前言:本節包含常見redis緩存問題,包含緩存一致性問題,緩存雪崩,緩存穿透,緩存擊穿問題及其解決方案
1. 緩存一致性
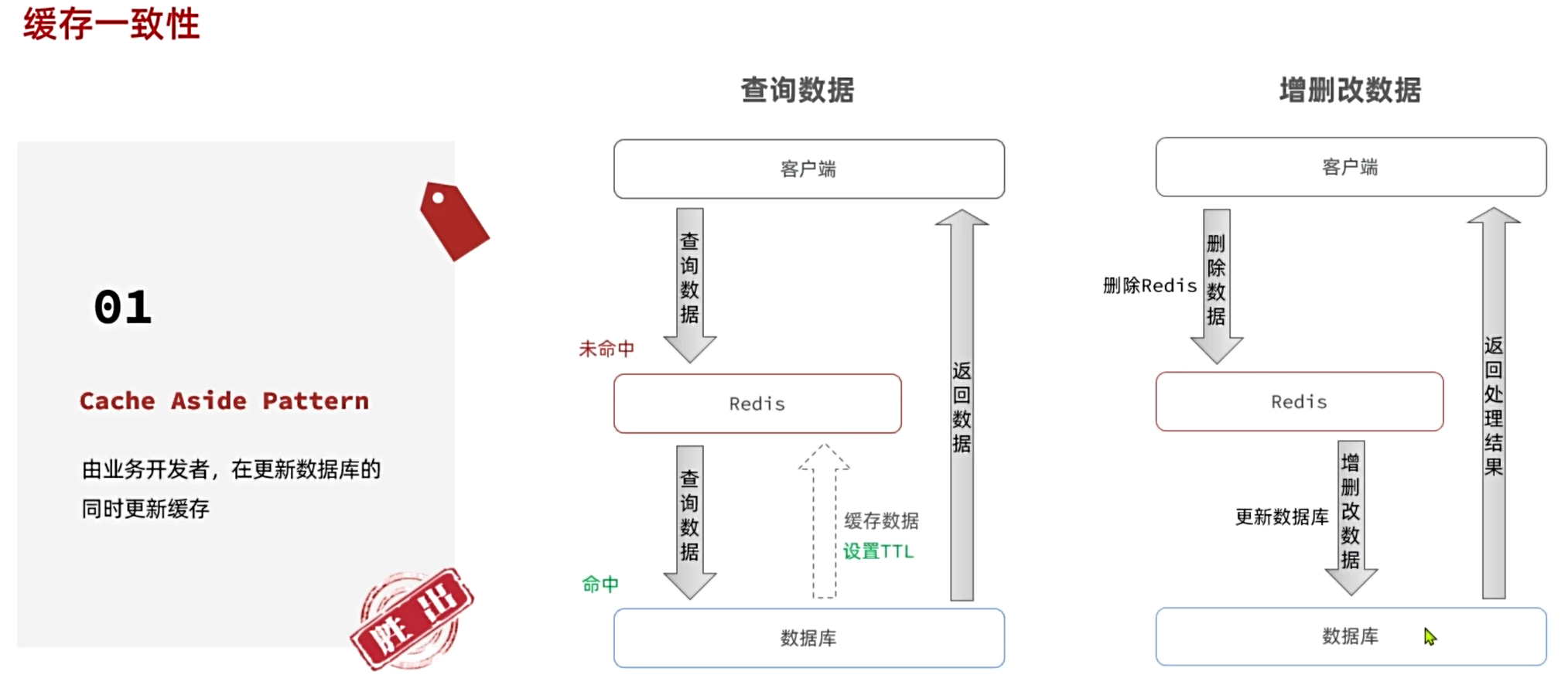
我們先看下目前企業用的最多的緩存模型。緩存的通用模型有三種:
| 緩存模型 | 解釋 |
| Cache Aside | 由緩存調用者自己維護數據庫與緩存的一致性 查詢時:命中則直接返回,未命中則查詢數據庫并寫入緩存 更新時:更新數據庫并刪除緩存,查詢時自然會更新緩存 |
| Read/Write Through | 數據庫自己維護一份緩存,底層實現對調用者透明 查詢時:命中則直接返回,未命中則查詢數據庫并寫入緩存 判斷緩存是否存在,不存在直接更新數據庫。存在則更新緩存,同步更新數據庫 |
| Write Behind Caching | 讀寫操作都直接操作緩存,由線程異步的將緩存數據同步到數據庫 |
目前項目中中使用最多的是Cache Aside模式,因為實現起來非常簡單。
在Cache Aside模式中,以下有兩點需要注意:
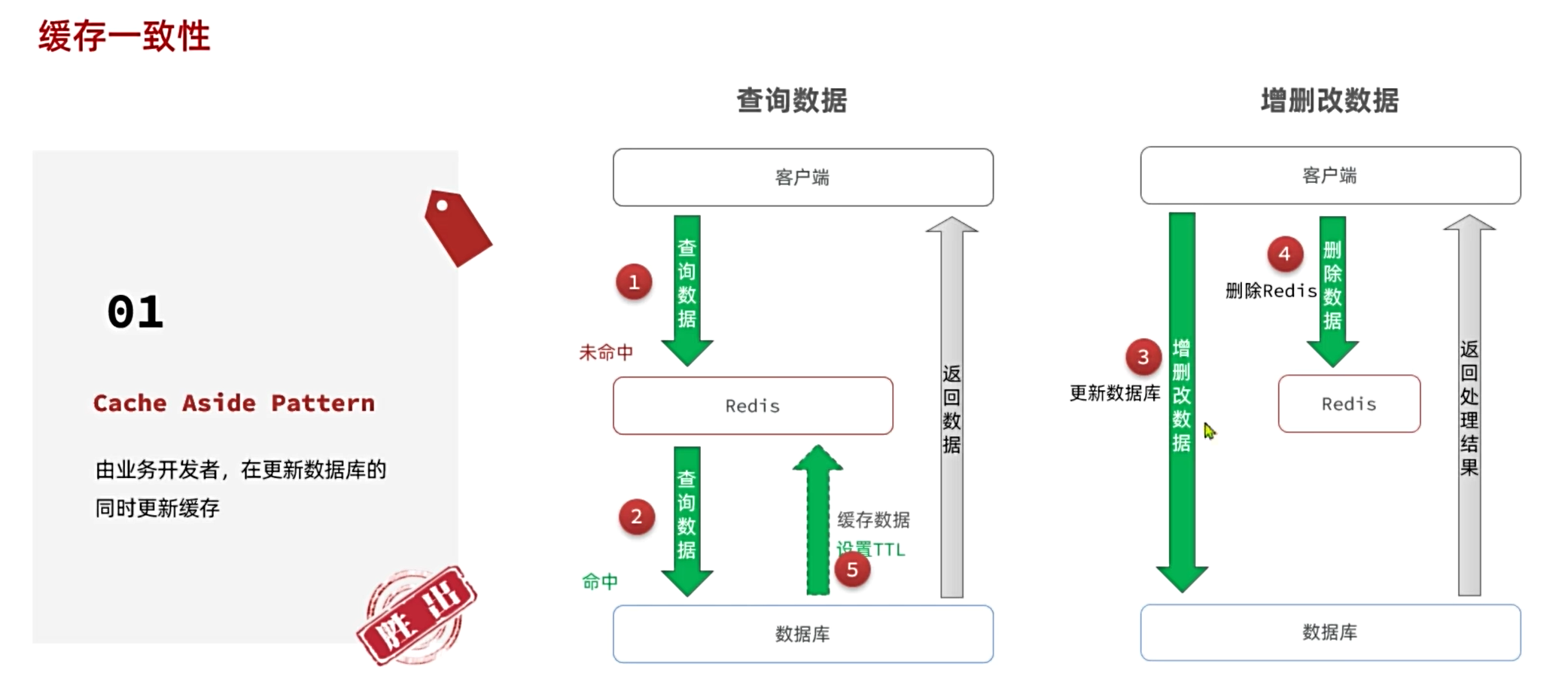
1.在對數據庫進行增刪改操作時,需要加入清理緩存邏輯
在數據庫進行增刪改等操作時,數據庫中數據會發生變化,但是Redis中緩存的數據未發生變化從而導致數據庫和Redis中的緩存的數據不一致,故而在對數據庫進行操作時,需要加入清理緩存邏輯來清理Redis中對應的未同步緩存數據
2.先更新數據庫再刪除緩存的方案
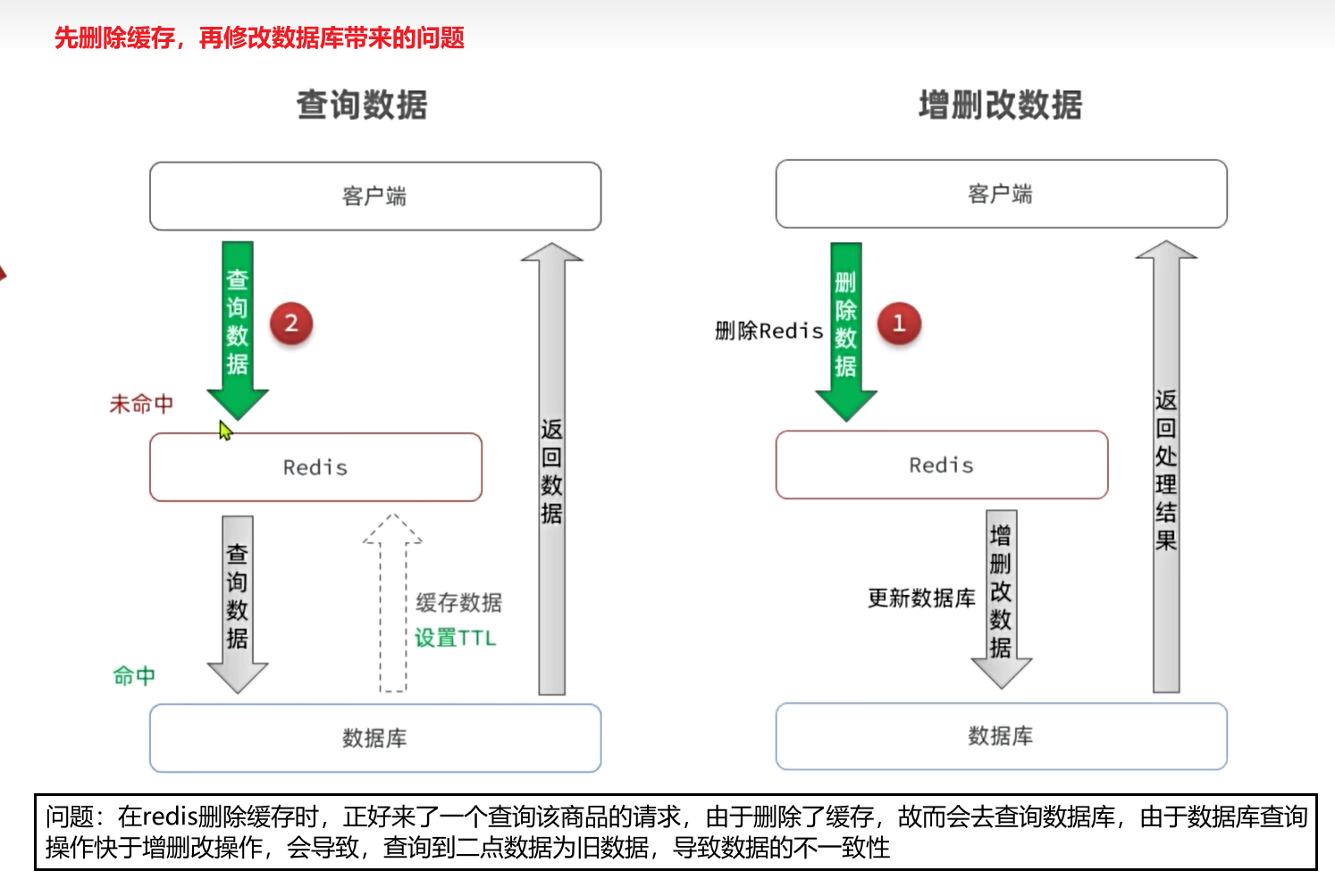
異常情況說明:
-
線程1查詢緩存未命中,于是去查詢數據庫,查詢到舊數據
-
線程1將數據寫入緩存之前,線程2來了,更新數據庫,刪除緩存
-
線程1執行寫入緩存的操作,寫入舊數據
???????可以發現,異常狀態發生的概率極為苛刻,線程1必須是查詢數據庫已經完成,但是緩存尚未寫入之前。線程2要完成更新數據庫同時刪除緩存的兩個操作。要知道線程1執行寫緩存的速度在毫秒之間,速度非常快,在這么短的時間要完成數據庫和緩存的操作,概率非常之低。
面試題:如何保證緩存的雙寫一致性?
