1. 執行摘要
挑戰: 傳統數據倉庫在處理現代數據需求時面臨諸多限制,包括高昂的存儲和計算成本、處理海量多樣化數據的能力不足、以及數據從產生到可供分析的端到端延遲過高。同時,雖然數據湖提供了低成本、靈活的存儲,但往往缺乏數據可靠性、治理能力和查詢性能,導致所謂的"數據沼澤"問題。這種兩層架構(數據湖 + 數據倉庫)導致了數據冗余、架構復雜和運維成本增加。
解決方案: 湖倉一體(Lakehouse)架構應運而生,旨在結合數據湖的靈活性、可擴展性和成本效益,以及數據倉庫的數據管理、可靠性和性能優勢。這種新范式建立在低成本的云對象存儲之上,通過引入開放表格式(如 Delta Lake 和 Apache Iceberg)來為數據湖帶來可靠性和高性能。
關鍵賦能技術: Delta Lake 和 Apache Iceberg 等開源表格式是實現湖倉一體的核心。它們直接在數據湖存儲(如 Parquet 文件)之上提供 ACID 事務、模式演進、時間旅行和并發控制等關鍵功能,確保數據湖的可靠性和可管理性,使其能夠支持傳統數倉的分析負載。
核心優勢: 本報告將詳細闡述基于 Delta Lake 或 Iceberg 構建湖倉一體平臺的核心優勢:
- 顯著降低延遲: 通過支持實時或近實時數據寫入,并允許直接在湖上進行高性能查詢和處理,極大地縮短了數據分析的端到端時間。
- 大幅降低成本: 利用廉價的云對象存儲和開放表格式,替代昂貴的專有數倉存儲和計算資源,同時簡化架構,減少數據冗余和 ETL 成本。
- 統一分析平臺: 在單一數據副本上支持多樣化的分析工作負載,包括BI報表、SQL 分析、數據科學和機器學習。
文章路線圖: 本文將深入探討 Delta Lake 和 Iceberg 的核心特性,闡述湖倉一體架構的概念與優勢,研究實時數據攝入和湖上數據處理的技術與模式,分析其在降低延遲和成本方面的效益,總結構建此類平臺的關鍵組件和技術棧,并探討與下游分析工具的集成實踐。
2. 基石:為可靠數據湖設計的開放表格式
引言: 傳統數據湖雖然提供了低成本、大容量的存儲能力,但其核心問題在于缺乏對存儲文件的有效管理機制。直接操作 HDFS 或對象存儲上的原始文件(如 Parquet、ORC)難以保證數據的一致性、可靠性和查詢性能,這正是導致需要額外構建數據倉庫進行分析的主要原因。開放表格式(Open Table Formats, OTF)如 Delta Lake 和 Apache Iceberg 的出現,旨在解決這一核心痛點。它們在數據湖的原始文件之上增加了一個元數據層,帶來了事務管理、模式約束和性能優化等關鍵能力,使得直接在數據湖上構建可靠、高性能的分析平臺成為可能。
Delta Lake:
- 核心概念: Delta Lake 是一個開源存儲層,它通過在 Parquet 數據文件 基礎上增加一個基于文件的事務日志 (_delta_log),為數據湖帶來了 ACID 事務能力和可擴展的元數據處理。它與 Apache Spark API 完全兼容,并與 Spark Structured Streaming 緊密集成,使得批處理和流處理可以無縫地操作同一份數據副本。Delta Lake 最初由 Databricks 開發并持續貢獻。
-
ACID 事務: Delta Lake 實現 ACID 事務的核心在于其事務日志。該日志存儲在表目錄下的 _delta_log 子目錄中,由一系列按順序編號的 JSON 文件(記錄單次提交的原子操作,如添加/刪除文件、更新元數據)和定期的 Parquet 格式檢查點文件(Checkpoint,用于加速狀態重建)組成。
- 原子性 (Atomicity): 每個寫操作(如 INSERT, UPDATE, DELETE, MERGE)對應日志中的一個原子提交。操作要么完全成功記錄在日志中,要么失敗回滾,不會產生部分寫入的數據。
- 一致性 (Consistency): 事務日志是表狀態的唯一真實來源。任何讀取操作都會首先查詢日志以確定當前有效的表版本包含哪些數據文件,確保數據視圖的一致性。
- 隔離性 (Isolation): Delta Lake 采用樂觀并發控制(Optimistic Concurrency Control, OCC)。它允許多個寫入者并發操作,但在提交時進行沖突檢測。通過嘗試原子性地創建下一個序號的日志文件(利用某些對象存儲的 put-if-absent 操作或協調服務),只有一個寫入者能成功提交,從而實現寫入隔離。讀取操作通常基于日志中的某個快照版本進行,提供快照隔離。
- 持久性 (Durability): 數據文件(Parquet)和事務日志都存儲在可靠的云對象存儲中,確保所有已提交的更改都是持久的。 事務日志不僅是實現 ACID 的基礎,更是 Delta Lake 許多高級功能(如時間旅行、流處理集成)的核心機制。這種設計將可靠性保證與底層存儲分離,雖然與 Spark 的集成最為深入和優化,但其開放的日志協議 也允許其他系統(如 Presto, Trino, Hive)訪問 Delta 表,盡管可能功能或性能受限。
-
模式演進與強制: Delta Lake 允許用戶在不重寫現有數據的情況下演進表模式,例如添加新列或更改列類型。這些模式變更作為元數據更新記錄在事務日志中。寫入時,Delta Lake 會強制執行當前模式(Schema Enforcement),確保寫入數據符合表定義,防止臟數據污染。此外,通過列映射(Column Mapping),可以支持重命名或刪除列,而無需重寫數據文件,進一步增強了模式管理的靈活性。需要注意,某些高級功能可能依賴于特定的 Delta Lake 或 Databricks Runtime 版本,且與 Iceberg 不同,Delta Lake 文檔中未明確提及支持分區結構的演進(Partition Evolution)。這種無需重寫數據的模式演進能力,相比傳統數倉模式變更可能涉及的昂貴且耗時的操作,是一個顯著的運營優勢。
-
時間旅行 (數據版本控制): Delta Lake 的每次寫入操作都會創建一個新的表版本,這些版本信息被完整地記錄在事務日志中。用戶可以通過指定版本號或時間戳來查詢表的歷史快照,或者回滾到之前的某個狀態。這對于數據審計、錯誤恢復、復現實驗等場景非常有用。
-
并發控制: 如前所述,Delta Lake 使用樂觀并發控制。其基本流程是:記錄起始表版本 -> 記錄讀寫操作 -> 嘗試提交(原子性創建日志文件) -> 如果提交失敗(別人先提交),檢查讀取的數據是否發生沖突 -> 如果無沖突,則重試提交(通常只需更新版本號并重試日志寫入,無需重新處理數據)。這種機制在大多數并發寫入沖突不頻繁的場景下,避免了傳統悲觀鎖帶來的開銷。
-
其他特性: Delta Lake 還提供可擴展的元數據處理(利用 Spark 處理大規模表的元數據),統一的批處理和流處理接口,以及一系列性能優化手段,如數據跳過(Data Skipping,利用文件統計信息跳過不相關文件)、Z-Ordering(多維聚類優化查詢性能)、文件壓縮(Compaction)和清理(Vacuum)。同時,它原生支持 MERGE(Upsert)、UPDATE 和 DELETE 等 DML 操作。
Apache Iceberg:
- 核心概念: Apache Iceberg 是一個為大型分析數據集設計的開放表格式 。其設計目標之一是引擎互操作性,使得 Spark、Trino、Flink、Presto、Hive 等多種計算引擎可以安全地并發讀寫同一個 Iceberg 表。Iceberg 在數據文件(支持 Parquet, Avro, ORC 等格式)之上構建了一個元數據層,該層包含指向當前有效元數據文件的指針(存儲在 Catalog 中)、元數據文件(Metadata files,包含 schema、partition spec、snapshot 信息)、清單列表(Manifest lists,指向構成快照的清單文件)和清單文件(Manifest files,跟蹤數據文件及其統計信息)。Iceberg 最初由 Netflix 開發。
Apache Iceberg 示例代碼:
// 使用 Java API 創建 Iceberg 表并執行操作
import org.apache.iceberg.Table;
import org.apache.iceberg.catalog.TableIdentifier;
import org.apache.iceberg.spark.SparkCatalog;
import org.apache.iceberg.Schema;
import org.apache.iceberg.types.Types;// 定義模式
Schema schema = new Schema(Types.NestedField.required(1, "id", Types.LongType.get()),Types.NestedField.optional(2, "data", Types.StringType.get()),Types.NestedField.optional(3, "ts", Types.TimestampType.withZone())
);// 創建表
catalog.createTable(TableIdentifier.of("db", "sample"), schema);// 使用 Spark SQL 操作 Iceberg 表
spark.sql("INSERT INTO db.sample VALUES (1, 'a', current_timestamp())");// 時間旅行查詢
spark.sql("SELECT * FROM db.sample FOR VERSION AS OF 1");// 動態分區演進
spark.sql("ALTER TABLE db.sample REPLACE PARTITION FIELD ts WITH days(ts)");// 添加新列
spark.sql("ALTER TABLE db.sample ADD COLUMN new_col string");
- ACID 事務: Iceberg 通過在 Catalog 中原子性地更新指向最新元數據文件的指針來實現 ACID 事務。每個元數據文件定義了一個表的完整、一致的快照(snapshot)。當寫入完成時,會生成一個新的元數據文件,并通過 Catalog 的原子操作(如 compare-and-swap)將表的引用指向這個新文件。這確保了讀取操作總是看到一個一致的快照,并且寫入操作是原子性的。這種機制提供了快照隔離。Iceberg 對 Catalog 的依賴是其實現原子提交的關鍵,這與 Delta Lake 基于文件系統原子寫入日志文件的方式不同。這種基于 Catalog 的設計天然地促進了引擎的互操作性,因為不同的引擎可以通過標準的 Catalog API 與 Iceberg 表交互,而無需理解底層文件日志的細節。
- 模式演進: Iceberg 提供了全面的模式演進能力,支持添加、刪除、重命名列,更新列類型(拓寬),以及重排序列序。這些變更都僅僅是元數據操作,無需重寫任何數據文件。Iceberg 通過為每個列分配唯一的 ID 來實現這一點。即使列被重命名或其在文件中的物理位置改變,查詢引擎也能通過 ID 正確地找到并讀取數據。這種基于 ID 的跟蹤避免了基于名稱或位置跟蹤可能出現的副作用(如意外取消刪除列或因刪除列導致后續列名改變)。
- 分區演進與隱藏分區: Iceberg 的一個顯著特性是隱藏分區(Hidden Partitioning)。Iceberg 可以根據列值自動生成分區值(例如,將時間戳轉換為年月),而用戶在編寫查詢時無需了解底層分區結構,也無需在查詢中添加額外的分區過濾條件。Iceberg 會利用元數據中的分區信息自動進行分區裁剪。更進一步,Iceberg 支持分區演進(Partition Evolution)。當數據量或查詢模式發生變化時,可以更改表的分區策略(Partition Spec)。舊數據將保留其原始分區布局,新數據則按照新的分區策略寫入。查詢時,Iceberg 可以同時處理不同分區策略下的數據。這些變更同樣是元數據操作,無需重寫歷史數據。隱藏分區和分區演進的結合,為表的長期維護提供了極大的靈活性,能夠適應不斷變化的需求,避免了傳統分區方案(如 Hive 風格分區)僵化且難以修改的痛點。
