華為云Flexus+DeepSeek征文|體驗華為云ModelArts快速搭建Dify-LLM應用開發平臺并搭建查詢數據庫的大模型工作流
什么是華為云ModelArts
- 華為云ModelArts ModelArts是華為云提供的全流程AI開發平臺,覆蓋從數據準備到模型部署的全生命周期管理,幫助企業和開發者高效構建、訓練、部署AI模型,實現智能化升級。
開始接觸華為云ModelArts Studio大模型即服務平臺
- 訪問官方地址
https://www.huaweicloud.com/product/modelarts/studio.html

快速搭建Dify-LLM應用開發平臺
什么是Dify-LLM應用開發平臺
-
Dify-LLM 應用開發平臺是一個基于大型語言模型(LLM)的低代碼/無代碼開發平臺,旨在幫助開發者快速構建、部署和管理基于 AI 的應用程序。它提供了可視化的操作界面和豐富的工具,簡化了從模型調用到應用上線的全流程,適合不同技術背景的用戶使用。
-
華為云提供了一鍵部署快速搭建Dify平臺的功能,使開發者可以快速搭建生產級的生成式AI應用
-
快速搭建的方案架構如下

-
通過VPC與安全組構建安全網絡,用戶經ELB接入CCE部署的Dify服務集群,結合Embedding與reranker增強AI能力,并依托Redis、PostgreSQL、CSS與OBS實現多樣化數據存儲與處理,具備高可用、可擴展特性
開始搭建Dify-LLM應用開發平臺
-
先進入官網
https://www.huaweicloud.com/solution/implementations/building-a-dify-llm-application-development-platform.html

-
選擇一鍵部署(云服務器單機部署)

-
這里不做操作直接下一步

-
把密碼設置好下一步

-
繼續下一步

-
點擊創建執行計劃

-
可以查看費用,然后點擊部署

-
可以看到正在按順序部署

-
等待服務部署完畢,訪問Dify-LLM應用開發平臺

-
部署完畢,訪問Dify-LLM應用開發平臺

-
登錄Dify-LLM應用開發平臺

-
至此搭建Dify-LLM應用開發平臺大功告成,不得不說,華為云一鍵部署Dify平臺真是太方便了,全程不需要怎么操作,全是一鍵搞定
開始搭建大模型工作流
什么是大模型工作流
- 大模型工作流(Large Model Workflow)是指利用大規模預訓練語言模型(如GPT、BERT等)完成復雜任務時,所采用的一系列系統化、結構化的處理步驟和方法。它通過將大模型能力與特定任務需求相結合,實現更高效、更可靠的AI應用
開始搭建
- 這次準備做一個大模型工作流,然后然后可以查詢數據庫數據輸出,


