代碼:https://github.com/Continual-Intelligence
腳本命令用法:knowledge-incorporation/README.md
生成self-edit數據
腳本:sbatch knowledge-incorporation/scripts/make_squad_data.sh
vllm serve啟動Qwen2.5-7B模型的服務。
執行self-edit合成:
--k是指定每篇文章生成多少個self-edit
Squad數據(knowledge-incorporation/data/squad_train.json):
默認用的這個prompt:
(如果用的instruct model,只需要按照該model的標簽和role來寫即可:)
調用vllm api,生成一批self-edit:
(所有文章數n,每篇生成k個self-edit,一共是n*k個prompt,其中每個文章的k個prompt是相同的)(最后輸出到文件)




對self-edit進行SFT, 在QA上評測正確率
sbatch knowledge-incorporation/scripts/TTT_server.sh
啟動vllm加載模型:
啟動ZMQ服務,
該ZMQ服務接受一組參數:
用train_sequences對model進行lora SFT訓練,用訓練前和訓練后的模型分別評測eval_questions,得到2組正確率指標;
用peft.get_peft_model從base model拿到lora model:
使用transformers.Trainer,trainer.train()訓練lora模型:
將訓練完的模型存到文件里。加載文件至vllm(給vllm服務發送/v1/load_lora_adapter請求):
評測完畢后,再將vllm的lora模型給卸掉(卸掉后vllm上是base model):
評測時,只輸入Q,不輸入self-edit:
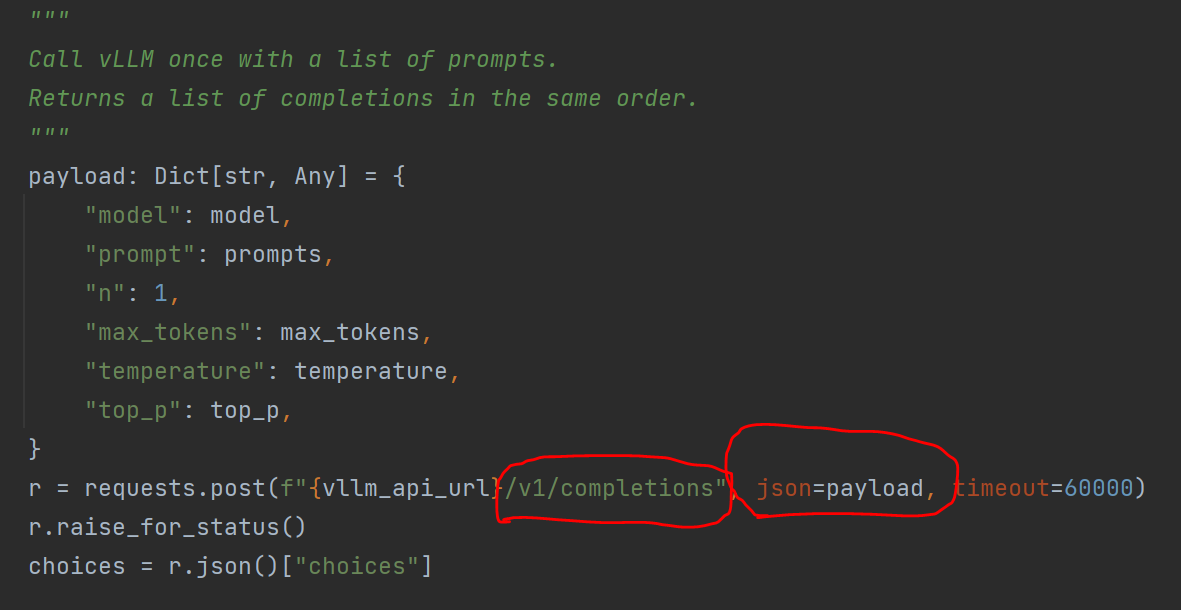
評測調用vllm的/v1/completions,吧model名稱傳入進去:
評測用的prompt,包含Q、A、模型生成的值:
用gpt-4.1做的評測:
可對比base模型和adaper模型在這批Q上的答對率,分出高下。
返回幾個指標:
accuracy: 答對的題數/總題數
texts: 所有題目的推理結果
correct: 所有題目的對錯(true/false)
adapter_gain: adapter相比base model的增益,即adapter_acc - base_acc
gains: 1/(-1)/0的數組,該題目adapter對了base錯了,則為1;adapter錯base對,則為-1;否則為0










將self-edit讀入并整理,調用上面的SFT服務進行Fine tune和評測:
sbatch knowledge-incorporation/scripts/query_server.sh
每個文章生成了多組self-edit:
每組edit,是1.2.3.4...這樣一條一條的,每條用\n分隔:
選項SPLIT_NEWLINES控制是否將每組的1、2、3、4用\n分割后,當成1個batch來喂給SFT模型去訓練;默認是true,當成1個batch。如果設為false,則這組的4條信息整個當成1條樣本交給SFT模型去訓練。
注意:除了self-edit,還要把原文(即context)也加入到SFT訓練數據集里:
注釋里也強調了這點:
EVAL_TIMES控制對每組self-edit,進行幾次evalute。每次evalute包括了SFT train和QA評判。(這里SFT train有些浪費?我感覺每組self-edit只做1次SFT train,QA評判多次,就可以了?)




構造RL訓練數據集:
python3 knowledge-incorporation/src/EM/build_SFT_dataset.py <path/to/result/of/run.json>
讀取上一步存盤的結果文件。把prompt(指令+原始文章內容)及其在SFT評測中表現最好的k(默認k=1)個self-edit,存入文件。
跑訓練
sbatch knowledge-incorporation/scripts/train_SFT.sh
上一步輸出的結果是jsonl文件:
prompt是指令+原文;completion是self-edit(在多個self-edit里,SFT后評測得分最高的那個)。
使用了accelerate:
--deepspeed_config_file內容:
綜上,用了:多卡,ZERO-3, offload,bf16,lora
上面的jsonl數據文件,可以被datasets.load_dataset直接加載至dataset:
用的trl.SFTTrainer:
將lora參數和base model合并至一個model:
保存:






Continoual實驗:
sbatch knowledge-incorporation/scripts/continual_self_edits.sh
最外面:多次實驗(N_SEQUENCES=8),每次采樣一批文章,從同一個模型ckpt開始做continue training,統計這N組實驗的平均效果。
里面:每次實驗,采樣N_DATAPOINTS篇文章;每篇文章,生成self-edit,做SFT訓練更新,統計訓練過的文章所對應的QA在當前模型上的正確率。這篇文章SFT訓練更新后的lora模型,被merge進當前model,生成新的model ckpt,作為下一篇文章的加載模型。








)






)


)
