本文在創作過程中借助 AI 工具輔助資料整理與內容優化。圖片來源網絡。

文章目錄
- 引言
- 一、Celery 概述
- 1.1 Celery 的定義和作用
- 1.2 Celery 的應用場景
- 二、Celery 架構分析
- 2.1 Celery 的整體架構
- 2.2 消息中間件(Broker)
- 2.3 任務隊列(Task Queue)
- 2.4 Worker 節點
- 三、Celery 核心代碼分析
- 3.1 Celery 的初始化和配置
- 3.2 任務的創建和調度
- 3.3 Worker 節點的啟動和運行
- 3.4 Celery 的信號機制
- 四、Celery 的性能優化
- 4.1 消息中間件的選擇和配置
- 4.2 任務隊列的優化
- 存儲結構優化
- 調度算法優化
- 4.3 Worker 節點的性能調優
- 并發數調整
- 資源隔離
- 4.4 監控與日志管理
- 監控指標
- 日志記錄
- 五、總結與展望
- 5.1 總結
- 5.2 展望
- 與新興技術的集成
- 人工智能與機器學習支持
- 安全性能提升
引言
大家好,我是沛哥兒。
隨著互聯網應用的不斷發展,用戶對系統響應速度和處理能力的要求越來越高。同步處理方式在面對大量并發任務時往往顯得力不從心,容易導致系統響應延遲,甚至出現崩潰的情況。而異步任務處理機制可以將耗時的任務從主線程中分離出來,使得主線程能夠繼續處理其他請求,從而顯著提高系統的并發處理能力和響應速度。
Celery 作為一個功能強大的分布式任務隊列系統,在異步任務處理方面有著廣泛的應用。它可以幫助開發者輕松地實現異步任務的調度、執行和管理,無論是在 Web 應用、數據處理還是實時系統中,Celery 都能發揮出重要的作用。
一、Celery 概述
1.1 Celery 的定義和作用
Celery 是一個用 Python 編寫的基于分布式消息傳遞的異步任務隊列系統。它允許開發者將耗時的任務(如文件處理、數據計算、網絡請求等)從主線程中分離出來,以異步的方式在后臺執行。 Celery 可以處理大量的并發任務,提高系統的吞吐量和響應速度。
例如,在一個電商網站中,用戶下單后,系統需要發送確認郵件、更新庫存等操作,這些操作可以作為異步任務交給 Celery 處理,而主線程則可以繼續處理其他用戶的請求,從而避免了用戶長時間等待。
1.2 Celery 的應用場景
Celery 的應用場景非常廣泛,主要包括以下幾個方面:
-
Web 應用:在 Web 應用中,Celery 可以用于處理用戶注冊時的郵件驗證、訂單處理、數據緩存更新等任務。
例如,當用戶注冊時,系統可以將發送驗證郵件的任務交給 Celery 異步處理,這樣用戶可以立即看到注冊成功的提示信息,而不必等待郵件發送完成。
-
數據處理:在數據處理領域,Celery 可以用于批量數據處理、數據清洗、機器學習模型訓練等任務。
例如,在一個大數據分析系統中,需要對大量的日志數據進行清洗和分析,Celery 可以將這些任務分配到多個 Worker 節點上并行處理,提高處理效率。
- 實時系統:在實時系統中,Celery 可以用于處理實時數據、監控系統狀態等任務。
例如,在一個物聯網系統中,需要實時處理傳感器采集到的數據,Celery 可以將數據處理任務異步執行,確保系統能夠及時響應新的數據。
二、Celery 架構分析
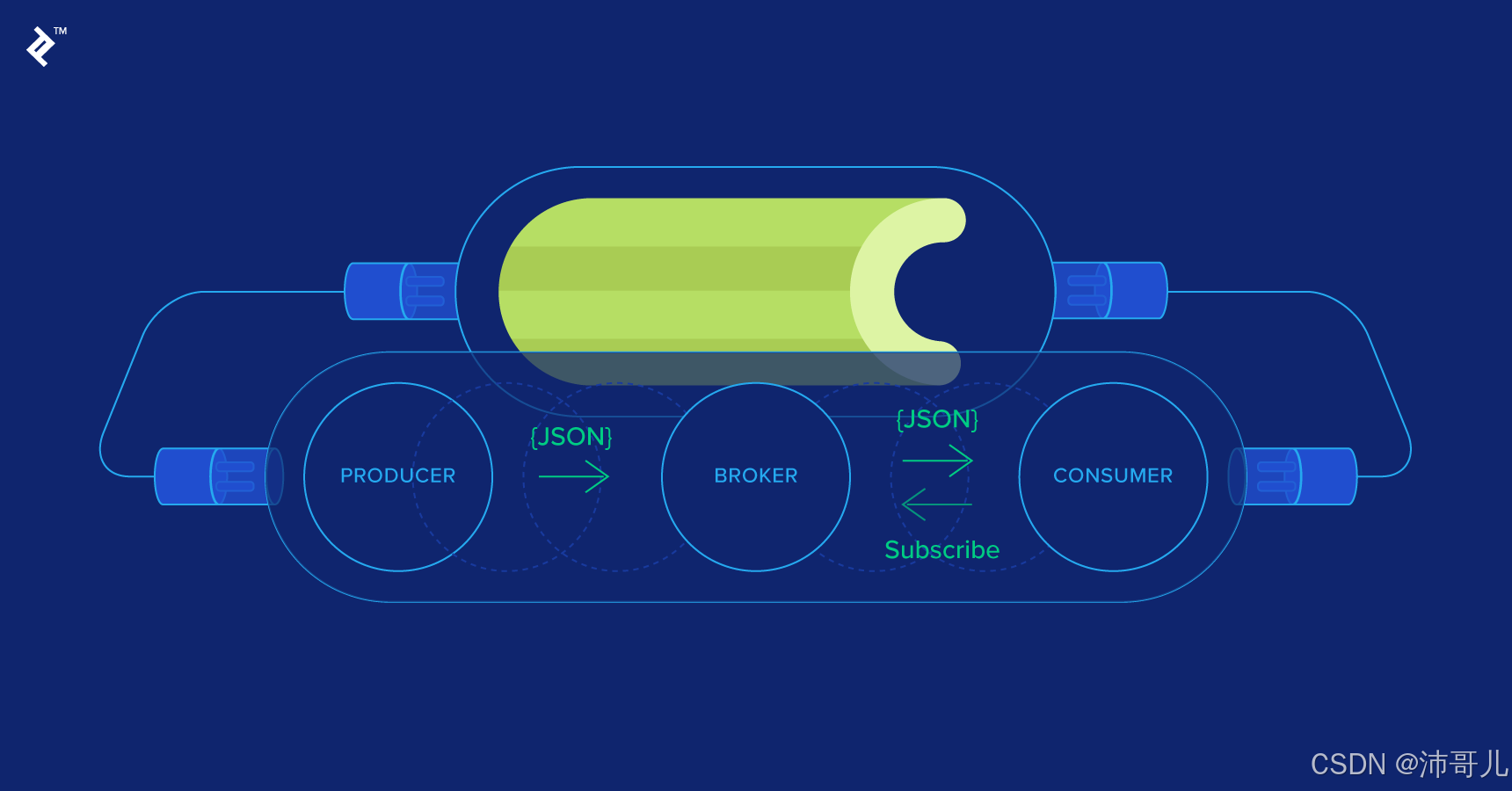
2.1 Celery 的整體架構
