25年3月來自新加坡公司 Carion 和北航的論文“DiffAD: A Unified Diffusion Modeling Approach for Autonomous Driving”。
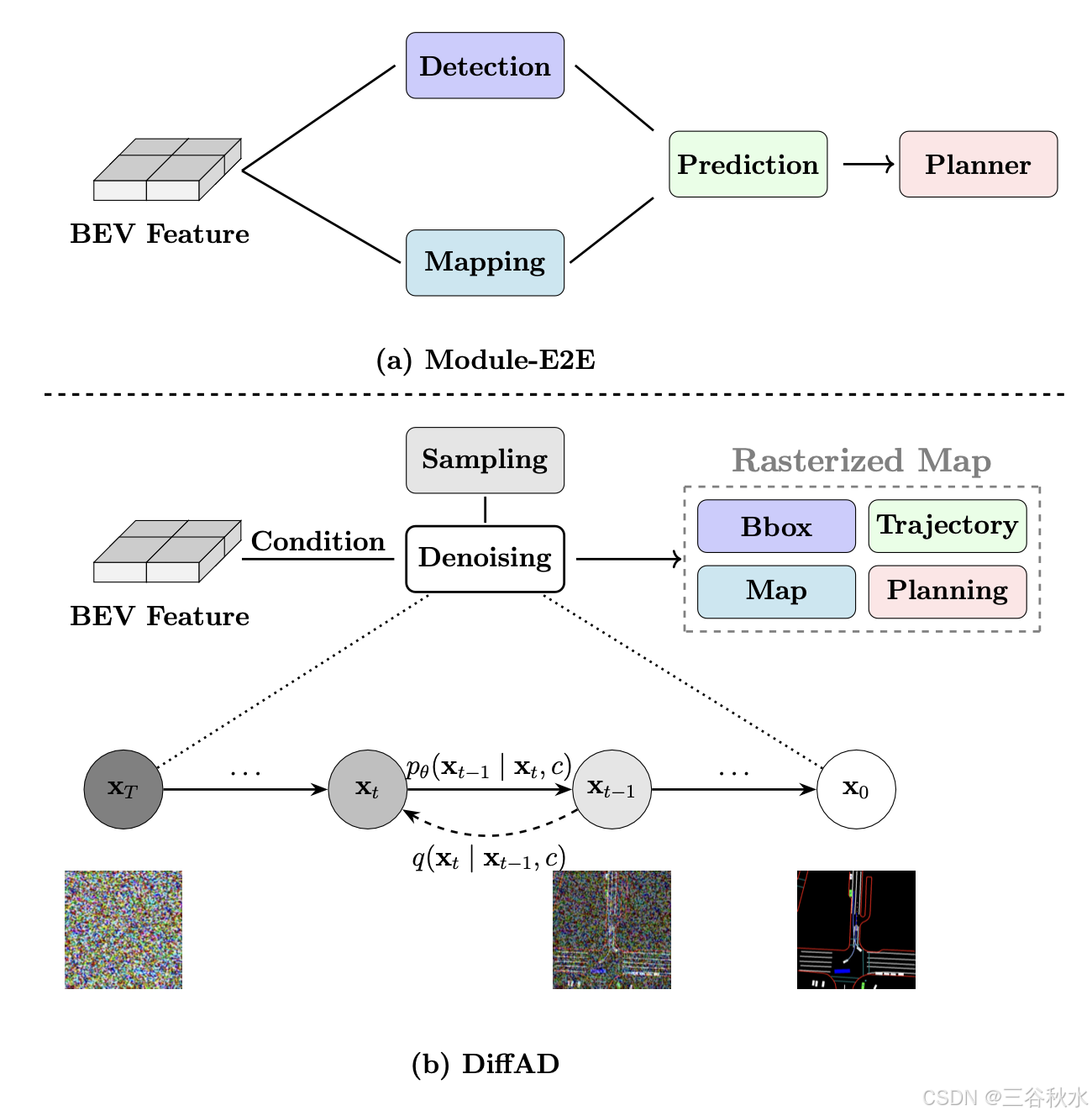
端到端自動駕駛 (E2E-AD) 已迅速成為實現完全自動駕駛的一種有前途的方法。然而,現有的 E2E-AD 系統通常采用傳統的多任務框架,通過單獨的特定任務頭來處理感知、預測和規劃任務。盡管以完全可微分的方式進行訓練,但它們仍然遇到任務協調問題,并且系統復雜性仍然很高。這項工作引入 DiffAD——一種擴散概率模型,它將自動駕駛重新定義為條件圖像生成任務。通過將異構目標柵格化到統一的鳥瞰圖 (BEV) 上并對其潛分布進行建模,DiffAD 統一各種駕駛目標并在單一框架中聯合優化所有駕駛任務,顯著降低系統復雜性并協調任務協調。逆過程迭代細化生成的 BEV 圖像,從而產生更穩健和逼真的駕駛行為。
實現全自動駕駛不僅需要對復雜場景有深入的理解,還需要與動態環境進行有效的交互,并全面學習駕駛行為。傳統的自動駕駛系統建立在模塊化架構之上,感知、預測和規劃都是獨立開發的,然后集成到車載系統中。雖然這種設計提供可解釋性并方便調試,但跨模塊的單獨優化目標往往會導致信息丟失和錯誤積累。
最近的端到端自動駕駛 (E2E-AD) 方法(例如 [3、16、20])試圖通過實現所有組件的聯合、完全可微分訓練來克服這些限制,如圖 (a) 所示。然而,仍然存在幾個關鍵問題:
- 次優優化:像 UniAD [16] 和 VAD [20] 這樣的方法仍然依賴于順序流水線,其中規劃階段取決于前面模塊的輸出。這種依賴性可能會放大整個系統的錯誤。
