為什么要分塊?
將長文本分解成適當大小的片段,以便于嵌入、索引和存儲,并提高檢索的精確度。
用ChunkViz工具可視化分塊
在線使用
ChunkViz
github
https://github.com/gkamradt/ChunkViz
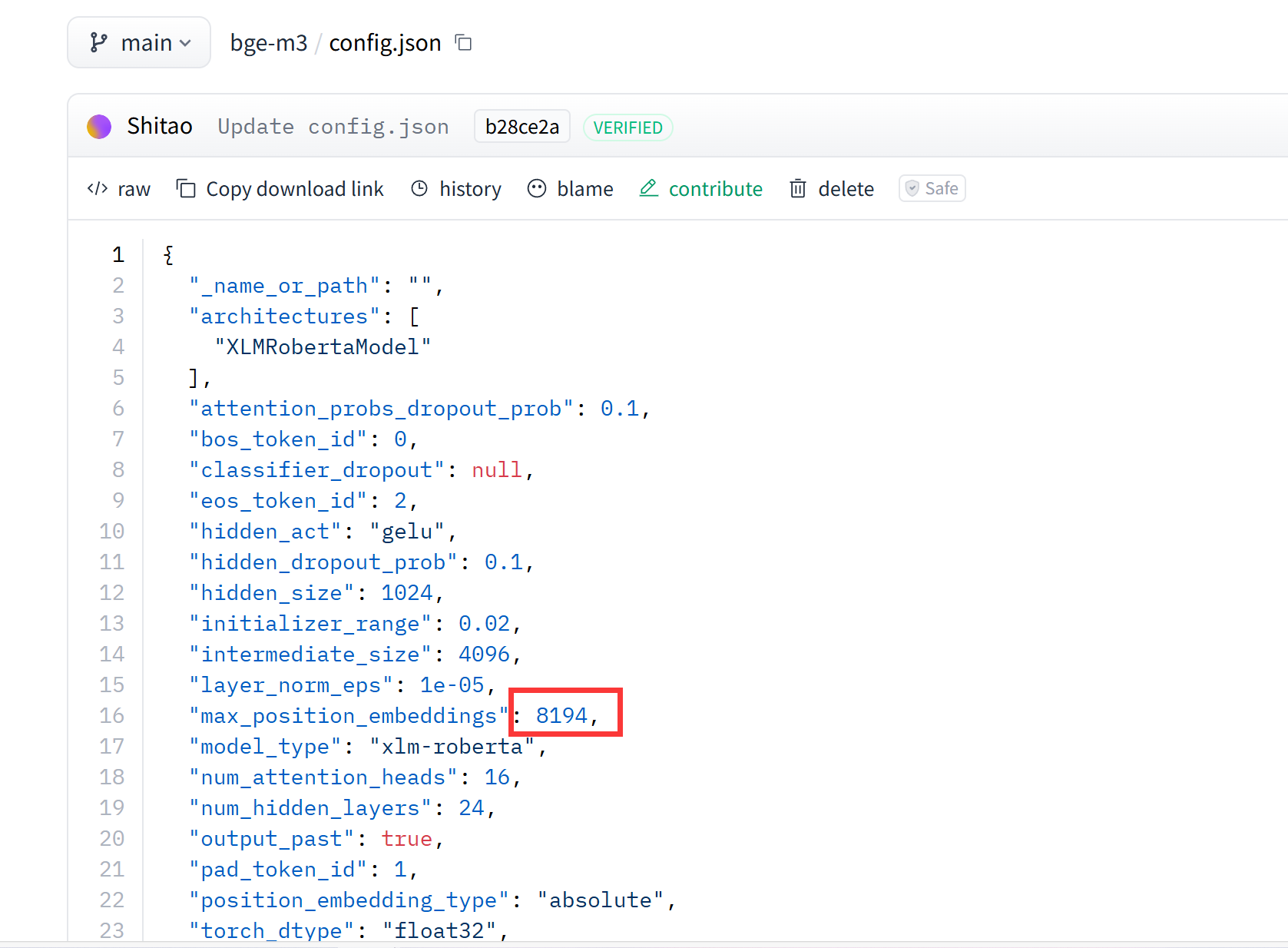
如何確定大模型所能接受的最長上下文
可以從模型card和config文件中得知
文本分塊的方法和實現
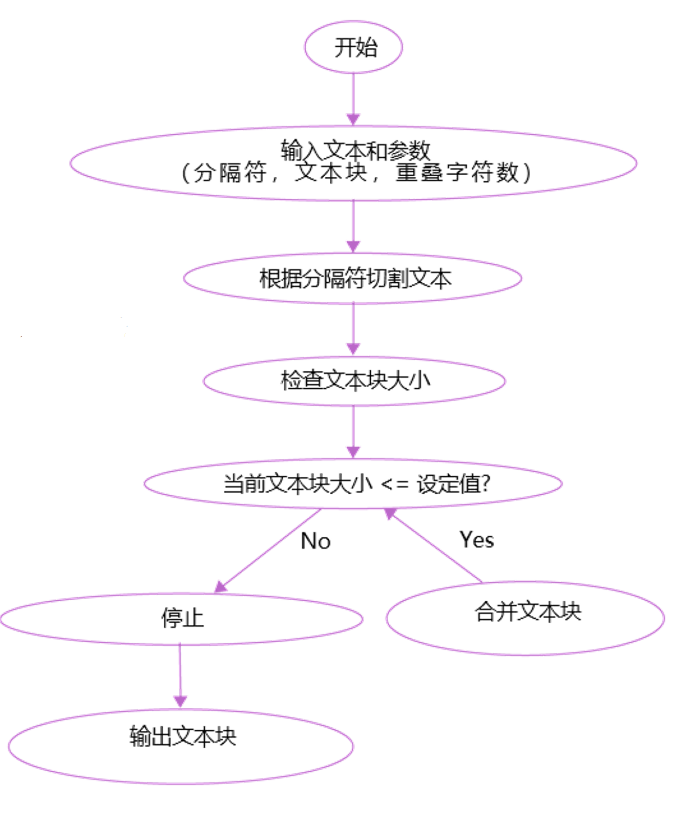
CharacterTextSplitter - 按固定字符數分塊
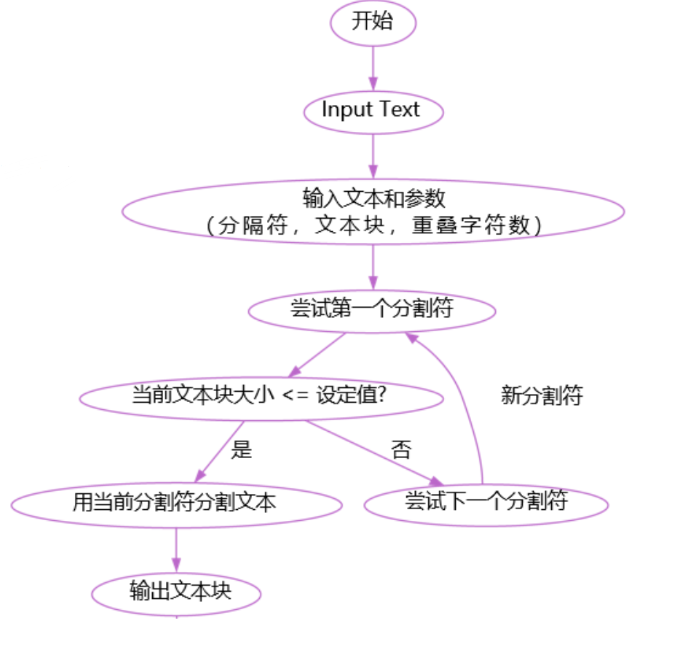
RecursiveCharacterTextSplitter – 遞歸分塊
from langchain_community.document_loaders import TextLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter
loader = TextLoader("90-文檔-Data/山西文旅/云岡石窟.txt")
documents = loader.load()
# 定義分割符列表,按優先級依次使用
separators = ["\n\n", ".", ",", " "] # . 是句號,, 是逗號, 是空格
# 創建遞歸分塊器,并傳入分割符列表
text_splitter = RecursiveCharacterTextSplitter(chunk_size=100,chunk_overlap=10,separators=separators
)
chunks = text_splitter.split_documents(documents)
print("\n=== 文檔分塊結果 ===")
