1. 詞匯表大小(input_dim)計算方法
嵌入層Embedding中的input_dim是根據數據中所有唯一詞(或字)的總數來決定的。可以通過Tokenizer文本分詞和編碼得到。
簡單說,Tokenizer 是一個文本分詞和編碼器,它主要做兩件事:
- 分詞:將句子拆分成詞或字
- 編碼:為每個詞/字分配唯一的數字編號
例如:
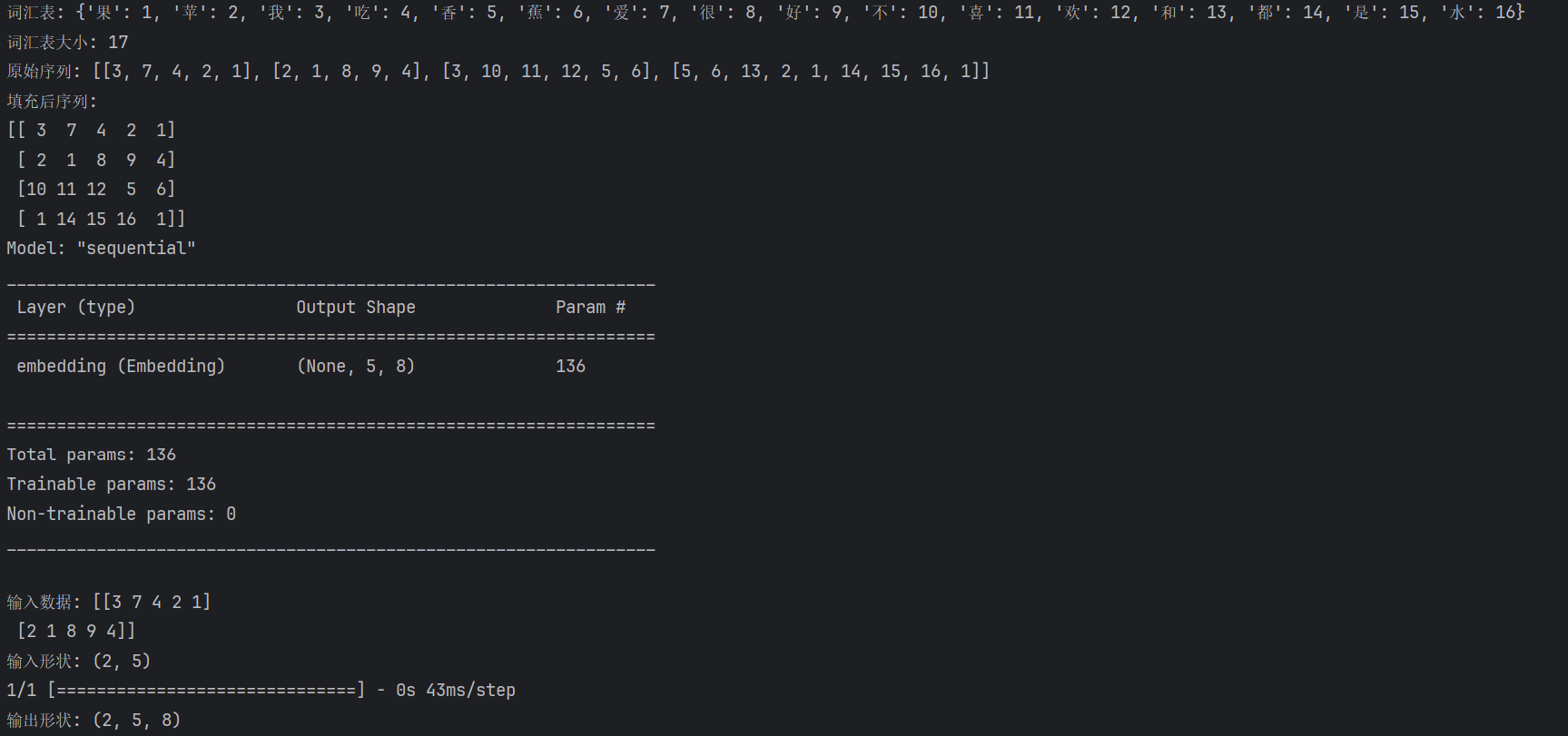
from keras.preprocessing.text import Tokenizer# 假設這是你的訓練文本數據
texts = ["我愛吃蘋果","蘋果很好吃","我不喜歡香蕉","香蕉和蘋果都是水果"
]# 創建分詞器并構建詞匯表,設置 char_level=True 按字分詞
# 如果想要更加合理的中文分詞,比如“蘋果”合并為一個詞,可以使用中文分詞工具(如 jieba)
# import jieba # 需要安裝: pip install jieba后 tokenized_texts = [' '.join(jieba.cut(text)) for text in texts]
tokenizer = Tokenizer(char_level=True)
tokenizer.fit_on_texts(texts) # 學習所有文本,構建詞匯表# 查看詞匯表,可以看到詞或字對應的索引數字
word_index = tokenizer.word_index
print("詞匯表:", word_index)
# 輸出可能是: {'果': 1, '蘋': 2, '我': 3, '吃': 4, '香': 5, '蕉': 6, '愛': 7, '很': 8, '好': 9, '不': 10, '喜': 11, '歡': 12, '和': 13, '都': 14, '是': 15, '水': 16}# 詞匯表大小 = 唯一詞的數量 + 1(+1是為了預留索引0給填充值),這邊的值就是嵌入層Embedding中input_dim的數值
vocab_size = len(word_index) + 1
print("詞匯表大小:", vocab_size) # 輸出: 17# 將文本轉換為數字序列
sequences = tokenizer.texts_to_sequences(texts)
print("數字序列:", sequences)
# 輸出:[[3, 7, 4, 2, 1], [2, 1, 8, 9, 4], [3, 10, 11, 12, 5, 6], [5, 6, 13, 2, 1, 14, 15, 16, 1]]
所以 input_dim=18,因為我們的詞匯表有17個唯一詞 + 1個填充索引
2.Tokenizer作用和簡單用法
Tokenizer會自動:
- 統計所有文本中出現的詞/字
- 按出現頻率從高到低排序
- 分配編號(頻率最高的詞編號為1,次高的為2,以此類推)
import numpy as np
from keras.models import Sequential
from keras.layers import Embedding
from keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences# 1. 準備數據
texts = ["我愛吃蘋果","蘋果很好吃", "我不喜歡香蕉","香蕉和蘋果都是水果"
]# 2. 創建詞匯表
tokenizer = Tokenizer(char_level=True)
tokenizer.fit_on_texts(texts)
word_index = tokenizer.word_index
vocab_size = len(word_index) + 1 # +1 為填充符0print("詞匯表:", word_index)
print("詞匯表大小:", vocab_size)# 3. 文本轉數字序列
sequences = tokenizer.texts_to_sequences(texts)
print("原始序列:", sequences)# 4. 填充序列到相同長度(input_length=5)
padded_sequences = pad_sequences(sequences, maxlen=5, padding='post')
print("填充后序列:")
print(padded_sequences)# 5. 創建Embedding層(input_dim根據vocab_size決定)
model = Sequential()
model.add(Embedding(input_dim=vocab_size, # 這里是18output_dim=8, # 每個詞用8維向量表示,是一個超參數,需要根據經驗和實驗來確定,小詞匯表(<1000):4-16維,一般8input_length=5 # 每個序列5個詞,由最大長度maxlen決定,這邊是9。統計所有序列長度:取一個合適的百分位數(如95%)
))# 查看模型摘要
model.summary()# 測試預測
sample_input = padded_sequences[:2] # 取前兩個樣本
print("\n輸入數據:", sample_input)
print("輸入形狀:", sample_input.shape) # (2, 5)output = model.predict(sample_input)
print("輸出形狀:", output.shape) # (2, 5, 8)
輸出結果:


)

代理的方法)










)