- 時間旅行與回滾: Iceberg 通過維護歷史快照(由歷代元數據文件定義)來實現時間旅行。用戶可以查詢特定時間點或特定快照 ID 的數據。同時,可以輕松地將表回滾到之前的某個快照狀態,用于快速糾正錯誤。
- 并發控制: Iceberg 通常采用樂觀并發控制策略。并發寫入操作會各自準備新的元數據文件和數據文件。在提交時,它們會嘗試通過 Catalog 的原子操作(如對元數據指針的 compare-and-swap)來更新表的當前狀態。只有一個操作能夠成功,失敗的操作通常需要重試。
- 其他特性: Iceberg 支持豐富的 SQL DML 操作,包括 MERGE INTO, UPDATE, DELETE。它提供了內置的數據壓縮(Compaction)機制來優化文件大小和布局。支持多種底層數據文件格式(Parquet, Avro, ORC)23,并具有可擴展的元數據管理能力。
對比分析:Delta Lake vs. Apache Iceberg
為了幫助在具體場景下選擇合適的表格式,下表總結了 Delta Lake 和 Apache Iceberg 的關鍵特性對比:
| 特性 | Delta Lake | Apache Iceberg |
|---|---|---|
| ACID 實現 | 基于文件系統的事務日志 (_delta_log) | 基于 Catalog 原子更新元數據指針 |
| 主要文件格式 | Parquet | Parquet, Avro, ORC |
| 模式演進 | 支持(添加、更新類型、列映射支持重命名/刪除) | 全面支持(添加、刪除、重命名、更新類型、重排序),基于唯一列 ID |
| 分區演進 | 不直接支持3 | 支持,無需重寫數據 |
| 隱藏分區 | 不支持 | 支持 |
| 時間旅行 | 支持,基于事務日志版本 | 支持,基于快照(元數據文件) |
| 并發控制 | 樂觀并發控制(OCC),基于日志文件原子創建 | 樂觀并發控制(OCC),通常基于 Catalog 原子操作 |
| 元數據存儲 | 事務日志文件(JSON, Parquet Checkpoints) | 元數據文件、清單列表、清單文件 + Catalog |
| 主要生態系統 | 與 Apache Spark 和 Databricks 緊密集成 | 設計強調引擎互操作性(Spark, Flink, Trino, Presto 等) |
| 引擎兼容性 | Spark 最佳,提供與其他引擎的連接器 | 廣泛兼容多種查詢引擎 |
| 社區/治理 | 由 Linux 基金會托管,Databricks 是主要貢獻者 | Apache 軟件基金會頂級項目,社區驅動 |
討論:
選擇 Delta Lake 還是 Iceberg 取決于具體的應用場景和技術棧偏好。
- 如果組織深度使用 Apache Spark 和 Databricks 生態系統,Delta Lake 提供了無縫的集成和優化體驗。其基于文件日志的事務機制在 Spark 環境中表現良好。
- 如果需要與多種計算引擎(如 Flink, Trino/Presto)交互,或者希望避免供應商鎖定,Iceberg 的開放性和廣泛的引擎兼容性更具優勢。其基于 Catalog 的設計使得集成新引擎更為方便。
- 對于需要靈活調整分區策略以適應數據增長或查詢模式變化的場景,Iceberg 的分區演進能力是一個重要的加分項。
- Iceberg 對多種文件格式的原生支持提供了更大的靈活性。
- 近年來,兩者也在相互借鑒和融合。例如,Delta Lake 推出了 UniForm 功能,旨在生成 Iceberg 元數據以提高兼容性,但這通常是只讀兼容,并且可能存在元數據同步延遲和功能限制。
最終決策應綜合考慮現有技術棧、未來發展方向、團隊熟悉度以及對特定功能(如分區演進、多引擎寫入)的需求。
3. 湖倉一體范式:融合數據湖與數據倉庫
定義湖倉一體架構:
湖倉一體(Lakehouse)是一種現代數據管理架構,它旨在將數據湖的低成本、靈活性和可擴展性與數據倉庫的數據管理、可靠性和性能特性相結合。其核心思想是直接在數據湖(通常是云對象存儲)上實現傳統數據倉庫的功能,而不是維護兩個獨立的系統。這得益于開放數據格式(如 Parquet, ORC) 和開放表格式(如 Delta Lake, Apache Iceberg) 的發展,這些技術為存儲在數據湖中的數據帶來了結構、事務和治理能力。湖倉一體的目標是提供一個統一的平臺,支持從原始數據到結構化數據的全生命周期管理,并能同時服務于 BI、SQL 分析、數據科學和機器學習等多種分析工作負載。
架構對比:湖倉一體 vs. 傳統數據倉庫 vs. 數據湖
| 特性 | 傳統數據倉庫 (DW) | 傳統數據湖 (Data Lake) | 湖倉一體 (Lakehouse) |
|---|---|---|---|
| 主要用途 | BI報表, SQL 分析 | 原始數據存儲, 數據科學, ML | 統一平臺,支持 BI, SQL, DS, ML, Streaming |
| 支持數據類型 | 結構化數據為主 | 結構化, 半結構化, 非結構化 | 結構化, 半結構化, 非結構化 |
| 存儲成本 | 高 (通常使用專有存儲) | 低 (基于廉價對象存儲) | 低 (基于廉價對象存儲) |
| 數據可靠性/ACID | 支持 ACID 事務 | 通常不支持 ACID, 可靠性差 | 通過表格式 (Delta/Iceberg) 支持 ACID 事務 |
| 模式處理 | Schema-on-Write (寫入時強制模式) | Schema-on-Read (讀取時解釋模式) | 支持 Schema Enforcement 和 Evolution |
| BI 查詢性能 | 高 | 通常較差 | 通過表格式優化和查詢引擎可達高性能 |
| ML/AI 支持 | 有限, 通常需導出數據 | 良好, 可直接訪問原始/多樣化數據 | 良好, 可直接在統一數據上進行 ML/AI |
| 治理 | 強治理 | 治理困難, 易成數據沼澤 | 通過表格式和目錄服務實現改進的治理 |
| 靈活性 | 較低, 模式僵化 | 高 | 高, 支持多種數據類型和工作負載 |
| 關鍵技術 | 專有數據庫技術 (e.g., Teradata, Oracle Exadata), 云數倉 (Snowflake, Redshift, BigQuery) | HDFS, 云對象存儲 (S3, ADLS, GCS), 文件格式 (Parquet, ORC) | 云對象存儲 + 開放表格式 (Delta Lake, Iceberg) + 查詢引擎 (Spark, Trino, Flink) |
湖倉一體方法的關鍵優勢:
- 成本效益 (Cost-Effectiveness): 這是湖倉一體最核心的吸引力之一。通過將數據存儲在低成本的云對象存儲(如 AWS S3, Azure ADLS, Google Cloud Storage)上,并利用開源的表格式和計算引擎,可以顯著降低相比傳統數據倉庫所需的昂貴專有存儲和計算許可費用。同時,統一的架構減少了在數據湖和數據倉庫之間進行復雜且昂貴的 ETL 操作的需求,進一步節省了開發和運維成本。
- 可擴展性與靈活性 (Scalability & Flexibility): 湖倉一體架構天然支持存儲和計算資源的分離與獨立擴展。組織可以根據實際工作負載的需求,彈性地調整計算資源,而存儲可以近乎無限地擴展。它能夠原生處理結構化、半結構化和非結構化數據,滿足現代多樣化的數據分析需求。采用開放標準(如 Parquet, Delta, Iceberg)也避免了供應商鎖定,提供了更大的技術選型自由度。
- 簡化的架構與減少的數據冗余 (Simplified Architecture & Reduced Redundancy): 湖倉一體通過消除數據湖和數據倉庫這兩個獨立的層級,顯著簡化了數據架構。數據不再需要在多個系統之間復制和移動,從而減少了數據冗余和由此帶來的存儲成本及數據一致性問題。這有助于建立一個單一、可信的數據源。
- 改進的數據質量與可靠性 (Improved Data Quality & Reliability): 借助于 Delta Lake 或 Iceberg 提供的 ACID 事務能力,湖倉一體確保了對數據湖中數據的并發讀寫操作的原子性、一致性、隔離性和持久性。模式強制(Schema Enforcement)功能確保了寫入數據的質量和一致性。時間旅行功能則為數據審計和錯誤恢復提供了保障。
- 增強的治理能力 (Enhanced Governance): 雖然治理仍然是數據湖環境中的一個挑戰,但湖倉一體通過表格式提供的元數據管理、事務日志以及與數據目錄(如 AWS Glue Data Catalog, Project Nessie, Unity Catalog)的集成,使得實施數據訪問控制、審計跟蹤、數據血緣追蹤等治理措施更為容易。例如,表格式支持的 DML 操作(UPDATE, DELETE)使得滿足 GDPR 等合規性要求(如數據刪除權)變得可行。
- 統一的分析能力 (Unified Analytics): 湖倉一體的核心價值在于打破了傳統 BI/數倉和 AI/數據科學之間的壁壘。數據分析師、數據科學家和機器學習工程師可以在同一個數據副本上,使用各自偏好的工具(SQL, Python, R 等)和引擎(Trino, Spark, Flink 等)進行工作,無需移動或復制數據。
- 更快獲得洞察 (Faster Time-to-Insights): 數據的實時或近實時攝入,加上簡化的 ETL 流程和直接在湖上進行查詢的能力,顯著縮短了數據從產生到可用于分析和決策的時間。對流處理的原生支持進一步賦能了實時分析應用。
湖倉一體架構并非簡單地將數據湖和數據倉庫的功能疊加,它代表了一種向開放性和統一性的根本轉變。正是這種基于開放標準(開放文件格式、開放表格式、開放計算引擎)的統一架構,打破了過去由專有技術和數據孤島造成的壁壘,從而實現了前所未有的靈活性和成本效益。
4. 實現實時能力
引言: 傳統的數據倉庫通常依賴于周期性的批量 ETL 作業來加載數據,這導致數據分析的延遲往往以小時甚至天為單位。現代業務場景,如實時監控、欺詐檢測、個性化推薦等,對數據的時效性提出了更高的要求。湖倉一體架構結合流處理技術,能夠支持實時或近實時的數據攝入和處理,從而顯著降低端到端的數據延遲。
實時與近實時攝入技術:
將數據實時或近實時地攝入到基于 Delta Lake 或 Iceberg 的湖倉一體平臺中,常用的技術和模式包括:
- Apache Spark Structured Streaming:
- 概念: 這是 Apache Spark 提供的用于流處理的、可擴展且容錯的引擎。它以微批(Micro-batch)的方式處理流數據,提供了與 Spark SQL 和 DataFrame API 一致的編程模型。Spark Structured Streaming 與 Delta Lake 具有非常緊密的集成,同時也良好地支持 Iceberg。
- 從 Delta/Iceberg 讀取流: 可以將 Delta 表或 Iceberg 表配置為流式數據源。在讀取時,可以配置多種選項來控制流的行為:
- 速率限制: 通過 maxFilesPerTrigger(限制每個微批處理的新文件數)或 maxBytesPerTrigger(限制每個微批處理的數據量)來控制處理速率,平衡延遲和成本1。
- 處理源表變更 (Delta): 對于 Delta 源,可以使用 ignoreDeletes 忽略分區邊界的刪除,或使用 ignoreChanges 重新處理因 UPDATE, MERGE, DELETE 等操作導致文件重寫的更新(需要下游處理可能出現的重復數據)。
- 指定起始位置: 通過 startingVersion 或 startingTimestamp 選項,可以指定流處理從表的哪個歷史版本或時間點開始,而不是從頭處理整個表。startingVersion: “latest” 可用于僅處理最新變更。
