
文章目錄
Standalone集群部署
一、節點劃分
二、搭建Standalone集群
1、將下載好的Spark安裝包上傳解壓
2、配飾spark-env.sh
3、配置workers
4、將配置好的安裝包發送到node2、node3節點上
5、啟動Standalone集群
三、提交任務測試
Standalone集群部署
Standalone 模式是 Spark 自帶的資源調度系統,無需依賴外部集群管理器。在此模式下,集群角色包含主節點(Master)、工作節點(Worker)、Client組成。各角色作用如下:
- Master節點:負責集群資源管理和任務調度。
- Worker節點:負責執行具體的計算任務。
- Client負責:向Standalone集群中提交任務。
一、節點劃分
這里搭建Standalone集群選擇一臺Master和兩臺Worker以及一臺Client,按照如下節點劃分在各個節點上部署各個角色。
#Spark安裝包中各個目錄和文件作用如下
[root@node1 software]# ll spark-3.5.5
drwxr-xr-x bin:包含管理Spark的可執行腳本。
drwxr-xr-x conf:包含Spark的配置模板文件。
drwxr-xr-x data:包含示例應用程序所需的數據集,通常用于GraphX、MLlib和Streaming的示例。
drwxr-xr-x examples:包含Spark的示例代碼和JAR包,供用戶參考和測試。
drwxr-xr-x jars:存放Spark運行時所需的所有JAR包,包括Spark自身的JAR以及其依賴項。
drwxr-xr-x kubernetes:包含與Kubernetes集成相關的資源和配置。
-rw-r--r-- LICENSE:Spark的許可證文件,說明了軟件的許可條款。
drwxr-xr-x licenses:包含Spark所依賴的第三方庫的許可證文件。
-rw-r--r-- NOTICE:關于Spark的一些法律聲明和通知。
drwxr-xr-x python:包含PySpark(Spark的Python API)相關的文件和資源。
drwxr-xr-x R:包含SparkR(Spark的R API)相關的文件和資源。
-rw-r--r-- README.md:提供關于Spark的簡要介紹和使用說明。
-rw-r--r-- RELEASE:包含當前Spark版本的發布說明。
drwxr-xr-x sbin:包含用于啟動和停止Spark集群的腳本。
drwxr-xr-x yarn:包含與Hadoop YARN集成相關的jar包。二、搭建Standalone集群
1、將下載好的Spark安裝包上傳解壓
將“spark-3.5.5-bin-hadoop3-scala2.13.tgz”上傳至node1節點,進行解壓并修改名稱。
[root@node1 ~]# cd /software/ [root@node1 software]# tar -zxvf ./spark-3.5.5-bin-hadoop3-scala2.13.tgz
[root@node1 software]# mv spark-3.5.5-bin-hadoop3-scala2.13 spark-3.5.5#Spark安裝包中各個目錄和文件作用如下
[root@node1 software]# ll spark-3.5.5 drwxr-xr-x bin:包含管理Spark的可執行腳本。