答:緩存的雙寫一致性很難保證強一致,只能盡可能降低不一致的概率,確保最終一致。我們項目中采用的是
Cache Aside模式。簡單來說,就是在更新數據庫之后刪除緩存;在查詢時先查詢緩存,如果未命中則查詢數據庫并寫入緩存。同時我們會給緩存設置過期時間作為兜底方案,如果真的出現了不一致的情況,也可以通過緩存過期來保證最終一致。追問:為什么不采用延遲雙刪機制?
答:延遲雙刪的第一次刪除并沒有實際意義,第二次采用延遲刪除主要是解決數據庫主從同步的延遲問題,我認為這是數據庫主從的一致性問題,與緩存同步無關。既然主節點數據已經更新,Redis的緩存理應更新。而且延遲雙刪會增加緩存業務復雜度,也沒能完全避免緩存一致性問題,投入回報比太低。
2. 緩存穿透
什么是緩存穿透呢?
我們知道,當請求查詢緩存未命中時,需要查詢數據庫以加載緩存。但是大家思考一下這樣的場景:
如果我訪問一個數據庫中也不存在的數據。會出現什么現象?
????????由于數據庫中不存在該數據,那么緩存中肯定也不存在。因此不管請求該數據多少次,緩存永遠不可能建立,請求永遠會直達數據庫。
????????假如有不懷好意的人,開啟很多線程頻繁的訪問一個數據庫中也不存在的數據。由于緩存不可能生效,那么所有的請求都訪問數據庫,可能就會導致數據庫因過高的壓力而宕機。
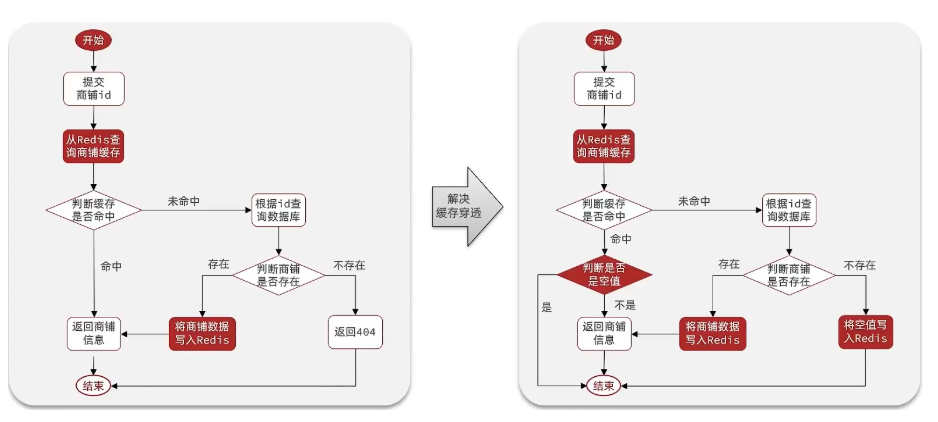
