目錄
1 概念認知
1.1 過擬合
1.2 欠擬合
1.3 如何判斷
2 解決欠擬合
3 解決過擬合
3.1 L2正則化
3.1.1 數學表示
3.1.2 梯度更新
3.1.3 作用
3.1.4 代碼實現
3.2 L1正則化
3.2.1 數學表示
3.2.2 梯度更新
3.2.3 作用
3.2.4 與L2對比
3.2.5 代碼實現
3.3 Dropout
3.3.1 基本實現
3.3.2 權重影響
3.4 數據增強
3.4.1 圖片縮放
3.4.2 隨機裁剪
3.4.3 隨機水平翻轉
3.4.4 調整圖片顏色
3.4.5 隨機旋轉
3.4.6 圖片轉Tensor
3.4.7 Tensor轉圖片
3.4.8 歸一化
3.4.9 數據增強整合
????????在訓練深層神經網絡時,由于模型參數較多,在數據量不足時很容易過擬合。而正則化技術主要就是用于防止過擬合,提升模型的泛化能力(對新數據表現良好)和魯棒性(對異常數據表現良好)。
1 概念認知
1.1 過擬合
過擬合是指模型對訓練數據擬合能力很強并表現很好,但在測試數據上表現較差。
過擬合常見原因有:
-
數據量不足:當訓練數據較少時,模型可能會過度學習數據中的噪聲和細節。
-
模型太復雜:如果模型很復雜,也會過度學習訓練數據中的細節和噪聲。
-
正則化強度不足:如果正則化強度不足,可能會導致模型過度學習訓練數據中的細節和噪聲。
舉個例子:
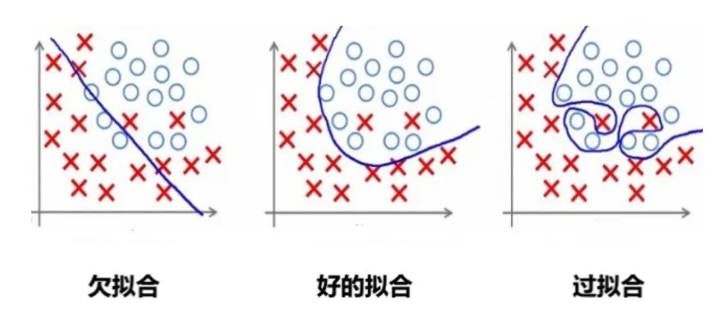
1.2 欠擬合
欠擬合是由于模型學習能力不足,無法充分捕捉數據中的復雜關系。
1.3 如何判斷
過擬合
訓練誤差低,但驗證時誤差高。模型在訓練數據上表現很好,但在驗證數據上表現不佳,說明模型可能過度擬合了訓練數據中的噪聲或特定模式。
欠擬合
訓練誤差和測試誤差都高。模型在訓練數據和測試數據上的表現都不好,說明模型可能太簡單,無法捕捉到數據中的復雜模式。
2 解決欠擬合
欠擬合的解決思路比較直接:
-
增加模型復雜度:引入更多的參數、增加神經網絡的層數或節點數量,使模型能夠捕捉到數據中的復雜模式。
-
增加特征:通過特征工程添加更多有意義的特征,使模型能夠更好地理解數據。
-
減少正則化強度:適當減小 L1、L2 正則化強度,允許模型有更多自由度來擬合數據。
-
訓練更長時間:如果是因為訓練不足導致的欠擬合,可以增加訓練的輪數或時間.
3 解決過擬合
避免模型參數過大是防止過擬合的關鍵步驟之一。
模型的復雜度主要由權重決定,而不是偏置
。偏置只是對模型輸出的平移,不會導致模型過度擬合數據。
怎么控制權重w,使w在比較小的范圍內?
考慮損失函數,損失函數的目的是使預測值與真實值無限接近,如果在原來的損失函數上添加一個非0的變量
其中是關于權重w的函數,
要使L1變小,就要使L變小的同時,也要使變小。從而控制權重
在較小的范圍內。
3.1 L2正則化
L2 正則化通過在損失函數中添加權重參數的平方和來實現,目標是懲罰過大的參數值。
3.1.1 數學表示
設損失函數為 L(\theta),其中 \theta 表示權重參數,加入L2正則化后的損失函數表示為:
其中:
-
是原始損失函數(比如均方誤差、交叉熵等)。
-
是正則化強度,控制正則化的力度。
-
是模型的第
個權重參數。
-
是所有權重參數的平方和,稱為 L2 正則化項。
L2 正則化會懲罰權重參數過大的情況,通過參數平方值對損失函數進行約束。
為什么是?