drwxr-xr-x conf:包含Spark的配置模板文件。
drwxr-xr-x data:包含示例應用程序所需的數據集,通常用于GraphX、MLlib和Streaming的示例。
drwxr-xr-x examples:包含Spark的示例代碼和JAR包,供用戶參考和測試。
drwxr-xr-x jars:存放Spark運行時所需的所有JAR包,包括Spark自身的JAR以及其依賴項。
drwxr-xr-x kubernetes:包含與Kubernetes集成相關的資源和配置。
-rw-r--r-- LICENSE:Spark的許可證文件,說明了軟件的許可條款。
drwxr-xr-x licenses:包含Spark所依賴的第三方庫的許可證文件。
-rw-r--r-- NOTICE:關于Spark的一些法律聲明和通知。
drwxr-xr-x python:包含PySpark(Spark的Python API)相關的文件和資源。
drwxr-xr-x R:包含SparkR(Spark的R API)相關的文件和資源。
-rw-r--r-- README.md:提供關于Spark的簡要介紹和使用說明。
-rw-r--r-- RELEASE:包含當前Spark版本的發布說明。
drwxr-xr-x sbin:包含用于啟動和停止Spark集群的腳本。
drwxr-xr-x yarn:包含與Hadoop YARN集成相關的jar包。2、配飾spark-env.sh
進入$SPARK_HOME/conf,配置spark-env.sh,配置如下內容:
[root@node1 ~]# cd /software/spark-3.5.5/conf/
[root@node1 conf]# mv spark-env.sh.template spark-env.sh
[root@node1 conf]# vim spark-env.sh
export SPARK_MASTER_HOST=node1
export SPARK_MASTER_PORT=7077
export SPARK_MASTER_WEBUI_PORT=8080
export SPARK_WORKER_CORES=2
export SPARK_WORKER_MEMORY=3g
export SPARK_WORKER_WEBUI_PORT=8081
- SPARK_MASTER_HOST:必配項,master的ip。
- SPARK_MASTER_PORT:提交任務的端口,默認7077。
- SPARK_MASTER_WEBUI_PORT:Spark WebUI端口,默認8080。
- SPARK_WORKER_CORES:每個worker從節點能夠支配的core的個數,默認是對應節點上所有可用的core。
- SPARK_WORKER_MEMORY:每個worker從節點能夠支配的內存大小,默認1G。
- SPARK_WORKER_WEBUI_PORT:worker WebUI 端口。
3、配置workers
進入$SPARK_HOME/conf,配置workers,寫入node2、node3節點:
[root@node1 ~]# cd /software/spark-3.5.5/conf/
[root@node1 conf]# mv workers.template workers
[root@node1 conf]# vim workers
node2
node3
4、將配置好的安裝包發送到node2、node3節點上