2.1 緩存空值
簡單來說,就是當我們發現請求的數據即不存在與緩存,也不存在與數據庫時,將空值緩存到Redis,避免頻繁查詢數據庫。實現思路如下:
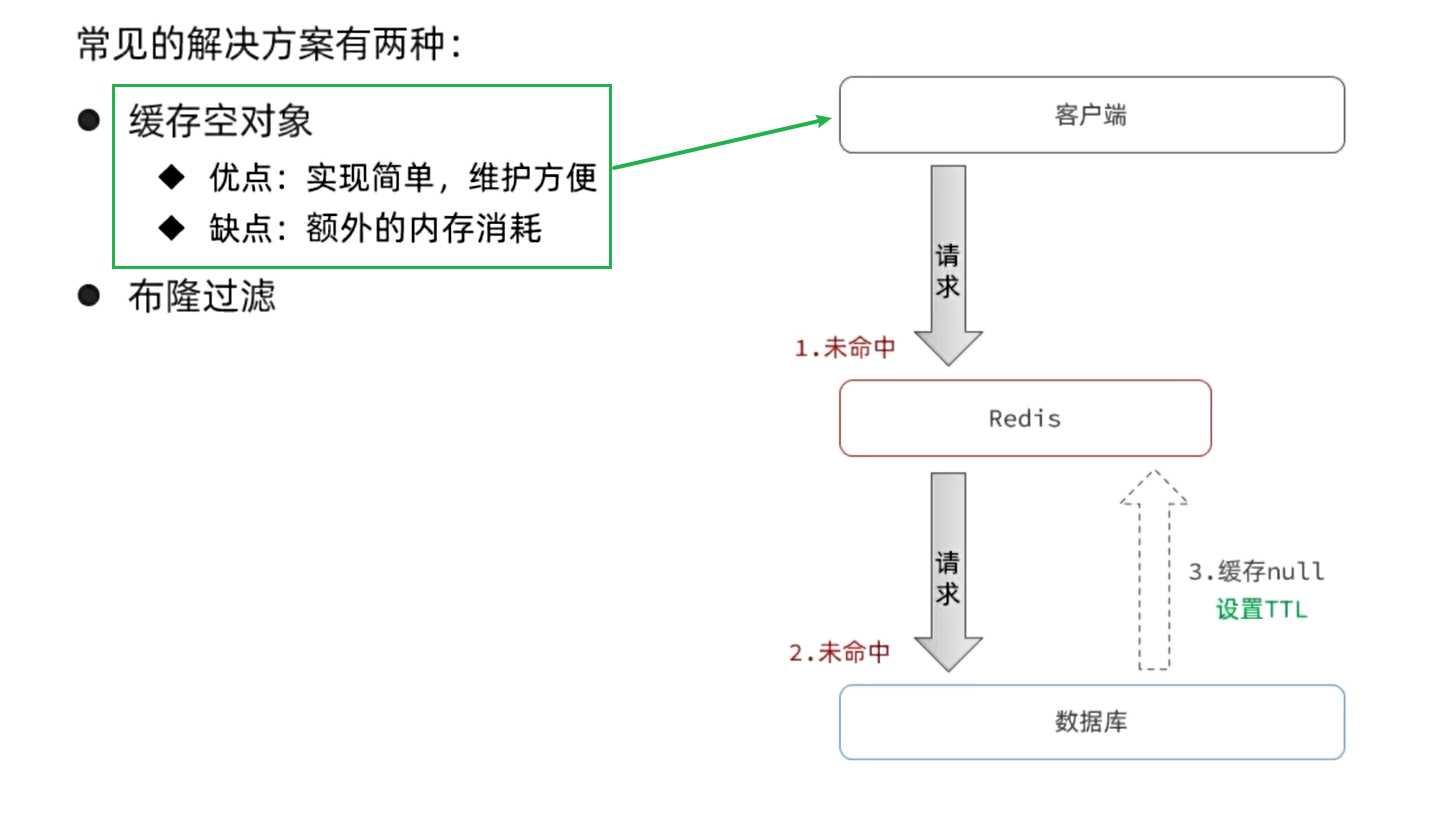
核心思路如下:
在原來的邏輯中,我們如果發現這個數據在mysql中不存在,直接就返回404了,這樣是會存在緩存穿透問題的
現在的邏輯中:如果這個數據不存在,我們不會返回404 ,還是會把這個數據寫入到Redis中,并且將value設置為空,歐當再次發起查詢時,我們如果發現命中之后,判斷這個value是否是null,如果是null,則是之前寫入的數據,證明是緩存穿透數據,如果不是,則直接返回數據。
2.2 布隆過濾器
布隆過濾是一種數據統計的算法,用于檢索一個元素是否存在一個集合中。
一般我們判斷集合中是否存在元素,都會先把元素保存到類似于樹、哈希表等數據結構中,然后利用這些結構查詢效率高的特點來快速匹配判斷。但是隨著元素數量越來越多,這種模式對內存的占用也越來越大,檢索的速度也會越來越慢。而布隆過濾的內存占用小,查詢效率卻很高。
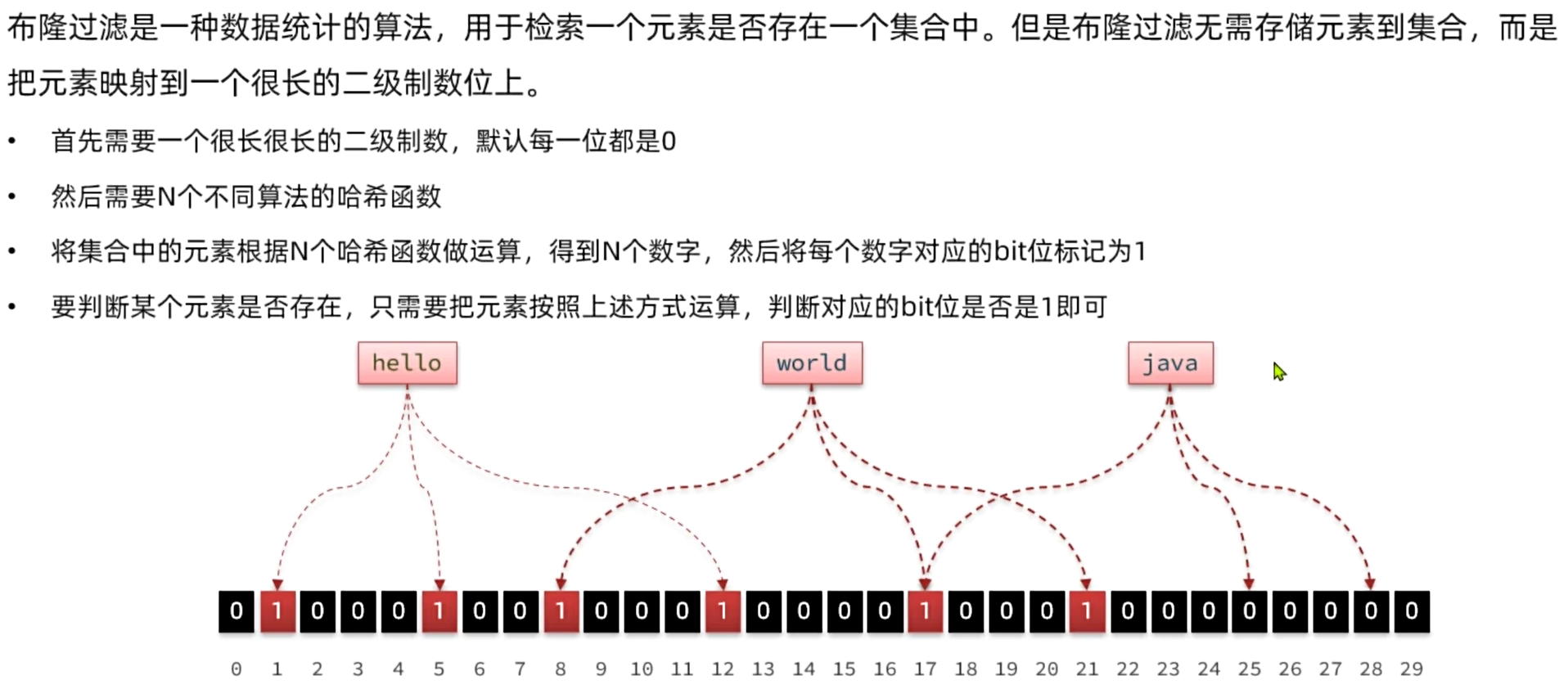
此時,我們要判斷元素是否存在,只需要再次基于K個hash函數做運算, 得到K個角標,判斷每個角標的位置是不是1:
-