Celery 的整體架構主要由三個核心部分組成:消息中間件(Broker)、任務隊列(Task Queue)和 Worker 節點。
- 消息中間件作為 Celery 的核心組件之一,負責接收和分發任務消息。常見的消息中間件包括 RabbitMQ、Redis 等。當一個任務被創建時,系統會將任務消息發送到消息中間件中。任務隊列則是消息中間件中的一個隊列,用于存儲待處理的任務消息。
- Worker 節點是負責執行任務的進程,它會從任務隊列中獲取任務消息,并執行相應的任務。當任務執行完成后,Worker 節點會將執行結果返回給消息中間件,供其他組件使用。
2.2 消息中間件(Broker)
消息中間件在 Celery 架構中起著至關重要的作用。它負責接收來自生產者(如 Web 應用)的任務消息,并將這些消息分發給 Worker 節點。不同的消息中間件具有不同的特點和適用場景。
例如,RabbitMQ 是一個功能強大、穩定可靠的消息中間件,它支持多種消息協議,具有高可用性和可擴展性。而 Redis 則是一個高性能的內存數據庫,它的讀寫速度非常快,適用于對性能要求較高的場景。在選擇消息中間件時,需要根據具體的業務需求和系統性能要求進行綜合考慮。

2.3 任務隊列(Task Queue)
任務隊列是消息中間件中的一個重要組成部分,它用于存儲待處理的任務消息。任務隊列的設計和管理直接影響到 Celery 的性能和可靠性。
在 Celery 中,可以使用不同的隊列來區分不同類型的任務,例如,可以創建一個高優先級隊列和一個低優先級隊列,將重要的任務放入高優先級隊列中,以確保這些任務能夠得到及時處理。同時,任務隊列還需要考慮隊列長度、任務超時等問題,以避免隊列過長導致系統性能下降或任務超時未處理的情況。
2.4 Worker 節點
Worker 節點是 Celery 中負責執行任務的進程。它會不斷地從任務隊列中獲取任務消息,并執行相應的任務。Worker 節點可以在多個服務器上部署,以實現分布式處理。在 Worker 節點的配置方面,需要考慮并發數、資源分配等問題。例如,可以根據服務器的硬件資源和任務的特點,合理配置 Worker 節點的并發數,以充分利用服務器的資源,提高任務執行效率。
三、Celery 核心代碼分析
3.1 Celery 的初始化和配置
在使用 Celery 之前,需要對其進行初始化和配置。以下是一個簡單的示例代碼:
from celery import Celery# 初始化 Celery 對象
app = Celery('tasks', broker='amqp://guest@localhost//')# 定義任務
@app.task
def add(x, y):return x + y
在上述代碼中,首先導入了 Celery 類,然后創建了一個 Celery 對象 app,并指定了消息中間件的地址。接著,使用 @app.task 裝飾器定義了一個任務 add,該任務用于計算兩個數的和。
3.2 任務的創建和調度
在 Celery 中,任務的創建和調度非常簡單。可以通過調用任務函數來創建任務,并使用 delay() 方法來異步執行任務。以下是一個示例代碼:
# 創建并調度任務
result = add.delay(4, 4)
# 獲取任務結果
print(result.get()) #將返回8
在上述代碼中,調用 add.delay(4, 4) 方法創建并調度了一個任務,該任務會被發送到任務隊列中等待 Worker 節點執行。然后,使用 result.get() 方法獲取任務的執行結果。
3.3 Worker 節點的啟動和運行