- 處理初始快照順序 (Delta): 對于需要按事件時間處理的有狀態流(如帶水印的聚合),可以使用 withEventTimeOrder 選項確保初始快照數據按事件時間順序處理,避免晚到數據被錯誤丟棄。
- 向 Delta/Iceberg 寫入流: 可以將流數據寫入Delta或Iceberg表。支持兩種主要模式:
- Append Mode (默認): 僅將每個微批中新產生的數據追加到目標表中。
- Complete Mode: 將每個微批的完整輸出結果覆蓋寫入目標表,適用于流式聚合場景。 對于 Delta Lake,還可以使用 foreachBatch 結合 txnAppId 和 txnVersion 選項來實現冪等寫入,這在需要在一個微批內執行更復雜邏輯或寫入多個表的場景中非常有用。
- 示例 (Kafka 到 Delta): 一個常見的模式是從 Kafka 讀取 JSON 流,進行轉換,然后使用 trigger(availableNow=True) 將數據寫入 Delta 表。availableNow=True 觸發器會處理自上次觸發以來 Kafka 中所有可用的新數據,然后停止,這是一種近實時處理模式,相比連續流處理可以節省計算資源。代碼結構通常包括:使用 spark.readStream 讀取 Kafka 源 -> 定義 JSON 數據的 schema -> 使用 from_json 和其他 Spark SQL 函數進行數據轉換 -> 使用 writeStream 將轉換后的 DataFrame 寫入 Delta 表,并指定檢查點位置 (checkpointLocation)。
# Spark Structured Streaming:從Kafka讀取數據寫入Delta Lake示例
from pyspark.sql import SparkSession
from pyspark.sql.functions import from_json, col
from pyspark.sql.types import StructType, StructField, StringType, IntegerType, TimestampType# 創建SparkSession
spark = SparkSession.builder \.appName("Kafka to Delta") \.config("spark.sql.extensions", "io.delta.sql.DeltaSparkSessionExtension") \.config("spark.sql.catalog.spark_catalog", "org.apache.spark.sql.delta.catalog.DeltaCatalog") \.getOrCreate()# 定義JSON數據的Schema
schema = StructType([StructField("id", StringType(), True),StructField("timestamp", TimestampType(), True),StructField("user_id", StringType(), True),StructField("product_id", StringType(), True),StructField("quantity", IntegerType(), True),StructField("price", IntegerType(), True)
])# 從Kafka讀取流數據
df = spark.readStream \.format("kafka") \.option("kafka.bootstrap.servers", "broker1:9092,broker2:9092") \.option("subscribe", "orders") \.option("startingOffsets", "latest") \.load()# 解析JSON數據
parsed_df = df.select(from_json(col("value").cast("string"), schema).alias("data")
).select("data.*")# 寫入Delta表
query = parsed_df.writeStream \.format("delta") \.outputMode("append") \.option("checkpointLocation", "/path/to/checkpoint/dir") \.trigger(availableNow=True) \.start("/path/to/delta/table")query.awaitTermination()
- 示例 (Kafka 到 Iceberg): 類似地,可以使用 Spark Structured Streaming 將 Kafka 數據寫入 Iceberg 表。需要確保 Spark Session 配置了正確的 Iceberg 擴展和 JAR 包。流程包括:讀取 Kafka 流 -> 解析和轉換數據 -> 使用 writeStream 以 iceberg 格式寫入目標表,同樣需要指定檢查點位置。
# Spark Structured Streaming:從Kafka讀取數據寫入Iceberg表示例
from pyspark.sql import SparkSession
from pyspark.sql.functions import from_json, col
from pyspark.sql.types import StructType, StructField, StringType, IntegerType, TimestampType# 創建SparkSession,配置Iceberg支持
spark = SparkSession.builder \.appName("Kafka to Iceberg") \.config("spark.sql.extensions", "org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions") \.config("spark.sql.catalog.iceberg_catalog", "org.apache.iceberg.spark.SparkCatalog") \.config("spark.sql.catalog.iceberg_catalog.type", "hive") \.config("spark.sql.catalog.iceberg_catalog.warehouse", "s3a://bucket/warehouse") \.getOrCreate()# 定義JSON數據的Schema
schema = StructType([StructField("id", StringType(), True),StructField("timestamp", TimestampType(), True),StructField("user_id", StringType(), True),StructField("event_type", StringType(), True),StructField("data", StringType(), True)
])# 從Kafka讀取流數據
df = spark.readStream \.format("kafka") \.option("kafka.bootstrap.servers", "broker1:9092,broker2:9092") \.option("subscribe", "events") \.option("startingOffsets", "latest") \.load()# 解析JSON數據
parsed_df = df.select(from_json(col("value").cast("string"), schema).alias("data")
).select("data.*")# 寫入Iceberg表
query = parsed_df.writeStream \.format("iceberg") \.outputMode("append") \.option("path", "iceberg_catalog.db.events_table") \.option("checkpointLocation", "/path/to/checkpoint/dir") \.start()query.awaitTermination()
- Apache Flink:
- 概念: Flink 是一個業界領先的分布式流處理引擎,以其低延遲和強大的狀態管理能力而聞名,通常被認為是實現真正實時處理的首選框架。Flink 提供了對 Iceberg 的良好支持,并且也有針對 Delta Lake 的連接器。
- 集成模式:
- 直接寫入: Flink 作業可以直接將處理后的數據寫入 Delta Lake 或 Iceberg 表。
- 間接寫入 (通過 Kafka): 在某些對延遲要求極高或需要進一步解耦的場景下,Flink 作業可以將結果寫入 Kafka 等消息隊列,然后由另一個獨立的作業(如 Spark Streaming 或 Flink 作業)負責從 Kafka 讀取并寫入 Delta/Iceberg 表。
- 示例 (Flink SQL: Kafka 到 Iceberg): 使用 Flink SQL 可以簡潔地實現從 Kafka 到 Iceberg 的流式數據管道。首先,使用 CREATE TABLE 語句定義 Kafka 源表,指定連接器信息、Topic、服務器地址和數據格式 (如 JSON),并明確列名和數據類型。然后,同樣使用 CREATE TABLE 定義 Iceberg 目標表,指定 Iceberg 連接器、Catalog 類型(如 Hive, REST)、Catalog 名稱、倉庫路徑 (Warehouse Location) 等 Iceberg 特定屬性。最后,通過 INSERT INTO <iceberg_table> SELECT… FROM <kafka_table> 語句啟動一個持續運行的 Flink 作業,將數據從 Kafka 源源不斷地流向 Iceberg 表。在這個過程中,可以在 SELECT 語句中進行數據轉換和過濾。Flink 的檢查點機制(通過 SET ‘execution.checkpointing.interval’ =… 設置)確保了端到端的精確一次(exactly-once)語義。
-- Flink SQL:從Kafka讀取數據寫入Iceberg表示例-- 設置檢查點間隔為30秒,確保精確一次語義
SET 'execution.checkpointing.interval' = '30s';-- 創建Kafka源表
CREATE TABLE kafka_source (id STRING,timestamp TIMESTAMP(3),user_id STRING,event_type STRING,data STRING
) WITH ('connector' = 'kafka','topic' = 'events','properties.bootstrap.servers' = 'broker1:9092,broker2:9092','properties.group.id' = 'flink-iceberg-group','scan.startup.mode' = 'latest-offset','format' = 'json'
);-- 創建Iceberg目標表
CREATE TABLE iceberg_sink (id STRING,event_time TIMESTAMP(3),user_id STRING,event_type STRING,data STRING,processing_time TIMESTAMP(3)