只要全是1,就證明元素存在
-
任意位置為0,就證明元素一定不存在
假如某個元素本身并不存在,也沒添加到布隆過濾器過。但是由于存在hash碰撞的可能性,這就會出現這個元素計算出的角標已經被其它元素置為1的情況。那么這個元素也會被誤判為已經存在。
因此,布隆過濾器的判斷存在誤差:
-
當布隆過濾器認為元素不存在時,它肯定不存在
-
當布隆過濾器認為元素存在時,它可能存在,也可能不存在
我們可以把數據庫中的數據利用布隆過濾器標記出來,當用戶請求緩存未命中時,先基于布隆過濾器判斷。如果不存在則直接拒絕請求,存在則去查詢數據庫。盡管布隆過濾存在誤差,但一般都在0.01%左右,可以大大減少數據庫壓力。
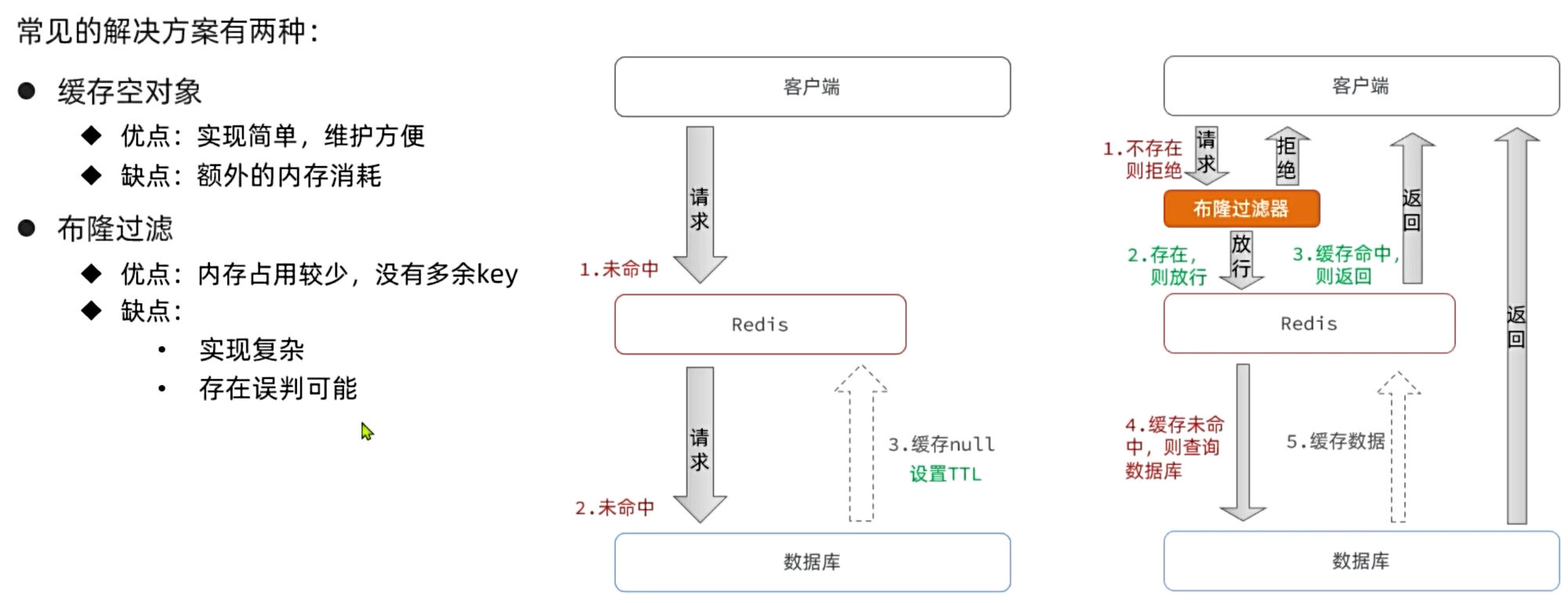
面試題:如何解決緩存穿透問題?
答:緩存穿透也可以說是穿透攻擊,具體來說是因為請求訪問到了數據庫不存在的值,這樣緩存無法命中,必然訪問數據庫。如果高并發的訪問這樣的接口,會給數據庫帶來巨大壓力。
我們項目中都是基于布隆過濾器來解決緩存穿透問題的,當緩存未命中時基于布隆過濾器判斷數據是否存在。如果不存在則不去訪問數據庫。
當然,也可以使用緩存空值的方式解決,不過這種方案比較浪費內存。
3. 緩存雪崩
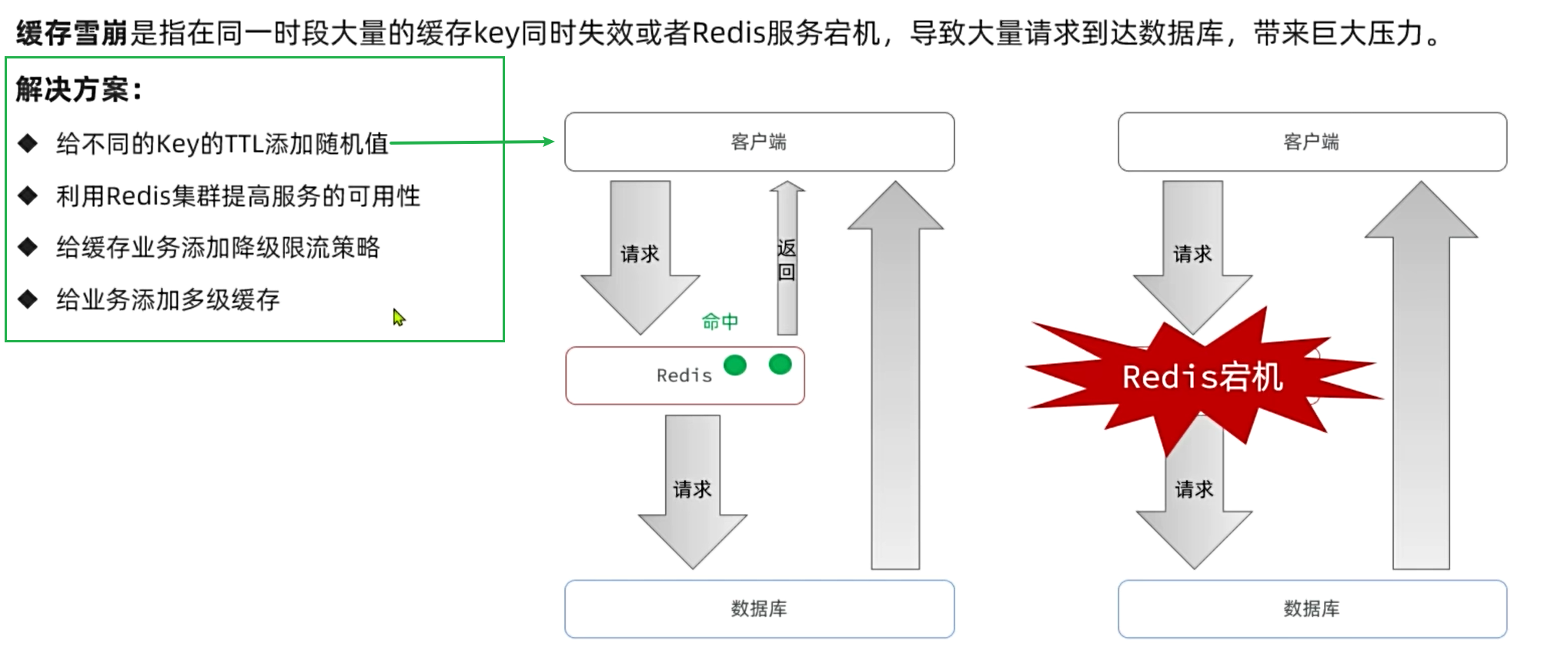
面試題:如何解決緩存雪崩問題?
