Elasticsearch 分析器的高級用法二(停用詞,拼音搜索)
- 停用詞
- 簡介
- 停用詞分詞過濾器
- 自定義停用詞分詞過濾器
- 內置分析器的停用詞過濾器
- 注意,有一個細節
- 拼音搜索
- 安裝
- 使用
- 相關配置
停用詞
簡介
停用詞是指,在被分詞后的詞語中包含的無搜索意義的詞。
例如:這里的風景真美。
分詞后,”這里“,”的“ 相對于文檔搜索意義不大,但這種詞使用頻率又比較高。 為了使搜索更加準確,往往需要在構建索引時,忽略掉這些詞
以在這個網站查看常用的停用詞
- 英文:https://www.ranks.nl/stopwords
- 中文:https://www.ranks.nl/stopwords/chinese-stopwords
停用詞分詞過濾器
ES支持兩種方式過濾停用詞
自定義停用詞分詞過濾器
通過自定義分詞過濾器為 停用詞過濾器,來實現停用詞過濾
DELETE /my-index-000001
PUT /my-index-000001
{"settings": {"analysis": {"analyzer": {"stop_analyer": {"tokenizer": "ik_smart","filter": ["stop"]}},"filter": {"stop": {"type": "stop","stopwords": ["我","的","這里","哪里"]}}}},"mappings": {"properties": {"content": {"type": "text","analyzer": "stop_analyer"}}}
}POST /my-index-000001/_analyze
{"field": "content","text": "這里的風景真美"
}

內置分析器的停用詞過濾器
一般情況下 我們常用的內置分析器內部都包含 停用詞的設置,這里以標準分析器和IK分析器舉例
-
standard 分析器
通過指定 standard 分析器 的stopwords 屬性 實現停用詞配置DELETE /my-index-000002PUT /my-index-000002 {"settings": {"analysis": {"analyzer": {"stop_standard": {"type":"standard","stopwords": ["我","的","這","里"]}}}},"mappings": {"properties": {"content": {"type": "text","analyzer": "stop_standard"}}} }POST /my-index-000002/_analyze {"field": "content","text": "這里的風景真美" }
-
ik 分析器
IK分析器默認只有英文停用詞,中文停用詞的使用需要自行添加。
與添加自定義詞典過程類似
進入ik 分析器 config 目錄
編輯 IKAnalyzer.cfg.xml 即可以實現自定義詞典<?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd"> <properties><comment>IK Analyzer 擴展配置</comment><!--用戶可以在這里配置自己的擴展字典 --><entry key="ext_dict">custom-dict.dic</entry><!--用戶可以在這里配置自己的擴展停止詞字典--><entry key="ext_stopwords">custom-stop.dic</entry><!--用戶可以在這里配置遠程擴展字典 --><!-- <entry key="remote_ext_dict">words_location</entry> --><!--用戶可以在這里配置遠程擴展停止詞字典--><!-- <entry key="remote_ext_stopwords">words_location</entry> --> </properties>在 custom-stop.dic 文件中 寫入 所需的停用詞,添加完成后,重啟ES即可
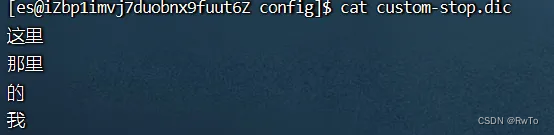
驗證下結果POST /_analyze {"analyzer": "ik_smart","text": "這里的風景真美" }
注意,有一個細節
-
IK分析器過濾器 是在 IK分詞器 內部開始過濾器
POST /_analyze {"analyzer": "ik_smart","text": "this is boy" }POST /_analyze {"tokenizer": "ik_smart","text": "this is boy" }執行上述請求,結果都發生了停用詞過濾,說明IK分析器在分詞器層面就完成了 停用詞過濾。

-
standard 分析器 的stopwords 是作用在 分詞過濾器上的
POST /_analyze {"tokenizer": {"type":"standard","stopwords": ["this","is"]},"text": "this is boy" }執行上述請求,停用詞stopwords 指令沒有生效。說明 stopwords 在分詞器階段無效!

