有沒有花 20 分鐘瀏覽您的文件夾以找到心中的特定圖像或屏幕截圖?您并不孤單。
作為工作中的產品經理,我總是淹沒在競爭對手產品的屏幕截圖、UI 靈感以及白板會議或草圖的照片的海洋中。在我的個人生活中,我總是捕捉我在生活中遇到的事物,比如我的晚餐、我可愛的貓,或者秋天隨機的美麗樹葉。我太了解這種掙扎了。有時很難找到一張你知道自己保存在某個地方的特定圖像。
隨著開源視覺語言模型 Llama 3.2 Vision 的發布,我想出了一個解決這個問題的方法:一個在本地運行的 AI 工具,它可以自動描述和標記圖像,以便于語義搜索,同時保持照片和標簽完全在本地(并且 API 費用為零)
在本文中,我將介紹如何構建 AI 圖像標記器/管理器,包括設置和運行本地視覺語言模型和矢量數據庫以進行語義搜索。無論您是對運行本地視覺語言模型感到好奇的 AI 愛好者,還是只是厭倦了在圖像文件夾中痛苦搜索的人,這對您來說都是一個有趣且有用的項目。讓我們開始吧!
(此項目在?https://github.com/Troyanovsky/llama-vision-image-tagger?上開源。隨意克隆并試用!
查看實際作
前端對于管理圖像集合相對簡單。它使用 Vue3 構建以實現交互性,并使用 TailwindCSS 構建用于樣式。它通過 FastAPI 服務器與后端通信,該服務器在視覺模型、矢量數據庫和文件系統之間進行協調。讓我們看看它是如何工作的。
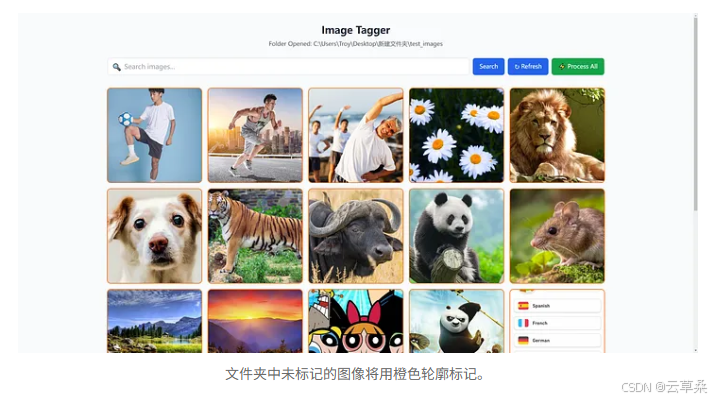
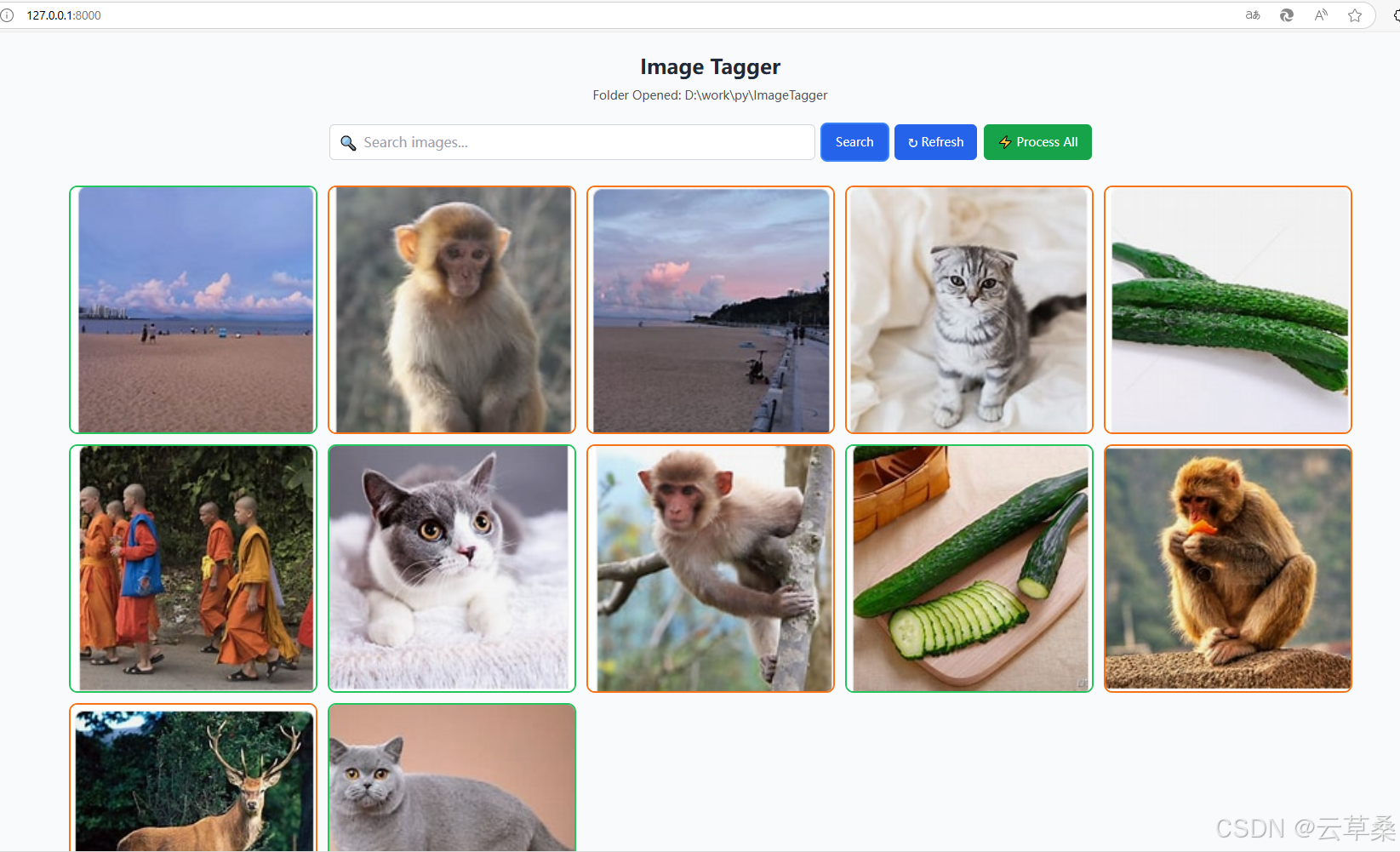
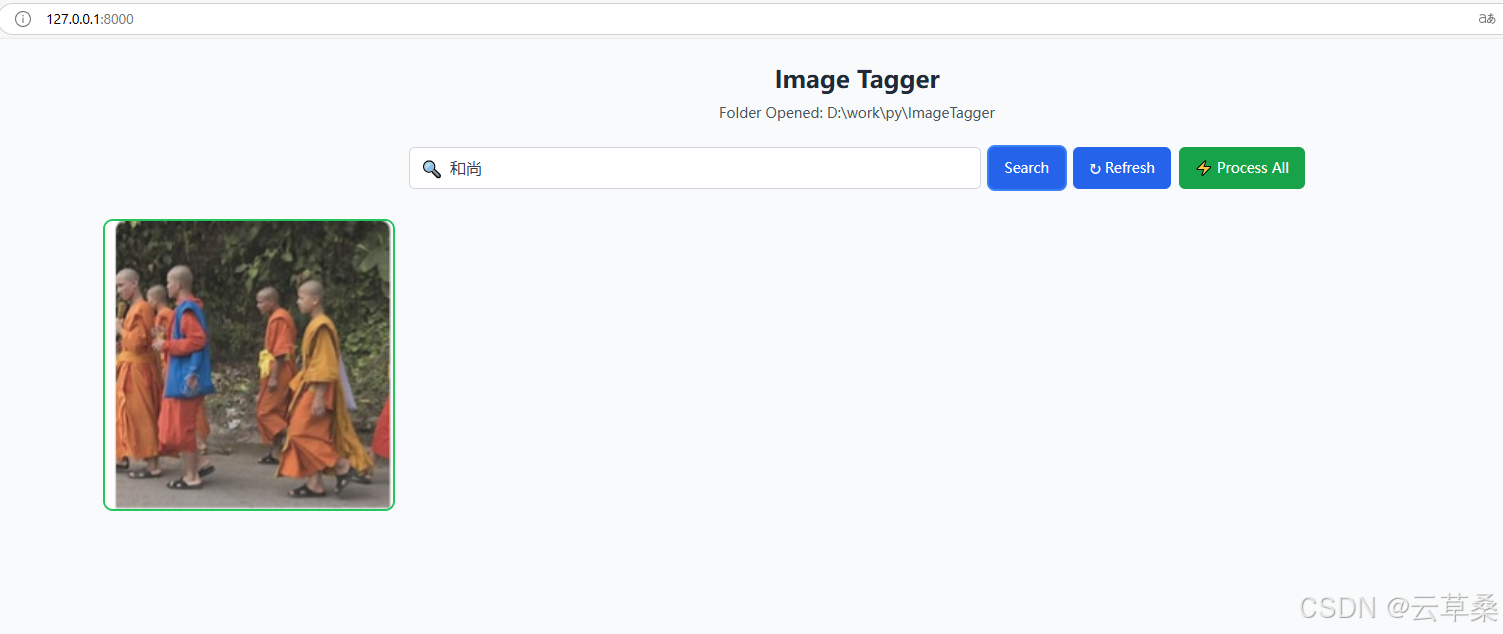
文件夾中未標記的圖像將用橙色輪廓標記。
當它啟動時,它會要求您提供一個包含您的圖像的文件夾。只需復制并粘貼文件夾路徑,它就會開始掃描文件夾和子文件夾中的圖像。第一次打開文件夾時,它還會初始化一個 vector database 來存儲數據,這可能需要一段時間。
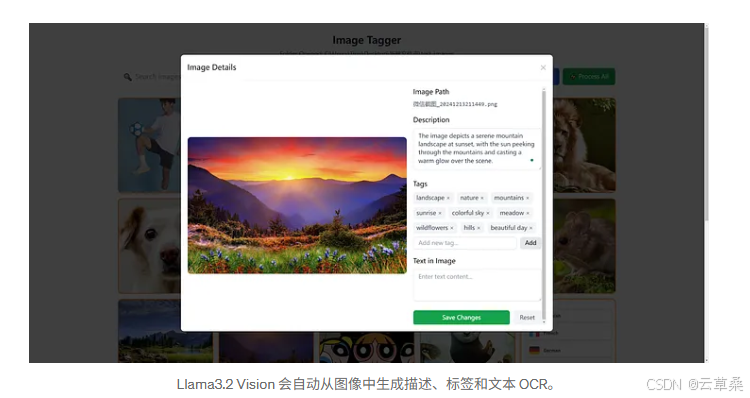
Llama3.2 Vision 會自動從圖像中生成描述、標簽和文本 OCR。
加載圖像后,您可以單擊單個圖像以開始標記。它將向本地后端服務器發送請求并為映像生成標簽。如果您對結果不滿意,還可以手動編輯結果。所有生成/編輯的標簽都將同步到矢量數據庫
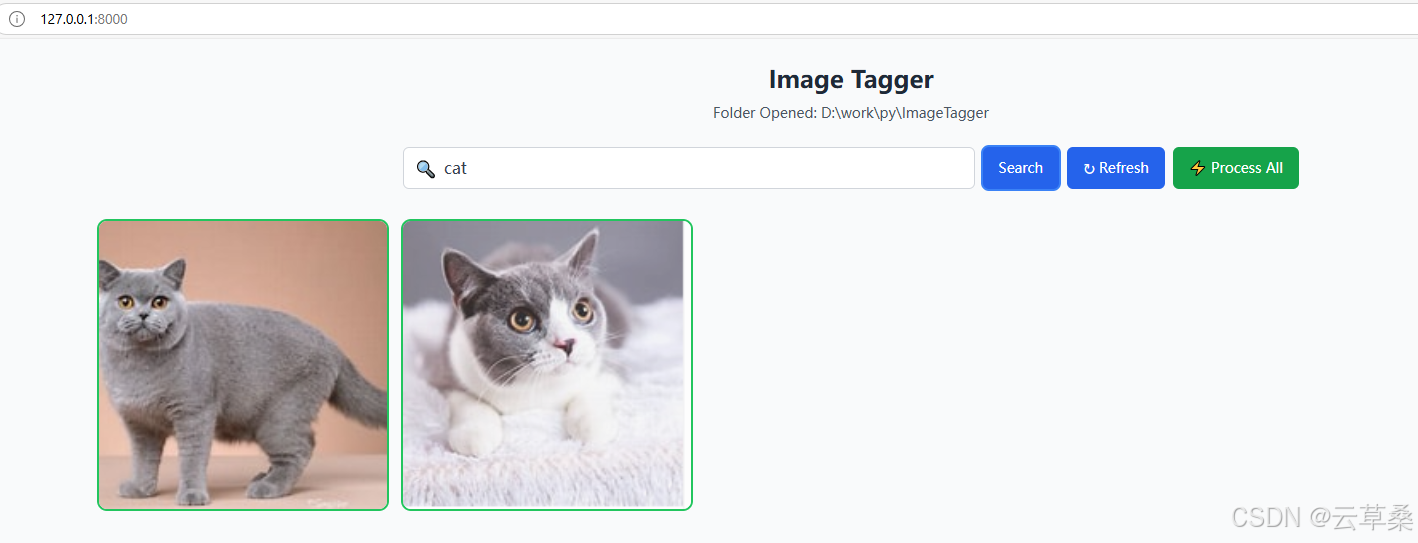
對于批處理,您只需按此 全部處理 按鈕,它將發送所有圖像進行處理。速度取決于您的計算機。如果您的 GPU 具有足夠的 VRAM 來運行模型,則比在具有 RAM 的 CPU 上運行要快得多。已處理的圖像將具有綠色輪廓,而尚未處理的圖像將以橙色顯示。
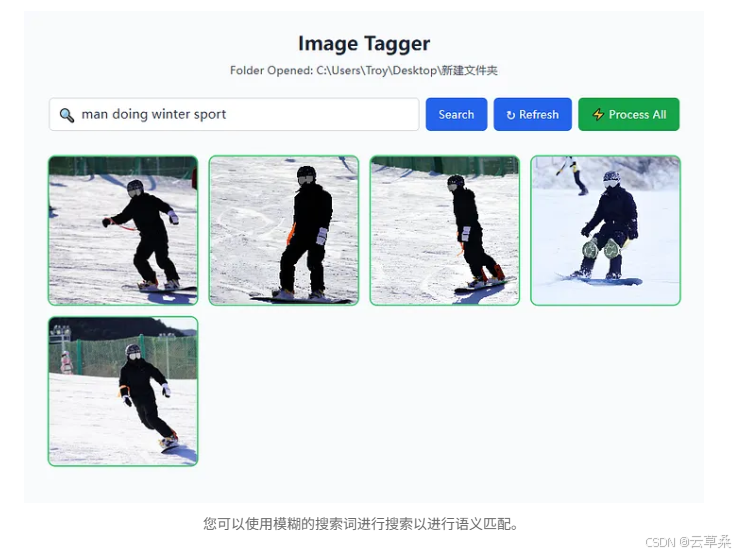
您可以使用模糊的搜索詞進行搜索以進行語義匹配。
處理和標記圖像后,您只需在搜索欄中鍵入要搜索的內容即可。它將執行包含全文搜索和向量相似性搜索的混合搜索。在這里,我們可以搜索帶有模糊描述“man doing winter sport”的單板滑雪圖片。
了解堆棧
在這個項目中,我們使用了 Llama 3.2 Vision、Ollama 和 ChromaDB。對于那些還不熟悉它們的人,讓我快速概述一下。
Llama 3.2 Vision?是 Meta 幾個月前于 2024 年 9 月發布的視覺語言模型 (VLM)。它有兩種不同的尺寸,11B 和 90B。11B 版本可以在消費級計算機上本地運行。作為 VLM,它不僅可以像大型語言模型 (LLM) 一樣理解文本,還可以理解上下文中的圖像。它可以描述場景,理解對象之間的關系,并根據您的指示根據圖像生成文本。在這個模型的幫助下,我們可以生成豐富的語義標簽,而不僅僅是簡單的對象檢測。