) WITH ('connector' = 'iceberg','catalog-name' = 'hadoop_catalog','catalog-type' = 'hive','warehouse' = 's3a://bucket/warehouse','database-name' = 'events_db','table-name' = 'events_table'
);-- 啟動持續查詢,將數據從Kafka流向Iceberg
INSERT INTO iceberg_sink
SELECTid,timestamp AS event_time,user_id,event_type,data,CURRENT_TIMESTAMP AS processing_time
FROM kafka_source;
- Kafka Connect 及其他工具:
- Kafka Connect: 是 Apache Kafka 的一個組件,用于在 Kafka 與其他系統之間可靠地流式傳輸數據。社區提供了 Iceberg Sink Connector,可以將 Kafka Topic 中的數據直接寫入Iceberg表。這對于不需要復雜流式轉換的直接攝入場景是一個簡單高效的選擇。Kafka Connect 通常也支持精確一次語義和多表分發(multi-table fan-out)等特性。針對Delta Lake 的 Kafka Connect連接器也可能存在,但在此次研究材料中提及較少。
{"name": "iceberg-sink-connector","config": {"connector.class": "org.apache.iceberg.kafka.connect.IcebergSinkConnector","topics": "events","key.converter": "org.apache.kafka.connect.storage.StringConverter","value.converter": "org.apache.kafka.connect.json.JsonConverter","value.converter.schemas.enable": "false","catalog-name": "hadoop_catalog","catalog-impl": "org.apache.iceberg.hive.HiveCatalog","warehouse": "s3a://bucket/warehouse","database": "events_db","table": "events_table","flush.size": "100","flush.interval.ms": "60000"}
}
- 專用數據集成工具: 市場上也存在一些商業或開源的數據集成工具,如 Estuary Flow、Upsolver、Fivetran等,它們提供了可視化界面或更簡化的配置方式,用于將來自各種源(包括流式源)的數據攝入到 Delta Lake 或 Iceberg 表中。
- dbt: 雖然 dbt 本身不是流處理工具,但它可以與流式攝入結合使用。數據可以通過 Spark Streaming 或 Flink 實時攝入到湖倉的原始層(例如 Delta/Iceberg 表),然后 dbt 可以定期運行(例如通過 Airflow 調度),對這些表中新增的數據執行批處理式的轉換,構建下游的聚合或分析模型3。
流式攝入的最佳實踐:
| 最佳實踐 | 描述 | 示例/建議 |
|---|---|---|
| 模式管理 | 在流式攝入開始前定義好目標表的初始模式 | 使用Delta Lake的schemaTrackingLocation選項跟蹤模式變更 |
| 精確一次語義 | 確保端到端的精確一次處理 | 配置恰當的檢查點機制,使用事務性寫入 |
| 小文件問題與壓縮 | 處理流式寫入產生的小文件問題 | 定期執行OPTIMIZE命令壓縮小文件 |
| 延遲與成本權衡 | 根據需求平衡實時性和成本 | 低延遲場景使用Flink,近實時場景考慮Spark微批 |
| 處理更新與刪除 | 合理處理源數據的變更操作 | 使用Delta CDF或Iceberg的MERGE INTO語句 |
| 監控 | 建立完善的監控機制 | 跟蹤延遲、吞吐量、資源使用和失敗情況 |
將實時或近實時數據攝入湖倉一體平臺的核心挑戰在于,既要保證數據的時效性,又要維持表格式帶來的數據可靠性(ACID 事務、模式一致性)。選擇 Spark Streaming、Flink 還是 Kafka Connect,很大程度上取決于對延遲的要求、數據轉換的復雜度以及團隊現有的技術棧和運維能力。
5. 直接在湖倉上處理數據
ETL vs ELT 策略
| 特性 | 傳統ETL | 湖倉一體ELT |
|---|---|---|
| 處理順序 | 先轉換后加載 | 先加載后轉換 |
| 數據存儲位置 | 在專門ETL工具中處理 | 直接在湖倉平臺處理 |
| 計算能力 | 依賴專用ETL工具 | 利用湖倉平臺計算引擎 |
| 數據可訪問性 | 僅最終狀態可訪問 | 原始和各階段數據均可訪問 |
| 靈活性 | 較低,固定管道 | 較高,多引擎處理 |
在數據倉庫領域,傳統的做法是 ETL(Extract, Transform, Load):先從源系統抽取數據,在專門的 ETL 工具或中間層進行轉換和清洗,最后加載到目標數據倉庫中。而在湖倉一體架構中,更常見的模式是 ELT(Extract, Load, Transform)。數據首先被抽取(Extract)并加載(Load)到湖倉的原始存儲層(通常是 Delta Lake 或 Iceberg 表),保持其原始或接近原始的格式。然后,利用湖倉平臺上的計算引擎直接對這些表進行轉換(Transform),生成清洗、整合或聚合后的數據,存儲在湖倉的不同層級中。
這種轉變的主要原因是湖倉平臺本身具備了強大的、可擴展的計算能力,并且可以直接操作存儲在廉價對象存儲上的數據。ELT 模式減少了數據在系統間移動的次數,簡化了數據管道,并允許數據科學家和分析師在需要時訪問更原始的數據。
多跳(Medallion)架構
一個在湖倉一體中廣泛采用的數據組織和處理模式是多跳(Multi-hop)或獎牌(Medallion)架構。這種架構通常包含三個邏輯層級:
- 銅牌層 (Bronze / Raw): 存儲從源系統攝入的原始數據,通常格式與源系統保持一致,僅做最少的處理(如格式轉換)。這一層是歷史數據的存檔,可以用于重新處理。
- 銀牌層 (Silver / Cleansed / Enriched): 存儲經過清洗、過濾、標準化和豐富化的數據。來自不同源的數據可能在這一層被整合。這一層的數據通常是可信的,可供下游的BI和 ML 應用使用。
- 金牌層 (Gold / Aggregated / Curated): 存儲為特定業務需求或分析場景(如BI報表、特征工程)而聚合或轉換的數據。通常包含業務級別的聚合指標、維度模型等。
數據在這些層級之間通過一系列的ELT作業(使用Spark, Flink, Trino, Dremio等引擎)進行處理和轉換,每一層都存儲為Delta Lake或Iceberg表。
銅牌到銀牌層SQL示例:
-- 銅牌層數據加載
CREATE TABLE bronze.sales_raw
USING DELTA
LOCATION 's3://data-lake/bronze/sales_raw'
AS SELECT * FROM kafka_source;-- 轉換到銀牌層
CREATE TABLE silver.sales_cleaned
USING DELTA
LOCATION 's3://data-lake/silver/sales_cleaned'
AS SELECTid,CAST(NULLIF(trim(customer_id), '') AS INT) AS customer_id,CAST(amount AS DECIMAL(10,2)) AS amount,TO_DATE(transaction_date, 'yyyy-MM-dd') AS transaction_date,region
FROM bronze.sales_raw
WHERE id IS NOT NULL;
利用計算引擎進行處理:
湖倉一體架構的核心優勢之一是其開放性,允許用戶選擇最適合其工作負載的計算引擎來處理存儲在 Delta Lake 或 Iceberg 表中的數據。
- Apache Spark: 是目前湖倉一體生態系統中最常用、功能最全面的計算引擎,尤其與Delta Lake緊密集成。Spark 提供了強大的DataFrame API和Spark SQL接口,支持批處理、流處理和機器學習。它可以高效地讀寫 Delta Lake 和 Iceberg 表,執行復雜的轉換邏輯,是構建 ELT 管道和進行大規模數據處理的首選工具。例如,可以使用 Spark 讀取一個 Iceberg 表,進行聚合操作,然后將結果寫回另一個 Iceberg 表。
Spark讀寫Iceberg表示例:
# PySpark示例 - 讀取Iceberg表并進行聚合操作
from pyspark.sql import SparkSession
from pyspark.sql.functions import sum, avg, month# 創建Spark會話
spark = SparkSession.builder \.appName("Iceberg Processing") \.config("spark.sql.extensions", "org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions") \.config("spark.sql.catalog.iceberg", "org.apache.iceberg.spark.SparkCatalog") \.config("spark.sql.catalog.iceberg.type", "hive") \.getOrCreate()# 讀取銀牌層銷售數據
sales_df = spark.read.format("iceberg").load("iceberg.silver.sales_cleaned")# 進行月度聚合分析
monthly_sales = sales_df \.groupBy(month("transaction_date").alias("month"), "region") \.agg(sum("amount").alias("total_sales"),avg("amount").alias("avg_sale_value"))# 將結果寫入金牌層表
monthly_sales.writeTo("iceberg.gold.monthly_sales_by_region") \.tableProperty("format-version", "2") \.createOrReplace()
- Trino (原 PrestoSQL): 是一個高性能的分布式 SQL 查詢引擎,專注于快速的交互式分析。Trino 可以連接多種數據源,包括Delta Lake和Iceberg。它非常適合BI分析師直接在湖倉數據上運行 SQL 查詢,為BI工具提供后端支持。
Trino查詢示例:
-- Trino上查詢Iceberg表
SELECT r.region_name,SUM(s.total_sales) AS total_regional_sales,AVG(s.avg_sale_value) AS avg_regional_sale
FROM iceberg.gold.monthly_sales_by_region s
JOIN iceberg.silver.region_dim r ON s.region = r.region_id
WHERE month BETWEEN 1 AND 3
GROUP BY r.region_name
ORDER BY total_regional_sales DESC;