- 查詢建模效率低下:當前基于查詢的方法(例如 [16, 20])部署數千個可學習查詢來捕獲潛在的交通元素。這種方法導致計算資源分配效率低下,過多關注上游輔助任務而不是核心規劃模塊。例如,在 VAD 中,感知任務消耗了總運行時間的 34.6%,而規劃模塊僅占 5.7%。
- 協調復雜性:由于每個任務頭都使用不同的目標函數獨立優化,并且目標的形狀和語義含義各不相同,因此整個系統變得支離破碎,難以進行連貫訓練 [5]。
為了解決這些限制,本文提出一種范式 DiffAD,它將所有駕駛任務的優化統一到一個模型中,如圖 (b) 所示。具體來說,將感知、預測和規劃中的異??構目標柵格化到統一的鳥瞰圖 (BEV) 空間中,從而將自動駕駛問題重塑為條件圖像生成問題之一。
擴散模型,也稱為基于分數的生成模型 [14, 39, 42],在正向(擴散)過程中逐漸將噪聲注入數據,并通過反向(去噪)過程從噪聲中生成數據。
如圖所示,DiffAD 由三個主要組件組成:潛在擴散模型、BEV 特征生成器和軌跡提取網絡 (TEN)。
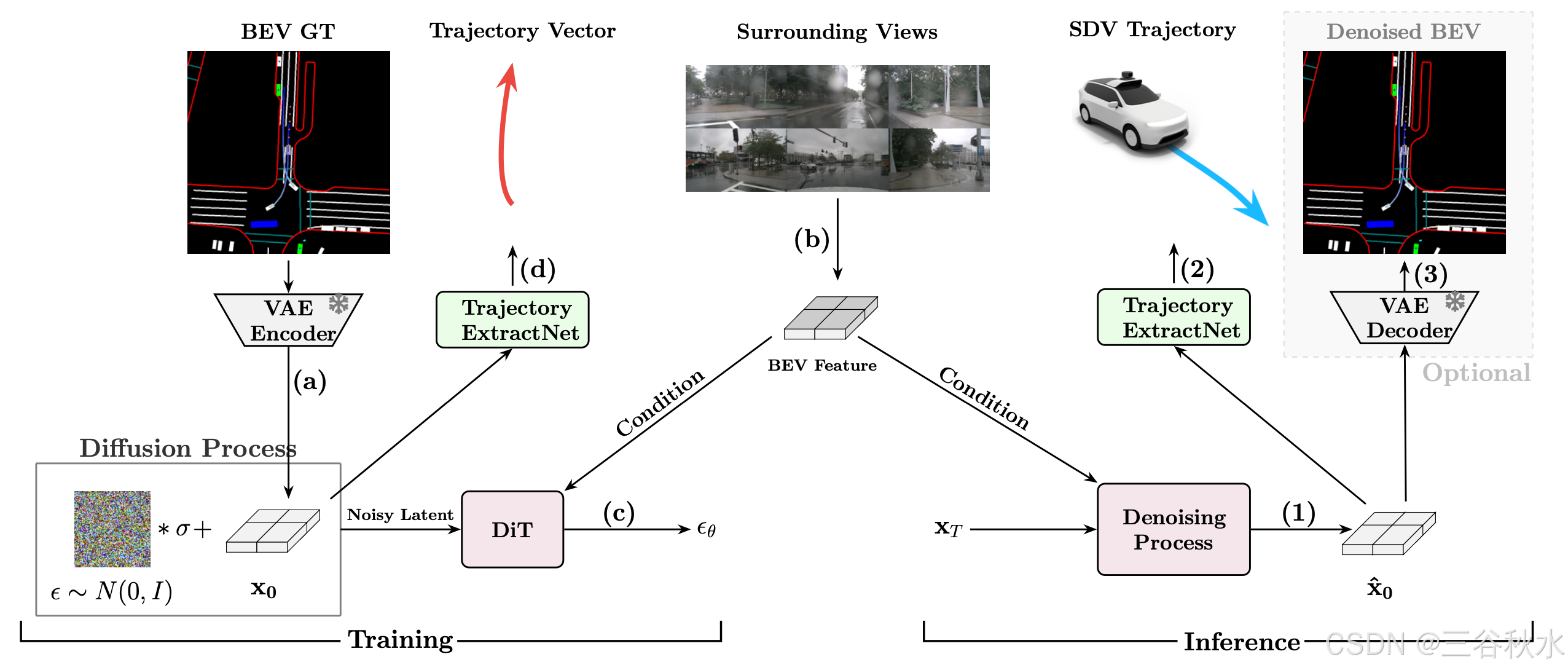
訓練過程:
- 柵格化和潛空間編碼:DiffAD 首先將感知、預測和規劃目標柵格化為 BEV 圖像。然后使用現成的 VAE 編碼器將 BEV 圖像壓縮到潛空間以進行降維。
- 特征提取和轉換:將周圍視圖圖像輸入到特征提取器中,該提取器將生成的透視圖特征轉換為統一的 BEV 特征。
- 用于噪聲預測的擴散模型:將高斯噪聲添加到潛 BEV 圖像中以獲得噪聲潛圖像。訓練擴散模型以根據 BEV 特征預測來自噪聲潛表示的噪聲。