Ollama?是一個開源項目,它使我們能夠在本地計算機上輕松運行語言模型。它可在 Windows、MacOS 和 Linux 上使用,并支持幾乎所有 GGUF 格式的本地語言模型,這使其成為在您自己的計算機上運行本地模型的最方便的選擇。它還提供 Python 和 JavaScript 中的綁定,以便您可以在代碼中以編程方式調用模型。更棒的是,它最近增加了對生成結構化輸出(如 JSON)的支持,從而可以更輕松地處理文本生成。
(如果您對運行本地 LLM 感興趣,可以閱讀本文或訪問此 GitHub 存儲庫,其中提供了有關如何運行本地 LLM 的資源,并為許多 LLM 提供了易于嘗試的 Web UI。
至于我們的語義搜索,我們將使用?ChromaDB。這是一個開源矢量數據庫,允許您保存文本嵌入數據,并使用自然語言以閃電般的速度查詢它們。例如,您可以使用 “water sport”、“aquatics” 或 “snorkeling” ,而不必使用 “swimming” 等確切的關鍵字進行搜索。像 ChromaDB 這樣的向量數據庫通過將我們的圖像描述轉換為捕獲語義含義并計算嵌入之間的相似性的高維向量來實現這一點。
現在您已經了解了此項目的組件,在下一節中,我們將深入探討這些組件如何協同工作以創建我們的圖像標記和搜索系統。
深入研究代碼
讓我們分解一下這些組件如何協同工作來創建我們的圖像管理系統。由于在瀏覽器中訪問文件系統的限制,我將應用程序分為前端和后端。前端用于查看和管理圖片,后端主要包含兩個流水線:圖片標注流水線和圖片查詢流水線。
使用 Ollama 和 Llama3.2 Vision 的圖像標記管道
選擇文件夾后,我們將在該文件夾中掃描該文件夾中的所有圖像。然后用戶可以選擇一個圖像進行標記或標記所有圖像。它本質上是具有結構化輸出的簡單提示工程。讓我們引導您了解如何在您自己的本地計算機上使用 Ollama 運行 Llama 3.2 Vision 模型。
首先,您需要在您的機器上安裝 Ollama。感謝出色的 Ollama 團隊,他們為 Windows、MacOS 和 Linux 提供輕松下載 (https://ollama.com/download)。只需下載并安裝可執行文件,您就可以使用 Ollama 命令行。然后,您可以使用以下命令下載 Llama3.2 Vision:
OLLAMA Run LLAMA3.2-vision如果你有一臺非常強大的機器,你可以使用 OLLAMA Run LLAMA3.2-vision:90B 來獲得更大的版本拉取模型后,您可以通過命令行或 Python 庫使用它。在我們的項目中,我們將使用 ollama-python 庫,您可以使用以下方法安裝該庫:
pip install ollama安裝后,我們可以使用 Python 與模型進行交互。Ollama 最近增加了對結構化輸出 (JSON) 的支持,因此我們可以使用 Pydantic 定義一個 JSON 模式,以傳遞給模型以進行類型安全和驗證。
import ollama
from pydantic import BaseModel
from pathlib import 路徑
from typing import List, Dictclass ImageTags(BaseModel):tags: List[str]def process_image(image_path: Path) -> Dict:try:# 如果不存在,請確保圖像路徑存在image_path exists():raise FileNotFoundError(f“Image not found: {image_path}”)# 將圖像路徑轉換為 Ollama的字符串 image_path_str = str(image_path)# 獲取標簽tags_response = get_tags(image_path_str)return {“tags”: tags_response.tags}except Exception as e:raisedef get_tags(image_path: str) -> ImageTags:“”“獲取圖像的結構化標簽。response = query_ollama(“列出此圖像的 5-10 個相關標簽。包括兩個對象、藝術風格、圖像類型、顏色等“,
