學習講義Day14安排的內容:SHAP圖的繪制
SHAP模型的基本概念
參考學習的帖子:SHAP 可視化解釋機器學習模型簡介_shap圖-CSDN博客
以下為學習該篇帖子的理解記錄:
Q. 什么是SHAP模型?它與機器學習模型的區別在哪兒?
機器學習模型仿若一個黑盒子,我們只能看到輸入和輸出,但至于“輸入到輸出之間發生了什么”我們是不知道的。這里讓我聯想到語言學家喬姆斯基在語言習得中提到的Black Box,可以與之關聯理解。SHAP模型就可以讓我們清楚地看到從輸入到輸出之間到底發生了什么(已知條件對最終預測結果起到了哪些影響,是正向還是負向)。
Q. SHAP的工作原理是什么?
帖子中寫到“SHAP是一種模型事后解釋的方法”。這里的“模型事后解釋”指的是SHAP是在模型訓練后,通過分析模型的行為來解釋其預測的結果。比如:為什么模型會預測某個客戶會違約?哪些特征對這個預測起了關鍵作用?
SHAP模型的工作原理就是計算特征對模型輸出的邊際貢獻。
? ? ? ? ? Q. 什么是“邊際貢獻”?

SHAP模型從全局和局部對“黑盒模型”進行解釋,并構建了一個“加性的解釋模型”。所有的特征都被視為“貢獻者”(這樣的話,我們就可以量化每個特征的作用。SHAP方法也確保了特征貢獻的分配是公平的,即每個特征的貢獻值是基于所有可能特征組合的平均邊際貢獻計算的)。
? ? ? ? ?Q. 如何理解“全局和局部”?什么是“加性的解釋模型”?