for i, chunk in enumerate(chunks, 1):print(f"\n--- 第 {i} 個文檔塊 ---")print(f"內容: {chunk.page_content}")print(f"元數據: {chunk.metadata}")print("-" * 50)基于特定格式(如python代碼格式)分塊
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_text_splitters import Language
separators = RecursiveCharacterTextSplitter.get_separators_for_language(Language.JAVASCRIPT)
print(separators)from langchain_text_splitters import (Language,RecursiveCharacterTextSplitter,
)
GAME_CODE = """
class CombatSystem:def __init__(self):self.health = 100self.stamina = 100self.state = "IDLE"self.attack_patterns = {"NORMAL": 10,"SPECIAL": 30,"ULTIMATE": 50}def update(self, delta_time):self._update_stats(delta_time)self._handle_combat()def _update_stats(self, delta_time):self.stamina = min(100, self.stamina + 5 * delta_time)def _handle_combat(self):if self.state == "ATTACKING":self._execute_attack()def _execute_attack(self):if self.stamina >= self.attack_patterns["SPECIAL"]:damage = 50self.stamina -= self.attack_patterns["SPECIAL"]return damagereturn self.attack_patterns["NORMAL"]
class InventorySystem:def __init__(self):self.items = {}self.capacity = 20self.gold = 0def add_item(self, item_id, quantity):if len(self.items) < self.capacity:if item_id in self.items:self.items[item_id] += quantityelse:self.items[item_id] = quantitydef remove_item(self, item_id, quantity):if item_id in self.items:self.items[item_id] -= quantityif self.items[item_id] <= 0:del self.items[item_id]def get_item_count(self, item_id):return self.items.get(item_id, 0)
class QuestSystem:def __init__(self):self.active_quests = {}self.completed_quests = set()self.quest_log = []def add_quest(self, quest_id, quest_data):if quest_id not in self.active_quests:self.active_quests[quest_id] = quest_dataself.quest_log.append(f"Started quest: {quest_data['name']}")def