- Dremio: Dremio 是一個集成了數據目錄、查詢加速和SQL查詢引擎的湖倉一體平臺。它對 Apache Iceberg 提供了深度支持,也能查詢Delta Lake。Dremio 提供了語義層、數據反射(通過預計算聚合或排序來加速查詢)等特性,旨在簡化數據訪問并提升BI查詢性能。Dremio 也支持通過 SQL(如 CREATE TABLE AS SELECT (CTAS), INSERT INTO SELECT)執行 ELT 任務,從其他數據源或湖倉內的表中讀取數據并寫入新的 Iceberg 表。
- 其他引擎: 湖倉一體的開放性意味著 Delta Lake 和 Iceberg 可以被越來越多的引擎所支持。例如,Apache Flink 可用于流式 ETL;傳統的 Hive 引擎也可以通過連接器訪問這些表格式;云服務商的查詢服務如 Amazon Athena、Google BigQuery、Azure Synapse Analytics以及 Snowflake等也都在不斷增強對Delta Lake和Iceberg的支持。這種互操作性,特別是對于Iceberg而言,是其核心價值主張之一。
執行轉換操作:
在湖倉一體平臺上,數據轉換通常使用所選計算引擎提供的SQL或DataFrame API來完成。例如,使用Spark SQL或Trino SQL,可以直接在 Delta Lake 或 Iceberg 表上執行 SELECT 語句進行過濾、連接(JOIN)、聚合(GROUP BY)、窗口函數等操作。轉換結果可以寫入新的表(例如,從銀牌層創建金牌層聚合表),或者使用MERGE INTO、UPDATE、DELETE 等 DML 語句修改現有表。
Delta Lake MERGE示例:
-- 使用MERGE INTO實現變更數據捕獲(CDC)處理
MERGE INTO silver.customers t
USING bronze.customer_updates s
ON t.customer_id = s.customer_id
WHEN MATCHED AND s.operation = 'DELETE' THENDELETE
WHEN MATCHED AND s.operation = 'UPDATE' THENUPDATE SETt.name = s.name,t.email = s.email,t.address = s.address,t.updated_at = CURRENT_TIMESTAMP
WHEN NOT MATCHED AND s.operation = 'INSERT' THENINSERT (customer_id, name, email, address, created_at, updated_at)VALUES (s.customer_id, s.name, s.email, s.address, CURRENT_TIMESTAMP, CURRENT_TIMESTAMP);
Delta Lake和Iceberg的模式演進能力 在此過程中也扮演了重要角色。當業務需求變化導致需要修改表結構(如添加新維度、更改指標計算方式)時,模式演進允許在不中斷現有數據或進行昂貴的數據遷移的情況下更新表定義,從而簡化了長期維護 ELT 管道的復雜性。
模式演進示例:
-- Iceberg表模式演進
ALTER TABLE silver.customers
ADD COLUMN loyalty_tier STRING COMMENT '客戶忠誠度等級';-- 回滾到某個時間點的數據(時間旅行功能)
SELECT * FROM silver.customers FOR TIMESTAMP AS OF '2023-06-01 00:00:00';
湖倉一體架構的核心理念在于,數據存儲在一個開放、可靠的平臺上,而計算則可以通過多種專門優化的引擎來完成。這種架構使得不同的團隊——BI 分析師使用 SQL 通過 Trino 或 Dremio 進行交互式查詢,數據工程師使用 Spark 或 Flink 構建批處理或流式 ETL 管道,數據科學家使用 Python 和 Spark 進行模型訓練——都能夠高效地在統一、最新的數據副本上協作,而無需將數據在不同的專用系統之間移動,從而打破了數據孤島。
6. 核心架構組件
湖倉一體架構分層圖
構建一個基于 Delta Lake 或 Iceberg 的湖倉一體數據分析平臺,需要整合一系列關鍵的技術組件,形成一個分層架構。
- 存儲層 (Storage Layer):
- 云對象存儲: 這是湖倉一體架構的基礎。利用公有云提供的低成本、高持久性、高可擴展性的對象存儲服務,如 Amazon S3、Azure Data Lake Storage (ADLS)或Google Cloud Storage (GCS) ,作為數據的主要存儲庫。這種存儲與計算分離的模式是實現彈性和成本效益的關鍵。
- 數據文件: 實際的數據記錄存儲在這些對象存儲中,通常采用開放的、面向列的(Columnar)文件格式,如 Apache Parquet(Delta Lake 的默認格式,也是 Iceberg 的常用格式)。列式存儲能夠有效壓縮數據并提高分析查詢的 I/O 效率。Iceberg 還支持 Apache Avro 和 Apache ORC 等格式。
云存儲配置示例 (AWS):
# 使用boto3配置S3存儲
import boto3# 創建S3客戶端
s3_client = boto3.client('s3',aws_access_key_id='YOUR_ACCESS_KEY',aws_secret_access_key='YOUR_SECRET_KEY',region_name='us-west-2'
)# 創建數據湖存儲桶和目錄結構
buckets = ['data-lake-bronze', 'data-lake-silver', 'data-lake-gold']
for bucket in buckets:try:s3_client.create_bucket(Bucket=bucket,CreateBucketConfiguration={'LocationConstraint': 'us-west-2'})print(f"存儲桶 {bucket} 創建成功")except Exception as e:print(f"存儲桶 {bucket} 創建錯誤: {e}")
- 表格式層 (Table Format Layer):
- 這是湖倉一體架構的核心創新所在,位于原始數據文件之上,提供了關鍵的數據管理能力。
- Delta Lake 或 Apache Iceberg: 選擇其中一種表格式來組織和管理數據湖中的文件。它們通過引入事務日志(Delta)或元數據文件和 Catalog(Iceberg)來提供 ACID 事務、模式演進、時間旅行、數據版本控制等功能,將不可靠的數據湖轉變為可靠的數據存儲。選擇哪種格式取決于具體需求,如前文(第2節)的對比分析所述。
- 元數據管理層 (Metadata Management Layer / Catalog):
- 角色: Catalog 對于湖倉一體至關重要,特別是對于 Iceberg 架構。它負責跟蹤表的元數據信息,如表的 Schema、分區規范、數據文件的位置、快照歷史等。計算引擎通過 Catalog 來發現表、理解表結構并規劃查詢執行。對于 Iceberg,Catalog 還需要支持原子操作以保證事務性。
- Hive Metastore (HMS): 源自 Hadoop 生態的傳統元數據存儲服務。它可以被 Delta Lake 和 Iceberg 使用。優點是廣泛兼容現有工具,缺點是需要自行部署和維護(包括后端關系數據庫),且在大規模或云原生環境中可能存在性能和集成方面的挑戰。
- AWS Glue Data Catalog: AWS 提供的云原生、完全托管的元數據目錄服務。它與 AWS 生態系統(如 Athena, EMR, Lake Formation)深度集成,提供無服務器體驗和自動化的 Schema 發現(Crawlers)。對于重度 AWS 用戶來說非常方便,但可能在極高分區數量下的性能表現不如精心調優的HMS,并且是 AWS 平臺綁定的。它支持Iceberg和Delta Lake表。
- Project Nessie: 一個專為現代數據湖和表格式(尤其是 Iceberg)設計的開源事務性Catalog。其核心特性是提供了類似 Git 的版本控制能力,允許對數據和元數據進行分支(Branching)、提交(Commits)和合并(Merging)操作。這極大地促進了數據協作、CI/CD for Data、數據質量保證和多表事務處理,代表了元數據管理的一種新范式,即"數據即代碼"(Data-as-Code)。Nessie 需要自行部署和管理。
- 其他 Catalog: 還存在一些其他的 Catalog 選項,包括:
- 特定于平臺的 Catalog: 如 Databricks Unity Catalog,它提供了統一的治理和元數據管理,并通過 UniForm 功能可以暴露 Iceberg 元數據。
- 數據庫 Catalog: 如 JDBC Catalog,可以使用關系數據庫來存儲 Iceberg 元數據。
- 文件系統 Catalog: 如 Hadoop Catalog,直接在文件系統(如HDFS或S3)上存儲元數據指針,適用于簡單場景1。
- 新興 Catalog: 如 Snowflake 推出的 Polaris Catalog。
下表對比了主要的元數據 Catalog 選項:
| 特性 | Hive Metastore (HMS) | AWS Glue Data Catalog | Project Nessie |
|---|---|---|---|
| 類型 | 開源,獨立服務 | AWS 托管服務 | 開源,事務性 Catalog |
| 管理 | 自行部署和維護 (服務 + RDBMS) | 完全托管,無服務器 | 自行部署和維護 |
| 云原生? | 否 | 是 (AWS) | 否 (但可在云上部署) |
| 關鍵特性 | 廣泛兼容,支持統計信息/約束 (非強制)2 | AWS 集成,Crawlers | Git 式版本控制 (分支/提交/合并)3 |
| 事務性 (Catalog層面) | 有限 (依賴后端 RDBMS) | 有限 | 支持事務性元數據操作 |
| 版本控制 (Git式) | 不支持 | 不支持 | 核心特性 |
| 主要格式焦點 | 通用 (Hive, Spark SQL 表) | 通用 (AWS 服務集成) | Iceberg (主要), Delta Lake (有限支持) |
| 擴展性考慮 | 高分區數下性能依賴RDBMS調優 | 高分區數下可能有性能瓶頸 | 針對大規模元數據設計 |
| 生態系統 | Hadoop, Spark, Presto/Trino | AWS | Iceberg, Dremio, Spark, Flink |
Nessie使用示例:
# 使用PyNessie操作分支和提交
from pynessie import init_nessie
from pynessie.conf import make_config
from pynessie.model import CommitMeta# 連接到Nessie服務
conf = make_config(endpoint="http://localhost:19120/api/v1")
client = init_nessie(conf)# 創建新的開發分支
client.create_branch("dev", reference="main")# 切換到開發分支
client.set_reference("dev")# 提交更改
commit_message = "更新銷售數據模型"
author = "data_engineer@example.com"
client.commit(CommitMeta(message=commit_message, author=author)
)# 最終將開發分支合并回主分支
client.merge("dev", "main")