答:緩存雪崩的常見原因有兩個,第一是因為大量key同時過期。針對問這個題我們可以可以給緩存key設置不同的TTL值,避免key同時過期。
第二個原因是Redis宕機導致緩存不可用。針對這個問題我們可以利用集群提高Redis的可用性。也可以添加多級緩存,當Redis宕機時還有本地緩存可用。
4.緩存擊穿
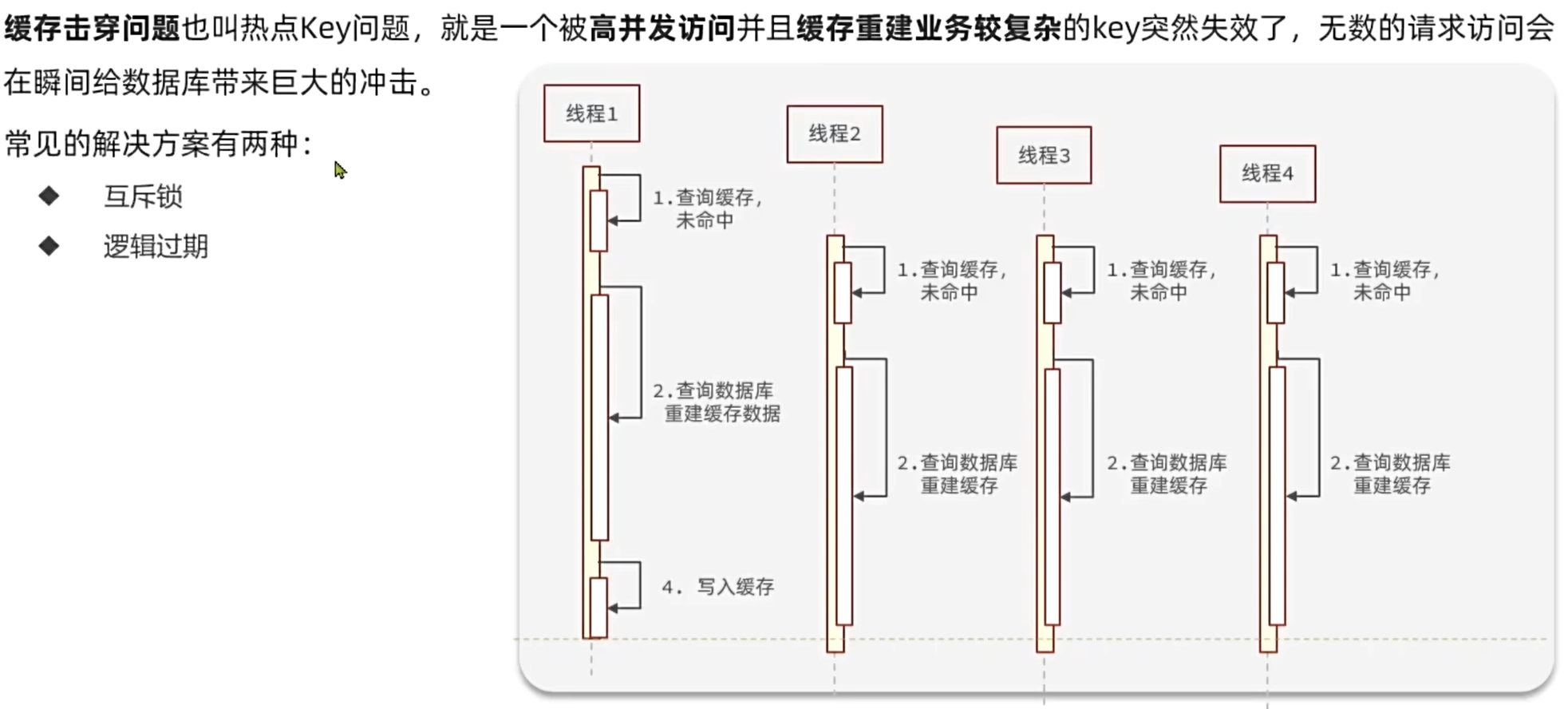
4.1 互斥鎖
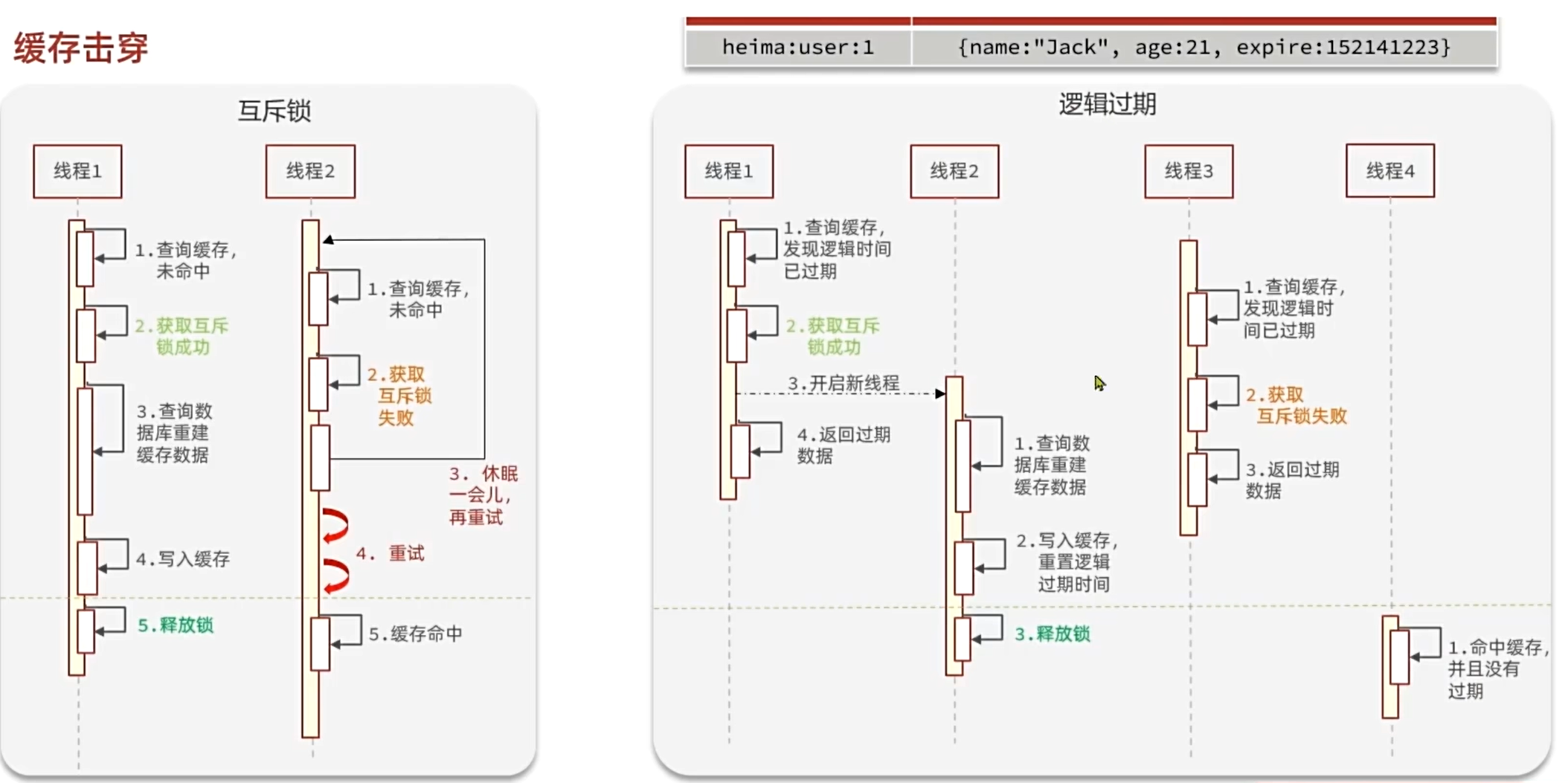
核心思路:相較于原來從緩存中查詢不到數據后直接查詢數據庫而言,現在的方案是 進行查詢之后,如果從緩存沒有查詢到數據,則進行互斥鎖的獲取,獲取互斥鎖后,判斷是否獲得到了鎖,如果沒有獲得到,則休眠,過一會再進行嘗試,直到獲取到鎖為止,才能進行查詢。
如果獲取到了鎖的線程,再去進行查詢,查詢后將數據寫入redis,再釋放鎖,返回數據,利用互斥鎖就能保證只有一個線程去執行操作數據庫的邏輯,防止緩存擊穿。
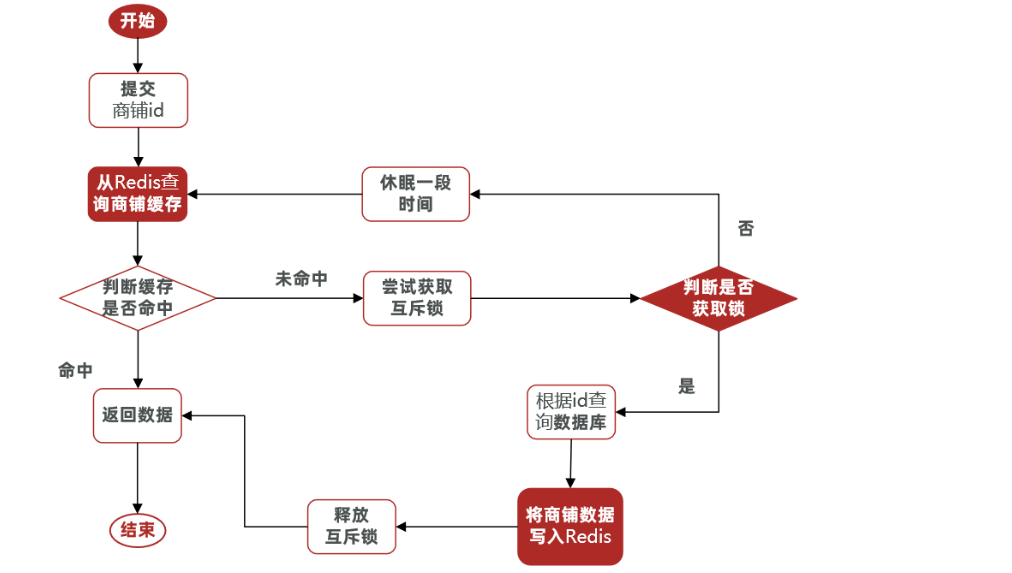
操作鎖的代碼:
核心思路就是利用redis的setnx方法來表示獲取鎖,該方法含義是redis中如果沒有這個key,則插入成功,返回1,在stringRedisTemplate中返回true, 如果有這個key則插入失敗,則返回0,在stringRedisTemplate返回false,我們可以通過true,或者是false,來表示是否有線程成功插入key,成功插入的key的線程我們認為他就是獲得到鎖的線程。
private boolean tryLock(String key) {Boolean flag = stringRedisTemplate.opsForValue().setIfAbsent(key, "1", 10, TimeUnit.SECONDS);return BooleanUtil.isTrue(flag);
}private void unlock(String key) {stringRedisTemplate.delete(key);
}操作代碼:
public Shop queryWithMutex(Long id) {String key = CACHE_SHOP_KEY + id;// 1、從redis中查詢商鋪緩存String shopJson = stringRedisTemplate.opsForValue().get("key");// 2、判斷是否存在if (StrUtil.isNotBlank(shopJson)) {// 存在,直接返回return JSONUtil.toBean(shopJson, Shop.class);}//判斷命中的值是否是空值if (shopJson != null) {//返回一個錯誤信息return null;}// 4.