complete_quest(self, quest_id):if quest_id in self.active_quests:self.completed_quests.add(quest_id)del self.active_quests[quest_id]def get_active_quests(self):return list(self.active_quests.keys())
"""
python_splitter = RecursiveCharacterTextSplitter.from_language(language=Language.PYTHON, # 指定編程語言為Pythonchunk_size=1000,chunk_overlap=0
)python_docs = python_splitter.create_documents([GAME_CODE])
print("\n=== 代碼分塊結果 ===")
for i, chunk in enumerate(python_docs, 1):print(f"\n--- 第 {i} 個代碼塊 ---")print(f"內容:\n{chunk.page_content}")print(f"元數據: {chunk.metadata}")print("-" * 50)LlamaIndex-語義分塊
from llama_index.core import SimpleDirectoryReader
from llama_index.core.node_parser import (SentenceSplitter,SemanticSplitterNodeParser,
)
from llama_index.embeddings.openai import OpenAIEmbedding
# from llama_index.embeddings.huggingface import HuggingFaceEmbedding
# embed_model = HuggingFaceEmbedding(model_name="BAAI/bge-small-zh")
documents = SimpleDirectoryReader(input_files=["90-文檔-Data/黑悟空/黑悟空wiki.txt"]).load_data()# 創建語義分塊器
splitter = SemanticSplitterNodeParser(buffer_size=3, # 緩沖區大小breakpoint_percentile_threshold=90, # 斷點百分位閾值embed_model=OpenAIEmbedding() # 使用的嵌入模型
)
# 創建基礎句子分塊器(作為對照)
base_splitter = SentenceSplitter(# chunk_size=512
)'''
buffer_size:
默認值為1
這個參數控制評估語義相似度時,將多少個句子組合在一起當設置為1時,每個句子會被單獨考慮
當設置大于1時,會將多個句子組合在一起進行評估例如,如果設置為3,就會將每3個句子作為一個組來評估語義相似度breakpoint_percentile_threshold:
默認值為95
這個參數控制何時在句子組之間創建分割點,它表示余弦不相似度的百分位數閾值,當句子組之間的不相似度超過這個閾值時,就會創建一個新的節點
數值越小,生成的節點就越多(因為更容易達到分割閾值)
數值越大,生成的節點就越少(因為需要更大的不相似度才會分割)這兩個參數共同影響文本的分割效果:
buffer_size 決定了評估語義相似度的粒度
breakpoint_percentile_threshold 決定了分割的嚴格程度
例如:
如果 buffer_size=2 且 breakpoint_percentile_threshold=90:每2個句子會被組合在一起,當組合之間的不相似度超過90%時就會分割,這會產生相對較多的節點