[root@node1 software]# cd /software/
[root@node1 software]# scp -r ./spark-3.5.5 node2:`pwd`
[root@node1 software]# scp -r ./spark-3.5.5 node3:`pwd`5、啟動Standalone集群
進入$SPARK_HOME/sbin,指定如下命令啟動standalone集群。
[root@node1 software]# cd /software/spark-3.5.5/sbin
[root@node1 sbin]#./start-all.sh注意:啟動SparkStandalone集群的命令“start-all.sh”與啟動HDFS集群的命令“start-all.sh”命令一樣,這里不再單獨配置Spark環境變量。
Standalone集群啟動完成后,在瀏覽器輸入“http://node1:8080”查看Spark Standalone集群信息。
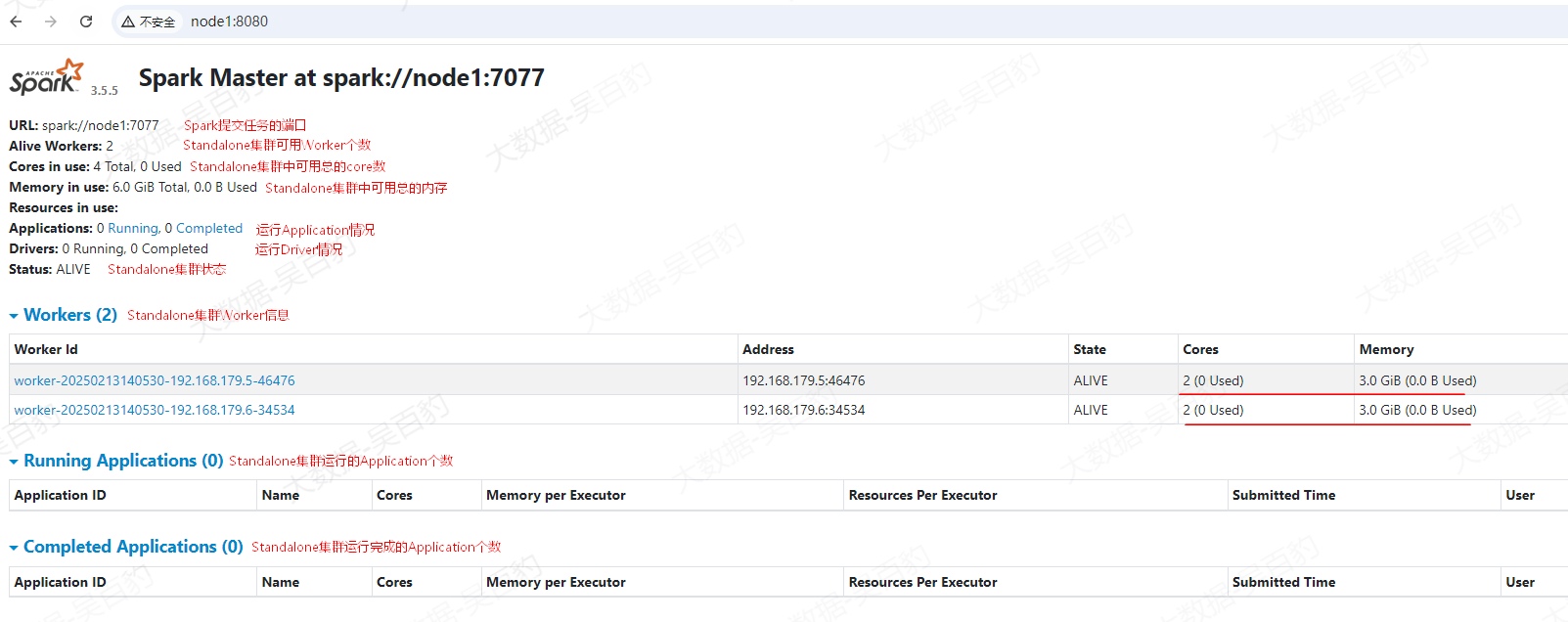 ?
?
注意:如果Standalone集群沒有正常運行,可以通過查看各個節點的$SPARK_HOME/logs目錄中的日志錯誤來解決。
三、提交任務測試
這里向Standalone集群中提交Spark Pi任務為例,來測試集群是否可以正常提交任務。向Standalone集群中提交任務需要準備Spark客戶端。
Spark客戶端主要就是向Spark集群中提交任務,只要一臺節點上有Spark安裝包,就可以向Spark集群中提交任務,這里在node4節點上單獨再搭建Spark提交任務的客戶端,只需要將Spark安裝包解壓放在node4節點即可。
[root@node4 ~]# cd /software/
[root@node4 software]# tar -zxvf ./spark-3.5.5-bin-hadoop3-scala2.13.tgz
[root@node4 software]# mv ./spark-3.5.5-bin-hadoop3-scala2.13 spark-3.5.5注意:任何一臺Spark Standalone集群中的節點都可以作為客戶端向Standalone集群中提交任務,這里只是將node4節點作為提交任務客戶端后續向Standalone集群中提交任務。
在node4節點上向Standalone集群中提交任務命令如下:
[root@node4 ~]# cd /software/spark-3.5.5/bin/
[root@node4 bin]# ./spark-submit --master spark://node1:7077 --class org.apache.spark.examples.SparkPi ../examples/jars/spark-examples_2.13-3.5.5.jar 100
任務提交后,可以看到向Standalone集群中提交任務并執行100個task,最終輸出pi大致結果。
- 📢博客主頁:https://lansonli.blog.csdn.net
- 📢歡迎點贊 👍 收藏 ?留言 📝 如有錯誤敬請指正!
- 📢本文由 Lansonli 原創,首發于 CSDN博客🙉
- 📢停下休息的時候不要忘了別人還在奔跑,希望大家抓緊時間學習,全力奔赴更美好的生活?












IRF堆疊心跳的LACP MAD、BFD MAD和ARP MAD差異)






