國產數據庫加速進入核心系統,傳統同步工具卻頻頻“掉鏈子”。本系列文章聚焦 OceanBase、GaussDB、TDSQL、達夢等主流信創數據庫,逐一拆解其日志機制與同步難點,結合 TapData 的實踐經驗,系統講解從 CDC 捕獲到實時入倉(Doris、StarRocks、ClickHouse 等)的完整鏈路構建方案,為工程師提供切實可行的替代路徑與最佳實踐。
本篇任務:GaussDB → StarRocks / Doris
背景:國產數據庫陸續上線生產,實時同步鏈路成新痛點
隨著信創進程的推進,國產數據庫已從非核心系統試點轉向全面生產落地。以 GaussDB、OceanBase、TDSQL、達夢等為代表的國產數據庫,已在金融、政務、電信等關鍵行業大規模部署,成為企業核心業務系統的數據承載平臺。
與此同時,“上云 + 實時數倉”的數據架構趨勢日益強化,企業對準實時同步能力的需求持續增長。無論是運營分析、風險監控,還是客戶行為洞察,數據從源庫同步到數據倉庫或其他下游系統的時效性,已成為業務響應速度的核心指標。
然而,OGG(Oracle GoldenGate)、Attunity、SharePlex 等曾廣泛使用的數據同步工具,早已停止對類似新興數據庫的支持。這些工具最初設計用于主流國際數據庫系統,無法適配國產數據庫的日志結構或提供 CDC(Change Data Capture)能力。這直接導致:
- 企業原有的 ETL、實時同步、實時入倉等任務難以繼續搭建
- 數據鏈路斷裂,影響業務連續性與實時數據能力的構建
國產數據庫的崛起,正在倒逼同步鏈路的技術演進:如何在缺乏傳統工具支持的情況下,構建面向新型數據源的完整實時同步方案,成為當前數據庫架構設計中的核心挑戰。本篇將以 GaussDB 為例,詳細講解如何構建信創數據庫的實時同步鏈路。
GaussDB 數據同步的關鍵技術挑戰
將 GaussDB 的數據變更同步至實時數倉(如 StarRocks / Doris)并非簡單的數據移動,而是涉及日志解析、數據一致性、類型兼容性及故障恢復等復雜問題。以下是構建該鏈路必須面對的核心參數與控制點:
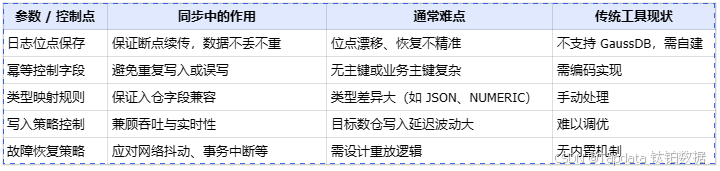
基于以上關鍵控制點,GaussDB 的數據同步面臨以下具體技術挑戰:
-
日志解析復雜化
GaussDB 的 WAL(Write-Ahead Logging)日志格式雖然與 PostgreSQL 類似,但存在差異化解析規則,需要針對性適配,無法直接復用傳統 PostgreSQL 的同步機制。 -
缺乏公開接口支撐
GaussDB 官方未提供完整的增量日志解析 API,需要進行二進制日志的反序列化與 checkpoint 管理,增加了開發與運維的復雜度。 -
數據一致性保障壓力大
在高并發環境下,如何處理亂序寫入、重復寫入、冪等控制成為保證鏈路正確性的核心問題,要求同步系統具備細粒度事務處理與數據校驗能力。 -
實時性要求高,兼容性要求嚴苛
下游如 StarRocks、Doris 等新一代數倉,對數據到達延遲要求秒級,且要求字段類型、結構高度兼容,進一步加劇了同步鏈路設計的技術門檻。
小結
傳統數據同步工具在面對 GaussDB 這類新型國產數據庫時,普遍缺乏基礎支撐能力,無法滿足日志捕獲、數據一致性控制、實時入倉等核心要求。構建可靠鏈路,需要在增量解析、鏈路調度、故障恢復等各個環節進行系統性的重構和優化。
TapData 的實時同步鏈路能力與技術實現
面對 GaussDB 到 StarRocks / Doris 的實時同步需求,TapData 設計并實現了從日志捕獲、數據清洗、順序保障到 下游高性能寫入的完整鏈路,能夠在完全國產化的軟硬件環境下穩定運行。
自研 CDC 引擎
TapData 自主研發的 CDC(Change Data Capture)引擎支持對 GaussDB 的增量日志(WAL)進行解析,核心能力包括:
日志捕獲
:通過邏輯復制槽(logical slot)持續拉取增量變更數據。
- 斷點恢復:結合位點管理機制,支持故障后的精準續傳,避免數據丟失或重復寫入。
- 事務順序與冪等控制:識別事務邊界,解決并發寫入導致的亂序和重復問題,確保下游數據一致性。
- 國產環境兼容性:該引擎已適配麒麟、統信 UOS 等國產操作系統,并在飛騰、鯤鵬等主流國產服務器上通過兼容性測試,可穩定運行于信創軟硬件環境。
內置 StarRocks / Doris Connector
為了滿足 GaussDB 的數據入倉等特定需求,TapData 提供了內置的數據連接器(如 StarRocks / Doris Connector),具備以下特性:
- 寬表支持:自動適配 StarRocks / Doris 的寬表建模特性,提升多維分析效率并降低查詢復雜度。
- 字段映射與類型轉換:內置字段映射規則,兼容 GaussDB 與 StarRocks / Doris 之間的數據類型差異,支持 JSON、DECIMAL、NUMERIC 等復雜字段的自動轉換。
- 批量寫入與合并策略:支持多種寫入策略,包括 insert 和類 upsert 行為(基于 Primary Key 模型),支持insert_or_update 及 merge 策略,用戶可根據業務需求靈活選擇。
- 物化視圖觸發:支持物化視圖自動刷新機制,在數據寫入后提升查詢性能和響應速度。
- 國產軟硬件支持:Connector 同樣通過國產操作系統和硬件的兼容性驗證,支持在國產化環境下的大規模數據寫入。
TapData 構建 GaussDB → StarRocks / Doris 的完整鏈路結構
TapData 的鏈路設計遵循模塊化、可視化、靈活調優的原則,支持用戶根據實際業務需求進行調整。
鏈路組成模塊