如果 buffer_size=3 且 breakpoint_percentile_threshold=98:每3個句子會被組合在一起,需要更大的不相似度才會分割,這會產生相對較少的節點
'''# 使用語義分塊器對文檔進行分塊
semantic_nodes = splitter.get_nodes_from_documents(documents)
print("\n=== 語義分塊結果 ===")
print(f"語義分塊器生成的塊數:{len(semantic_nodes)}")
for i, node in enumerate(semantic_nodes, 1):print(f"\n--- 第 {i} 個語義塊 ---")print(f"內容:\n{node.text}")print("-" * 50)# 使用基礎句子分塊器對文檔進行分塊
base_nodes = base_splitter.get_nodes_from_documents(documents)
print("\n=== 基礎句子分塊結果 ===")
print(f"基礎句子分塊器生成的塊數:{len(base_nodes)}")
for i, node in enumerate(base_nodes, 1):print(f"\n--- 第 {i} 個句子塊 ---")print(f"內容:\n{node.text}")print("-" * 50)使用Unstructured基于文檔結構分塊

與分塊相關的高級索引技巧?
帶滑動窗口的句子切分(Sliding Windows)
上下窗口為3的滑動窗口
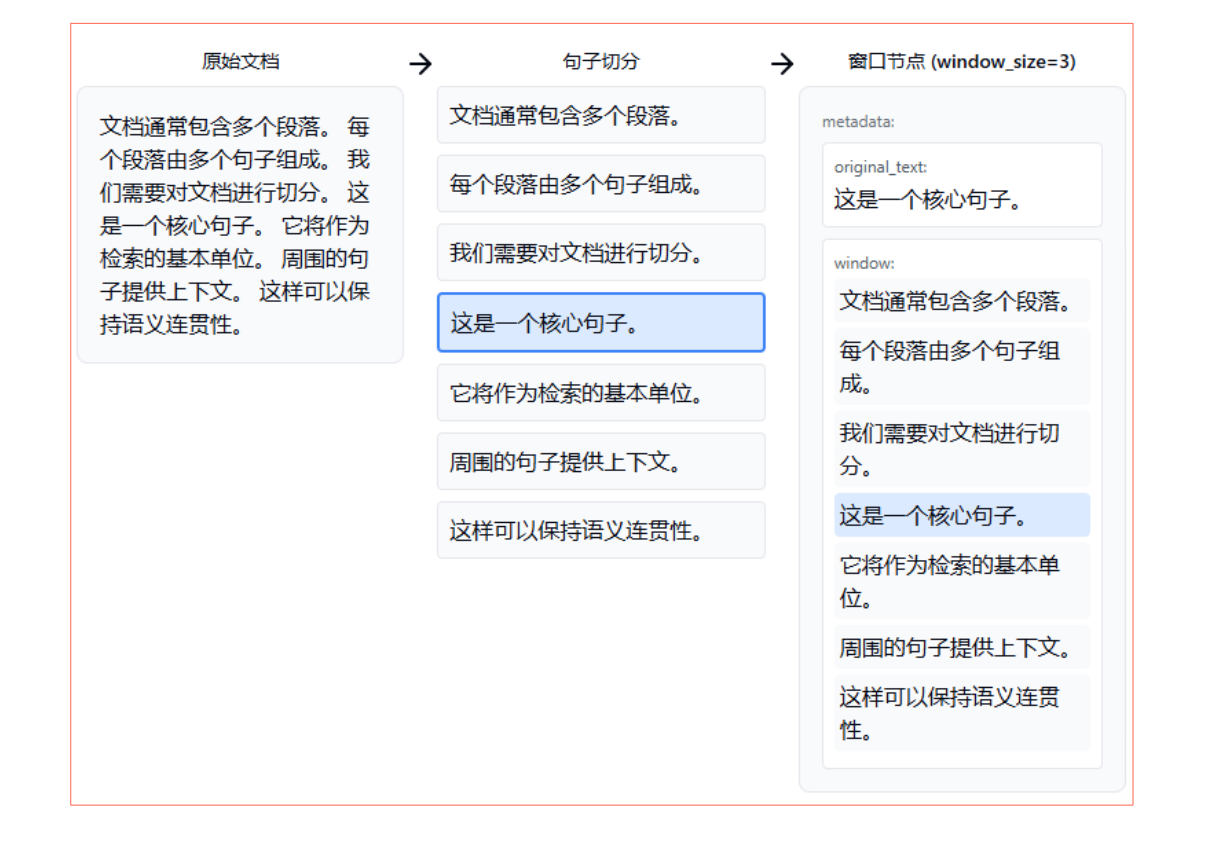
分塊時混合生成父子文本塊(Parent-Child Docs)
通過子文本塊檢索父文本塊
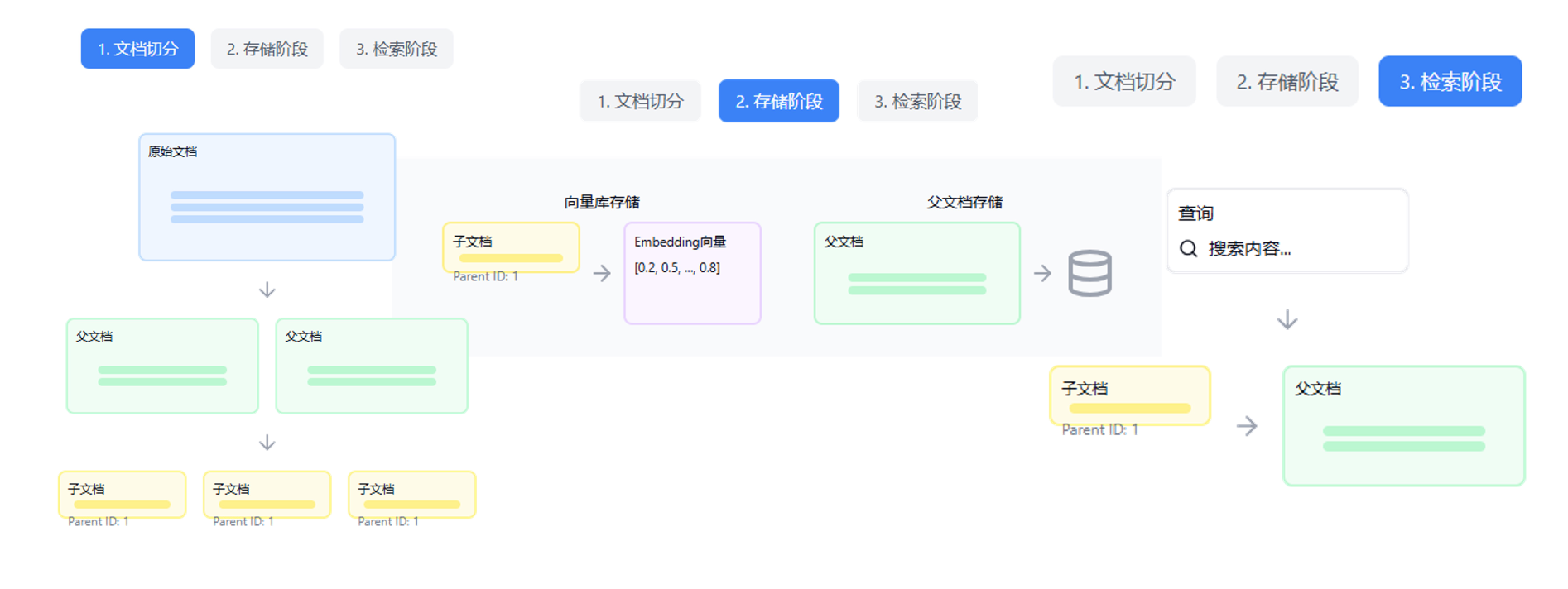
分塊時為文本塊創建元數據
打關鍵信息標簽
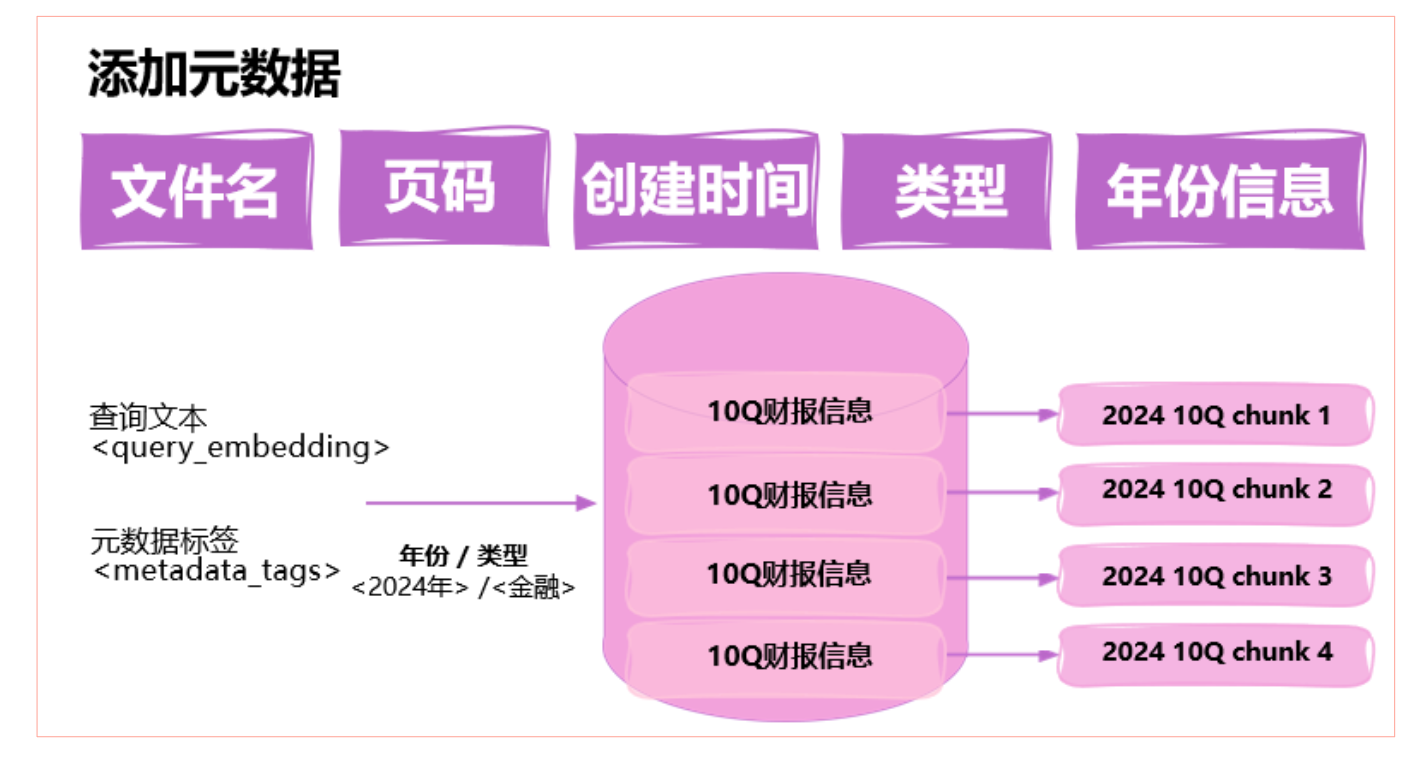
在分塊時形成有級別的索引(Summary→Details )?