實現緩存重構//4.1 獲取互斥鎖String lockKey = "lock:shop:" + id;Shop shop = null;try {boolean isLock = tryLock(lockKey);// 4.2 判斷否獲取成功if(!isLock){//4.3 失敗,則休眠重試Thread.sleep(50);return queryWithMutex(id);}//4.4 成功,根據id查詢數據庫shop = getById(id);// 5.不存在,返回錯誤if(shop == null){//將空值寫入redisstringRedisTemplate.opsForValue().set(key,"",CACHE_NULL_TTL,TimeUnit.MINUTES);//返回錯誤信息return null;}//6.寫入redisstringRedisTemplate.opsForValue().set(key,JSONUtil.toJsonStr(shop),CACHE_NULL_TTL,TimeUnit.MINUTES);}catch (Exception e){throw new RuntimeException(e);}finally {//7.釋放互斥鎖unlock(lockKey);}return shop;}4.2 邏輯過期
需求:修改根據id查詢商鋪的業務,基于邏輯過期方式來解決緩存擊穿問題
思路分析:當用戶開始查詢redis時,判斷是否命中,如果沒有命中則直接返回空數據,不查詢數據庫,而一旦命中后,將value取出,判斷value中的過期時間是否滿足,如果沒有過期,則直接返回redis中的數據,如果過期,則在開啟獨立線程后直接返回之前的數據,獨立線程去重構數據,重構完成后釋放互斥鎖。
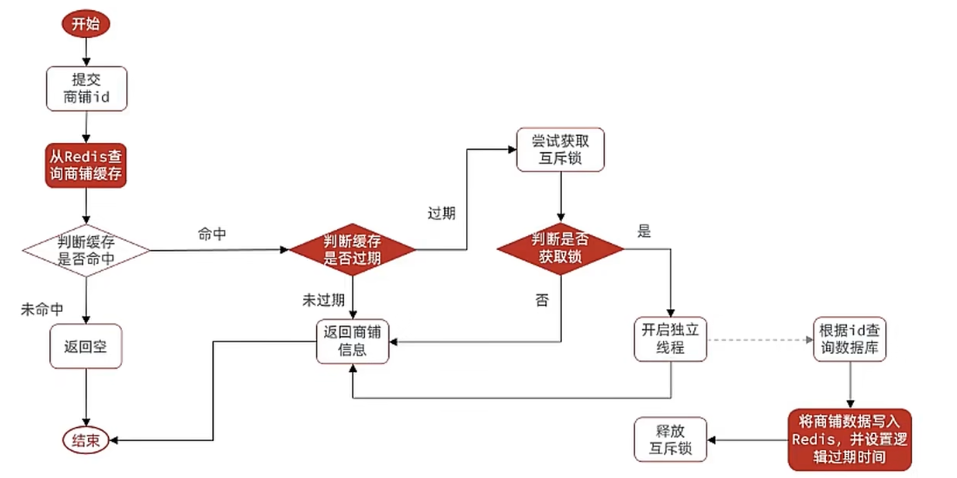
private static final ExecutorService CACHE_REBUILD_EXECUTOR = Executors.newFixedThreadPool(10);
public Shop queryWithLogicalExpire( Long id ) {String key = CACHE_SHOP_KEY + id;// 1.從redis查詢商鋪緩存String json = stringRedisTemplate.opsForValue().get(key);// 2.判斷是否存在if (StrUtil.isBlank(json)) {// 3.