啟動 Worker 節點可以使用 Celery 提供的命令行工具。以下是啟動 Worker 節點的命令:
celery -A tasks worker --loglevel=info
在上述命令中,-A tasks 表示指定 Celery 應用的名稱,worker 表示啟動 Worker 節點,--loglevel=info 表示設置日志級別為信息級別。啟動 Worker 節點后,它會不斷地從任務隊列中獲取任務消息,并執行相應的任務。
3.4 Celery 的信號機制
Celery 提供了豐富的信號機制,允許開發者在任務執行的不同階段插入自定義的代碼。
例如,可以在任務開始執行前、執行完成后等階段執行一些操作。以下是一個使用信號機制的示例代碼:
from celery.signals import task_prerun, task_postrun# 注冊任務執行前的信號處理器
@task_prerun.connect
def task_prerun_handler(sender=None, task_id=None, task=None, args=None, kwargs=None, **rest):"""任務開始執行前觸發的處理函數參數:sender: 發送信號的任務類task_id: 任務的唯一標識符task: 任務實例args: 任務調用時的位置參數kwargs: 任務調用時的關鍵字參數"""print(f'Task {task_id} is about to run')# 注冊任務執行后的信號處理器
@task_postrun.connect
def task_postrun_handler(sender=None, task_id=None, task=None, args=None, kwargs=None, retval=None, state=None, **rest):"""任務執行完成后觸發的處理函數參數:sender: 發送信號的任務類task_id: 任務的唯一標識符task: 任務實例args: 任務調用時的位置參數kwargs: 任務調用時的關鍵字參數retval: 任務的返回值state: 任務的最終狀態 (如 'SUCCESS', 'FAILURE')"""print(f'Task {task_id} has finished with state {state}')
在上述代碼中,使用 task_prerun.connect 和 task_postrun.connect 裝飾器分別定義了任務開始執行前和執行完成后的處理函數。當任務開始執行前,會調用 task_prerun_handler 函數;當任務執行完成后,會調用 task_postrun_handler 函數。
四、Celery 的性能優化
4.1 消息中間件的選擇和配置
選擇合適的消息中間件對于 Celery 的性能至關重要。如前面所述,不同的消息中間件具有不同的特點和適用場景。在配置消息中間件時,需要根據具體的業務需求和系統性能要求進行調整。
4.2 任務隊列的優化
任務隊列是 Celery 架構中的關鍵部分,其性能直接影響到整個系統的處理能力。除了合理劃分不同優先級隊列外,還需要對隊列的存儲結構和調度算法進行優化。
存儲結構優化
可以采用更高效的數據結構來存儲任務消息。例如,對于高并發場景下的任務隊列,可以考慮使用 Redis 的有序集合(Sorted Set)來存儲任務消息,通過設置任務的執行時間戳作為分數,實現任務的按時間排序和快速查找。這樣可以避免傳統隊列在處理任務調度時的線性查找開銷,提高任務調度的效率。