image_path,ImageTags.model_json_schema
())返回 ImageTags.model_validate_json(響應)在這里,我只展示了get_tags函數來獲取標簽列表,但也可以添加其他數據,如描述、圖像中的對象、圖像上的 OCR 文本等。您只需為每個提示編寫不同的提示,然后調用 Ollama,類似于調用 OpenAI 的 API 的方式。
def query_ollama(prompt: str, image_path: str, format_schema: dict) -> str:“”“向 Ollama 發送帶有結構化輸出圖像的查詢。try:response = ollama.chat(model='llama3.2-vision',messages=[{'角色': '用戶','內容': 提示符,'images': [image_path],'options': {'num_gpu': 41}}],format=format_schema)return response['message']['content']except Exception as e:raise通過類似的設置,您可以在自己的計算機上使用 Ollama 輕松運行其他 LLM 或視覺語言模型。您可以在 Ollama 模型庫 (library) 中找到可用模型的列表。
具有向量數據庫的語義查詢管道
標記所有圖像后,我們可以保存它以便于查詢。對于全文搜索,我們可以簡單地將數據保存到 JSON 或關系數據庫。但是,如果只有全文搜索,仍然很難找到相關的圖像——有時您可能只是對您想要的圖像有一個模糊的概念,而不是確切的標簽,例如,您可能記得您有一張吃一頓豐盛晚餐的照片,但您不記得確切的菜肴。因此,我們將標簽和描述保存到向量數據庫中,并通過可以捕獲語義含義的嵌入的相似性搜索來檢索它們。
ChromaDB 易于設置,您可以完全離線運行。我們的向量存儲實現的核心是 VectorStore 類。它處理與 ChromaDB 的所有交互,包括添加新圖像、更新現有圖像和執行語義搜索。
設置數據并將其保存到 ChromaDB 非常簡單:
def add_or_update_image(self, image_path: str, metadata: Dict) -> None:# 合并所有文本字段進行嵌入text_to_embed = f“{metadata.get('description', '')} {' '.join(metadata.get('tags', []))} {metadata.get('text_content', '')}”# 準備元數據字典 - ChromaDB 需要字符串值meta_dict = {“description”: metadata.get(“description”, “”),“tags”: “,”.join(metadata.get(“tags”, [])),“text_content”: metadata.get(“text_content”, “”),“is_processed”: str(metadata.get(“is_processed“, False))}# 檢查文檔是否存在并相應地更新或添加results = self.collection.get(ids=[image_path])if results and results['ids']:self.collection.update(ids=[image_path],documents=[text_to_embed],metadatas=[meta_dict])否則:self.collection.add(ids=[image_path],documents=[text_to_embed],metadatas=[meta_dict])在這個函數中,我們做了一些重要的事情:
- 將所有文本字段(描述、標記、文本內容)合并為一個字符串以進行嵌入
- 將元數據轉換為 ChromaDB 可以存儲的格式(所有值都必須是字符串)
- 如果不在數據庫中,則添加圖像數據,如果圖像數據已存在,則更新圖像數據
現在我們已經存儲了數據,讓我們看看我們如何搜索它。ChromaDB 提供了簡單的方法來查詢數據庫:
def search_images(self, query: str, limit: int = 5) -> List[str]:results = self.collection.query(query_texts=[query],n_results=limit,include=['documents', 'metadatas', 'distances'])filtered_results = []for image_id, distance in zip(results['ids'][0], results['distances'][0]):如果距離< 1.1: # 僅包含高置信度匹配項filtered_results.append(image_id)return filtered_results[:limit]ChromaDB 在后臺使用相同的嵌入模型將您的搜索查詢和存儲的圖像描述轉換為高維向量。然后,它會根據相似性查找最接近的匹配項。這意味著搜索“beach vacation”可能會匹配帶有“tropical paradise”或“seaside resort”標簽的圖片,即使您的查詢中沒有這些確切的字詞。我還添加了對最大距離的檢查,以便過濾掉不真正相關的結果。
通過結合全文搜索和矢量搜索的混合搜索方法,如果我們對全文搜索有把握,我們可以確保準確找到我們想要的內容,并在不太確定時找到相關圖像。
這是后端的兩個主要組件,用于處理圖像標記和語義查詢。通過了解它們的工作原理,您還將學習如何使用 Ollama 在本地計算機上運行多模態視覺語言模型(或任何 LLM),以及如何設置向量數據庫并使用 ChromaDB 等向量數據庫對文本進行語義查詢。這些對于許多其他基于 LLM 的本地項目非常有用。
一些進一步的改進
當前版本只是初始版本,非常適合我個人用于查找屏幕截圖和個人照片。有很多方法可以改進它:
- 圖像相似性搜索:用戶不僅可以按文本搜索,還可以選擇圖像并找到視覺上相似的圖像。但遺憾的是,Ollama 目前不支持多模態嵌入。我們可以使用其他嵌入模型(如 CLIP)并將嵌入保存到 ChromaDB。
- 可自定義的標記:目前,標記提示在代碼中是硬編碼的,但我們可以允許更靈活的方法來定義提示,以便不同的用戶可以擁有符合他們需求的不同標簽。例如,UI 設計人員可能希望專門標記界面元素,而攝影師可能更關心構圖和光照。
- 更強大的視覺模型:我發現較小的 11B 版本的 llama 3.2 視覺有時會誤解圖像。幸運的是,模型公司不斷推出新的開源模型,例如 Qwen 最近發布的 QvQ 模型。我們可以允許交換視覺模型,以便對圖像進行更準確和詳細的標記。
- 允許 Vision Model API。對于那些不太關心將圖像發送到模型提供商的人,我們可以允許他們使用視覺語言模型的 API,以便更快地進行標記過程(Gemini、Qwen、OpenAI 等)。
結論:釋放局部視覺模型的潛力