假設沒有1/2,則對L2 正則化項的梯度為:
,會引入一個額外的系數 2,使梯度計算和更新公式變得復雜。
添加1/2后,對的梯度為:
。
3.1.2 梯度更新
在 L2 正則化下,梯度更新時,不僅要考慮原始損失函數的梯度,還要考慮正則化項的影響。更新規則為:
其中:
-
是學習率。
-
是損失函數關于參數
的梯度。
-
是 L2 正則化項的梯度,對應的是參數值本身的衰減。
很明顯,參數越大懲罰力度就越大,從而讓參數逐漸趨向于較小值,避免出現過大的參數。
3.1.3 作用
-
防止過擬合:當模型過于復雜、參數較多時,模型會傾向于記住訓練數據中的噪聲,導致過擬合。L2 正則化通過抑制參數的過大值,使得模型更加平滑,降低模型對訓練數據噪聲的敏感性。
-
限制模型復雜度:L2 正則化項強制權重參數盡量接近 0,避免模型中某些參數過大,從而限制模型的復雜度。通過引入平方和項,L2 正則化鼓勵模型的權重均勻分布,避免單個權重的值過大。
-
提高模型的泛化能力:正則化項的存在使得模型在測試集上的表現更加穩健,避免在訓練集上取得極高精度但在測試集上表現不佳。
-
平滑權重分布:L2 正則化不會將權重直接變為 0,而是將權重值縮小。這樣模型就更加平滑的擬合數據,同時保留足夠的表達能力。
3.1.4 代碼實現
import torch
import torch.nn as nn
import torch.optim as optim
import matplotlib.pyplot as plt# 設置隨機種子以保證可重復性
torch.manual_seed(42)# 生成隨機數據
n_samples = 100
n_features = 20
X = torch.randn(n_samples, n_features) # 輸入數據
y = torch.randn(n_samples, 1) # 目標值# 定義一個簡單的全連接神經網絡
class SimpleNet(nn.Module):def __init__(self):super(SimpleNet, self).__init__()self.fc1 = nn.Linear(n_features, 50)self.fc2 = nn.Linear(50, 1)def forward(self, x):x = torch.relu(self.fc1(x))return self.fc2(x)# 訓練函數
def train_model(use_l2=False, weight_decay=0.01, n_epochs=100):# 初始化模型model = SimpleNet()criterion = nn.MSELoss() # 損失函數(均方誤差)# 選擇優化器if use_l2:optimizer = optim.SGD(model.parameters(), lr=0.01, weight_decay=weight_decay) # 使用 L2 正則化else:optimizer = optim.SGD(model.parameters(), lr=0.01) # 不使用 L2 正則化# 記錄訓練損失train_losses = []# 訓練過程for epoch in range(n_epochs):optimizer.zero_grad() # 清空梯度outputs = model(X) # 前向傳播loss = criterion(outputs, y) # 計算損失loss.backward() # 反向傳播optimizer.step() # 更新參數train_losses.append(loss.item()) # 記錄損失if (epoch + 1) % 10 == 0:print(f'Epoch [{epoch + 1}/{n_epochs}], Loss: {loss.item():.4f}')return train_losses# 訓練并比較兩種模型
train_losses_no_l2 = train_model(use_l2=False) # 不使用 L2 正則化
train_losses_with_l2 = train_model(use_l2=True, weight_decay=0.01) # 使用 L2 正則化# 繪制訓練損失曲線
