.setProperty("HADOOP_USER_NAME","lyh");// 1. 創建配置對象SparkConf conf = new SparkConf().setMaster("local[*]").setAppName("spark sql operate hive");// 2. 獲取 SparkSessionSparkSession spark = SparkSession.builder().enableHiveSupport() // 添加 hive 支持.config(conf).getOrCreate();spark.sql("use db_hive2");// order_detail_id order_id sku_id create_date price sku_num// 每件商品的最高銷量spark.sql("SELECT sku_id, create_date, sum(sku_num) sum_num FROM order_detail GROUP BY sku_id,create_date").createOrReplaceTempView("t1");spark.sql("SELECT sku_id, create_date, sum_num, ROW_NUMBER() OVER(PARTITION BY sku_id ORDER BY sum_num DESC,create_date ASC) rk FROM t1").createOrReplaceTempView("t2");spark.sql("SELECT sku_id, create_date, sum_num FROM t2 WHERE rk = 1").show();// 4. 關閉 SparkSessionspark.close();}?沒啥難度,這就是官網說的使用 Spark SQL 或者 HQL?來操作數倉中的數據,之后做個 Spark SQL 項目多練練手就行了。
運行結果:



)



超詳細教程)












)