從摘要到細節的文檔索引
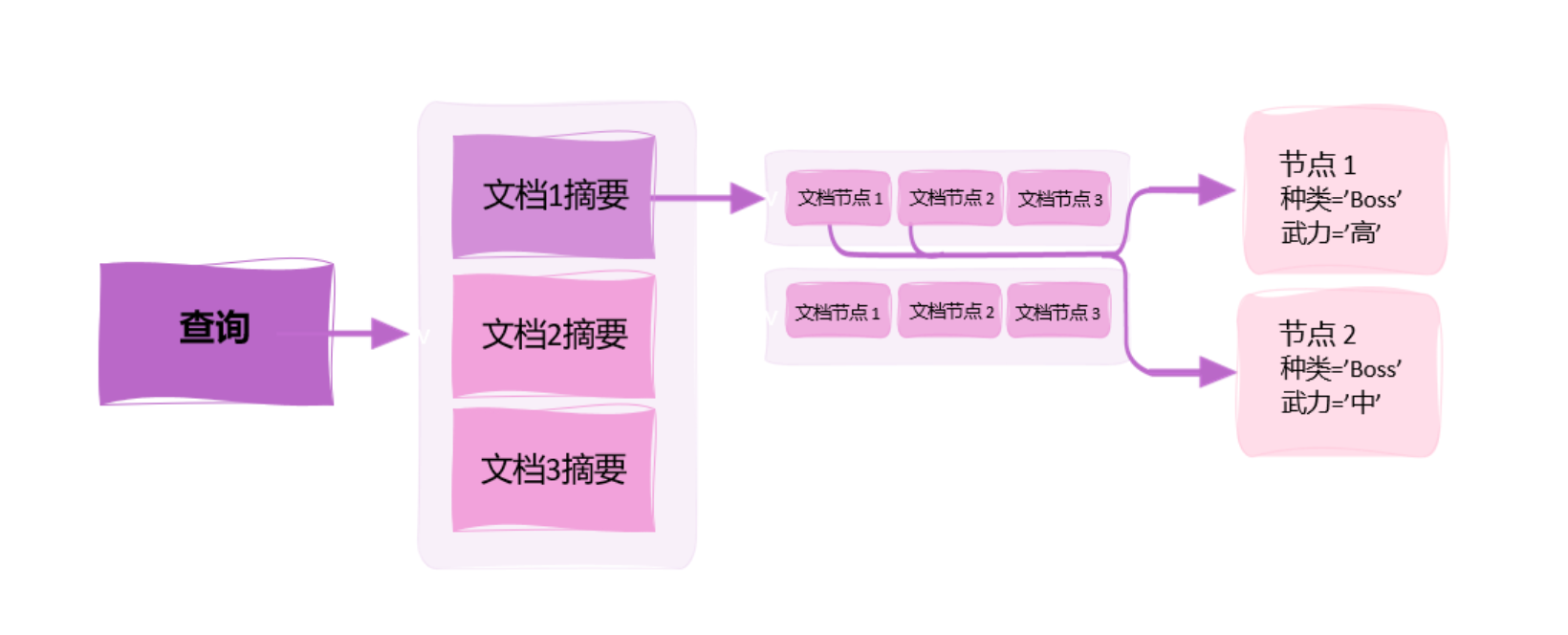
文檔→嵌入對象(Document→Embedded Objects)?