以下是使用 Redis 有序集合優化任務隊列的示例代碼:
import redis
import time# 連接 Redis 數據庫,默認使用本地主機、6379端口和0號數據庫
r = redis.Redis(host='localhost', port=6379, db=0)# 添加任務到有序集合(Sorted Set)
# 參數:task_id - 任務唯一標識,execution_time - 任務執行時間戳
# 有序集合中 score 為執行時間,value 為任務 ID
def add_task_to_queue(task_id, execution_time):r.zadd('task_queue', {task_id: execution_time})# 從隊列獲取下一個待執行的任務(按時間排序)
# 返回:待執行的任務 ID 或 None
def get_next_task():# 獲取當前時間戳now = time.time()# 查詢所有 score(執行時間)小于等于當前時間的任務# start=0, num=1 表示只取第一個(最早到期的任務)task_ids = r.zrangebyscore('task_queue', 0, now, start=0, num=1)# 如果有到期任務if task_ids:# 轉換字節類型為字符串task_id = task_ids[0].decode('utf-8')# 從隊列中移除該任務(原子操作)r.zrem('task_queue', task_id)return task_idreturn None
調度算法優化
對于多隊列的場景,可以采用動態調度算法來分配任務。例如,使用基于負載均衡的調度算法,根據每個 Worker 節點的當前負載情況,動態地將任務分配到最合適的隊列和 Worker 節點上。可以通過監控 Worker 節點的 CPU 使用率、內存使用率等指標,實時調整任務分配策略。
4.3 Worker 節點的性能調優
Worker 節點是實際執行任務的核心,其性能調優對于提高系統整體性能至關重要。
并發數調整
Worker 節點的并發數設置需要根據服務器的硬件資源和任務的特點進行動態調整。可以通過監控系統的資源使用情況,實時調整 Worker 節點的并發數。
例如,在系統負載較低時,適當增加并發數以提高任務處理速度;在系統負載較高時,減少并發數以避免資源耗盡。
以下是一個簡單的腳本示例,用于根據系統的 CPU 使用率動態調整 Worker 節點的并發數:
import psutil
import subprocess# 獲取當前 CPU 使用率
def get_cpu_usage():return psutil.cpu_percent(interval=1)# 根據 CPU 使用率調整并發數
def adjust_concurrency():cpu_usage = get_cpu_usage()if cpu_usage < 30:new_concurrency = 10 # 低負載時增加并發數elif cpu_usage > 70:new_concurrency = 2 # 高負載時減少并發數else:new_concurrency = 5 # 正常負載時保持默認并發數# 重啟 Worker 節點并設置新的并發數subprocess.run(f'celery -A tasks worker --loglevel=info --concurrency={new_concurrency}', shell=True)資源隔離
