Kafka Broker 核心原理全解析:存儲、高可用與數據同步
思維導圖
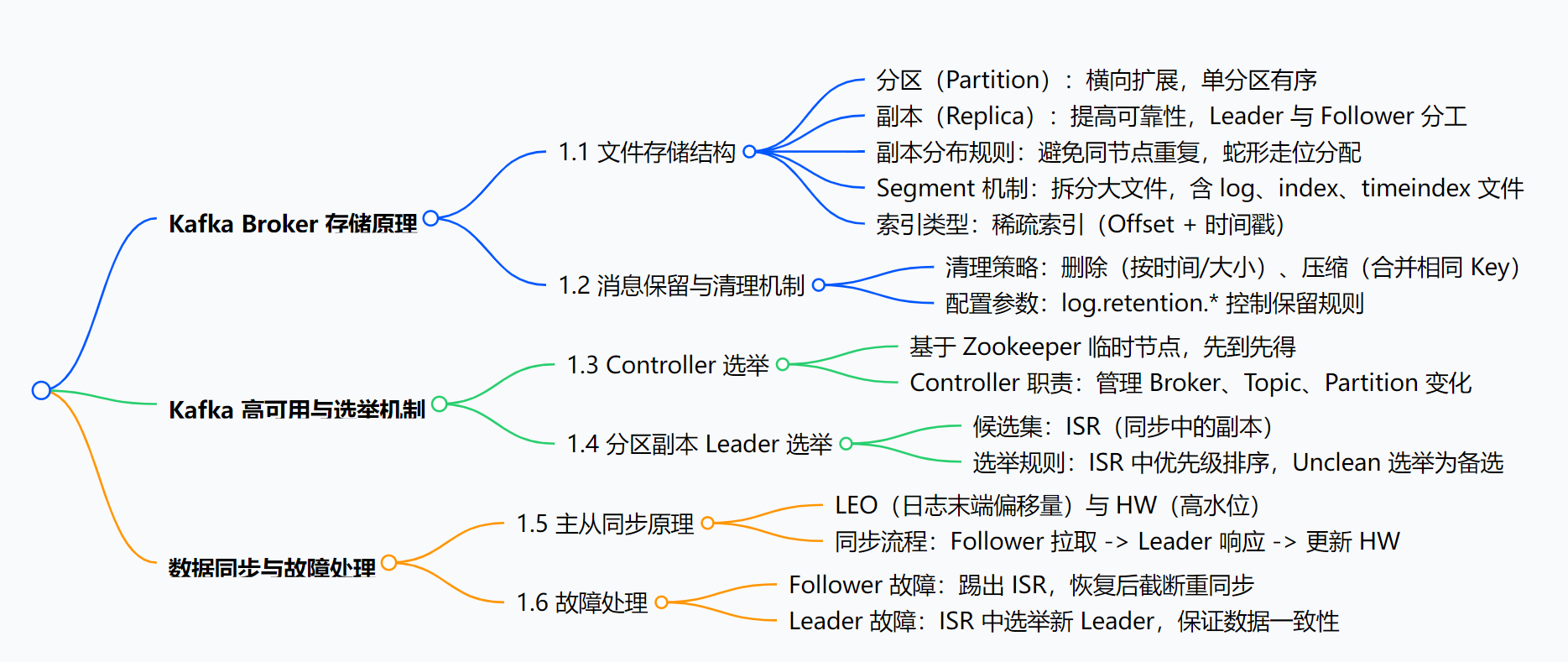
正文:Kafka Broker 核心原理深度剖析
Kafka 作為高性能的分布式消息隊列,其 Broker 節點的設計是支撐高吞吐、高可用的核心。本文將從存儲結構、消息清理、高可用選舉、數據同步四個維度,解析 Kafka Broker 的工作原理。
一、Kafka Broker 存儲原理:如何高效管理海量消息?