這個項目最讓我興奮的不僅僅是為自己解決了圖像搜索問題,還在于開源多模態 AI 模型的可訪問性。就像本地大型語言模型允許我們創建完全在本地機器上運行的基于文本的有趣應用程序一樣,視覺語言模型開辟了更多的可能性。
這只是本地視覺語言模型可能性的一個示例。相同的基本組件:使用 Ollama + 向量數據庫運行本地模型可以適應更多用例。
如果你一直對構建 AI 驅動的應用程序感到好奇,但擔心復雜性、隱私或 API 成本,我希望這個項目向你展示它比你想象的要平易近人得多。請隨意提取代碼來試用它,或者更好的是,為這個項目做出貢獻。您還可以對其進行修改,讓它成為您自己項目的起點。
命令備注
Uvicorn 使用方法
bash
pip install uvicorn
在開始之前,你需要確保你的開發環境中安裝了 Python 3.7 或更高版本。你還需要安裝 FastAPI 和 Uvicorn。可以通過以下命令安裝:
bash
pip install fastapi uvicorn安裝ChromaDB
要安裝ChromaDB,你需要先安裝Python 3.6或更高版本,然后用pip命令安裝chromadb包:
pip install chromadbChromaDB python 使用教程及記錄 - 知乎
mark bei
小編實測? 基本上是英文 對中文不友好
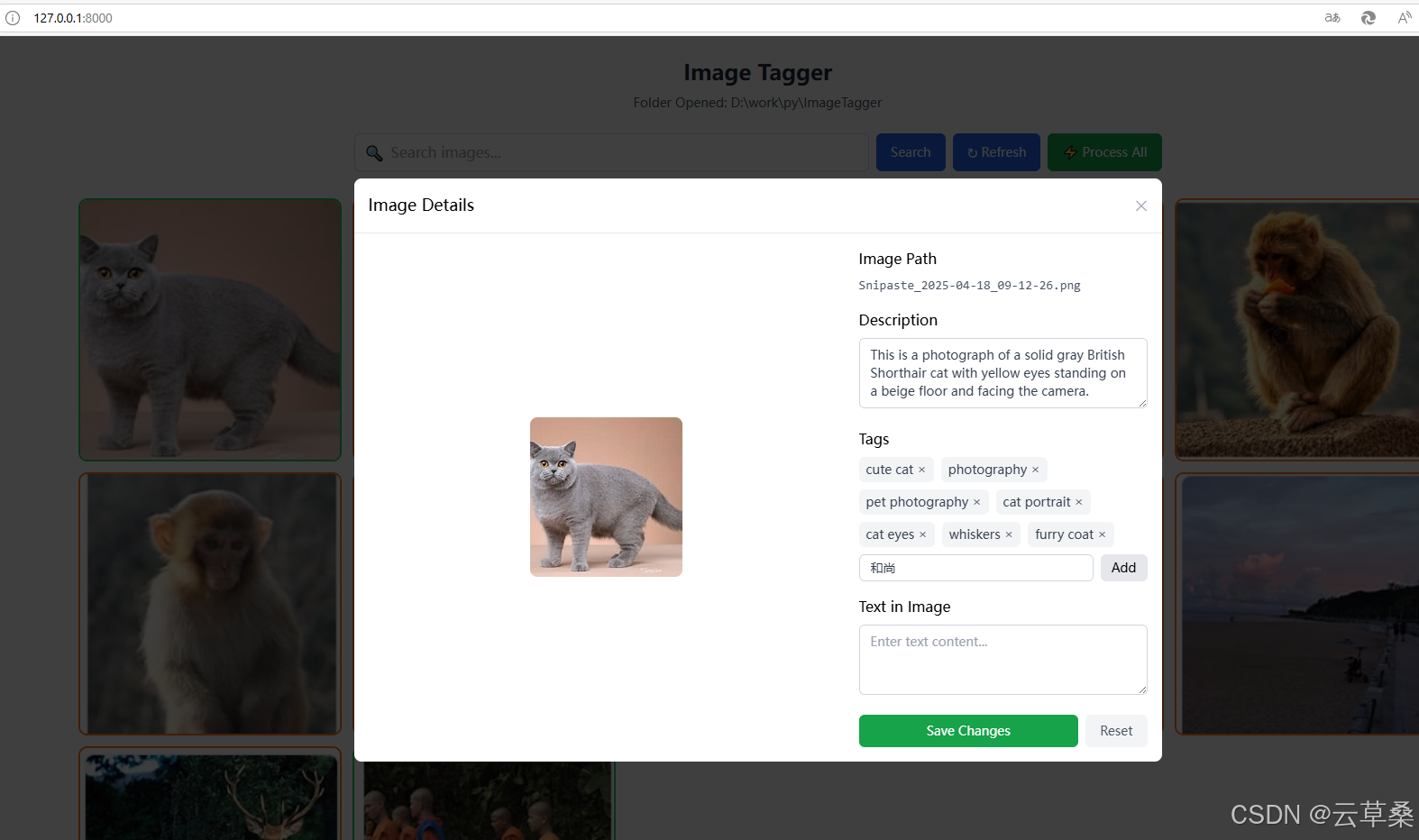
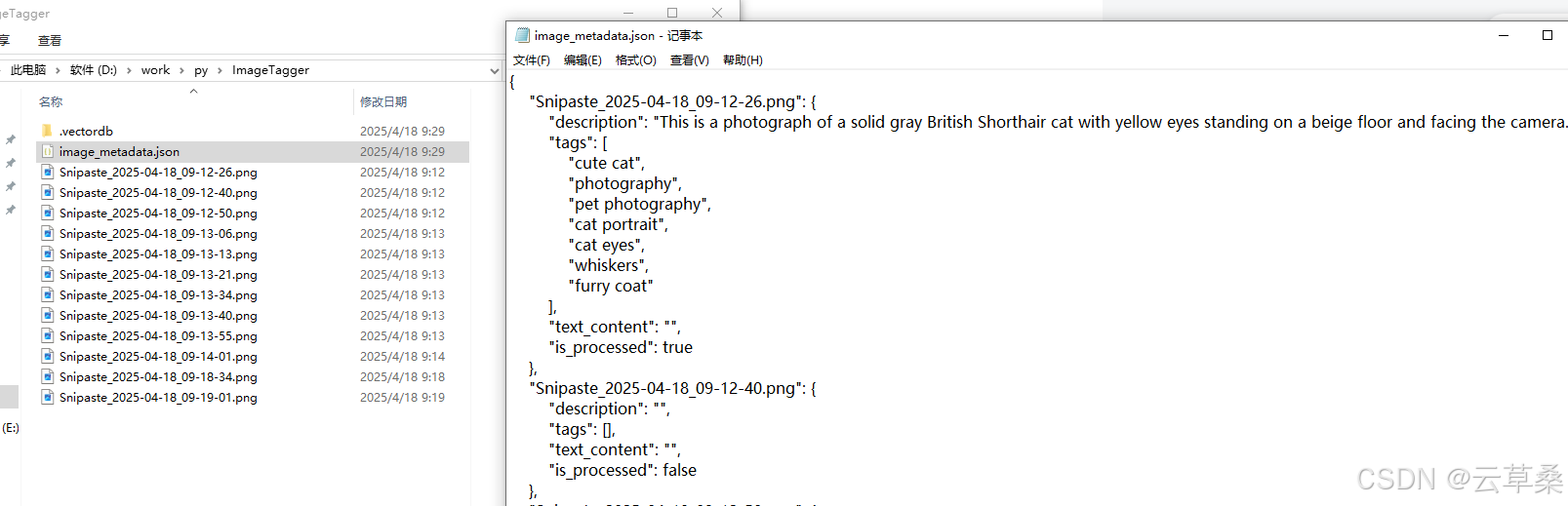
這是AI自己加的tag?
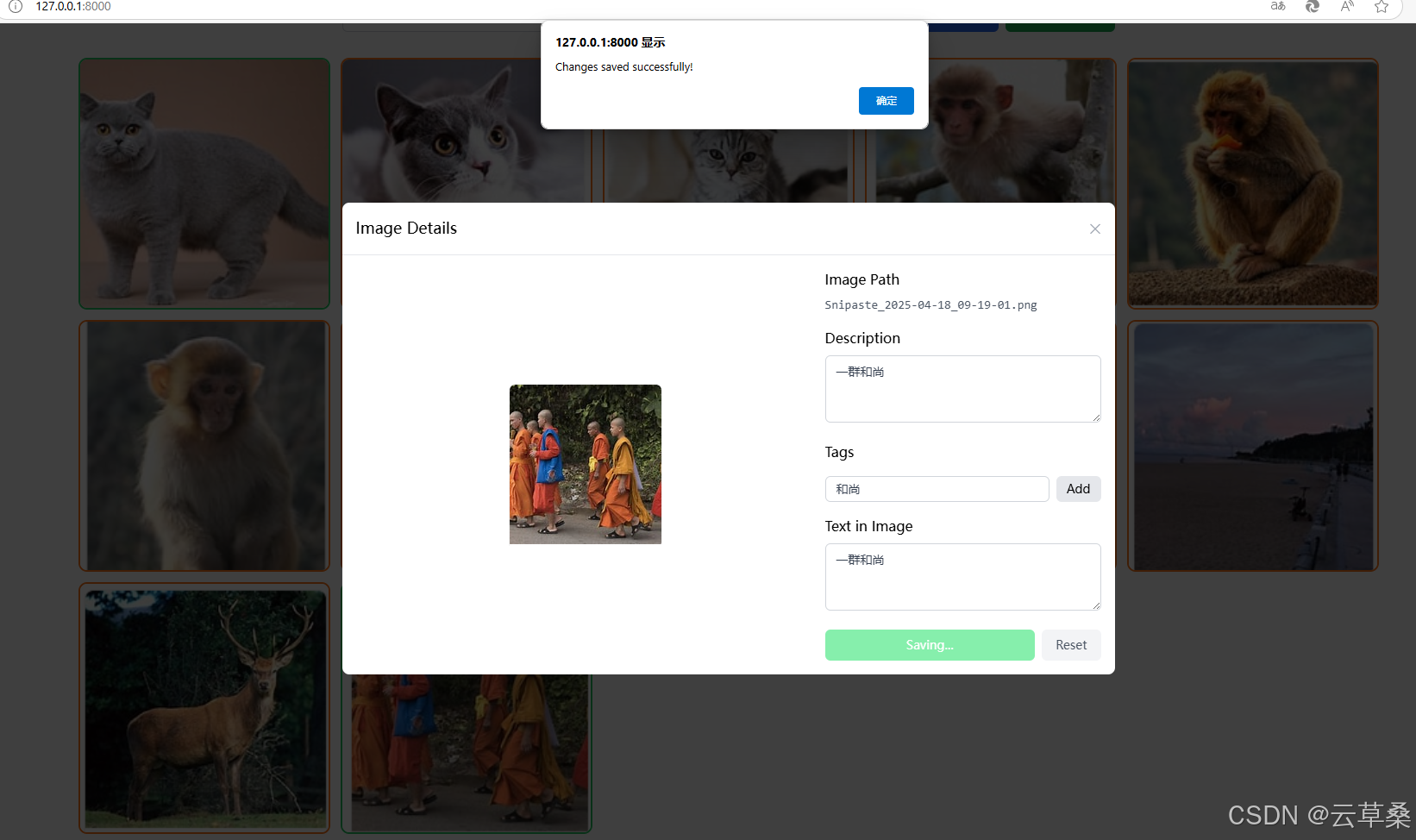
{"Snipaste_2025-04-18_09-12-26.png": {"description": "This is a photograph of a solid gray British Shorthair cat with yellow eyes standing on a beige floor and facing the camera.","tags": ["cute cat","photography","pet photography","cat portrait","cat eyes","whiskers","furry coat"],"text_content": "","is_processed": true},"Snipaste_2025-04-18_09-12-40.png": {"description": "The image shows a close-up of the head and upper body of what appears to be a British Shorthair cat lying down on a white fur blanket. The cat has orange eyes, a gray face with white markings around its nose and mouth, and a white body.","tags": ["cat","animal","fur","white","gray","close-up","portrait","pet","feline","photography","indoor","studio","lighting"],"text_content": "","is_processed": true},"Snipaste_2025-04-18_09-12-50.png": {"description": "","tags": [],"text_content": "","is_processed": false},"Snipaste_2025-04-18_09-13-06.png": {"description": "","tags": [],"text_content