plt.plot(train_losses_no_l2, label='Without L2 Regularization')
plt.plot(train_losses_with_l2, label='With L2 Regularization')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.title('Training Loss: L2 Regularization vs No Regularization')
plt.legend()
plt.show()3.2 L1正則化
L1 正則化通過在損失函數中添加權重參數的絕對值之和來約束模型的復雜度。
3.2.1 數學表示
設模型的原始損失函數為,其中
表示模型權重參數,則加入 L1 正則化后的損失函數表示為:
其中:
-
-
-
是模型第i 個參數的絕對值。
-
是所有權重參數的絕對值之和,這個項即為 L1 正則化項。
3.2.2 梯度更新
在 L1 正則化下,梯度更新時的公式是:
其中:
-
-
-
是參數
因為 L1 正則化依賴于參數的絕對值,其梯度更新時不是簡單的線性縮小,而是通過符號函數來直接調整參數的方向。這就是為什么 L1 正則化能促使某些參數完全變為 0。
3.2.3 作用
-
稀疏性:L1 正則化的一個顯著特性是它會促使許多權重參數變為 零。這是因為 L1 正則化傾向于將權重絕對值縮小到零,使得模型只保留對結果最重要的特征,而將其他不相關的特征權重設為零,從而實現 特征選擇 的功能。
-
防止過擬合:通過限制權重的絕對值,L1 正則化減少了模型的復雜度,使其不容易過擬合訓練數據。相比于 L2 正則化,L1 正則化更傾向于將某些權重完全移除,而不是減小它們的值。
-
簡化模型:由于 L1 正則化會將一些權重變為零,因此模型最終會變得更加簡單,僅依賴于少數重要特征。這對于高維度數據特別有用,尤其是在特征數量遠多于樣本數量的情況下。
-
特征選擇:因為 L1 正則化會將部分權重置零,因此它天然具有特征選擇的能力,有助于自動篩選出對模型預測最重要的特征。
3.2.4 與L2對比
-
L1 正則化 更適合用于產生稀疏模型,會讓部分權重完全為零,適合做特征選擇。
-
L2 正則化 更適合平滑模型的參數,避免過大參數,但不會使權重變為零,適合處理高維特征較為密集的場景。
3.2.5 代碼實現
l1_lambda = 0.001
# 計算 L1 正則化項并將其加入到總損失中
l1_norm = sum(p.abs().sum() for p in model.parameters())
loss = loss + l1_lambda * l1_norm3.3 Dropout
Dropout 的工作流程如下:
-
在每次訓練迭代中,隨機選擇一部分神經元(通常以概率 p丟棄,比如 p=0.5)。
-
被選中的神經元在當前迭代中不參與前向傳播和反向傳播。
-
在測試階段,所有神經元都參與計算,但需要對權重進行縮放(通常乘以 1?p),以保持輸出的期望值一致。
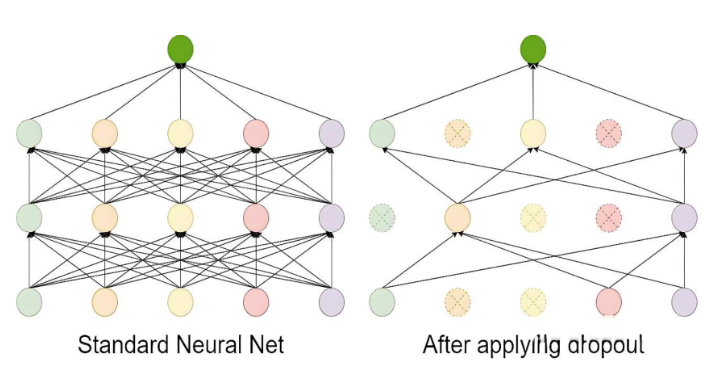
Dropout 是一種在訓練過程中隨機丟棄部分神經元的技術。它通過減少神經元之間的依賴來防止模型過于復雜,從而避免過擬合。
3.3.1 基本實現
import torch
import torch.nn as nndef dropout():dropout = nn.Dropout(p=0.5)x = torch.randint(0, 10, (5, 6), dtype=torch.float)print(x)# 開始dropoutprint(dropout(x))if __name__ == "__main__":dropout()
Dropout過程:
-
按照指定的概率把部分神經元的值設置為0;
-
為了規避該操作帶來的影響,需對非 0 的元素使用縮放因子1/(1-p)進行強化。
假設某個神經元的輸出為 x,Dropout 的操作可以表示為:
-
在訓練階段:

-
在測試階段:
為什么要使用縮放因子1/(1-p)?