拼音搜索
要實現拼音搜索,需要安裝相應的拼音分析器插件
官網:https://github.com/infinilabs/analysis-pinyin
插件下載地址:https://release.infinilabs.com/analysis-pinyin/stable/
安裝
下載對應 壓縮包(要求與ES版本一致)
本文以 elasticsearch-analysis-pinyin-7.10.2.zip 為例
# 進入es的插件目錄
cd es/plugins
# 創建pinyin目錄
mkdir pinyin
# 在pinyin 目錄下解壓 pinyin分析器
unzip elasticsearch-analysis-pinyin-7.10.2.zip
# 進入es/bin目錄,重啟es
./elasticsearch -d
使用
POST /_analyze
{"analyzer": "pinyin","text":"北京大學"
}
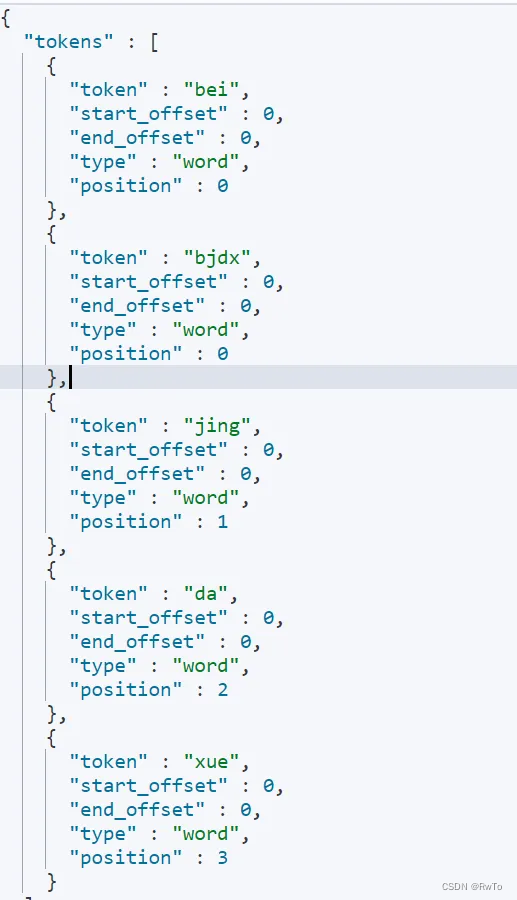
如上:北京大學 被 切割為 bei ,jing, da,xue, bjdx
相關配置
-
keep_first_letter: 啟用后,保留每個漢字的第一個字母。
例如,劉德華變為 ldh。默認值:true。
-
keep_separate_first_letter: 啟用后,保留每個漢字的首字母。
例如,劉德華變成 l,d,h。默認值:false。注意:這可能會因術語頻率而增加查詢的模糊性。
-
limit_first_letter_length: 設置第一個字母結果的最大長度。默認值:16。
-
keep_full_pinyin: 啟用后,保留每個漢字的完整拼音。默認值:true
例如,劉德華變成 [liu,de,hua]。
-
keep_joined_full_pinyin: 啟用時,連接每個漢字的完整拼音。默認值:false。
例如,劉德華變成 [liudehua]。
-
keep_none_chinese: 在結果中保留非中文字母或數字。默認值:true。
-
keep_none_chinese_together: 將非中文字母保留在一起。默認值:true。
例如,DJ 音樂家變成 DJ,yin,yue,jia。設置為 false 時,DJ 音樂家會變成 D,J,yin,yue,jia。注意:應首先啟用 keep_none_chinese。
-
keep_none_chinese_in_first_letter: 將非中文字母保留在首字母中。
例如,劉德華 AT2016 變成 ldhat2016。默認值:true。
-
keep_none_chinese_in_joined_full_pinyin:將非中文字母保留在連接的完整拼音中。
例如,劉德華 2016 將變為 liudehua2016。默認值:false。
-
none_chinese_pinyin_tokenize: 如果非中文字母是拼音字母,則將其分解為獨立的拼音術語。默認值:true。
例如,liudehuaalibaba13zhuanghan 變成 liu,de,hua,a,li、

-MVCC多版本管理)








)