": "","is_processed": false},"Snipaste_2025-04-18_09-13-13.png": {"description": "","tags": [],"text_content": "","is_processed": false},"Snipaste_2025-04-18_09-13-21.png": {"description": "","tags": [],"text_content": "","is_processed": false},"Snipaste_2025-04-18_09-13-34.png": {"description": "","tags": [],"text_content": "","is_processed": false},"Snipaste_2025-04-18_09-13-40.png": {"description": "The image depicts a partially sliced cucumber on a light-colored cutting board. A basket of additional cucumbers sits above it to the left, while a partial view of another cucumber is visible behind the cutting board.","tags": ["food","cucumber","cutting board","kitchen","photography","still life","vegetable","slicing","raw food","healthy eating","cooking","ingredients"],"text_content": "","is_processed": true},"Snipaste_2025-04-18_09-13-55.png": {"description": "The photo is a low-resolution image of a sandy beach and body of water, with white clouds on the horizon.","tags": ["beach","ocean","clouds","sky","water","sand","people","blue"],"text_content": "","is_processed": true},"Snipaste_2025-04-18_09-14-01.png": {"description": "","tags": [],"text_content": "","is_processed": false},"Snipaste_2025-04-18_09-18-34.png": {"description": "","tags": [],"text_content": "","is_processed": false},"Snipaste_2025-04-18_09-19-01.png": {"description": "\u4e00\u7fa4\u548c\u5c1a","tags": [],"text_content": "\u4e00\u7fa4\u548c\u5c1a","is_processed": true}
}缺點 識別處理的很慢 很容易卡死有可能是慢 不能識別為中文的
不支持高版本的Python
------------
C# WPF 圖像處理 使用
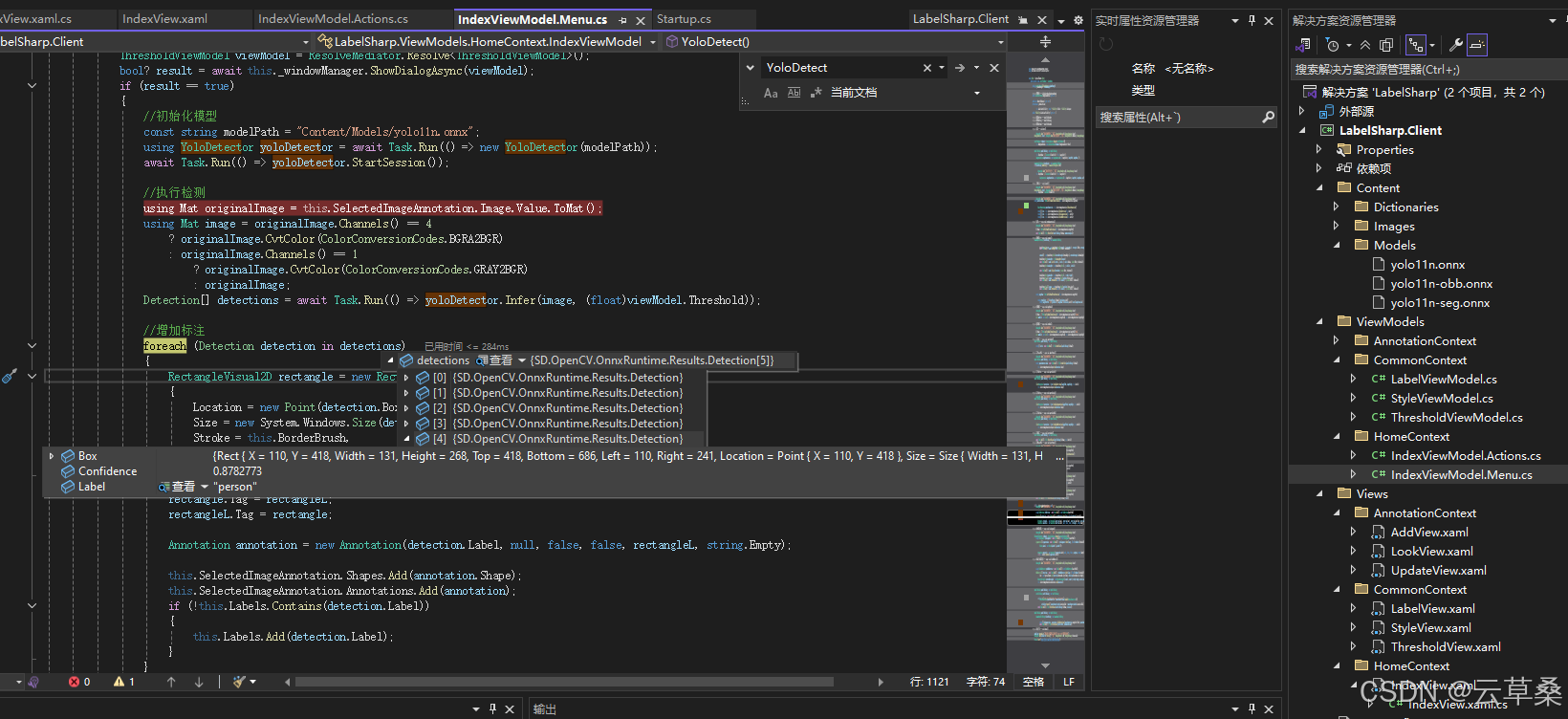
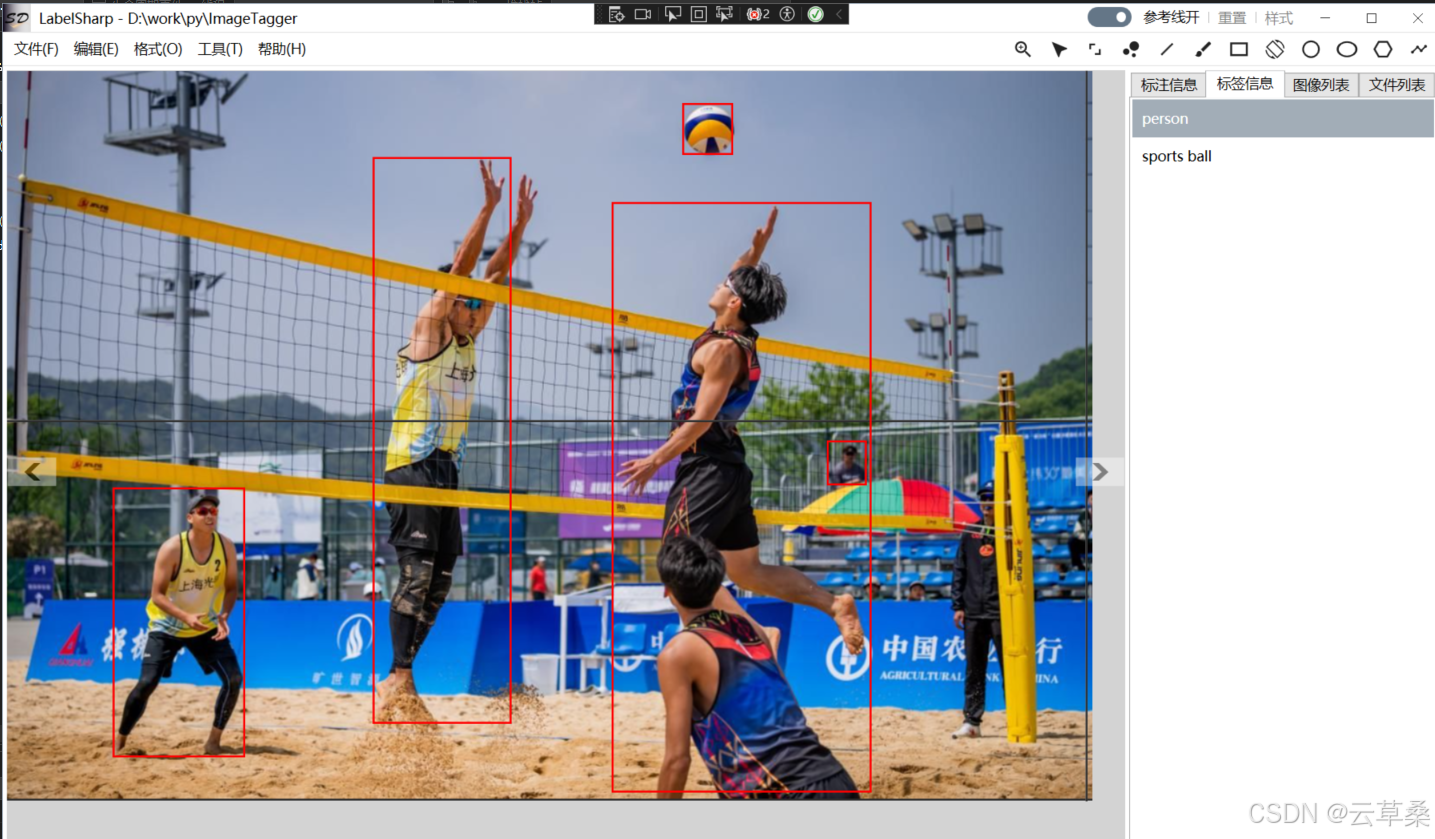
LabelSharp: 深度學習計算機視覺標注工具/PascalVOC/YOLO