在訓練階段,Dropout 會以概率 p隨機將某些神經元的輸出設置為 0,而以概率 1?p 保留這些神經元。
假設某個神經元的原始輸出是 x,那么在訓練階段,它的期望輸出值為:
通過這種縮放,訓練階段的期望輸出值仍然是 x,與沒有 Dropout 時一致。
3.3.2 權重影響
示例:對圖片進行隨機丟棄
import torch
from torch import nn
from PIL import Image
from torchvision import transforms
import osfrom matplotlib import pyplot as plttorch.manual_seed(42)def load_img(path, resize=(224, 224)):pil_img = Image.open(path).convert('RGB')print("Original image size:", pil_img.size) # 打印原始尺寸transform = transforms.Compose([transforms.Resize(resize),transforms.ToTensor() # 轉換為Tensor并自動歸一化到[0,1]])return transform(pil_img) # 返回[C,H,W]格式的tensorif __name__ == '__main__':dirpath = os.path.dirname(__file__)path = os.path.join(dirpath, 'img', '100.jpg') # 使用os.path.join更安全# 加載圖像 (已經是[0,1]范圍的Tensor)trans_img = load_img(path)# 添加batch維度 [1, C, H, W],因為Dropout默認需要4D輸入trans_img = trans_img.unsqueeze(0)# 創建Dropout層dropout = nn.Dropout2d(p=0.2)drop_img = dropout(trans_img)# 移除batch維度并轉換為[H,W,C]格式供matplotlib顯示trans_img = trans_img.squeeze(0).permute(1, 2, 0).numpy()drop_img = drop_img.squeeze(0).permute(1, 2, 0).numpy()# 確保數據在[0,1]范圍內drop_img = drop_img.clip(0, 1)# 顯示圖像fig = plt.figure(figsize=(10, 5))ax1 = fig.add_subplot(1, 2, 1)ax1.imshow(trans_img)ax2 = fig.add_subplot(1, 2, 2)ax2.imshow(drop_img)plt.show()效果:

說明:
nn.Dropout2d(p):Dropout2d 是針對二維數據設計的 Dropout 層,它在訓練過程中隨機將輸入張量的某些通道(二維平面)置為零。
| 參數 | 要求格式 | 示例形狀 | 說明 |
|---|---|---|---|
| 輸入 | (N, C, H, W) | (16, 64, 32, 32) | 批大小×通道×高×寬 |
| 輸出 | (N, C, H, W) | (16, 64, 32, 32) | 與輸入同形,部分通道歸零 |
3.4 數據增強
樣本數量不足(即訓練數據過少)是導致過擬合(Overfitting)的常見原因之一,可以從以下角度理解:
-
當訓練數據過少時,模型容易“記住”有限的樣本(包括噪聲和無關細節),而非學習通用的規律。
-
簡單模型更可能捕捉真實規律,但數據不足時,復雜模型會傾向于擬合訓練集中的偶然性模式(噪聲)。
-
樣本不足時,訓練集的分布可能與真實分布偏差較大,導致模型學到錯誤的規律。
-
小數據集中,個別樣本的噪聲(如標注錯誤、異常值)會被放大,模型可能將噪聲誤認為規律。
數據增強(Data Augmentation)是一種通過人工生成或修改訓練數據來增加數據集多樣性的技術,常用于解決過擬合問題。數據增強通過“模擬”更多訓練數據,迫使模型學習泛化性更強的規律,而非訓練集中的偶然性模式。其本質是一種低成本的正則化手段,尤其在數據稀缺時效果顯著。
在了解計算機如何處理圖像之前,需要先了解圖像的構成元素。
圖像是由像素點組成的,每個像素點的值范圍為: [0, 255], 像素值越大意味著較亮。比如一張 200x200 的圖像, 則是由 40000 個像素點組成, 如果每個像素點都是 0 的話, 意味著這是一張全黑的圖像。
我們看到的彩色圖一般都是多通道的圖像, 所謂多通道可以理解為圖像由多個不同的圖像層疊加而成, 例如我們看到的彩色圖像一般都是由 RGB 三個通道組成的,還有一些圖像具有 RGBA 四個通道,最后一個通道為透明通道,該值越小,則圖像越透明。
數據增強是提高模型泛化能力(魯棒性)的一種有效方法,尤其在圖像分類、目標檢測等任務中。數據增強可以模擬更多的訓練樣本,從而減少過擬合風險。數據增強通過torchvision.transforms模塊來實現。
數據增強的好處
大幅度降低數據采集和標注成本;
模型過擬合風險降低,提高模型泛化能力;
官方地址:
transforms:Transforming and augmenting images — Torchvision 0.22 documentation
transforms:
常用變換類
-
transforms.Compose:將多個變換操作組合成一個流水線。
-
transforms.ToTensor:將 PIL 圖像或 NumPy 數組轉換為 PyTorch 張量,將圖像數據從 uint8 類型 (0-255) 轉換為 float32 類型 (0.0-1.0)。
-