1. 分區與副本:橫向擴展與可靠性的基石
-
分區(Partition):
一個 Topic 被拆分為多個 Partition,分布在不同 Broker 上實現橫向擴展。單個 Partition 內的消息順序寫入,但全局無序。例如
tom-topic可分為 Partition0、Partition1 等,每個分區對應獨立的物理目錄(如tom-topic-0)。 -
副本(Replica):
為避免單節點故障導致數據丟失,每個 Partition 可設置多個副本(通過
replication-factor配置)。副本分為:-
Leader:對外提供讀寫服務;
-
Follower:僅從 Leader 異步拉取數據,保持同步。
注意:副本數不能超過 Broker 節點數,否則會報錯。
-
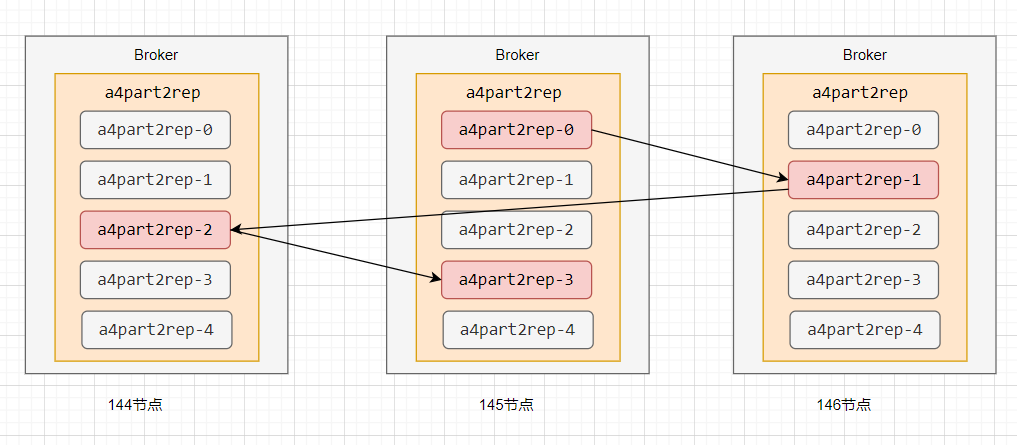
2. 副本分布規則:均衡負載與容災
Kafka 通過 assignReplicasToBrokers 函數分配副本,核心規則包括:
-
分區 0 的第一個副本隨機分配到某個 Broker;
-
其他分區的第一個副本按 “蛇形走位” 分布(如 Broker2→Broker3→Broker1→Broker2…);畫圖表示 “蛇形走位” ;
-
同一分區的副本必不在同一 Broker,避免單點故障。
例如,4 個分區、2 個副本的 Topic 會將 8 個副本均衡分布到 3 臺 Broker 上(3:3:2),確保負載均衡。
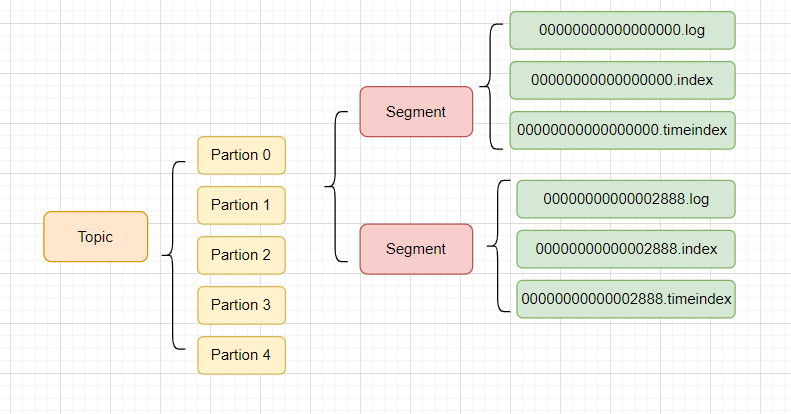
3. Segment 機制:避免文件過大的拆分策略
為防止單個日志文件無限膨脹,Kafka 將每個 Partition 拆分為多個 Segment,每個 Segment 包含:
-
.log:存儲消息數據; -
.index:Offset 與消息物理位置的映射(稀疏索引); -
.timeindex:時間戳與 Offset 的映射。
Segment 切分觸發條件:
-
大小達到閾值(默認 1G,由
log.segment.bytes控制); -
時間超過閾值(默認 1 周,由
log.roll.hours控制); -
索引文件滿(默認 10M,由
log.index.size.max.bytes控制)。
4. 稀疏索引:平衡查詢效率與存儲成本
Kafka 采用 稀疏索引(非每條消息都建索引),通過 log.index.interval.bytes(默認 4KB)控制索引密度:每寫入 4KB 數據,生成一條索引記錄。
-
優勢:減少索引文件大小,降低維護成本;
-
查詢流程:先通過二分法定位 Segment,再在索引中查找最近 Offset,最后在
.log文件中遍歷匹配。
5. 總結
Kafka存儲結構:
二、消息保留與清理機制:如何防止磁盤撐爆?
Kafka 通過兩種策略管理消息生命周期,可通過 log.cleanup.policy 配置(默認 delete)。
1. 刪除策略(Delete)
定時任務(默認每 5 分鐘,log.retention.check.interval.ms)觸發刪除,規則包括:
-
時間閾值:默認保留 1 周(
log.retention.hours),支持分鐘(log.retention.minutes)或毫秒級配置; -
大小閾值:通過
log.retention.bytes限制總大小,超過后從最舊數據開始刪除。
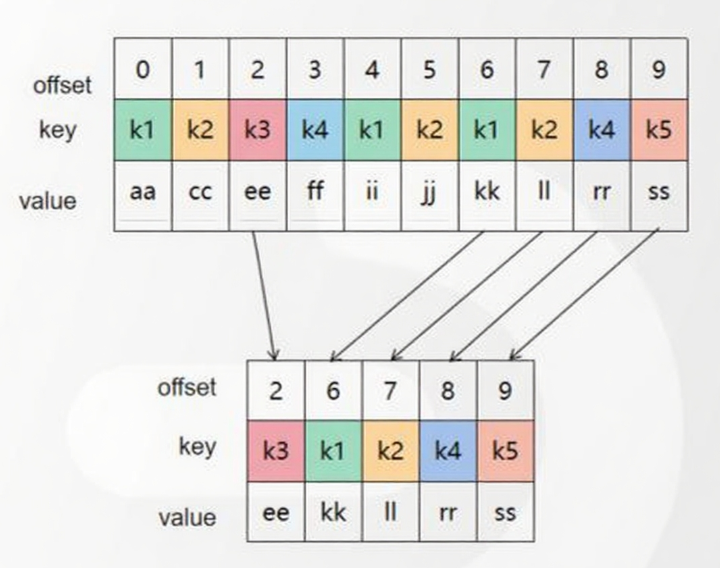
2. 壓縮策略(Compact)
針對 Key 重復的消息(如 __consumer_offsets 主題),壓縮后僅保留最新版本。例如:
-
原消息:
k1:aa → k1:ii → k1:kk -
壓縮后:僅保留
k1:kk(最新 Offset)。壓縮可減少存儲空間,但會導致 Offset 不連續(不影響查詢)。
三、高可用機制:如何保證服務不中斷?