數據流動路徑

核心控制邏輯
- 亂序恢復:基于事務 ID 的排序機制,確保寫入順序正確。
- 緩沖與批處理:支持數據緩沖區與寫入批次調優,兼顧實時性與吞吐。
- 多數據管道支持:允許并行同步多個業務域的數據,實現鏈路擴展性。
- 信創兼容:鏈路所有組件已通過國產操作系統及硬件兼容性驗證,支持在信創環境下穩定運行,目標數據庫節點亦已完成兼容性測試,適配金融、政務等關鍵行業要求。
可視化鏈路編排

TapData 提供拖拽式的鏈路編排界面,用戶可通過 UI 快速構建和調整數據同步鏈路。每個任務節點的功能與狀態一目了然,同時支持參數調整、鏈路監控及錯誤追蹤,降低了工程復雜度,提高了運維效率。
小結
通過自研 CDC 引擎與內置 Connector 的深度整合,TapData 能夠在國產數據庫 GaussDB 與新一代實時數倉之間建立高可靠、高兼容、低延遲的數據同步鏈路,同時滿足信創環境下對軟硬件兼容性的嚴格要求,有效解決傳統同步工具在性能、寫入策略和國產化支持方面的技術難題。
實戰案例:某金融客戶構建 GaussDB → StarRocks 實時分析數倉
客戶背景與需求:該客戶為國內大型金融機構,近期將部分核心業務數據庫遷移至 GaussDB,并規劃構建新的審計分析平臺。平臺要求實現業務數據的近實時同步,并通過 StarRocks 構建支撐自定義 BI 報表的高并發分析引擎,滿足日常審計與數據分析需求。
數據鏈路設計
- 鏈路目標:
日志(GaussDB WAL)→ TapData → 實時寬表(StarRocks)→ 自定義 BI 報表 - 替代方案:
新鏈路成功替代原有 OGG + Kafka + Flink 方案,整體架構更輕量,運維復雜度顯著降低。
實現效果
- 實現 T+0 近實時同步,覆蓋超過 30 張表。
- StarRocks 查詢性能顯著提升,數據延遲從分鐘級壓縮至秒級以下,滿足金融核心系統的低延遲分析需求。
- 通過 TapData 的可視化鏈路配置與監控功能,降低了鏈路部署與維護的技術門檻。
最佳實踐建議
在實施過程中,結合業務需求與鏈路特性,總結出以下最佳實踐:
- 寬表建模 + 物化視圖加速:簡化查詢邏輯,提高響應速度。
- 字段命名統一標準:減少同步過程中的字段映射錯誤,便于后期維護。
- 啟用 TapData 的鏈路狀態監控與自動重試機制:提升鏈路的容錯能力。
- StarRocks 分區與分桶設計:結合業務邏輯進行合理建模,提升查詢效率并降低資源消耗。
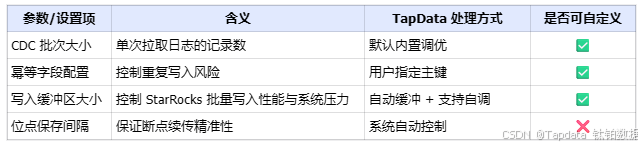
高級設置項與可調參數(供架構評估參考)
雖然 TapData 封裝了大部分復雜操作,但對于性能敏感或有定制需求的場景,以下參數可作為架構設計和調優的重要參考:
小結
本案例展示了在缺乏傳統工具支持的環境下,如何通過 TapData 構建 GaussDB → StarRocks 的高性能實時分析鏈路,不僅滿足了高實時性與一致性要求,同時顯著簡化了工程實現的復雜度,并驗證了最佳實踐的有效性。
總結與展望
隨著 GaussDB 等國產數據庫在核心業務系統中的廣泛應用,傳統同步工具(如 OGG、Attunity、SharePlex)在數據源支持上的缺位,直接導致企業在構建信創數據鏈路時需要重新尋找可行的新方案。
本次實踐中,通過 TapData 的日志捕獲、數據清洗、順序保障及寫入能力,高效、低成本實現了 GaussDB 到實時數倉的高并發低延遲數據鏈路,并在生產環境中驗證了其高可靠性與擴展性,支撐了自定義 BI 分析的落地。
此外,TapData 針對信創數據庫的數據源支持能力正在持續擴展,鏈路的穩定性、一致性控制及對國產軟硬件的兼容性也在不斷提升,能夠滿足金融、政務等關鍵行業的生產級同步需求。
次回預告
TDSQL for MySQL → ClickHouse 實時鏈路實踐
將在下一篇中深入解析騰訊云 TDSQL for MySQL 的增量日志捕獲難點、與 ClickHouse 的數據類型兼容策略,以及如何通過 TapData 構建高吞吐低延遲的數據鏈路,滿足復雜查詢場景的性能需求。






對比辨析)












