前置知識
python中各個進制的開頭?
二進制 : 0b
八進制 : 0o
十六進制 : 0x進制轉換函數 :? bin()? 轉為2進制? ?oct() 轉換為八進制的函數? ?hex() 轉換為16進制的函數
ascii碼和字符之間的轉換? :? chr('97')? 碼轉為字符? ? ? ? ? ? 字符轉為碼? ord('a')
進制轉換腳本 :
def jinzhi(num_str, from_base, to_base): #傳入的參數 需要數字 當前的進制 想要轉換的進制try: #類型確定的容錯# 確保輸入是字符串類型shuru = int(str(num_str), from_base) # 先轉為字符串if to_base == 2:return bin(shuru)[2:] # 切片去除前綴 2位elif to_base == 8:return oct(shuru)[2:]elif to_base == 16:return hex(shuru)[2:].upper()elif to_base == 10:return str(shuru) # 修正切片錯誤return Noneexcept (ValueError, TypeError):return None# 應該傳入字符串類型的數字
print(jinzhi("123", 10, 2)) # 正確輸出:1111011
print(jinzhi(123, 10, 2)) # 現在也能正常工作(因為內部做了轉換)進制轉ascii字符串
每八個二進制代表一個ascii字符串? ?三個八進制代表一個
def bin_tostr(bin_str):ascii_str=''for i in range(0,len(bin_str),8): //進行遍歷 步長是8a=bin_str[i,i+8] //進行 切片每八位一個asciiascii_str+=chr(int(a,2)) // 二進制轉為 asciireturn ascii_strdef oct_tostr(oct_str):ascii_str=''for i in range(0.,len(oct_str),3):a=oct_str[i,i+3]ascii_str+=chr(int(a,8))return ascii_strdef hex_tostr(hex_str:str):if hex_str.startswith('0x'):hex_str=hex_str[2:]return bytes.fromhex(hex_str).decode('ascii') //16 進制可以直接轉為 ascii 碼 需要先進行字節流的轉換 然后進行ascii解碼
if __name__ == "__main__":a='0x68656c6c6f'print(hex_tostr(a))但是上面這樣寫 如果我們給與的二進制的數大于8 多余的該怎么辦 ??? 小于8該怎么辦???
這個就是腳本撰寫常考慮的 多減 少補問題
下面是改進的
def bin_tostr(bin_str:str,pad=True): #pad 就是是否開啟下面的補 0 模式ascii_str=''lens=len(bin_str)//8 #表示向下取整這樣就會篩下 大于8位的 這樣后邊我們還有進行處理#先處理 8的整數for i in range(0,lens):a=bin_str[i*8:(i+1)*8] # +1的目的是為了循壞的時候挨個向后推ascii_str+=chr(int(a,2))# 處理溢出或缺少的值 :remain=len(bin_str) % 8if remain>0 : #存在余數 if pad: # 當我們的輸入值大于 8 或小于的時候 補 0 pad是true的時候進行補充 0 padded=bin_str[-remain:].ljust(8,'0') #ljust() 函數就是用來填充的 他對于字符串會自動進行左排序 然后根據第一個參數 進行右邊填充ascii_str+=chr(int(padded,2)) #對填充的模式加到ascii 總和之后else:# 不補0 直接轉換ascii_str+=chr(int(bin_str[-remain:],2))return ascii_str #return的 模式寫的必須是這個地方 否則如果 str是正常的8的倍數就無法返回改的地方 :pad 是是否開啟補0模式
remain 有余數表示是對于? lens 是需要補充的 因為他是向下取整? 不論是大于8的位數還是小于 對于 8的向下取整而言 都是需要進行補充的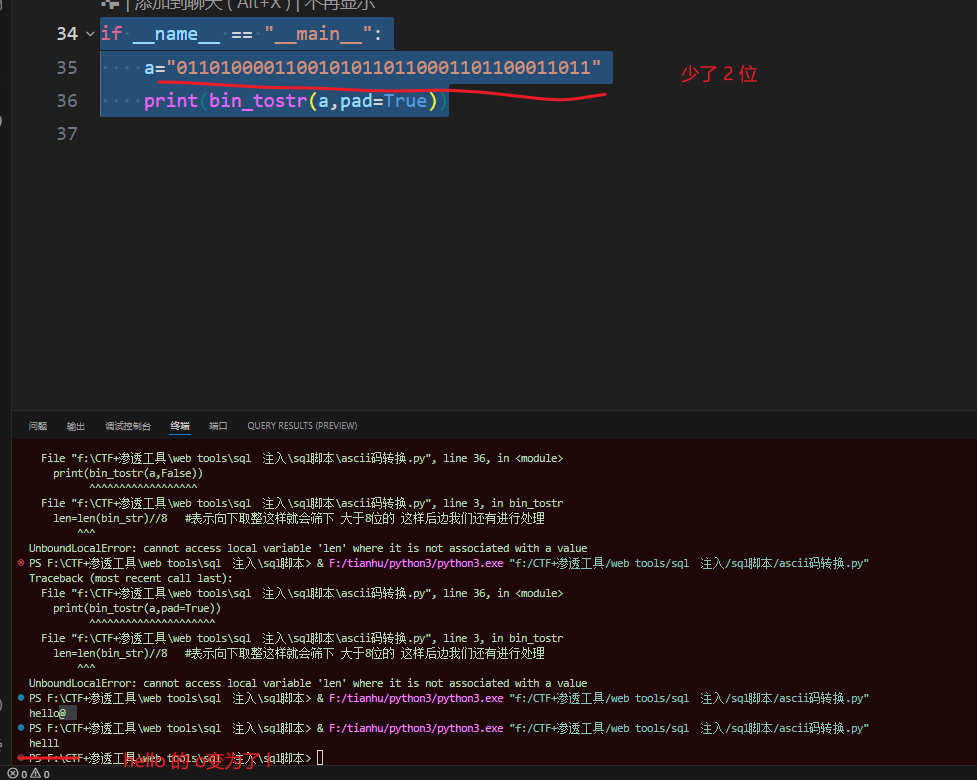
練習是試著把 補 3位的 8進制也進行一下 補充
)




)




)



)
)

)

![[Java實戰]Spring Boot 靜態資源配置(十三)](http://pic.xiahunao.cn/[Java實戰]Spring Boot 靜態資源配置(十三))