transforms.Normalize:對張量進行標準化。
-
transforms.Resize:調整圖像大小。
-
transforms.CenterCrop:從圖像中心裁剪指定大小的區域。
-
transforms.RandomCrop:隨機裁剪圖像。
-
transforms.RandomHorizontalFlip:隨機水平翻轉圖像。
-
transforms.RandomVerticalFlip:隨機垂直翻轉圖像。
-
transforms.RandomRotation:隨機旋轉圖像。
-
transforms.ColorJitter:隨機調整圖像的亮度、對比度、飽和度和色調。
-
transforms.RandomGrayscale:隨機將圖像轉換為灰度圖像。
-
transforms.RandomResizedCrop:隨機裁剪圖像并調整大小。
3.4.1 圖片縮放
具體參考官方文檔:Illustration of transforms — Torchvision 0.22 documentation
參考代碼:
from PIL import Imagedef test03():img1 = plt.imread('./img/100.jpg')plt.imshow(img1)plt.show()img = Image.open('./img/100.jpg')transform = transforms.Compose([transforms.Resize((224, 224)), transforms.ToTensor()])r_img = transform(img)print(r_img.shape)r_img = r_img.permute(1, 2, 0)plt.imshow(r_img)plt.show()3.4.2 隨機裁剪
img = Image.open('./img/100.jpg')transform = transforms.Compose([transforms.RandomCrop(size=(224, 224)), transforms.ToTensor()])r_img = transform(img)print(r_img.shape)r_img = r_img.permute(1, 2, 0)plt.imshow(r_img)plt.show()3.4.3 隨機水平翻轉
RandomHorizontalFlip(p):隨機水平翻轉圖像,參數p表示翻轉概率(0 ≤ p ≤ 1),p=1 表示必定翻轉,p=0 表示不翻轉
img = Image.open('./img/100.jpg')transform = transforms.Compose([transforms.RandomHorizontalFlip(p=1), transforms.ToTensor()])r_img = transform(img)print(r_img.shape)r_img = r_img.permute(1, 2, 0)plt.imshow(r_img)plt.show()3.4.4 調整圖片顏色
transforms.ColorJitter(brightness=0, contrast=0, saturation=0, hue=0)brightness:
-
亮度調整的范圍。
-
可以
float或(min, max)元組:-
如果是
float(如brightness=0.2),則亮度在[max(0, 1 - 0.2), 1 + 0.2] = [0.8, 1.2]范圍內隨機縮放。 -
如果是
(min, max)(如brightness=(0.5, 1.5)),則亮度在[0.5, 1.5]范圍內隨機縮放。
-
contrast:
-
對比度調整的范圍。
-
格式與 brightness 相同。
saturation:
-
飽和度調整的范圍。
-
格式與 brightness 相同。
hue:
-
色調調整的范圍。
-
可以是一個浮點數(表示相對范圍)或一個元組 (min, max)。
-
取值范圍必須為
[-0.5, 0.5](因為色相在 HSV 色彩空間中是循環的,超出范圍會導致顏色異常)。 -
例如,hue=0.1 表示色調在 [-0.1, 0.1] 之間隨機調整。
img = Image.open('./img/100.jpg')transform = transforms.Compose([transforms.ColorJitter(brightness=0.2, contrast=0.2, saturation=0.2, hue=0.2), transforms.ToTensor()])r_img = transform(img)print(r_img.shape)r_img = r_img.permute(1, 2, 0)plt.imshow(r_img)plt.show()3.4.5 隨機旋轉
RandomRotation用于對圖像進行隨機旋轉。
transforms.RandomRotation(degrees, interpolation=InterpolationMode.NEAREST, expand=False, center=None, fill=0
)degrees:
-
旋轉角度的范圍,可以是一個浮點數或元組 (min_degree, max_degree)。
-
例如,degrees=30 表示旋轉角度在 [-30, 30] 之間隨機選擇。
-
例如,degrees=(30, 60) 表示旋轉角度在 [30, 60] 之間隨機選擇。
interpolation:
-
插值方法,用于旋轉圖像。
-
默認是 InterpolationMode.NEAREST(最近鄰插值)。
-
其他選項包括 InterpolationMode.BILINEAR(雙線性插值)、InterpolationMode.BICUBIC(雙三次插值)等。
expand:
-
是否擴展圖像大小以適應旋轉后的圖像。如:當需要保留完整旋轉后的圖像時(如醫學影像、文檔掃描)
-
如果為 True,旋轉后的圖像可能會比原始圖像大。
-
如果為 False,旋轉后的圖像大小與原始圖像相同。
center:
-
旋轉中心點的坐標,默認為圖像中心。
-
可以是一個元組 (x, y),表示旋轉中心的坐標。
fill:
-
旋轉后圖像邊緣的填充值。
-
可以是一個浮點數(用于灰度圖像)或一個元組(用于 RGB 圖像)。默認填充0(黑色)
# 加載圖像image = Image.open('./img/100.jpg')# 定義 RandomRotation 變換transform = transforms.RandomRotation(degrees=30) # 旋轉角度在 [-30, 30] 之間隨機選擇# 應用變換rotated_image = transform(image)# 顯示圖像plt.imshow(rotated_image)plt.axis('off')plt.show()3.4.6 圖片轉Tensor
import torch
from PIL import Image
from torchvision import transforms
import osdef test001():dir_path = os.path.dirname(__file__)file_path = os.path.join(dir_path,'img', '1.jpg')file_path = os.path.relpath(file_path)print(file_path)# 1. 讀取圖片img = Image.open(file_path)# transforms.ToTensor()用于將 PIL 圖像或 NumPy 數組轉換為 PyTorch 張量,并自動進行數值歸一化和維度調整# 將像素值從 [0, 255] 縮放到 [0.0, 1.0](浮點數)# 自動將圖像格式從 (H, W, C)(高度、寬度、通道)轉換為 PyTorch 標準的 (C, H, W)transform = transforms.ToTensor()img_tensor = transform(img)print(img_tensor)if __name__ == "__main__":test001()3.4.7 Tensor轉圖片
import torch
from PIL import Image
from torchvision import transformsdef test002():# 1. 隨機一個數據表示圖片img_tensor = torch.randn(3, 224, 224)# 2. 創建一個transformstransform = transforms.ToPILImage()# 3. 轉換為圖片img = transform(img_tensor)img.show()# 4. 保存圖片img.save("./test.jpg")if __name__ == "__main__":test002()
練習:通過一個Demo加深對Torch的API理解和使用
import torch
from PIL import Image
from torchvision import transforms
import osdef test003():# 獲取文件的相對路徑dir_path = os.path.dirname(__file__)file_path = os.path.relpath(os.path.join(dir_path, 'dog.jpg'))# 加載圖片img = Image.open(file_path)# 轉換圖片為tensortransform = transforms.ToTensor()t_img = transform(img)print(t_img.shape)# 獲取GPU資源,將圖片處理移交給CUDAdevice = 'cuda' if torch.cuda.is_available() else 'cpu't_img = t_img.to(device)t_img += 0.3# 將圖片移交給CPU進行圖片保存處理,一般IO操作是基于CPU的t_img = t_img.cpu()transform = transforms.ToPILImage()img = transform(t_img)img.show()if __name__ == "__main__":test003()3.4.8 歸一化
-
標準化:將圖像的像素值從原始范圍(如 [0, 255] 或 [0, 1])轉換為均值為 0、標準差為 1 的分布。
-
加速訓練:標準化后的數據分布更均勻,有助于加速模型訓練。
-
提高模型性能:標準化可以使模型更容易學習到數據的特征,提高模型的收斂性和穩定性。
img = Image.open('./img/100.jpg')transform = transforms.Compose([transforms.ToTensor(),transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])])r_img = transform(img)print(r_img.shape)r_img = r_img.permute(1, 2, 0)plt.imshow(r_img)plt.show()mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])]
均值(Mean):數據集中所有圖像在每個通道上的像素值的平均值。
標準差(Std):數據集中所有圖像在每個通道上的像素值的標準差。
RGB 三個通道的均值和標準差 不是隨便定義的,而是需要根據具體的數據集進行統計計算。這些值是 ImageNet 數據集的統計結果,已成為計算機視覺任務的默認標準。