Catalog 的選擇對湖倉平臺的運維模式和高級功能(如 Nessie 的數據版本控制)有顯著影響。云原生 Catalog (Glue) 簡化了運維但可能犧牲部分功能或帶來平臺綁定 。開源選項 (HMS, Nessie) 提供了靈活性但需要管理成本。Nessie 代表了一種更現代的、面向數據開發流程優化的方法。
- 計算引擎層 (Compute Engine Layer):
- 提供執行數據處理和查詢任務的計算資源。如前文(第5節)所述,包括 Apache Spark, Apache Flink, Trino, Dremio 等。關鍵在于這些引擎與存儲層是解耦的,可以獨立擴展和選擇。
- 查詢接口/API 層 (Query Interface / API Layer):
- 用戶和應用程序與湖倉平臺交互的接口。這包括:
- SQL 接口: 通過 Trino, Spark SQL, Dremio, Athena, BigQuery 等引擎提供的標準 SQL 查詢能力。
- DataFrame API: 如 Spark DataFrame API 或 Flink DataStream/Table API,用于更復雜的編程邏輯。
- 專用庫: 如 pyiceberg,允許通過 Python 直接操作 Iceberg 表。
- BI 工具連接器: 允許 Tableau, PowerBI等工具連接到湖倉平臺(通常通過計算引擎或專用連接器)。
- REST API: 例如,Iceberg 定義了 REST Catalog 協議,允許通過 HTTP API 進行元數據交互。
- 用戶和應用程序與湖倉平臺交互的接口。這包括:
PyIceberg示例:
# 使用PyIceberg直接操作Iceberg表
from pyiceberg.catalog import load_catalog# 加載目錄
catalog = load_catalog("my_catalog", **{"uri": "https://my-rest-catalog/api","credential": "token123"}
)# 獲取表引用
table = catalog.load_table("sales.transactions")# 獲取表元數據
print(f"表名: {table.name}")
print(f"表結構: {table.schema()}")
print(f"分區規范: {table.partition_spec()}")# 掃描數據
from pyiceberg.expressions import GreaterThan, col# 過濾大于1000元的交易
results = table.scan(row_filter=GreaterThan(col("amount"), 1000.0))# 讀取數據到Pandas
with results.to_pandas() as df:print(df.head())
- 治理與安全層 (Governance & Security Layer):
- 負責數據安全、訪問控制、合規性和數據質量。這可能涉及:
- 身份與訪問管理 (IAM): 控制誰可以訪問哪些資源。
- 訪問控制策略: 在 Catalog 層面(如 AWS Lake Formation, Unity Catalog)或表格式層面實施細粒度的權限控制。
- 數據加密: 對靜態存儲和傳輸中的數據進行加密。
- 審計日志: 記錄對數據的訪問和修改操作。
- 數據質量規則: 定義和監控數據質量。
- 數據血緣: 追蹤數據的來源和轉換過程。
- 數據目錄與業務元數據: 工具如AWS DataZone或Microsoft Purview用于添加業務上下文和促進數據發現。
- 負責數據安全、訪問控制、合規性和數據質量。這可能涉及:
AWS Lake Formation權限配置示例:
-- 使用AWS Lake Formation數據權限語法
GRANT SELECT
ON DATABASE lakehouse
TO IAM_USER 'arn:aws:iam::123456789012:user/analyst';GRANT INSERT, DELETE
ON TABLE lakehouse.gold.sales_mart
TO IAM_ROLE 'arn:aws:iam::123456789012:role/data_engineer';-- 列級別權限
GRANT SELECT (customer_id, region, total_sales)
ON TABLE lakehouse.gold.sales_mart
TO IAM_ROLE 'arn:aws:iam::123456789012:role/marketing_analyst';
參考技術棧示例
| 層級 | 技術選項 |
|---|---|
| 存儲層 | AWS S3 / Azure ADLS / Google GCS |
| 表格式層 | Apache Iceberg / Delta Lake |
| 元數據管理層 | Project Nessie / AWS Glue / Hive Metastore |
| 攝入引擎 | Apache Flink / Kafka Connect / Spark Structured Streaming |
| 處理/查詢引擎 | Apache Spark / Trino / Dremio |
| 治理層 | AWS Lake Formation / 自定義策略+Nessie審計 / Unity Catalog |
| 消費接口 | Tableau / Power BI / SQL客戶端 / Python APIs |
一個典型的基于Iceberg的湖倉一體技術棧可能如下所示:
- **存儲層:**AWS S3 / Azure ADLS / Google GCS
- 表格式層: Apache Iceberg
- 元數據管理層: Project Nessie (提供版本控制) 或 AWS Glue Data Catalog (簡化云上運維)
- 攝入引擎: Apache Flink (低延遲流) / Kafka Connect (簡單流) / Apache Spark Structured Streaming (批流一體)
- 處理/查詢引擎: Apache Spark (批處理/ML), Trino (交互式 SQL), Dremio (BI 加速/語義層)
- 治理層: AWS Lake Formation (如果使用 Glue Catalog) / 自定義策略 + Nessie 審計 / Unity Catalog (如果使用 Databricks)
- ** 消費接口: ** BI工具 (Tableau, Power BI) 通過 Trino/Dremio 連接, ML 平臺 (SageMaker, Vertex AI) 通過 Spark 或直接讀取, SQL客戶端, 應用程序通過 API。
7. 效益分析:延遲與成本
構建基于 Delta Lake 或 Iceberg 的湖倉一體平臺,其核心驅動力在于解決傳統數據架構在延遲和成本方面的痛點。
降低端到端數據延遲:
- 傳統數據倉庫的延遲: 傳統數據倉庫通常采用批處理模式進行數據加載和轉換。數據需要經過多個階段(源系統 -> ETL -> Staging -> Data Lake (可選) -> ETL -> Data Warehouse),每個階段都可能引入延遲。ETL 作業通常按小時、天甚至更長的周期運行,導致業務用戶或分析應用獲取到的數據往往不是最新的,延遲可能高達數小時或數天。這對于需要快速響應市場變化或實時決策的場景是不可接受的。
- 湖倉一體的低延遲優勢: 湖倉一體架構通過以下方式顯著縮短了數據從產生到可供分析的端到端延遲:
- 實時/近實時攝入: 如第 節所述,利用 Spark Structured Streaming, Flink, Kafka Connect 等技術,可以將數據流式地直接寫入湖倉中的 Delta Lake 或 Iceberg 表,使得數據在產生后的幾秒或幾分鐘內即可用。
- 消除 ETL 瓶頸: ELT 模式和簡化的架構減少了數據在不同系統間冗長、耗時的移動和轉換過程0。轉換可以直接在湖倉上進行,無需等待數據加載到單獨的倉庫系統。
- **直接查詢:**BI工具、數據科學平臺和應用程序可以直接查詢湖倉中的數據,無需等待數據被加載到數據倉庫。這意味著分析師和模型可以使用更新鮮的數據。
- 性能優化: Delta Lake和Iceberg內建的性能優化機制(如數據跳過、索引、文件布局優化、緩存)以及高性能查詢引擎(如 Trino, Dremio, Photon)的應用,使得在數據湖上直接進行大規模數據分析的性能得以保障,甚至可以媲美傳統數倉。
- 延遲量級轉變: 湖倉一體架構使得數據可用性的延遲從傳統的**批處理周期(小時/天)轉變為近實時(分鐘/秒)甚至實時(秒級/亞秒級,取決于流處理引擎和配置)**成為可能。
| 延遲比較 | 傳統數據倉庫 | 湖倉一體平臺 |
|---|---|---|
| 數據攝入 | 批處理(小時/天) | 實時/近實時(秒/分鐘) |
| ETL處理 | 多階段ETL(小時) | 簡化ELT流程(分鐘) |
| 查詢延遲 | 復雜的數據同步 | 直接查詢源數據 |
| 端到端延遲 | 小時到天級別 | 秒到分鐘級別 |
# 示例:使用Spark Structured Streaming實現實時數據攝入到Delta Lake
from pyspark.sql import SparkSession
from pyspark.sql.functions import *# 初始化Spark會話
spark = SparkSession.builder \.appName("RealTimeIngestion") \.config("spark.sql.extensions", "io.delta.sql.DeltaSparkSessionExtension") \.config("spark.sql.catalog.spark_catalog", "org.apache.spark.sql.delta.catalog.DeltaCatalog") \.getOrCreate()# 從Kafka流中讀取數據
kafka_stream = spark.readStream \.format("kafka") \.option("kafka.bootstrap.servers", "kafka:9092") \.option("subscribe", "transactions") \.load()# 處理數據
parsed_stream = kafka_stream.selectExpr("CAST(value AS STRING)") \.select(from_json(col("value"), schema).alias("data")) \.select("data.*")# 將數據流式寫入Delta表
query = parsed_stream.writeStream \.format("delta") \.outputMode("append") \.option("checkpointLocation", "/delta/checkpoints/transactions") \.start("/delta/tables/transactions")
實現顯著的成本效益:
- 存儲成本: 這是最顯著的成本節約來源。湖倉一體架構將數據存儲在成本極低的云對象存儲上,其單位存儲成本遠低于傳統數據倉庫通常使用的、與計算緊耦合的專有存儲系統。雖然像 Snowflake 這樣的云數倉也利用了對象存儲,但其整體架構和定價模型可能與基于開放格式的湖倉有所不同,后者通常提供更高的存儲成本效益和數據所有權。
- 計算成本:
- 存算分離: 存儲和計算資源的解耦允許根據實際需求獨立擴展計算能力,避免了傳統倉庫中計算資源可能因存儲需求而被動擴展或閑置的情況,從而優化了計算成本。
- 查詢效率: 表格式提供的元數據優化(如分區裁剪、文件統計信息)和查詢引擎的優化(如 Dremio 的反射、向量化執行)可以減少查詢所需掃描的數據量和計算時間,從而降低按需計算的費用。