- 軌跡提取:訓練基于查詢的 TEN,從潛 BEV 圖像中恢復自我智體的矢量化軌跡。
推理過程:
- 條件去噪:DiffAD 首先根據 BEV 特征,從純高斯噪聲中生成去噪的潛 BEV 圖像。
- 規劃提取:TEN 然后從潛 BEV 圖像中提取自智體的規劃軌跡。
- 解碼 BEV:通過將潛 BEV 圖像解碼回像素空間,可以獲得預測的 BEV 圖像以供解釋和調試。
據說開環評估不足以滿足 E2E 模型的要求 [19, 26]。為了解決這個問題,用 Bench2Drive 數據集在 CARLA 模擬器中進行訓練和閉環評估[8]。Bench2Drive 提供三個數據子集:mini(10 個剪輯用于調試)、base(1,000 個剪輯)和 full(10,000 個剪輯用于大規模研究)。按照 [19] 的方法,用基礎子集進行訓練。
訓練。用來自 Stable Diffusion[36] 的現成預訓練變分自動編碼器 (VAE) 模型 [23]。VAE 編碼器的下采樣因子為 8。在所有實驗中,擴散模型都在潛空間中運行。保留來自 DiT [34] 的擴散超參。為了促進學習過程,在第一階段從感知部分(即檢測和地圖)的單幅圖像學習開始,而預測和規劃 BEV 圖像則用零填充。然后在時間設置中與所有感知、預測和規劃部分聯合訓練模型。
推理。利用 DDIM-10 采樣器 [40] 進行推理,并使用官方評估工具 [19] 來計算閉環指標。對于車輛控制,采用官方提供的 PID 控制器。

)
)



)


)


:分布式存儲 Leader 設計)
)




)
)