Q. SHAP可以解決哪些實際的問題?
模型調試,指導特征工程,指導數據采集,指導做決策,以及建立模型與人之間的信任。
Q. 為什么會生成shap_values數組?
截圖自講義文件


代碼實現
首先還是運行預處理好的代碼
# 先運行之前預處理好的代碼
import pandas as pd
import pandas as pd #用于數據處理和分析,可處理表格數據。
import numpy as np #用于數值計算,提供了高效的數組操作。
import matplotlib.pyplot as plt #用于繪制各種類型的圖表
import seaborn as sns #基于matplotlib的高級繪圖庫,能繪制更美觀的統計圖形。
import warnings
warnings.filterwarnings("ignore")# 設置中文字體(解決中文顯示問題)
plt.rcParams['font.sans-serif'] = ['SimHei'] # Windows系統常用黑體字體
plt.rcParams['axes.unicode_minus'] = False # 正常顯示負號
data = pd.read_csv('data.csv') #讀取數據# 先篩選字符串變量
discrete_features = data.select_dtypes(include=['object']).columns.tolist()
# Home Ownership 標簽編碼
home_ownership_mapping = {'Own Home': 1,'Rent': 2,'Have Mortgage': 3,'Home Mortgage': 4
}
data['Home Ownership'] = data['Home Ownership'].map(home_ownership_mapping)# Years in current job 標簽編碼
years_in_job_mapping = {'< 1 year': 1,'1 year': 2,'2 years': 3,'3 years': 4,'4 years': 5,'5 years': 6,'6 years': 7,'7 years': 8,'8 years': 9,'9 years': 10,'10+ years': 11
}
data['Years in current job'] = data['Years in current job'].map(years_in_job_mapping)# Purpose 獨熱編碼,記得需要將bool類型轉換為數值
data = pd.get_dummies(data, columns=['Purpose'])
data2 = pd.read_csv("data.csv") # 重新讀取數據,用來做列名對比
list_final = [] # 新建一個空列表,用于存放獨熱編碼后新增的特征名
for i in data.columns:if i not in data2.columns:list_final.append(i) # 這里打印出來的就是獨熱編碼后的特征名
for i in list_final:data[i] = data[i].astype(int) # 這里的i就是獨熱編碼后的特征名# Term 0 - 1 映射
term_mapping = {'Short Term': 0,'Long Term': 1
}
data['Term'] = data['Term'].map(term_mapping)
data.rename(columns={'Term': 'Long Term'}, inplace=True) # 重命名列
continuous_features = data.select_dtypes(include=['int64', 'float64']).columns.tolist() #把篩選出來的列名轉換成列表# 連續特征用中位數補全
for feature in continuous_features: mode_value = data[feature].mode()[0] #獲取該列的眾數。data[feature].fillna(mode_value, inplace=True) #用眾數填充該列的缺失值,inplace=True表示直接在原數據上修改。# 最開始也說了 很多調參函數自帶交叉驗證,甚至是必選的參數,你如果想要不交叉反而實現起來會麻煩很多
# 所以這里我們還是只劃分一次數據集
from sklearn.model_selection import train_test_split
X = data.drop(['Credit Default'], axis=1) # 特征,axis=1表示按列刪除
y = data['Credit Default'] # 標簽
# 按照8:2劃分訓練集和測試集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42) # 80%訓練集,20%測試集基準模型
from sklearn.ensemble import RandomForestClassifier #隨機森林分類器from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score # 用于評估分類器性能的指標
from sklearn.metrics import classification_report, confusion_matrix #用于生成分類報告和混淆矩陣
import warnings #用于忽略警告信息
warnings.filterwarnings("ignore") # 忽略所有警告信息
# --- 1. 默認參數的隨機森林 ---
# 評估基準模型,這里確實不需要驗證集
print("--- 1. 默認參數隨機森林 (訓練集 -> 測試集) ---")
import time # 這里介紹一個新的庫,time庫,主要用于時間相關的操作,因為調參需要很長時間,記錄下會幫助后人知道大概的時長