?GPL-2.0
YOLO11 旋轉目標檢測 | OBB定向檢測 | ONNX模型推理 | 旋轉NMS_yolo11 obb-CSDN博客
yolo11n.onnx模型
YOLO(You Only Look Once)系列模型是目標檢測領域的經典算法,由 Joseph Redmon 等人首次提出,后續經過多次迭代,目前官方最新版本為?YOLOv8(2023 年發布,由 Ultralytics 公司維護)。以下是 YOLO 系列的核心版本梳理及最新進展:
一、YOLO 系列核心版本回顧
1.?YOLOv1(2016)
- 特點:首次提出端到端單階段目標檢測框架,將目標檢測視為回歸問題,直接輸出目標的位置和類別,速度極快(45 FPS),但精度較低,小目標檢測效果差。
- 缺點:定位誤差大,召回率低,依賴手工特征提取。
2.?YOLOv2(2017)
- 改進:引入?錨框(Anchor Boxes)、批歸一化(Batch Normalization)、高分辨率訓練(HRNet),使用?Darknet-19?作為骨干網絡,精度和速度均有提升(mAP 28.2,67 FPS)。
- 創新:提出?K-means 錨框聚類?和?跨階段特征融合(Feature Fusion)。
3.?YOLOv3(2018)
- 核心升級:采用?多尺度檢測(3 種尺度特征圖),支持不同大小目標檢測;使用?Darknet-53?骨干網絡,結合殘差連接(Residual Connections),平衡速度和精度(mAP 33,32 FPS)。
- 優勢:在保持實時性的同時,顯著提升小目標檢測能力。
4.?YOLOv4(2020)
- 優化:由 Alexey Bochkovskiy 團隊開發,引入大量優化技巧,如?Mish 激活函數、馬賽克數據增強(Mosaic Augmentation)、路徑聚合網絡(PAN)?等,精度大幅提升(mAP 43.5,65 FPS)。
- 特點:更適合工業級應用,對 GPU 算力要求較高。
5.?YOLOv5(2020 至今)
- 商業化:Ultralytics 公司推出,非官方但廣泛流行,基于 PyTorch 重構,代碼更簡潔靈活。
- 特性:支持?模型縮放(N/S/M/L/X 不同尺寸),適應不同算力設備;引入?Focus 結構、CSPNet(跨階段局部網絡),速度更快(YOLOv5s 在 COCO 上 26.2 mAP,140 FPS)。
- 生態:支持數據增強、模型導出(ONNX/TensorRT)、自定義訓練,社區活躍。
6.?YOLOv8(2023)
- 官方最新版本:Ultralytics 正式推出的首個官方 YOLO 版本(此前 v5 為非官方),支持?目標檢測、實例分割、分類、姿態估計?四大任務。
- 關鍵改進:
- 骨干網絡:使用?YOLO-NAS(基于神經架構搜索)?改進的骨干,引入?深度聚合網絡(Deep Aggregation Network, PAN++)。
- 損失函數:優化?CIoU Loss?和?分類損失,提升邊界框回歸精度。
- 效率:比 v5 更快更強,YOLOv8n 在 COCO 上實現 50.1 mAP(640×640),推理速度 170 FPS(RTX 3090)。
- 部署:支持多平臺(CPU/GPU/Edge),導出格式豐富(ONNX/TensorRT/OpenVINO 等)。
三、YOLO 系列核心優勢與應用場景
-
優勢:
- 速度快:單階段檢測框架,適合實時應用(如視頻監控、自動駕駛)。
- 易用性:端到端訓練,支持自定義數據集,部署流程成熟。
- 多任務支持:v8 版本擴展到實例分割和姿態估計,適用場景更廣泛。
-
典型應用:
- 安防領域:實時目標檢測與跟蹤。
- 智能交通:車輛、行人檢測與違章識別。
- 工業質檢:產品缺陷檢測與分揀。
- 無人機 / 機器人:環境感知與避障。
 ?
?