- 基礎設施與運維成本:
- 架構簡化: 消除獨立的、需要分別管理和維護的數據湖和數據倉庫系統,降低了整體基礎設施的復雜性和運維成本。
- 減少 ETL: 簡化的ELT流程意味著更少的 ETL 作業開發、調度和維護工作量。
- 開源與避免鎖定: 廣泛采用開源表格式(Delta, Iceberg)和開源計算引擎(Spark, Trino, Flink)可以避免與專有數據倉庫供應商相關的昂貴許可費用和供應商鎖定風險。這為組織提供了更大的技術選擇自由度和議價能力。
| 成本類別 | 傳統數據架構 | 湖倉一體架構 | 節約潛力 |
|---|---|---|---|
| 存儲成本 | 專有存儲系統(高成本) | 云對象存儲(低成本) | 60-80% |
| 計算成本 | 存算耦合,資源浪費 | 存算分離,按需擴展 | 30-50% |
| 運維成本 | 多系統管理,復雜ETL | 架構簡化,減少ETL | 40-60% |
| 許可費用 | 專有軟件高額許可 | 開源技術棧降低授權費 | 50-70% |
湖倉一體的成本優勢是多維度的,它不僅僅來自于更便宜的存儲介質,更源于架構的簡化、運維效率的提升以及開放標準帶來的靈活性。這種經濟上的吸引力使得湖倉一體成為處理當今海量、多樣化數據的極具競爭力的解決方案。
8. 與分析生態系統集成
構建湖倉一體平臺的目的最終是為了服務于下游的分析應用,包括商業智能(BI)報表和機器學習(ML)平臺。因此,確保平臺與這些工具的順暢集成至關重要。
連接商業智能工具 (如 Power BI, Tableau):
- 目標: 使BI用戶能夠方便、高效地連接到湖倉平臺,直接對存儲在 Delta Lake 或 Iceberg 表中的數據進行可視化和探索分析。
- 集成方法:
- 平臺原生連接器: 許多BI工具提供了針對主流數據平臺或引擎的連接器。例如,Power BI提供了專門的 Databricks連接器,支持使用個人訪問令牌(PAT)或OAuth進行身份驗證,并可以選擇 Import(導入數據到 Power BI)或 DirectQuery(直接查詢 Databricks)模式。PowerBI甚至還有一個獨立的 Delta Lake 連接器,可以直接讀取存儲中的Delta文件。
- 通過查詢引擎連接: 更通用的方法是讓BI工具連接到一個能夠查詢湖倉數據的 SQL 查詢引擎,如 Trino, Dremio, Spark SQL, Snowflake, BigQuery等。這些引擎充當了BI工具和底層 Delta/Iceberg 表之間的橋梁。例如,Dremio 提供了優化的 Tableau 和Power BI連接器,并利用其反射(Reflections)功能加速BI查詢,實現直接在湖倉上進行高性能交互式分析7。
- 利用平臺特性: 某些湖倉平臺提供了簡化的集成功能。例如,Databricks 允許用戶直接從其 UI 將 Unity Catalog 中的表或 Schema 發布為 Power BI數據集,或者可以通過其 SQL Endpoint 連接。Snowflake 也可以查詢外部的 Iceberg 表,然后通過 Snowflake 的BI連接器進行訪問。
- 關鍵考慮因素:
- 身份驗證: 需要配置安全的身份驗證機制,如OAuth或PAT。
- 連接模式 (Import vs. DirectQuery): Import 模式通常性能更好,但數據有延遲且受內存限制;DirectQuery 模式提供實時數據,但對后端查詢引擎的性能要求很高。對于 DirectQuery,使用高性能引擎(如 Trino, Dremio, Databricks SQL Warehouse)和優化技術(如 Dremio 反射)至關重要。
- 性能: 確保查詢引擎和表格式本身經過優化(如分區、壓縮、統計信息),以提供可接受的BI查詢響應時間。
- 安全與訪問控制: 必須在連接層或底層數據平臺實施恰當的訪問控制策略,確保用戶只能看到他們有權限訪問的數據。
-- 示例:在Trino中優化Delta表查詢性能的SQL
-- 1. 創建優化的表布局
CREATE TABLE sales_optimized
WITH (partitioning = ARRAY['year', 'month'],bucketed_by = ARRAY['customer_id'],bucket_count = 32
)
AS SELECT * FROM sales;-- 2. 在Trino中使用分區裁剪查詢
SELECT customer_id,SUM(amount) as total_sales
FROM sales_optimized
WHERE year = 2023 AND month = 6 ANDregion = 'APAC'
GROUP BY customer_id
ORDER BY total_sales DESC
LIMIT 10;
集成機器學習平臺 (如 MLflow, SageMaker, Vertex AI):
- 目標: 使數據科學家能夠輕松地從湖倉中訪問數據進行模型訓練,并利用MLOps平臺(如MLflow)進行實驗跟蹤、模型管理,最終將模型部署到生產環境(如SageMaker, Vertex AI)。
- 數據訪問: 湖倉一體架構極大地簡化了 ML 的數據訪問。由于數據通常存儲在開放格式(如Parquet)中,主流的 ML 框架(如 TensorFlow, PyTorch, scikit-learn)和庫(如 Pandas)通常可以直接讀取這些文件。Apache Spark 的集成(尤其是對于 Delta Lake)也為大規模數據預處理和特征工程提供了便利。
- MLflow 集成: MLflow 是一個流行的開源 MLOps 平臺。
- 實驗跟蹤: 可以在 Databricks 等環境中訓練模型(使用 Delta Lake 數據),并使用 MLflow 自動或手動跟蹤實驗參數、指標和模型構件。
- 模型部署: MLflow 提供了將已注冊模型部署到云平臺的功能:
- 部署到 Amazon SageMaker: 使用 mlflow sagemaker build-and-push-container 和 mlflow deployments create 命令,可以構建兼容 SageMaker 的 Docker 鏡像,推送到 ECR,并創建 SageMaker Endpoint 來托管模型。這需要預先配置好 AWS IAM 角色、ECR倉庫和S3存儲桶的權限。
- 部署到 Google Cloud Vertex AI: 通過安裝 google-cloud-mlflow 插件,可以將 MLflow 中(可能在 Databricks 上訓練)的模型部署到 Vertex AI Endpoint。這同樣需要配置Google Cloud服務賬號權限,并將模型構件存儲在Google Cloud Storage中。
- Amazon SageMaker 集成:
- 數據處理: SageMaker Studio 可以連接到運行 Spark 的 EMR 集群,以處理存儲在S3上的 Delta Lake 數據。
- 模型訓練與托管: SageMaker 提供了豐富的內置算法,支持主流 ML 框架,并提供模型訓練和托管服務。
- SageMaker Lakehouse: 這是 SageMaker 的一項新功能,允許通過 AWS Glue Iceberg REST Catalog 訪問S3上的 Iceberg 表,并利用 AWS Lake Formation 進行權限管理。這使得 SageMaker 可以更原生、安全地與 Iceberg 數據湖集成。
- MLflow on SageMaker: 可以在 SageMaker Unified Studio 中創建和管理MLflow Tracking Server,用于跟蹤在 SageMaker 環境中進行的實驗。
- Google Cloud Vertex AI集成:
- 模型部署: 如前所述,通過google-cloud-mlflow插件,可以將來自Databricks/MLflow的模型部署到 Vertex AI 進行托管和在線預測。Vertex AI提供統一的AI平臺,涵蓋數據準備、訓練、部署和監控。
| 集成平臺 | 集成方式 | 主要優勢 | 挑戰 |
|---|---|---|---|
| BI工具 | 原生連接器/查詢引擎 | 直接可視化湖倉數據 | 查詢性能、身份驗證 |
| MLflow | 實驗跟蹤/模型管理 | 統一ML生命周期管理 | 跨平臺部署復雜性 |
| SageMaker | API集成/Lakehouse功能 | 強大的訓練托管能力 | AWS生態系統鎖定 |
| Vertex AI | 插件集成/API | 全面AI平臺能力 | GCP生態系統鎖定 |
# 示例:從Delta Lake讀取數據并訓練模型,使用MLflow跟蹤實驗
import mlflow
from pyspark.sql import SparkSession
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score# 初始化Spark會話
spark = SparkSession.builder \.appName("ML-DeltaLake-Integration") \.config("spark.sql.extensions", "io.delta.sql.DeltaSparkSessionExtension") \.config("spark.sql.catalog.spark_catalog", "org.apache.spark.sql.delta.catalog.DeltaCatalog") \.getOrCreate()# 從Delta Lake讀取特征數據
delta_table_path = "/delta/tables/features"
features_df = spark.read.format("delta").load(delta_table_path)
pandas_df = features_df.toPandas()# 準備訓練數據
X = pandas_df.drop("target", axis=1)
y = pandas_df["target"]# 使用MLflow跟蹤實驗
mlflow.set_experiment("delta-lake-ml-experiment")
with mlflow.start_run():# 記錄數據來源mlflow.log_param("data_source", delta_table_path)# 訓練模型rf = RandomForestClassifier(n_estimators=100, random_state=42)rf.fit(X, y)# 評估模型y_pred = rf.predict(X)accuracy = accuracy_score(y, y_pred)mlflow.log_metric("accuracy", accuracy)# 記錄模型mlflow.sklearn.log_model(rf, "random_forest_model")print(f"模型訓練完成,準確率: {accuracy:.4f}")# 部署到SageMaker的示例命令
# mlflow sagemaker build-and-push-container
# mlflow deployments create -t sagemaker://<region>/model-name \
# --name my-model-deployment \
# --model-uri models:/random_forest_model/1
湖倉一體架構,特別是其對開放數據格式的支持,顯著簡化了機器學習流程中的數據準備和訪問環節。集成的挑戰更多地轉向了 MLOps 層面:如何在湖倉環境(通常是模型訓練發生的地方)與云端托管的 ML 服務(用于模型部署和推理)之間建立順暢的工作流。MLflow 及其相關的部署工具和插件在彌合這一差距方面發揮著越來越重要的作用。