start_time = time.time() # 記錄開始時間
rf_model = RandomForestClassifier(random_state=42)
rf_model.fit(X_train, y_train) # 在訓練集上訓練
rf_pred = rf_model.predict(X_test) # 在測試集上預測
end_time = time.time() # 記錄結束時間print(f"訓練與預測耗時: {end_time - start_time:.4f} 秒")
print("\n默認隨機森林 在測試集上的分類報告:")
print(classification_report(y_test, rf_pred))
print("默認隨機森林 在測試集上的混淆矩陣:")
print(confusion_matrix(y_test, rf_pred))SHAP模型的代碼實現
import shap
import matplotlib.pyplot as plt# 初始化 SHAP 解釋器
explainer = shap.TreeExplainer(rf_model)# 計算 SHAP 值(基于測試集),這個shap_values是一個numpy數組,表示每個特征對每個樣本的貢獻值
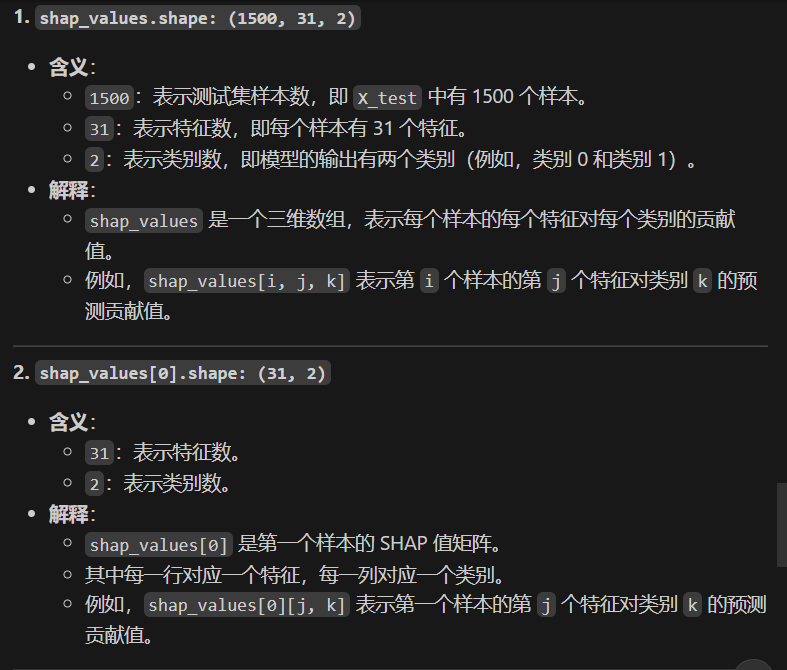
shap_values = explainer.shap_values(X_test) shap_values # 每一行代表一個樣本,每一列代表一個特征,值表示該特征對該樣本的預測結果的影響程度。正值表示該特征對預測結果有正向影響,負值表示負向影響。輸出:
array([[[ 9.07465700e-03, -9.07465700e-03],[ 7.21456498e-03, -7.21456498e-03],[ 4.55189444e-02, -4.55189444e-02],...,[ 7.12857198e-05, -7.12857198e-05],[ 4.67733508e-05, -4.67733508e-05],[ 1.61298135e-04, -1.61298135e-04]],[[-1.02606871e-02, 1.02606871e-02],[ 1.85572634e-02, -1.85572634e-02],[-1.64992848e-02, 1.64992848e-02],...,[ 2.00070852e-04, -2.00070852e-04],[ 5.11798841e-05, -5.11798841e-05],[ 1.02827796e-04, -1.02827796e-04]],[[ 3.21529115e-03, -3.21529115e-03],[ 1.28184070e-02, -1.28184070e-02],[ 1.02124914e-01, -1.02124914e-01],...,[ 1.73012306e-04, -1.73012306e-04],[ 4.74133256e-05, -4.74133256e-05],[ 1.26753231e-04, -1.26753231e-04]],...,[[ 1.15222741e-03, -1.15222741e-03],[-1.71843266e-02, 1.71843266e-02],[-3.04994337e-02, 3.04994337e-02],...,[ 1.44859329e-04, -1.44859329e-04],[ 1.80111014e-05, -1.80111014e-05],[ 1.30107512e-04, -1.30107512e-04]],[[ 1.29249120e-03, -1.29249120e-03],[ 5.66948438e-03, -5.66948438e-03],[ 2.49050264e-02, -2.49050264e-02],...,[ 2.50590715e-06, -2.50590715e-06],[ 4.68839113e-05, -4.68839113e-05],[ 1.15002997e-05, -1.15002997e-05]],[[-1.12640555e-03, 1.12640555e-03],[ 1.42648293e-02, -1.42648293e-02],[ 4.74790019e-02, -4.74790019e-02],...,[ 6.19451775e-05, -6.19451775e-05],[ 3.30996384e-05, -3.30996384e-05],[ 4.45219920e-05, -4.45219920e-05]]])shap_values.shape # 第一維是樣本數,第二維是特征數,第三維是類別數輸出:(1500,31,2)
print("shap_values shape:", shap_values.shape)
print("shap_values[0] shape:", shap_values[0].shape)
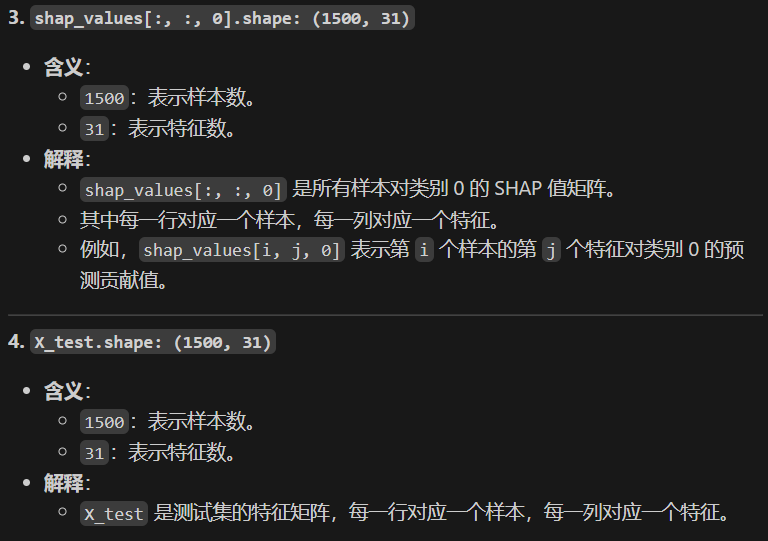
print("shap_values[:, :, 0] shape:", shap_values[:, :, 0].shape)
print("X_test shape:", X_test.shape)輸出:
shap_values shape: (1500, 31, 2)
shap_values[0] shape: (31, 2)
shap_values[:, :, 0] shape: (1500, 31)
X_test shape: (1500, 31)現在對這個輸出結果通過AI進行理解學習:

今日學習到這里。明日繼續這部分SHAP圖繪制的學習。加油!!!@浙大疏錦行



)
:Secret高級使用模式與安全實踐指南)






)
)





_監視屬性、深度監視、監視的簡寫形式)