-----------
阿里云通用圖像打標
通用圖像打標常用語言和示例有哪些_視覺智能開放平臺(VIAPI)-阿里云幫助中心
如何創建AccessKey_視覺智能開放平臺(VIAPI)-阿里云幫助中心
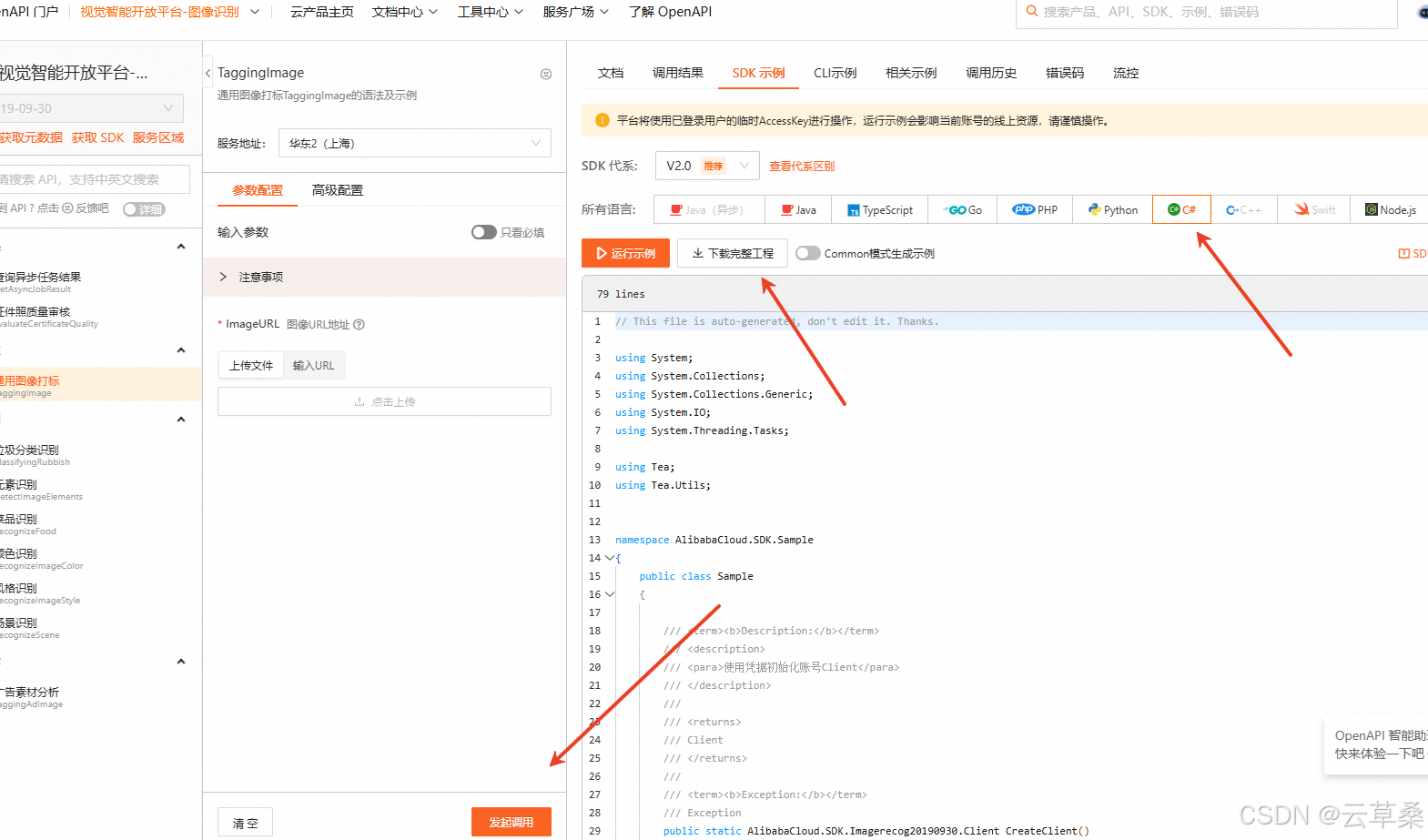
TaggingImage_視覺智能開放平臺-圖像識別_API調試-阿里云OpenAPI開發者門戶
通用圖像打標常用語言和示例有哪些_視覺智能開放平臺(VIAPI)-阿里云幫助中心
這個SKD 文檔找了好久 丟如何下載安裝、使用視覺智能開放平臺C#SDK及代碼示例_視覺智能開放平臺(VIAPI)-阿里云幫助中心
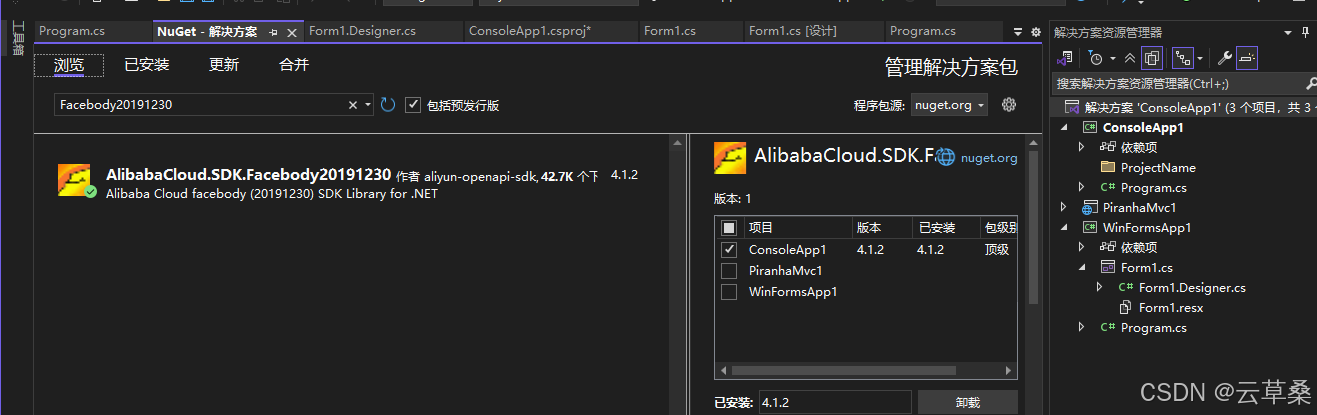
代碼和圖像打標結果
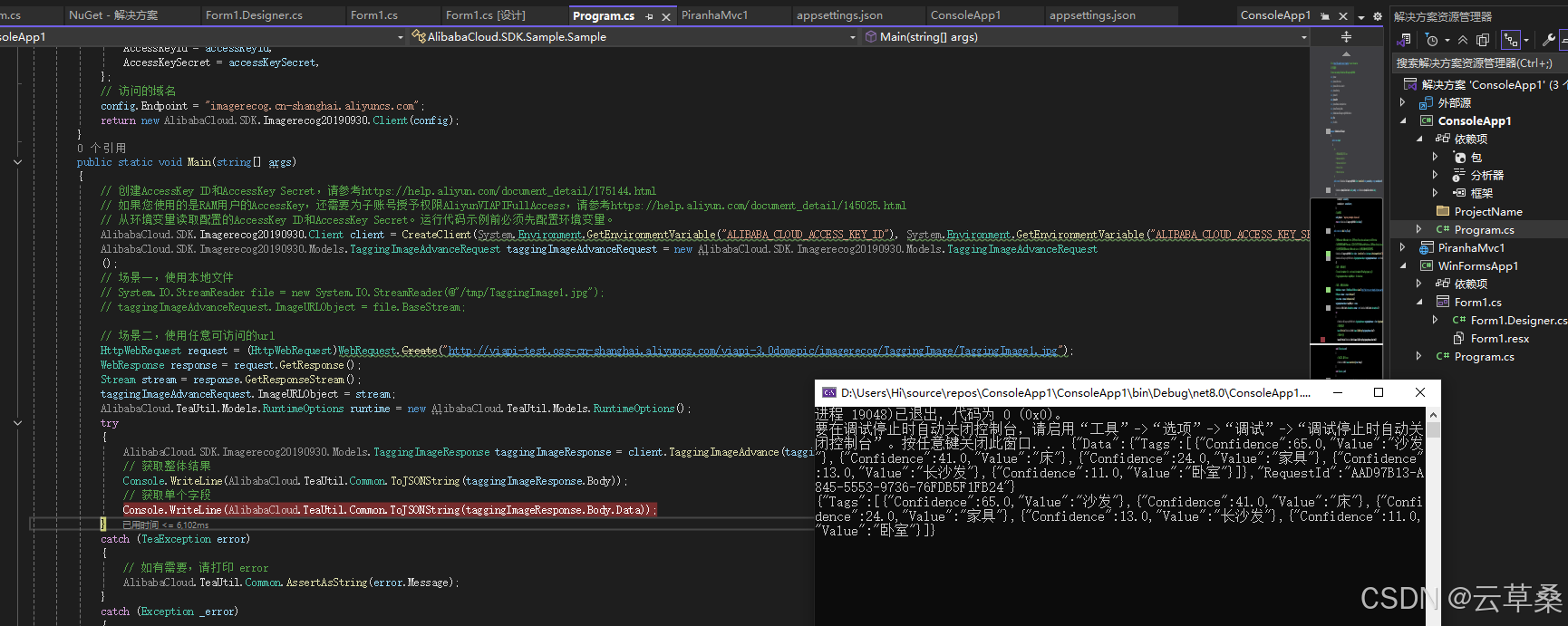 ?
?









)
(ArkTs))
(lv_label,lv_btn))
)

)

![[創業之路-377]:企業法務 - 有限責任公司與股份有限公司的優缺點對比](http://pic.xiahunao.cn/[創業之路-377]:企業法務 - 有限責任公司與股份有限公司的優缺點對比)
)