集成最佳實踐:
- 優先使用平臺或引擎提供的原生連接器(如 Databricks-PowerBI連接器),因為它們通常經過優化且易于配置。
- 當原生連接器性能不足或功能受限時,考慮使用高性能 SQL 查詢引擎(如 Trino, Dremio)作為BI工具的中間層。利用這些引擎的查詢加速功能(如 Dremio Reflections)。
- 對于 ML 工作流,使用 MLflow 進行標準化的實驗跟蹤和模型管理。利用MLflow提供的部署工具或插件實現與 SageMaker 或 Vertex AI 等云 ML 平臺的集成。
- 在所有集成點上,務必仔細配置安全和治理。確保身份驗證安全,權限控制到位(例如,使用 Lake Formation 控制 SageMaker 對 Iceberg 數據的訪問,配置 IAM 角色進行模型部署)。
9. 結論與戰略建議
總結:
本報告深入探討了如何利用 Delta Lake 和 Apache Iceberg 等開放表格式構建支持實時寫入、融合數據湖與數據倉庫優勢的湖倉一體(Lakehouse)數據分析平臺。分析表明,湖倉一體架構通過在低成本的云對象存儲之上實現 ACID 事務、模式管理、時間旅行和高性能查詢,有效克服了傳統數據倉庫的高成本、高延遲和靈活性差的缺點,以及傳統數據湖在可靠性、治理和性能方面的不足。
湖倉一體架構流程圖
價值主張:
基于 Delta Lake 或 Iceberg 的湖倉一體平臺的核心價值在于:
- 統一數據管理: 在單一平臺上管理從原始數據到聚合數據的全生命周期,打破BI和 AI/ML 的數據孤島。
- 降低總擁有成本: 通過利用廉價存儲、存算分離和開源技術顯著降低成本。
- 提升數據時效性: 支持實時/近實時數據攝入和處理,大幅縮短數據洞察時間。
- 增強靈活性與可擴展性: 輕松處理多樣化數據類型,獨立擴展存儲和計算資源,避免供應商鎖定。
- 提高數據可靠性與治理: 保證數據事務一致性,實施模式強制,簡化治理和合規任務。
Delta Lake與Iceberg功能對比表
| 功能特性 | Delta Lake | Apache Iceberg |
|---|---|---|
| 開源許可 | Apache 2.0 | Apache 2.0 |
| 主要貢獻者 | Databricks | Netflix, Apple, Adobe |
| ACID事務 | ? | ? |
| 時間旅行 | ? | ? |
| 模式演進 | ? | ? |
| 分區演進 | 有限支持 | ? 完全支持 |
| 數據跳過 | Z-Order | 分區+位置索引 |
| 兼容引擎 | Spark, Flink(有限) | Spark, Flink, Trino, Dremio等 |
| SQL DML支持 | MERGE, UPDATE, DELETE | MERGE, UPDATE, DELETE |
| 行級安全 | ? (Databricks付費版) | 有限支持 |
| 云平臺集成 | 所有主流云 | 所有主流云 |
戰略建議:
- 選擇 Delta Lake vs. Apache Iceberg:
- 評估現有生態: 若深度綁定 Databricks/Spark 生態,Delta Lake提供無縫集成。若追求多引擎互操作性(Flink, Trino等)或希望最大程度避免供應商影響,Iceberg的開放性和廣泛兼容性更優。
- 考慮特定功能: 如果靈活的分區演進是關鍵需求,Iceberg 是明確的選擇。
- 探索融合方案: 對于已有Delta Lake但希望提高與其他Iceberg兼容工具互操作性的場景,可評估Delta UniForm,但需注意其限制(如只讀、異步元數據、不支持所有Delta特性)。
數據操作代碼示例
Delta Lake (使用Spark SQL)
-- 創建Delta表
CREATE TABLE sales_delta (id BIGINT,product STRING,category STRING,amount DOUBLE,ts TIMESTAMP
) USING DELTA
PARTITIONED BY (category)
LOCATION 's3://lakehouse-demo/sales_delta';-- 執行MERGE操作
MERGE INTO sales_delta AS target
USING sales_updates AS source
ON target.id = source.id
WHEN MATCHED THEN UPDATE SET target.amount = source.amount, target.ts = source.ts
WHEN NOT MATCHED THENINSERT (id, product, category, amount, ts) VALUES (source.id, source.product, source.category, source.amount, source.ts);-- 時間旅行查詢
SELECT * FROM sales_delta VERSION AS OF 123
WHERE category = 'Electronics';
Iceberg (使用Spark SQL)
-- 創建Iceberg表
CREATE TABLE sales_iceberg (id BIGINT,product STRING,category STRING,amount DOUBLE,ts TIMESTAMP
) USING ICEBERG
PARTITIONED BY (category)
LOCATION 's3://lakehouse-demo/sales_iceberg';-- 執行UPDATE操作
UPDATE sales_iceberg
SET amount = amount * 1.1
WHERE category = 'Electronics';-- 執行時間旅行查詢
SELECT * FROM sales_iceberg FOR TIMESTAMP AS OF '2023-01-01 12:00:00';
- 選擇合適的工具:
- 數據攝入: 根據延遲要求和轉換復雜度選擇:Flink (最低延遲), Spark Streaming (批流一體), Kafka Connect (簡單攝入)。
- 數據處理/查詢: Spark (通用批處理/ML), Trino (交互式SQL/BI) , Dremio (BI加速/語義層)。
- 元數據管理: AWS Glue (簡化AWS運維), Project Nessie (需要 Git 式數據版本控制), HMS (兼容舊系統)。
使用Spark Streaming攝入數據示例
from pyspark.sql import SparkSession
from pyspark.sql.functions import *# 創建SparkSession
spark = SparkSession.builder \.appName("KafkaToLakehouse") \.config("spark.sql.extensions", "io.delta.sql.DeltaSparkSessionExtension") \.config("spark.sql.catalog.spark_catalog", "org.apache.spark.sql.delta.catalog.DeltaCatalog") \.getOrCreate()# 從Kafka讀取流數據
df = spark \.readStream \.format("kafka") \.option("kafka.bootstrap.servers", "kafka:9092") \.option("subscribe", "sales_events") \.load()# 解析JSON數據
parsed_df = df.select(from_json(col("value").cast("string"), schema).alias("data")
).select("data.*")# 寫入Delta Lake表
query = parsed_df \.writeStream \.format("delta") \.outputMode("append") \.option("checkpointLocation", "s3://lakehouse-demo/checkpoints/sales") \.table("sales_delta")query.awaitTermination()
湖倉一體平臺實施路線圖
- 實施規劃:
- 從小處著手: 從特定的業務用例開始,逐步擴展湖倉平臺的應用范圍。
- 設計先行: 仔細規劃初始的 Schema 設計、分區策略,并考慮未來的演進需求。
- 關注數據質量: 在數據管道中盡早實施數據質量檢查和驗證規則。
- 建立治理框架: 在平臺建設初期就考慮數據安全、訪問控制和合規性要求。
- 分階段遷移: 如果從現有系統遷移,制定詳細的、分階段的遷移計劃。
- 擁抱開放標準: 盡可能利用開放文件格式、開放表格式和開源計算引擎,以保持長期的靈活性和成本效益。
- 投資技能培養: 確保團隊具備分布式計算(Spark, Flink)、SQL-on-Lake 引擎、所選表格式和 Catalog 的專業知識。
數據質量檢查示例 (使用Python與Great Expectations)
import great_expectations as ge
from pyspark.sql import SparkSession# 初始化Spark會話
spark = SparkSession.builder \.appName("DataQualityChecks") \.config("spark.sql.extensions", "io.delta.sql.DeltaSparkSessionExtension") \.getOrCreate()# 讀取Delta表數據
df = spark.read.format("delta").load("s3://lakehouse-demo/sales_delta")
ge_df = ge.dataset.SparkDFDataset(df)# 定義期望并驗證
results = ge_df.expect_column_values_to_not_be_null("id")
print(f"ID列非空檢查: {'通過' if results.success else '失敗'}")results = ge_df.expect_column_values_to_be_between("amount", min_value=0, max_value=1000000)
print(f"金額范圍檢查: {'通過' if results.success else '失敗'}")results = ge_df.expect_column_values_to_be_in_set("category", ["Electronics", "Clothing", "Food", "Home", "Sports"])
print(f"分類值檢查: {'通過' if results.success else '失敗'}")
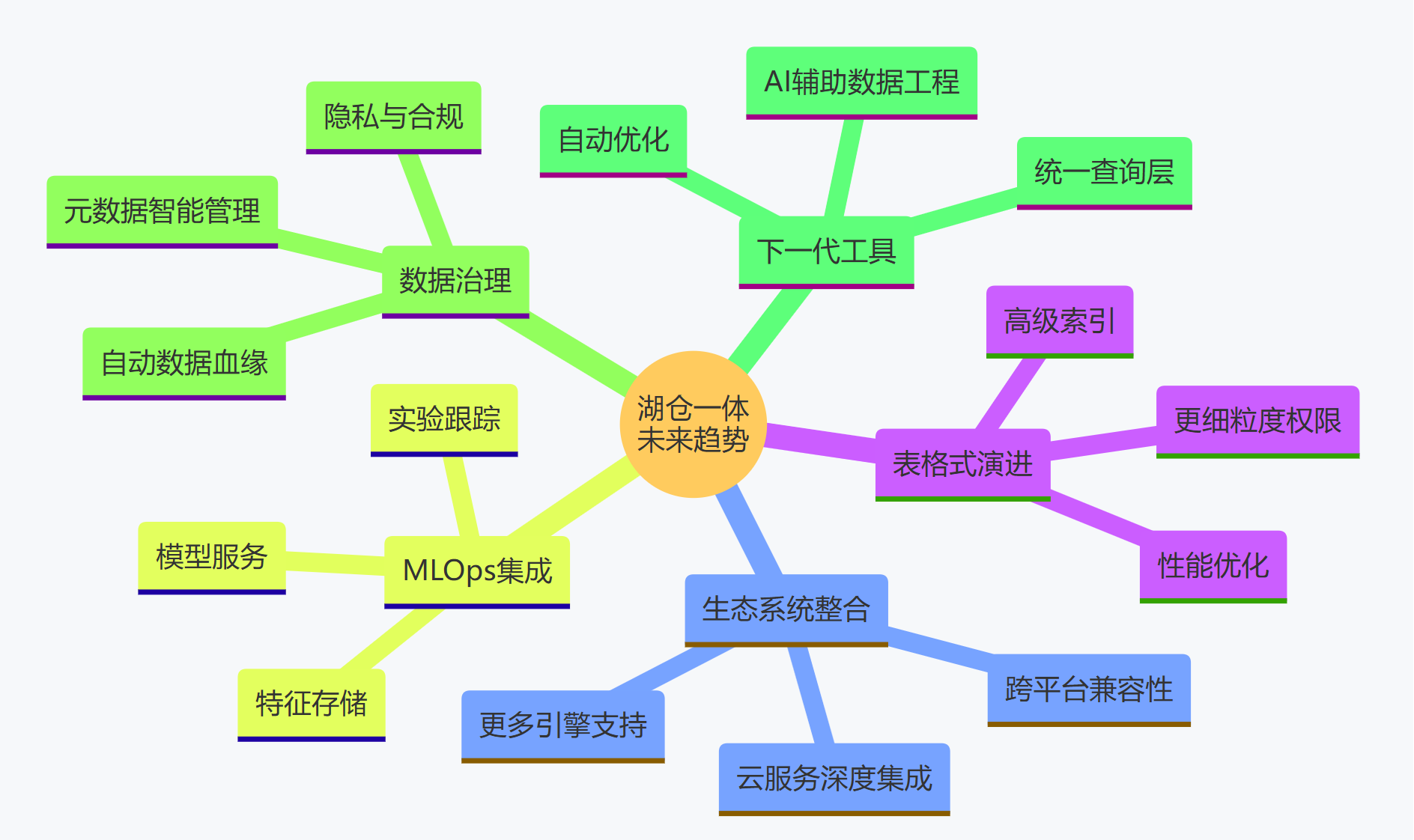
未來展望:
湖倉一體技術仍在快速發展中。我們可以預期看到表格式功能的持續增強、更多計算引擎的集成、以及更成熟的治理和 MLOps 工具的出現。Delta Lake 和 Iceberg 之間的競爭與融合(如 Delta UniForm、Snowflake 對 Iceberg 的支持)將進一步推動生態系統的發展,為用戶提供更多選擇和更強大的能力。采用湖倉一體架構,特別是基于 Delta Lake 或 Iceberg 這樣的開放技術,將是企業構建面向未來的、敏捷、高效、可擴展的數據分析平臺的關鍵戰略方向。
未來技術趨勢預測





)




)


·(重點))
)


:聯邦學習與隱私保護)
)