存在,直接返回return null;}// 4.命中,需要先把json反序列化為對象RedisData redisData = JSONUtil.toBean(json, RedisData.class);Shop shop = JSONUtil.toBean((JSONObject) redisData.getData(), Shop.class);LocalDateTime expireTime = redisData.getExpireTime();// 5.判斷是否過期if(expireTime.isAfter(LocalDateTime.now())) {// 5.1.未過期,直接返回店鋪信息return shop;}// 5.2.已過期,需要緩存重建// 6.緩存重建// 6.1.獲取互斥鎖String lockKey = LOCK_SHOP_KEY + id;boolean isLock = tryLock(lockKey);// 6.2.判斷是否獲取鎖成功if (isLock){CACHE_REBUILD_EXECUTOR.submit( ()->{try{//重建緩存this.saveShop2Redis(id,20L);}catch (Exception e){throw new RuntimeException(e);}finally {unlock(lockKey);}});}// 6.4.返回過期的商鋪信息return shop;
}
面試題:如何解決緩存擊穿問題?
答:緩存擊穿往往是由熱點Key引起的,當熱點Key過期時,大量請求涌入同時查詢,發現緩存未命中都會去訪問數據庫,導致數據庫壓力激增。解決這個問題的主要思路就是避免多線程并發去重建緩存,因此方案有兩種。
第一種是基于互斥鎖,當發現緩存未命中時需要先獲取互斥鎖,再重建緩存,緩存重建完成釋放鎖。這樣就可以保證緩存重建同一時刻只會有一個線程執行。不過這種做法會導致緩存重建時性能下降嚴重。
第二種是基于邏輯過期,也就是不給熱點Key設置過期時間,而是給數據添加一個過期時間的字段。這樣熱點Key就不會過期,緩存中永遠有數據。
查詢到數據時基于其中的過期時間判斷key是否過期,如果過期開啟獨立新線程異步的重建緩存,而查詢請求先返回舊數據即可。當然,這個過程也要加互斥鎖,但由于重建緩存是異步的,而且獲取鎖失敗也無需等待,而是返回舊數據,這樣性能幾乎不受影響。
需要注意的是,無論是采用哪種方式,在獲取互斥鎖后一定要再次判斷緩存是否命中,做dubbo check. 因為當你獲取鎖成功時,可能是在你之前有其它線程已經重建緩存了。













)



)
配置WDS手拉手業務)