為了避免不同任務之間的資源競爭,可以對 Worker 節點進行資源隔離。例如,使用 Docker 容器來部署 Worker 節點,通過 Docker 的資源限制功能,為每個 Worker 節點分配固定的 CPU、內存等資源,確保任務的執行不會相互干擾。
4.4 監控與日志管理
為了及時發現和解決系統中出現的問題,需要建立完善的監控和日志管理系統。
監控指標
監控 Celery 系統的各項關鍵指標,如任務隊列長度、Worker 節點的負載情況、任務執行時間等。可以使用 Prometheus 和 Grafana 等工具來實現對這些指標的實時監控和可視化展示。通過監控這些指標,可以及時發現系統的瓶頸和潛在問題,采取相應的優化措施。
日志記錄
詳細記錄 Celery 系統的運行日志,包括任務的創建、調度、執行等各個階段的信息。可以使用 Python 的內置日志模塊來記錄日志,并將日志存儲到文件或遠程日志服務器中。通過分析日志信息,可以定位系統中的錯誤和異常情況,進行及時的修復和優化。
以下是一個簡單的日志記錄示例代碼:
import logging# 配置日志
logging.basicConfig(filename='celery.log', level=logging.INFO,format='%(asctime)s - %(levelname)s - %(message)s')# 記錄任務開始執行日志
def log_task_start(task_id):logging.info(f'Task {task_id} started')# 記錄任務執行完成日志
def log_task_finish(task_id, result):logging.info(f'Task {task_id} finished with result: {result}')五、總結與展望
通過對 Celery 架構及核心代碼的深入分析,我們了解了其在異步任務處理方面的強大功能和優勢。Celery 作為一個成熟的分布式任務隊列系統,能夠有效地提高系統的并發處理能力和響應速度,廣泛應用于各種領域。
5.1 總結
本文詳細介紹了 Celery 的定義、應用場景、整體架構、核心代碼以及性能優化方法。通過合理選擇消息中間件、優化任務隊列、調優 Worker 節點以及建立完善的監控和日志管理系統,可以進一步提升 Celery 系統的性能和可靠性。
5.2 展望
隨著軟件開發技術的不斷發展,異步任務處理的需求也在不斷增加。未來,Celery 可能會在以下幾個方面進行進一步的發展和優化:
與新興技術的集成
隨著容器化、微服務架構的普及,Celery 可能會與 Docker、Kubernetes 等容器編排工具進行更緊密的集成,實現更高效的資源管理和彈性伸縮。
人工智能與機器學習支持
在人工智能和機器學習領域,對異步任務處理的需求也越來越高。未來 Celery 可能會提供更多的機器學習模型訓練和推理任務的支持,如分布式訓練、模型部署等。
安全性能提升
隨著信息安全問題的日益突出,Celery 可能會加強其安全性能,例如提供更完善的身份認證、數據加密等功能,保障任務處理過程中的數據安全。
總之,Celery 作為一款優秀的分布式任務隊列系統,在未來的軟件開發領域將繼續發揮重要作用,為開發者提供更強大、更高效的異步任務處理解決方案。
的方法(2))
)
加密與 SQL Server 建立安全連接,)

接口與實現)











網關數據顯示)