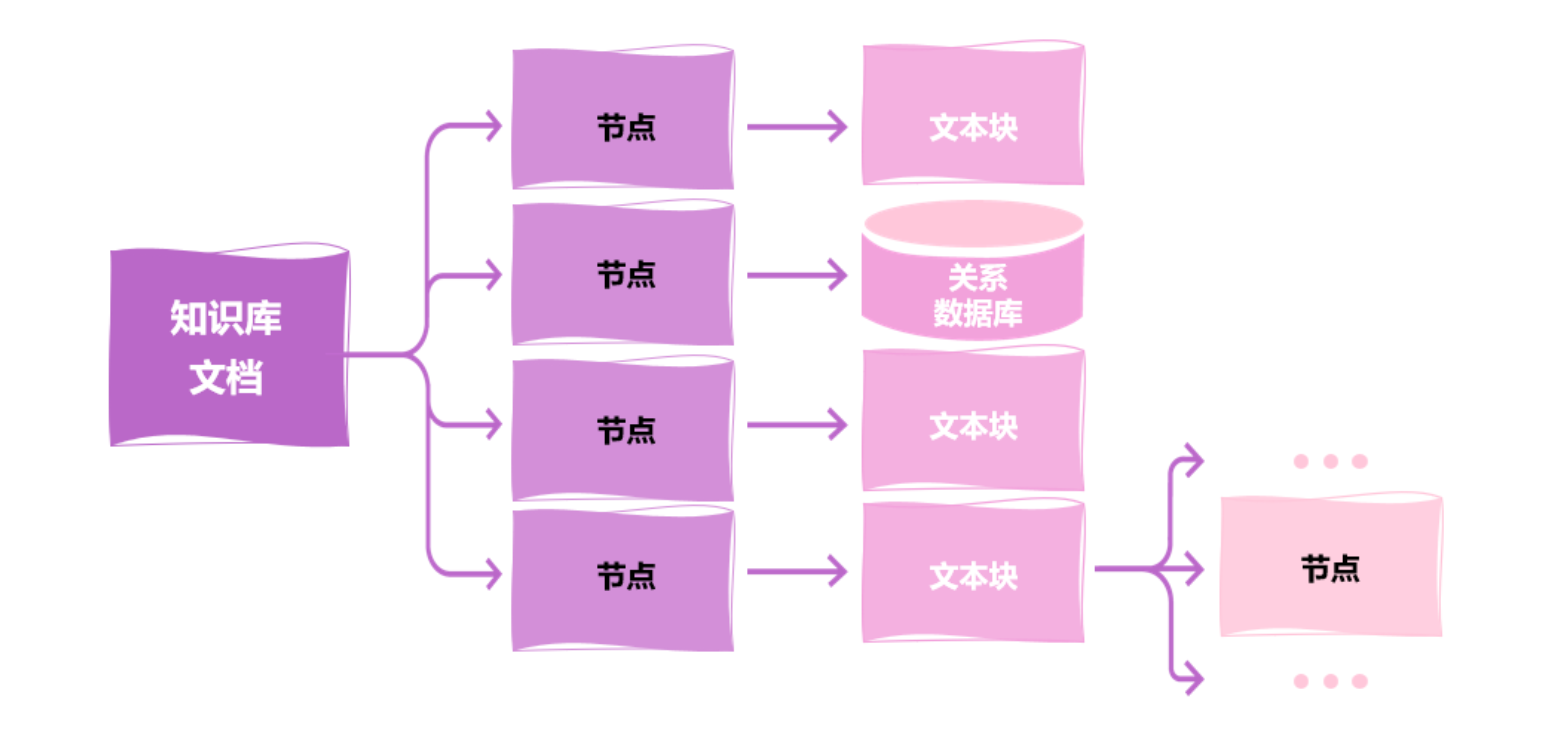






)

- computed的使用)






 的用法詳解(Vue響應式系統相關))
)