數據集計算均值和標準差
以CIFAR10數據集為例:
# 獲取數據集
train_data = datasets.CIFAR10(root='./cifar10',train=True,download=True,transform=transforms.ToTensor() # 自動將PIL圖像轉為[0,1]范圍的張量
)def compute_mean_std(dataset):# 初始化累加器mean = torch.zeros(3)std = torch.zeros(3)num_samples = len(dataset)# 遍歷數據集計算均值for img, _ in dataset:# dim=(1, 2) 表示對圖像的高度(H)和寬度(W)維度求均值,保留通道維度(C)。mean += img.mean(dim=(1, 2)) # 全局的通道均值mean /= num_samplesprint(mean)# 遍歷數據集計算標準差for img, _ in dataset:# 原始mean 是一個形狀為 [3] 的張量,表示每個通道的均值。# 使用 view(3, 1, 1) 將 mean 的形狀從 [3] 改變為 [3, 1, 1]。# 這樣,mean 的形狀變為 [3, 1, 1],其中 3 表示通道數,1 和 1 分別表示高度和寬度的維度。# 當執行 img - mean.view(3, 1, 1) 時,PyTorch 會利用廣播機制將 mean 自動擴展到與 img 相同的形狀 [3, H, W]。# 然后利用方差公式計算:var=E(x-E(x))^2std += (img - mean.view(3, 1, 1)).pow(2).mean(dim=(1, 2))# 計算出所有圖片的方差后,計算平均方差,然后求標準差std = torch.sqrt(std / num_samples)return mean, stdmean, std = compute_mean_std(train_data)
print(f"Mean: {mean}") # 輸出類似 [0.4914, 0.4822, 0.4465]
print(f"Std: {std}") # 輸出類似 [0.2470, 0.2435, 0.2616]3.4.9 數據增強整合
使用transforms.Compose()把要增強的操作整合到一起:
from PIL import Image
from pathlib import Path
import matplotlib.pyplot as plt
import numpy as np
import torch
from torchvision import transforms, datasets, utilsdef test01():# 定義數據增強和歸一化transform = transforms.Compose([transforms.RandomHorizontalFlip(), # 隨機水平翻轉transforms.RandomRotation(10), # 隨機旋轉 ±10 度transforms.RandomResizedCrop(32, scale=(0.8, 1.0)), # 隨機裁剪到 32x32,縮放比例在0.8到1.0之間transforms.ColorJitter(brightness=0.2, contrast=0.2, saturation=0.2, hue=0.1), # 隨機調整亮度、對比度、飽和度、色調transforms.ToTensor(), # 轉換為 Tensortransforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)), # 歸一化,這是一種常見的經驗設置,適用于數據范圍 [0, 1],使其映射到 [-1, 1]])# 加載 CIFAR-10 數據集,并應用數據增強trainset = datasets.CIFAR10(root="./cifar10_data", train=True, download=True, transform=transform)dataloader = DataLoader(trainset, batch_size=4, shuffle=False)# 獲取一個批次的數據images, labels = next(iter(dataloader))# 還原圖片并顯示plt.figure(figsize=(10, 5))for i in range(4):# 反歸一化:將像素值從 [-1, 1] 還原到 [0, 1]img = images[i] / 2 + 0.5# 轉換為 PIL 圖像img_pil = transforms.ToPILImage()(img)# 顯示圖片plt.subplot(1, 4, i + 1)plt.imshow(img_pil)plt.axis('off')plt.title(f'Label: {labels[i]}')plt.show()if __name__ == "__main__":test01()代碼解釋:
transforms.Normalize(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5])若數據分布與ImageNet差異較大(如醫學影像、衛星圖、MNIST等),或均值和標準差未知時,可用此簡化設置。
將圖片進行歸一化,使數據更符合正態分布,歸一化公式:
img = img / 2 + 0.5表示反歸一化,是歸一化的逆運算:
img=\frac{normalized\_img+1}{2} =\frac{normalized\_img}{2}+0.5應用場景分析)




后,如果要使用當前的wb.Application在后臺操作其他Excel文件(保持隱藏狀態))













:最短路)