1. Controller 選舉:集群的 “管理者”
Kafka 通過 Zookeeper 選舉唯一的 Controller 節點,負責管理全集群元數據:
-
選舉方式:所有 Broker 競爭創建 Zookeeper 臨時節點
/controller,成功創建者成為 Controller; -
故障轉移:若 Controller 宕機,Zookeeper 臨時節點消失,其他 Broker 重新競爭。
2. Leader 選舉:分區級別的高可用
當 Leader 副本故障時,需從副本中選舉新 Leader,核心邏輯如下:
-
候選集:僅 ISR(In-Sync Replicas) 中的副本有資格(與 Leader 保持同步的副本);
-
選舉規則:ISR 列表中按優先級排序(如副本列表
[146,144,145]中優先選擇 146); -
極端情況:若 ISR 為空,可開啟
unclean.leader.election.enable允許 OSR(落后的副本)參選,但可能導致數據丟失。
四、數據同步與故障處理:如何保證數據一致性?
1. 核心概念:LEO 與 HW
-
LEO(Log End Offset):每個副本中下一條待寫入消息的 Offset(即當前最大 Offset + 1);
-
HW(High Watermark):ISR 中所有副本的最小 LEO,消費者只能消費 HW 之前的消息(確保數據已同步到多數副本)。
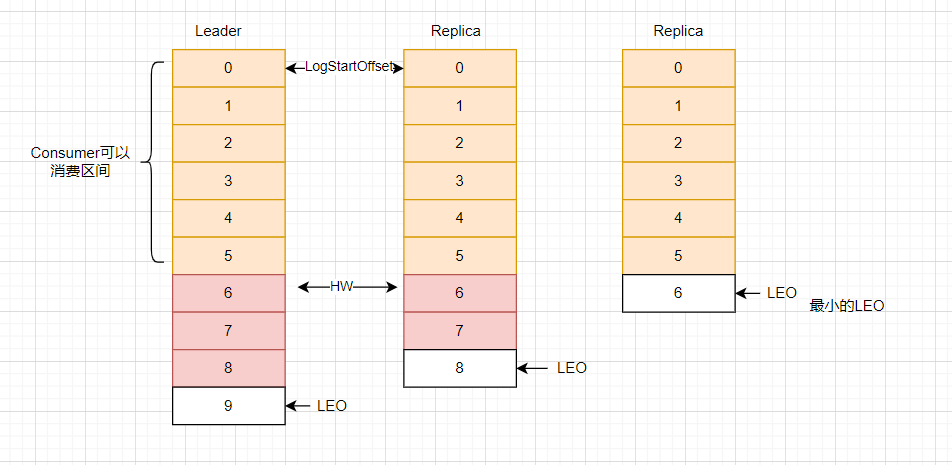
2. 同步流程:Follower 如何追平 Leader?
-
Follower 向 Leader 發送拉取請求(fetch);
-
Leader 響應數據,Follower 寫入消息并更新自身 LEO;
-
Leader 收集所有 ISR 副本的 LEO,更新全局 HW。
3. 故障處理機制
-
Follower 故障:
故障時被踢出 ISR,恢復后先截斷 HW 之后的消息(避免臟數據),重新同步追上 Leader 后,重新加入 ISR。
-
Leader 故障:
從 ISR 中選舉新 Leader,其他 Follower 截斷 HW 之后的消息,向新 Leader 同步數據,保證副本一致性。
總結
Kafka Broker 通過分區與副本實現擴展與可靠性,通過Segment 與稀疏索引高效管理存儲,通過Controller 與 ISR 選舉保障高可用,通過LEO 與 HW 機制確保數據同步一致性。這些設計共同支撐了 Kafka 高吞吐、低延遲、高容錯的核心能力,使其成為分布式系統中消息傳遞的首選方案。

)


——定時任務,緩存監控,服務監控以及系統接口)