-
然后我們需要調用華為云的DeepSeek-V3-32K模型作為基底大模型
-
安裝dify中的大模型插件,OpenAI-API-compatible

-
等待安裝完成

-
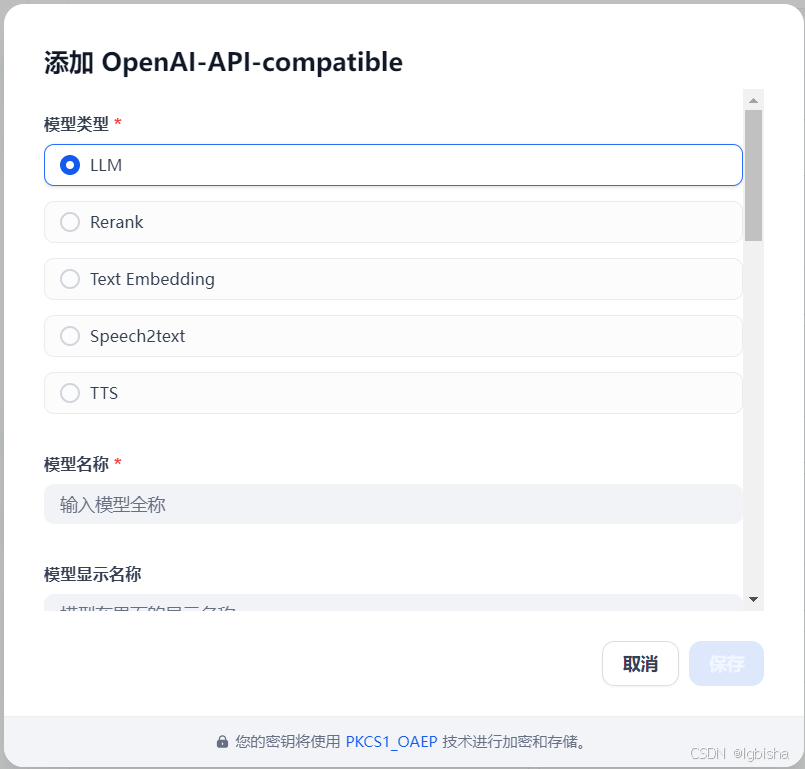
設置大模型
-
密鑰從華為云中獲取

-
進入api-key管理,創建自己的key,用于調用大模型

-
回來繼續配置key,注意接口地址是
https://api.modelarts-maas.com/v1

-
這樣大模型就配置完畢了
-
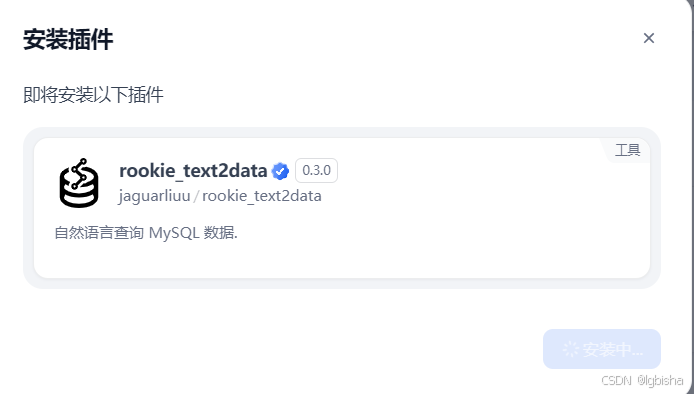
然后安裝插件,點擊右上角工具列表,搜索
rookie_text2data

-
開始安裝
-
這里我們準備的mysql數據庫,新建一個test的庫

-
然后準備一個用戶表與一個部門表
CREATE TABLE `test`.`user` (`id` int NOT NULL AUTO_INCREMENT COMMENT '主鍵id',`name` varchar(30) NULL COMMENT '用戶名稱',`age` int NULL COMMENT '年齡',`department_id` int NULL COMMENT '部門id',`gender` varchar(255) NULL COMMENT '性別(男/女)',PRIMARY KEY (`id`)
) COMMENT = '用戶表';
CREATE TABLE `test`.`department` (`id` int NOT NULL AUTO_INCREMENT COMMENT '主鍵id',`name` varchar(255) NULL COMMENT '部門名稱',PRIMARY KEY (`id`)
) COMMENT = '部門表';
- 然后插入一些數據
INSERT INTO `department` (`name`) VALUES
('人力資源部'),
('財務部'),
('技術研發部'),
('市場營銷部'),
('客戶服務部');
INSERT INTO `user` (`name`, `age`, `department_id`, `gender`) VALUES
-- 人力資源部 (部門ID 1)
('張偉', 32, 1, '男'),
('李娜', 28, 1, '女'),
('王芳', 35, 1, '女'),-- 財務部 (部門ID 2)
('趙明', 45, 2, '男'),
('錢靜', 30, 2, '女'),
('孫麗', 29, 2, '女'),-- 技術研發部 (部門ID 3)
('周強', 27, 3, '男'),
('吳昊', 31, 3, '男'),
('鄭雪', 26, 3, '女'),
('王磊', 33, 3, '男'),-- 市場營銷部 (部門ID 4)
('馮敏', 29, 4, '女'),
('陳陽', 34, 4, '男'),
('褚小云', 25, 4, '女'),-- 客戶服務部 (部門ID 5)
('衛華', 28, 5, '女'),
('蔣濤', 31, 5, '男'),
('沈月', 24, 5, '女');


- 然后去工作流添加節點


-
配置輸入參數與接受參數

-
新增節點模板轉換,用于json轉換字符串

-
然后添加LLM節點,進行sql檢測

你是一位精通mysql的數據庫專家,你需要檢查sql語句是否存在錯誤,如果有錯就改正,沒錯就輸出結果
回答要求:
1. 不能包含多余信息
2. 必須是可執行的sql語句
3. 刪除掉Sql中的\n,用空格替換。json數據: /output
-
然后添加執行sql節點

-
然后跟上面一樣把json輸出為字符串

-
然后對結果進行分析總結
你是數據分析專家,處理JSON格式SQL查詢結果時需要遵守以下核心規則:
1. 嚴格依賴現有數據,直接使用提供的JSON數據進行分析,不質疑數據準確性或完整性
2. 禁止數據編造,當數據字段為[]、空或None時,必須回復"沒有查詢到相關數據"
不得自行推斷或補充不存在的數據
3. 高效分析原則,無需重復驗證數據條件/時間范圍/類別(默認數據已符合用戶查詢條件)
避免不必要的重復篩選操作
4. 格式要求,輸入數據為JSON結構
輸出保持簡潔,但需完整包含上述所有關鍵點
數據:/output
問題:/test
Sql語句:/text
回答要求:
1.以表格方式列出數據。
2.提供分析和建議。
3.提供查詢的Sql語句。

- 添加結束節點并發布

-
然后點擊運行進行簡單測試

-
至此查詢數據庫的大模型工作流就見好了
歡迎大家一起加入華為云


)

















 快速入門 - 用戶管理(下))